【AI论文】MemMamba:对状态空间模型中记忆模式的重新思考
摘要:随着数据的爆炸式增长,长序列建模在自然语言处理和生物信息学等任务中变得愈发重要。然而,现有方法在效率和内存之间面临固有的权衡。循环神经网络存在梯度消失和梯度爆炸问题,难以扩展规模。Transformer模型能够建模全局依赖关系,但受限于二次复杂度。近期,诸如Mamba等选择性状态空间模型展现出了高效性,其时间复杂度为O(n),循环推理复杂度为O(1),但其长程记忆却呈指数级衰减。在本研究中,我们通过数学推导和信息论分析,系统地揭示了Mamba模型记忆衰减的机制,回答了一个基本问题:Mamba长程记忆的本质是什么,以及它是如何保留信息的?为了量化关键信息的损失,我们进一步引入了水平和垂直记忆保真度指标,以捕捉层内和层间的信息退化情况。受人类阅读长文档时如何提炼并保留重要信息的启发,我们提出了MemMamba这一新型架构框架,它集成了状态总结机制以及跨层和跨标记注意力机制,在保持线性复杂度的同时,缓解了长程遗忘问题。在PG19和密码检索等长序列基准测试中,MemMamba相较于现有的Mamba变体和Transformer模型取得了显著提升,同时推理效率提升了48%。理论分析和实证结果均表明,MemMamba在复杂度与内存的权衡方面实现了突破,为超长序列建模提供了新的范式。Huggingface链接:Paper page,论文链接:2510.03279
研究背景和目的
研究背景:
随着大数据时代的到来,长序列建模在自然语言处理、生物信息学等领域的重要性日益凸显。
传统的序列建模方法,如循环神经网络(RNNs)及其变体(LSTM、GRU),由于存在梯度消失和梯度爆炸问题,难以处理长距离依赖关系。尽管Transformer模型通过自注意力机制和全局上下文建模,在一定程度上解决了这些问题,但其二次复杂度在处理超长序列时仍显得效率低下。近期,选择性状态空间模型(SSMs),特别是Mamba架构,展示了高效的长序列建模能力,时间复杂度为O(n),递归推理复杂度为O(1)。然而,Mamba及其后续变体在长距离记忆保持方面仍存在显著缺陷,随着序列长度的增加,早期信息的贡献呈指数级衰减,导致模型在需要强记忆保持的任务上表现不佳。
研究目的:
本研究旨在通过系统性分析Mamba模型的记忆衰减机制,提出一种新的架构MemMamba,以解决长序列建模中的记忆衰减问题。具体目标包括:
- 揭示Mamba模型的记忆衰减机制:通过数学推导和信息论分析,量化Mamba模型在处理长序列时的信息损失。
- 提出MemMamba架构:集成状态总结机制、跨层和跨令牌注意力,以减轻长距离遗忘问题,同时保持线性复杂度。
- 验证MemMamba的有效性:在多个长序列基准测试上评估MemMamba的性能,展示其在语言建模、稀疏检索和跨文档推理任务上的显著改进。
研究方法
1. 记忆衰减机制分析:
本研究首先通过数学推导和信息论分析,揭示Mamba模型在处理长序列时的记忆衰减机制。
具体步骤包括:
- 定义信息贡献:量化早期输入对当前状态的影响,并推导出信息贡献随距离增加的指数衰减规律。
- 引入水平-垂直记忆保真度框架:提出期望令牌记忆保真度(ETMF)和期望跨层记忆保真度(ECLMF)两个指标,分别衡量令牌级语义传输和跨层信息耦合中的信息损失。
2. MemMamba架构设计:
基于上述分析,本研究设计了MemMamba架构,主要创新点包括:
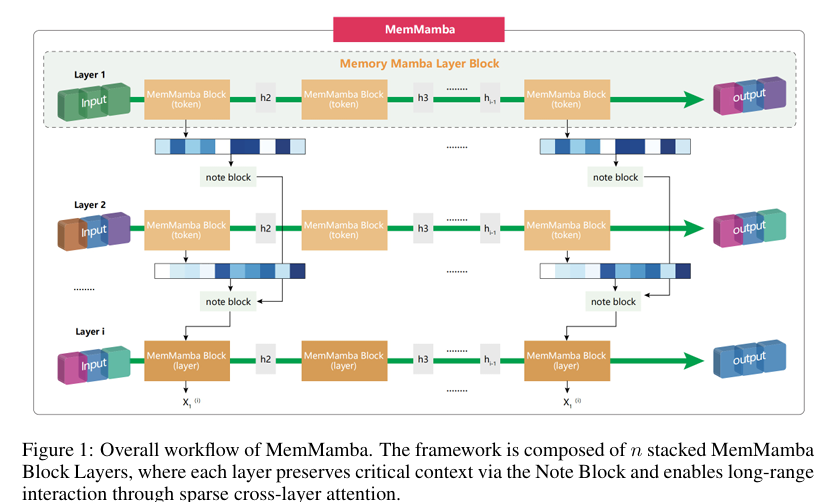
- 状态总结机制:通过Note Block动态识别和提取关键信息,压缩并存储重要令牌到状态池中,模拟人类阅读长文档时的笔记行为。
- 跨令牌和跨层注意力:在每个MemMamba块层中集成跨令牌注意力和周期性触发的跨层注意力,以恢复被遗忘的信息并促进跨层信息交互。
- 稀疏跨层注意力:为避免冗余计算,跨层注意力仅在每p层激活一次,通过聚合前几层的状态摘要实现跨层上下文补充。
3. 实验设置:
- 数据集:在PG19-PPL、Passkey Retrieval和Document Retrieval等长序列基准测试上评估MemMamba的性能。
- 模型配置:MemMamba是一个24层的SSM模型,每个状态摘要向量压缩到64维,状态池大小固定为50。
- 训练设置:使用AdamW优化器,学习率为1e-4,权重衰减为0.1,训练序列长度为8000个令牌,训练步数为100k步。
研究结果
1. 记忆保真度提升:
MemMamba通过状态总结和跨层/跨令牌注意力机制,显著提升了模型在长序列处理中的记忆保真度。
实验结果表明,在PG19语言建模任务上,MemMamba在60k令牌长度下仍能保持稳定的困惑度(17.35),而Mamba和DeciMamba等基线模型在相同长度下表现急剧下降。
2. 性能显著提升:
在多个长序列基准测试上,MemMamba均取得了显著优于基线模型的性能。
具体而言:
- 语言建模:在PG19数据集上,MemMamba的困惑度显著低于Mamba、DeciMamba和Transformer等基线模型。
- 稀疏检索:在Passkey Retrieval任务上,MemMamba在400k令牌长度下仍能保持90%的检索准确率,而Mamba和Pythia等模型在相同长度下表现不佳。
- 跨文档推理:在Document Retrieval任务上,MemMamba在噪声条件下的表现显著优于Transformer和Mamba变体,展示了其强大的跨文档和跨域推理能力。
3. 效率提升:
尽管引入了额外的计算以增强建模能力,MemMamba在推理效率上仍实现了48%的提升。
在相同硬件条件下,MemMamba的端到端延迟仅为Transformer的0.52倍,展示了其在长序列处理中的高效性。
研究局限
尽管MemMamba在长序列建模中取得了显著进展,但仍存在一些局限性:
1. 状态池大小的限制:
MemMamba中的状态池大小固定为50,这在一定程度上限制了模型对极端长序列的处理能力。
未来研究可以探索动态调整状态池大小的方法,以更好地适应不同长度的序列。
2. 跨层注意力触发的周期性:
跨层注意力仅在每p层激活一次,这可能导致在某些情况下跨层信息交互不足。
未来研究可以探索更灵活的跨层注意力触发机制,以进一步提升模型的记忆保持能力。
3. 复杂指令理解能力的局限:
尽管MemMamba在长序列建模中表现出色,但其对复杂指令的理解能力仍有限。
未来研究可以探索将MemMamba与更先进的自然语言处理技术相结合,以提升其对复杂指令的理解和执行能力。
未来研究方向
针对上述局限,未来的研究可以从以下几个方面展开:
1. 动态状态池管理:
研究动态调整状态池大小的方法,根据序列长度和任务需求动态分配状态池资源,以更好地适应不同长度的序列和复杂度的任务。
2. 自适应跨层注意力机制:
探索自适应的跨层注意力触发机制,根据序列特性和任务需求灵活调整跨层注意力的触发频率和范围,以进一步提升模型的记忆保持能力和计算效率。
3. 多模态长序列建模:
将MemMamba架构扩展到多模态领域,研究如何处理包含文本、图像、音频等多种模态的长序列数据,提升模型在多模态任务上的表现。
4. 与先进自然语言处理技术的融合:
将MemMamba与预训练语言模型、知识图谱等先进自然语言处理技术相结合,提升模型对复杂指令的理解和执行能力,推动长序列建模技术在更多实际应用场景中的落地。
5. 实际应用场景的探索:
将MemMamba应用于虚拟现实、增强现实、智能设计等实际场景中,通过实际应用验证技术的有效性和实用性,并收集用户反馈以进一步优化模型性能。