灵巧手——Task-Oriented Hand Motion Retargeting for Dexterous Manipulation Imitation
Task-Oriented Hand Motion Retargeting for Dexterous Manipulation Imitation
- 论文解读
-
- 摘要
- 主要内容概述
-
- 1. 研究背景与挑战
- 2. 方法框架
- 3. 混合PSO重定向方法
- 4. 实验与结果
- 5. 结论与展望
- 代码解读
-
- 轨迹优化
-
- 代码
- 详解
-
- 概览
- 主要模块和依赖
- 主要函数与流程
- 关键变量/设计要点
- 如何运行(示例)
- 注意事项与调试建议
- 轨迹回放
-
- 代码
- 详解
-
- 概述
- 依赖(重要)
- 命令行参数(argsparser)
- 辅助函数
- 关键功能:replay_frame(sim, frame, data)
- 关键功能:play(model_path, data, fps=60, loop=False, second_data=None)
- 主流程:main(args)
- 数据格式假设(.npz)
- 注意 / 潜在问题 / 可改进点
- 示例用法
- 数据(`.npz`)
-
- .npz 文件是什么
- 数据生成流程
- 关键步骤关联
- 包含的内容
- 本地查看 .npz(推荐做法)
project
paper(2018)
更详细的介绍和使用方法,参考原论文及githua代码
论文解读
摘要
人类的手部动作相当复杂,尤其是在涉及物体操作时,这主要是由于手部的高维度以及由此带来的巨大动作空间所致。用灵巧的手部模型模仿这些动作涉及不同的重要且具有挑战性的步骤:获取人类手部信息、将其重新定位到手部模型上以及从获取的数据中学习策略。在这项工作中,我们通过使用最先进的手部姿态估计器来捕获手部信息。我们通过结合逆运动学和粒子群优化(PSO)以及任务目标优化来解决从手部姿态到 29 自由度手部模型的重新定位问题。该目标鼓励虚拟手完成操作任务,减轻了估计器噪声和领域差距的影响。与我们的逆运动学基线相比,我们的方法在抓取任务中取得了更高的成功率,使我们能够记录成功的演示。此外,我们使用这些演示通过生成对抗模仿学习(GAIL)来学习策略网络,该网络能够在虚拟空间中自主抓取物体。
这篇论文《Task-Oriented Hand Motion Retargeting for Dexterous Manipulation Imitation》由Dafni Antotsiou等人提出,旨在解决模仿人类手部动作(尤其是涉及物体操作的复杂任务)中的核心挑战。其主要贡献是开发了一个结合任务目标优化的运动重定向框架,以提高在虚拟环境中使用高自由度拟人手模型进行抓取等操作的成功率。
主要内容概述
1. 研究背景与挑战
- 目标:模仿人类手部灵巧操作任务(如抓取),使用29自由度的拟人手模型。
- 核心挑战:
- 运动重定向(Retargeting):将从真实世界捕获的人手姿态映射到虚拟手模型的困难,包括:
- 人手与模型之间的运动学差异。
- 手部姿态估计器(HPE)因遮挡、噪声和未知视角导致的输出不准确。
- 任务成功率:即使微小误差也可能导致抓取失败。
- 运动重定向(Retargeting):将从真实世界捕获的人手姿态映射到虚拟手模型的困难,包括:
2. 方法框架
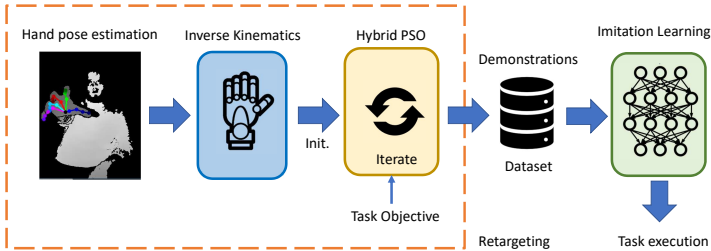
论文提出一个完整流程(如图所示):
- 输入:使用基于
深度相机的HPE(hand pose estimation)提取人手的21个关节点3D骨架。 - 重定向:通过
混合粒子群优化(Hybrid PSO) 方法将HPE输出映射到29自由度的虚拟手模型(基于MuJoCo的MPL模型)。 - 模仿学习:用重定向后的成功演示数据训练
生成对抗模仿学习(GAIL) 策略网络,使虚拟手能自主抓取物体。
3. 混合PSO重定向方法
-
基础:结合逆运动学(IK) 和粒子群优化(PSO)。
- IK初始化:快速近似人手姿态。
- PSO优化:在IK基础上微调,以提升任务性能。
-
优化目标函数:
Etotal = ωposeEpose + ωtaskEtask -
姿态能量(Epose):最小化HPE骨架与虚拟手关节点位置(Ep)和角度(Ea)的差异(见图3)。
-
任务能量(Etask):鼓励虚拟手与物体交互(见图4),最小化手掌和指尖(共6个点)到物体表面的距离。
-
优势:
- 通过任务目标补偿HPE噪声和域差异。
- 可高频运行(独立于HPE帧率),实现实时微调。
4. 实验与结果
-
重定向泛化测试(仅用Epose):表明需平衡位置和角度项权重(见图5),否则可能导致姿态错误。
-
混合PSO抓取测试:
- 定性结果(见图6):相比IK基线,Hybrid PSO能显著改善抓取接触。
- 定量结果(见图7):在“关注序列”(手可抓取物体的帧)中,Hybrid PSO(即使少量迭代/粒子)显著提升物体悬空帧比例(最高达80%),且任务权重ωtask=0.8时最优。
-
模仿学习测试:
- 使用161条成功演示训练GAIL网络。
- 结果(见图8):策略在已知初始状态下成功率高,但对噪声敏感,泛化能力有限(高维度策略学习的常见问题)。
5. 结论与展望
贡献:Hybrid PSO通过任务优化提升了抓取鲁棒性,为从噪声HPE数据学习灵巧操作提供了可行管道。
未来方向:包括探索新任务、利用手部层次结构、端到端任务学习,以及结合真实手部操作数据提升运动自然性。
关键词
手部姿态估计、运动重定向、粒子群优化、拟人手模型、模仿学习、GAIL。
代码解读
轨迹优化
对“trajectories”目录下的一组轨迹应用面向任务的优化,运行如下命令:
python3 optimise_trajectories.py --traj_path trajectories
代码
参考论文github:
optimise_trajectories.py
__author__ = 'DafniAntotsiou'import os
from pso import pso, particle2actuator
from functions import *
import mujoco_py as mp
from math import ceil
from mjviewerext import MjViewerExt
import glob
import argparse
from replay_trajectories import playdef argsparser():parser = argparse.ArgumentParser("Implementation of Task Oriented Hand Motion Retargeting")parser.add_argument('--model_path', help='path to model xml', type=str, default="model/MPL/MPL_Sphere_6.xml")parser.add_argument('--traj_path', help='path to the trajectory file or directory', default='trajectories')parser.add_argument('--out_dir', help='directory to save the output results', default='trajectories/result')parser.add_argument('--seed', help='RNG seed', type=int, default=0)boolean_flag(parser, 'play', default=False, help='playback the original and optimised trajectories')boolean_flag(parser, 'rot_scene', default=True, help='set if scene was rotated during HPE acquisition')return parser.parse_args()def boolean_flag(parser, name, default=False, help=None):""" This function is from OpenAI's baselines.Add a boolean flag to argparse parser.Parameters----------parser: argparse.Parserparser to add the flag toname: str--<name> will enable the flag, while --no-<name> will disable itdefault: bool or Nonedefault value of the flaghelp: strhelp string for the flag"""dest = name.replace('-', '_')parser.add_argument("--" + name, action="store_true", default=default, dest=dest, help=help)parser.add_argument("--no-" + name, action="store_false", dest=dest)def optimise_actions(model_path, traj_path, rot_scene=False, fps=60, render=False, name=None, replay=False):per_hpe = False # apply pso only on new hpe frame regardless of simulation fpsdata = read_npz(traj_path)iterations = [100]swarms = [100]c_tasks = [0.8]c_angles = [0.5]for it in iterations:for swarmsize in swarms:for c_task in c_tasks:for c_a in c_angles:trajectory = {'obs': [], 'acs': [], 'hpe': []}assert 'hpe' in data and 'obs' in data and 'acs' in dataif 'hpe' in data and 'obs' in data and 'acs' in data:model = mp.load_model_from_path(model_path)nsubstep = int(ceil(1/(fps * model.opt.timestep)))sim = mp.MjSim(model, nsubsteps=nsubstep)sim.reset()if render:viewer = MjViewerExt(sim)# initialise environmentidvA, default_q = get_model_info(model)default_mat = array([[-1, 0, 0], [0, -1, 0], [0, 0, 1]])default_q2 = rotmat2quat(default_mat)default_q = default_q2 * default_qinit_pos = array([0, -0.8, 0.1])m_in = np.zeros(shape=(5, 3))for i in range