深度学习8-卷积神经网络-CNN概述-卷积层-池化层-深度卷积神经网络-案例:服装分类
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 1. CNN概述
- 2. 卷积层
- 1.1 数学上卷积运算
- 1.2 卷积运算
- 1.3 填充
- 1.4 步幅
- 1.5 3维数据的卷积运算
- 1.6 API使用
- 3. 池化层
- 3.1 API使用
- 4. 深度卷积神经网络
- 4.1 AlexNet
- 4.2 VGG
- 4.3 GoogleNet
- 4.4 ResNet
- 4.5 API使用
- 5. 案例:服装分类
- 5.1 加载数据
- 5.2 创建模型
- 5.3 模型训练
- 5.4 模型测试
- 总结
前言
卷积神经网络
1. CNN概述
卷积神经网络(Convolutional Neural Network,CNN)常被用于图像识别、语音识别等各种场合。它在计算机视觉领域表现尤为出色,广泛应用于图像分类、目标检测、图像分割等任务。
卷积神经网络的灵感来自于动物视觉皮层组织的神经连接方式,单个神经元只对有限区域内的刺激作出反应,不同神经元的感知区域相互重叠从而覆盖整个视野。
CNN中新出现了卷积层(Convolution层)和池化层(Pooling层),下图是一个CNN的结构:
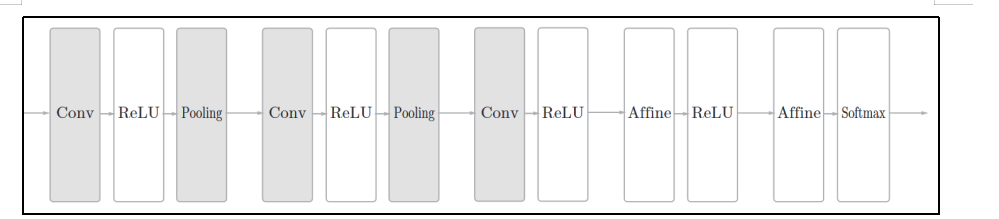
卷积层用于提取输入数据的局部特征。
池化层用于降维,增强鲁棒性并防止过拟合。
全连接层用于整合特征并输出结果。
卷积-激活函数-池化-卷积-激活-池化-卷积-激活-全链接-激活-全链接-最终输出
卷积和池化当做一层
所以总共五层
2. 卷积层
在全连接层中,相邻层的神经元全部连接在一起,输出的数量可以任意决定,但是却忽视了数据的形状。比如,输入数据为图像时,图像通常是长、宽、通道方向上的3维数据,但是向全连接层输入时却需要将其拉平为1维数据,这种情况下3维形状的数据中的空间信息可能被全连接层忽视掉。
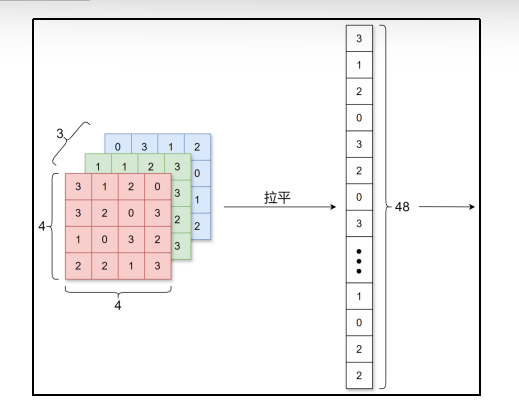
而卷积层可以保持数据形状不变,即接收3维形状的输入数据后同样以3维形状将数据输出至下一层。在CNN中,卷积层的输入输出数据也称为特征图(feature map)。
1.1 数学上卷积运算
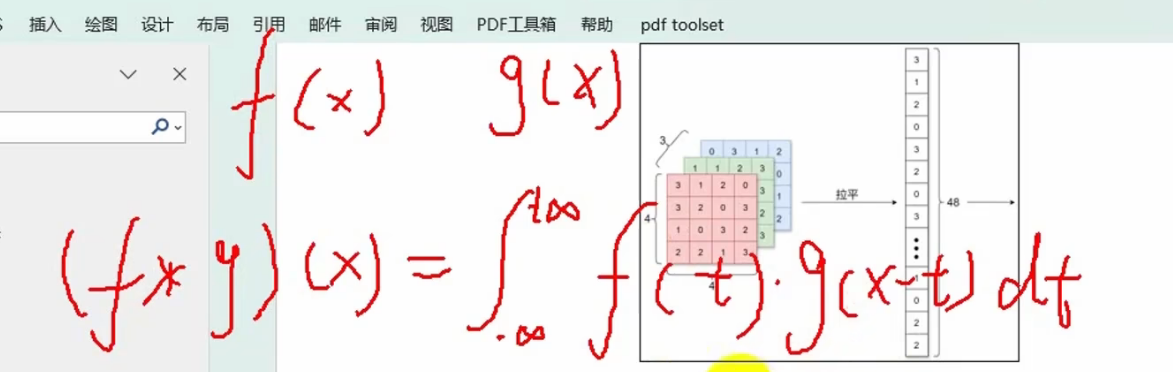

卷积层对数据进行卷积运算,卷积运算相当于图像处理中的滤波器运算。
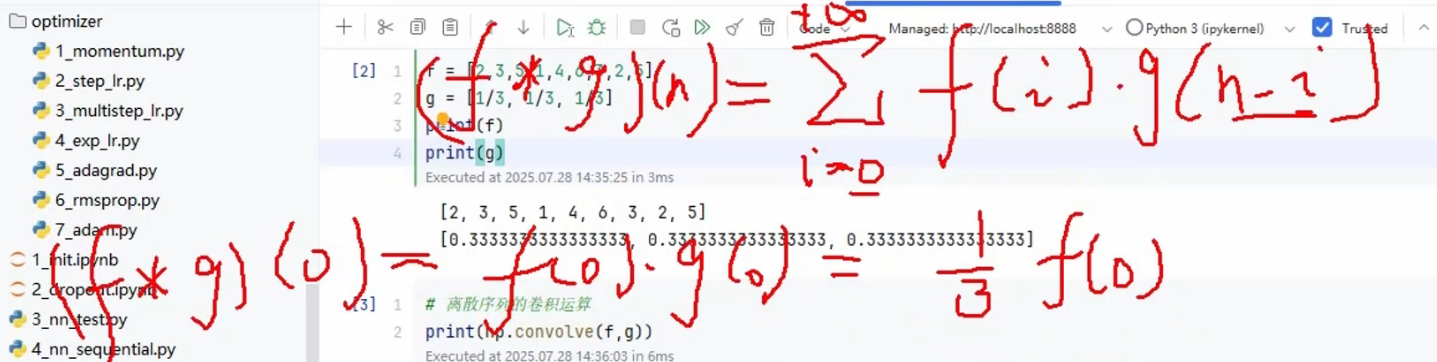
f = [2,3,5,1,4,6,3,2,5]
g = [1/3,1/3,1/3]
print(np.convolve(f,g))
这个就是进行卷积运算




这个就相当于每次去f截三个数据来进行计算,一开始和最后—》截不够,相当于一个滑动的窗口
f = [2,3,5,1,4,6,3,2,5]
g = [1/3,1/3,1/3]
print(np.convolve(f,g,mode ='full'))
默认就是full,意思就是窗口大小不够三的时候也要进行运算
f = [2,3,5,1,4,6,3,2,5]
g = [1/3,1/3,1/3]
print(np.convolve(f,g,mode ='valid'))
这个就是窗口有三个的时候才运算
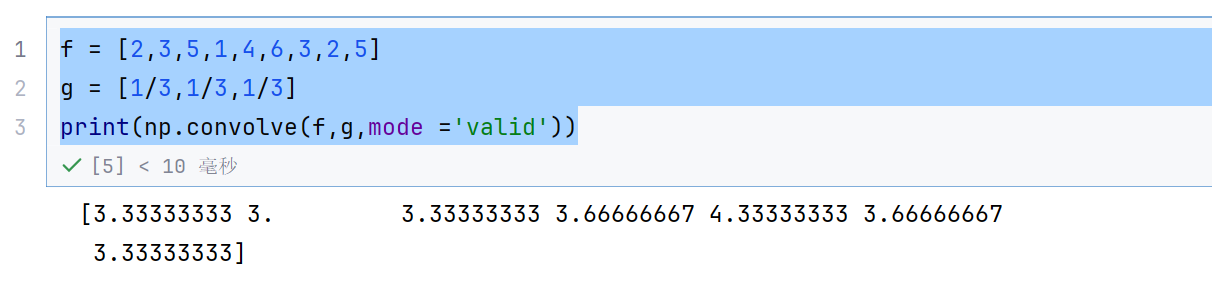
截取一部分局部信息—》滤波器
f就相当于是输入信号,g就相当于是滤波器
1.2 卷积运算
卷积层对数据进行卷积运算,卷积运算相当于图像处理中的滤波器运算。
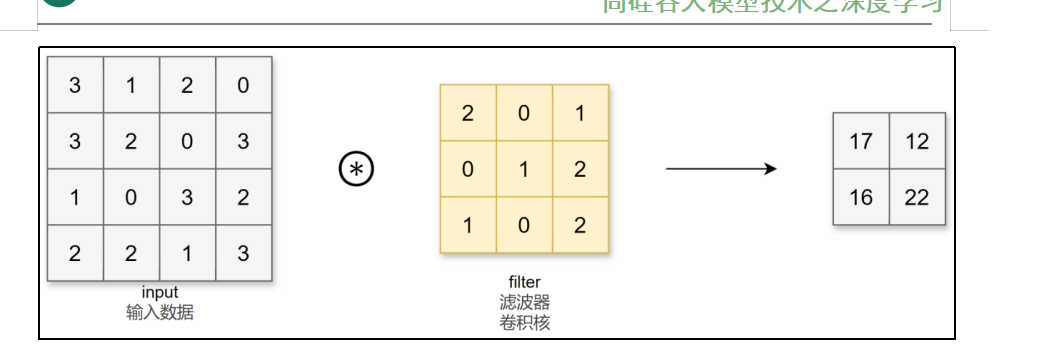
这个就相当于在44的上面每次截取33
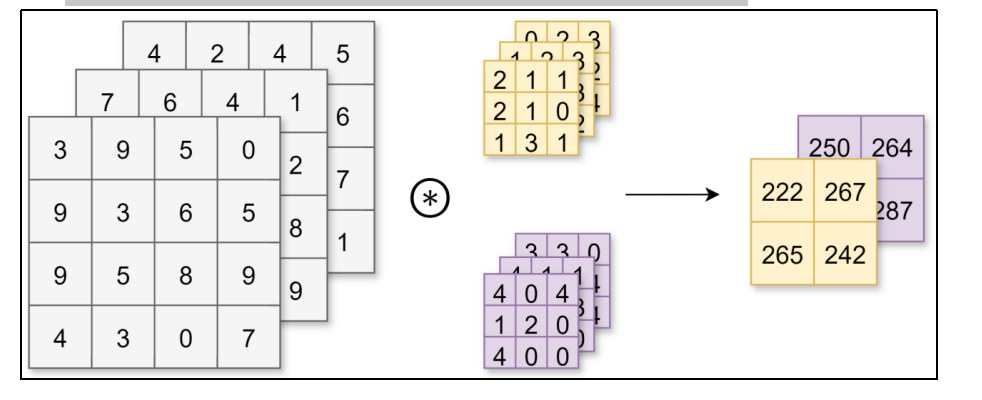
对于输入数据,卷积运算以一定间隔滑动卷积核的窗口并应用。将各个位置上卷积核的元素和输入的对应元素相乘,然后再求和(也称为乘积累加运算、矩阵的内积)。
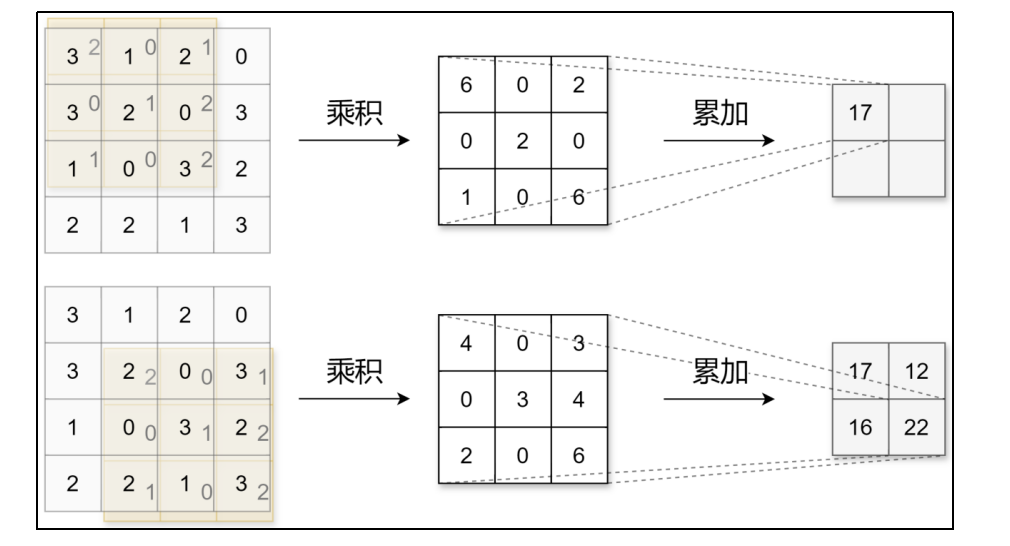
44中截取33与滤波器33,对应位置相乘,再次得到33,再次全部加起来得到17
然后把滤波器向右移动,再次这样运算
CNN中,卷积核(滤波器)的参数对应之前的权重。并且CNN中也存在偏置。
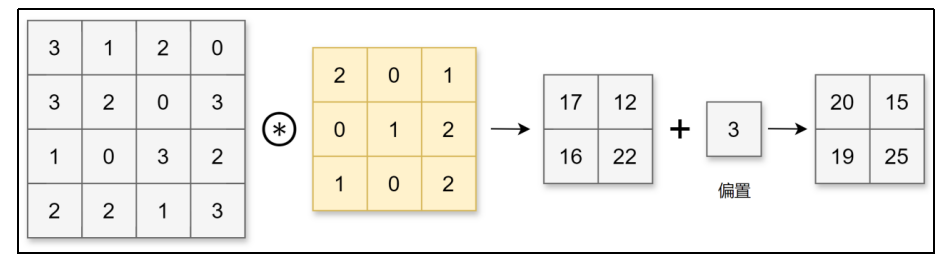
所以最后得到2*2
1.3 填充
原来是44,滤波之后还是44,这样才是滤波好吧
–》越卷越小了
在进行卷积层的处理之前,有时要向输入数据的周围填入固定的数据(比如0),这称为填充(padding)。例如,对形状为4×4的数据进行幅度为1的填充,即用幅度为1、值为0的数据填充周围:
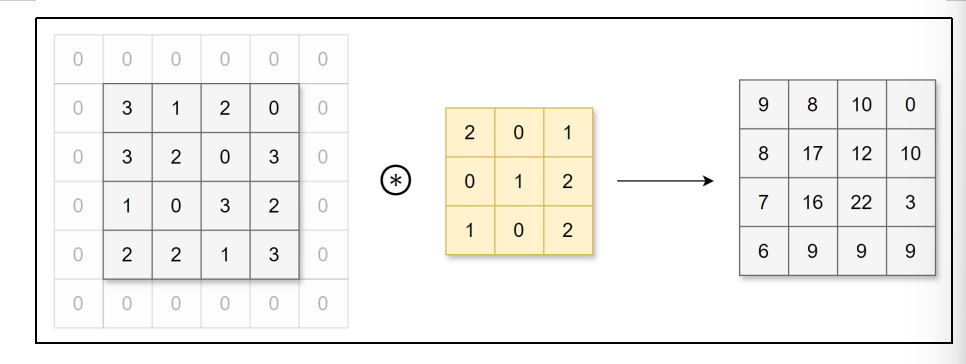
可以看到,4×4的数据进行幅度为1的填充后形状变为6×6,再经过卷积后数据的形状为4×4。使用填充主要目的是为了调整输出数据的形状大小,避免多次卷积后数据形状大小过小导致无法继续进行卷积运算。运用填充可以令数据形状在经过卷积运算后保持不变。
1.4 步幅
应用卷积核的位置间隔称之为步幅(stride)。
之前的例子中步幅都为1,下面我们进行步幅为3的卷积运算:
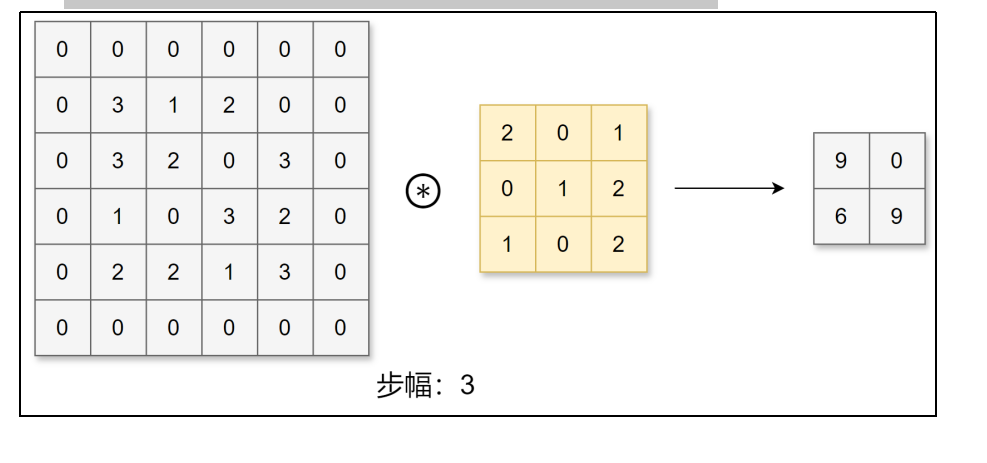
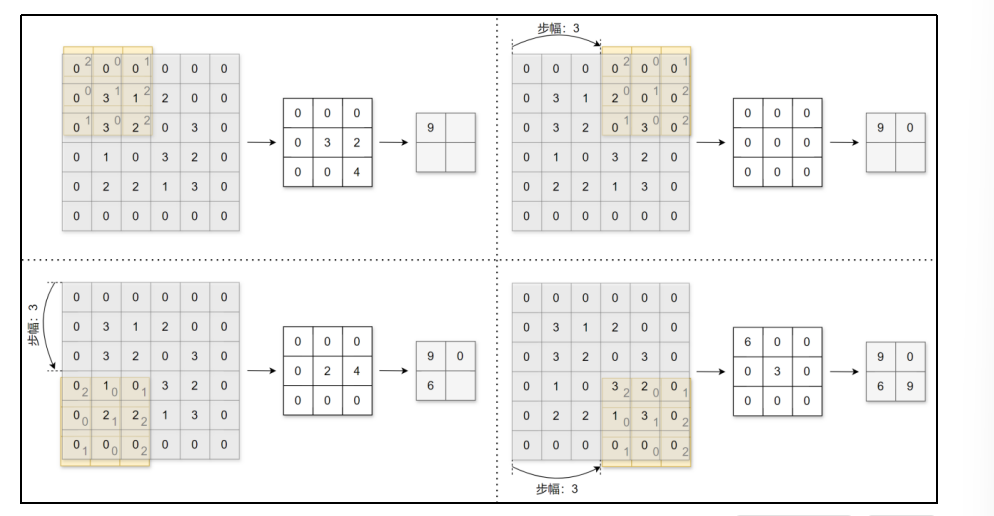
可以看到填充和步幅都会影响输出数据的形状大小。增大填充,输出数据形状大小会变大;增大步幅,输出数据形状大小会变小。让我们分析一下给定填充和步幅如何计算输出数据的形状大小。

卷积核越大,步幅越小—》输出越小
1.5 3维数据的卷积运算
图像是3维数据,除了长、宽外还需要处理通道方向。在3维数据的卷积运算中,输入数据的通道数和卷积核的通道数须设为相同的值。当有多个通道时,会按通道进行输入数据和卷积核的卷积运算,并将结果相加得到输出数据。
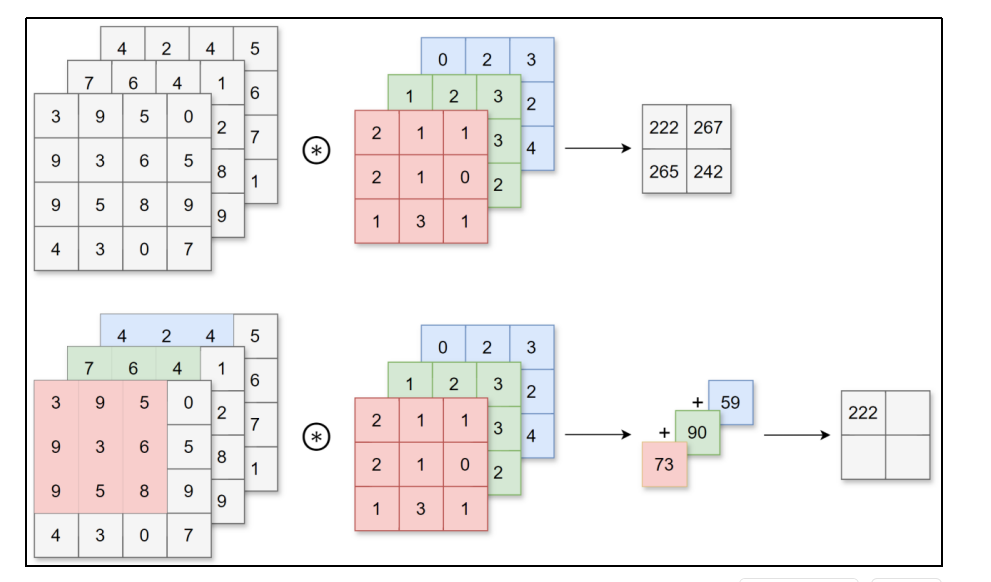
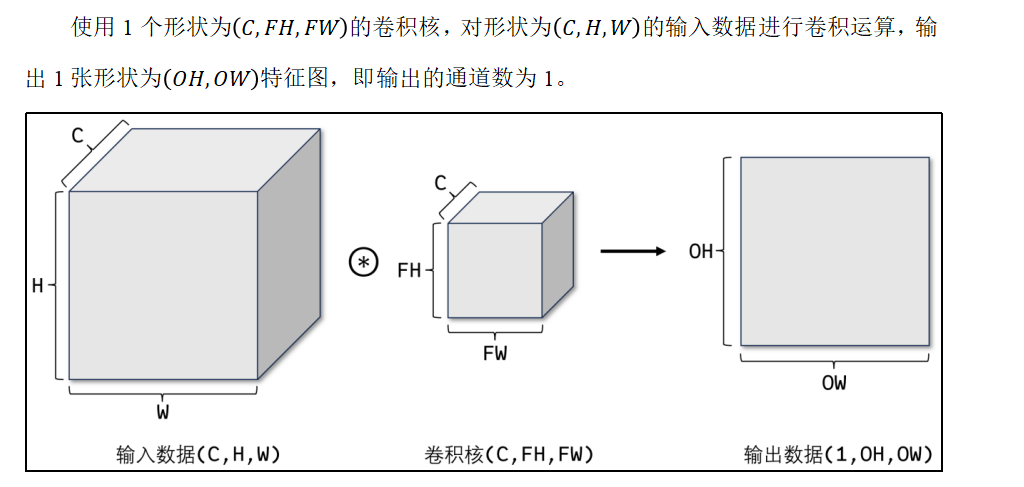
若想在通道方向获得多个卷积运算的输出,需要使用多个卷积核。
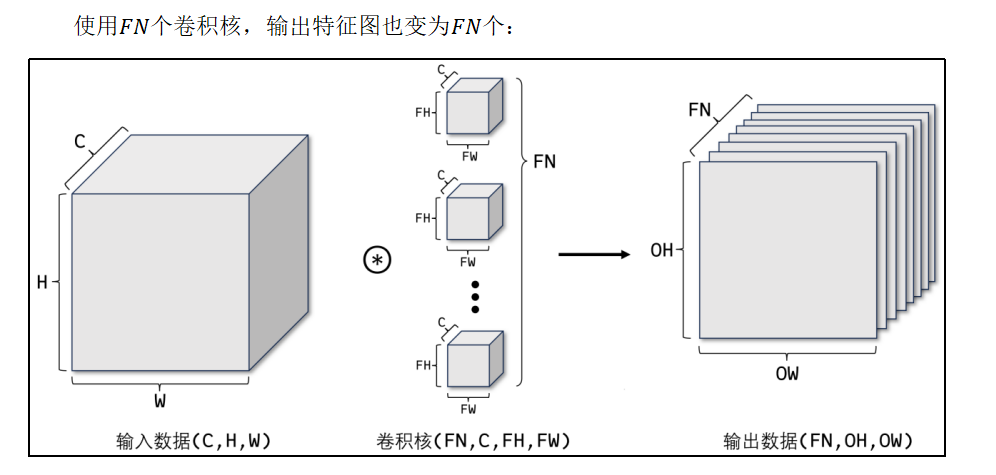
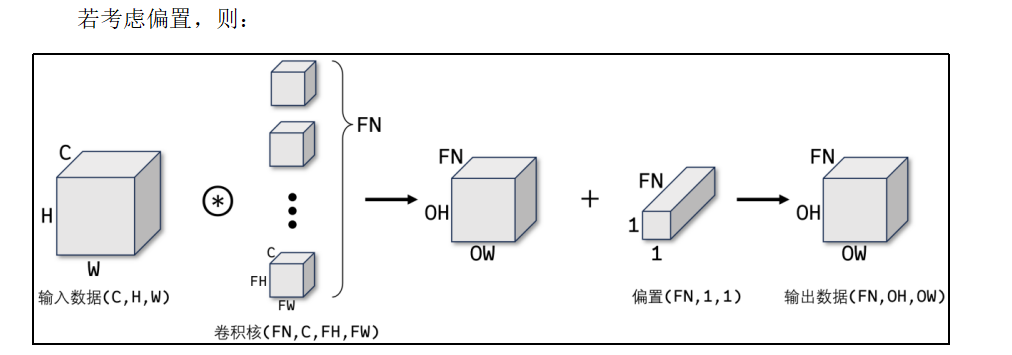
1.6 API使用
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
# in_channels:输入通道数----》颜色通道数C,
# out_channels:输出通道数---->卷积核的个数FN---》决定输出通道数
# kernel_size:卷积核大小----->卷积核的形状--》FH,FW
# stride:步幅-------
# padding:填充幅度
这个是二维的卷积操作Conv2d–>二维图像
Conv1d–》一维数据,文本信息
Conv3d—》医学影像,图像分割,视频动作检测–》有时间三维
import torch
import matplotlib.pyplot as plt
#卷积层的定义和应用测试
#1. 读取图片
img = plt.imread("./data/duck.jpg")
print(img.shape)
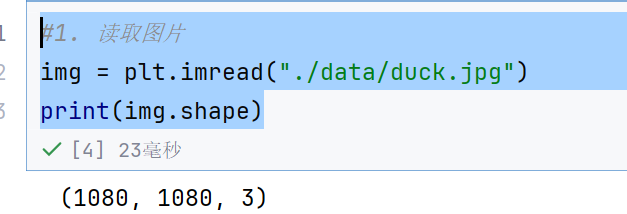
#2.将图片数据调整为卷积层输入特征图对应的形状,就是3在第一个位置C
input = torch.tensor(img).permute(2,0,1).float()
print(input.shape)

#3.定义卷积层,kernel_size=9表示9*9的卷积核,bias=False表示不要偏置
conv = torch.nn.Conv2d(in_channels=3,out_channels=3,kernel_size=9,stride=3,padding=0,bias=False)
#4.前向传播
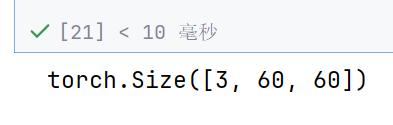
output = conv(input)
print(output.shape)
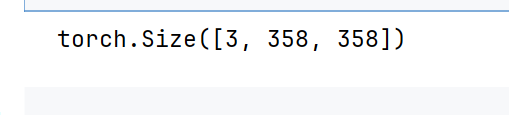
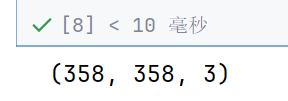
#5. 输出为图片---》358*358*3,而且必须为整数,
# 将输出特征图转换为图片数据
output = torch.clamp(output.int(),0,255)#表示把所有数据夹断到0~255
output = output.permute(1,2,0).detach().numpy()#转换为ndarray,因为要显示图片
print(output.shape)
#显示图片对比
fig,ax = plt.subplots(1,2,figsize=(10,5))
ax[0].imshow(img)
ax[1].imshow(output)
plt.show()
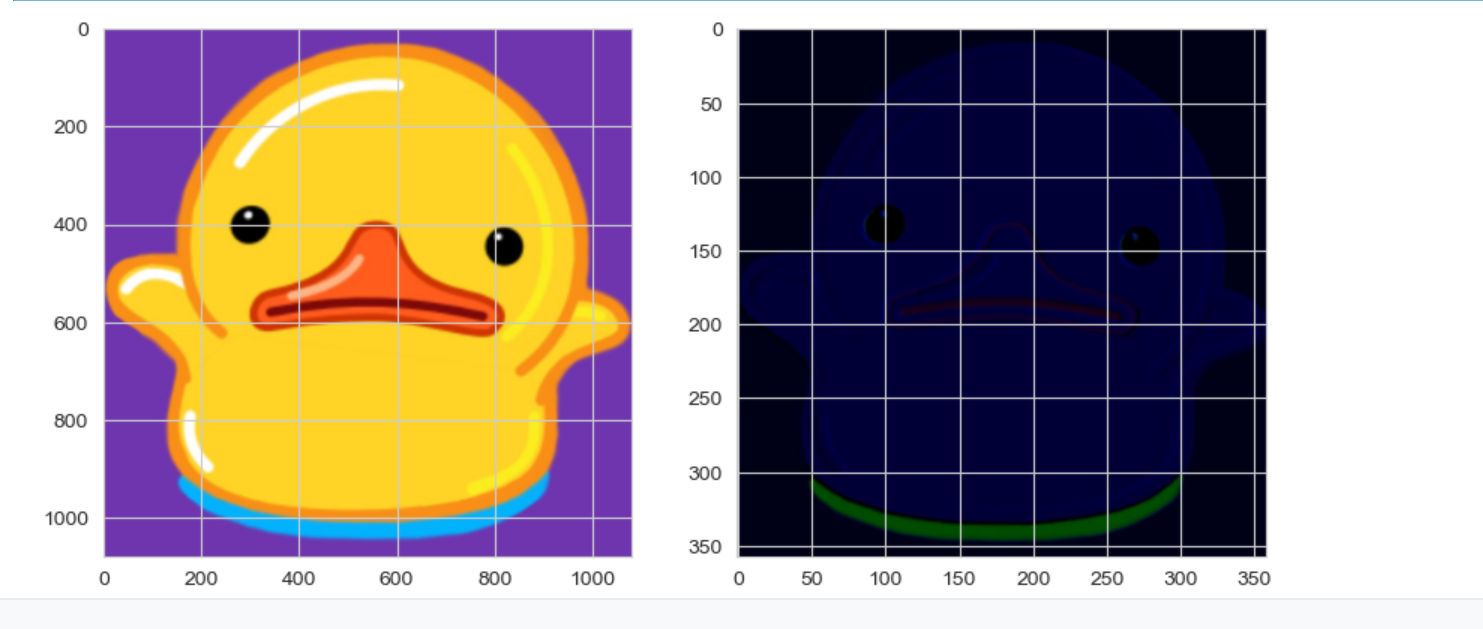
卷黑了
但是轮廓还是有的
卷积核的值是随机生成的
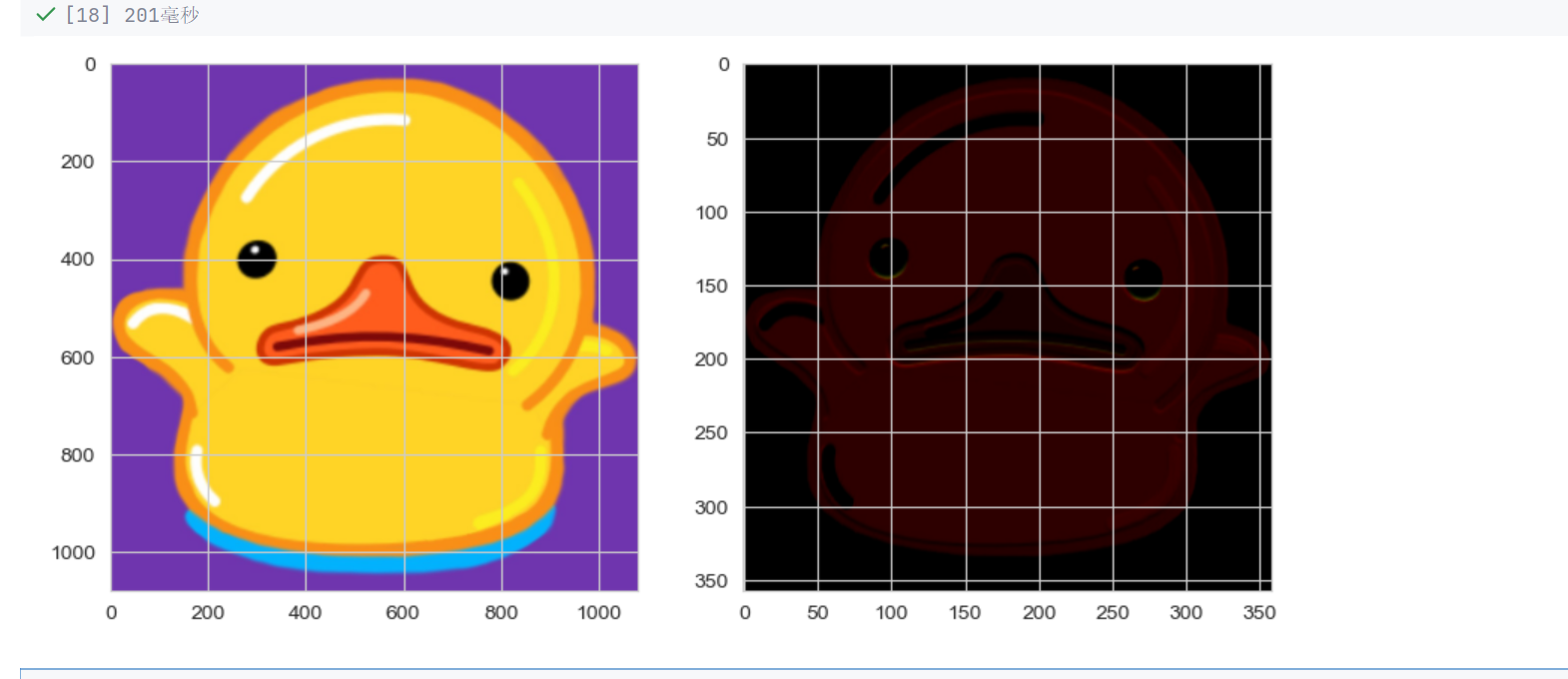
每次卷积都不一样
3. 池化层
一般跟在卷积层后面
池化层缩小长、宽方向上的空间来进行降维,能够缩减模型的大小并提高计算速度。例如,对数据进行步幅为2的2×2的Max池化:
这里的降维其实是缩小,比如44变成22,而不是机器学习里面的那种降维
2×2的Max池化意思就是用22的框去框,然后取出22中的最大值—》最亮点
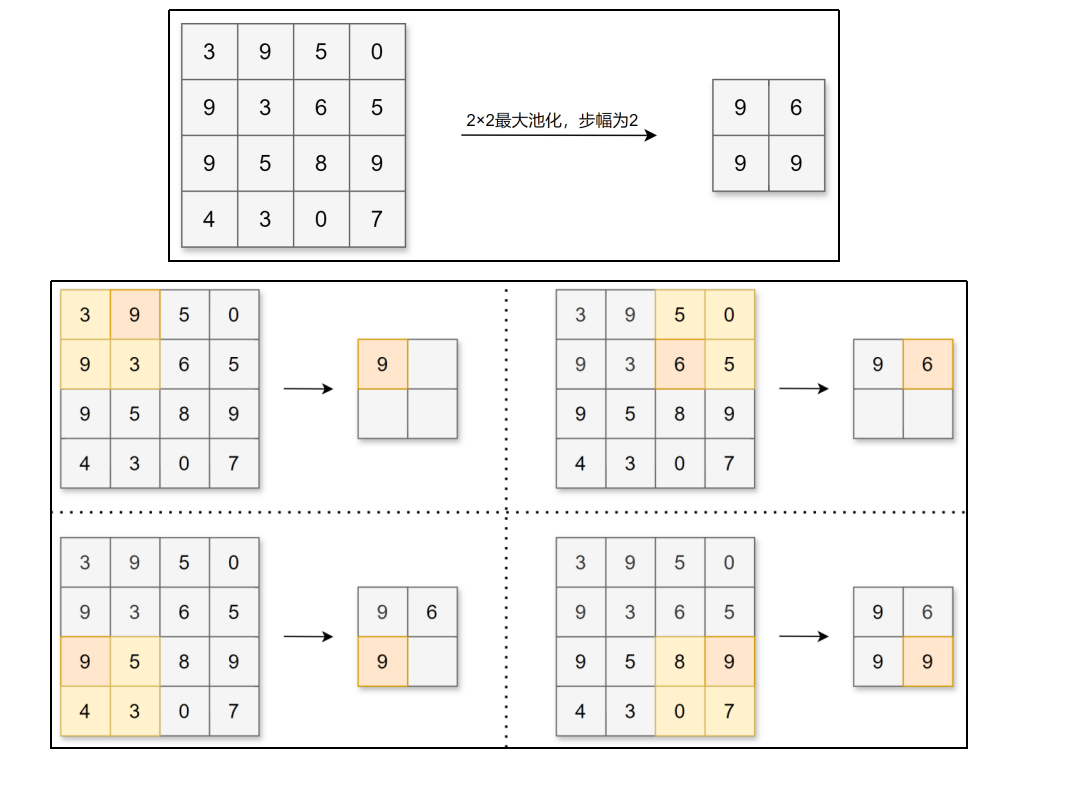
因为划分过的地方不会在划了,所以池化窗口不会有重叠的
所以我们的步幅就用池化窗口的大小—》就不会有重叠了
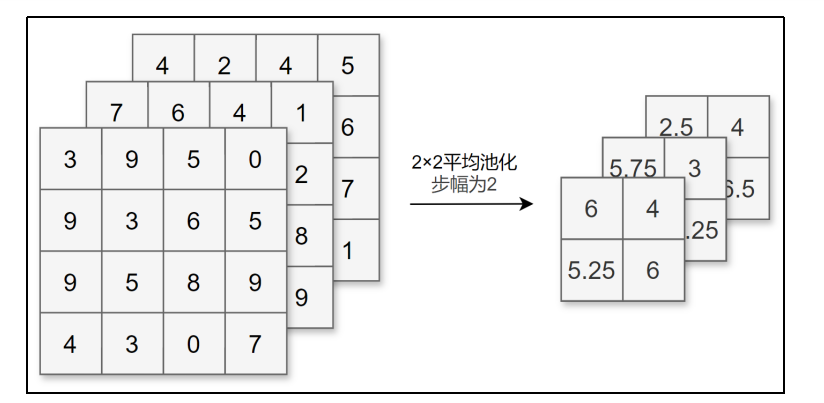
除了Max池化(计算窗口内的最大值),还有Average池化(平均池化,计算窗口内的平均值)等。一般会将池化的大小窗口和步幅设置为相同的值,比如2×2的窗口大小,步幅会设置为2。池化同样也可以设置填充。
和卷积层不同,池化层没有要学习的参数,并且池化运算按通道独立进行,经过池化运算后数据的通道数不会发生变化。
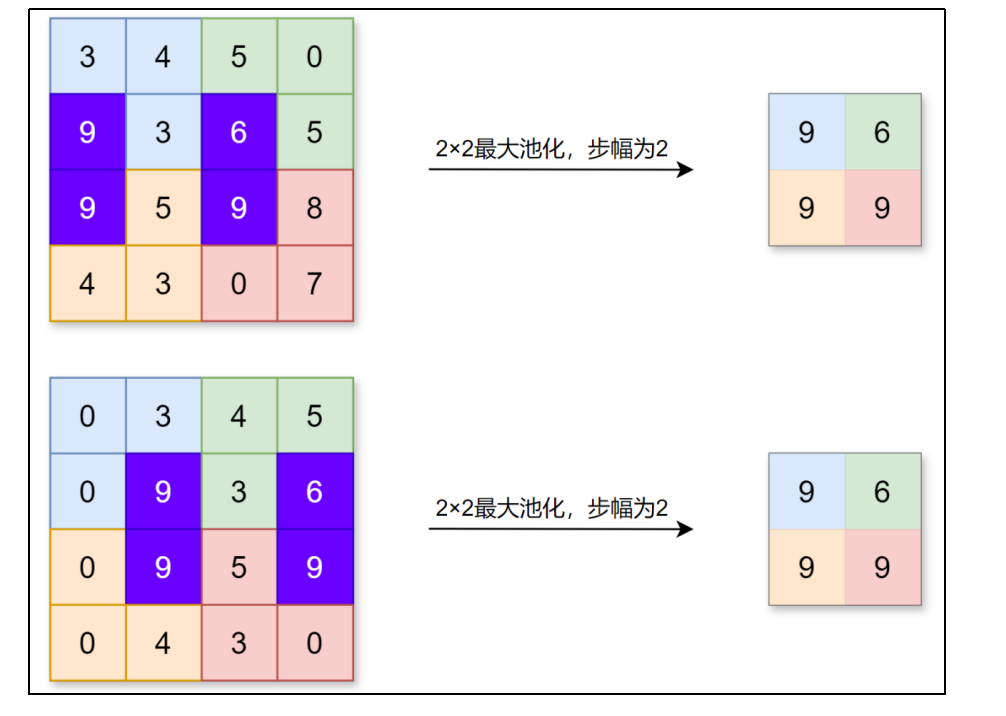
池化的另一个特点是对微小偏差具有鲁棒性,数据发生微小偏差时,池化可能会返回相同的结果。例如,数据在宽度方向上偏离1个元素,返回的结果不变。
3.1 API使用
# 最大池化
torch.nn.MaxPool2d(kernel_size, stride, padding)
# 平均池化
torch.nn.AvgPool2d(kernel_size, stride, padding)
kernel_size就是池化窗口的形状
stride是步幅
padding是填充
#1. 读取图片
img = plt.imread("./data/duck.jpg")
print(img.shape)
#2.将图片数据调整为卷积层输入特征图对应的形状,就是3在第一个位置C
input = torch.tensor(img).permute(2,0,1).float()
print(input.shape)
#3.定义卷积层,kernel_size=9表示9*9的卷积核,bias=False表示不要偏置
conv = torch.nn.Conv2d(in_channels=3,out_channels=3,kernel_size=9,stride=3,padding=0,bias=False)
#4.前向传播
output = conv(input)
print(output.shape)
#5.定义池化层
pool = torch.nn.MaxPool2d(kernel_size=6,stride=6,padding=1)
#6.前向传播,池化操作
output2 = pool(output)
print(output2.shape)
# 将输出特征图转换为图片数据
output = torch.clamp(output.int(),0,255)#表示把所有数据夹断到0~255
output = output.permute(1,2,0).detach().numpy()#转换为ndarray,因为要显示图片
output2 = torch.clamp(output2.int(),0,255)#表示把所有数据夹断到0~255
output2 = output2.permute(1,2,0).detach().numpy()#转换为ndarray,因为要显示图片
#显示图片对比
fig,ax = plt.subplots(1,3,figsize=(10,5))
ax[0].imshow(img)
ax[1].imshow(output)
ax[2].imshow(output2)
plt.show()
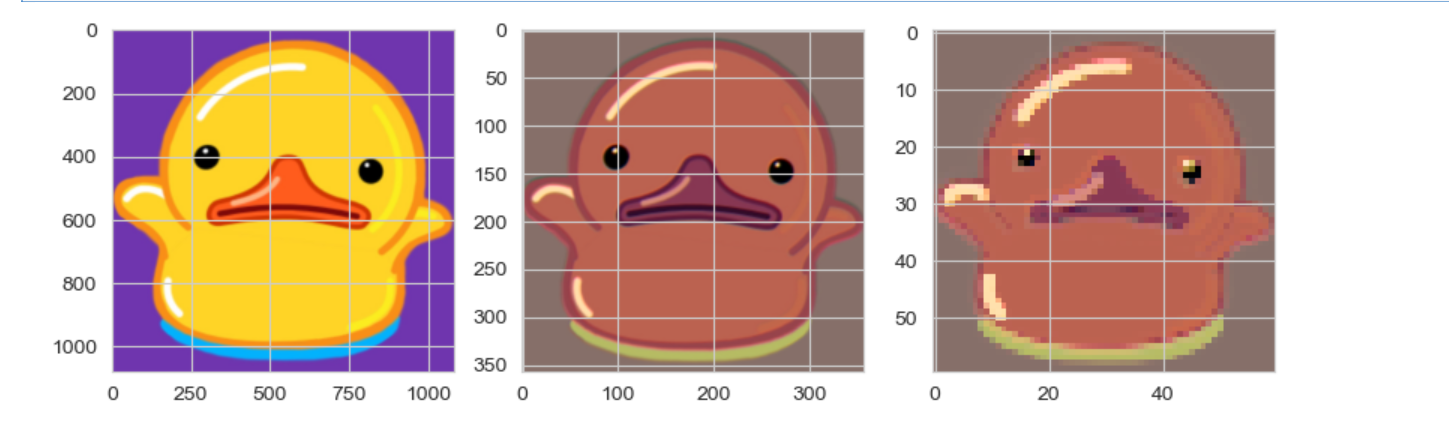
池化就变模糊了—》因为就取了最大值
但是有些时候运行会卷成小黑鸭子
因为每次都是随机的,所以这个也正常
怎么避免呢—》对数据不要直接截断,因为负数截断—》直接变0,可以先归一化0~1,在乘以255
4. 深度卷积神经网络
将神经网络的层数加深,可以更有效地提取层次信息,还可以减少参数数量,从而让学习更加高效。
基于CNN构建深度神经网络,可以提取出更多的图片信息,大幅提高图像识别精度。在人工智能的发展历程中,正是深度卷积神经网络,掀起了最近一轮深度学习的热潮。
4.1 AlexNet
是一个基于CNN构建的神经网络模型,主要架构包含8层(5个卷积层+3个全连接层),激活函数使用 ReLU,最后经全连接层输出结果,并且使用了Dropout。
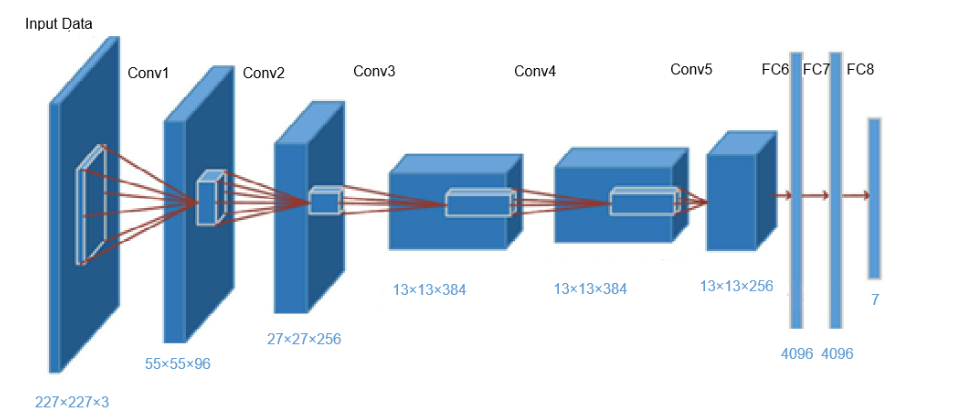
五个卷积层,Conv5,三个全连接–》FC6~8
AlexNet在当年的ImageNet图像分类挑战赛中大幅刷新性能纪录,引发广泛关注;这被认为是深度学习兴起的标志。
4.2 VGG
2014年由牛津大学 Visual Geometry Group(视觉几何组)提出。VGG网络由多个卷积-池化层堆叠构成,将有权重的层(卷积层或全连接层)叠加至 16 或 19 层,也被称为VGG-16和VGG-19。
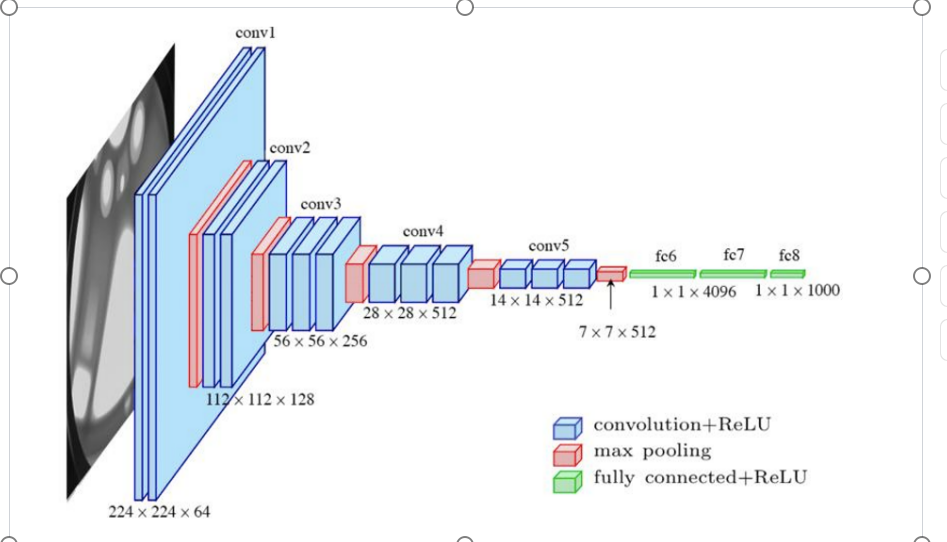
VGG结构简单,应用性强,因此得到了大量技术人员的青睐。
4.3 GoogleNet
2014年由Google团队提出的深度卷积神经网络架构。
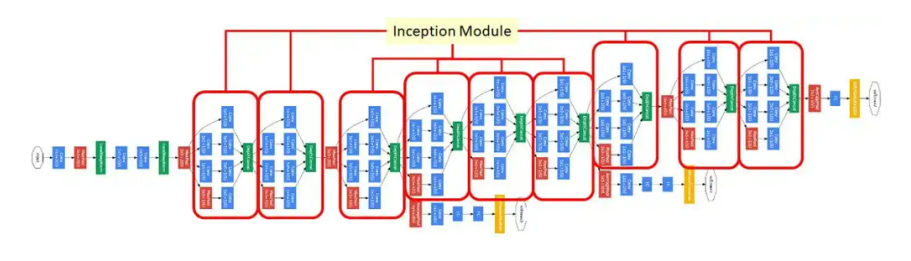
整体上看,GoogleNet有更加复杂的网络结构,不过它的底层依然和CNN相同。它的特点是,引入了“Inception结构”,使得网络不仅纵向上有深度,在横向上也有深度。
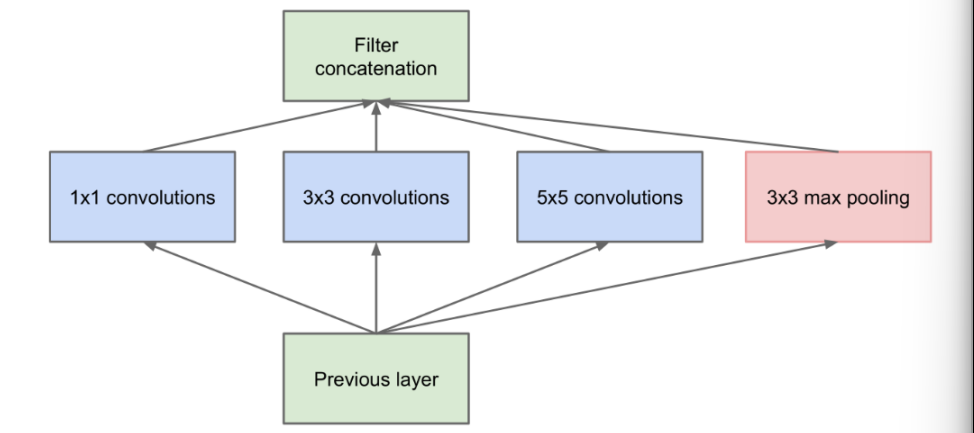
横向上使用多个大小不同的滤波器、最后再合并;有利于 减少参数数量、解决梯度消失问题。
4.4 ResNet

2015年由微软团队(何恺明等人)提出,比之前的网络具有更深的结构。
为了解决深度网络的梯度消失问题,ResNet以 VGG 为基础,引入了“快捷结构”。这样一来,网络学习的目标就由原始的输出变为了,这被称为“残差学习”;引入的这个恒等映射被称为“残差连接”(或者“跳跃连接”),这种网络结构也被称为“残差网络”(Residual Network,ResNet)。
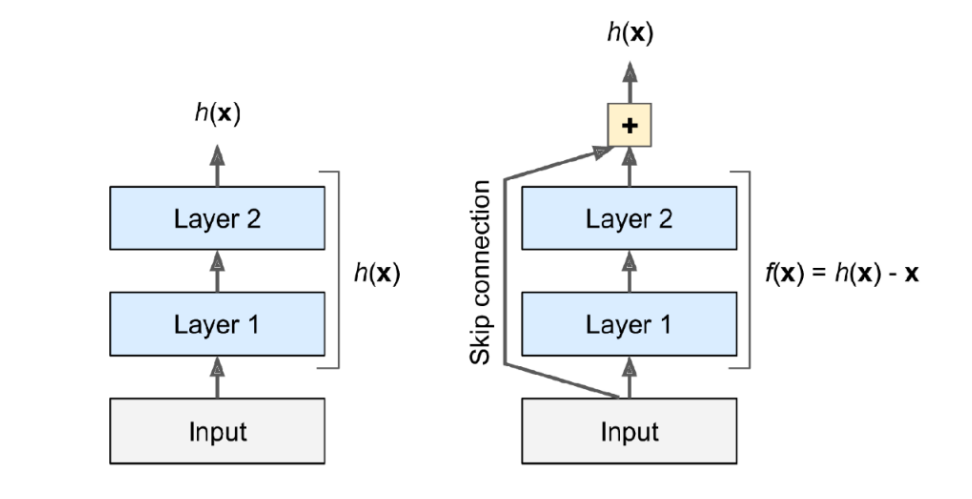
ResNet有效地解决了深度网络中的梯度消失和梯度爆炸问题,在加深层的同时,提高了网络性能。
如果中间两层会梯度消失—》发现之后,就直接跳跃—》避免梯度消失
这一部分太难了—》直接跳题
就是说这两条路走出的效果是一样的,但是有一条路,可能就会走着走着就梯度消失了,所以可以走另一条路—》解决梯度消失
4.5 API使用
这些网络架构都是可以使用的
计算机视觉,图像处理–》torchvision
import torchvision.models as models
#1. Alexnet pretrained=True表示预训练模型的加载,这个模型是别人已经训练好的,
# 训练好的模型有优质的参数,也是训练好的---》我们可以直接使用---》优质参数需要联网下载
# alexnet = models.alexnet(pretrained=True)
# 没有指定参数的话,参数就是随机加载的了
alexnet = models.alexnet()
print(alexnet)

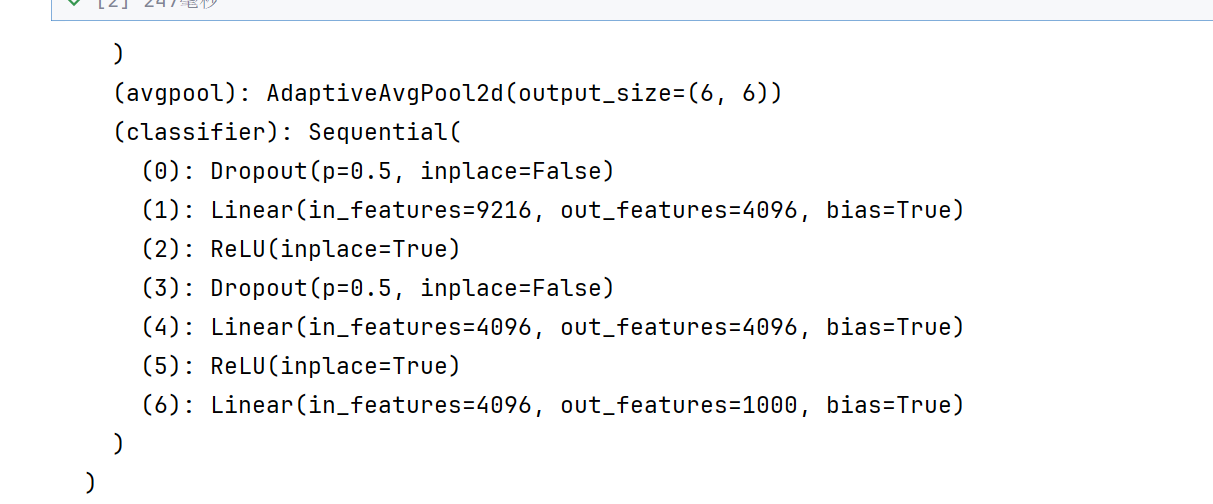
(features): Sequential(中都是一些卷积池化的操作–》五个卷积层,可以自己去数数
(classifier): Sequential(是三个线性层–》全连接层
#2. VGG-16
vgg16 = models.vgg16()
print(vgg16)
13个卷积,3个全连接
#3.Googlenet
googlenet = models.googlenet()
print(googlenet)

这个警告让你加一个init_weights=True,进行初始化,不初始化也是可以的
#4. ResNet
resnet50 = models.resnet50()
print(resnet50)
GAN---->生成模型
CNN—>回归+分类
CNN+GAN–>DCGAN—>深度生成图像网络
2017–》transformer—》提高了自然语言处理能力-----》渗透到图像处理
谷歌提出—》ViT—>图像处理,图像分类识别—》超级好用
transformer–》复杂
CNN—》简单底层,可以用于嵌入式
2025----》CNN+transformer结合—》ConvNext,混合架构
5. 案例:服装分类
使用Fashion MNIST数据集:https://www.kaggle.com/datasets/zalando-research/fashionmnist。

数据集中每个样本都是28×28的灰度图像,与来自10个类别的标签相关联。标签对应如下:
0:T恤/上衣
1:裤子
2:套头衫
3:连衣裙
4:外套
5:凉鞋
6:衬衫
7:运动鞋
8:包
9:靴子
5.1 加载数据

训练集和测试集已经分开了
第一列label是分类标签
后面的就是依次排开的像素点
所以要转化为二维的形状—》28*28
如果不转化的话,比如袖子是长还是短—》看不出来
import torch
import torch.nn as nn
# 读取文件
import pandas as pd
# 画图
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader, TensorDataset
# 1.加载数据
fasion_train = pd.read_csv('./data/fashion-mnist_train.csv')
fasion_test = pd.read_csv('./data/fashion-mnist_test.csv')
# 从数据中提取x和y,转换为张量形式
x_train = fasion_train.iloc[:,1:].values
# x_train = torch.tensor(x_train,dtype=torch.float).reshape(-1,28,28)
#直接转换为三维,-1表示不知道有多少张图片,后面的28和28表示长和宽,但是还有颜色通道呢
x_train = torch.tensor(x_train,dtype=torch.float).reshape(-1,1,28,28)
# 1就表示颜色通道个数了,直接转换为四维数据
y_train = fasion_train.iloc[:,0].values
y_train = torch.tensor(y_train,dtype=torch.int64)x_test = fasion_test.iloc[:,1:].values
x_test = torch.tensor(x_test,dtype=torch.float).reshape(-1,1,28,28)
y_test = fasion_test.iloc[:,0].values
y_test = torch.tensor(y_test,dtype=torch.int64)#显示图片和标签信息,表示拿出第12345张图片的第0个颜色通道,灰度
plt.imshow(x_train[12345,0,:,:],cmap='gray')
plt.show()
print(y_train[12345])

因为放的太大了,所以都成马赛克了
# 构建数据集
train_dataset = TensorDataset(x_train,y_train)
test_dataset = TensorDataset(x_test,y_test)
5.2 创建模型
图片分类—》用CNN
搭建如下结构的模型:
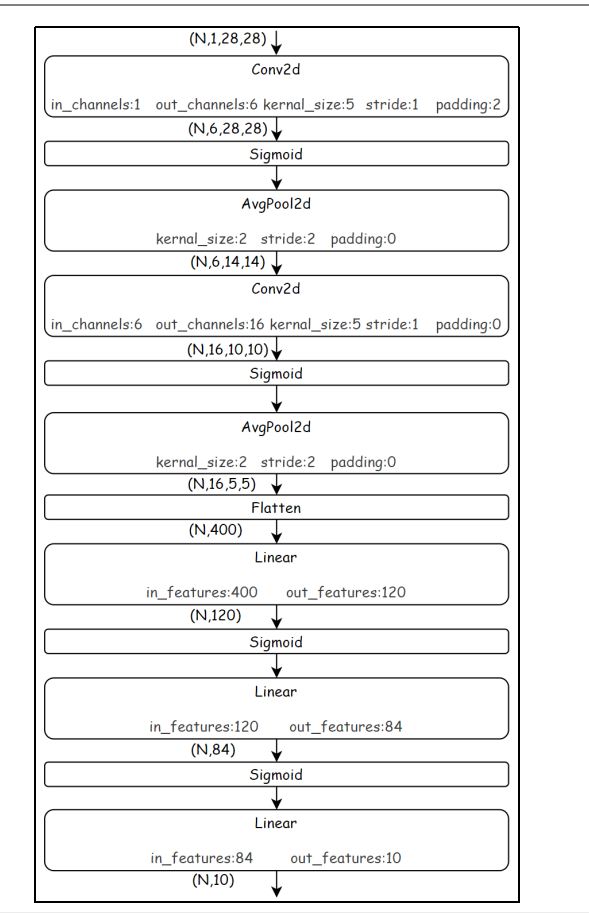
卷积Conv2d,激活函数Sigmoid,池化AvgPool2d,平均池化,模糊化处理----》形状判断
最后一个Linear后面接的就是损失函数了
前面有两个卷积池化层,后面有三个全连接层
中间有个Flatten层—》把高维结构,行向量化,一维展开
因为如果不一维展开的话—》线性层无法处理高维结构了
输入N,C,H,W
N是一个小批次
C就是1,H就是28,W也是28

我们发现颜色通道变多了
这些新通道提取的是轮廓,形状,纹理,花纹等信息了
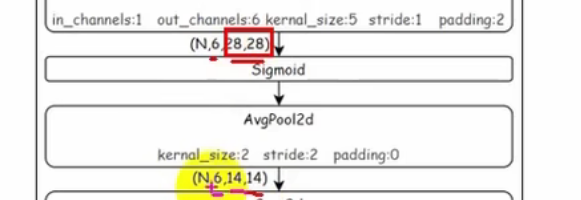
池化层直接压缩
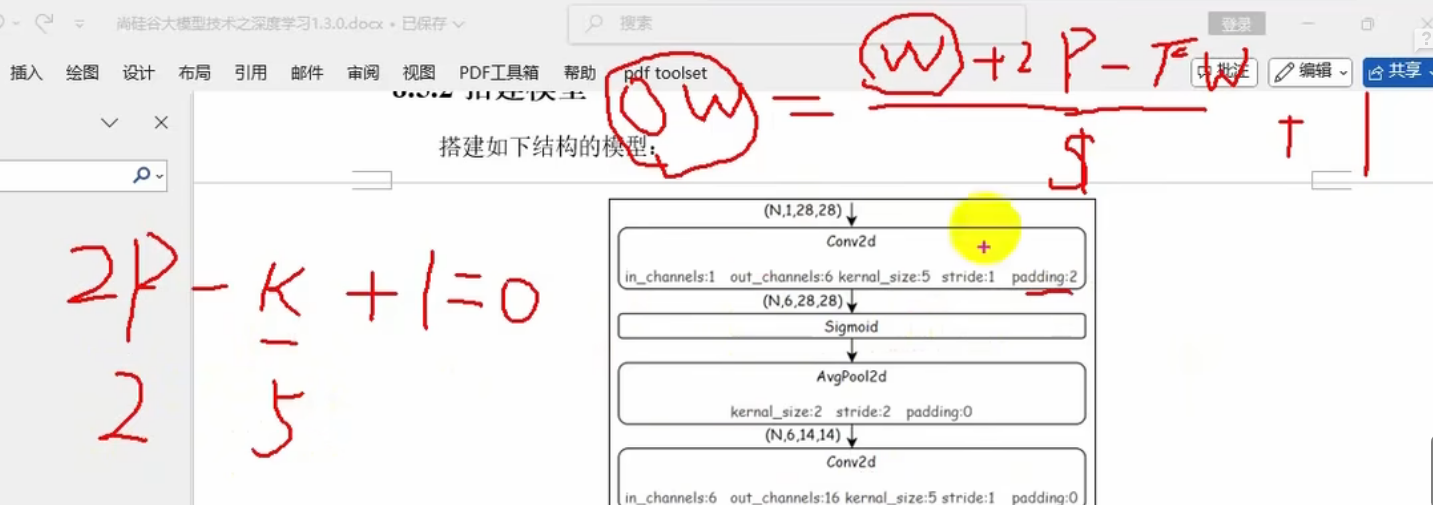
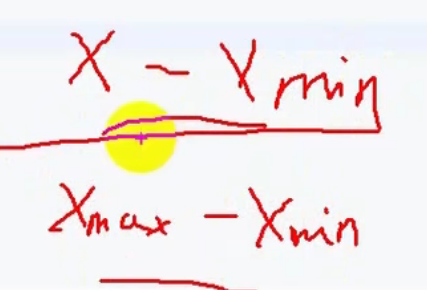
OW是28
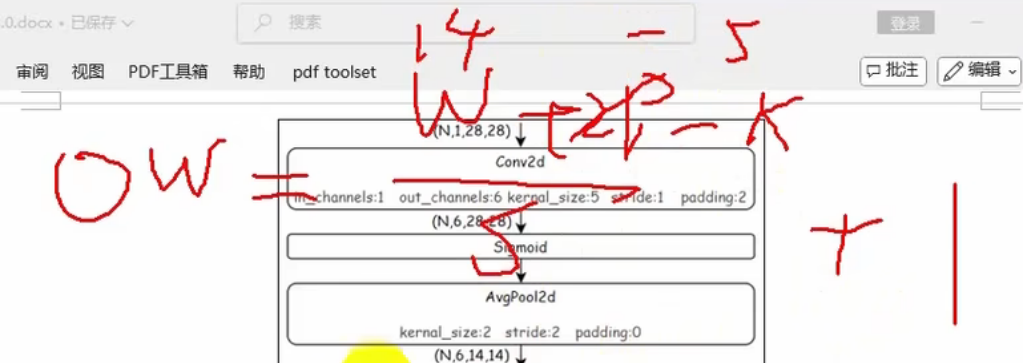
OW是输出的长,W是输入的长,P是扩充长度,K是卷积核大小,S是步长
池化层的话,池化大小应该和步长一样大,为2—》缩小一半
Flatten层就是把每一条数据变成一行
4维变二维
#2. 创建模型
model = nn.Sequential(nn.Conv2d(1,6,5,stride=1,padding=2),nn.Sigmoid(),nn.AvgPool2d(kernel_size=2,stride=2),nn.Conv2d(6, 16, 5, stride=1, padding=0),nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Flatten(),nn.Linear(400, 120),nn.Sigmoid(),nn.Linear(120, 84),nn.Sigmoid(),nn.Linear(84, 10),)
最后一个为什么没有激活函数呢,因为损失函数里面可以整合Softmax
x= torch.randn(size=(1,1,28,28),dtype=torch.float)for layer in model:x = layer(x)print(f"{layer.__class__.__name__:<12}: output shape{x.shape}")

<12表示左对齐,然后总共12个字符
5.3 模型训练
#3. 模型训练和测试
def train_test(model,train_dataset,test_dataset,lr,epoch_num,batch_size,device):#权值权重参数初始化函数---》全连接层和卷积层都要初始化,偏重初始化直接默认就可以了def init_weights(layer):if isinstance(layer, nn.Conv2d) or isinstance(layer, nn.Linear):nn.init.xavier_uniform_(layer.weight)#3.1 初始化相关操作model.apply(init_weights)model.to(device)loss = nn.CrossEntropyLoss()#损失函数,交叉熵损失函数#定义优化器optimizer = torch.optim.SGD(model.parameters(), lr=lr)#3.2 训练过程for epoch in range(epoch_num):model.train()#开启训练模式#定义DataLoadertrain_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)train_loss = 0train_correct_num = 0for batch_idx, (X,y) in enumerate(train_loader):X,y = X.to(device), y.to(device)#3.2.1 前向传播output = model(X)#3.2.2计算损失loss_value = loss(output, y)#3.3.3前向传播loss_value.backward()#3.3.4 更新参数optimizer.step()#3.3.5 梯度清0optimizer.zero_grad()#累加训练损失train_loss += loss_value.item()*X.shape[0]#累加预测正确的数量-----》loss中自带Softmax函数,可以计算出概率,但是我们要取出其中概率最大的作为预测值,看与y一不一样# 然后又因为Softmax计算的概率,值越大---》概率越大,所以可以直接取出output中的最大值pred = output.argmax(dim=1)#一行中所有概率取最大值的索引号train_correct_num+=pred.eq(y).sum()#打印进度条,\r回到起点,0>2表示右对齐,然后2个空间,左边补0,end=""表示不换行,每次都在这一行操作,*表示字符的复制# (batch_idx+1)/len(train_loader)*50 表示50个=就是100%,int表示把浮点数转换为intprint(f"\rEpoch:{epoch+1:0>2}[{'=' * int ((batch_idx+1)/len(train_loader)*50) }]",end="")#本轮训练结束,计算平均训练误差和预测准确率this_loss = train_loss/len(train_dataset)this_train_acc = train_correct_num/len(train_dataset)#准确率
5.4 模型测试
#3. 模型训练和测试
def train_test(model,train_dataset,test_dataset,lr,epoch_num,batch_size,device):#权值权重参数初始化函数---》全连接层和卷积层都要初始化,偏重初始化直接默认就可以了def init_weights(layer):if isinstance(layer, nn.Conv2d) or isinstance(layer, nn.Linear):nn.init.xavier_uniform_(layer.weight)#3.1 初始化相关操作model.apply(init_weights)model.to(device)loss = nn.CrossEntropyLoss()#损失函数,交叉熵损失函数#定义优化器optimizer = torch.optim.SGD(model.parameters(), lr=lr)#3.2 训练过程for epoch in range(epoch_num):model.train()#开启训练模式#定义DataLoadertrain_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)train_loss = 0train_correct_num = 0for batch_idx, (X,y) in enumerate(train_loader):X,y = X.to(device), y.to(device)#3.2.1 前向传播output = model(X)#3.2.2计算损失loss_value = loss(output, y)#3.3.3前向传播loss_value.backward()#3.3.4 更新参数optimizer.step()#3.3.5 梯度清0optimizer.zero_grad()#累加训练损失train_loss += loss_value.item()*X.shape[0]#累加预测正确的数量-----》loss中自带Softmax函数,可以计算出概率,但是我们要取出其中概率最大的作为预测值,看与y一不一样# 然后又因为Softmax计算的概率,值越大---》概率越大,所以可以直接取出output中的最大值pred = output.argmax(dim=1)#一行中所有概率取最大值的索引号train_correct_num+=pred.eq(y).sum()#打印进度条,\r回到起点,0>2表示右对齐,然后2个空间,左边补0,end=""表示不换行,每次都在这一行操作,*表示字符的复制# (batch_idx+1)/len(train_loader)*50 表示50个=就是100%,int表示把浮点数转换为intprint(f"\rEpoch:{epoch+1:0>2}[{'=' * int ((batch_idx+1)/len(train_loader)*50) }]",end="")#本轮训练结束,计算平均训练误差和预测准确率this_loss = train_loss/len(train_dataset)this_train_acc = train_correct_num/len(train_dataset)#准确率#3.3 验证过程model.eval()test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=True)test_correct_num = 0#迭代预测,进行准确数量的累加with torch.no_grad(): #不开启梯度计算for X,y in test_loader:X,y = X.to(device), y.to(device)output = model(X)pred = output.argmax(dim=1)test_correct_num+=pred.eq(y).sum()#计算预测准确率this_test_acc = test_correct_num/len(test_dataset)print(f"train_loss:{this_loss:.4f}, train_acc:{this_train_acc:.4f},test_acc:{this_test_acc:.4f}")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#定义超参数
lr = 0.9
batch_size = 256
epoch_num = 20
train_test(model,train_dataset,test_dataset,lr,epoch_num,batch_size,device)#选取一个数据,进行测试对比
plt.imshow(x_test[666,0,:,:],cmap='gray')
plt.show()
print(y_test[666])#查看真实标签
#传入模型,前向传播,进行预测
# x_test[666]获取的是三维数据,所以用unsqueeze在0维增加1值,1*28*28 变 1*1*28*28
output = model(x_test[666].unsqueeze(0).to(device))
y_pred = output.argmax(dim=1)
print(y_pred)
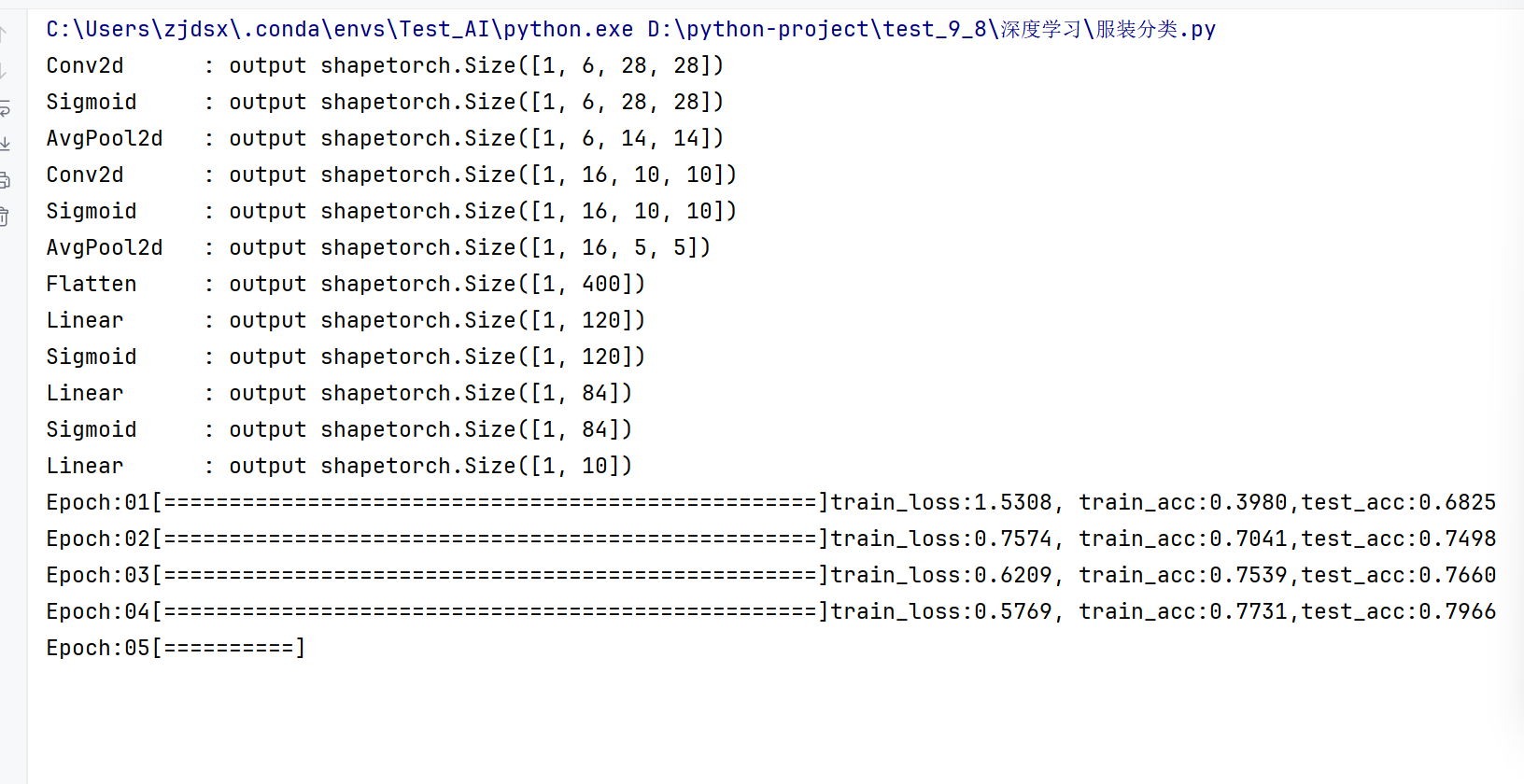
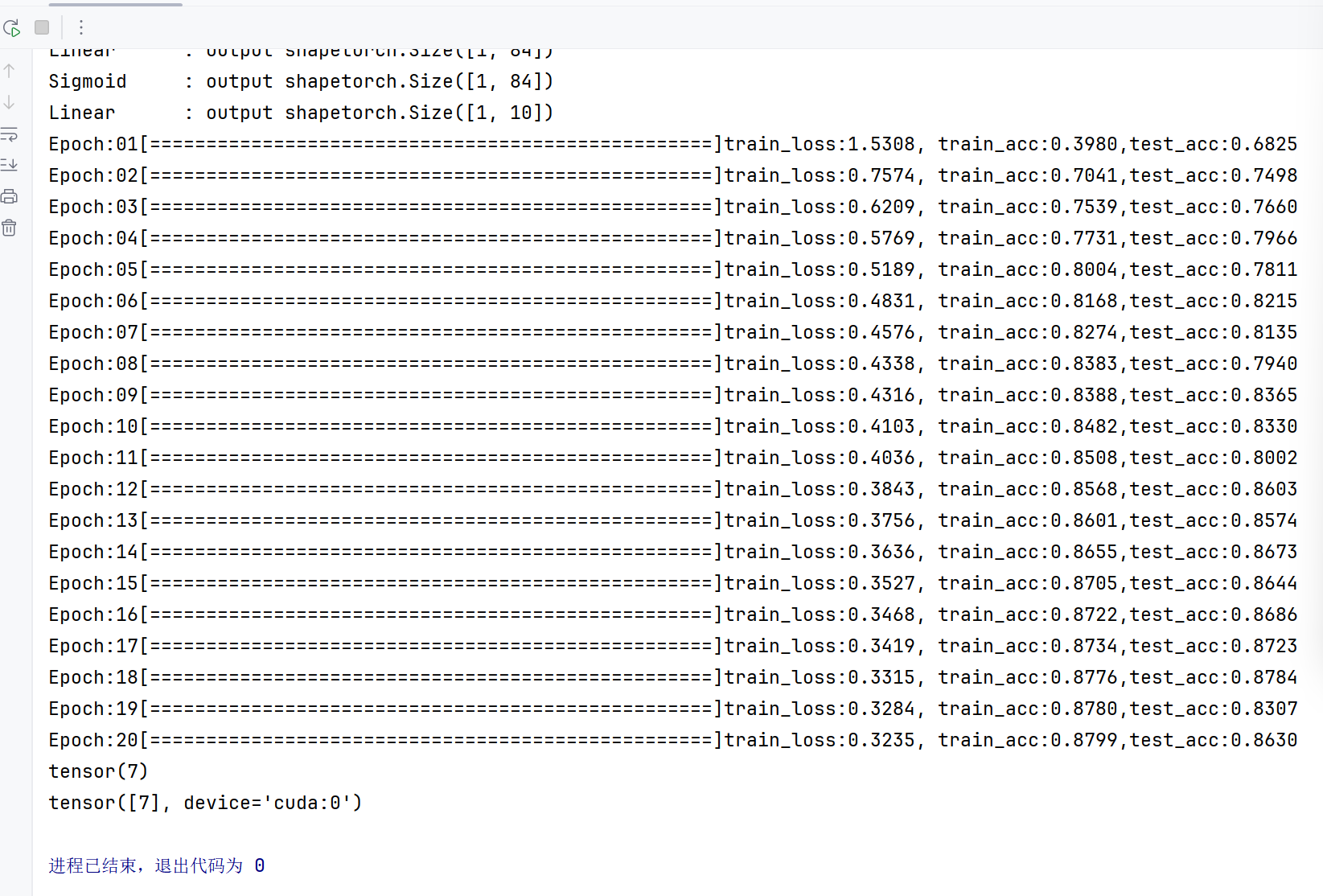
长得像运动鞋7.是对的
#定义优化器optimizer = torch.optim.Adam(model.parameters(), lr=lr)
如果使用Adam这个优化器的话—》自带动量法—》lr要小一点
#定义超参数
lr = 0.01
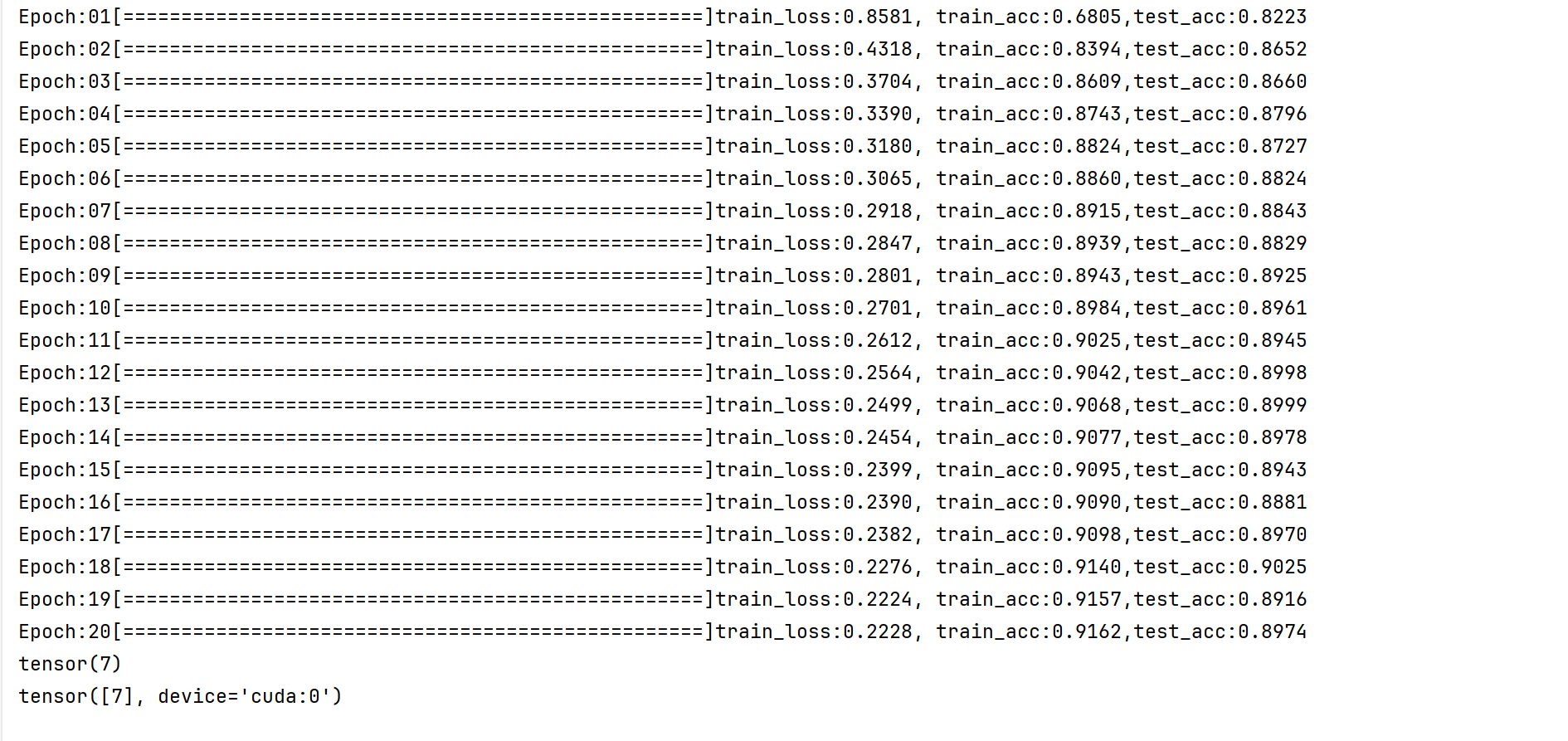
发现预测得更准了