李宏毅机器学习笔记28
目录
摘要
Abstract
1.self-supervised learning在语音上的应用
2.self-supervised learning在影像上的应用
3.generative
BERT
GPT系列
摘要
本篇文章继续学习李宏毅老师2025春季机器学习课程,学习内容是self-supervised learning在语音和影像上的应用以及相应的实现方法。
Abstract
1.self-supervised learning在语音上的应用
self-supervised learning在语音上和在文字上,其实大多框架没有什么大的不同。我们可以有一个语音版的BERT,一样是通过大量没有标注的声音讯号训练出来的。语音版的BERT做的事情是,给他听一段声音讯号,他会把这段声音讯号变成一排向量。假设做的是语音辨识,我们要把声音讯号转写为文字,我们需要收集一些标注的声音讯号,就可以训练一个语音辨识的模型,把BERT的输出变成文字。
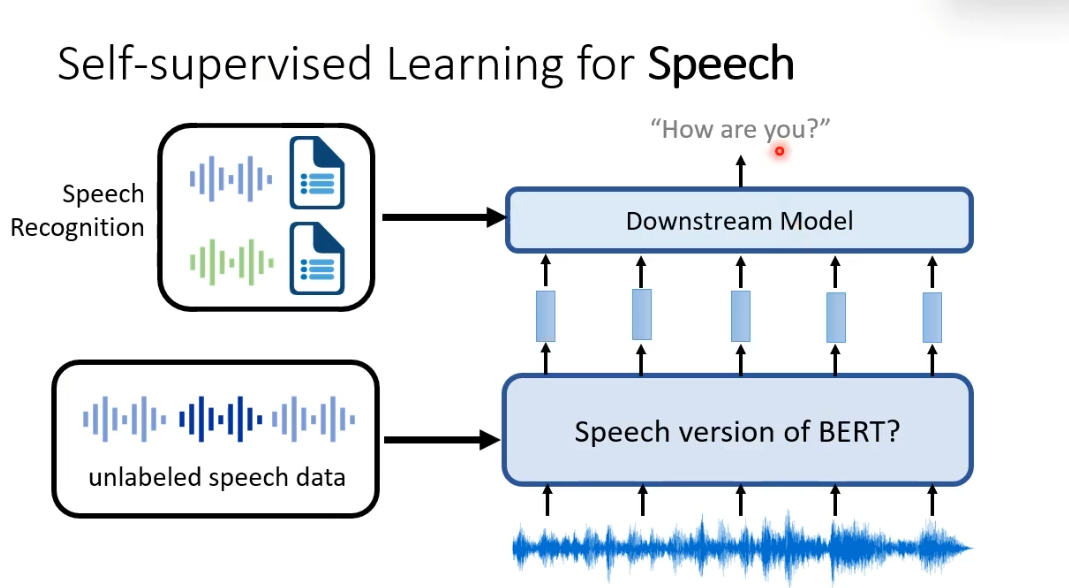
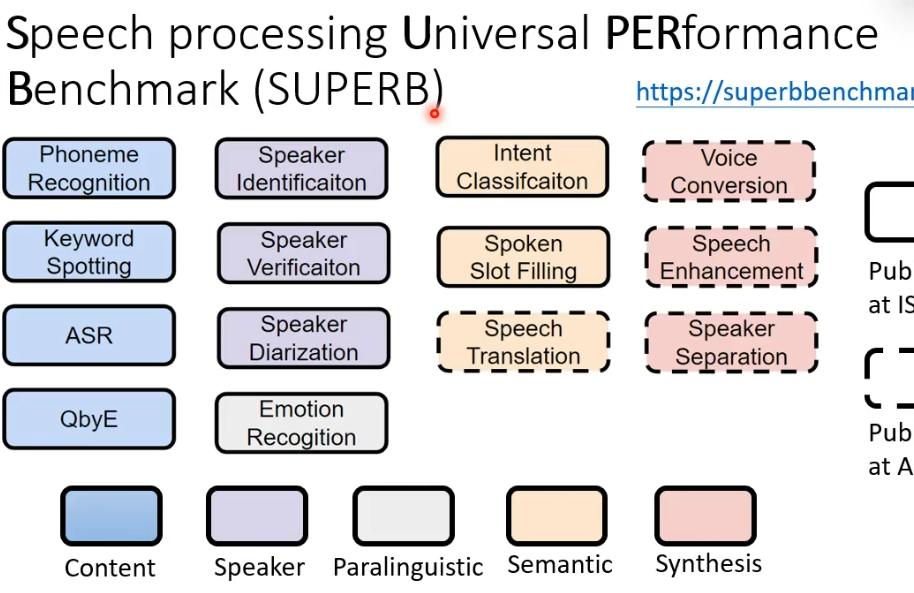
我们要衡量BERT在语音上应用的好坏,通常是需要BERT在SUPERB(多个自然语言处理的任务集合)测试。我们会让一个self-supervised的model解下图中的14个任务,看看是否可以在14个任务都取得好的结果。
2.self-supervised learning在影像上的应用
self-supervised learning同样可以用在各式各样的影像任务上。

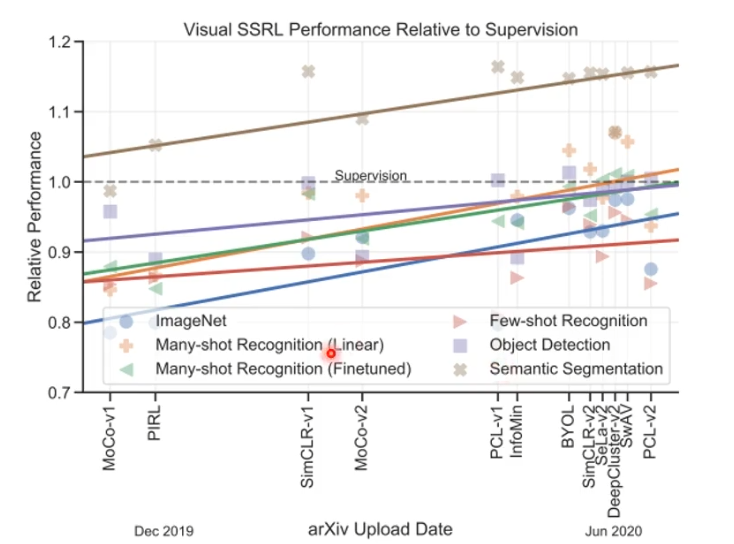
它在影像上的表现跟语音,文字的结论是很像的。横轴是不同的模型,纵轴代表模型在某个任务上的效能如何,不同点的形状代表不同的任务。某些任务不需要那些标注就能比标注的资料有更好的效果(supervision虚线之上)。
3.generative
BERT
我们把在文字上面训练的方法搬过来,在语音讯号上把一些部分盖起来,接下来让模型把这段声音讯号包括盖起来的部分读进去,输出一排向量,用这一排向量去还原被盖起来的部分。在语音版的BERT里有一个很具代表性的模型叫Mockingjay
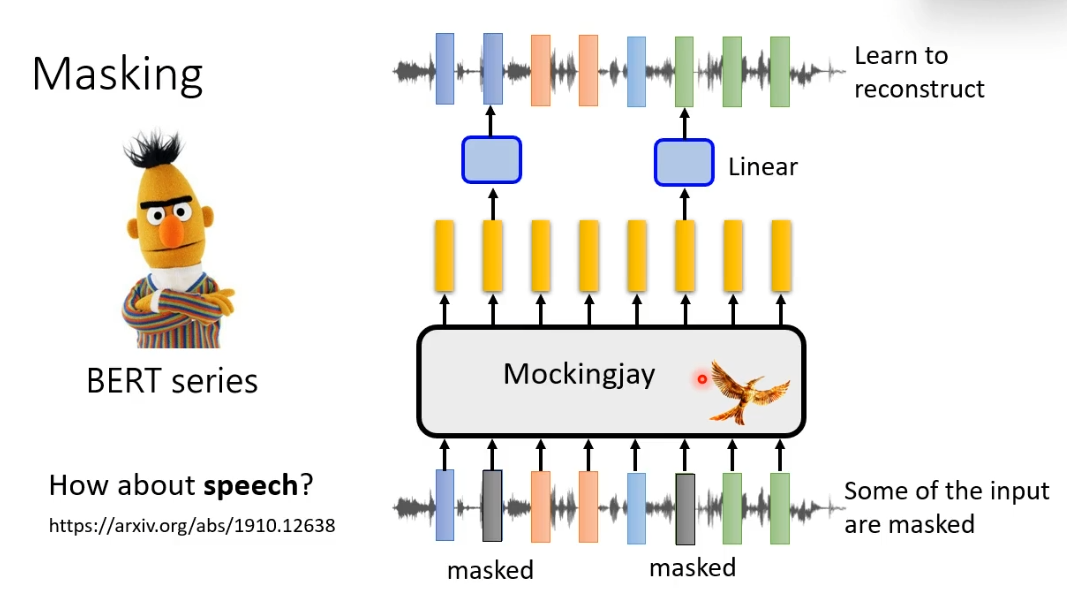
但是语音和文字毕竟不相同,直接套用也有需要注意的地方。声音讯号可以看作是一排向量,但是这个向量和向量间相邻的向量,往往内容非常接近。所以假设只是把某一个向量盖起来,机器无法学习到什么,因为相邻的向量非常接近很容易就可以预测到。所以语音上如果要用masking技术,我们要mask一长串的向量。还要一个不同的地方就是,我们可以一次mask所有向量的某几个维度。
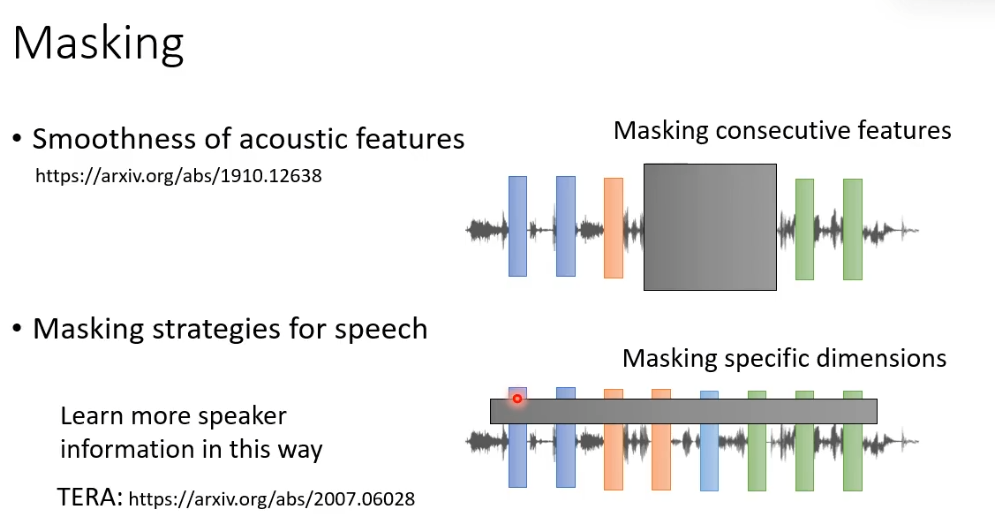
GPT系列
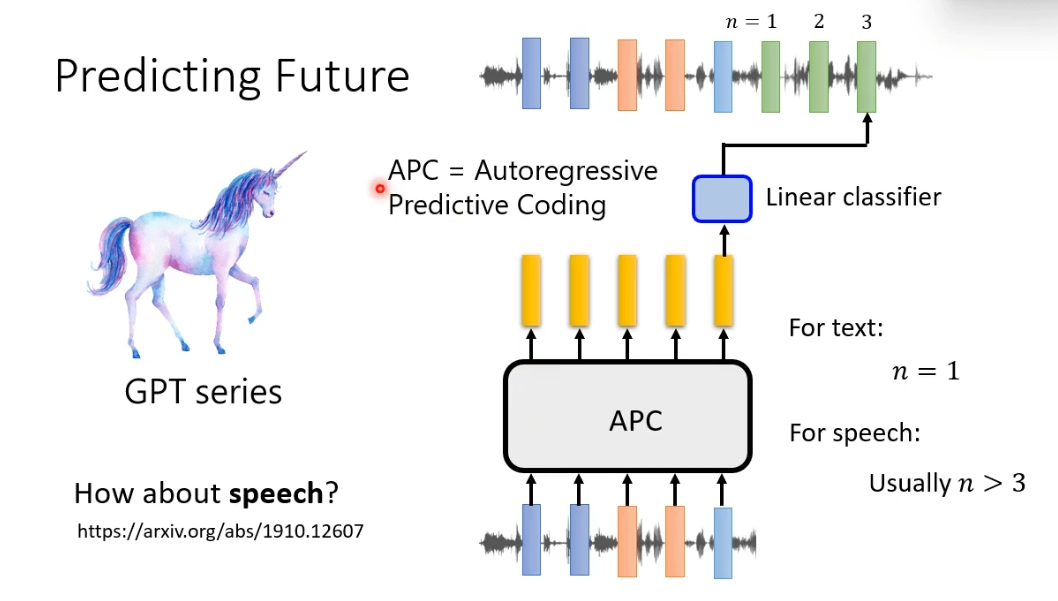
在语言上同样做一模一样的事情,给一段声音讯号,机器要预测接下来的声音讯号长什么样子。同样有一点不同之处,在文字上机器要预测下一个token,而在语音上机器要预测下一个声音讯号太简单了,因为相邻的向量非常接近。所以通常会让机器预测接下来某一段时间之后的一个向量。GPT的一个代表模型是APC。
在影像上也是一样的,可以将影像看做是向量(每个像素点的RGB),让BERT预测缺失的像素点,或者是让GPT预测下一个像素点都是与语音和文字类似的。

那么直接套用是否存在问题呢?语音,影像与文字不同,他们包含了很多细节,所以让模型去把一段声音或者是影像完整还原出来是非常困难的。