灵巧手——DexMV
DexMV: Imitation Learning for Dexterous Manipulation from Human Videos
- 论文解读
- 研究背景与动机
- DexMV平台设计
- DexMV流程框架
- 1. 3D姿态估计
- 2. 演示转换(关键创新)
- 3. 模仿学习
- 实验结果
- 重定位任务性能
- 消融研究
- 复杂任务性能
- 泛化能力评估
- 主要贡献
project
git
paper(2022)
更详细的内容,参考原论文和github代码
论文解读
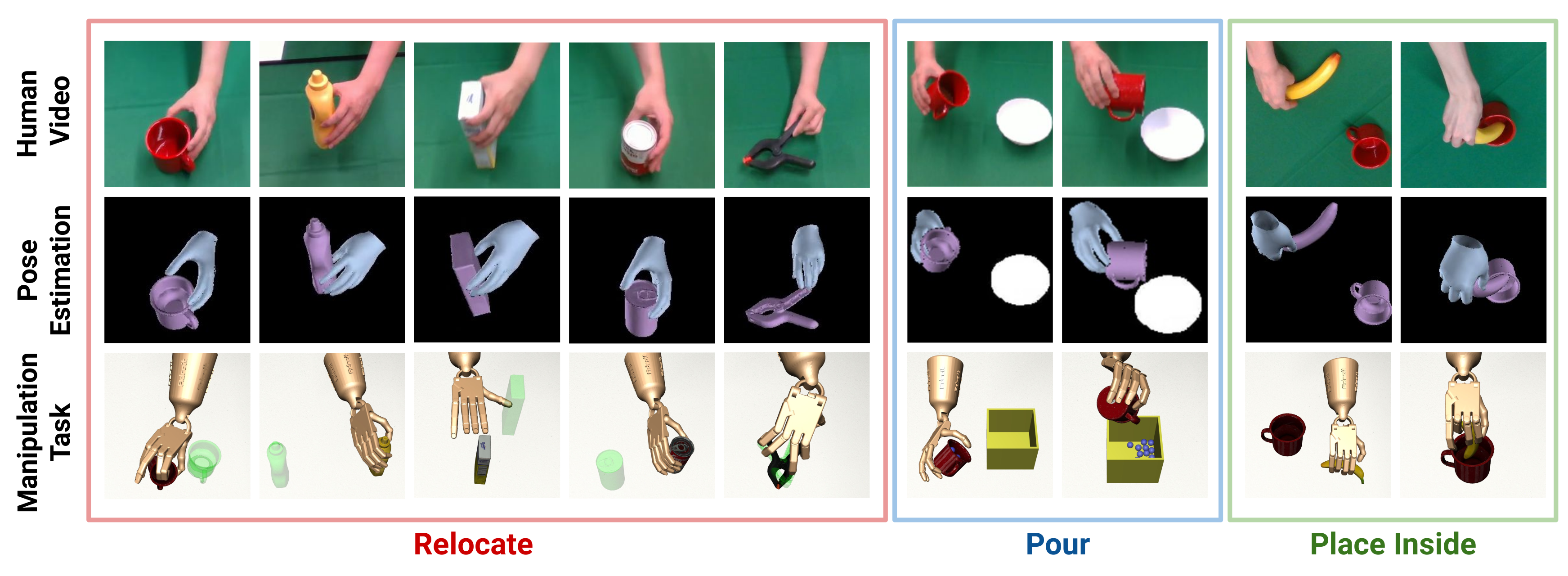
DexMV: Imitation Learning for Dexterous Manipulation from Human Videos 这篇论文提出了一个从人类视频中学习灵巧操作的新平台和流程。以下是主要内容总结:
研究背景与动机
灵巧操作是人与物理世界交互的主要方式,但让机器人具备类似人类的灵巧性仍极具挑战性。传统强化学习(RL)方法需要大量训练数据且容易产生不自然行为。虽然模仿学习是很有前景的替代方案,但现有方法通常依赖VR设备收集演示数据,成本高且难以扩展。
DexMV平台设计
DexMV平台包含两个配对系统:
- 计算机视觉系统:使用两个RealSense D435摄像头记录人类执行操作任务的视频(图1第一行)
- 物理仿真系统:基于MuJoCo和Adroit Robotic Hand(30个自由度)构建,提供与人类演示相同的灵巧操作任务
平台设计了三种具有挑战性的任务:
- 重定位(Relocate):将物体从桌面移动到目标位置,使用5种复杂物体
- 倾倒(Pour):将杯子中的颗粒物倒入容器
- 放入(Place Inside):将物体放入容器内
DexMV流程框架
DexMV流程包含三个核心阶段
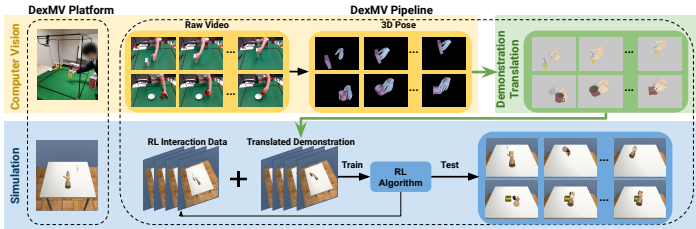
1. 3D姿态估计
- 物体姿态估计:使用PVN3D模型从RGB-D数据估计6自由度物体姿态
- 手部姿态估计:基于MANO模型,通过优化重投影误差和深度一致性获得3D手部关节位置
2. 演示转换(关键创新)
将人类手部运动转换为机器人演示的两个步骤:
-
手部运动重定向(图3):
- 传统方法仅匹配指尖-手掌任务空间向量(TSV),可能导致物体穿透
- 创新性地加入中指节向量匹配,提高运动质量
-
机器人动作估计:
- 拟合最小加加速度轨迹,确保运动自然平滑
- 通过逆动力学函数计算关节扭矩
3. 模仿学习
评估两种模仿学习设置:
- 状态-动作模仿:GAIL+(生成对抗模仿学习)和DAPG(演示增强策略梯度)
- 仅状态模仿:SOIL(状态仅模仿学习),学习逆模型预测缺失动作
实验结果
重定位任务性能
所有模仿学习方法均显著优于纯RL基线。
消融研究
- 运动重定向方法:提出的TSV方法优于传统指尖映射
- 演示数量:更多演示带来更好样本效率和性能
- 环境条件:演示在不同物体尺寸和摩擦系数下保持有效
- 手部姿态估计:双摄像头配置提供更平滑轨迹
复杂任务性能
- 倾倒任务:DAPG性能最佳,平均27.2%颗粒物倒入容器
- 放入任务:DAPG同样表现最优
泛化能力评估
在未见过的物体实例上测试策略泛化能力(图8,9):
- 同类物体:在can、bottle、mug类别上表现良好
- 新类别物体:在camera等新类别上仍有不错表现
主要贡献
- DexMV平台:首个将人类视频与机器人仿真配对的学习平台
- 演示转换模块:创新性地将人类视频转换为机器人演示数据
- 性能提升:在多个复杂任务上大幅提升灵巧操作性能
- 泛化能力:展示了对未见物体实例的良好泛化能力
这项研究为从人类视频中学习灵巧操作提供了新的基准,开辟了计算机视觉与机器人灵巧操作交叉领域的新研究方向。