BERT,GPT,ELMO模型对比
1. BERT模型深度解析
1.1 BERT核心架构详解
Embedding层三维融合:
-
Token Embeddings:词汇编码,包含[CLS]和[SEP]特殊标记
-
Segment Embeddings:句子分段编码,服务句子对任务
-
Position Embeddings:位置编码,通过学习获得而非三角函数计算
Transformer Encoder架构:
# BERT基础架构参数
config = {"hidden_size": 768, # 隐藏层维度"num_hidden_layers": 12, # Transformer层数(Base)"num_attention_heads": 12, # 注意力头数"intermediate_size": 3072, # 前馈网络维度"max_position_embeddings": 512 # 最大序列长度
}1.2 预训练任务技术细节
Masked LM技术实现:
def create_masked_lm_predictions(tokens, masked_lm_prob=0.15):cand_indices = []for i, token in enumerate(tokens):if token == "[CLS]" or token == "[SEP]":continuecand_indices.append(i)random.shuffle(cand_indices)output_tokens = list(tokens)num_to_predict = max(1, int(round(len(tokens) * masked_lm_prob)))masked_lms = []covered_indices = set()for index in cand_indices:if len(masked_lms) >= num_to_predict:breakif index in covered_indices:continuecovered_indices.add(index)# 80%概率替换为[MASK]if random.random() < 0.8:masked_token = "[MASK]"else:# 10%概率替换为随机词if random.random() < 0.5:masked_token = random.choice(vocab_list)# 10%概率保持原词else:masked_token = tokens[index]output_tokens[index] = masked_tokenmasked_lms.append({"index": index, "label": tokens[index]})return output_tokens, masked_lmsNSP任务实现:
def create_next_sentence_predictions(example_a, example_b):# 50%概率使用真实下一句if random.random() < 0.5:is_next = Truetokens_b = example_b# 50%概率使用随机句子else:is_next = Falsetokens_b = random.choice(other_documents)return tokens_b, is_next1.3 微调策略详解
不同任务的微调方式:
-
句子分类任务:使用[CLS]标记的输出向量
-
序列标注任务:使用每个token对应的输出向量
-
问答任务:使用问题与段落拼接的特殊处理
-
句子对任务:使用两个句子拼接的特殊编码
2. BERT系列模型技术演进
2.1 AlBERT架构创新
参数共享机制:
# 传统BERT参数计算
total_params = (vocab_size * hidden_size + # Embeddinghidden_size * hidden_size * 4 * num_layers + # Attentionhidden_size * intermediate_size * 2 * num_layers) # FFN# AlBERT参数计算
total_params = (vocab_size * projection_dim + # 因式分解Embeddingprojection_dim * hidden_size +(hidden_size * hidden_size * 4 + # 共享参数hidden_size * intermediate_size * 2))SOP任务设计:
-
正样本:句子A + 句子B(正常顺序)
-
负样本:句子B + 句子A(颠倒顺序)
-
相比NSP更能捕捉句子间语义关系
2.2 RoBERTa优化策略
训练策略改进:
-
动态Masking:每个epoch重新生成mask模式
-
更大批次训练:batch size从256增加到8000
-
移除NSP任务:发现对性能有负面影响
-
更长的序列:使用全长512token序列训练
2.3 中文优化模型
MacBert中文特色:
# 中文MLM策略
def chinese_mlm_strategy(text):words = jieba.cut(text)masked_text = []for word in words:if should_mask(word): # 根据n-gram概率决定# 使用同义词替换而非[MASK]synonym = find_synonym(word)masked_text.append(synonym)else:masked_text.append(word)return "".join(masked_text)3. ELMo模型技术深度解析
3.1 双向语言模型架构
前向LSTM计算:
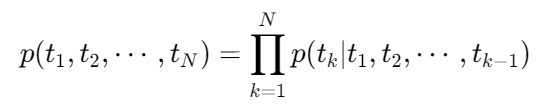
后向LSTM计算:
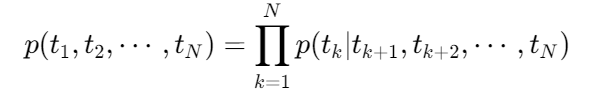
特征融合公式:
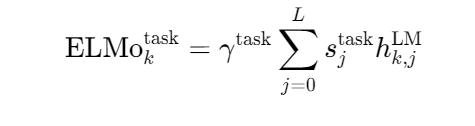
3.2 具体实现细节
字符级CNN编码:
class CharCNNEncoder(nn.Module):def __init__(self, char_vocab_size, char_embed_dim=50, num_filters=100):super().__init__()self.char_embedding = nn.Embedding(char_vocab_size, char_embed_dim)self.convs = nn.ModuleList([nn.Conv2d(1, num_filters, (filter_size, char_embed_dim))for filter_size in [1, 2, 3, 4, 5, 6, 7]])def forward(self, char_ids):# char_ids: [batch_size, seq_len, max_word_len]batch_size, seq_len, max_word_len = char_ids.shape# 字符嵌入char_embeds = self.char_embedding(char_ids) # [batch_size, seq_len, max_word_len, embed_dim]char_embeds = char_embeds.view(-1, max_word_len, char_embed_dim)char_embeds = char_embeds.unsqueeze(1) # 添加通道维度# 多尺度卷积conv_outputs = []for conv in self.convs:conv_out = conv(char_embeds) # [batch_size*seq_len, num_filters, output_len, 1]conv_out = F.relu(conv_out.squeeze(3))conv_out = F.max_pool1d(conv_out, conv_out.size(2)).squeeze(2)conv_outputs.append(conv_out)# 特征拼接word_embeds = torch.cat(conv_outputs, 1)word_embeds = word_embeds.view(batch_size, seq_len, -1)return word_embeds4. GPT模型架构深度分析
4.1 Transformer Decoder改造
Masked Multi-Head Attention:
class MaskedSelfAttention(nn.Module):def __init__(self, hidden_size, num_heads):super().__init__()self.attention = nn.MultiheadAttention(hidden_size, num_heads)def forward(self, x, mask=None):# 创建look-ahead maskif mask is None:seq_len = x.size(1)mask = torch.triu(torch.ones(seq_len, seq_len), diagonal=1).bool()# 注意力计算attn_output, _ = self.attention(x, x, x, attn_mask=mask)return attn_outputGPT-2架构参数:
gpt2_config = {"vocab_size": 50257, # 字节对编码词汇表大小"n_positions": 1024, # 最大序列长度"n_ctx": 1024, # 上下文长度"n_embd": 768, # 嵌入维度"n_layer": 12, # Transformer层数"n_head": 12, # 注意力头数"layer_norm_epsilon": 1e-5, # LayerNorm epsilon
}4.2 训练策略
语言模型训练目标:
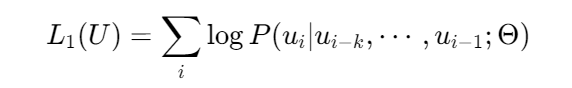
下游任务微调:
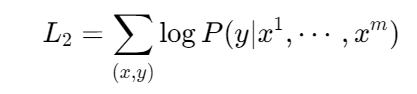
综合优化目标:
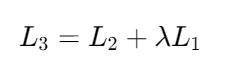
5. 三大模型对比分析
5.1 架构对比表
| 特征 | BERT | GPT | ELMo |
|---|---|---|---|
| 基础架构 | Transformer Encoder | Transformer Decoder | 双向LSTM |
| 语言模型 | 双向 | 单向 | 表面双向 |
| 特征提取 | ★★★★★ | ★★★★☆ | ★★★☆☆ |
| 生成能力 | ★★☆☆☆ | ★★★★★ | ★★★☆☆ |
| 理解能力 | ★★★★★ | ★★★☆☆ | ★★★★☆ |
| 训练效率 | ★★★☆☆ | ★★★★☆ | ★★★☆☆ |
| 资源消耗 | 高 | 中 | 中 |
5.2 具体技术差异
注意力机制对比:
# BERT的注意力(双向)
attention_mask = (input_ids != padding_id).float()# GPT的注意力(单向)
seq_len = input_ids.size(1)
attention_mask = torch.triu(torch.ones(seq_len, seq_len), diagonal=1)# ELMo的注意力(无注意力机制,使用LSTM)位置编码差异:
-
BERT:学习得到的位置嵌入
-
GPT:学习得到的位置嵌入
-
ELMo:无显式位置编码,依赖LSTM的顺序处理
5.3 性能对比分析
GLUE基准测试结果:
| 模型 | CoLA | SST-2 | MRPC | STS-B | QQP | MNLI | QNLI | RTE | Average |
|---|---|---|---|---|---|---|---|---|---|
| BERT-base | 52.1 | 93.5 | 84.8 | 85.8 | 71.2 | 84.6 | 90.5 | 66.4 | 79.0 |
| GPT | 45.4 | 91.3 | 82.3 | 80.0 | 70.3 | 81.8 | 87.2 | 62.3 | 75.1 |
| ELMo | 36.5 | 90.4 | 78.5 | 75.3 | 68.4 | 78.5 | 85.5 | 59.5 | 71.6 |
6. 实际应用指南
6.1 模型选择策略
根据任务类型选择:
-
文本分类:BERT系列(特别是RoBERTa)
-
序列标注:BERT + CRF
-
文本生成:GPT系列
-
语义相似度:Sentence-BERT
-
轻量级应用:AlBERT或DistilBERT
根据资源约束选择:
-
计算资源充足:BERT-large、GPT-3
-
中等资源:BERT-base、GPT-2
-
资源受限:AlBERT、DistilBERT、TinyBERT
6.2 微调最佳实践
学习率设置:
# BERT微调学习率设置
optimizer = AdamW([{'params': model.bert.parameters(), 'lr': 2e-5},{'params': model.classifier.parameters(), 'lr': 1e-4}
], weight_decay=0.01)# 学习率预热
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=100, num_training_steps=1000
)批次大小与序列长度:
# 不同任务的推荐配置
task_configs = {"text_classification": {"batch_size": 16,"max_length": 128,"gradient_accumulation_steps": 1},"sequence_labeling": {"batch_size": 8,"max_length": 256,"gradient_accumulation_steps": 2},"question_answering": {"batch_size": 4,"max_length": 384,"gradient_accumulation_steps": 4}
}7. 进阶主题与未来发展
7.1 模型压缩技术
知识蒸馏:
# Teacher-Student蒸馏
def distillation_loss(student_logits, teacher_logits, true_labels, alpha=0.5, temperature=2.0):# 知识蒸馏损失soft_teacher = F.softmax(teacher_logits / temperature, dim=-1)soft_student = F.log_softmax(student_logits / temperature, dim=-1)kl_loss = F.kl_div(soft_student, soft_teacher, reduction='batchmean') * (temperature ** 2)# 标准交叉熵损失ce_loss = F.cross_entropy(student_logits, true_labels)return alpha * kl_loss + (1 - alpha) * ce_loss模型剪枝:
def magnitude_pruning(model, pruning_rate=0.2):parameters_to_prune = []for name, module in model.named_modules():if isinstance(module, nn.Linear):parameters_to_prune.append((module, 'weight'))prune.global_unstructured(parameters_to_prune,pruning_method=prune.L1Unstructured,amount=pruning_rate,)7.2 多模态扩展
ViLT(Vision-and-Language Transformer):
class ViLT(nn.Module):def __init__(self, text_model, image_model, hidden_size):super().__init__()self.text_encoder = text_modelself.image_encoder = image_modelself.cross_attention = nn.MultiheadAttention(hidden_size, 8)def forward(self, text_input, image_input):text_features = self.text_encoder(text_input)image_features = self.image_encoder(image_input)# 跨模态注意力combined_features = torch.cat([text_features, image_features], dim=1)attended_features, _ = self.cross_attention(combined_features, combined_features, combined_features)return attended_features8. 实践代码示例
8.1 BERT文本分类完整示例
from transformers import BertTokenizer, BertForSequenceClassification
from transformers import Trainer, TrainingArguments
import torch
from datasets import load_dataset# 加载tokenizer和模型
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)# 数据处理函数
def preprocess_function(examples):return tokenizer(examples['text'], truncation=True, padding='max_length', max_length=128)# 加载数据集
dataset = load_dataset('imdb')
tokenized_dataset = dataset.map(preprocess_function, batched=True)# 训练参数设置
training_args = TrainingArguments(output_dir='./results',num_train_epochs=3,per_device_train_batch_size=16,per_device_eval_batch_size=16,warmup_steps=500,weight_decay=0.01,logging_dir='./logs',logging_steps=10,evaluation_strategy="epoch"
)# 创建Trainer
trainer = Trainer(model=model,args=training_args,train_dataset=tokenized_dataset['train'],eval_dataset=tokenized_dataset['test'],tokenizer=tokenizer
)# 开始训练
trainer.train()8.2 GPT文本生成示例
from transformers import GPT2Tokenizer, GPT2LMHeadModel
import torch# 加载模型和tokenizer
tokenizer = GPT2Tokenizer.from_pretrained('gpt2-medium')
model = GPT2LMHeadModel.from_pretrained('gpt2-medium')
model.eval()def generate_text(prompt, max_length=100, temperature=0.7):inputs = tokenizer.encode(prompt, return_tensors='pt')with torch.no_grad():outputs = model.generate(inputs,max_length=max_length,temperature=temperature,do_sample=True,top_k=50,top_p=0.95,num_return_sequences=1)return tokenizer.decode(outputs[0], skip_special_tokens=True)# 生成文本
prompt = "人工智能的未来发展"
generated_text = generate_text(prompt)
print(generated_text)这份深度复习笔记涵盖了BERT、GPT、ELMo三大预训练模型的详细技术内容,包括架构细节、训练策略、性能对比和实践代码,适合深入学习和复习使用。