深度学习-卷积神经网络基础
目录
1 简介
2 图像卷积
2.1 卷积与互相关运算
2.2 卷积层
2.3 图像中目标的边缘检测
2.4 学习卷积核
2.5 特征映射和感受野
3 填充和步幅
3.1 基本原理
3.2 填充
3.3 步幅
4 多输入多输出通道
4.1 多输入通道
4.2 多输出通道
5 汇聚层
参考文献
1 简介
卷积神经网络与多层感知机主要的区别就在于它能够通过卷积操作保留高维张量中特征值之间的位置信息。例如,图像中的一块局部区域如果在多层感知机中会被展平映射到一维张量中相隔较远的多个小段,且区域大小不同多个小段的间隔大小也不一样,如果这块区域包含我们想要的目标也很难被机器学习到。但在卷积神经网络中我们保留了图像的二维结构,采用合适比例将图像中的各个区域进行“浓缩”提取该区域中的特征,这种方式符合人眼识别事物的整体性局部性,也便于机器精准判断每个小区域的特征分布情况。
在正式学习卷积神经网络之前,我们首先要熟悉网络中常见的操作。本着先速成再补漏的理念,本章简单带过书中的四个基础知识部分:图像卷积、填充和步幅、多输入输出通道、汇聚层。
2 图像卷积
2.1 卷积与互相关运算
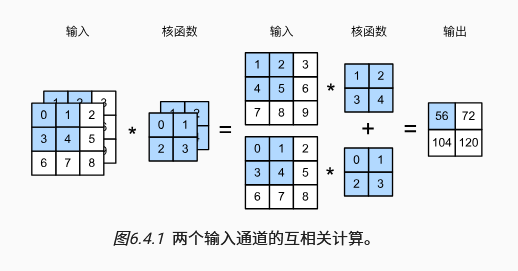
严格来讲,卷积运算与互相关运算是两种不同操作,但是在深度学习中使用两种操作训练的模型本质上效果是一样的,他们的唯一区别只是在于卷积运算需要先将卷积核进行水平+垂直翻转后再计算乘积。下面是书中的互相关运算例图,在卷积神经网络中我们都会采用这种互相关运算代替需要翻转的卷积运算,并且我们通常也会将错就错称为卷积运算。
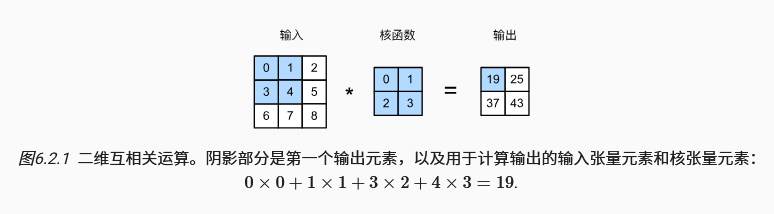
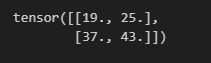
下面的代码对应上图中的卷积运算。
import torch
from torch import nn
from d2l import torch as d2ldef corr2d(X, K): #@save"""计算二维互相关运算"""h, w = K.shapeY = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))for i in range(Y.shape[0]):for j in range(Y.shape[1]):Y[i, j] = (X[i:i + h, j:j + w] * K).sum()return YX = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]])
K = torch.tensor([[0.0, 1.0], [2.0, 3.0]])
corr2d(X, K)
2.2 卷积层
卷积层包含权重和标量偏置,在用权重进行卷积操作后会加上标量偏置,这可以类比多层感知机中的全连接层。
class Conv2D(nn.Module):def __init__(self, kernel_size):super().__init__()self.weight = nn.Parameter(torch.rand(kernel_size))self.bias = nn.Parameter(torch.zeros(1))def forward(self, x):return corr2d(x, self.weight) + self.bias2.3 图像中目标的边缘检测
卷积操作提取出信息时,除了可能在区域大小上进行“压缩”,还可能进行图像信息的“提纯”,例如对于下面的二维张量,我们希望提取出01边界的分布,可以考虑设计一个合适的卷积核。
X = torch.ones((6, 8))
X[:, 2:6] = 0
X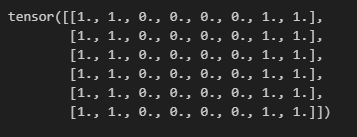
如下所示的卷积核进行卷积运算时,可以清晰划分出水平方向的边缘
K = torch.tensor([[1.0, -1.0]])
Y = corr2d(X, K)
Y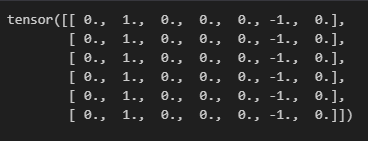
这是我们设计的专门划分水平方向边缘的卷积核,自然没法划分垂直方向,如下所示
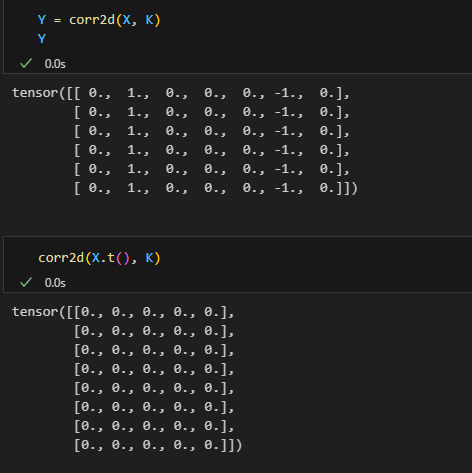
2.4 学习卷积核
对于更复杂的识别需求,我们不太容易设计出合适的卷积核,因此就像多层感知机一样,我们训练模型模型学习特征并自己更新卷积层的参数。下面代码中,nn.Conv2d定义了一个输入输出通道为1、卷积大小为(1,2)、不带偏置的卷积层。
# 构造一个二维卷积层,它具有1个输出通道和形状为(1,2)的卷积核
conv2d = nn.Conv2d(1,1, kernel_size=(1, 2), bias=False)# 这个二维卷积层使用四维输入和输出格式(批量大小、通道、高度、宽度),
# 其中批量大小和通道数都为1
X = X.reshape((1, 1, 6, 8))
Y = Y.reshape((1, 1, 6, 7))
lr = 3e-2 # 学习率for i in range(10):Y_hat = conv2d(X)l = (Y_hat - Y) ** 2conv2d.zero_grad()l.sum().backward()# 迭代卷积核conv2d.weight.data[:] -= lr * conv2d.weight.gradif (i + 1) % 2 == 0:print(f'epoch {i+1}, loss {l.sum():.3f}')conv2d.weight.data.reshape((1, 2))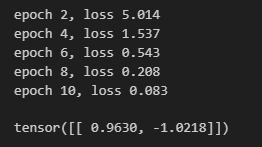
可以看到通过给定了输入和标签后,训练出的模型参数和我们自己设计的非常接近。
2.5 特征映射和感受野
卷积运算的输出也称为特征映射(feature map)。 在卷积神经网络中,对于某一层的任意元素,其感受野(receptive field)是指在前向传播期间可能影响该元素计算的所有元素(来自所有先前层),这类似于一个自底向上树形结构,层数越深越接近根节点,其对应的子结点也越多,即感受野越大。
3 填充和步幅
3.1 基本原理
在对整个图像进行卷积时,如果我们不对图像进行填充,且每次卷积核移动的长度小于卷积核边长时,对靠近图像边缘的像素点的遍历次数往往会少于靠近图像中心的像素点,这会导致图像边缘信息获取不够充分。并且随着多次卷积,特征图规模也会越来越小,不利于后续处理。因此适当填充图像后再做卷积能保留更多图像信息。
默认情况下卷积步幅为1,相邻元素的感受野会高度重合。有时候我们不希望特征映射出现过多冗余信息,这时就可以使用较大的步幅跳过部分重合的位置。
3.2 填充
填充即在输入图像的边界填充元素(通常填充元素是0)。在行/列方向上的输入长度为n,卷积核长度为k,填充宽度为p时,该方向的输出长度为n+p-k+1。如果要保持输出大小与输入大小一致,填充宽度就是k-1,此时为了让填充均匀分布在输入的四周,卷积核大小通常为奇数,这样填充宽度k-1为偶数,就能被均分到两侧。
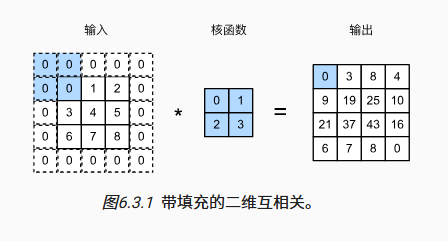
import torch
from torch import nn# 为了方便起见,我们定义了一个计算卷积层的函数。
# 此函数初始化卷积层权重,并对输入和输出提高和缩减相应的维数
def comp_conv2d(conv2d, X):# 这里的(1,1)表示批量大小和通道数都是1X = X.reshape((1, 1) + X.shape)Y = conv2d(X)# 省略前两个维度:批量大小和通道return Y.reshape(Y.shape[2:])# 请注意,这里每边都填充了1行或1列,因此总共添加了2行或2列
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1)
X = torch.rand(size=(8, 8))
comp_conv2d(conv2d, X).shape
上面代码中nn.Conv2d()方法初始化了一个卷积大小为3,填充大小为1的卷积层。
当卷积核高度和宽度不同时,填充的高度和宽度通常也会不同,如下所示
conv2d = nn.Conv2d(1, 1, kernel_size=(5, 3), padding=(2, 1))
comp_conv2d(conv2d, X).shape3.3 步幅
和填充一样,步幅也可以分成水平步幅和垂直步幅,对应卷积核每次在该方向上移动的距离。很多情况下会默认使用相同的水平与垂直步幅。
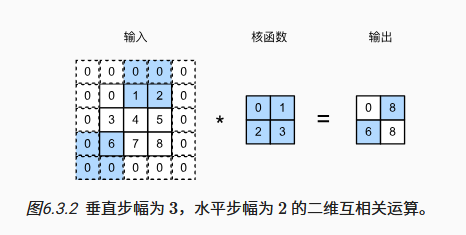
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1, stride=2)
comp_conv2d(conv2d, X).shape
conv2d = nn.Conv2d(1, 1, kernel_size=(3, 5), padding=(0, 1), stride=(3, 4))
comp_conv2d(conv2d, X).shape
4 多输入多输出通道
4.1 多输入通道
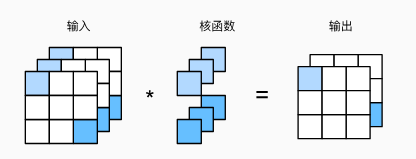
需要多输入通道通常是因为图像不只有灰度一个特征,每个像素点可能有(R,G,B)三种层面的特征甚至更多特征,这种时候我们需要输入同一个图像不同通道下的特征张量,即多输入通道。多个输入通道的特征张量分别对应不同的卷积核,进行卷积运算后得到与输入通道数相同的张量后,将它们相加得到输出。
import torch
from d2l import torch as d2ldef corr2d_multi_in(X, K):# 先遍历“X”和“K”的第0个维度(通道维度),再把它们加在一起return sum(d2l.corr2d(x, k) for x, k in zip(X, K))
4.2 多输出通道
有时候我们希望对同一个特征张量采用多个卷积核提取出多个输出,这时候就会得到多输出通道,结合前面的多输入通道,此时的卷积核具有两个维度的通道。这时候我们如果把一个卷积核抽象成一个标量权重wi,同时把每个通道的输入张量抽象成一个标量xi,卷积层就退化成多层感知机中的线性层。输入通道c0就是线性层输入的长度,输出通道c1就是线性层输出的长度,而权重w就是一个c0*c1的张量,偏置b为1*c1的张量。
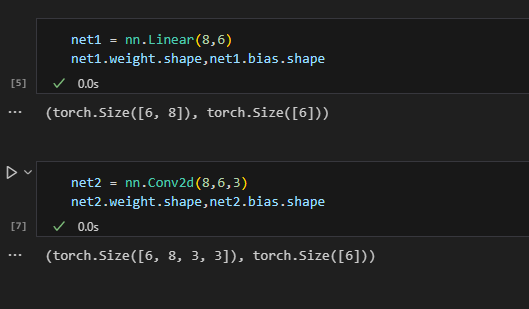
如上图所示,可以看到卷积层和线性层参数相比,只有权重内层多了两个维度3*3,即卷积核本身的大小,除此之外两者的输入输出通道和偏置的维度都完全一致。
下图是特殊的1*1卷积核。对于这种特殊卷积核,一种有趣的角度是从每个像素点的不同通道来看这个变换,对每个像素点来说都从3个通道变成了2个通道,这是权重和偏置完全一致的线性变换过程。总共9个像素点所以共9次变换,即批量大小为9。因此有 X(9,3)W(3,2)=Y(9,2),然后将结果中的批量大小9还原为3*3的张量形状,并将通道数放在外层得到Y(2,3,3)。
5 汇聚层
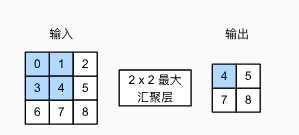
汇聚层也叫池化(pooling)层,是通过对图像的每个局部区域进行汇聚,使用同一个像素值进行代替,从而降低图像分辨率,增强平滑性的操作。它具有双重目的:降低卷积层对位置的敏感性,同时降低对空间降采样表示的敏感性。
与卷积窗口类似,汇聚操作也有一个窗口,并且可以设置一定的填充和步幅让汇聚窗口在输入张量上滑动。汇聚操作一般分为最大汇聚和平均汇聚,顾名思义就是提取出当前窗口的最大值或者平均值作为输出。
import torch
from torch import nn
from d2l import torch as d2ldef pool2d(X, pool_size, mode='max'):p_h, p_w = pool_sizeY = torch.zeros((X.shape[0] - p_h + 1, X.shape[1] - p_w + 1))for i in range(Y.shape[0]):for j in range(Y.shape[1]):if mode == 'max':Y[i, j] = X[i: i + p_h, j: j + p_w].max()elif mode == 'avg':Y[i, j] = X[i: i + p_h, j: j + p_w].mean()return YX = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]])
pool2d(X, (2, 2))pool2d = nn.MaxPool2d((2, 3), stride=(2, 3), padding=(0, 1))
pool2d(X)比较简单,这里不再赘述,具体例子可以从文末参考文献查看电子书。需要注意的一点是,与卷积的输出不同,在处理多通道输入数据时,汇聚层在每个输入通道上单独运算,而不是像卷积层一样在通道上对卷积结果进行汇总。 这意味着汇聚层的输出通道数与输入通道数相同。所以汇聚层参数不需要传入通道数。
参考文献
[1]《动手学深度学习》,https://zh-v2.d2l.ai/