stack、queue与priority_queue的用法解析与模拟实现
一、stack、queue
1.1 stack、queue的使用
1.1.1 stack栈
首先就是对于stack这个栈的介绍可以看我们数据结构队列和栈数据结构-CSDN博客,简单介绍就是先进后出。
stack构造初始化

int main()
{stack<int> st({1,2,3,4,5});while (!st.empty()){cout << st.top() << ' ';st.pop();}return 0;
}
判断栈内是否有元素

stack<int> st2;if (st2.empty()){cout << "true";}else{cout << "false";}
计算有效元素个数

stack<int> st3({ 1,2,3,4,5,6 });cout << st3.size() << endl;

取栈顶元素

stack<int> st3({ 1,2,3,4,5,6 });cout << st3.top() << endl;

入栈(插入元素到栈中)

stack<int> st4;st4.push(1);st4.push(2);st4.push(3);st4.push(4);while (!st4.empty()){cout << st4.top() << ' ';st4.pop();}
出栈(将栈顶元素删除)

stack<int> st3({ 1,2,3,4,5,6 });cout << "pop之前" << st3.size() << endl;st3.pop();cout << "pop之后" << st3.size() << endl;
1.1.2 queue队列
对于queue队列的介绍同样也可以参考这个博客队列和栈数据结构-CSDN博客,简单介绍就是先进先出。
queue的初始化

queue<int> q1({ 1,2,3,4,5,6,7 });while (!q1.empty()){cout << q1.front() << " ";q1.pop();}
判断队列中是否有元素

queue<int> q2({ 1,2,3,4,5 });queue<int> q3;if (q2.empty())cout << "q2:" << "true";elsecout << "q2:" << "false";cout << endl;cout << endl;if (q3.empty())cout << "q3:" << "true";elsecout << "q3:" << "false";
计算队列中元素个数

queue<int> q4({1,2,3,4,5});cout << "q4.size():" << q4.size();
![]()
取对头元素

queue<int> q4({1,2,3,4,5});cout << "q4.front():" << q4.front();
![]()
取队尾元素

queue<int> q4({1,2,3,4,5});cout << "q4.back():" << q4.back();
![]()
在队尾插入一个元素

queue<int> q5;q5.push(1);q5.push(2);q5.push(3);q5.push(4);q5.push(5);while (!q5.empty()){cout << q5.front() << " ";q5.pop();}
![]()
从对头删一个删数据

queue<int> q6({ 1,2,3,4,5 });cout << "q6.pop()之前:" << q6.size()<<endl;q6.pop();cout << "q6.pop()之后:" << q6.size();

1.2 容器适配器
1.2.1 vector和list优缺点
| 优点 | 缺点 |
| 下标随机访问快,尾删尾插效率高(o(1)) | 头插头删中间插入删除效率低(o(n)) |
| cpu高速缓存命中率高(物理结构是连续的) | 插入过程扩容(1.5/2倍)导致空间浪费(会有性能亏损) |
| 优点 | 缺点 |
| 头查头删中间插入删除效率高(o(1)) | 不能支持下标随机访问,尾删尾插效率低(需要遍历o(n)) |
| 插入过程不需要扩容,创多少申请多少内存,节约空间 | cpu高速缓存命中率低(cpu会先缓存后面高地址,但是list是物理结构非连续) |
1.2.2 deque
容器适配器也是一个模板类,用于适配对应的容器(stack和queue)。

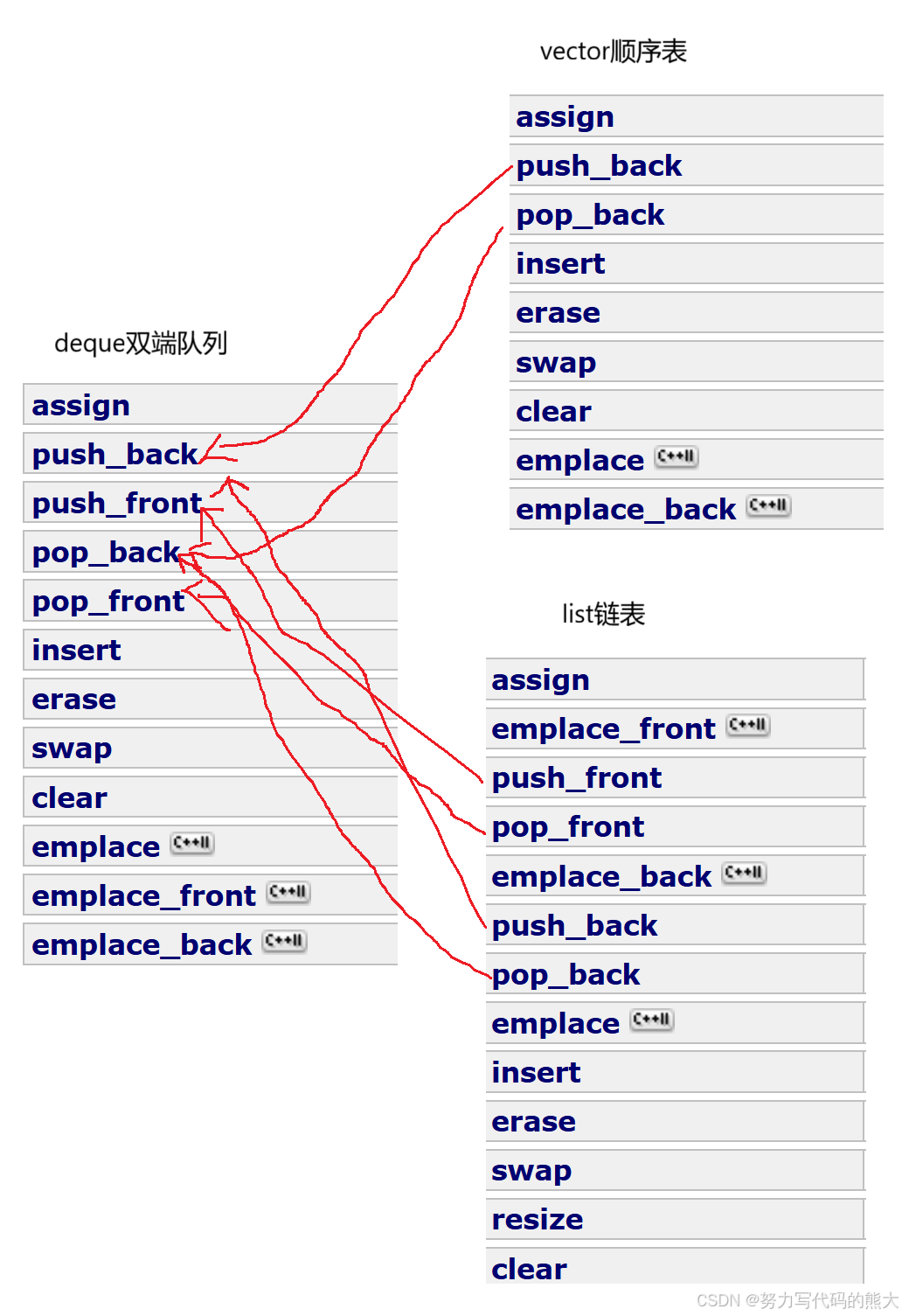
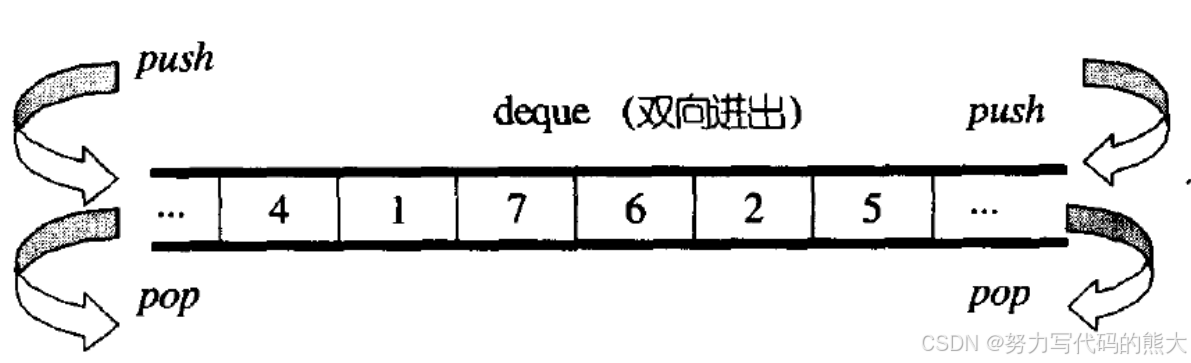
在stl中源码可参看CSDN代码共享资源: 分享比较常用的源码,并介绍展示源码的工作原来,里面也简单了解了原理。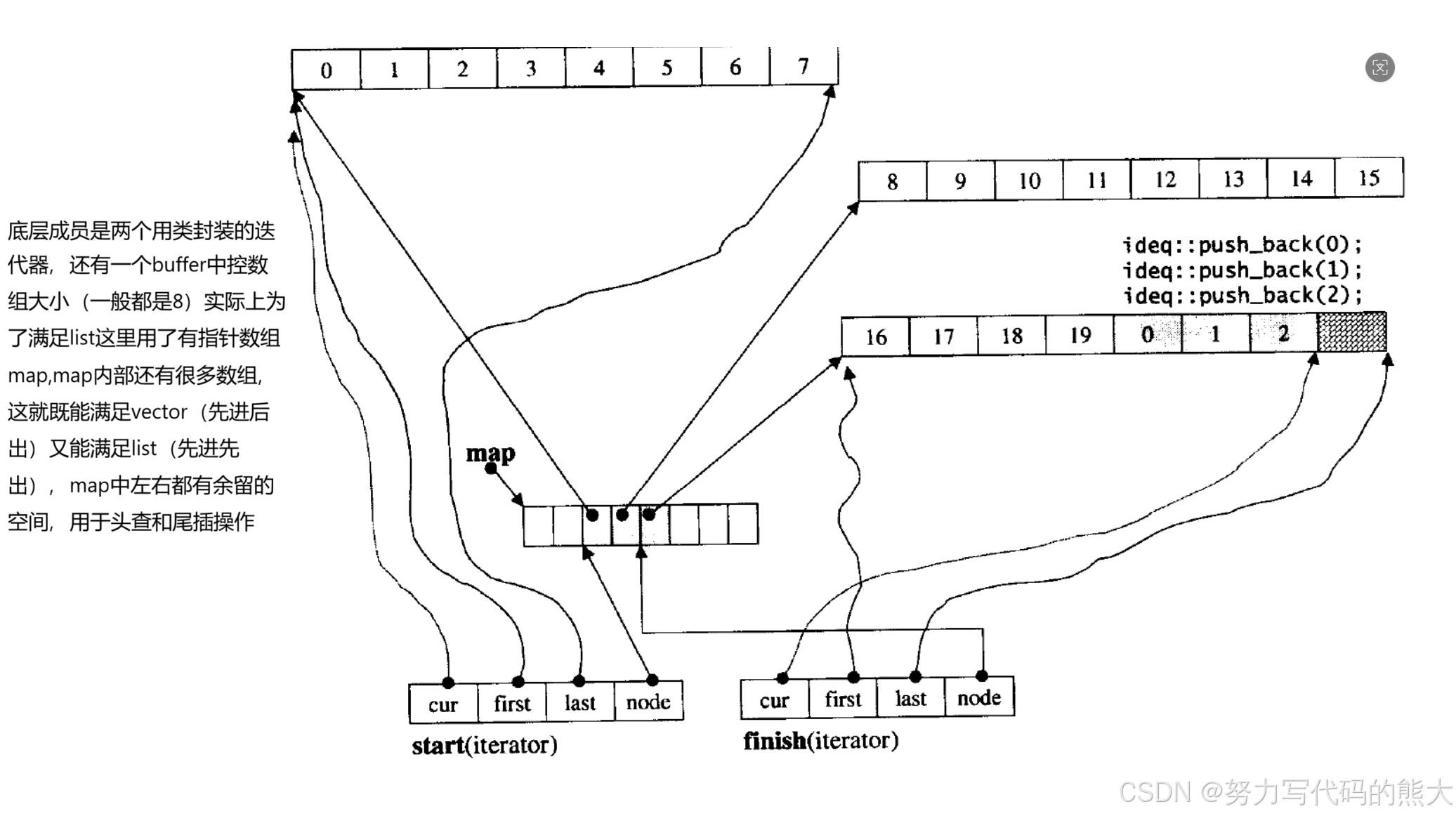
对于deque既能代替list和vector,但是他并不是针对某一个的数据结构而设计的,而是既满足list又满足vector,但是在某方面性能会不如list和vector,所以这个不能完全代替list和vector数据结构。
1.3 stack、queue的模拟
stack的底层是vector数组,queue的底层是list链表,但是上面我们说了容器适配器的概念,deque能够代替stack和vector的底层,所以stack和queue的模拟会很简单实现。
stack的模拟
namespace bear
{template<class T,class Contain = deque<T>>//T表示栈存储的类型,Contain表示容器适配器class stack{public://调用自定义类的内部构造函数(拷贝、初始化)stack(){}//入栈void push(const T& vaule){_con.push_back(vaule);}//删栈顶void pop(){_con.pop_back();}//计算栈内元素size_t size(){return _con.size();}//取栈顶数据(非const)T& top(){return _con.back();}//取栈顶数据(const)const T& top()const{return _con.back();}//判断栈内是否有元素bool empty(){return _con.empty();}private://自定义类成员Contain _con;};
}queue的模拟
namespace bear
{template<class T,class Contain = deque<T>>//T表示队列存储类型,Contain表示容器适配器(存储的数据结构)class queue{public://入队列void push(const T& vaule){_con.push_back(vaule);}//出队列void pop(){_con.pop_front();}//计算队列元素个数size_t size(){return _con.size();}//取对头元素(非const)T& front(){return _con.front();}//取对头元素(const)const T& front()const{return _con.front();}//取队尾元素(非const)T& back(){return _con.back();}//取队尾元素(const)const T& back()const{return _con.back();}//判读队列是否为空bool empty()const{return _con.empty();}private:Contain _con;};
}二、priority_queue
2.1 priority_queue的使用
priority_queue优先级队列就是和队列一样的使用方法,都满足先进后出的原理,只不过他这个队列出队列是有升序和降序的,其实底层本质就是内部是一个堆数据结构(具体可以参考这个堆博客堆数据结构_堆 数据结构-CSDN博客)
取对头数据(这里指排序后的对头)
priority_queue<int> pq;pq.push(3132);pq.push(123);pq.push(4000);pq.push(5000);pq.push(1000);pq.push(1);while (!pq.empty()){cout << pq.top() << ' ';//相当于取对头数据pq.pop();}

改变出对头数据顺序
priority_queue<int,vector<int>,greater<int>> pq;pq.push(3132);pq.push(123);pq.push(4000);pq.push(5000);pq.push(1000);pq.push(1);while (!pq.empty()){cout << pq.top() << ' ';pq.pop();}

2.2 仿函数使用和解释
首先我们先来写一个仿函数:
namespace bear
{//仿函数主体template<class T>struct less{bool compare(T& x, T& y){return x < y;}};//仿函数应用template<class T, class compare = less<T>>void BubbleSort(T* arr, int n, compare com){int flag = 0;for (int i = 0; i < n; i++){for (int j = 0; j < n - 1 - i; j++){//没仿函数的冒泡//if (arr[j] > arr[j + 1])//{// swap(arr[j], arr[j + 1]);// flag = 1;//}//有访函数的冒泡if (com(arr[j], arr[j + 1])){swap(arr[j], arr[j + 1]);flag = 1;}}if (flag == 0){break;}}}
}
这个仿函数功能和实现很简单,所以是没有成员变量的,但是大部分情况下可能需要自己写成员变量,来增加仿函数的功能:
状态保持:成员变量让仿函数可以在多次调用之间保持状态
配置灵活性:通过构造函数或setter方法配置仿函数的行为
信息记录:可以记录调用次数、处理的数据等信息
参数化行为:成员变量可以作为参数影响仿函数的逻辑
仿函数用于泛型函数(相当于函数指针,仿函数是用类封装然后再用模板去泛型,而函数指针则是用指针去封装),都是做的对应需求判断(也可以是需要的类型,不一定是bool类型,还能是int类型),然后进行控制最终结果。仿函数在类包装然后通过在其他类中使用该类模板来调用对应类的函数(该里面就和函数指针一样,传参这些,在外部仿函数是用类封装的,所以使用时是需要用匿名对象来传给另一个类)仿函数是模板函数,其速度比一般函数要慢,但是使得代码更加通用,简化了代码,还能用不同类型,通过不同类型代表不同的状态(也就是返回类型)
传模板时候我们只能传类型,而不是传对象,在传参时候就需要传对象,如下图:
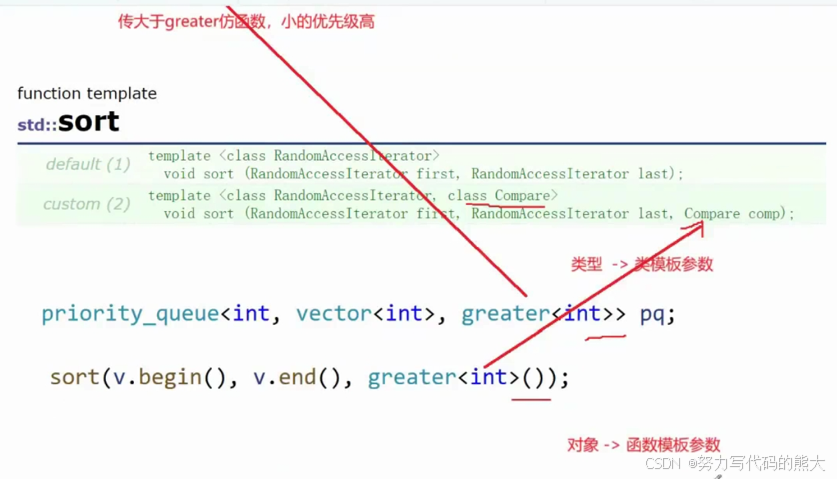
2.3 priority_queue的模拟
根据仿函数的使用和priority_queue的介绍,知道内部是一个堆结构,并通过仿函数来控制priority_queue的顺序。

整体结构
using namespace std;
namespace bear
{template<class T,class Contain = vector<T>,class Compare = less<T>>class priority_queue{public:private:Contain _con;};
}判断优先级队列是否有元素
//判断优先级队列为空bool empty()const{return _con.empty();}
计算优先级队列的元素个数
//计算优先级队列元素个数size_t size()const{return _con.size();}
取优先级队列的对头元素
//取优先级队列对头元素(非const)T& top(){return _con.front();}//const版本const T& top()const{return _con.front();}
向上建堆
//非仿函数比较void adjust_up(size_t child){size_t parent = (child - 1) / 2;while (child > 0){if (_con[parent] < _con[child]){swap(_con[parent], _con[child]);child = parent;parent = (child - 1) / 2;}else{break;}}}//仿函数template<class T>//大堆struct less{bool operator()(T& x, T& y)const{return x < y;}};//小堆template<class T>struct greater{bool operator()(T& x, T& y){return x > y;}};//仿函数比较void adjust_up(size_t child){Compare com;size_t parent = (child - 1) / 2;while (child > 0){if (com(_con[parent],_con[child])){swap(_con[parent], _con[child]);child = parent;parent = (child - 1) / 2;}else{break;}}}
向下建堆
//非仿函数比较void adjust_down(size_t parent){size_t child = (parent * 2) + 1;//默认左孩子while (child < size()){//判断左右孩子哪个大/小(还得防止越界)if (child + 1 < size() && _con[child] < _con[child + 1])child++;if (_con[parent] < _con[child]){swap(_con[parent], _con[child]);parent = child;child = parent * 2 + 1;}else{break;}}}template<class T>//大堆struct less{bool operator()(T& x, T& y)const{return x < y;}};//小堆template<class T>struct greater{bool operator()(T& x, T& y){return x > y;}};//仿函数比较void adjust_down(size_t parent){Compare com;size_t child = (parent * 2) + 1;//默认左孩子while (child < size()){//判断左右孩子哪个大/小(还得防止越界)if (child + 1 < size() && com(_con[child], _con[child + 1]))child++;if (com(_con[parent],_con[child])){swap(_con[parent], _con[child]);parent = child;child = parent * 2 + 1;}else{break;}}}
push入队尾数据(会按照堆结构进行排队,而不是插入顺序)
//入优先级队列void push(const T& value){_con.push_back(value);adjust_up(_con.size()-1);}pop删对头数据(通过堆结构进行排序,堆顶和堆尾交换进行尾删)
//删优先级队列对头void pop(){assert(!empty());//先交换堆顶和堆尾swap(_con[0], _con[size() - 1]);//再尾删_con.pop_back();if(size() != 1)//再进行调整堆adjust_down(0);}
初始化(迭代器给队列初始化)
priority_queue() = default;//用于调用默认构造template<class InputIterator>priority_queue(InputIterator first,InputIterator last):_con(first,last)//调用自定义成员的迭代器初始化{for (int i = (size() - 1-1) / 2; i >= 0; i--){adjust_down(i);}}
完整代码
#pragma once#include<vector>
#include<assert.h>using namespace std;
namespace bear
{template<class T>//大堆struct less{bool operator()(T& x, T& y)const{return x < y;}};//小堆template<class T>struct greater{bool operator()(T& x, T& y){return x > y;}};template<class T,class Contain = vector<T>,class Compare = less<T>>class priority_queue{public:priority_queue() = default;//用于调用默认构造template<class InputIterator>priority_queue(InputIterator first,InputIterator last):_con(first,last)//调用自定义成员的迭代器初始化{for (int i = (size() - 1-1) / 2; i >= 0; i--){adjust_down(i);}} //判断优先级队列为空bool empty()const{return _con.empty();}//计算优先级队列元素个数size_t size()const{return _con.size();}//取优先级队列对头元素(非const)T& top(){return _con.front();}//const版本const T& top()const{return _con.front();}//入优先级队列void push(const T& value){_con.push_back(value);adjust_up(_con.size()-1);}//删优先级队列对头void pop(){assert(!empty());//先交换堆顶和堆尾swap(_con[0], _con[size() - 1]);//再尾删_con.pop_back();if(size() > 0)//再进行调整堆adjust_down(0);}private:Contain _con;//会调用默认自定义类成员的构造函数//向上调整//小堆 <//大堆 >//void adjust_up(size_t child)//{// size_t parent = (child - 1) / 2;// while (child > 0)// {// if (_con[parent] < _con[child])// {// swap(_con[parent], _con[child]);// child = parent;// parent = (child - 1) / 2;// }// else// {// break;// }// }//}void adjust_up(size_t child){Compare com;size_t parent = (child - 1) / 2;while (child > 0){if (com(_con[parent],_con[child])){swap(_con[parent], _con[child]);child = parent;parent = (child - 1) / 2;}else{break;}}}//void adjust_down(size_t parent)//{// size_t child = (parent * 2) + 1;//默认左孩子// while (child < size())// {// //判断左右孩子哪个大/小(还得防止越界)// if (child + 1 < size() && _con[child] < _con[child + 1])// child++;// if (_con[parent] < _con[child])// {// swap(_con[parent], _con[child]);// parent = child;// child = parent * 2 + 1;// }// else// {// break;// }// }//}void adjust_down(size_t parent){Compare com;size_t child = (parent * 2) + 1;//默认左孩子while (child < size()){//判断左右孩子哪个大/小(还得防止越界)if (child + 1 < size() && com(_con[child], _con[child + 1]))child++;if (com(_con[parent],_con[child])){swap(_con[parent], _con[child]);parent = child;child = parent * 2 + 1;}else{break;}}}};
}三、总结
stack是一个先进后出数据结构,而queue是一个先进先出的数据结构,还有一个queue的展开就是优先级队列priority_queue,这里priority_queue的知识点较多,涉及到了仿函数和综合了堆排列。其次就是栈和队列,他们之间的模拟又涉及到了容器适配器deque(双端队列),以及让我们学习到该如何学习和了解源码。这里最主要的就是stack、queue和priority_queue的应用场景
stack |
算法和数据结构
实际开发
|
queue |
算法和数据结构
实际开发
|
priority_queue |
算法和数据结构
实际开发
|