【完整源码+数据集+部署教程】【后勤&运输集装箱】集装箱表面腐蚀检测系统源码&数据集全套:改进yolo11-swintransformer
背景意义
随着全球贸易的迅速发展,集装箱作为国际物流的重要载体,其安全性和可靠性日益受到重视。集装箱在海洋运输过程中,常常暴露于恶劣的环境条件下,如高湿度、盐雾和温差变化等,这些因素极易导致集装箱表面发生腐蚀和锈蚀现象。腐蚀不仅影响集装箱的外观,还可能对其结构强度造成严重威胁,进而影响货物的安全。因此,及时、准确地检测集装箱表面的腐蚀情况,对于维护集装箱的使用寿命和确保运输安全具有重要意义。
传统的人工检测方法不仅效率低下,而且容易受到人为因素的影响,导致漏检和误检的情况发生。近年来,随着计算机视觉和深度学习技术的迅猛发展,基于图像处理的自动化检测系统逐渐成为研究热点。YOLO(You Only Look Once)系列目标检测算法因其高效性和实时性,广泛应用于各种物体检测任务。YOLOv11作为该系列的最新版本,具备更强的特征提取能力和更快的检测速度,适合于处理复杂的图像数据。
本研究旨在基于改进的YOLOv11算法,构建一个集装箱表面腐蚀检测系统。我们将利用“Rust_Corrosion_Front_Door_Zoom_Out_yolo_filter_noise_NA_20220719”数据集,该数据集包含108幅图像,涵盖了腐蚀和锈蚀两类目标。通过对该数据集的深入分析和模型训练,我们期望能够提高腐蚀检测的准确性和效率,从而为集装箱的维护和管理提供有力支持。该研究不仅具有重要的理论价值,也为实际应用提供了可行的解决方案,推动了智能检测技术在物流行业的应用进程。
图片效果


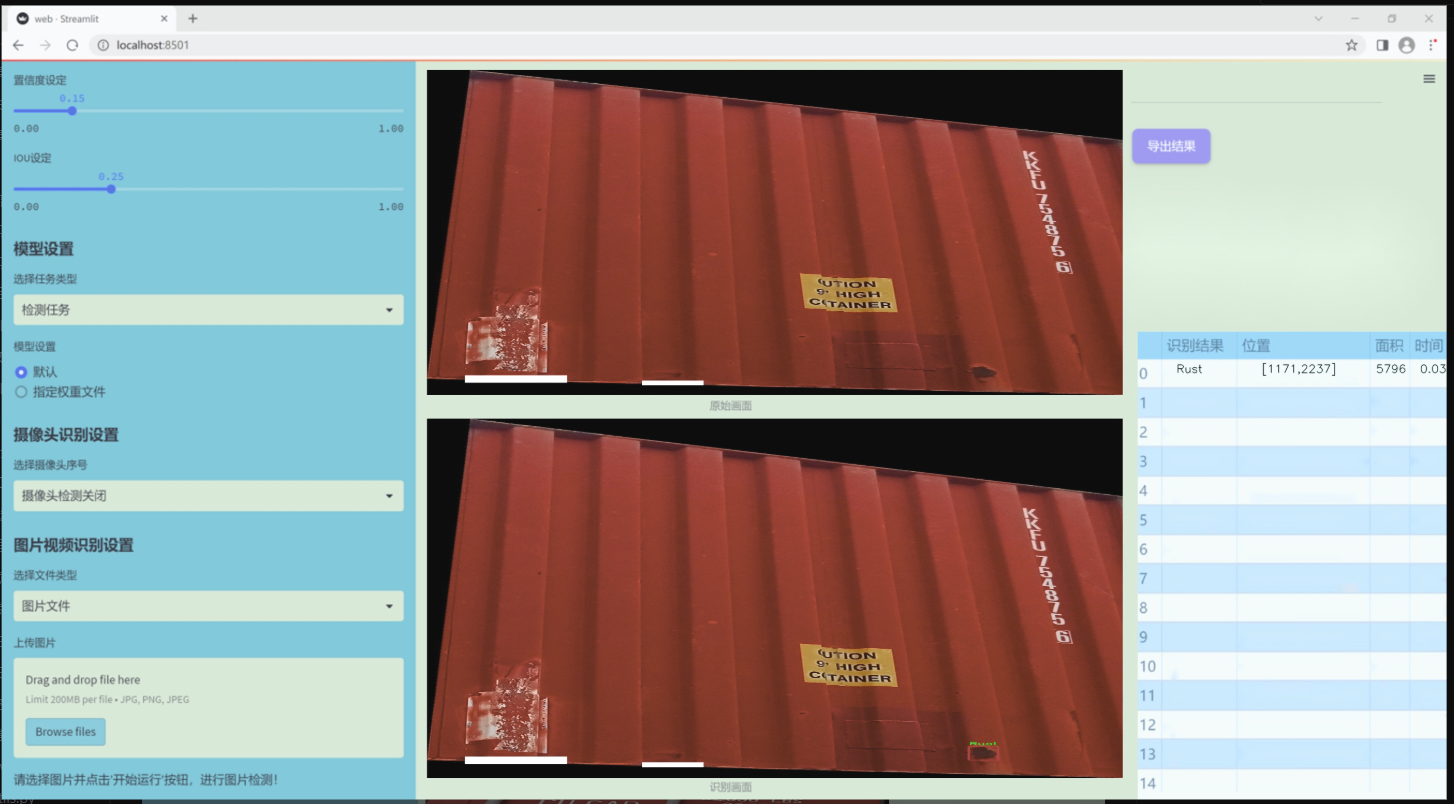
数据集信息
本项目所使用的数据集名为“Rust_Corrosion_Front_Door_Zoom_Out_yolo_filter_noise_NA_20220719”,专门用于训练和改进YOLOv11模型,以实现高效的集装箱表面腐蚀检测。该数据集包含了丰富的图像数据,旨在为模型提供多样化的训练样本,从而提升其在实际应用中的检测准确性和鲁棒性。数据集中共包含两类目标,分别为“Corrosion”(腐蚀)和“Rust”(锈蚀),这两类目标在集装箱表面腐蚀检测中具有重要的实际意义。
数据集中的图像经过精心挑选,涵盖了不同光照条件、角度和背景的样本,以确保模型能够在各种环境下有效识别腐蚀和锈蚀现象。每一张图像都经过标注,明确指出了腐蚀和锈蚀的具体位置,这为模型的训练提供了必要的监督信息。此外,数据集还经过噪声过滤处理,以减少背景干扰,提高目标检测的准确性。
通过使用该数据集,YOLOv11模型能够学习到腐蚀和锈蚀的特征,进而在实际应用中实现对集装箱表面状态的快速评估。随着集装箱运输业的不断发展,集装箱表面的腐蚀问题日益突出,及时发现和处理这些问题对于确保运输安全和降低维护成本至关重要。因此,本项目的数据集不仅具有重要的学术价值,也为实际工业应用提供了强有力的支持。通过对“Rust_Corrosion_Front_Door_Zoom_Out_yolo_filter_noise_NA_20220719”数据集的深入研究和应用,我们期望能够显著提升集装箱表面腐蚀检测的效率和准确性,为相关领域的研究和实践提供新的思路和方法。





核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
from functools import partial
定义线性归一化的函数,使用 LayerNorm 和 RepBN
ln = nn.LayerNorm
linearnorm = partial(LinearNorm, norm1=ln, norm2=RepBN, step=60000)
class TransformerEncoderLayer_RepBN(nn.Module):
def init(self, c1, cm=2048, num_heads=8, dropout=0, act=…, normalize_before=False):
# 初始化 Transformer 编码器层,设置输入通道数、隐藏层维度、头数、dropout、激活函数等参数
super().init()
self.norm1 = linearnorm(c1) # 第一层归一化
self.norm2 = linearnorm(c1) # 第二层归一化
class AIFI_RepBN(TransformerEncoderLayer_RepBN):
“”“定义 AIFI transformer 层。”“”
def __init__(self, c1, cm=2048, num_heads=8, dropout=0, act=nn.GELU(), normalize_before=False):"""使用指定参数初始化 AIFI 实例。"""super().__init__(c1, cm, num_heads, dropout, act, normalize_before)def forward(self, x):"""AIFI transformer 层的前向传播。"""c, h, w = x.shape[1:] # 获取输入张量的通道数、高度和宽度pos_embed = self.build_2d_sincos_position_embedding(w, h, c) # 构建二维正弦余弦位置嵌入# 将输入张量从形状 [B, C, H, W] 展平为 [B, HxW, C]x = super().forward(x.flatten(2).permute(0, 2, 1), pos=pos_embed.to(device=x.device, dtype=x.dtype))# 将输出张量恢复为原始形状并返回return x.permute(0, 2, 1).view([-1, c, h, w]).contiguous()@staticmethod
def build_2d_sincos_position_embedding(w, h, embed_dim=256, temperature=10000.0):"""构建二维正弦余弦位置嵌入。"""assert embed_dim % 4 == 0, "嵌入维度必须是4的倍数,以便进行二维正弦余弦位置嵌入"grid_w = torch.arange(w, dtype=torch.float32) # 创建宽度的网格grid_h = torch.arange(h, dtype=torch.float32) # 创建高度的网格grid_w, grid_h = torch.meshgrid(grid_w, grid_h, indexing="ij") # 生成网格坐标pos_dim = embed_dim // 4 # 计算位置维度omega = torch.arange(pos_dim, dtype=torch.float32) / pos_dim # 计算频率omega = 1.0 / (temperature**omega) # 根据温度调整频率# 计算宽度和高度的正弦余弦嵌入out_w = grid_w.flatten()[..., None] @ omega[None]out_h = grid_h.flatten()[..., None] @ omega[None]# 返回拼接后的正弦余弦位置嵌入return torch.cat([torch.sin(out_w), torch.cos(out_w), torch.sin(out_h), torch.cos(out_h)], 1)[None]
代码说明:
导入库:导入了 PyTorch 相关的库和函数。
线性归一化:使用 LayerNorm 和 RepBN 定义了一个线性归一化的函数,方便后续使用。
TransformerEncoderLayer_RepBN 类:继承自 nn.Module,初始化时设置了两个归一化层。
AIFI_RepBN 类:继承自 TransformerEncoderLayer_RepBN,实现了 AIFI transformer 层的功能。
前向传播:在 forward 方法中,首先获取输入的形状,然后构建位置嵌入,最后调用父类的 forward 方法进行处理,并将输出恢复为原始形状。
构建位置嵌入:build_2d_sincos_position_embedding 方法用于生成二维正弦余弦位置嵌入,确保嵌入维度是4的倍数,并根据输入的宽度和高度计算出位置嵌入。
这个程序文件 transformer.py 实现了一个基于 Transformer 架构的编码器层,主要使用了改进的归一化方法(RepBN)和位置编码(2D 正弦余弦位置编码)。文件中定义了两个类:TransformerEncoderLayer_RepBN 和 AIFI_RepBN。
首先,导入了必要的库,包括 PyTorch 的核心模块和一些自定义的模块。RepBN 和 LinearNorm 是在其他文件中定义的,可能用于改进模型的归一化过程。
接下来,定义了一个名为 linearnorm 的部分函数,它结合了 LayerNorm 和 RepBN,并设置了一个步长参数(step=60000),用于后续的归一化层创建。
TransformerEncoderLayer_RepBN 类继承自 TransformerEncoderLayer,并在初始化时调用父类的构造函数,同时定义了两个归一化层 norm1 和 norm2,这两个层使用了之前定义的 linearnorm。
AIFI_RepBN 类则是 TransformerEncoderLayer_RepBN 的子类,代表了一种特定的 Transformer 层(AIFI)。在其构造函数中,除了传入基本参数外,还默认使用了 GELU 激活函数。它的 forward 方法实现了前向传播,首先获取输入张量的形状信息(通道数、宽度和高度),然后调用 build_2d_sincos_position_embedding 方法生成 2D 的正弦余弦位置编码。接着,将输入张量从形状 [B, C, H, W] 转换为 [B, HxW, C],并调用父类的 forward 方法进行处理,最后将输出重新调整为原始的形状。
build_2d_sincos_position_embedding 是一个静态方法,用于生成 2D 的正弦余弦位置编码。它首先检查嵌入维度是否能被 4 整除,然后生成宽度和高度的网格,并计算相应的正弦和余弦值,最终返回一个包含这些位置编码的张量。
整体来看,这个文件实现了一个增强型的 Transformer 编码器层,利用了新的归一化技术和位置编码方法,以提高模型的性能和表达能力。
10.3 pkinet.py
以下是经过简化并添加详细中文注释的核心代码部分:
import math
import torch
import torch.nn as nn
class DropPath(nn.Module):
“”“实现随机深度(Drop Path)功能的模块,用于在残差块的主路径中随机丢弃路径。”“”
def __init__(self, drop_prob: float = 0.1):super().__init__()self.drop_prob = drop_prob # 丢弃路径的概率def forward(self, x: torch.Tensor) -> torch.Tensor:"""前向传播,应用丢弃路径的操作。"""if self.drop_prob == 0. or not self.training:return x # 如果不丢弃,直接返回输入keep_prob = 1 - self.drop_probshape = (x.shape[0], ) + (1, ) * (x.ndim - 1) # 处理不同维度的张量random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)output = x.div(keep_prob) * random_tensor.floor() # 应用丢弃路径return output
class InceptionBottleneck(nn.Module):
“”“实现Inception模块的瓶颈结构。”“”
def __init__(self, in_channels: int, out_channels: int):super().__init__()self.pre_conv = nn.Conv2d(in_channels, out_channels, kernel_size=1) # 预卷积层self.dw_conv = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1, groups=out_channels) # 深度卷积self.pw_conv = nn.Conv2d(out_channels, out_channels, kernel_size=1) # 点卷积def forward(self, x):"""前向传播,执行Inception瓶颈操作。"""x = self.pre_conv(x) # 通过预卷积层x = self.dw_conv(x) # 通过深度卷积x = self.pw_conv(x) # 通过点卷积return x
class PKINet(nn.Module):
“”“实现Poly Kernel Inception网络的主类。”“”
def __init__(self, arch: str = 'S'):super().__init__()self.stem = nn.Conv2d(3, 32, kernel_size=3, stride=2, padding=1) # Stem层self.blocks = nn.ModuleList([InceptionBottleneck(32, 64), # 添加Inception瓶颈块InceptionBottleneck(64, 128),])def forward(self, x):"""前向传播,依次通过Stem层和Inception瓶颈块。"""x = self.stem(x) # 通过Stem层for block in self.blocks:x = block(x) # 通过每个Inception瓶颈块return x
def PKINET_S():
“”“构建并返回一个PKINet网络实例。”“”
return PKINet(‘S’)
if name == ‘main’:
model = PKINET_S() # 创建PKINET_S模型
inputs = torch.randn((1, 3, 640, 640)) # 生成随机输入
res = model(inputs) # 通过模型进行前向传播
print(res.size()) # 输出结果的尺寸
代码注释说明:
DropPath: 实现了随机深度的功能,允许在训练期间随机丢弃某些路径,以增强模型的泛化能力。
InceptionBottleneck: 该类实现了Inception模块的瓶颈结构,包含预卷积、深度卷积和点卷积的组合,旨在减少参数量和计算量。
PKINet: 这是主网络类,包含一个Stem层和多个Inception瓶颈块,负责处理输入数据并生成输出特征。
PKINET_S: 用于创建一个特定架构的PKINet实例的函数。
主程序: 在主程序中,创建模型实例并通过随机输入进行前向传播,最后输出结果的尺寸。
这个程序文件 pkinet.py 实现了一个名为 PKINet 的深度学习模型,主要用于计算机视觉任务。该模型的结构灵感来源于 Inception 模块,并引入了多种创新的组件,如上下文锚注意力(CAA)和多层感知机(MLP)等。下面是对文件中各个部分的详细说明。
首先,文件导入了一些必要的库,包括数学库、类型提示库以及 PyTorch 和相关的深度学习模块。接着,尝试导入一些来自 mmcv 和 mmengine 的模块,如果导入失败,则使用 PyTorch 的基本模块作为替代。
文件定义了一些工具函数和类。drop_path 函数实现了随机深度(Stochastic Depth)技术,用于在训练过程中随机丢弃某些路径,以增强模型的泛化能力。DropPath 类是对该函数的封装,便于在模型中使用。
autopad 函数用于自动计算卷积操作的填充,确保卷积核的大小为奇数。make_divisible 函数则用于确保通道数能够被指定的因子整除,这在设计模型时非常重要。
接下来,文件定义了一些基本的张量变换类,如 BCHW2BHWC 和 BHWC2BCHW,用于在不同的张量格式之间转换。GSiLU 类实现了一种新的激活函数,结合了全局平均池化和 Sigmoid 激活。
CAA 类实现了上下文锚注意力机制,旨在通过对输入特征图进行平均池化和卷积操作来生成注意力因子。ConvFFN 类实现了一个多层感知机结构,使用卷积模块构建,支持可选的身份连接。
Stem 类和 DownSamplingLayer 类分别实现了模型的初始层和下采样层,负责将输入特征图转换为适合后续处理的格式。InceptionBottleneck 类则实现了一个包含多个卷积操作的瓶颈结构,支持多种卷积核大小和上下文锚注意力。
PKIBlock 类是多核 Inception 模块的实现,结合了前述的各个组件。PKIStage 类则将多个 PKIBlock 组合在一起,形成模型的一个阶段。
最后,PKINet 类是整个模型的核心实现,负责构建网络的各个阶段,并定义前向传播的逻辑。模型的架构设置在 arch_settings 字典中定义,支持不同规模的模型(如 T、S、B),每种模型都有不同的层数和参数配置。
在文件的最后部分,定义了三个函数 PKINET_T、PKINET_S 和 PKINET_B,用于实例化不同规模的 PKINet 模型。在主程序中,创建了一个 PKINET_T 模型实例,并通过随机输入测试了模型的前向传播,输出了各个阶段的特征图尺寸。
总体来说,这个文件实现了一个复杂的深度学习模型,包含了多种先进的技术和结构,适用于图像处理等任务。
10.4 mamba_yolo.py
以下是经过简化和注释的核心代码部分,保留了主要的功能和结构,同时对每个部分进行了详细的中文注释:
import torch
import torch.nn as nn
from einops import rearrange
定义二维层归一化类
class LayerNorm2d(nn.Module):
def init(self, normalized_shape, eps=1e-6, elementwise_affine=True):
super().init()
# 使用 nn.LayerNorm 进行归一化
self.norm = nn.LayerNorm(normalized_shape, eps, elementwise_affine)
def forward(self, x):# 将输入的形状从 (B, C, H, W) 转换为 (B, H, W, C)x = rearrange(x, 'b c h w -> b h w c').contiguous()# 进行归一化x = self.norm(x)# 再次转换回 (B, C, H, W)x = rearrange(x, 'b h w c -> b c h w').contiguous()return x
自适应填充函数,确保输出形状与输入相同
def autopad(k, p=None, d=1): # kernel, padding, dilation
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # 实际的卷积核大小
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # 自动填充
return p
定义交叉扫描的前向传播
class CrossScan(torch.autograd.Function):
@staticmethod
def forward(ctx, x: torch.Tensor):
B, C, H, W = x.shape
ctx.shape = (B, C, H, W)
xs = x.new_empty((B, 4, C, H * W)) # 创建一个新的张量用于存储不同方向的特征
xs[:, 0] = x.flatten(2, 3) # 正常方向
xs[:, 1] = x.transpose(dim0=2, dim1=3).flatten(2, 3) # 水平翻转
xs[:, 2:4] = torch.flip(xs[:, 0:2], dims=[-1]) # 垂直翻转
return xs
@staticmethod
def backward(ctx, ys: torch.Tensor):B, C, H, W = ctx.shapeL = H * W# 反向传播ys = ys[:, 0:2] + ys[:, 2:4].flip(dims=[-1]).view(B, 2, -1, L)y = ys[:, 0] + ys[:, 1].view(B, -1, W, H).transpose(dim0=2, dim1=3).contiguous().view(B, -1, L)return y.view(B, -1, H, W)
定义选择性扫描的核心功能
class SelectiveScanCore(torch.autograd.Function):
@staticmethod
@torch.cuda.amp.custom_fwd
def forward(ctx, u, delta, A, B, C, D=None, delta_bias=None, delta_softplus=False, nrows=1, backnrows=1):
# 确保输入是连续的
if u.stride(-1) != 1:
u = u.contiguous()
if delta.stride(-1) != 1:
delta = delta.contiguous()
if D is not None and D.stride(-1) != 1:
D = D.contiguous()
if B.stride(-1) != 1:
B = B.contiguous()
if C.stride(-1) != 1:
C = C.contiguous()
if B.dim() == 3:
B = B.unsqueeze(dim=1)
ctx.squeeze_B = True
if C.dim() == 3:
C = C.unsqueeze(dim=1)
ctx.squeeze_C = True
ctx.delta_softplus = delta_softplus
ctx.backnrows = backnrows
# 调用 CUDA 核心进行前向计算
out, x, *rest = selective_scan_cuda_core.fwd(u, delta, A, B, C, D, delta_bias, delta_softplus, 1)
ctx.save_for_backward(u, delta, A, B, C, D, delta_bias, x)
return out
@staticmethod
@torch.cuda.amp.custom_bwd
def backward(ctx, dout, *args):u, delta, A, B, C, D, delta_bias, x = ctx.saved_tensorsif dout.stride(-1) != 1:dout = dout.contiguous()# 调用 CUDA 核心进行反向计算du, ddelta, dA, dB, dC, dD, ddelta_bias, *rest = selective_scan_cuda_core.bwd(u, delta, A, B, C, D, delta_bias, dout, x, ctx.delta_softplus, 1)return (du, ddelta, dA, dB, dC, dD, ddelta_bias, None, None, None, None)
定义简单的卷积网络结构
class SimpleStem(nn.Module):
def init(self, inp, embed_dim, ks=3):
super().init()
self.hidden_dims = embed_dim // 2
self.conv = nn.Sequential(
nn.Conv2d(inp, self.hidden_dims, kernel_size=ks, stride=2, padding=autopad(ks, d=1), bias=False),
nn.BatchNorm2d(self.hidden_dims),
nn.GELU(),
nn.Conv2d(self.hidden_dims, embed_dim, kernel_size=ks, stride=2, padding=autopad(ks, d=1), bias=False),
nn.BatchNorm2d(embed_dim),
nn.SiLU(),
)
def forward(self, x):return self.conv(x)
定义一个视觉线索合并模块
class VisionClueMerge(nn.Module):
def init(self, dim, out_dim):
super().init()
self.hidden = int(dim * 4)
self.pw_linear = nn.Sequential(
nn.Conv2d(self.hidden, out_dim, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(out_dim),
nn.SiLU()
)
def forward(self, x):# 通过下采样合并特征y = torch.cat([x[..., ::2, ::2],x[..., 1::2, ::2],x[..., ::2, 1::2],x[..., 1::2, 1::2]], dim=1)return self.pw_linear(y)
代码解释
LayerNorm2d: 实现了二维层归一化,适用于图像数据。
autopad: 计算卷积操作的自动填充,确保输出与输入的空间维度相同。
CrossScan: 定义了交叉扫描操作,用于处理输入特征的不同方向。
SelectiveScanCore: 实现了选择性扫描的前向和反向传播逻辑,依赖于 CUDA 核心进行高效计算。
SimpleStem: 一个简单的卷积网络结构,用于特征提取。
VisionClueMerge: 通过下采样合并特征图,增加特征的表达能力。
以上代码片段是原始代码的核心部分,经过简化并添加了详细的中文注释,以便于理解其功能和结构。
这个程序文件 mamba_yolo.py 是一个用于构建深度学习模型的代码,主要涉及计算机视觉领域,特别是 YOLO(You Only Look Once)系列模型的实现。文件中使用了 PyTorch 框架,包含了多个自定义的神经网络模块和函数,下面是对代码的详细说明。
首先,文件导入了一些必要的库,包括 torch、math、functools 和 torch.nn,这些库提供了构建和训练神经网络所需的基础功能。此外,还导入了 einops 库用于张量重排,以及 timm 库中的 DropPath 类用于实现随机深度的丢弃。
接下来,定义了一个 LayerNorm2d 类,它是对 2D 数据进行层归一化的实现。该类的 forward 方法通过调整张量的维度来实现层归一化。
然后,定义了一个 autopad 函数,用于根据卷积核的大小和填充方式自动计算填充的大小,以确保输出的形状与输入相同。
接着,定义了多个自定义的 PyTorch 自动求导函数,如 CrossScan 和 CrossMerge,这些函数实现了特定的张量操作,主要用于在网络中进行交叉扫描和合并操作。
在 SelectiveScanCore 类中,定义了一个选择性扫描的核心功能,该功能用于在特定条件下选择性地处理输入数据。这个类的 forward 和 backward 方法实现了前向传播和反向传播的逻辑。
cross_selective_scan 函数是一个用于执行选择性扫描的高层接口,它接收多个输入参数并返回处理后的输出。该函数内部调用了 SelectiveScan 类,执行复杂的张量操作。
SS2D 类是一个重要的模块,结合了选择性扫描和卷积操作。它的构造函数定义了多个参数,如模型的维度、状态维度、卷积核大小等,并初始化了相应的层和参数。forward 方法实现了该模块的前向传播逻辑。
接下来,定义了 RGBlock 和 LSBlock 类,这些类实现了特定的网络块结构,通常用于构建更复杂的网络架构。它们包含卷积层、激活函数和归一化层。
XSSBlock 和 VSSBlock_YOLO 类是网络的主要构建块,结合了之前定义的模块,构建了具有选择性扫描功能的复杂网络结构。这些类的构造函数定义了输入输出通道、隐藏维度、正则化等参数,并在 forward 方法中实现了前向传播逻辑。
SimpleStem 类是一个简单的网络前端,负责将输入图像转换为特征图。它使用了两个卷积层和激活函数。
最后,VisionClueMerge 类用于合并不同来源的特征图,增强模型的特征提取能力。
总体来说,这个文件实现了一个复杂的深度学习模型,结合了选择性扫描、卷积操作和多种网络结构,适用于计算机视觉任务,尤其是目标检测和图像识别。
注意:由于此博客编辑较早,上面“10.YOLOv11核心改进源码讲解”中部分代码可能会优化升级,仅供参考学习,以“11.完整训练+Web前端界面+200+种全套创新点源码、数据集获取”的内容为准。
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻