【大模型LLM面试合集】分布式训练_张量并行
4.张量并行
和流水线并行类似,张量并行也是将模型分解放置到不同的GPU上,以解决单块GPU无法储存整个模型的问题。和流水线并行不同的地方在于,张量并行是针对模型中的张量进行拆分,将其放置到不同的GPU上。
1.简述
模型并行是不同设备负责单个计算图不同部分的计算。而将计算图中的层内的参数(张量)切分到不同设备(即层内并行),每个设备只拥有模型的一部分,以减少内存负荷,我们称之为张量模型并行。
张量并行从数学原理上来看就是对于linear层就是把矩阵分块进行计算,然后把结果合并;对于非linear层,则不做额外设计。
2.张量并行方式
张量切分方式分为按行进行切分和按列进行切分,分别对应行并行(Row Parallelism)与列并行(Column Parallelism)。
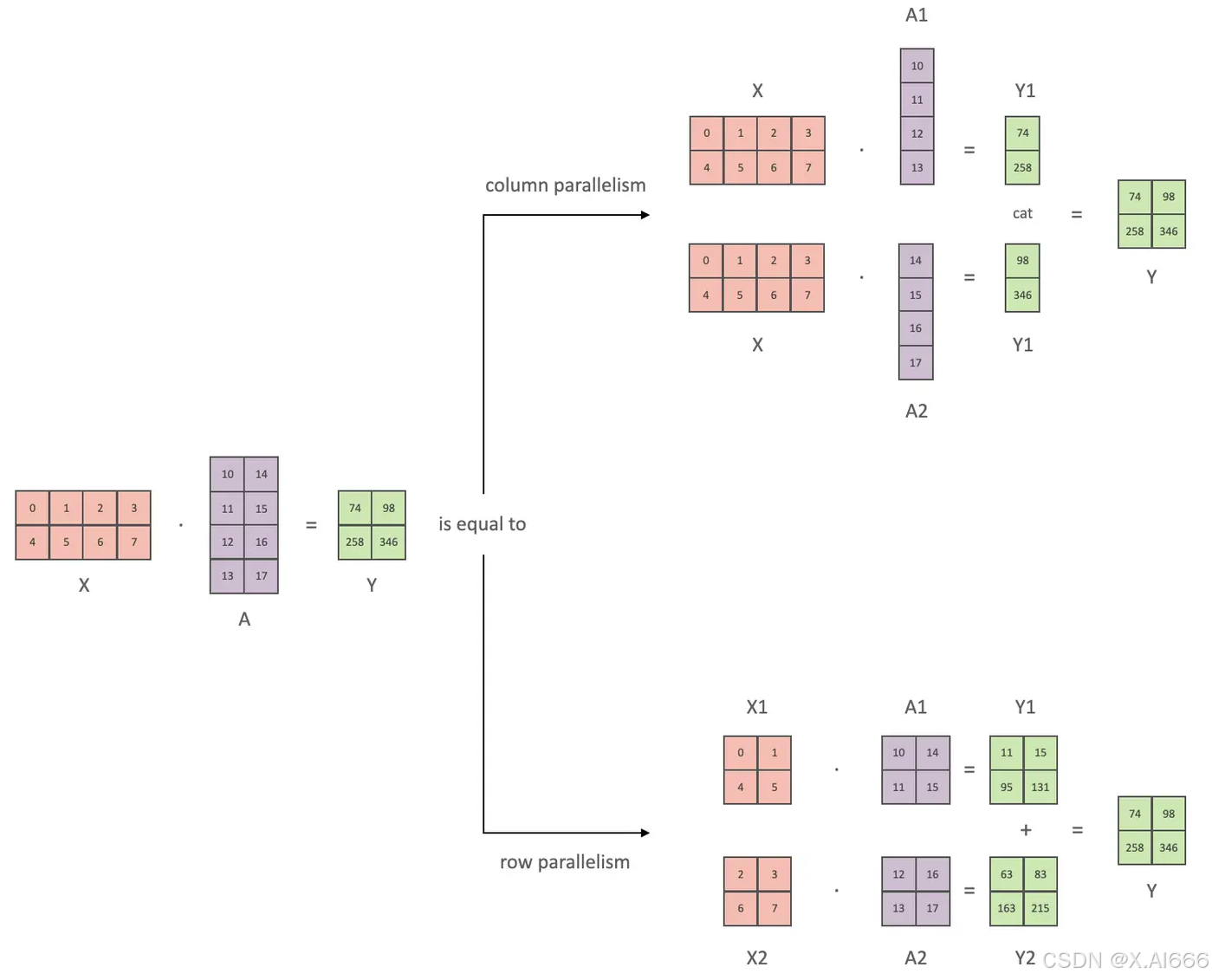
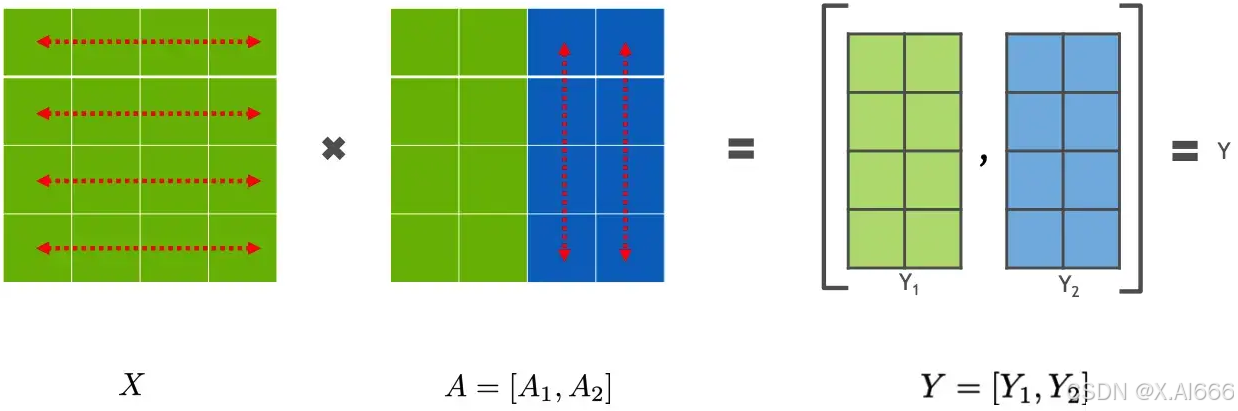
下面用通用矩阵的矩阵乘法(GEMM)来进行示例,看看线性层如何进行模型并行。假设 Y = XA ,对于模型来说,X 是输入,A是权重,Y是输出。
2.1 行并行
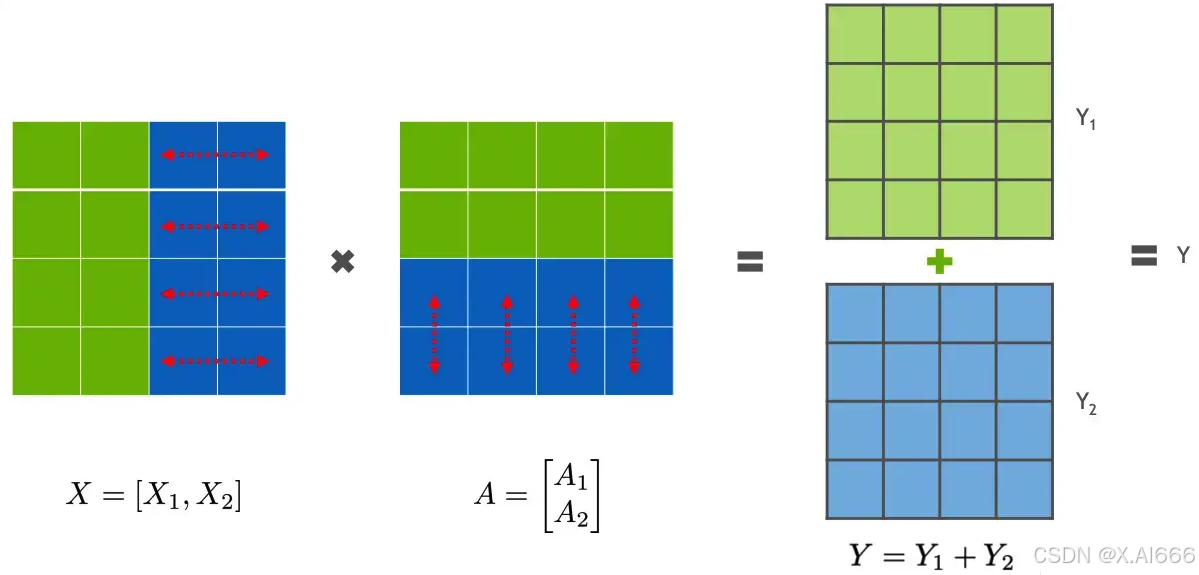
行并行就是把权重 A 按照行分割成两部分。为了保证运算,同时我们也把 X 按照列来分割为两部分,具体如下所示:
X A = [ X 1 X 2 ] [ A 1 A 2 ] = X 1 A 1 + X 2 A 2 = Y 1 + Y 2 = Y X A=\left[\begin{array}{ll}X 1 & X 2\end{array}\right]\left[\begin{array}{l}A 1 \\ A 2\end{array}\right]=X 1 A 1+X 2 A 2=Y 1+Y 2=Y XA=[X1X2][A1A2]=X1A1+X2A2=Y1+Y2=Y
这样,X1 和 A1 就可以放到 GPU0 之上计算得出 Y1,,X2 和 A2 可以放到第二个 GPU1 之上计算得出 Y2,然后,把Y1和Y2结果相加,得到最终的输出Y。
2.2 列并行
列并行就是把 A按照列来分割,具体示例如下:
X A = [ X ] [ A 1 A 2 ] = [ X A 1 X A 2 ] = [ Y 1 Y 2 ] = Y X A=[X]\left[\begin{array}{ll}A 1 & A 2\end{array}\right]=\left[\begin{array}{ll}X A 1 & X A 2\end{array}\right]=\left[\begin{array}{ll}Y 1 & Y 2\end{array}\right]=Y XA=[X][A1A2]=[XA1XA2]=[Y1Y2]=Y
这样,将 X 分别放置在GPU0 和GPU1,将 A1 放置在 GPU0,将 A2 放置在 GPU1,然后分别进行矩阵运行,最终将2个GPU上面的矩阵拼接在一起,得到最终的输出Y。
3. 1维(1D)张量并行(Megatron-LM)
张量并行则涉及到不同的分片 (sharding)方法,现在最常用的都是 1D 分片,即将张量按照某一个维度进行划分(横着切或者竖着切)。
目前,在基于Transformer架构为基础的大模型中,最常见的张量并行方案由Megatron-LM提出,它是一种高效的一维(1D)张量并行实现。它采用的则是非常直接的张量并行方式,对权重进行划分后放至不同GPU上进行计算。
如下图所示,对于一个基于 Transformer 结构的模型来说,主要由一个 N 层 Transformer 块组成,除此之外还有输入和输出 Embedding 层。
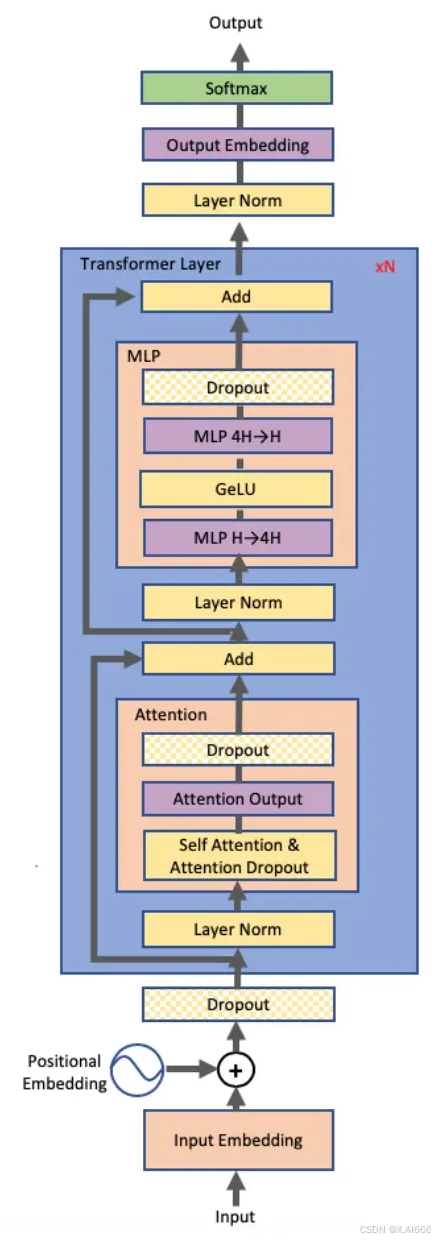
而一个 Transformer 层里面主要由由自注意力(Self-Attention)和 MLP 组成。因此,本方案主要针对多头注意力(MHA)块和MLP块进行切分进行模型并行。
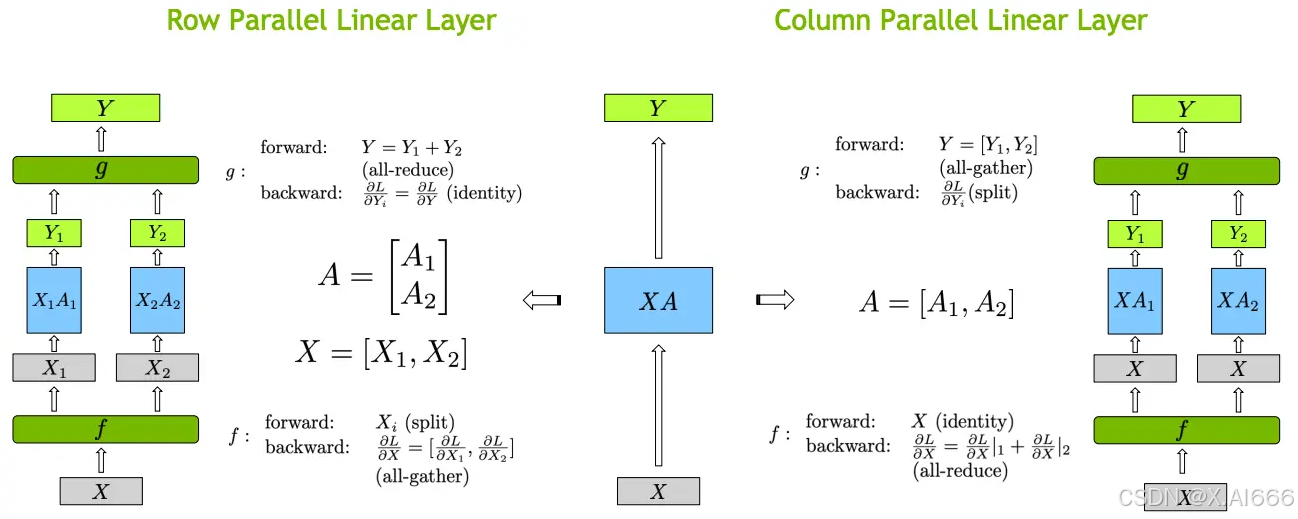
对于 MLP 层切分相对来说比较简单,该层主要由一个GELU是激活函数,以及 A 和 B 两个线性层组成。其中,f 和 g 分别表示两个算子,每个算子都包含一组forward + backward 操作。f 和 g 是共轭的。
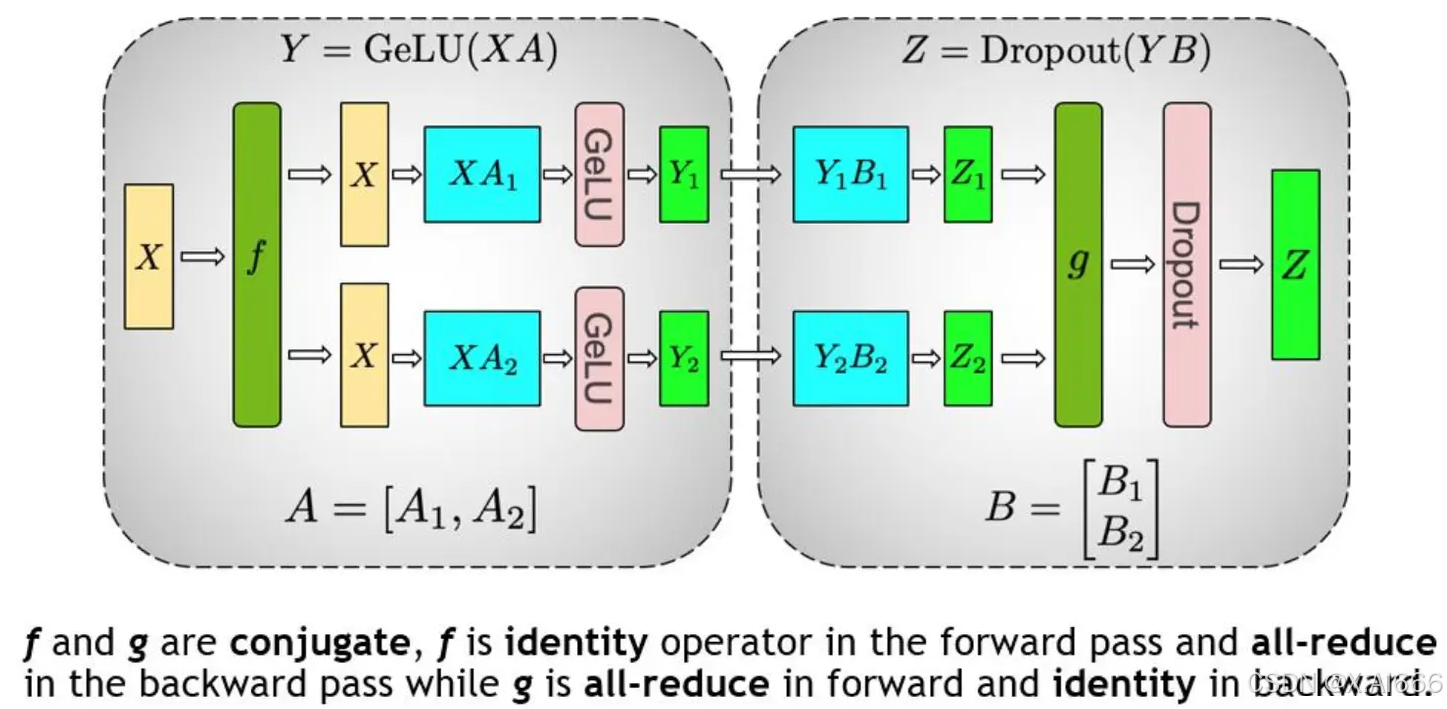
在MLP层中,先对A采用“列切割”,然后对B采用“行切割” 。
f的 forward 计算:把输入X拷贝到两块GPU上,每块GPU即可独立做forward计算。g的 forward 计算:每块GPU上的forward的计算完毕,取得Z1和Z2后,GPU间做一次AllReduce,相加结果产生Z。g的 backward 计算:只需要把 ∂ L ∂ Z \frac{\partial L}{\partial Z} ∂Z∂L拷贝到两块GPU上,两块GPU就能各自独立做梯度计算。f的 backward 计算:当前层的梯度计算完毕,需要传递到下一层继续做梯度计算时,我们需要求得 ∂ L ∂ X \frac{\partial L}{\partial X} ∂X∂L。则此时两块GPU做一次AllReduce,把各自的梯度 ∂ L ∂ X 1 \frac{\partial L}{\partial X_1} ∂X1∂L和 $ \frac{\partial L}{\partial X_2} $相加即可。
对于 MHA 层进行切分稍微会复杂一点。一个MHA层由多个自注意力块组成。每个自注意力头都可以独立计算,最后,再将结果拼接(concat)起来。也就是说,可以把每个头的参数放到一块GPU上。
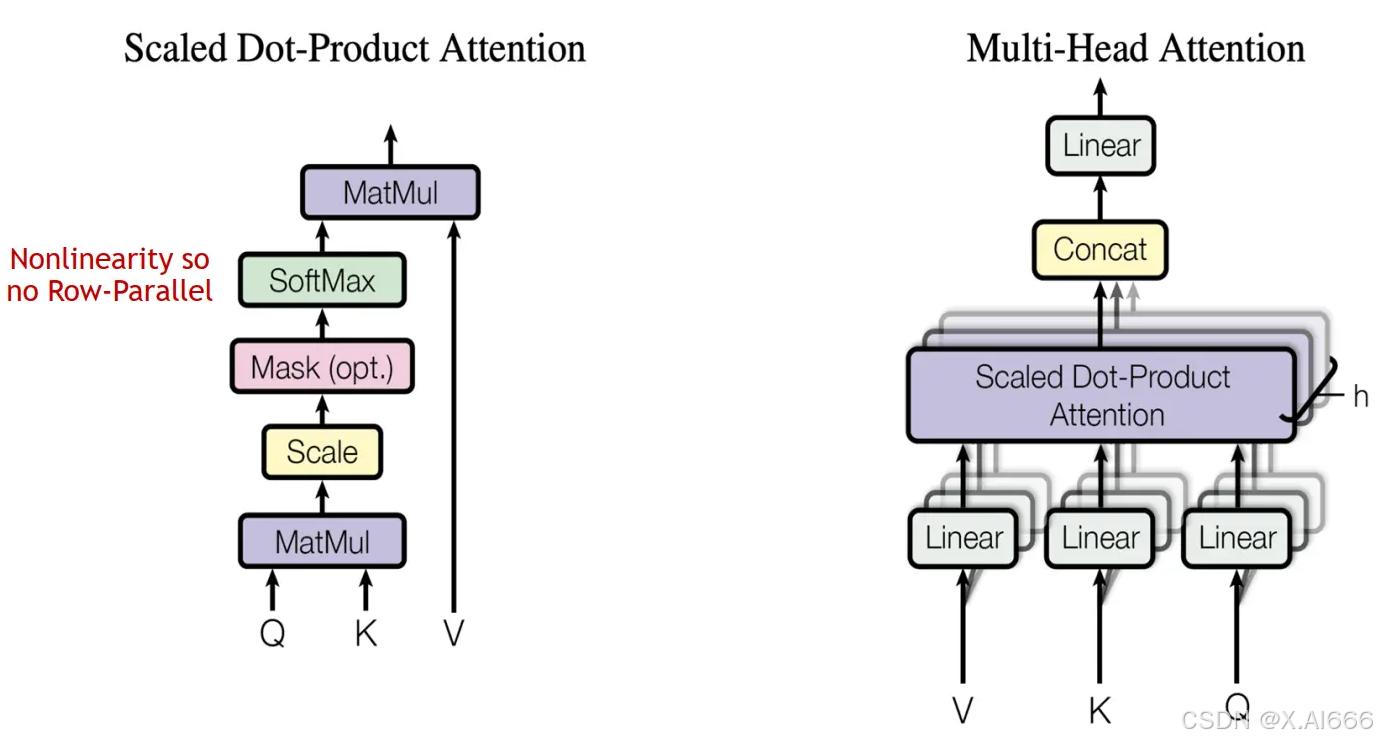
在 MHA 层,对三个参数矩阵Q,K,V,按照“列切割” ,每个头放到一块GPU上,做并行计算。对线性层B,按照“行切割” 。切割的方式和 MLP 层基本一致,其forward与backward原理也一致,这里不再赘述。
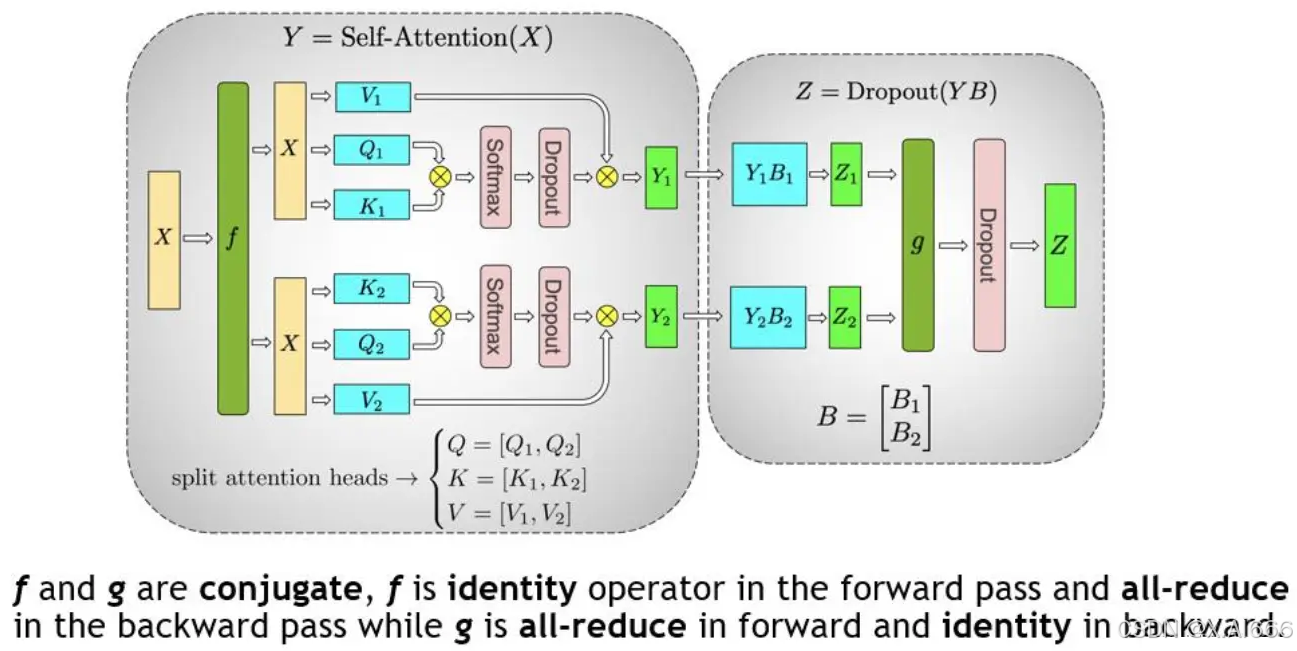
最后,在实际应用中,并不一定按照一个head占用一块GPU来切割权重,我们也可以一个多个head占用一块GPU,这依然不会改变单块GPU上独立计算的目的。所以实际设计时,我们尽量保证head总数能被GPU个数整除**。**
现在,将 MLP 与 MHA 块放置在一起,一个 Transformer 层的张量模型并行如下所示:
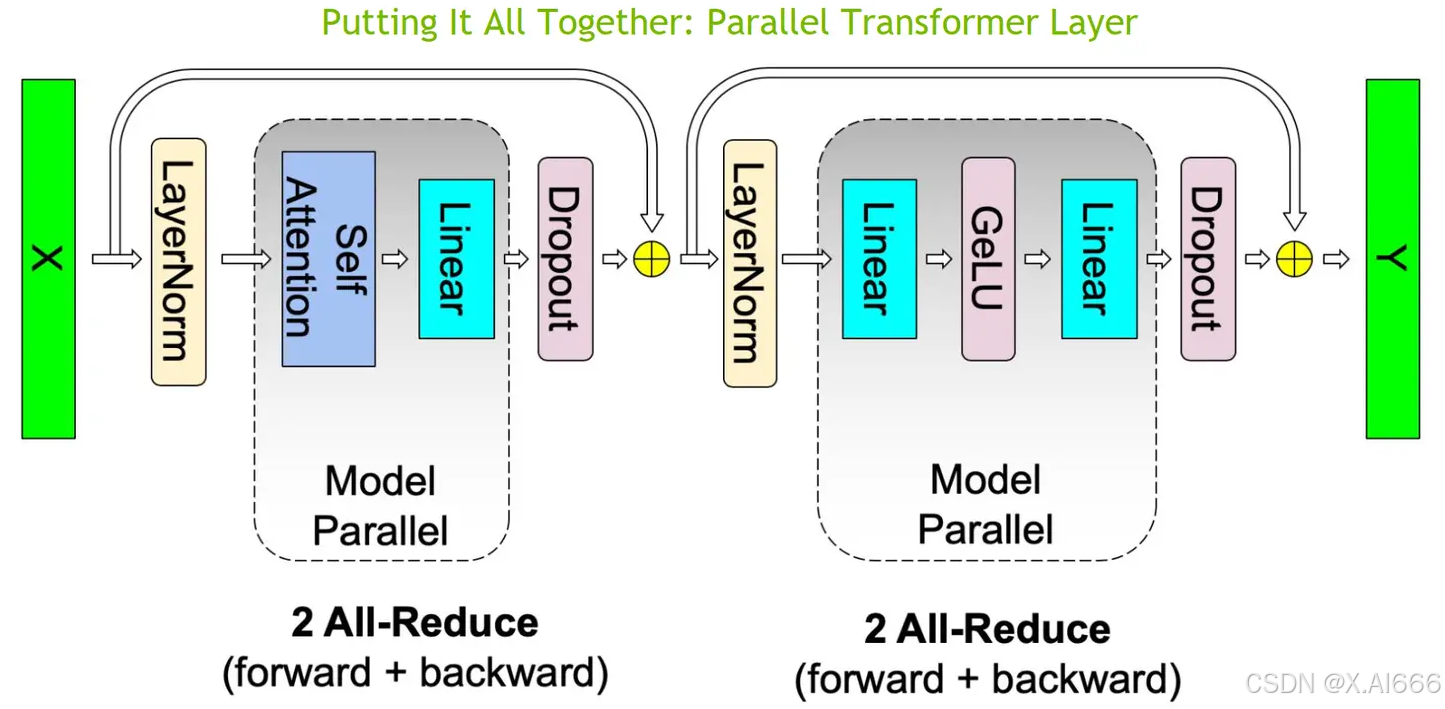
可以看到,一个 Transformer 层的正向和反向传播中总共有 4 个 All-Reduce 通信操作。
上面提到了对于一个 Transformer 结构的模型来说,通常,还有一个输入Embeding和一个输出Embeding层,其维数为 (v, h),其中,h表示隐藏大小,v表示词汇量大小。
由于现代语言模型的词汇量约为数万个(例如,GPT-2使用的词汇量为50257),因此,将 Embeding 层 GEMM 进行并行化是非常有益的。然而,在Transformer语言模型中,为了节约内存,通常输出 Embeding 层与输入 Embeding 层共享权重,因此,需要对两者进行修改。
在Embbedding层,按照词的维度切分,即每张卡只存储部分词向量表,然后,通过 All Gather 汇总各个设备上的部分词向量结果,从而得到完整的词向量结果
在 Megatron-LM 中,通过如下方法来初始化张量并行、流水线并行以及数据并行组。
from megatron.core import mpu, tensor_parallel
mpu.initialize_model_parallel(args.tensor_model_parallel_size,
args.pipeline_model_parallel_size,
args.virtual_pipeline_model_parallel_size,
args.pipeline_model_parallel_split_rank)
在给定 P 个处理器的情况下,下面为理论上的计算和内存成本,以及基于环形(ring)算法的1D 张量并行的前向和后向的通信成本。
| 计算 | 内存 (参数) | 内存 (activations) | 通信 (带宽) | 通信 (时延) |
|---|---|---|---|---|
| O(1/P) | O(1/P) | O(1) | O(2(P−1)/P) | O(2(P−1)) |
4.多维张量并行
英伟达Megatron-LM的张量并行本质上使用的是 1 维矩阵划分,这种方法虽然将参数划分到多个处理器上,但每个处理器仍需要存储整个中间激活,在处理大模型时会浪费大量显存空间。此外,由于仅采用1维矩阵划分,在每次计算中,每个处理器都需要与其他所有处理器进行通信,因此,通信成本会随并行度增高而激增。
显然,1 维张量并行已无法满足当前超大AI模型的需求。对此,Colossal-AI 提供多维张量并行,即以 2/2.5/3 维方式进行张量并行。
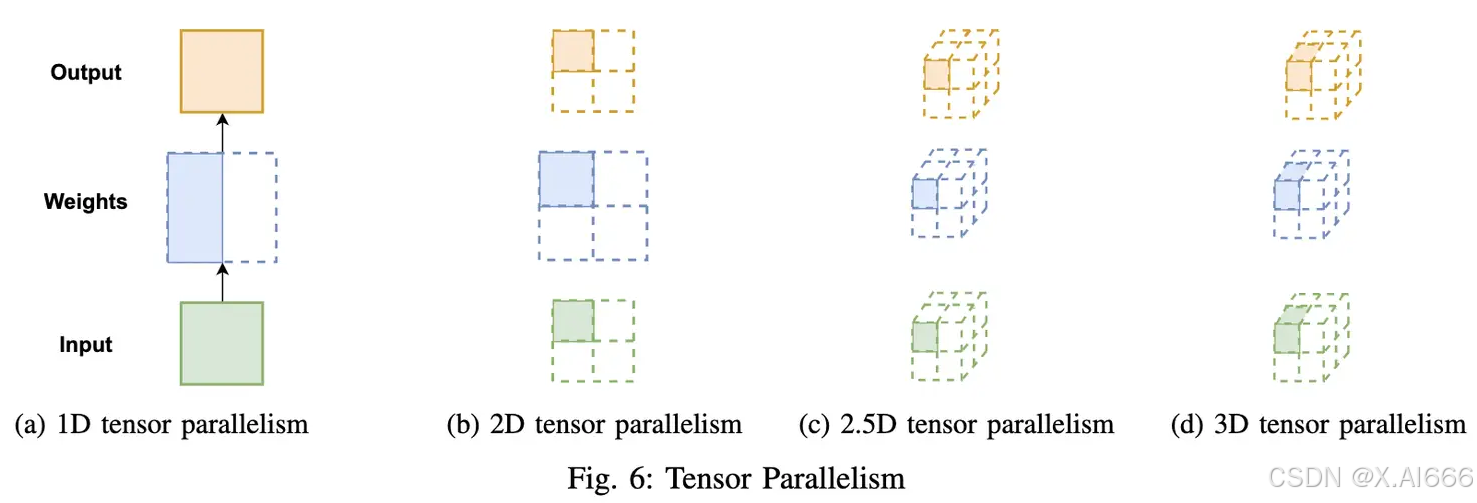
4.1 2D张量并行
Megatron中的 1D 张量并行方案并没有对激活(activations)进行划分,对于大模型而言,这也会消耗大量的内存。
为了平均分配计算和内存负荷,在 SUMMA 算法(一种可扩展的通用矩阵乘法算法,并行实现矩阵乘法)的基础上, 2D 张量并行 被引入。它把 input 和 weight 都沿着两个维度均匀切分。
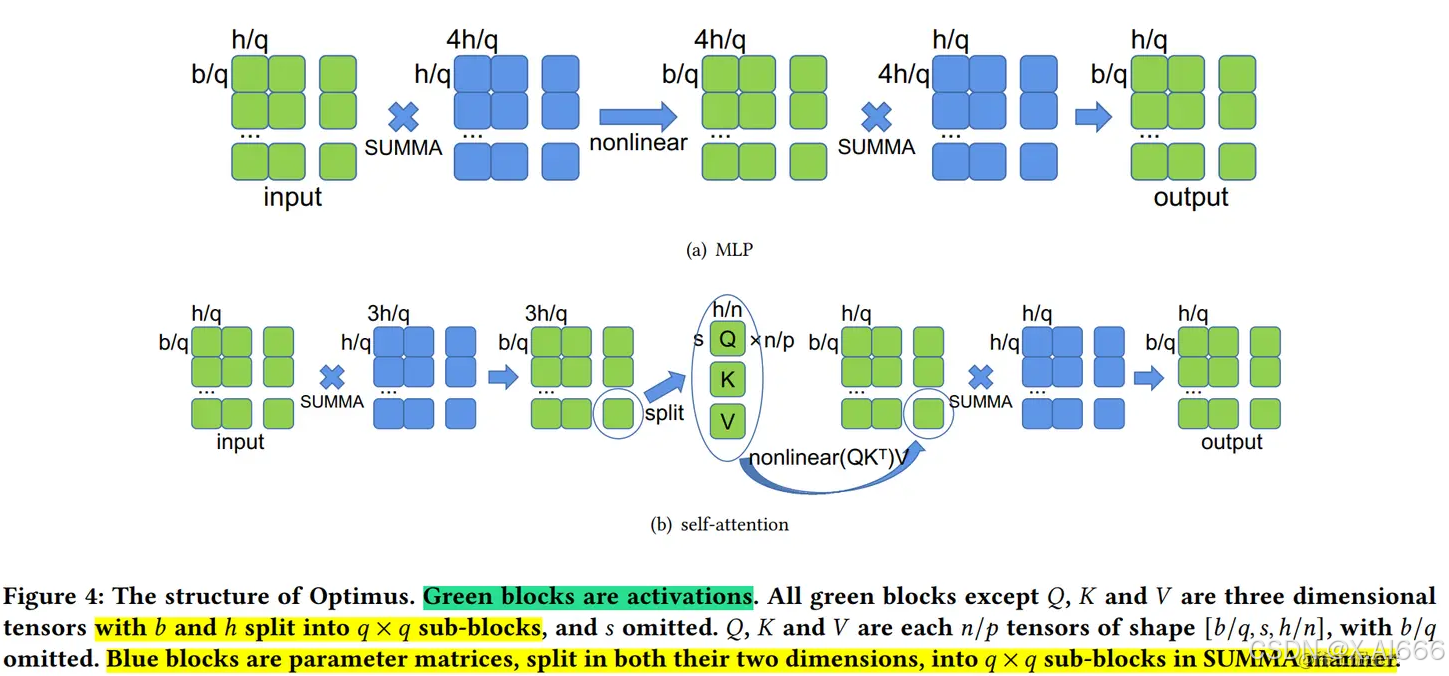
这里还是以线性层 Y = X A Y=XA Y=XA为例。给定 P = q × q P=q \times q P=q×q个处理器(必要条件),如果 q = 2 q=2 q=2,我们把输入 X X X和权重 A A A都划分为:
[ X 00 X 01 X 10 X 11 ] 和 [ A 00 A 01 A 10 A 11 ] \left[\begin{array}{ll}X_{00} & X_{01} \\ X_{10} & X_{11}\end{array}\right] 和 \left[\begin{array}{ll}A_{00} & A_{01} \\ A_{10} & A_{11}\end{array}\right] [X00X10X01X11]和[A00A10A01A11]
该计算包括 q q q步。
当 t = 1 t=1 t=1时,即第一步, X i 0 X_{i0} Xi0 (即: [ X 00 X 10 ] \left[\begin{array}{l}X_{00} \\ X_{10}\end{array}\right] [X00X10])在其行中被广播,而 A 0 j A_{0j} A0j(即: [ A 00 A 01 ] \left[\begin{array}{ll}A_{00} & A_{01}\end{array}\right] [A00A01])在其列中被广播。因此,我们有
[ X 00 , A 00 X 00 , A 01 X 10 , A 00 X 10 , A 01 ] \left[\begin{array}{ll}X_{00}, A_{00} & X_{00}, A_{01} \\ X_{10}, A_{00} & X_{10}, A_{01}\end{array}\right] [X00,A00X10,A00X00,A01