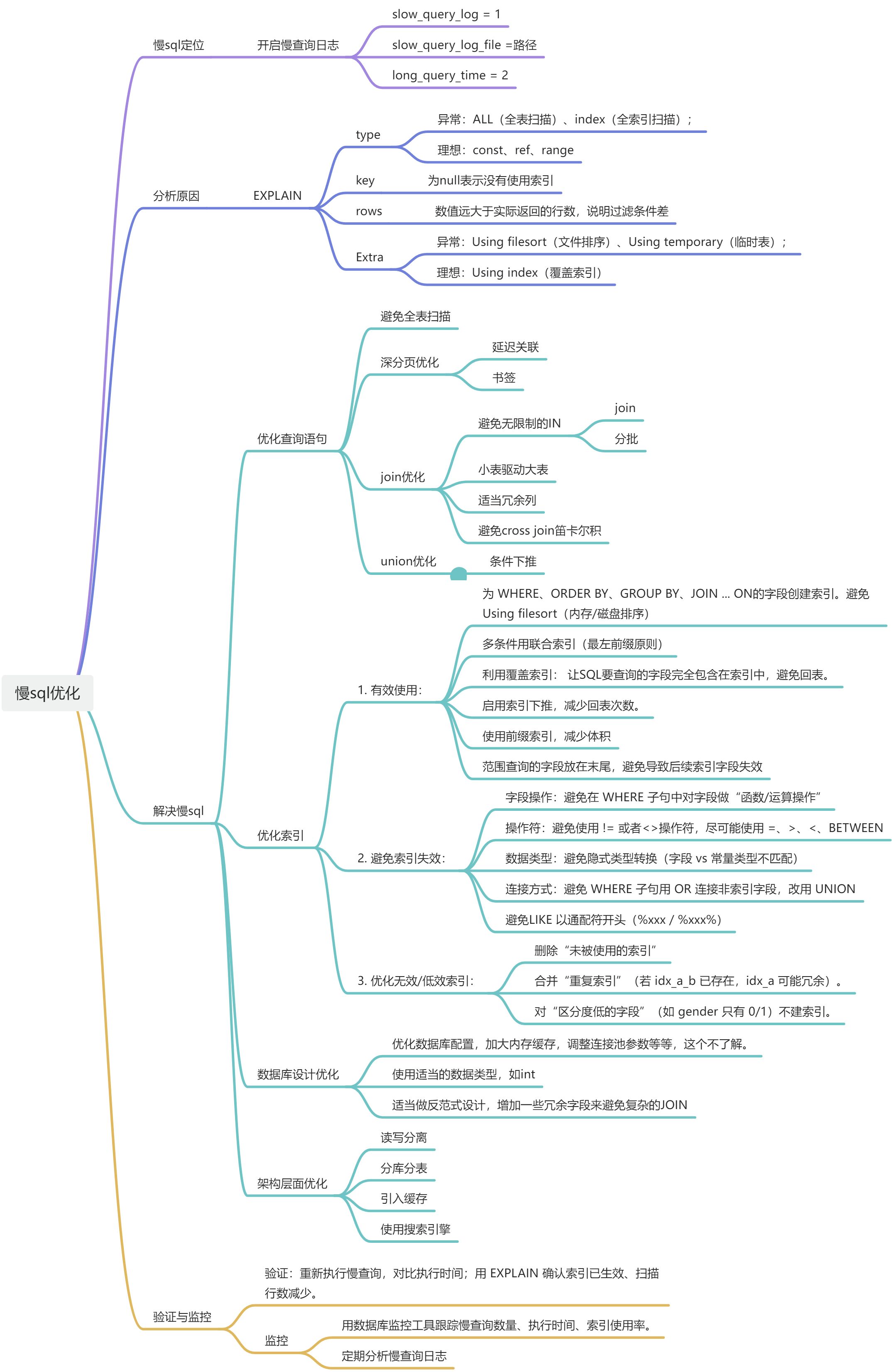
【MySQL】慢查寻的发现和解决优化(思维导图版)
“慢查询”是数据库领域的核心性能问题之一,指执行时间超过预设阈值(如 MySQL 的 long_query_time,默认 10 秒)的 SQL 语句。解决慢查询需遵循“定位问题 → 分析根源 → 优化执行 → 验证效果”的闭环流程,具体方案可从 查询本身、索引、数据库配置、架构设计 四个维度展开。
EXPLAIN
通过日志工具定位到慢查询后,需用 EXPLAIN 命令分析其 执行计划,明确慢的原因。EXPLAIN 会展示查询的索引使用、表连接方式、数据扫描量等关键信息。
①、id 列:查询的标识符。
- id 越大越先执行;相同 id 按从上到下顺序执行
复杂子查询可考虑改为 JOIN,减少嵌套层级
②、select_type 列:查询的类型。常见的类型有:
- SIMPLE:简单查询,不包含子查询或者 UNION 查询。
- PRIMARY:查询中如果包含子查询,则最外层查询被标记为 PRIMARY。
- SUBQUERY:子查询。
- DERIVED:派生表的 SELECT,FROM 子句的子查询。
- 出现 DERIVED(衍生表)可能产生临时表;
- 多层 SUBQUERY 可能影响性能
避免过度使用子查询,优先用 JOIN 替代
③、table 列:查的哪个表。
④、type 列:访问类型(查询效率等级)表示 MySQL 在表中找到所需行的方式,性能从最优到最差分别为:system > const > eq_ref > ref > range > index > ALL。
- system,表只有一行,一般是系统表,往往不需要进行磁盘 IO,速度非常快
- const:表中只有一行匹配,或通过主键或唯一索引获取单行记录。性能非常高。
- eq_ref:对于每个来自上一张表的记录,最多只返回一条匹配记录,通常用于多表关联且使用主键或唯一索引的查询。效率非常高,适合多表关联查询。
- ref:使用非唯一索引或前缀索引查询的情况,返回符合条件的多行记录。通常用于普通索引或联合索引查询,效率较高,但不如 const 和 eq_ref。
- range:只检索给定范围的行,使用索引来检索。在
where语句中使用bettween...and、<、>、<=、in等条件查询type都是range。 - index:全索引扫描,即扫描整个索引而不访问数据行。
- ALL:全表扫描,效率最低。
异常:ALL(全表扫描)、index(全索引扫描);
理想:const、ref、range
确保 WHERE/JOIN 字段有索引,避免无过滤条件的查询
⑤、possible_keys 列:可能会用到的索引,但并不一定实际被使用。
⑥、key 列:实际使用的索引。为 NULL 表示未使用索引(即使 possible_keys 有值)检查索引是否被正确使用(如避免函数操作索引字段)
⑦、key_len 列:MySQL 决定使用的索引长度(以字节为单位)。判断查询使用了联合索引的哪些字段。联合索引 idx_columns(column1, column2),如果 key_len 等于 column1 的长度,表示查询只使用了 column1。调整联合索引顺序,确保过滤性强的字段在前
⑧、ref 列:用于与索引列比较的值来源。
- const:表示常量,这个值是在查询中被固定的。例如在 WHERE
column = 'value'中。 - 一个或多个列的名称,通常在 JOIN 操作中,表示 JOIN 条件依赖的字段。
- NULL,表示没有使用索引,或者查询使用的是全表扫描。
⑨、rows 列:估算查到结果集需要扫描的数据行数,原则上 rows 越少越好。数值远大于实际返回的行数,说明过滤条件差。优化 WHERE 条件,增加过滤性强的条件(如用精确匹配替代模糊匹配)。
⑩、Extra 列:附加信息。
- Using index:表示用了覆盖索引。
- Using where:表示使用了 WHERE 过滤。
- Using temporary :表示使用了临时表来存储中间结果。
异常:Using filesort(文件排序)、Using temporary(临时表);
理想:Using index(覆盖索引)
- 对 Using filesort:为排序字段建索引;
- 对 Using temporary:避免非索引字段 GROUP BY;
- 优先实现 Using index(查询字段全在索引中)
示例:一条慢查询的 EXPLAIN 结果若显示 type: ALL、key: NULL、rows: 100000,说明是“未走索引的全表扫描”,根源明确。
解决方案:从 4 个维度优化
维度 1:优化查询语句本身(最直接,成本最低)
多数慢查询是因 SQL 写法不规范导致:
- 避免全表扫描/全索引扫描
禁止无过滤条件的 SELECT *(如 SELECT * FROM user)。
- 优化分页查询
对于 LIMIT offset, size深度分页问题,不要直接 LIMIT 1000000, 20
延迟关联(Late Row Lookups)和书签(Seek Method)是两种优化分页查询的有效方法。
①、延迟关联
延迟关联适用于需要从多个表中获取数据且主表行数较多的情况。它首先从索引表中检索出需要的行 ID,然后再根据这些 ID 去关联其他的表获取详细信息。
避免了每条id都要回表(查聚簇索引)
SELECT e.id, e.name, d.details
FROM (SELECT idFROM employeesORDER BY idLIMIT 1000, 20
) AS sub
JOIN employees e ON sub.id = e.id
JOIN department d ON e.department_id = d.id;②、书签(Seek Method)
书签方法通过记住上一次查询返回的最后一行的某个值,然后下一次查询从这个值开始,避免了扫描大量不需要的行。
SELECT id, name
FROM users
WHERE id > last_max_id -- 假设last_max_id是上一页最后一行的ID
ORDER BY id
LIMIT 20;- join 优化
①、禁止无限制的 IN 子句(如 IN (1,2,...,10000)),改用 JOIN 或分批查询。
低效:SELECT * FROM order WHERE user_id IN (SELECT id FROM user WHERE status=1);
优化:SELECT o.* FROM order o JOIN user u ON o.user_id = u.id WHERE u.status=1;
若 IN 中的值是离散的 “硬编码列表”(如 IN (1,2,...,10000)),则将 10000 个值拆分为多个小批次(如每批 500 个),执行多次 IN (1-500)、IN (501-1000)...,避免单次 SQL 过长和匹配压力。
②、小表驱动大表
在执行 JOIN 操作时,应尽量让行数较少的表(小表)驱动行数较多的表(大表),这样建立连接的次数就少,查询速度就快了。
③、适当增加冗余字段
在某些情况下,通过在表中适当增加冗余字段来避免 JOIN 操作,可以提高查询效率,尤其是在高频查询的场景下。
④ 避免 CROSS JOIN(笛卡尔积),必须加连接条件。
- UNION 优化
条件下推:将 where、limit 等子句下推到 union 的各个子查询中,以便优化器可以充分利用这些条件进行优化。
SELECT * FROM (SELECT * FROM AUNIONSELECT * FROM B
) AS sub
WHERE sub.id = 1;可以改写成:
SELECT * FROM A WHERE id = 1
UNION
SELECT * FROM B WHERE id = 1;通过将查询条件下推到 UNION 的每个分支中,每个分支查询都只处理满足条件的数据,减少了不必要的数据合并和过滤。
维度 2:优化索引(提升查询效率的核心)
- 有效使用:
-
- 为
WHERE子句、ORDER BY、GROUP BY以及JOIN ... ON的字段考虑创建索引。避免ORDER BY/GROUP BY对非索引字段操作,会触发Using filesort(内存/磁盘排序) - 多条件用联合索引(最左前缀原则)
- 利用覆盖索引: 让SQL要查询的字段完全包含在索引中,避免回表。
- 启用索引下推,减少回表次数。
- 使用前缀索引,减少体积
- 范围查询(
>,<,BETWEEN)的字段放在末尾,避免导致后续索引字段失效
- 为
- 避免索引失效:
-
- 字段操作:避免在
WHERE子句中对字段做“函数/运算操作” - 操作符:避免使用 != 或者 <> 操作符,尽可能使用
=、>、<、BETWEEN等 - 数据类型:隐式类型转换(如字符串不加引号)
- 连接方式:避免
WHERE子句用OR连接非索引字段,改用UNION - 避免LIKE 以通配符开头(%xxx / %xxx%)
- 字段操作:避免在
- 优化无效/低效索引:
-
- 删除“未被使用的索引”(可通过
sys.schema_unused_indexes或慢查询日志排查)。 - 合并“重复索引”(若
idx_a_b已存在,idx_a可能冗余)。 - 对“区分度低的字段”(如
gender只有 0/1)不建索引。
- 删除“未被使用的索引”(可通过
维度 3:数据库设计优化
也可以优化数据库配置,加大内存缓存,调整连接池参数等等,这个不了解。
- 数据类型: 使用适当的数据类型(如用
INT存数字,而不是VARCHAR)。 - 范式与反范式: 在数据一致性和查询性能之间做权衡。有时可以适当做反范式设计,增加一些冗余字段来避免复杂的JOIN
维度 4:架构层面优化(解决根本性、高并发问题)
当单库单表性能达到瓶颈(如数据量超 1000 万行,并发 QPS 超 1 万),需从架构层面拆分压力:
- 读写分离
主库负责“写操作”,从库负责“读操作”,通过主从复制同步数据。
- 分库分表
当单表数据量过大(如超 5000 万行),索引和查询效率会下降,需拆分表:
- 引入缓存
将高频访问的“热点数据”缓存到内存中,适合“读多写少”的数据。
- 使用列存数据库/搜索引擎
- 对“海量数据分析场景”(如日志分析、报表统计),传统行存数据库(MySQL/PostgreSQL)效率低,可改用列存数据库(如 ClickHouse)。
- 对“全文检索场景”(如商品搜索、文章检索),用搜索引擎(如 Elasticsearch)替代数据库的
LIKE查询,支持分词、高亮、排序等高级功能。