目标检测:使用自己的数据集微调DEIMv2进行物体检测
目标检测:使用自己的数据集微调DEIMv2进行物体检测
- 前言
- 环境要求
- 相关介绍
- 微调DEIMv2模型
- 下载DEIMv2项目
- Windows
- Linux
- 准备数据集
- 下载预训练模型
- 配置文件
- deimv2_dinov3_s_coco.yml
- coco_detection.yml
- dataloader.yml
- 进行训练
- 输出结果
- 进行验证
- 输出结果
- 进行预测
- 输出结果
- 导出ONNX
- 输出结果
- 推理ONNX
- 输出结果
- 参考

前言
- 由于本人水平有限,难免出现错漏,敬请批评改正。
- 更多精彩内容,可点击进入Python日常小操作专栏、OpenCV-Python小应用专栏、YOLO系列专栏、自然语言处理专栏、人工智能混合编程实践专栏或我的个人主页查看
- Ultralytics:使用 YOLO11 进行速度估计
- Ultralytics:使用 YOLO11 进行物体追踪
- Ultralytics:使用 YOLO11 进行物体计数
- Ultralytics:使用 YOLO11 进行目标打码
- 人工智能混合编程实践:C++调用Python ONNX进行YOLOv8推理
- 人工智能混合编程实践:C++调用封装好的DLL进行YOLOv8实例分割
- 人工智能混合编程实践:C++调用Python ONNX进行图像超分重建
- 人工智能混合编程实践:C++调用Python AgentOCR进行文本识别
- 通过计算实例简单地理解PatchCore异常检测
- Python将YOLO格式实例分割数据集转换为COCO格式实例分割数据集
- YOLOv8 Ultralytics:使用Ultralytics框架训练RT-DETR实时目标检测模型
- 基于DETR的人脸伪装检测
- YOLOv7训练自己的数据集(口罩检测)
- YOLOv8训练自己的数据集(足球检测)
- YOLOv5:TensorRT加速YOLOv5模型推理
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- 玩转Jetson Nano(五):TensorRT加速YOLOv5目标检测
- YOLOv5:添加SE、CBAM、CoordAtt、ECA注意力机制
- YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层
- Python将COCO格式实例分割数据集转换为YOLO格式实例分割数据集
- YOLOv5:使用7.0版本训练自己的实例分割模型(车辆、行人、路标、车道线等实例分割)
- 使用Kaggle GPU资源免费体验Stable Diffusion开源项目
- Stable Diffusion:在服务器上部署使用Stable Diffusion WebUI进行AI绘图(v2.0)
- Stable Diffusion:使用自己的数据集微调训练LoRA模型(v2.0)
环境要求
Package Version
------------------------ ------------
absl-py 2.3.1
accelerate 1.10.1
calflops 0.3.2
certifi 2025.10.5
charset-normalizer 3.4.4
colorama 0.4.6
coloredlogs 15.0.1
faster-coco-eval 1.6.8
filelock 3.20.0
flatbuffers 25.9.23
fsspec 2025.9.0
grpcio 1.75.1
huggingface-hub 0.35.3
humanfriendly 10.0
idna 3.11
Jinja2 3.1.6
Markdown 3.9
markdown-it-py 4.0.0
MarkupSafe 3.0.3
mdurl 0.1.2
ml_dtypes 0.5.3
mpmath 1.3.0
networkx 3.5
numpy 1.26.4
nvidia-cuda-runtime-cu13 0.0.0a0
onnx 1.19.1
onnxruntime 1.23.1
onnxruntime-gpu 1.15.0
onnxsim 0.4.36
opencv-python 4.6.0.66
packaging 25.0
pillow 12.0.0
pip 24.0
protobuf 6.33.0
psutil 7.1.0
Pygments 2.19.2
pyreadline3 3.5.4
PyYAML 6.0.3
regex 2025.9.18
requests 2.32.5
rich 14.2.0
safetensors 0.6.2
scipy 1.16.2
setuptools 65.5.0
sympy 1.13.1
tensorboard 2.20.0
tensorboard-data-server 0.7.2
tensorrt 8.6.1
tensorrt-dispatch 8.6.1
tensorrt-lean 8.6.1
tokenizers 0.22.1
torch 2.5.1+cu118
torchaudio 2.5.1+cu118
torchvision 0.20.1+cu118
tqdm 4.67.1
transformers 4.57.1
typing_extensions 4.15.0
urllib3 2.5.0
Werkzeug 3.1.3
相关介绍
- Python是一种跨平台的计算机程序设计语言。是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越多被用于独立的、大型项目的开发。
- PyTorch 是一个深度学习框架,封装好了很多网络和深度学习相关的工具方便我们调用,而不用我们一个个去单独写了。它分为 CPU 和 GPU 版本,其他框架还有 TensorFlow、Caffe 等。PyTorch 是由 Facebook 人工智能研究院(FAIR)基于 Torch 推出的,它是一个基于 Python 的可续计算包,提供两个高级功能:1、具有强大的 GPU 加速的张量计算(如 NumPy);2、构建深度神经网络时的自动微分机制。
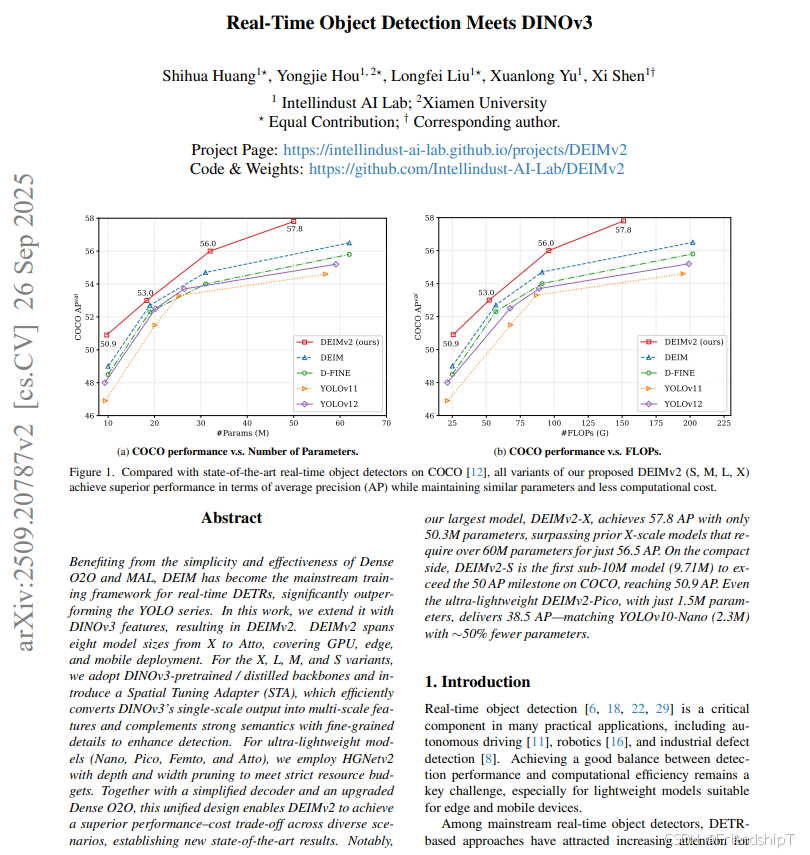
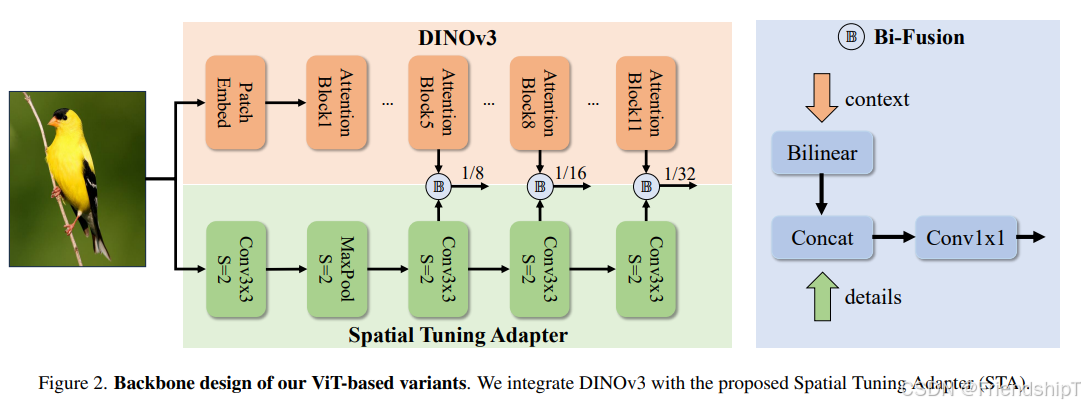
- DEIMv2是一种基于DINOv3特性的实时对象检测器,其核心特点是:
- 多种模型规模:DEIMv2设计了多种模型规模,从满足GPU到移动设备部署需求的大型模型到超轻量级模型。
- Spatial Tuning Adapter(STA):引入STA高效融合单尺度输出为多尺度特征。
- 简化解码器和增强的密集物体对齐(Dense O2O)策略:进一步提升性能。
- DEIMv2的优点是能够在不同的场景下实现高效的实时对象检测,尤其是在大模型和紧凑型模型方面表现出色。同时,DEIMv2还能够提高实时检测性能和效率。
- DEIMv2也有一些局限性,例如需要大量的计算资源和训练时间。此外,DEIMv2在处理小目标时可能存在一定的误检率。
- 未来,可以考虑针对DEIMv2的局限性进行改进,如优化训练算法、增加数据集样本等,以进一步提高DEIMv2的性能和适用范围。
- 官方源代码: https://github.com/Intellindust-AI-Lab/DEIMv2.git
- Huang, Shihua and Hou, Yongjie and Liu, Longfei and Yu, Xuanlong and Shen, Xi. Real-Time Object Detection Meets DINOv3. 2025
微调DEIMv2模型
下载DEIMv2项目
- 官方源代码: https://github.com/Intellindust-AI-Lab/DEIMv2.git
Windows
Linux
git clone https://github.com/Intellindust-AI-Lab/DEIMv2.git
准备数据集
准备一个COCO格式的目标检测数据集。
dataset/
├── images/
│ ├── train/
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ └── ...
│ ├── val/
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ └── ...
└── annotations/├── instances_train.json├── instances_val.json└── ...
下载预训练模型
对于 DINOv3 S 和 S+模型,请按照 https://github.com/facebookresearch/dinov3 中的指南下载。
对于蒸馏的 ViT-Tiny 和 ViT-Tiny+模型,您可以从 ViT-Tiny 和 ViT-Tiny+ 下载。
然后将它们放入 ./ckpts 中:
ckpts/
├── dinov3_vits16.pth
├── vitt_distill.pt
├── vittplus_distill.pt
└── ...
配置文件
deimv2_dinov3_s_coco.yml
__include__: ['../dataset/coco_detection.yml','../runtime.yml','../base/dataloader.yml','../base/optimizer.yml','../base/deimv2.yml',
]output_dir: ./outputs/deimv2_dinov3_s_cocoDEIM:backbone: DINOv3STAsDINOv3STAs:name: vit_tinyembed_dim: 192weights_path: ./ckpts/vitt_distill.ptinteraction_indexes: [3, 7, 11] # only need the [1/8, 1/16, 1/32]num_heads: 3HybridEncoder:in_channels: [192, 192, 192]depth_mult: 0.67expansion: 0.34hidden_dim: 192dim_feedforward: 512DEIMTransformer:feat_channels: [192, 192, 192]hidden_dim: 192dim_feedforward: 512num_layers: 4 # 4 5 6eval_idx: -1 # -2 -3 -4## Optimizer
optimizer:type: AdamWparams: -# except norm/bn/bias in self.dinov3params: '^(?=.*.dinov3)(?!.*(?:norm|bn|bias)).*$' lr: 0.000025-# including all norm/bn/bias in self.dinov3params: '^(?=.*.dinov3)(?=.*(?:norm|bn|bias)).*$' lr: 0.000025weight_decay: 0.- # including all norm/bn/bias except for the self.dinov3params: '^(?=.*(?:sta|encoder|decoder))(?=.*(?:norm|bn|bias)).*$'weight_decay: 0.lr: 0.0005betas: [0.9, 0.999]weight_decay: 0.0001# Increase to search for the optimal ema
epoches: 132 # 120 + 4n## Our LR-Scheduler
flat_epoch: 64 # 4 + epoch // 2, e.g., 40 = 4 + 72 / 2
no_aug_epoch: 12## Our DataAug
train_dataloader:dataset: transforms:ops:- {type: Mosaic, output_size: 320, rotation_range: 10, translation_range: [0.1, 0.1], scaling_range: [0.5, 1.5],probability: 1.0, fill_value: 0, use_cache: True, max_cached_images: 50, random_pop: True}- {type: RandomPhotometricDistort, p: 0.5}- {type: RandomZoomOut, fill: 0}- {type: RandomIoUCrop, p: 0.8}- {type: SanitizeBoundingBoxes, min_size: 1}- {type: RandomHorizontalFlip}- {type: Resize, size: [640, 640], }- {type: SanitizeBoundingBoxes, min_size: 1}- {type: ConvertPILImage, dtype: 'float32', scale: True}- {type: Normalize, mean: [0.485, 0.456, 0.406], std: [0.229, 0.224, 0.225]}- {type: ConvertBoxes, fmt: 'cxcywh', normalize: True}policy:epoch: [4, 64, 120] # list collate_fn:base_size: 640mixup_prob: 0.5ema_restart_decay: 0.9999base_size_repeat: 20mixup_epochs: [4, 64]stop_epoch: 120copyblend_epochs: [4, 120]val_dataloader:dataset:transforms:ops:- {type: Resize, size: [640, 640], }- {type: ConvertPILImage, dtype: 'float32', scale: True}- {type: Normalize, mean: [0.485, 0.456, 0.406], std: [0.229, 0.224, 0.225]}DEIMCriterion:matcher:# change matcherchange_matcher: Trueiou_order_alpha: 4.0matcher_change_epoch: 100
coco_detection.yml
task: detectionevaluator:type: CocoEvaluatoriou_types: ['bbox', ]num_classes: 80
remap_mscoco_category: Truetrain_dataloader: type: DataLoaderdataset: type: CocoDetectionimg_folder: 你自己的数据路径/images/train/ann_file: 你自己的数据路径/annotations/instances_train.jsonreturn_masks: Falsetransforms:type: Composeops: ~shuffle: Truenum_workers: 4drop_last: True collate_fn:type: BatchImageCollateFunctionval_dataloader:type: DataLoaderdataset: type: CocoDetectionimg_folder: 你自己的数据路径/images/val/ann_file: 你自己的数据路径/annotations/instances_val.jsonreturn_masks: Falsetransforms:type: Composeops: ~ shuffle: Falsenum_workers: 4drop_last: Falsecollate_fn:type: BatchImageCollateFunction
dataloader.yml
train_dataloader:dataset:transforms:ops:- {type: RandomPhotometricDistort, p: 0.5}- {type: RandomZoomOut, fill: 0}- {type: RandomIoUCrop, p: 0.8}- {type: SanitizeBoundingBoxes, min_size: 1}- {type: RandomHorizontalFlip}- {type: Resize, size: [640, 640], }- {type: SanitizeBoundingBoxes, min_size: 1}- {type: ConvertPILImage, dtype: 'float32', scale: True}- {type: ConvertBoxes, fmt: 'cxcywh', normalize: True}policy:name: stop_epochepoch: 72 # epoch in [71, ~) stop `ops`ops: ['Mosaic', 'RandomPhotometricDistort', 'RandomZoomOut', 'RandomIoUCrop']collate_fn:type: BatchImageCollateFunctionbase_size: 640base_size_repeat: 3stop_epoch: 72 # epoch in [72, ~) stop `multiscales`shuffle: True# total_batch_size: 32 # total batch size equals to 32 (4 * 8)total_batch_size: 2 # 单卡,8G显存num_workers: 4val_dataloader:dataset:transforms:ops:- {type: Resize, size: [640, 640], }- {type: ConvertPILImage, dtype: 'float32', scale: True}shuffle: False# total_batch_size: 64 # 8G显存不够total_batch_size: 2 # 单卡,8G显存num_workers: 4进行训练
python train.py -c configs/deimv2/deimv2_dinov3_s_coco.yml --use-amp --seed=0 -t deimv2_dinov3_s_coco.pth
$python train.py -c configs/deimv2/deimv2_dinov3_s_coco.yml --use-amp --seed=0 -t deimv2_dinov3_s_coco.pth
Not init distributed mode.
cfg: {'task': 'detection', '_model': None, '_postprocessor': None, '_criterion': None, '_optimizer': None, '_lr_scheduler': None, '_lr_warmup_scheduler': None, '_train_dataloader': None, '_val_dataloader': None, '_ema': None, '_scaler': None, '_train_dataset': None, '_val_dataset': None, '_collate_fn': None, '_evaluator': None, '_writer': None, 'num_workers': 0, 'batch_size': None, '_train_batch_size': None, '_val_batch_size': None, '_train_shuffle': None, '_val_shuffle': None, 'resume': None, 'tuning': 'deimv2_dinov3_s_coco.pth', 'epoches': 132, 'last_epoch': -1, 'lrsheduler': 'flatcosine', 'lr_gamma': 0.5, 'no_aug_epoch': 12, 'warmup_iter': 2000, 'flat_epoch': 64, 'use_amp': True, 'use_ema': True, 'ema_decay': 0.9999, 'ema_warmups': 2000, 'sync_bn': True, 'clip_max_norm': 0.1, 'find_unused_parameters': True, 'seed': 0, 'print_freq': 500, 'checkpoint_freq': 5, 'output_dir': './outputs/deimv2_dinov3_s_coco', 'summary_dir': None, 'device': '', 'yaml_cfg': {'task': 'detection', 'evaluator': {'type': 'CocoEvaluator', 'iou_types': ['bbox']}, 'num_classes': 80, 'remap_mscoco_category': True, 'train_dataloader': {'type': 'DataLoader', 'dataset': {'type': 'CocoDetection', 'img_folder': 'F:/user/mytest/DEIMv2_test/coco_mini_dataset/images/train/', 'ann_file': 'F:/user/mytest/DEIMv2_test/coco_mini_dataset/annotations/instances_train.json', 'return_masks': False, 'transforms': {'type': 'Compose', 'ops': [{'type': 'Mosaic', 'output_size': 320, 'rotation_range': 10, 'translation_range': [0.1, 0.1], 'scaling_range': [0.5, 1.5], 'probability': 1.0, 'fill_value': 0, 'use_cache': True, 'max_cached_images': 50, 'random_pop': True}, {'type': 'RandomPhotometricDistort', 'p': 0.5}, {'type': 'RandomZoomOut', 'fill': 0}, {'type': 'RandomIoUCrop', 'p': 0.8}, {'type': 'SanitizeBoundingBoxes', 'min_size': 1}, {'type': 'RandomHorizontalFlip'}, {'type': 'Resize', 'size': [640, 640]}, {'type': 'SanitizeBoundingBoxes', 'min_size': 1}, {'type': 'ConvertPILImage', 'dtype': 'float32', 'scale': True}, {'type': 'Normalize', 'mean': [0.485, 0.456, 0.406], 'std': [0.229, 0.224, 0.225]}, {'type': 'ConvertBoxes', 'fmt': 'cxcywh', 'normalize': True}], 'policy': {'name': 'stop_epoch', 'epoch': [4, 64, 120], 'ops': ['Mosaic', 'RandomPhotometricDistort', 'RandomZoomOut', 'RandomIoUCrop']}, 'mosaic_prob': 0.5}}, 'shuffle': True, 'num_workers': 4, 'drop_last': True, 'collate_fn': {'type': 'BatchImageCollateFunction', 'base_size': 640, 'base_size_repeat': 20, 'stop_epoch': 120, 'mixup_prob': 0.5, 'mixup_epochs': [4, 64], 'copyblend_prob': 0.5, 'copyblend_epochs': [4, 120], 'area_threshold': 100, 'num_objects': 3, 'with_expand': True, 'expand_ratios': [0.1, 0.25], 'ema_restart_decay': 0.9999}, 'total_batch_size': 2}, 'val_dataloader': {'type': 'DataLoader', 'dataset': {'type': 'CocoDetection', 'img_folder': 'F:/user/mytest/DEIMv2_test/coco_mini_dataset/images/val/', 'ann_file': 'F:/user/mytest/DEIMv2_test/coco_mini_dataset/annotations/instances_val.json', 'return_masks': False, 'transforms': {'type': 'Compose', 'ops': [{'type': 'Resize', 'size': [640, 640]}, {'type': 'ConvertPILImage', 'dtype': 'float32', 'scale': True}, {'type': 'Normalize', 'mean': [0.485, 0.456, 0.406], 'std': [0.229, 0.224, 0.225]}]}}, 'shuffle': False, 'num_workers': 4, 'drop_last': False, 'collate_fn': {'type': 'BatchImageCollateFunction'}, 'total_batch_size': 2}, 'print_freq': 500, 'output_dir': './outputs/deimv2_dinov3_s_coco', 'checkpoint_freq': 5, 'sync_bn': True, 'find_unused_parameters': True, 'use_amp': True, 'scaler': {'type': 'GradScaler', 'enabled': True}, 'use_ema': True, 'ema': {'type': 'ModelEMA', 'decay': 0.9999, 'warmups': 1000, 'start': 0}, 'epoches': 132, 'clip_max_norm': 0.1, 'optimizer': {'type': 'AdamW', 'params': [{'params': '^(?=.*.dinov3)(?!.*(?:norm|bn|bias)).*$', 'lr': 2.5e-05}, {'params': '^(?=.*.dinov3)(?=.*(?:norm|bn|bias)).*$', 'lr': 2.5e-05, 'weight_decay': 0.0}, {'params': '^(?=.*(?:sta|encoder|decoder))(?=.*(?:norm|bn|bias)).*$', 'weight_decay': 0.0}], 'lr': 0.0005, 'betas': [0.9, 0.999], 'weight_decay': 0.0001}, 'lr_scheduler': {'type': 'MultiStepLR', 'milestones': [500], 'gamma': 0.1}, 'lr_warmup_scheduler': {'type': 'LinearWarmup', 'warmup_duration': 500}, 'model': 'DEIM', 'criterion': 'DEIMCriterion', 'postprocessor': 'PostProcessor', 'use_focal_loss': True, 'eval_spatial_size': [640, 640], 'DEIM': {'backbone': 'DINOv3STAs', 'encoder': 'HybridEncoder', 'decoder': 'DEIMTransformer'}, 'HGNetv2': {'name': 'B4', 'return_idx': [1, 2, 3], 'freeze_at': -1, 'freeze_stem_only': True, 'freeze_norm': False, 'pretrained': False, 'local_model_dir': './weight/hgnetv2/'}, 'HybridEncoder': {'in_channels': [192, 192, 192], 'feat_strides': [8, 16, 32], 'hidden_dim': 192, 'use_encoder_idx': [2], 'num_encoder_layers': 1, 'nhead': 8, 'dim_feedforward': 512, 'dropout': 0.0, 'enc_act': 'gelu', 'expansion': 0.34, 'depth_mult': 0.67, 'act': 'silu', 'version': 'deim', 'csp_type': 'csp2', 'fuse_op': 'sum'}, 'DEIMTransformer': {'feat_channels': [192, 192, 192], 'feat_strides': [8, 16, 32], 'hidden_dim': 192, 'num_levels': 3, 'num_layers': 4, 'eval_idx': -1, 'num_queries': 300, 'num_denoising': 100, 'label_noise_ratio': 0.5, 'box_noise_scale': 1.0, 'reg_max': 32, 'reg_scale': 4, 'layer_scale': 1, 'num_points': [3, 6, 3], 'cross_attn_method': 'default', 'query_select_method': 'default', 'activation': 'silu', 'mlp_act': 'silu', 'dim_feedforward': 512}, 'PostProcessor': {'num_top_queries': 300}, 'lrsheduler': 'flatcosine', 'lr_gamma': 0.5, 'warmup_iter': 2000, 'flat_epoch': 64, 'no_aug_epoch': 12, 'DEIMCriterion': {'weight_dict': {'loss_mal': 1, 'loss_bbox': 5, 'loss_giou': 2, 'loss_fgl': 0.15, 'loss_ddf': 1.5}, 'losses': ['mal', 'boxes', 'local'], 'gamma': 1.5, 'alpha': 0.75, 'reg_max': 32, 'matcher': {'type': 'HungarianMatcher', 'weight_dict': {'cost_class': 2, 'cost_bbox': 5, 'cost_giou': 2}, 'alpha': 0.25, 'gamma': 2.0, 'change_matcher': True, 'iou_order_alpha': 4.0, 'matcher_change_epoch': 100}}, '__include__': ['../dataset/coco_detection.yml', '../runtime.yml', '../base/dataloader.yml', '../base/optimizer.yml', '../base/deimv2.yml'], 'DINOv3STAs': {'name': 'vit_tiny', 'embed_dim': 192, 'weights_path': './ckpts/vitt_distill.pt', 'interaction_indexes': [3, 7, 11], 'num_heads': 3}, 'config': 'configs/deimv2/deimv2_dinov3_s_coco.yml', 'tuning': 'deimv2_dinov3_s_coco.pth', 'seed': 0, 'test_only': False, 'print_method': 'builtin', 'print_rank': 0}}
Training ViT-Tiny from scratch...
Using Lite Spatial Prior Module with inplanes=16--- Use Gateway@True ------ Use Share Bbox Head@False ------ Use Share Score Head@False ------ Wide Layer@1 ---
Tuning checkpoint from deimv2_dinov3_s_coco.pth
F:\user\mytest\DEIMv2_test\DEIMv2-main\engine\solver\_solver.py:169: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.state = torch.load(path, map_location='cpu')
Load model.state_dict, {'missed': [], 'unmatched': []}
Using the new matching cost with iou_order_alpha = 4.0 at epoch 100
F:\user\mytest\DEIMv2_test\DEIMv2-main\engine\core\workspace.py:177: FutureWarning: `torch.cuda.amp.GradScaler(args...)` is deprecated. Please use `torch.amp.GradScaler('cuda', args...)` instead.return module(**module_kwargs)
Initial lr: [2.5e-05, 2.5e-05, 0.0005, 0.0005]
building train_dataloader with batch_size=2...### Transform @Mosaic ###### Transform @RandomPhotometricDistort ###### Transform @RandomZoomOut ###### Transform @RandomIoUCrop ###### Transform @SanitizeBoundingBoxes ###### Transform @RandomHorizontalFlip ###### Transform @Resize ###### Transform @SanitizeBoundingBoxes ###### Transform @ConvertPILImage ###### Transform @Normalize ###### Transform @ConvertBoxes ###### Mosaic with Prob.@0.5 and ZoomOut/IoUCrop existed ###### ImgTransforms Epochs: [4, 64, 120] ###### Policy_ops@['Mosaic', 'RandomPhotometricDistort', 'RandomZoomOut', 'RandomIoUCrop'] ###### Using MixUp with Prob@0.5 in [4, 64] epochs ###### Using CopyBlend-blend with Prob@0.5 in [4, 120] epochs ###### CopyBlend -- area threshold@100 and num of object@3 ###### CopyBlend -- expand@[0.1, 0.25] ###### Multi-scale Training until 120 epochs ###### Multi-scales@ [480, 512, 544, 576, 608, 640, 640, 640, 640, 640, 640, 640, 640, 640, 640, 640, 640, 640, 640, 640, 640, 640, 640, 640, 640, 800, 768, 736, 704, 672] ###
building val_dataloader with batch_size=2...### Transform @Resize ###### Transform @ConvertPILImage ###### Transform @Normalize ###------------------------------------- Calculate Flops Results -------------------------------------
Notations:
number of parameters (Params), number of multiply-accumulate operations(MACs),
number of floating-point operations (FLOPs), floating-point operations per second (FLOPS),
fwd FLOPs (model forward propagation FLOPs), bwd FLOPs (model backward propagation FLOPs),
default model backpropagation takes 2.00 times as much computation as forward propagation.Total Training Params: 9.71 M
fwd MACs: 12.7678 GMACs
fwd FLOPs: 25.6242 GFLOPS
fwd+bwd MACs: 38.3033 GMACs
fwd+bwd FLOPs: 76.8725 GFLOPS
---------------------------------------------------------------------------------------------------
{'Model FLOPs:25.6242 GFLOPS MACs:12.7678 GMACs Params:9707403'}
------------------------------------------Start training-------------------------------------------
Index 194: decoder.decoder.layers.1.cross_attn.attention_weights.weight - requires_grad: True
Index 195: decoder.decoder.layers.1.cross_attn.attention_weights.bias - requires_grad: True## Using Self-defined Scheduler-flatcosine ##
[2.5e-05, 2.5e-05, 0.0005, 0.0005] [1.25e-05, 1.25e-05, 0.00025, 0.00025] 13200 2000 6400 1200
number of trainable parameters: 9779836
number of non-trainable parameters: 2
Epoch: [0] [ 0/100] eta: 1:10:51 lr: 0.000000 loss: 24.4887 (24.4887) loss_mal: 1.3350 (1.3350) loss_bbox: 0.0748 (0.0748) loss_giou: 0.4123 (0.4123) loss_fgl: 1.1017 (1.1017) loss_mal_aux_0: 1.2637 (1.2637) loss_bbox_aux_0: 0.0727 (0.0727) loss_giou_aux_0: 0.4149 (0.4149) loss_fgl_aux_0: 1.1103 (1.1103) loss_ddf_aux_0: 0.0201 (0.0201) loss_mal_aux_1: 1.2578 (1.2578) loss_bbox_aux_1: 0.0753 (0.0753) loss_giou_aux_1: 0.4027 (0.4027) loss_fgl_aux_1: 1.1033 (1.1033) loss_ddf_aux_1: 0.0044 (0.0044) loss_mal_aux_2: 1.3594 (1.3594) loss_bbox_aux_2: 0.0758 (0.0758) loss_giou_aux_2: 0.4157 (0.4157) loss_fgl_aux_2: 1.1035 (1.1035) loss_ddf_aux_2: 0.0013 (0.0013) loss_mal_pre: 1.2695 (1.2695) loss_bbox_pre: 0.0724 (0.0724) loss_giou_pre: 0.4064 (0.4064) loss_mal_enc_0: 1.3691 (1.3691) loss_bbox_enc_0: 0.0837 (0.0837) loss_giou_enc_0: 0.4584 (0.4584) loss_mal_dn_0: 0.6572 (0.6572) loss_bbox_dn_0: 0.0996 (0.0996) loss_giou_dn_0: 0.4012 (0.4012) loss_fgl_dn_0: 1.1022 (1.1022) loss_ddf_dn_0: 0.1698 (0.1698) loss_mal_dn_1: 0.5098 (0.5098) loss_bbox_dn_1: 0.0670 (0.0670) loss_giou_dn_1: 0.2808 (0.2808) loss_fgl_dn_1: 1.0306 (1.0306) loss_ddf_dn_1: 0.0210 (0.0210) loss_mal_dn_2: 0.4963 (0.4963) loss_bbox_dn_2: 0.0623 (0.0623) loss_giou_dn_2: 0.2722 (0.2722) loss_fgl_dn_2: 1.0261 (1.0261) loss_ddf_dn_2: 0.0015 (0.0015) loss_mal_dn_3: 0.4963 (0.4963) loss_bbox_dn_3: 0.0616 (0.0616) loss_giou_dn_3: 0.2690 (0.2690) loss_fgl_dn_3: 1.0251 (1.0251) loss_mal_dn_pre: 0.6597 (0.6597) loss_bbox_dn_pre: 0.1088 (0.1088) loss_giou_dn_pre: 0.4065 (0.4065) time: 42.5199 data: 40.4094 max mem: 1979
......
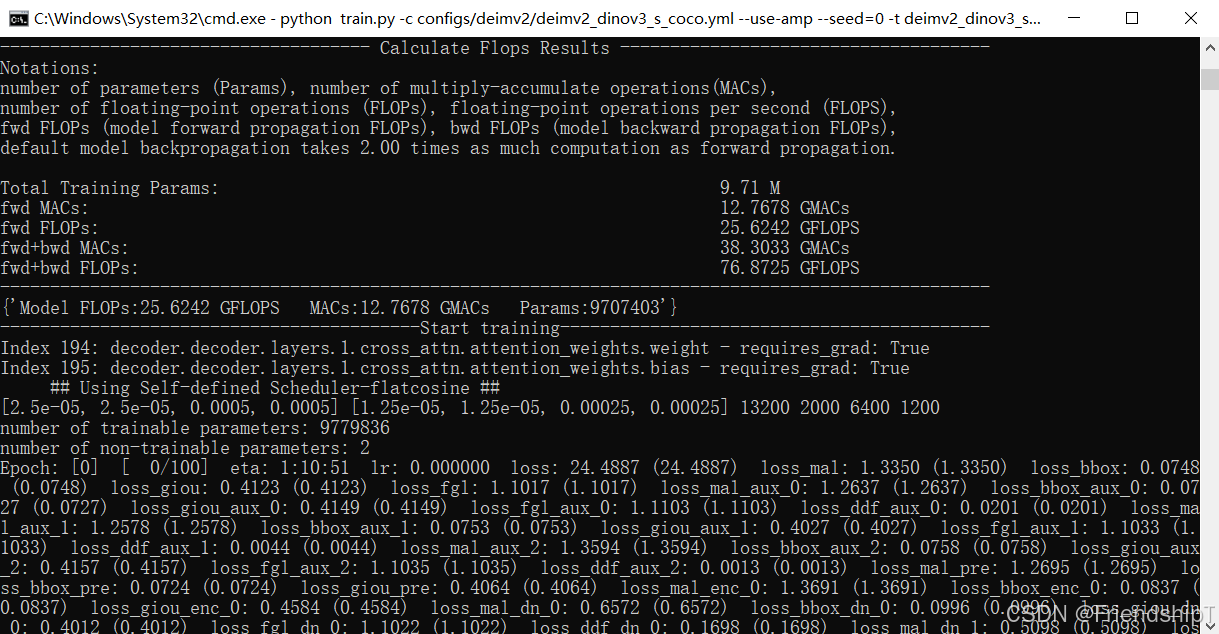
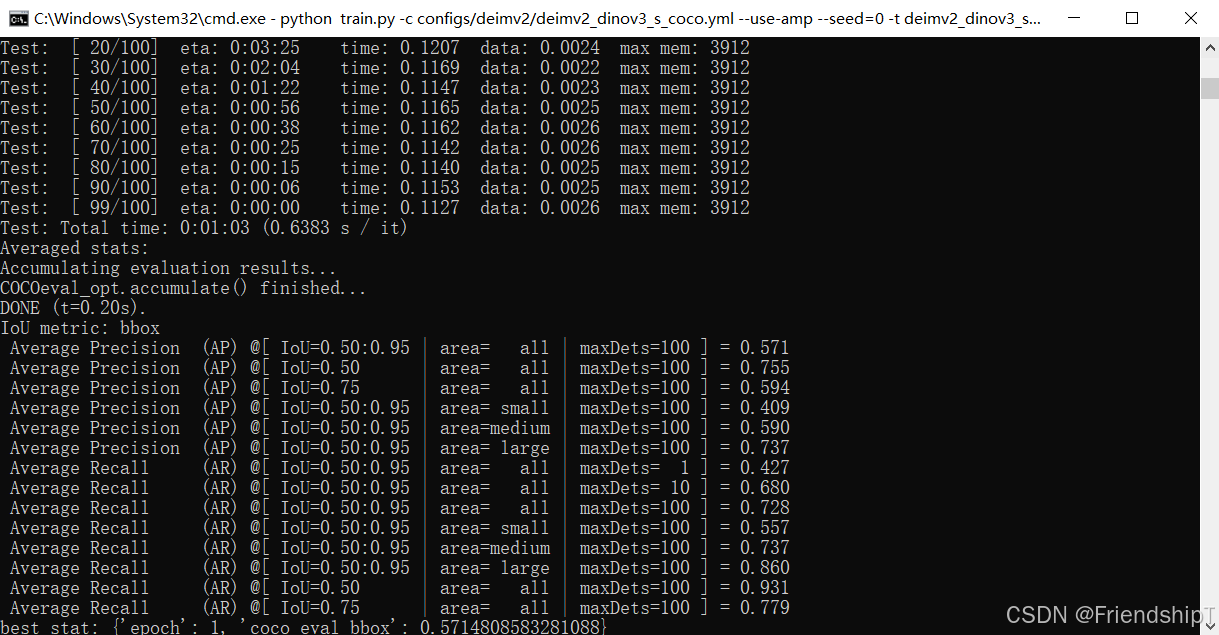
输出结果
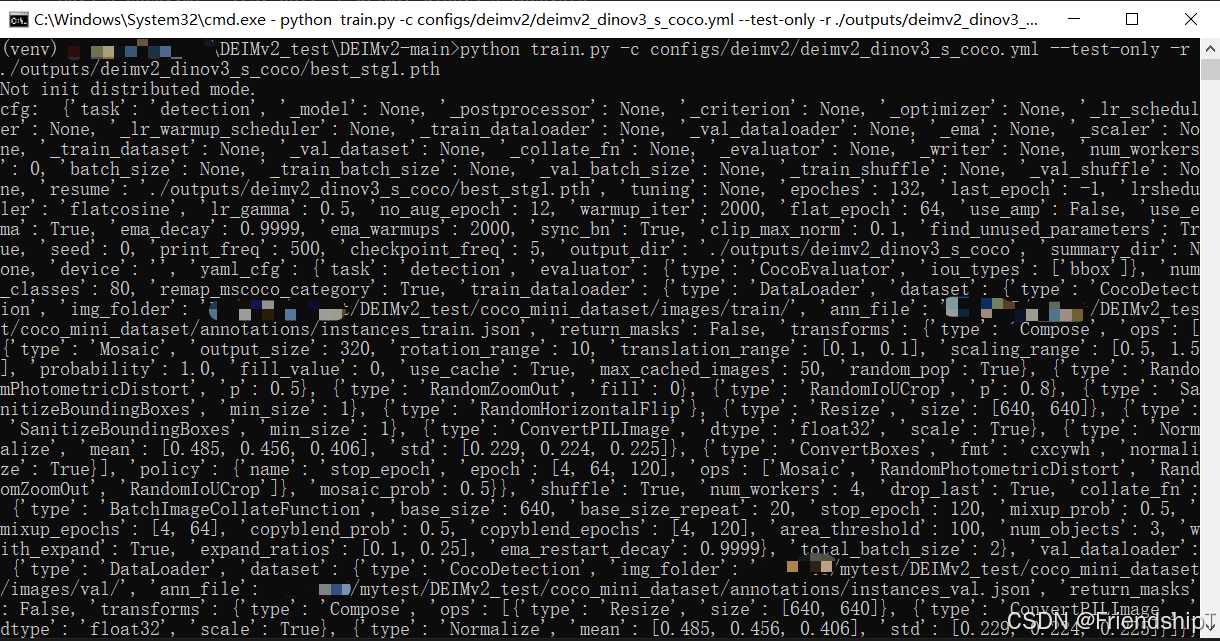
进行验证
python train.py -c configs/deimv2/deimv2_dinov3_s_coco.yml --test-only -r ./outputs/deimv2_dinov3_s_coco/best_stg1.pth
输出结果
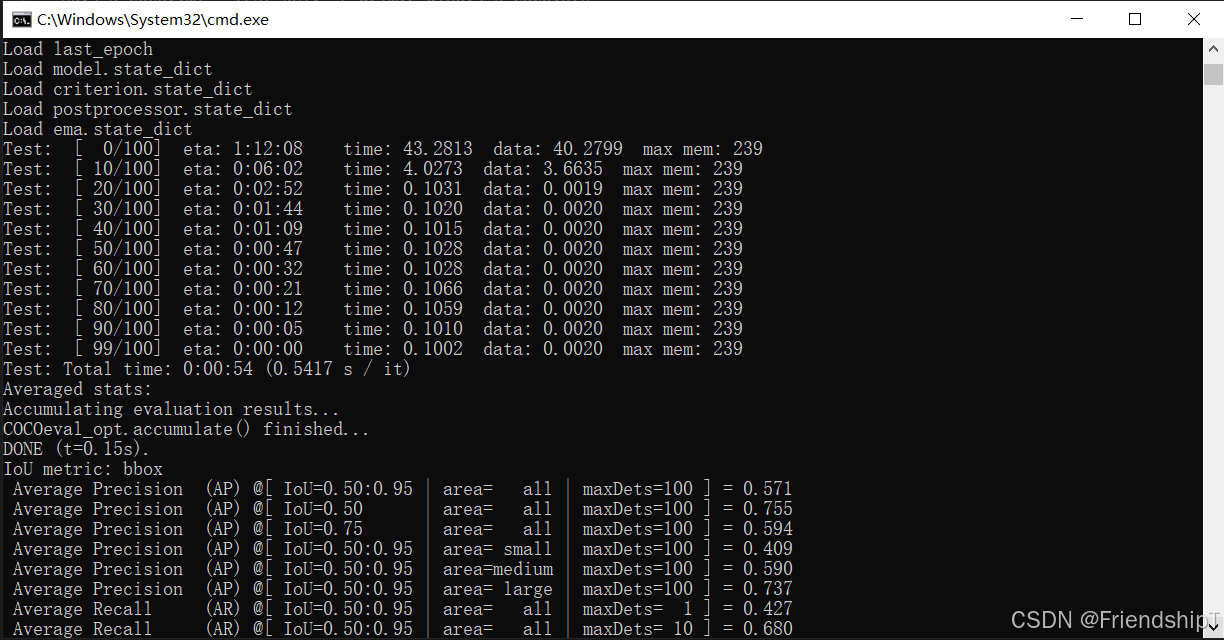
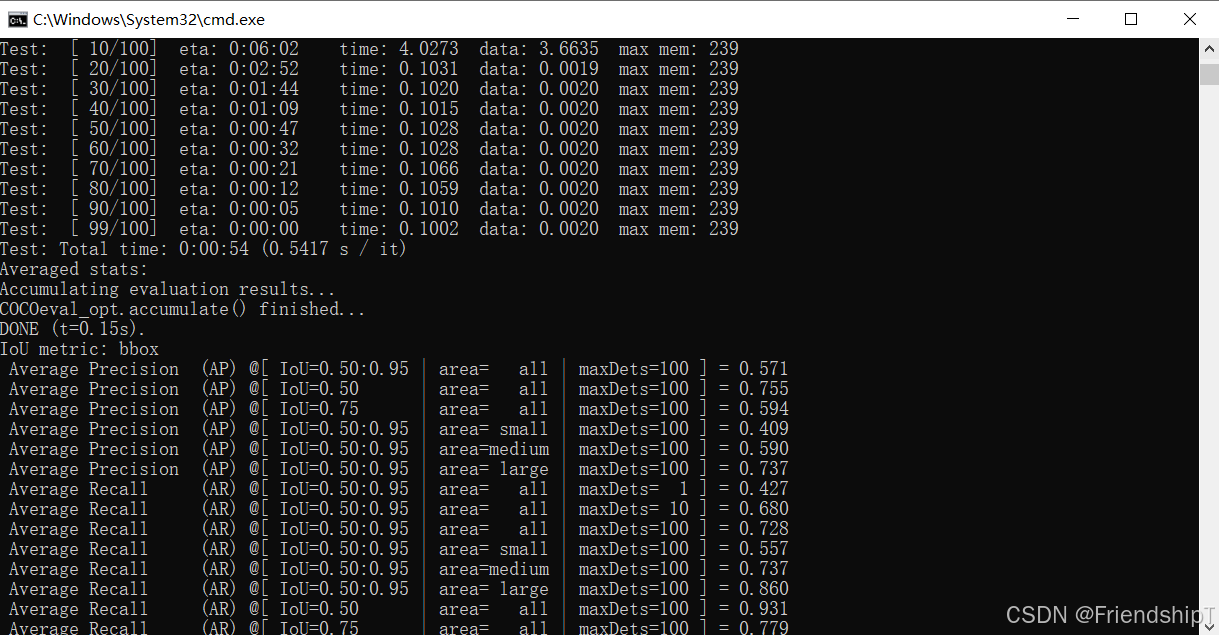
进行预测
python tools/inference/torch_inf.py -c configs/deimv2/deimv2_dinov3_s_coco.yml -r ./outputs/deimv2_dinov3_s_coco/best_stg1.pth --input ./test_imgs/1.png --device cuda:0
输出结果
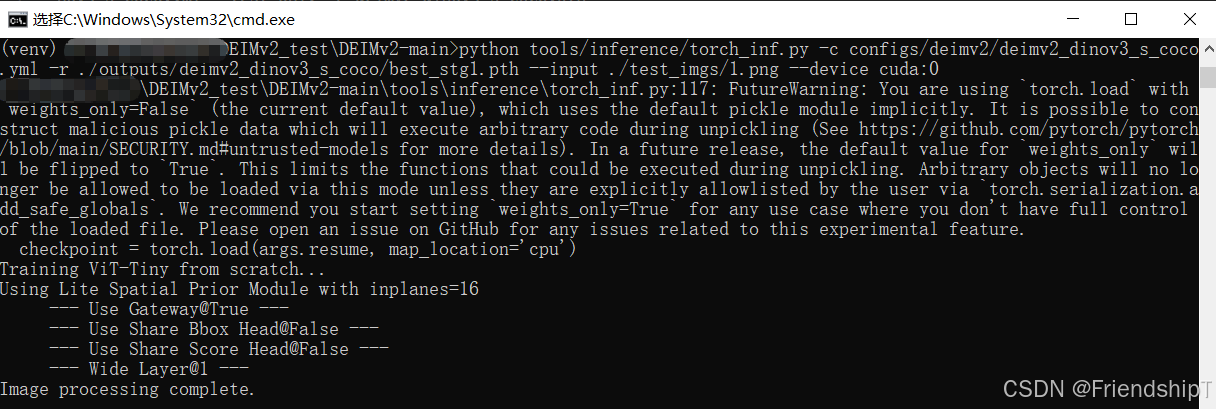
导出ONNX
python tools/deployment/export_onnx.py --check -c configs/deimv2/deimv2_dinov3_s_coco.yml -r ./outputs/deimv2_dinov3_s_coco/best_stg1.pth
输出结果
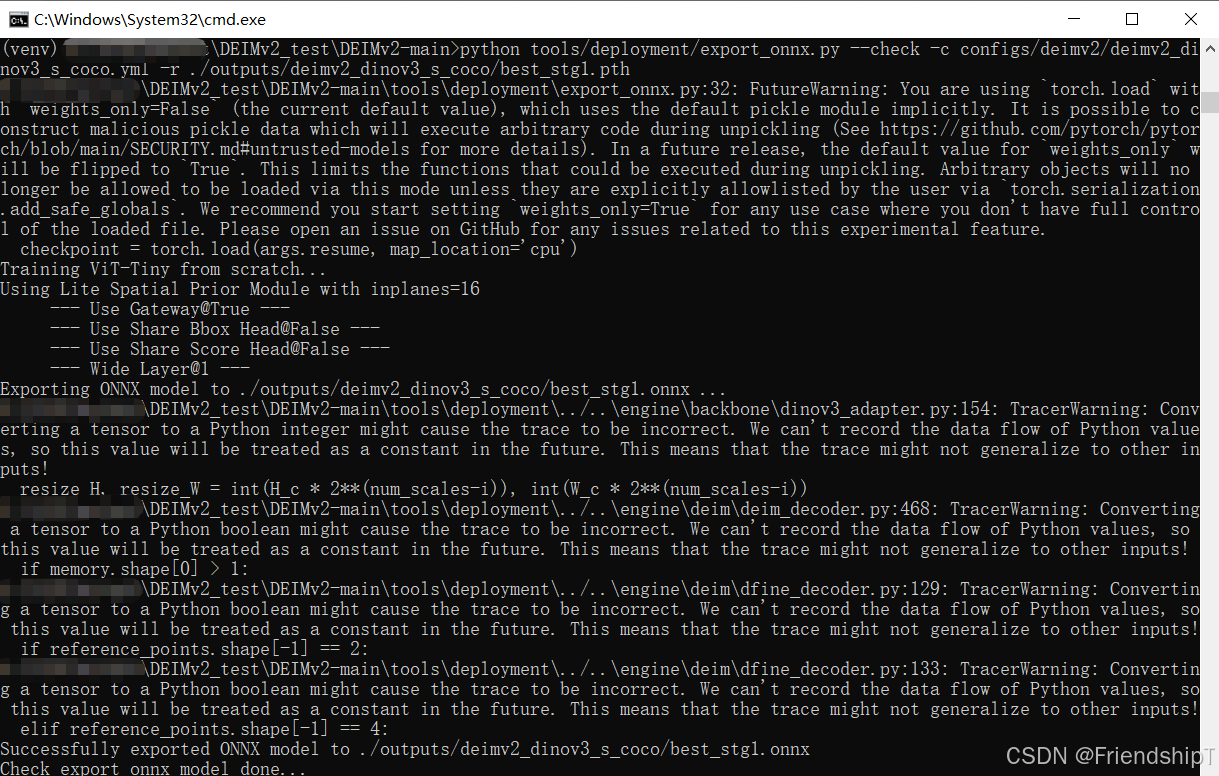
推理ONNX
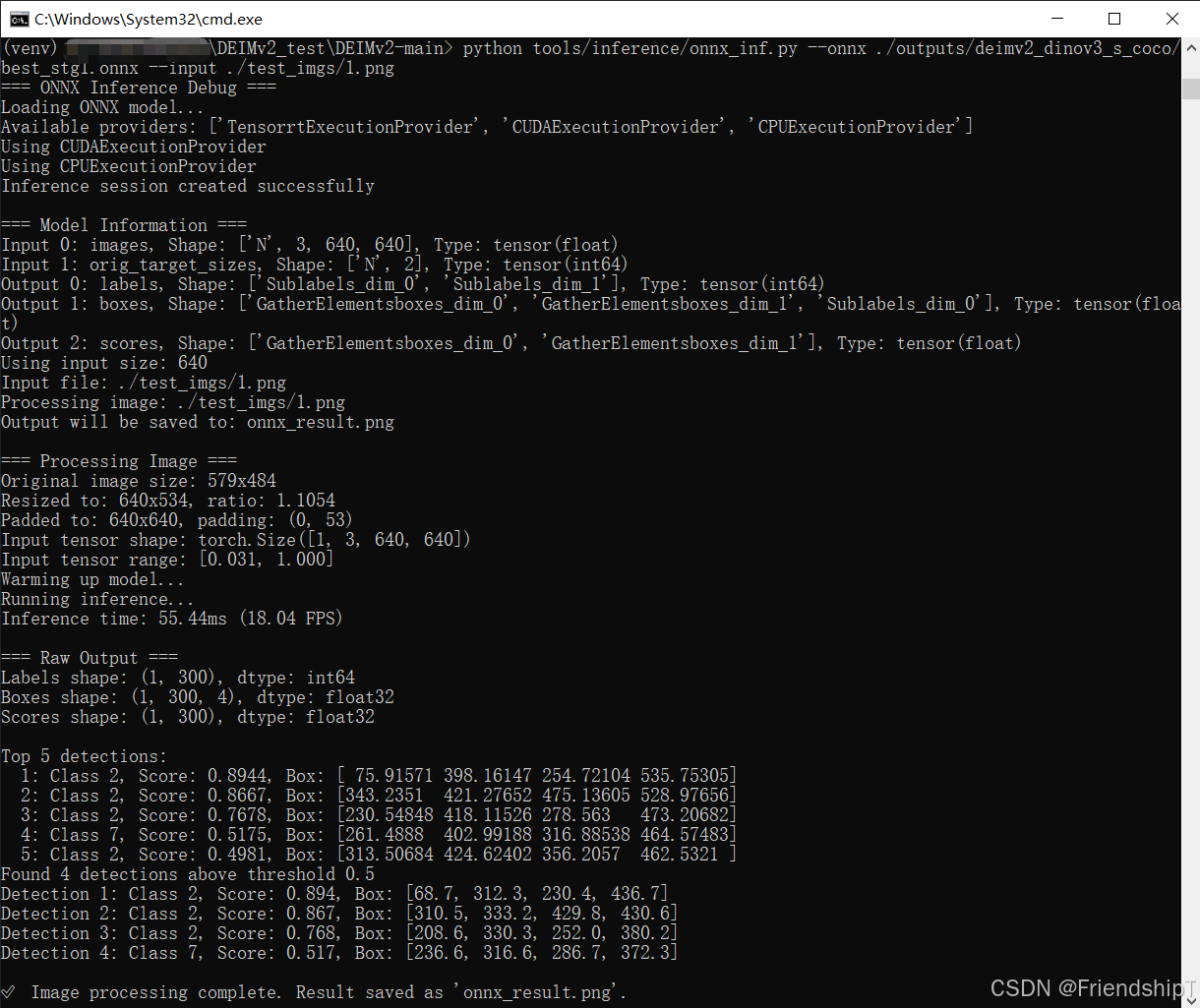
python tools/inference/onnx_inf.py --onnx ./outputs/deimv2_dinov3_s_coco/best_stg1.onnx --input ./test_imgs/1.png
输出结果

参考
[1] Huang, Shihua and Hou, Yongjie and Liu, Longfei and Yu, Xuanlong and Shen, Xi. Real-Time Object Detection Meets DINOv3. 2025
[2] https://github.com/xinntao/Real-ESRGAN.git
@article{huang2025deimv2,title={Real-Time Object Detection Meets DINOv3},author={Huang, Shihua and Hou, Yongjie and Liu, Longfei and Yu, Xuanlong and Shen, Xi},journal={arXiv},year={2025}
}
- 由于本人水平有限,难免出现错漏,敬请批评改正。
- 更多精彩内容,可点击进入Python日常小操作专栏、OpenCV-Python小应用专栏、YOLO系列专栏、自然语言处理专栏、人工智能混合编程实践专栏或我的个人主页查看
- Ultralytics:使用 YOLO11 进行速度估计
- Ultralytics:使用 YOLO11 进行物体追踪
- Ultralytics:使用 YOLO11 进行物体计数
- Ultralytics:使用 YOLO11 进行目标打码
- 人工智能混合编程实践:C++调用Python ONNX进行YOLOv8推理
- 人工智能混合编程实践:C++调用封装好的DLL进行YOLOv8实例分割
- 人工智能混合编程实践:C++调用Python ONNX进行图像超分重建
- 人工智能混合编程实践:C++调用Python AgentOCR进行文本识别
- 通过计算实例简单地理解PatchCore异常检测
- Python将YOLO格式实例分割数据集转换为COCO格式实例分割数据集
- YOLOv8 Ultralytics:使用Ultralytics框架训练RT-DETR实时目标检测模型
- 基于DETR的人脸伪装检测
- YOLOv7训练自己的数据集(口罩检测)
- YOLOv8训练自己的数据集(足球检测)
- YOLOv5:TensorRT加速YOLOv5模型推理
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- 玩转Jetson Nano(五):TensorRT加速YOLOv5目标检测
- YOLOv5:添加SE、CBAM、CoordAtt、ECA注意力机制
- YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层
- Python将COCO格式实例分割数据集转换为YOLO格式实例分割数据集
- YOLOv5:使用7.0版本训练自己的实例分割模型(车辆、行人、路标、车道线等实例分割)
- 使用Kaggle GPU资源免费体验Stable Diffusion开源项目
- Stable Diffusion:在服务器上部署使用Stable Diffusion WebUI进行AI绘图(v2.0)
- Stable Diffusion:使用自己的数据集微调训练LoRA模型(v2.0)