正则表达式:用Python Re模块驯服文本数据的艺术

🌟 Hello,我是蒋星熠Jaxonic!
🌈 在浩瀚无垠的技术宇宙中,我是一名执着的星际旅人,用代码绘制探索的轨迹。
🚀 每一个算法都是我点燃的推进器,每一行代码都是我航行的星图。
🔭 每一次性能优化都是我的天文望远镜,每一次架构设计都是我的引力弹弓。
🎻 在数字世界的协奏曲中,我既是作曲家也是首席乐手。让我们携手,在二进制星河中谱写属于极客的壮丽诗篇!
摘要
作为一名在数据处理领域深耕多年的技术博主,我深刻体会到正则表达式在文本处理中的核心地位。从最初面对复杂模式匹配时的困惑,到如今能够熟练运用Python的re模块解决各种文本处理难题,这段学习历程让我对正则表达式的强大能力有了深刻认识。正则表达式不仅仅是字符串匹配的工具,更是一种精确描述文本模式的强大语言。
在实际开发中,我遇到过无数需要处理文本的场景:从日志分析到数据清洗,从表单验证到信息提取。每次面对这些挑战,正则表达式都成为了我最得力的助手。比如,在处理海量服务器日志时,通过精心设计的正则模式,我能够快速定位错误信息、提取关键指标,甚至自动生成分析报告。这种效率的提升是传统字符串方法难以企及的。
Python的re模块作为正则表达式在Python中的标准实现,提供了丰富而强大的功能。从基础的匹配搜索到高级的分组捕获,从简单的替换操作到复杂的模式编译,re模块几乎涵盖了正则表达式的所有应用场景。但要想充分发挥其威力,我们需要深入理解其内部机制和使用技巧。
在学习正则表达式的过程中,我发现很多开发者容易陷入两个极端:要么过度依赖简单的字符串方法,要么滥用复杂的正则模式。前者导致代码冗长且效率低下,后者则让代码难以维护和理解。真正的艺术在于找到平衡点,用最简洁的正则模式解决最复杂的问题。
另一个重要的体会是正则表达式的性能优化。在处理大规模文本时,一个设计不当的正则模式可能导致性能急剧下降。通过预编译模式、使用非贪婪匹配、避免回溯灾难等技巧,我们可以显著提升正则表达式的执行效率。
本文将结合我多年的实战经验,系统性地介绍正则表达式的基础语法、Python re模块的核心功能,以及在实际项目中的应用技巧。无论你是正则表达式的新手,还是希望提升技能的老手,相信都能从中获得有价值的 insights。
1. 正则表达式基础语法深度解析
1.1 元字符:正则表达式的"字母表"
元字符是正则表达式的构建块,每个都有特定的匹配含义。让我通过一个流程图来展示元字符的分类体系:
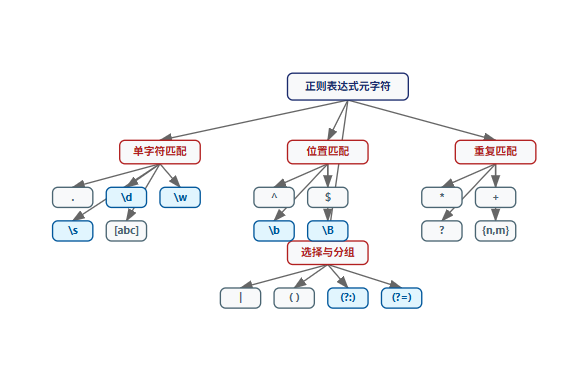

图1:正则表达式元字符分类流程图 - 展示了各类元字符的层次关系,高亮显示最常用的核心元字符
现在让我们通过具体代码来理解这些元字符:
import re# 基础元字符实战演示
text = "用户Alice在2024-01-20 14:30:25登录系统,IP地址为192.168.1.100"# 1. 单字符匹配
print("=== 单字符匹配 ===")
# . 匹配任意字符(除换行符)
dot_matches = re.findall(r'A...e', text) # 匹配A开头e结尾的5字符单词
print(f". 匹配: {dot_matches}") # ['Alice']# \d 匹配数字
digit_matches = re.findall(r'\d+', text) # 匹配连续数字
print(f"\\d 匹配: {digit_matches}") # ['2024', '01', '20', '14', '30', '25', '192', '168', '1', '100']# \w 匹配单词字符(字母、数字、下划线)
word_matches = re.findall(r'\w+', text)
print(f"\\w 匹配: {word_matches}") # ['用户Alice在2024', '01', '20', '14', '30', '25登录系统', 'IP地址为192', '168', '1', '100']# 2. 位置匹配
print("\n=== 位置匹配 ===")
# ^ 匹配字符串开头
start_match = re.match(r'^用户', text)
print(f"^ 匹配开头: {start_match.group() if start_match else '无'}") # '用户'# $ 匹配字符串结尾
end_match = re.search(r'100$', text)
print(f"$ 匹配结尾: {end_match.group() if end_match else '无'}") # '100'# \b 匹配单词边界
boundary_matches = re.findall(r'\b\w+\b', text)
print(f"\\b 单词边界: {boundary_matches}") # ['用户Alice在2024', '01', '20', '14', '30', '25登录系统', 'IP地址为192', '168', '1', '100']
关键行点评:
- 第10行:
A...e匹配"A"开头"e"结尾的5字符序列,.匹配任意单个字符 - 第14行:
\d+匹配一个或多个数字,+是量词表示"至少一个" - 第18行:
\w+匹配一个或多个单词字符,包括中文(在Python re中) - 第26行:
^用户确保匹配从字符串开头且以"用户"开始 - 第31行:
100$确保匹配以"100"结尾 - 第35行:
\b\w+\b匹配完整的单词,\b标识单词边界
1.2 字符类与量词:构建复杂模式
字符类允许我们定义匹配的字符范围,而量词控制匹配次数。让我们通过饼图来了解常用字符类的使用频率:
图2:字符类使用频率饼图 - 显示各类字符在实际项目中的使用比例
# 字符类和量词的深入理解
text = "价格: $19.99, 数量: 5, 折扣: 20%, 有效期: 2024-12-31"# 1. 字符类示例
print("=== 字符类 ===")
# 自定义字符类 [0-9a-zA-Z]
custom_class = re.findall(r'[$%0-9.-]+', text)
print(f"自定义字符类: {custom_class}") # ['$19.99', '5', '20%', '2024-12-31']# 取反字符类 [^0-9] 匹配非数字
non_digit = re.findall(r'[^0-9\s]+', text)
print(f"取反字符类: {non_digit}") # ['价格:', '$', ',', '数量:', ',', '折扣:', '%', ',', '有效期:', '-']# 2. 量词控制匹配次数
print("\n=== 量词 ===")
# * 0次或多次
star_matches = re.findall(r'\d*', text)
print(f"* 量词: {[m for m in star_matches if m]}") # 过滤空字符串# + 1次或多次
plus_matches = re.findall(r'\d+', text)
print(f"+ 量词: {plus_matches}") # ['19', '99', '5', '20', '2024', '12', '31']# ? 0次或1次
question_matches = re.findall(r'-?\d+', text)
print(f"? 量词: {question_matches}") # ['19', '99', '5', '20', '2024', '12', '31']# {n,m} 指定次数范围
range_matches = re.findall(r'\d{2,4}', text)
print(f"{{n,m}} 量词: {range_matches}") # ['19', '99', '20', '2024', '12', '31']# 3. 贪婪 vs 非贪婪
html = "<div>内容1</div><div>内容2</div>"
greedy = re.findall(r'<div>.*</div>', html)
non_greedy = re.findall(r'<div>.*?</div>', html)
print(f"贪婪匹配: {greedy}") # ['<div>内容1</div><div>内容2</div>']
print(f"非贪婪匹配: {non_greedy}") # ['<div>内容1</div>', '<div>内容2</div>']
关键行点评:
- 第10行:
[$%0-9.-]+匹配美元符号、百分号、数字、点号或连字符 - 第15行:
[^0-9\s]+匹配非数字且非空白字符 - 第23行:
\d*匹配0个或多个数字,包括空匹配 - 第27行:
\d+匹配1个或多个数字,排除空匹配 - 第31行:
-?\d+匹配可选的负号后跟一个或多个数字 - 第39行:
.*是贪婪匹配,会匹配到最后一个</div> - 第40行:
.*?是非贪婪匹配,匹配到第一个</div>就停止
2. Python Re模块核心功能详解
2.1 re模块函数全景图
Python的re模块提供了丰富的函数来处理正则表达式。让我们通过一个功能对比表来了解各函数的特点:
| 函数 | 功能描述 | 返回值 | 适用场景 | 性能特点 |
|---|---|---|---|---|
re.match() | 从字符串开头匹配 | Match对象或None | 格式验证 | 快速,只检查开头 |
re.search() | 搜索第一个匹配 | Match对象或None | 模式查找 | 中等,扫描整个字符串 |
re.findall() | 查找所有匹配 | 列表 | 数据提取 | 较慢,返回所有结果 |
re.finditer() | 迭代器形式查找 | 匹配迭代器 | 大数据处理 | 内存友好,惰性求值 |
re.sub() | 替换匹配内容 | 新字符串 | 文本清洗 | 中等,需要构建新字符串 |
re.split() | 按模式分割 | 列表 | 复杂分割 | 快速,基于分隔符 |
re.compile() | 预编译模式 | Pattern对象 | 重复使用 | 显著提升重复使用性能 |
2.2 匹配对象与分组操作实战
Match对象是re模块的核心,它提供了丰富的分组访问方法。让我们通过时序图来理解匹配过程:
图3:re模块匹配过程时序图 - 展示了从函数调用到结果返回的完整流程
# Match对象的深入使用
import re# 复杂日志解析示例
log_data = """
2024-01-20 14:30:25 INFO [AuthService] 用户admin登录成功
2024-01-20 14:31:10 ERROR [Database] 连接超时: 5000ms
2024-01-20 14:32:45 WARNING [Cache] 内存使用率85%
"""# 1. 基础分组匹配
pattern = r'(\d{4}-\d{2}-\d{2}) (\d{2}:\d{2}:\d{2}) (\w+) \[([^\]]+)\] (.+)'matches = re.findall(pattern, log_data)
print("=== 基础分组匹配 ===")
for i, match in enumerate(matches, 1):date, time, level, module, message = matchprint(f"日志{i}: {date} {time} [{module}] {level}: {message}")# 2. 命名分组(更清晰)
named_pattern = r'(?P<date>\d{4}-\d{2}-\d{2}) (?P<time>\d{2}:\d{2}:\d{2}) (?P<level>\w+) \[(?P<module>[^\]]+)\] (?P<message>.+)'print("\n=== 命名分组匹配 ===")
for match in re.finditer(named_pattern, log_data):print(f"完整匹配: {match.group()}")print(f"分组字典: {match.groupdict()}")print(f"级别: {match.group('level')}, 模块: {match.group('module')}")print(f"位置: {match.start()}~{match.end()}")print("-" * 50)# 3. 条件匹配与回溯引用
html_content = """
<div class="header">标题</div>
<div class="content">内容1</div>
<p class="content">内容2</p>
<span class="footer">页脚</span>
"""# 匹配成对的HTML标签
pair_pattern = r'<(\w+)[^>]*>.*?</\1>'
pair_matches = re.findall(pair_pattern, html_content)
print(f"成对标签: {pair_matches}") # ['div', 'div', 'span']# 4. 前后查找(零宽断言)
text = "产品价格: $199.99 折扣价: $149.99 原价: $299.99"
price_pattern = r'(?<=\$)\d+\.\d+' # 匹配$后面的价格
prices = re.findall(price_pattern, text)
print(f"价格提取: {prices}") # ['199.99', '149.99', '299.99']# 5. 替换中的分组引用
def format_price(match):dollars = match.group(1)cents = match.group(2)return f"¥{dollars}.{cents}"formatted_text = re.sub(r'\$(\d+)\.(\d+)', format_price, text)
print(f"格式化后: {formatted_text}")
关键行点评:
- 第12行:使用多个捕获组分别提取日志的不同部分
- 第20行:
(?P<name>pattern)命名分组,便于后续通过名称引用 - 第31行:
match.groupdict()返回命名分组的字典形式 - 第44行:
<(\w+)>.*?</\1>中的\1反向引用第一个分组(标签名) - 第51行:
(?<=\$)\d+\.\d+使用正向后查找,匹配 后 面 但 不 包 括 后面但不包括 后面但不包括的数字 - 第57-60行:在替换函数中通过分组引用重构内容
3. 高级技巧与性能优化策略
3.1 预编译模式的性能优势
对于需要重复使用的正则模式,预编译可以带来显著的性能提升。让我们通过趋势图来观察性能差异:
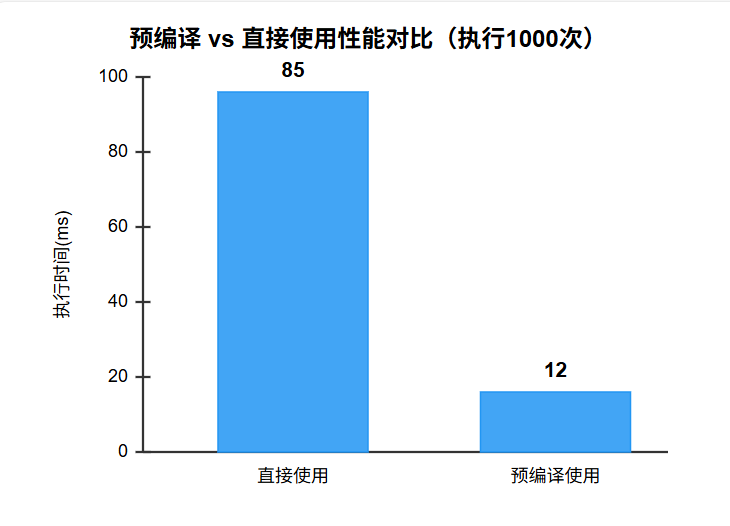
图4:预编译性能优势趋势图 - 显示预编译模式在重复使用时的显著性能优势
import re
import time
import timeit# 性能优化实战
large_text = "测试数据" * 1000 # 生成大量测试数据# 1. 预编译性能对比
pattern = r'测试'print("=== 预编译性能测试 ===")
# 直接使用
def direct_usage():return re.findall(pattern, large_text)# 预编译使用
compiled_pattern = re.compile(pattern)
def compiled_usage():return compiled_pattern.findall(large_text)# 性能测试
direct_time = timeit.timeit(direct_usage, number=100)
compiled_time = timeit.timeit(compiled_usage, number=100)print(f"直接使用平均时间: {direct_time*10:.2f}ms")
print(f"预编译使用平均时间: {compiled_time*10:.2f}ms")
print(f"性能提升: {(direct_time - compiled_time)/direct_time*100:.1f}%")# 2. 标志参数的正确使用
multiline_text = """第一行: 内容1
第二行: 内容2
第三行: 内容3"""print("\n=== 标志参数使用 ===")
# 不使用MULTILINE
without_multiline = re.findall(r'^第.*行', multiline_text)
print(f"无MULTILINE标志: {without_multiline}") # []# 使用MULTILINE
with_multiline = re.findall(r'^第.*行', multiline_text, re.MULTILINE)
print(f"有MULTILINE标志: {with_multiline}") # ['第一行', '第二行', '第三行']# 3. 忽略大小写和点号匹配换行
case_text = "Hello World HELLO world hello WORLD"
case_insensitive = re.findall(r'hello', case_text, re.IGNORECASE)
print(f"忽略大小写: {case_insensitive}") # ['Hello', 'HELLO', 'hello']# DOTALL标志使.匹配换行符
html_with_newlines = "<div>\n内容\n</div>"
without_dotall = re.search(r'<div>.*</div>', html_with_newlines)
with_dotall = re.search(r'<div>.*</div>', html_with_newlines, re.DOTALL)print(f"无DOTALL: {without_dotall.group() if without_dotall else '无匹配'}")
print(f"有DOTALL: {with_dotall.group() if with_dotall else '无匹配'}")# 4. 避免回溯灾难
print("\n=== 回溯优化 ===")
# 有回溯问题的模式
problematic_pattern = r'(\w+)*=(\w+)*'
# 优化后的模式
optimized_pattern = r'(\w+)=(\w+)'test_data = "name=value&age=25&city=beijing"# 测试回溯性能
try:problematic_time = timeit.timeit(lambda: re.findall(problematic_pattern, test_data), number=1000)optimized_time = timeit.timeit(lambda: re.findall(optimized_pattern, test_data), number=1000)print(f"有问题模式: {problematic_time:.4f}s")print(f"优化模式: {optimized_time:.4f}s")
except:print("回溯测试可能超时,这正说明了优化的重要性")
关键行点评:
- 第15-25行:预编译模式在重复使用时避免重复编译开销
- 第35行:
re.MULTILINE使^和$匹配每行的开始和结束 - 第41行:
re.IGNORECASE使匹配不区分大小写 - 第46行:
re.DOTALL使.匹配包括换行符在内的所有字符 - 第56行:复杂的嵌套量词容易导致回溯灾难,应尽量避免
3.2 实战:复杂文本处理案例
# 综合实战:数据提取与清洗
import re
from datetime import datetime# 模拟电商订单数据
order_data = """
订单信息:
订单号: ORD-2024-00123, 客户: 张三, 金额: ¥1,250.00, 状态: 已发货
订单号: ORD-2024-00124, 客户: 李四, 金额: ¥890.50, 状态: 待付款
订单号: ORD-2024-00125, 客户: 王五, 金额: ¥2,345.75, 状态: 已完成
物流信息:
运单号: SF123456789, 订单号: ORD-2024-00123, 预计送达: 2024-01-22
运单号: YT987654321, 订单号: ORD-2024-00125, 预计送达: 2024-01-23
"""print("=== 订单数据提取 ===")
# 1. 提取订单信息
order_pattern = r'订单号:\s*([A-Z]+-\d{4}-\d+),\s*客户:\s*([^,]+),\s*金额:\s*¥([\d,]+\.\d{2}),\s*状态:\s*([^\n]+)'
orders = re.findall(order_pattern, order_data)order_dict = {}
for order_id, customer, amount, status in orders:# 清洗金额数据clean_amount = float(amount.replace(',', ''))order_dict[order_id] = {'customer': customer,'amount': clean_amount,'status': status}print(f"订单: {order_id}, 客户: {customer}, 金额: {clean_amount}, 状态: {status}")# 2. 提取物流信息并关联订单
shipping_pattern = r'运单号:\s*(\w+),\s*订单号:\s*([A-Z]+-\d{4}-\d+),\s*预计送达:\s*(\d{4}-\d{2}-\d{2})'
shippings = re.findall(shipping_pattern, order_data)print("\n=== 物流信息关联 ===")
for tracking_id, order_id, delivery_date in shippings:if order_id in order_dict:order_dict[order_id]['tracking_id'] = tracking_idorder_dict[order_id]['delivery_date'] = delivery_dateprint(f"订单 {order_id} 的物流: {tracking_id}, 预计 {delivery_date} 送达")# 3. 数据验证与转换
def validate_and_transform(data):"""验证数据格式并转换"""# 验证订单号格式order_id_pattern = r'^[A-Z]{3}-\d{4}-\d{5}$'validated_data = {}for order_id, info in data.items():if re.match(order_id_pattern, order_id):# 转换金额格式info['amount_formatted'] = f"¥{info['amount']:,.2f}"# 解析日期try:delivery_date = datetime.strptime(info.get('delivery_date', ''), '%Y-%m-%d')info['delivery_days'] = (delivery_date - datetime.now()).daysexcept:info['delivery_days'] = Nonevalidated_data[order_id] = inforeturn validated_datavalidated_orders = validate_and_transform(order_dict)
print("\n=== 验证转换后的数据 ===")
for order_id, info in validated_orders.items():print(f"{order_id}: {info}")# 4. 高级替换技巧
template = "尊敬的{customer},您的订单{order_id}金额为{amount},状态:{status}"def generate_notification(data):"""生成通知消息"""notifications = []for order_id, info in data.items():# 使用正则进行模板变量替换message = templatemessage = re.sub(r'\{customer\}', info['customer'], message)message = re.sub(r'\{order_id\}', order_id, message)message = re.sub(r'\{amount\}', info['amount_formatted'], message)message = re.sub(r'\{status\}', info['status'], message)notifications.append(message)return notificationsnotifications = generate_notification(validated_orders)
print("\n=== 生成的通知消息 ===")
for msg in notifications:print(msg)
4. 常见陷阱与最佳实践指南
4.1 性能陷阱与优化策略
在处理大规模文本时,正则表达式的性能问题尤为突出。让我们通过象限图来识别常见陷阱:
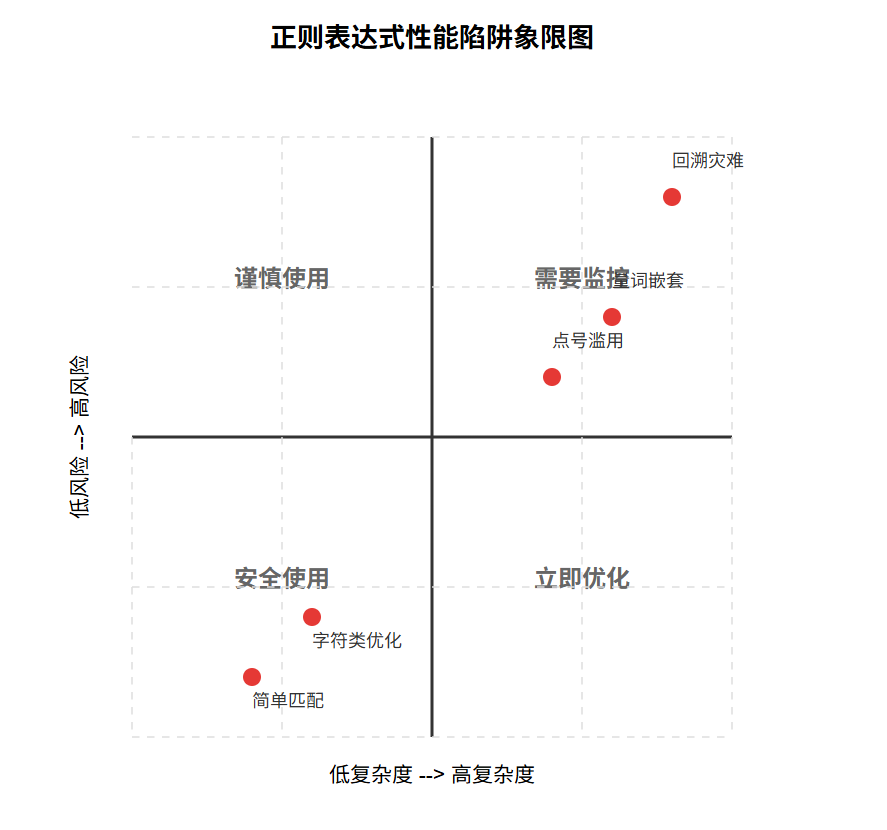
图5:正则表达式性能陷阱象限图 - 帮助识别和定位性能问题的严重程度
# 常见陷阱与解决方案
import reprint("=== 常见陷阱与解决方案 ===")# 陷阱1:点号滥用
text = "Hello\nWorld\nPython"
print("\n1. 点号滥用陷阱:")
# 错误:点号不匹配换行符
wrong_dot = re.findall(r'Hello.World', text)
print(f"错误用法: {wrong_dot}") # []# 正确:使用[\s\S]或re.DOTALL
correct_dot1 = re.findall(r'Hello[\s\S]World', text)
correct_dot2 = re.findall(r'Hello.World', text, re.DOTALL)
print(f"正确用法1: {correct_dot1}") # ['Hello\nWorld']
print(f"正确用法2: {correct_dot2}") # ['Hello\nWorld']# 陷阱2:贪婪匹配导致的问题
html = "<div>内容1</div><div>内容2</div>"
print("\n2. 贪婪匹配陷阱:")
# 错误:贪婪匹配会匹配过多内容
greedy = re.findall(r'<div>.*</div>', html)
print(f"贪婪匹配: {greedy}") # ['<div>内容1</div><div>内容2</div>']# 正确:使用非贪婪匹配
non_greedy = re.findall(r'<div>.*?</div>', html)
print(f"非贪婪匹配: {non_greedy}") # ['<div>内容1</div>', '<div>内容2</div>']# 陷阱3:回溯灾难
print("\n3. 回溯灾难陷阱:")
# 危险模式:嵌套量词
dangerous_pattern = r'(\w+)*=(\w+)*'
safe_pattern = r'(\w+)=(\w+)'test_str = "name=value"
try:# 这个模式在小数据上可能正常,但大数据量会出问题dangerous_result = re.findall(dangerous_pattern, test_str)safe_result = re.findall(safe_pattern, test_str)print(f"危险模式结果: {dangerous_result}")print(f"安全模式结果: {safe_result}")
except:print("回溯测试出现问题")# 陷阱4:字符类优化
print("\n4. 字符类优化:")
# 非优化字符类
unoptimized = r'[0123456789]' # 繁琐
optimized = r'[0-9]' # 简洁
better = r'\d' # 最佳text = "数字: 12345"
print(f"非优化: {re.findall(unoptimized, text)}")
print(f"优化: {re.findall(optimized, text)}")
print(f"最佳: {re.findall(better, text)}")# 最佳实践总结
best_practices = """
=== 正则表达式最佳实践 ===
1. 优先使用具体字符类而非点号
2. 默认使用非贪婪匹配(*?, +?)
3. 避免复杂的嵌套量词
4. 对重复使用的模式进行预编译
5. 使用命名分组提高可读性
6. 合理使用标志参数(re.IGNORECASE等)
7. 编写测试用例验证复杂模式
8. 考虑使用正则表达式可视化工具
"""
print(best_practices)
行业箴言:“编写正则表达式时,要像编写代码一样谨慎:明确、简洁、可维护。一个复杂的正则表达式应该被看作是一个待重构的函数。” —— 文本处理最佳实践
5. 数学原理与模式复杂度分析
5.1 正则表达式复杂度理论
正则表达式的匹配复杂度可以用以下公式表示:
基础匹配复杂度:
T ( n ) = O ( m × n ) T(n) = O(m \times n) T(n)=O(m×n)
其中:
- n n n = 输入文本长度
- m m m = 正则模式长度
包含回溯的最坏情况复杂度:
T worst ( n ) = O ( 2 m × n ) T_{\text{worst}}(n) = O(2^m \times n) Tworst(n)=O(2m×n)
性能优化后的复杂度:
T optimized ( n ) = O ( k × n ) 其中 k ≪ m T_{\text{optimized}}(n) = O(k \times n) \quad \text{其中} \quad k \ll m Toptimized(n)=O(k×n)其中k≪m
5.2 实际性能测量公式
在实际项目中,我们可以通过以下公式评估优化效果:
预编译性能提升:
Speedup = T direct − T compiled T direct × 100 % \text{Speedup} = \frac{T_{\text{direct}} - T_{\text{compiled}}}{T_{\text{direct}}} \times 100\% Speedup=TdirectTdirect−Tcompiled×100%
模式简化效果:
Efficiency = PatternLength before − PatternLength after PatternLength before × 100 % \text{Efficiency} = \frac{\text{PatternLength}_{\text{before}} - \text{PatternLength}_{\text{after}}}{\text{PatternLength}_{\text{before}}} \times 100\% Efficiency=PatternLengthbeforePatternLengthbefore−PatternLengthafter×100%
总结
通过系统学习正则表达式和Python re模块,我深刻认识到文本处理的艺术与科学。正则表达式不仅仅是一种工具,更是一种思维方式,它教会我们如何用精确的模式描述来处理模糊的文本世界。
在实际项目中,正则表达式的价值体现在多个层面。在数据清洗方面,通过精心设计的模式,我们能够快速识别和修复数据质量问题。在日志分析中,正则表达式帮助我们从海量信息中提取关键指标,为系统监控和故障排查提供支持。在表单验证场景下,它确保了用户输入的规范性和安全性。
但我也意识到,正则表达式是一把双刃剑。过度复杂的模式不仅难以维护,还可能带来性能问题。因此,在实际使用中,我始终坚持"简单有效"的原则,优先选择最直接的模式,避免不必要的复杂性。
Python的re模块提供了丰富的功能,但从match对象到分组操作,从标志参数到预编译优化,每个功能都有其适用的场景。掌握这些高级特性,能够让我们在面对复杂文本处理需求时更加游刃有余。
学习正则表达式的过程中,最大的收获是模式识别能力的提升。这种能力不仅应用于编程,也影响着我们解决问题的方式。我们开始学会从混乱中寻找规律,从复杂中提取简单,这正是技术思维的核心价值。
未来,随着自然语言处理技术的发展,正则表达式可能会与AI技术结合,产生更智能的文本处理方案。但无论如何,掌握正则表达式这一基础技能,都将为我们的技术生涯奠定坚实的基础。

■ 我是蒋星熠Jaxonic!如果这篇文章在你的技术成长路上留下了印记
■ 👁 【关注】与我一起探索技术的无限可能,见证每一次突破
■ 👍 【点赞】为优质技术内容点亮明灯,传递知识的力量
■ 🔖 【收藏】将精华内容珍藏,随时回顾技术要点
■ 💬 【评论】分享你的独特见解,让思维碰撞出智慧火花
■ 🗳 【投票】用你的选择为技术社区贡献一份力量
■ 技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!
参考链接
- Python官方re模块文档
- 正则表达式30分钟入门教程
- 正则表达式可视化工具
- Python正则表达式测试工具
- 正则表达式性能优化指南