大模型推理中的 Prefill/Decode 分离技术的一些思考
近年来,随着大语言模型(Large Language Models, LLMs)在各类应用场景中广泛部署,如何高效、稳定、低成本地提供推理服务,已成为工业界关注的核心问题。在这一背景下,“PD 分离”——即 Prefill(预填充)与 Decode(解码)阶段的分离调度——逐渐成为高性能推理引擎的关键优化技术。
Prefill与 Decode 解耦,是指将LLM推理过程中的预填充阶段与解码阶段分离开来。LLM 应用通常对每个阶段的延迟有明确要求:预填充阶段关注首 token 响应时间(Time To First Token,TTFT),而解码阶段则关注每个输出 token 的时间(Time Per Output Token,TPOT)。
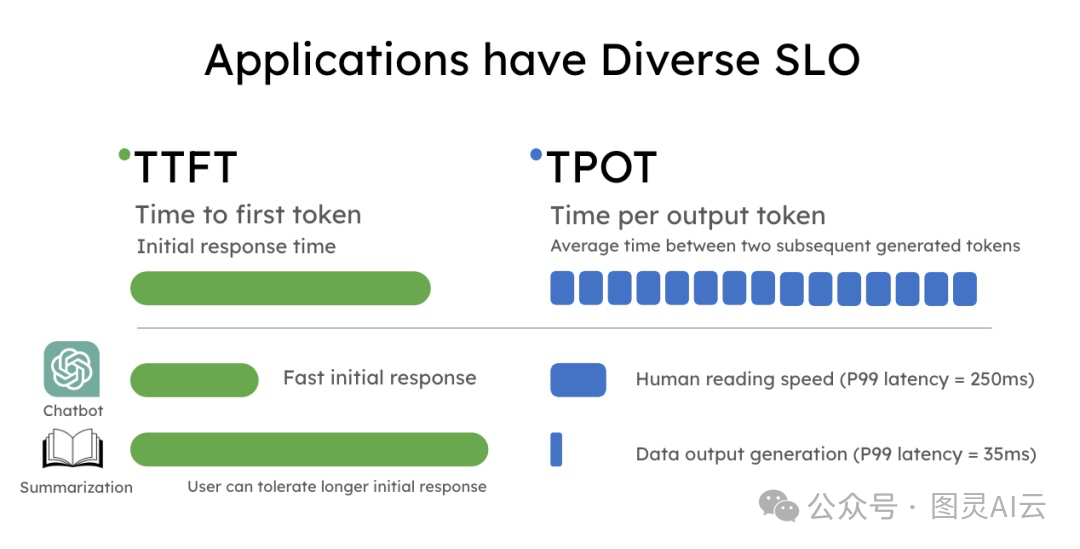
为了提供更好的用户体验,不同的应用会优化不同的目标。例如,实时聊天机器人系统优先优化低 TTFT,而像 DeepResearch 这类应用则希望降低 TPOT,以缩短整体生成时间。将预填充与解码解耦,可以在每个阶段独立进行优化,从而提高 GPU 的利用率。
为何需要PD分离?
在自回归大语言模型(如 Llama、Qwen、ChatGLM 等)的推理过程中,生成一段文本分为两个逻辑阶段:
-
1. Prefill 阶段(P):
将用户输入的完整提示(prompt)一次性送入模型,计算所有输入 token 的隐藏状态,并生成对应的 Key-Value Cache(KV Cache)。该过程可高度并行,计算密集,但仅执行一次。 -
2. Decode 阶段(D):
从第一个生成 token 开始,模型逐个自回归地输出新 token。每一步仅处理一个 token,完全依赖前序生成的 KV Cache,计算量小但需反复执行,直至生成结束符或达到最大长度。
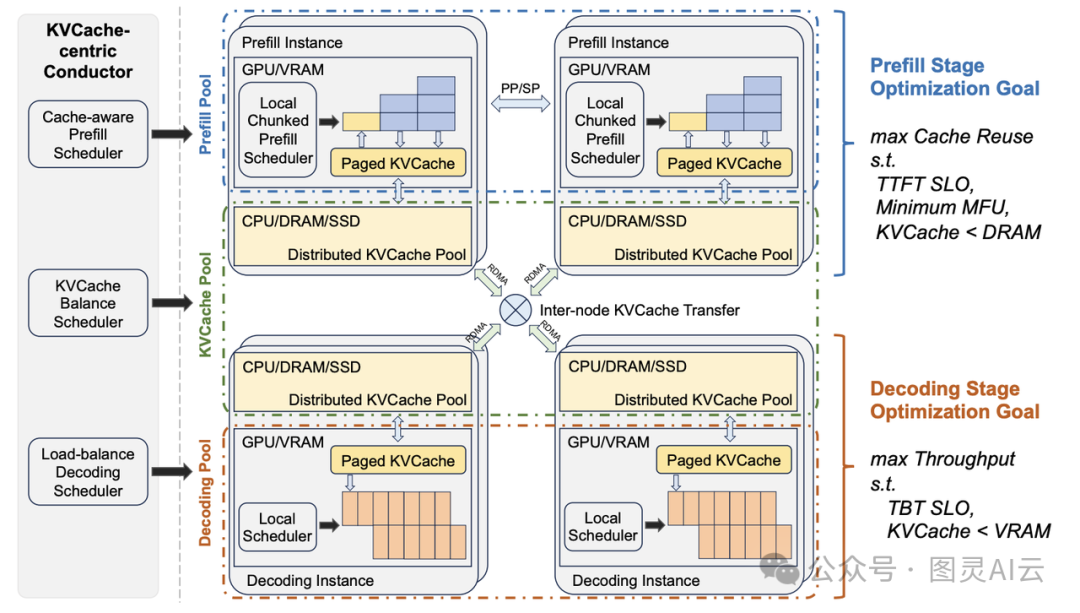
图为 kimi 的 mooncake架构
这两个阶段在计算特征上存在显著差异:
| 维度 | Prefill | Decode |
| 并行性 | 高(整个 prompt 可并行处理) | 低(逐 token 串行) |
| 计算强度 | 高(大量矩阵乘) | 低(以访存为主) |
| 显存带宽压力 | 中等 | 极高(频繁读写 KV Cache) |
| 延迟敏感度 | 相对较低(影响 TTFT) | 极高(直接影响 TPOT 和交互体验) |
若将 Prefill 与 Decode 混合在同一调度单元中处理,会导致以下问题:
-
• 资源争抢:长 prompt 的 Prefill 占用大量计算资源,阻塞短请求的 Decode,拉高尾延迟(P99 latency);
-
• 批处理效率下降:混合调度难以对不同阶段任务进行有效批合并(batching),GPU 利用率波动大;
-
• 服务质量不稳定:交互式应用(如聊天机器人)对 Decode 延迟极为敏感,但可能被后台长文本生成任务拖累。
因此,将 Prefill 与 Decode 在调度层面解耦,实现“按需分配、各司其职”,成为提升推理系统吞吐量与服务质量的关键路径。这便是 PD 分离的核心动因。
KV Cache:PD 分离的基石
要深入理解 PD 分离,必须厘清 KV Cache 的原理与实现机制——它是连接 Prefill 与 Decode 的桥梁,也是推理显存消耗的“大头”。
1. KV Cache 的原理
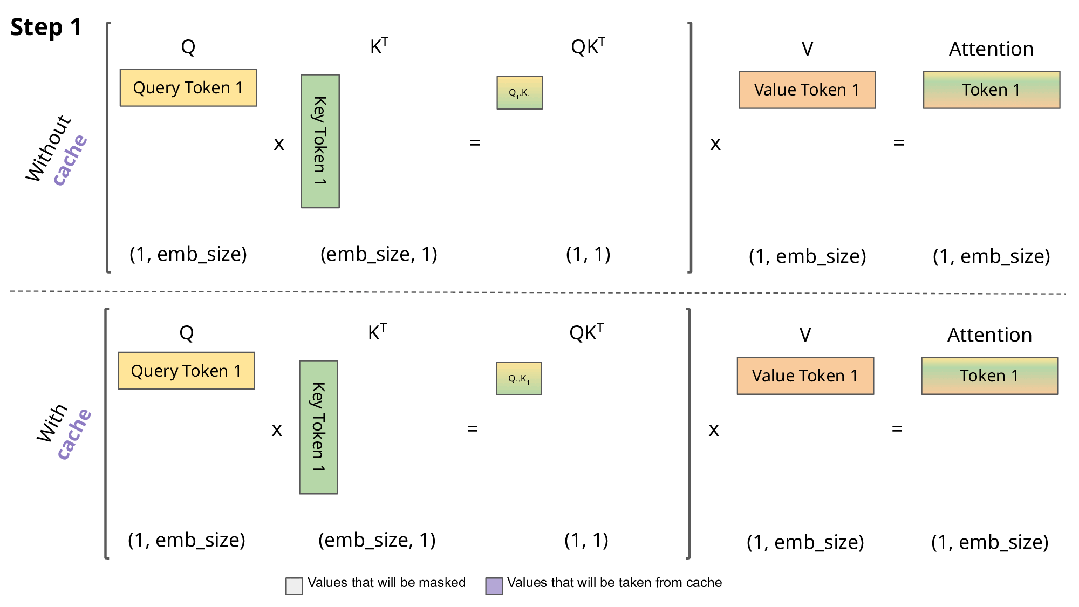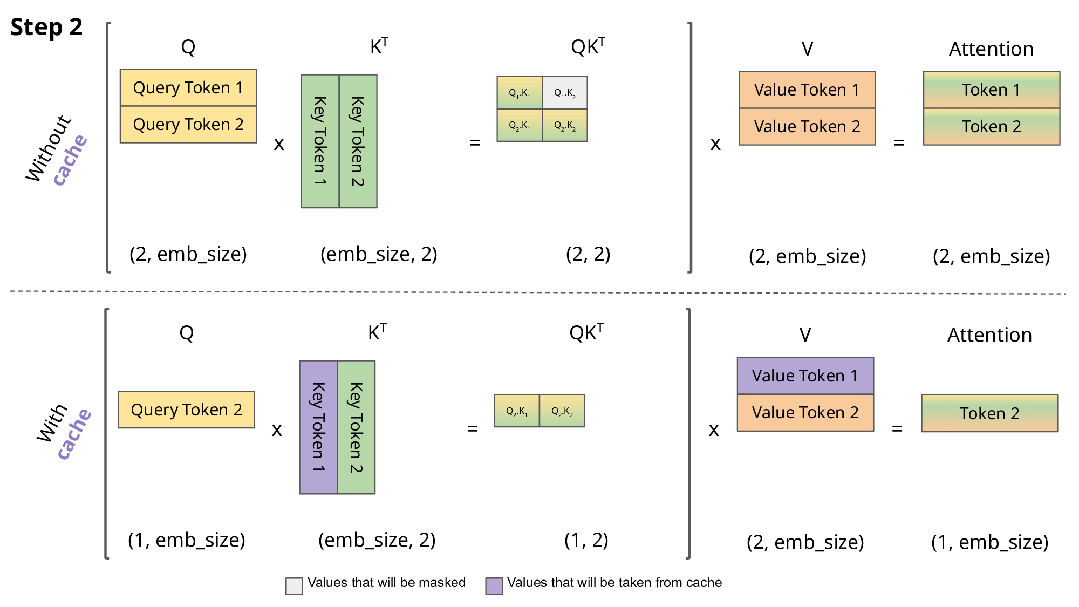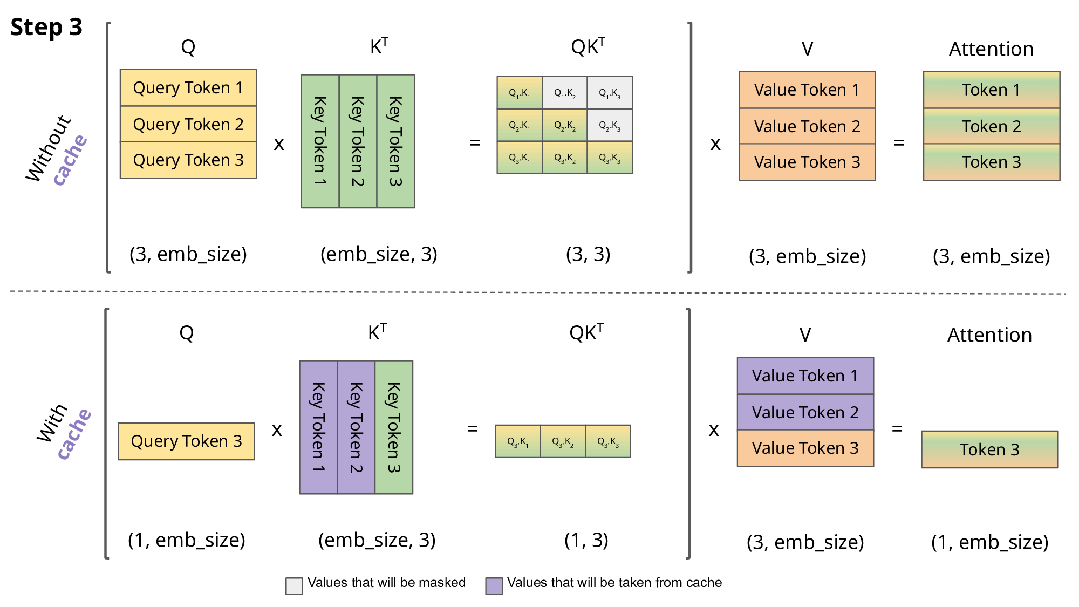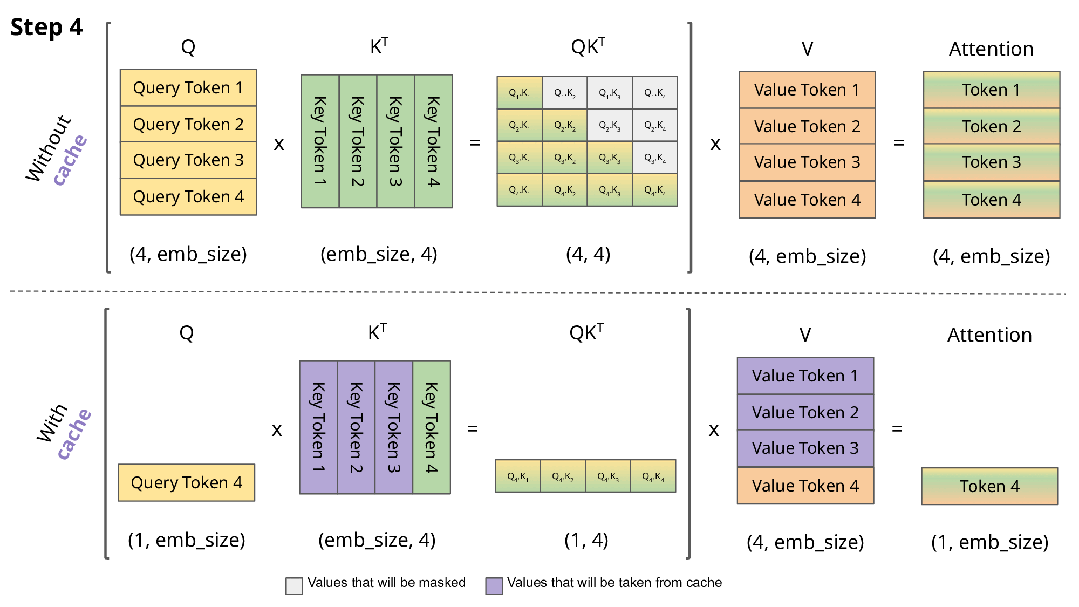
图来源: https://blog.csdn.net/ningyanggege/article/details/134564203
在 Transformer 架构中,自注意力机制需要计算所有历史 token 与当前 token 的相关性。若每次生成新 token 都重新计算全部历史注意力,时间复杂度将呈平方级增长(O(n²))。为避免重复计算,推理时采用 KV Cache 技术:
-
• 在 Prefill 阶段,对 prompt 中的每个 token,计算其对应的 Key(K)和 Value(V)向量,并缓存;
-
• 在 Decode 阶段,每生成一个新 token,仅计算其 K/V,并追加到已有缓存中,同时注意力计算复用全部历史 K/V。
由此,每次 Decode 步骤的计算复杂度降至 O(n),显著提升生成效率。
2. KV Cache 的存储开销
以 Llama-7B 为例:
-
• 每层有 32 个注意力头,hidden size 为 4096;
-
• 每个 token 的 K/V 向量维度为 4096/32 = 128;
-
• 单个 token 在一层中占用显存:2(K+V) × 128 × 2(float16) = 512 字节;
-
• 32 层共需:512 × 32 ≈ 16 KB/token;
-
• 若上下文长度为 8192,则单个请求的 KV Cache 约需 128 MB。
在高并发场景下,KV Cache 可占 GPU 显存的 70% 以上,成为推理系统的瓶颈。
3. KV Cache 的高效管理:PagedAttention 与分块机制
传统实现中,KV Cache 需连续显存分配,导致严重内存碎片(类似操作系统中的“外部碎片”)。为此,vLLM 提出 PagedAttention 技术:
-
• 将逻辑上的 KV Cache 序列划分为固定大小的“页”(如每页 16 个 token);
-
• 物理显存以页为单位分配,逻辑页可映射到任意物理页;
-
• 支持非连续存储,显存利用率提升至 90%+;
-
• 为 PD 分离中的 Decode 阶段提供灵活、高效的缓存访问能力。
此外,TensorRT-LLM 等框架采用 块状 KV Cache(Block-wise KV Cache),结合 CUDA Graph 优化访存路径,进一步降低 Decode 阶段的延迟。
PD 分离的核心思想与关键技术
PD 分离并非改变模型结构,而是一种推理调度架构的优化策略,其核心思想是:识别并分离两类计算模式,分别进行资源分配与调度优化。
关键技术包括:
-
1. 双队列调度机制
推理引擎内部维护两个任务队列:Prefill 队列与 Decode 队列。新请求首先进入 Prefill 队列;Prefill 完成后,其生成状态(含 KV Cache)被移入 Decode 队列,等待后续 token 生成。 -
2. 连续批处理(Continuous Batching)
在各自队列内,系统动态合并多个请求进行批处理。例如,vLLM 的调度器可将多个 Decode 请求合并为一个 batch,即使它们处于不同生成步长,通过 PagedAttention 技术高效管理非连续显存。 -
3. 显存高效管理(如 PagedAttention)
KV Cache 通常占据推理显存的 70% 以上。PD 分离依赖高效的显存抽象(如将逻辑序列分页映射到物理显存块),使得 Prefill 生成的 Cache 可被 Decode 阶段灵活复用,避免内存碎片。 -
4. 优先级与资源配比控制(可选)
在高并发场景下,可为 Decode 队列设置更高调度优先级,或动态调整分配给两个阶段的 GPU 流处理器比例,保障交互式请求的响应速度。
如何使用?代码示例与底层机制
对终端用户而言,PD 分离通常由推理引擎自动完成,无需显式编程。但理解其机制有助于合理设计请求与监控性能。
以下以开源推理引擎 vLLM 为例,展示其如何隐式实现 PD 分离:
from vllm import LLM, SamplingParams# 初始化 LLM 引擎(自动启用 PD 分离 + Continuous Batching)
llm = LLM(model="Qwen/Qwen2-7B-Instruct",tensor_parallel_size=2, # 多 GPU 并行max_model_len=8192, # 支持长上下文gpu_memory_utilization=0.9 # 高显存利用率
)# 混合长度的用户请求
prompts = ["你好!", # 短 prompt,Prefill 快,Decode 少"请写一篇关于人工智能伦理的 1000 字议论文,要求结构清晰、论据充分。"# 长 prompt
]sampling_params = SamplingParams(temperature=0.7,max_tokens=512,stop=["\n\n"] # 自定义停止符
)# vLLM 内部自动:
# 1. 为每个 prompt 执行 Prefill(并行计算)
# 2. 生成完整的 KV Cache 并分页存储
# 3. 将生成状态加入 Decode 队列
# 4. 动态合并多个 Decode 请求进行批处理
outputs = llm.generate(prompts, sampling_params)for i, output inenumerate(outputs):print(f"【回复 {i+1}】\n{output.outputs[0].text}\n") 在 vLLM 源码中(vllm/engine/llm_engine.py 和 vllm/core/scheduler.py),可清晰看到 prefill 与 decoding 两类请求的分离管理逻辑。KV Cache 的生命周期由 BlockSpaceManager 统一管理,确保 Prefill 与 Decode 之间的状态无缝传递。
企业落地实践与可借鉴经验
在真实业务场景中,PD 分离的价值已得到充分验证。以下为若干典型经验:
-
1. 性能监控需分阶段
某头部大模型 API 平台在监控系统中分别采集 Prefill 延迟与 Decode 延迟。发现当用户 prompt 平均长度从 100 增至 2000 时,Prefill P99 延迟上升 5 倍,但 Decode 几乎不变。据此优化了长文本请求的限流策略。 -
2. 资源配比动态调优
一家智能客服企业通过 A/B 测试发现,在其 80% 为短问答的场景下,将 70% 的 GPU 计算时间分配给 Decode 阶段,整体 QPS 提升 35%,P99 延迟下降 40%。 -
3. 结合请求分类做调度
某内容生成平台对请求打标(如“chat”“summarize”“code”),对“chat”类请求赋予 Decode 阶段更高优先级,确保对话流畅性;对“summarize”类则允许 Prefill 占用更多资源。 -
4. 硬件选型匹配阶段特征
在边缘推理场景中,有企业尝试用高带宽显卡(如 L4)专司 Decode(访存密集),而将 Prefill(计算密集)卸载至云端 A100 集群,实现成本与性能的平衡。
未来演进:从 PD 分离到“计算-访存-通信”协同调度
当前 PD 分离已显著提升推理效率,但随着以下技术的发展,其架构正向更细粒度的协同调度演进:
1. 推测解码(Speculative Decoding)
该技术引入一个小型“草稿模型”(draft model)并行生成多个候选 token,再由大模型“验证”(verify)这些 token。其核心挑战在于:
-
• 草稿模型的 Prefill/Decode 与主模型的验证阶段需紧密协同;
-
• KV Cache 需在多个模型间共享或快速重建;
-
• 调度器需动态决定“推测长度”与“验证批大小”。
此时,简单的 Prefill/Decode 二分法已不足,需进一步拆解为 “草稿生成—验证计算—KV 同步” 多阶段流水线,调度粒度细化至“计算单元”与“访存单元”的协同。
2. 分块预填充(Chunked Prefill)
为支持超长上下文(如 1M token),传统一次性 Prefill 会因显存溢出而失败。Chunked Prefill 将 prompt 分块处理:
-
• 每块独立执行 Prefill,逐步累积 KV Cache;
-
• 各块之间存在数据依赖,需通信同步;
-
• 可与 Decode 阶段重叠执行(流水线 Prefill)。
这要求调度器不仅区分 P/D,还需管理 Prefill 内部的块间依赖 与 Prefill-Decode 间的流水线气泡,调度逻辑从“两阶段”扩展为“多阶段流水”。
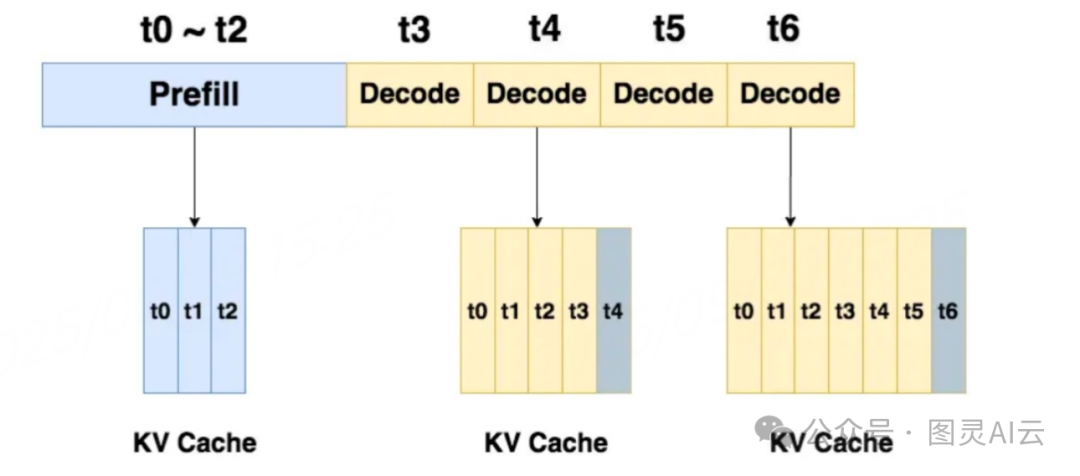
如图,展示了 KV Cache(键值缓存)在不同时间阶段(t0 到 t6)的运作情况,主要分为两个阶段:
1) Prefill(预填充)阶段(t0~t2) :在这段时间内,KV Cache 正在进行预填充操作,将数据 t0、t1、t2 依次存入缓存中。这个阶段的目的是在系统开始正式处理之前,预先将可能需要的数据加载到缓存里,以提高后续处理的效率。
2) Decode(解码)阶段(t3~t6) :从 t3 开始进入解码阶段,此时缓存中已经有 t0、t1、t2 的数据,并且在每个时间点,缓存会继续添加新的数据。例如在 t3 时,缓存包含 t0、t1、t2、t3;在 t4 时,包含 t0 到 t4 的数据,依此类推,直到 t6 时,缓存中存有从 t0 到 t6 的完整数据序列。
3. 异构计算协同
未来推理系统可能融合 CPU、GPU、NPU、DPU 等多种硬件:
-
• CPU 负责请求解析与调度;
-
• GPU 执行高算力 Prefill;
-
• NPU 专司低功耗 Decode;
-
• DPU 加速 KV Cache 的网络传输(在分布式推理中)。
此时,PD 分离需升级为 跨设备的“计算-访存-通信”三维协同调度:
-
• 计算:分配不同算子到最优硬件;
-
• 访存:优化 KV Cache 在异构内存(HBM、DDR、CXL)间的布局;
-
• 通信:减少设备间数据搬运,尤其在多卡或多机场景下。
例如,NVIDIA 的 NVLink + Unified Memory 技术、Intel 的 AMX + CXL 架构,均在为这一范式提供硬件基础。
总结
Prefill/Decode 分离(PD 分离)是大模型推理系统从“能用”走向“好用”的重要一步。它以 KV Cache 为纽带,通过调度解耦,实现了对两类异构计算模式的精准优化。
当前,PD 分离已成为 vLLM、TensorRT-LLM、SGLang 等主流推理框架的标配能力。而随着推测解码、分块预填充、异构计算等技术的成熟,PD 分离正从“阶段解耦”迈向“操作级协同”,最终演化为覆盖计算、访存、通信三维度的智能调度范式。
最后,欢迎同行交流指正。