C++:STL--》 mapset以及multsetmultmap的使用
前言 map和set的认知

Set
Sets are containers that store unique elements following a specific order.
In a set, the value of an element also identifies it (the value is itself the key, of type T), and each value must be unique. The value of the elements in a set cannot be modified once in the container (the elements are always const), but they can be inserted or removed from the container.
Internally, the elements in a set are always sorted following a specific strict weak ordering criterion indicated by its internal comparison object (of type Compare).
set containers are generally slower than unordered_set containers to access individual elements by their key, but they allow the direct iteration on subsets based on their order.
Sets are typically implemented as binary search trees.
补充+上文基本内容: 本质上set和map除了存放的值,底层都是一样的,关联式容器,set因为底层使用的是搜索树(具体是红黑树)能实现: 插入的元素是唯一的(可以去重),查询效率稳定的O(log n),由于底层是搜索树的缘故它是不支持修改的,但是可以删除啊。
在内部中也就是set和map的排序情况,当你用迭代器去遍历一遍你会发现它是有序的(默认是升序从低到高)
通常认为(平均上来说),查询单个元素的效率还是hash实现的unordered_set&&map比set要快的(O(log n)),但是set和map人家可以有效查看元素啊!

Maps are associative containers that store elements formed by a combination of a key value and a mapped value, following a specific order.
In a map, the key values are generally used to sort and uniquely identify the elements, while the mapped values store the content associated to this key. The types of key and mapped value may differ, and are grouped together in member type value_type, which is a pair type combining both:
补充+上文基本内容: map它是关联式容器(associative container),它存放的元素是键值对,故这么说,区别于之前学习的序列容器,都是线性的,像链表和vector,他们是按照位置访问的,而且是线性的。 元素类型是关联式的: KV 通过K来访问val值 线性容器更期待的是: 【pos】通过位置来访问。
值得一提的是,map在红黑树中是用Key来比较确定次序的。
一. 构造函数赋值重载 constructor以及对Compare仿函数的认知
1.1 set构造函数 和仿函数Compare
template < class Key, // map::key_typeclass T, // map::mapped_typeclass Compare = less<Key>, // map::key_compareclass Alloc = allocator<pair<const Key,T> > // map::allocator_type> class map;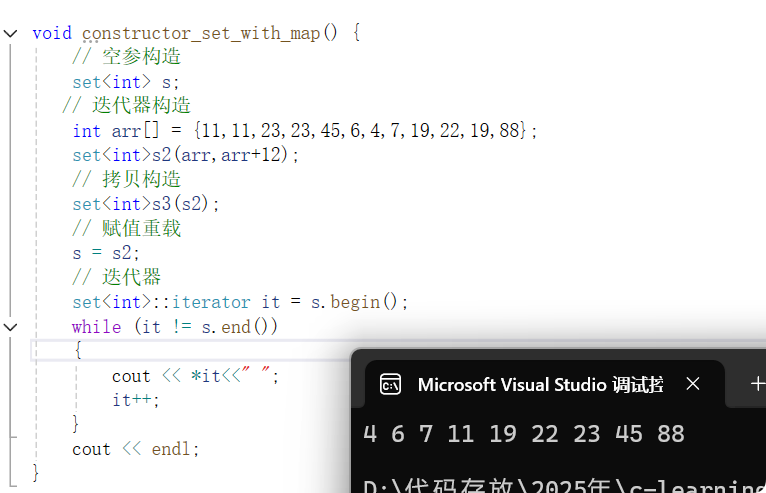
输出顺序是升序,说明此时Less仿函数作用就是return (this->key>)
compare仿函数:

template<class T>
struct Less {// 内部实现的时候 对Less 加上const 表面这是一个const的函数 const对象 仿函数一般会被定义为const的bool operator()( const T& key_x, const T& key_y)const {return key_x < key_y;}
};
template<class T>
struct Greater {// 内部实现的时候 对Less 加上const 表面这是一个const的函数 const对象 仿函数一般会被定义为const的bool operator()(const T& key_x, const T& key_y)const {return key_x > key_y;}
};void constructor_set_with_map() {// 空参构造set<int,Greater<int>> s;// 迭代器构造int arr[] = {11,11,23,23,45,6,4,7,19,22,19,88};set<int,Greater<int>>s2(arr,arr+12);// 拷贝构造set<int, Greater<int>>s3(s2);// 赋值重载s = s2;// 迭代器set<int,Greater<int>>::iterator it = s.begin();while (it != s.end()){cout << *it<<" ";it++;}cout << endl;}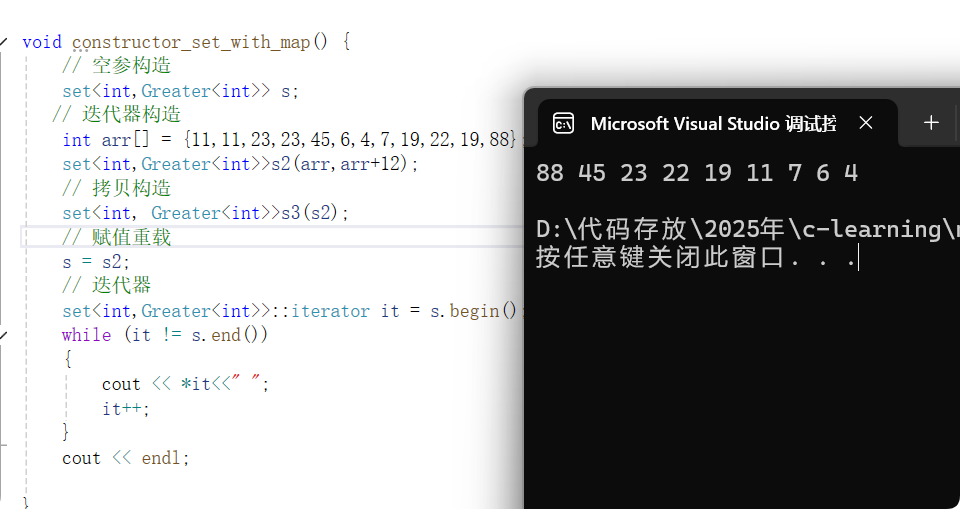
tip: 注意类型不匹配问题:
有人说:看看这个代码能行吗 :
set<int,Greater<int>>s2(arr,arr+12);
// 拷贝构造
set<int>s3(s2);不行注意类型不匹配,即便是你实现的功能根库里面的一样,但是模板实例化的时候,根据作用域能看出来你的Greater根我库里的不是一个类。
1.2 map构造函数 和仿函数Compare
template < class Key, // map::key_typeclass T, // map::mapped_typeclass Compare = less<Key>, // map::key_compareclass Alloc = allocator<pair<const Key,T> > // map::allocator_type> class map;
map模板实例化的类型的时候,Key对应的就是关键值类型,但是这个T还有注释说的这个mapped_type 查文档发现其实就是T也就是pair类型也就意味着其实map里面放着的就是pair<const K,V>然后实例化给底层的树结构:下面这个能说明这个问题,在K-V模型来对待的话,其实V对应的就是pair<int,string> 报错是因为现在试图插入的pair对不上应该插入一个pair<int,pair<int,string>> 类型哦!
但是为了限制用户的使用对键修改其实内部返回的pair的时候会对pair进行一层修饰:
pair<const K,V> 这样就达到了K不能被修改的目的

当然按照语境代码应该是这样的:

仿函数
map的仿函数,首先你要理解在map类实习的时候,根据你传入的K,V类型 (对应: Key_type和 mapped_tyep) 这时操作的基本单元其实是 pair<K,V>.
基于这个给红黑树,红黑树根据K来调节二叉搜索树。 所以你写的仿函数应该是 class Compare = less<Key>,
把Key的类型传进去的模板类。
仿函数是一样的,我并没有修改,因为它的作用就是用来比较的,至于要传递什么类型的数过来比较,我们只需要在map实现的时候封装对应的类型即可。

二. map和set的迭代器
map和set的迭代器,其实底层都是封装了基于红黑树实现的迭代器,如果你阅读侯捷先生或者其他人的关于queue的迭代器实现的话,你能感受到其实这是一种组合的策略,也就是在封装map和set的时候,他们的私有对象封装一个红黑树模板类的对象即可。
过多的底层实现这里暂且不谈,具体实现我打算下一期谈谈,本期同大家一起探讨map和set的迭代器。
2.1 遍历
既然已经理解map和set的底层是一个搜索二叉树,他们二者的区别就是在于,K模型还是K-V模型罢了。 我们迭代器的出现本身就是为了统一容器的大多操作,让代码更为优雅,既然如此他们的迭代器使用都是同之前的容器非常类似的。
但是值得一谈的是map和set通过迭代器遍历的结果是有序的,至于是升序还是降序,这根你传入的仿函数有关(默认Less 得到的是升序)
set:
vector<string> vs;
vs.push_back("王1");
vs.push_back("王2");
vs.push_back("王3");
set<string> s(vs.begin(), vs.end());
// 正常迭代器
set<string>::iterator it = s.begin();
while (it != s.end()) {*it;// 解引用访问 得到数据类型对象的string 不过 迭代器返回的key类型// 被封装之后会是 const key 得到是 const stringconst char* s = it->c_str();it++; //
}如下代码和输出结果,我们能知道其实set内部对于string类型也是有一个比较的,对于它的仿函数我们说一下默认的仿函数如下我们自己写的: 实例化以后:
operator()(const stirng* key_x,const stirng* key_x)
两个string类型能直接比较吗? 我们能验证的如下代码 也就验证了,至于原因也很简单,我们都知道对于string 封装了 运算符重载 = 那么对于值的比较也大概率会封装的。
所以那么这里用我们自己的仿函数也是没问题的!渐渐的你会感受到stl库的设计真是又巧妙又简洁!

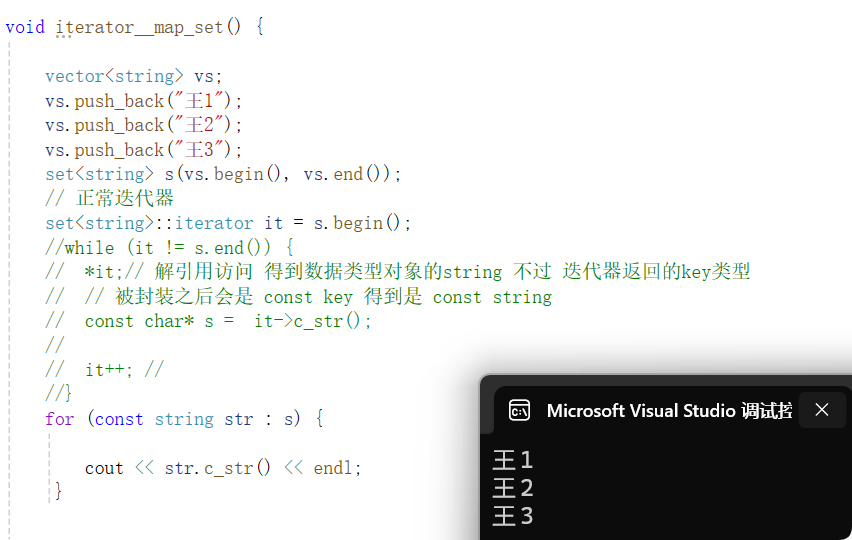
稍微补充一下这里的迭代器的一些知识: 先前我们了解了map和set的迭代器的基本原理,其实还会封装其他的像reverse_iterator 逆向迭代器,用它遍历会得到逆序。
以及加上cbegin() 其实就是说迭代器是const_iterator 意思是迭代器是const。
有趣的是什么呢,我们都知道set的的迭代器其实得到的返回值key都是const key 不可以修改的所以基本上 const的迭代器和 非const的迭代器对于set来说没什么区别,都不能修改key。
tip: set的使用场景
对于set这种k模型,我的建议是根据它的有序性,以及key唯一性,我们可以拿来去重以及得到一个有序的数列。
map:

对于map的迭代器使用,我认为基本的知识参考如下代码吧:
正常理解迭代器使用就是一个是: 通过begin() 和end() 以及范围for(范围for底层就是迭代器实现的 只不过很好看 也简洁)
// map的迭代器
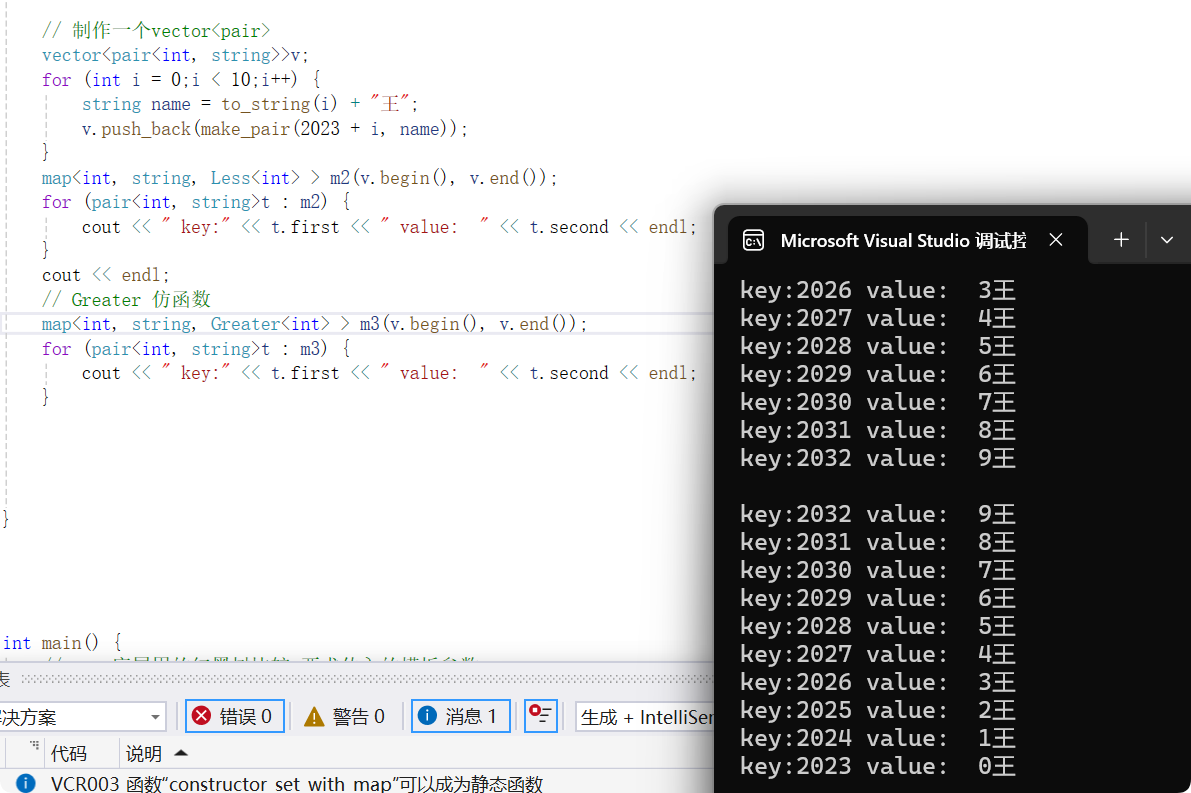
vector<pair<string, int>> v;pair<string,int>p1 = make_pair("香蕉",4);pair<string,int>p2 = make_pair("苹果",5);pair<string,int>p3 = make_pair("西瓜",6);pair<string,int>p4 = make_pair("葡萄",10);v.push_back(p1);v.push_back(p2);v.push_back(p3);v.push_back(p4);map<string,int>m (v.begin(),v.end());map<string, int>::iterator it = m.begin();while (it != m.end()) {// *it 得到数据是红黑树的基本单元 也就是一个pair<K,V> 通过迭代器返回的是 pair<const key,v>cout << (*it).first << " " << (*it).second << endl;it++;}cout << "\n";for (pair<const string,int> p : m) {cout << p.first << " " << p.second << endl;}
map的通过键来访问值
我认为最值得一提的就是map的通过键来访问值了,它很好用的,因为它可以通过键来访问值,如果当前键不存在就会创建当前这个键,相关的V会调用它自己的构造函数。
如下参考文档对他的介绍 : 我简单阐述就是: 1.我们可以通过key来访问它的value,2.如果当前key存在则可以通过得到的v修改我们的value值。 从前文学习我们值得map的key是不能被修改的,使用我们之前得到key的方式都是通过迭代器得到了pair 然后通过pair能访问到key。
对于如何实现key不能被修改我感觉全文我已经赘述许多便了。
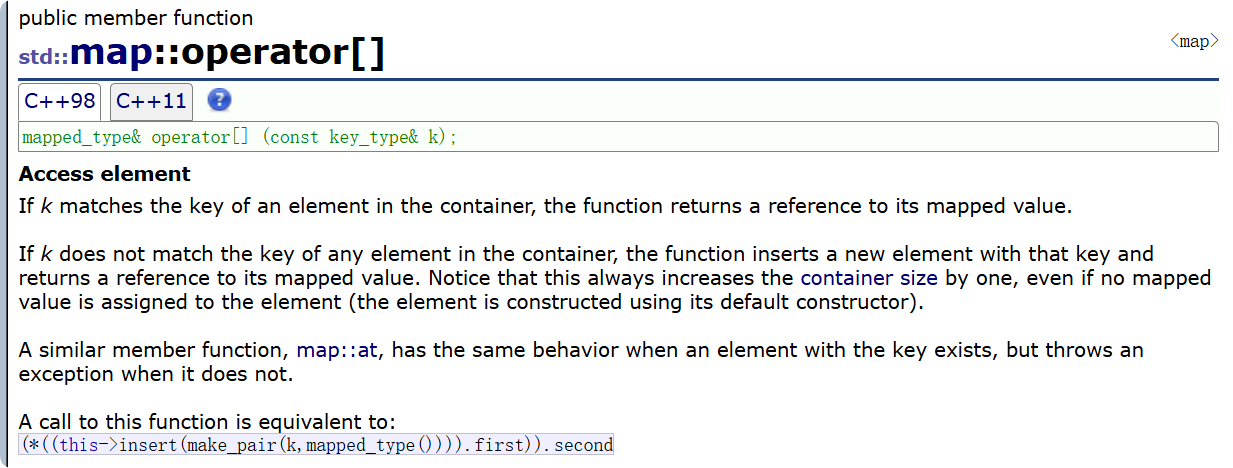
值得一提的是map通过方括号[key] 得到值这个方式它的原理,参考文档给了一个看起来很复杂的东西:
operator[]
(*((this->insert(make_pair(k,mapped_type()))).first)).second
看起来挺复杂其实一点也不简单哈哈哈,首先看里面 其实是调用了一层insert,this指针指向的是当前map的对象,调用了它的插入函数,最后拿它的返回值解引用得到了一个pair类型,说明这里返回的是一个迭代器类型, 如何访问pair的 second。
所以最好输出的是当前对象插入函数返回值的pair的second 那么它的类型我们可以知道 operator[] 返回值是Value 所以它也是Value
我们查看文档 最符合的就是下面这个:
大家把这个代码简化一下来理解 如下:



demo:
//map 一个小demo 统计水果出现的次数vector<string> v;v.push_back("西瓜");v.push_back("西瓜");v.push_back("西瓜");v.push_back("西瓜");v.push_back("哈密瓜");v.push_back("哈密瓜");v.push_back("哈密瓜");v.push_back("黄瓜");v.push_back("香蕉");map<string, int, Greater<string>> m;for (string s : v) {m[s]++;// 这里得到是 键对应的值的引用}for (auto t : m) {cout << t.first << " " << t.second<<endl;}

补充: 就是这里的一个at函数我觉得需要提一下,其实at是为了抛异常出现的,之前对于vector的实现我提到过,我们为了避免越界访问,对于vecotor 它没有越界抛异常的访问检测所以可能直接导致程序崩溃,所以用at来检测范围。
这里map也是一样的,但是map又不怕越界,你不存在我插入就行了嘛! 这是区别

三 . Modifiy 修改和Operations:
接下来的话题就是关于map,set的增删查,注意没有修改原因前文提到过.
简单来说: 插入呢其实对于底层是搜索树的他们,第一问题就是找到插入的位置,如何就是 插入元素。 删除: 我们用的少,但是它的逻辑上其实和删除是类似的。
3.1 insert 插入

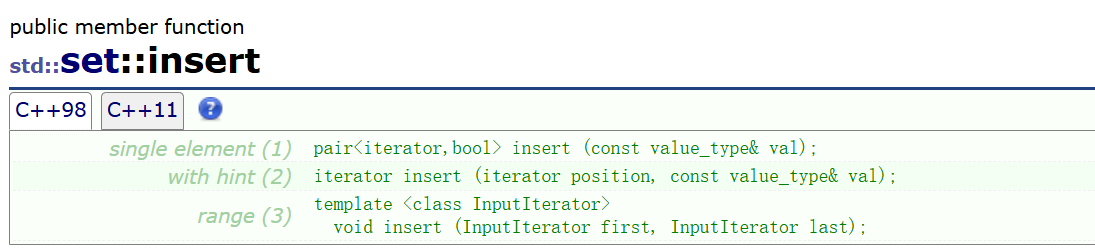
再提一嘴“C++的泛型编程和容器的思想实在是太优雅了”,对于stl的研究一直一来深刻感受其中的魅力,你如上观察这些插入函数,其实大多容器的插入都是类似的接口。 这就是优雅,可重用。
简单来说三种插入: 1. 插入单个元素: 给我返回pair<iterator,bool> 这个位置的迭代器以及插入的结果(bool)。
2. 然后就是 在值得的迭代器位置之后插入: 感觉这个有点鸡肋,对于搜索树当中,你要是想插入一个值有一定的规则 比如插入一个100,得到的100的迭代器,然后我现在又插入一个12,可是你也得去从根开始比较啊不然你会破坏规则,但是估计这是为了容器尽量一致性设计的吧。
3. 最好一种就是给定迭代器的范围插入: 这个其实很像我们之前使用的构造函数的迭代器范围插入。
demo:
void Modify_test() {vector<pair<string, int>> v;pair<string,int>p1 = make_pair("香蕉",4);pair<string,int>p2 = make_pair("苹果",5);pair<string,int>p3 = make_pair("西瓜",6);pair<string,int>p4 = make_pair("葡萄",10);v.push_back(p1);v.push_back(p2);v.push_back(p3);v.push_back(p4);map<string,int>m;m.insert(v.begin(),v.end());for (auto t : m) {cout << t.first << " " << t.second << endl;}} 输出结果: 
3.2 删除 erase
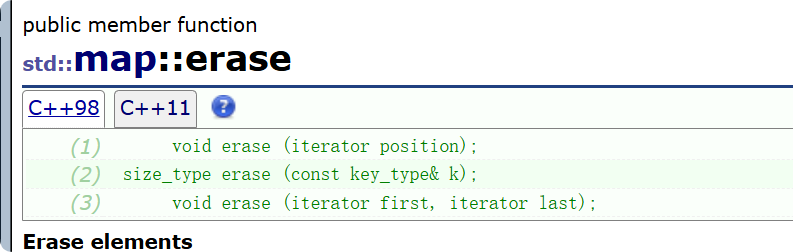

如上删除的逻辑其实根插入很类似: 第一步就是要找到删除的位置 ,然后就是让这棵树保持完整性。 删除也是三种:
1. 传入迭代器的然后删除这个位置的节点
2. 范围迭代器删除,其实这里肯定是根据中序来删的:
比如现在的中序之后是: 11,12,55,66,877
3. size_type erase(const value_type& val); 这个更像是为了统一stl,总之它传入你要删除的key然后删除这个位置的值 返回一个size_t 类型 标识个数: 这里的size_type 如下:

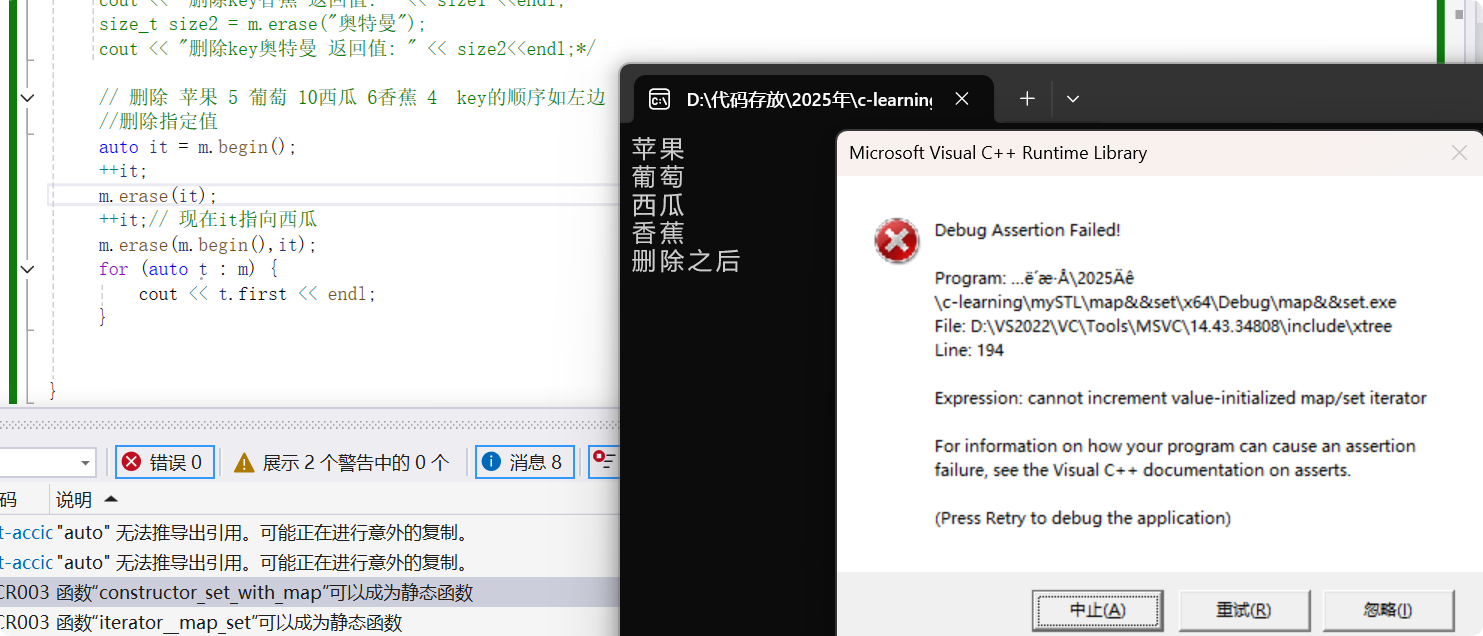
void Modify_test() {vector<pair<string, int>> v;pair<string,int>p1 = make_pair("香蕉",4);pair<string,int>p2 = make_pair("苹果",5);pair<string,int>p3 = make_pair("西瓜",6);pair<string,int>p4 = make_pair("葡萄",10);v.push_back(p1);v.push_back(p2);v.push_back(p3);v.push_back(p4);map<string,int>m;m.insert(v.begin(),v.end());for (auto t : m) {cout << t.first<< endl;}cout << "删除之后" << endl;/* size_t size1 = m.erase("香蕉");cout << "删除key香蕉 返回值: " << size1 <<endl;size_t size2 = m.erase("奥特曼");cout << "删除key奥特曼 返回值: " << size2<<endl;*/// 删除 苹果 5 葡萄 10西瓜 6香蕉 4 key的顺序如左边//删除指定值 auto it = m.begin();++it;++it;// 现在it指向西瓜m.erase(m.begin(),it);for (auto t : m) {cout << t.first << endl;}}
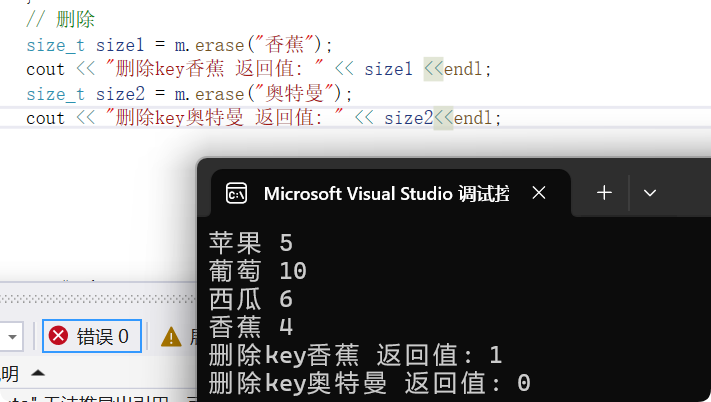
注意迭代器失效问题:
3.3 查找

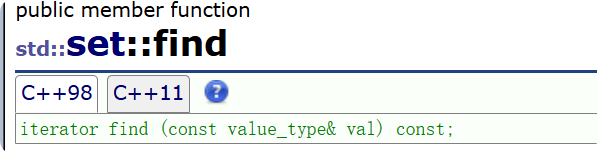
如果你细心会发现都是通过key来查找对应的节点位置然后用迭代器的形式返会给你,但是set凭什么至于一个类型的find啊,核心原因因为,set: const_iterator 和 iterator没什么区别,都是不能修改。
但是我的map需要修改值,对应的const的map是不能修改value的。map的key 什么情况都不能修改!
返回值 查找失败返回end(),这也符合stl统一行为
核心思想已经知道了使用吧: 如下demo: 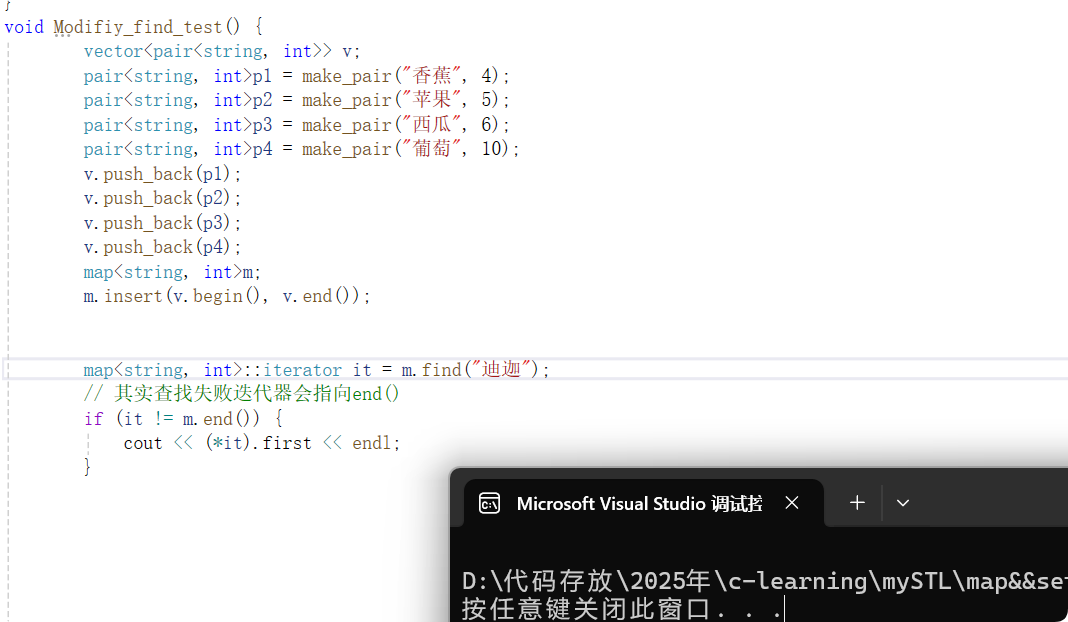
map和set总结
对map和set深刻理解呢,他们底层都是用红黑树,而且插入的条件呢不允许出现重复的key值而且遍历的结果是有序的这两个特性。
可以拿来去重,可以拿来排序这是他们很有特征的属性,以及他们是通过键值对隐射的,至于时间复杂度要看底层是谁,常用的红黑树能很好的保证: 增删查的效率都在稳定的O(log n)。
涉及到刚才说的map和set可以去重是因为我们在插入的时候,我们要求出现重复的时候不左处理,但是如果我们允许插入重复值呢,而且这样做的结果还能具有有序性呢,这样的使用场景有没有呢,有: 比如一个想统计大家的成绩呢而且想有序,那就允许重复了
所以有了 mult_set和mult_map
四. 拓展了解 mult_set 和mult_map
4.1、multiset:以 “班级成绩统计” 为例
场景:记录学生成绩(允许重复),需支持插入新成绩、删除无效成绩、统计分数出现次数、查询分数区间等操作。
1. 插入(insert)
multiset 的 insert 会自动按元素值(成绩)排序,且允许重复插入相同值。
demo代码:
void mult_test() {multiset<int> scores; // 存储成绩,自动按升序排序// 插入成绩(允许重复,插入后自动排序)scores.insert(85); // 插入单个元素scores.insert({ 90, 75, 90, 80 }); // 插入多个元素scores.insert(90); // 再次插入90(重复值)// 遍历所有成绩(已排序)cout << "所有成绩:";for (int s : scores) {cout << s << " "; // 输出:75 80 85 90 90 90}cout << endl;}输出:
![]()
2. 删除(erase)
multiset 的删除有两种常用方式:
- 删除所有等于某个值的元素(按值删除);
- 删除迭代器指向的单个元素(按位置删除)。 简单来说按照key来删除会把key对应的全部删除,而find(key) 会优先返回中序遍历中第一个key值的节点
如果你只是想删除单独某一个节点的话得按照迭代器来删除 通过find找到它的位置然后删除
demo代码:
void mult_test() {multiset<int> scores; // 存储成绩,自动按升序排序// 插入成绩(允许重复,插入后自动排序)scores.insert(85); // 插入单个元素scores.insert({ 90, 75, 90, 80 }); // 插入多个元素scores.insert(90); // 再次插入90(重复值)// 遍历所有成绩(已排序)cout << "所有成绩:";for (int s : scores) {cout << s << " "; // 输出:75 80 85 90 90 90}cout << endl;scores.insert({80,80,100});// 按照值删除全部90scores.erase(90);cout << "全部90被删" << endl;for (int s : scores) {cout << s << " "; // 输出:75 80 85 90 90 90}// 删第二个80multiset<int>::iterator it = scores.find(80); // 返回第一个80++it;cout << "删除第二个80" << endl;scores.erase(it);for (int s : scores) {cout << s << " "; // 输出:75 80 85 90 90 90}}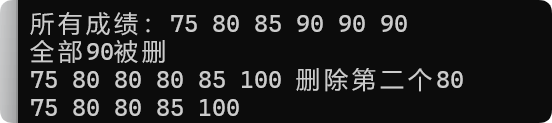
3. 查找与关键函数
(1)count(key):统计特定值的出现次数
场景:统计 85 分的人数。
demo:
int cnt_85 = scores.count(85);
cout << "85分的人数:" << cnt_85 << endl; // 输出:1(上面删除后剩余1个85)
(2)lower_bound(key):返回第一个 >=key 的元素迭代器
场景:查找 “不低于 80 分” 的第一个成绩。
demo:
auto it_low = scores.lower_bound(80);
if (it_low != scores.end()) {cout << "第一个不低于80分的成绩:" << *it_low << endl; // 输出:80
}
(3)upper_bound(key):返回第一个 >key 的元素迭代器
场景:查找 “高于 85 分” 的第一个成绩。
cpp
auto it_high = scores.upper_bound(85);
if (it_high != scores.end()) {cout << "第一个高于85分的成绩:" << *it_high << endl; // 输出:90
}
(4)equal_range(key):返回包含所有 **=key** 元素的范围(pair<iterator, iterator>)
场景:获取所有 90 分的成绩(迭代器范围)。
cpp
auto range = scores.equal_range(90);
cout << "所有90分的成绩:";
for (auto it = range.first; it != range.second; ++it) {cout << *it << " "; // 输出:90 90
}
cout << endl;
二、multimap:以 “课程 - 学生映射” 为例
场景:记录 “课程号 - 学生姓名” 的一对多关系(一门课有多个学生),需支持插入学生、删除退课学生、统计课程人数、查询某课程的所有学生等。
1. 插入(insert)
multimap 插入键值对(key=课程号,value=学生名),键可重复,插入后按键自动排序。
cpp
#include <map>
#include <string>
#include <iostream>
using namespace std;int main() {multimap<int, string> course_students; // key:课程号,value:学生名// 插入学生(同一课程号可重复插入)course_students.insert({101, "张三"}); // 课程101插入张三course_students.insert(make_pair(101, "李四")); // 课程101插入李四course_students.insert({102, "王五"}); // 课程102插入王五course_students.insert({101, "赵六"}); // 课程101插入赵六// 遍历所有课程(按课程号排序)cout << "所有课程及学生:";for (auto& [course, student] : course_students) {cout << "(" << course << "," << student << ") "; // 输出:(101,张三) (101,李四) (101,赵六) (102,王五)}cout << endl;return 0;
}
2. 删除(erase)
multimap 的删除方式与 multiset 类似:
- 按键删除:删除所有该键对应的键值对(如删除某门课程的所有学生);
- 按迭代器删除:删除单个键值对(如删除某课程的某个学生)。
cpp
// 接上面的代码
// 场景1:删除课程101的所有学生(整门课取消)
course_students.erase(101);
cout << "删除课程101后:";
for (auto& [c, s] : course_students) {cout << "(" << c << "," << s << ") "; // 输出:(102,王五)
}
cout << endl;// 重新插入课程101的学生,用于演示单个删除
course_students.insert({101, "张三"});
course_students.insert({101, "李四"});// 场景2:删除课程101中的“李四”(单个学生退课)
// 步骤:先找到课程101中“李四”的迭代器,再删除
auto it = course_students.find(101); // 找到课程101的第一个学生(张三)
while (it != course_students.end() && it->first == 101) {if (it->second == "李四") {course_students.erase(it); // 删除李四break;}++it;
}cout << "删除李四后课程101的学生:";
for (auto& [c, s] : course_students) {if (c == 101) cout << s << " "; // 输出:张三
}
cout << endl;
3. 查找与关键函数
(1)count(key):统计键对应的元素个数(如某课程的学生数)
cpp
int cnt_101 = course_students.count(101);
cout << "课程101的学生数:" << cnt_101 << endl; // 输出:1(只剩张三)
(2)lower_bound(key):返回第一个键≥key的键值对迭代器
场景:查找 “课程号不小于 101” 的第一个课程。
cpp
auto it_low = course_students.lower_bound(101);
if (it_low != course_students.end()) {cout << "第一个不小于101的课程及学生:" << "(" << it_low->first << "," << it_low->second << ")" << endl; // 输出:(101,张三)
}
(3)upper_bound(key):返回第一个键 > key的键值对迭代器
场景:查找 “课程号大于 101” 的第一个课程。
cpp
auto it_high = course_students.upper_bound(101);
if (it_high != course_students.end()) {cout << "第一个大于101的课程及学生:" << "(" << it_high->first << "," << it_high->second << ")" << endl; // 输出:(102,王五)
}
(4)equal_range(key):返回所有键 = key的键值对范围(最常用!)
场景:获取课程 101 的所有学生(无需遍历整个容器)。
cpp
auto range = course_students.equal_range(101);
cout << "课程101的所有学生:";
for (auto it = range.first; it != range.second; ++it) {cout << it->second << " "; // 输出:张三
}
cout << endl;
总结
multiset 和 multimap 的核心价值在于 “有序存储重复键”,配合以下函数可高效处理重复数据:
insert:插入元素 / 键值对(自动排序,允许重复);erase:按值 / 键或迭代器删除(灵活处理单个或所有重复项);count:快速统计重复键的数量;lower_bound/upper_bound:定位范围边界(如 “≥x”“>x”);equal_range:直接获取所有相同键的元素范围(最适合批量处理重复键)。
这些接口在 “统计重复数据”“一对多关系管理” 等场景中能极大简化代码.