2.CUDA编程模型
2. CUDA编程模型
引言:简述以下块,网格,线程的关系。
Grid(网格)
└── Block(块)└── Thread(线程)
线程(Thread):最基本的执行单位,对应一段程序(kernel)的一次执行。
块(Block):一组线程的集合,通常是 1D、2D 或 3D。
网格(Grid):一组块的集合,也可以是 1D、2D 或 3D。
线程在块内的索引(局部索引)
int tx = threadIdx.x;
int ty = threadIdx.y;➤ 块在网格中的索引
int bx = blockIdx.x;
int by = blockIdx.y;➤ 每个块内的维度(大小)
int blockDim.x; // 每个 block 的 x 方向线程数
int blockDim.y; // 每个 block 的 y 方向线程数➤ 全局线程索引(矩阵坐标)
int ix = tx + bx * blockDim.x;
int iy = ty + by * blockDim.y;➤ 一维数组中的全局索引(线性化)
int idx = iy * nx + ix; // 注意这里 nx 是行宽(x方向元素个数)👉 这个公式:
idx = iy * nx + ix;这个表达式的含义是:将二维坐标(ix, iy)转换为一维数组下标 idx,以便访问内存中对应元素。
2.1 CUDA模型编程概述
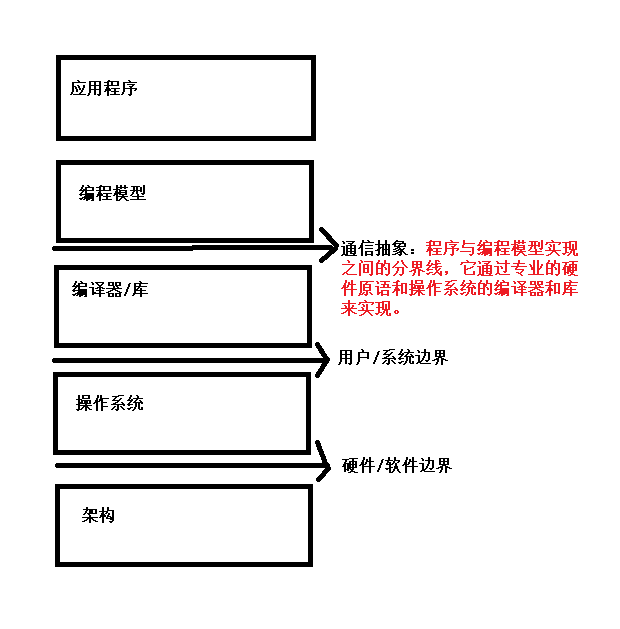
2.1.1 CUDA编程结构
CUDA编程模型使用由C语言扩展生成的注释代码在异构计算系统中执行应用程序。在一个异构环境中包含多个CPU与GPU,每个CPU与GPU的内存由一条PCI-Express总线分隔开。
主机:CPU及其内存。(主机内存) 变量名 h_开头
设备:GPU及其内存。(设备内存) 变量名 d_开头
2.1.2 CUDA内存管理
GPU内存分配函数:
cudaError_t cudaMalloc(void** devPtr, size_t size)
GPU拷贝内存函数:
cudaError_t cudaMemcpy(void* dst,const void* src,size_t count,cudaMemcpyKind kind);
cudaMemcpyKind 有以下几种:
cudaMemcpyHostToHost
cudaMemcpyHostToDevice
cudaMemcpyDeviceToHost
cudaMemcpyDeviceToDevice
返回值cudaError_t :
cudaSuccess :成功
cudaErrorMemoryAllocation
如何将其转为可读的错误信息:
char* cudaGetErrorString(cudaError_t error);
GPU内存结构主要包含两部分:全局内存与共享内存
2.1.3 实现两个数组相加
2.1.3.1 cpu(主机端)
#include<stdio.h>
#include<string.h>
#include<time.h>
void sumArrayOnHost(float* a, float* b,float* c,const int n) {for(int i = 0; i < n; ++i) {c[i] = a[i] + b[i];}
}
void initData(float* ip,int size) {time_t t;srand((unsigned int) time(&t));for(int i = 0; i < size; ++i) {ip[i] = (float)(rand() & 0xFF) / 10;}
}int main() {int n = 1024;size_t n_bytes = n * sizeof(float);float* h_a,*h_b,*h_c;h_a = (float*) malloc(n_bytes);h_b = (float*) malloc(n_bytes);h_c = (float*) malloc(n_bytes);initData(h_a,n);initData(h_b,n);sumArrayOnHost(h_a,h_b,h_c,n);free(h_a);free(h_b);free(h_c);h_a = NULL;h_b = NULL;h_c = NULL;return 0;
}
2.1.3.2 gpu(设备端)
#include<stdio.h>
#include<string.h>
#include<time.h>
__global__ void sumArrayOnHost(float* a, float* b,float* c,const int n) {int i = blockIdx.x * blockDim.x + threadIdx.x;if(i < n) {c[i] = a[i] + b[i];}
}
void initData(float* ip,int size) {time_t t;srand((unsigned int) time(&t));for(int i = 0; i < size; ++i) {ip[i] = (float)(rand() & 0xFF) / 10;//printf("ip[i]: %d\t",ip[i]);}
}int main() {int n = 1024;size_t n_bytes = n * sizeof(float);float* h_a,*h_b,*h_c;h_a = (float*) malloc(n_bytes);h_b = (float*) malloc(n_bytes);h_c = (float*) malloc(n_bytes);initData(h_a,n);initData(h_b,n);float* d_a,*d_b,*d_c;cudaMalloc((float**)&d_a ,n_bytes );cudaMalloc((float**)&d_b ,n_bytes );cudaMalloc((float**)&d_c,n_bytes );cudaMemcpy( d_a,h_a ,n_bytes , cudaMemcpyHostToDevice);cudaMemcpy( d_b, h_b,n_bytes , cudaMemcpyHostToDevice);int blockSize = 256;//每个网格中启动256个线程int gridSize = (n + blockSize - 1) / blockSize;//确保有足够多的线程来处理这些数sumArrayOnHost<<<gridSize ,blockSize>>>(d_a,d_b,d_c,n);cudaMemcpy( h_c, d_c,n_bytes , cudaMemcpyDeviceToHost);for(int i = 0; i < n; ++i) {printf("%f ",h_c[i]);if(i % 10 == 0) {printf("\n");}}printf("\n");free(h_a);free(h_b);free(h_c);cudaFree(d_a);cudaFree(d_b);cudaFree(d_c);d_a = NULL;d_b = NULL;d_c = NULL;h_a = NULL;h_b = NULL;h_c = NULL;return 0;
}
2.1.4 线程管理
网格概念:由一个内核启动所产生的所有线程称之为网格。同一网格中的所有线程共享相同的全局内存空间。一个网格由多个线程块构成,一个线程块包含一组线程。
线程块:其含有一组线程,同一线程内的线程协作可通过同步与共享内存实现。
几个变量说下把:
blockIdx:当前 block 在整个 grid 中的编号
blockDim:每个block的线程数
threadIdx:局部线程的Id
-
1D 一维,只用x,y、z为1,默认是有xyz三个维度的
int i = blockIdx.x * blockDim.x + threadIdx.x;
-
2D 二维
int x = blockIdx.x * blockDim.x + threadIdx.x; // 横向坐标
int y = blockIdx.y * blockDim.y + threadIdx.y; // 纵向坐标
if (x < width && y < height) {
int idx = y * width + x; // 映射到 1D 索引
img[idx] = 255 - img[idx]; // 图像反转}
启动方式:
dim3 block(16, 16); // 每个 block 256 线程(16x16)
dim3 grid((width+15)/16, (height+15)/16);
processImage<<<grid, block>>>(d_img, width, height); -
3D 三维
__global__ void kernel3D(float* volume, int X, int Y, int Z) {
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
int z = blockIdx.z * blockDim.z + threadIdx.z;if (x < X && y < Y && z < Z) {
int idx = z * X * Y + y * X + x; // 3D 映射为 1D volume[idx] = some_operation(x, y, z);
}
}
2.1.5 启动一个CUDA核函数
kernel_name<<<4,8>>> (argument list)
grid:块
block:8个元素

和函数的调用与主机线程是异步的,核函数调用结束后,会立即返回给主机端,你可以调用以下函数来让主机端程序等待所有的核函数执行完成:
cudaError_t cudaDeviceSynchronize(void)
2.1.6 编写核函数
__global__ 开头的函数:在设备端运行。
__device__开头的函数:在设备端运行。
__host__开头的函数:在主机端运行。
2.1.7 处理错误
#define CHECK(call)
{const cudaError_t error = call;if(error != cudaSuccess) {printf("Error :%s %d",__LINE__,__LINE__);printf("code :%d,reason:%s\n",error,cudaGetErrorString(error));exit(1);}
}
2.1.8 编译和执行
#include<cuda_runtime.h>
#include<stdio.h>
#include<stdlib.h>
#define CHECK(call) \do { \const cudaError_t error = call; \if (error != cudaSuccess) { \printf("CUDA Error: %s:%d, ", __FILE__, __LINE__); \printf("code: %d, reason: %s\n", error, cudaGetErrorString(error)); \exit(1); \} \} while (0)
void checkResult(float* hostRef, float* gpuRef,const int n) {double ep = 1.0E-8;bool match = 1;for(int i = 0; i < n; ++i) {if(abs(hostRef[i] - gpuRef[i]) > ep) {match = 0;printf("array not match\n");break;}}if(match) {printf("array match\n");}
}
void initData(float* ip,const int size) {time_t t;srand((unsigned)time(&t));for(int i = 0; i < size; ++i) {ip[i] = (float)(rand() & 0xFF ) /10;}
}
void sumArrayOnHost(float* a, float* b,float* c,const int size) {for(int i = 0; i < size; ++i) {c[i] = a[i] + b[i];}
}
__global__ void sumArrayOnDevice(float* a ,float* b,float* c,const int size) {int i = threadIdx.x;c[i] = a[i] + b[i];
}
int main() {int dev = 0;cudaSetDevice(dev);int nElem = 32;printf("vector size:%d\n",nElem);size_t n_Bytes = nElem * sizeof(float);float* h_a,*h_b,*hostRef,*gpuRef;h_a =(float*) malloc(n_Bytes);h_b =(float*) malloc(n_Bytes);hostRef =(float*) malloc(n_Bytes);gpuRef =(float*) malloc(n_Bytes);initData(h_a,nElem);initData(h_b,nElem);memset(hostRef,0,n_Bytes);memset(gpuRef,0,n_Bytes);float* d_a,*d_b,*d_c;cudaMalloc( (float**)&d_a,n_Bytes );cudaMalloc( (float**)&d_b,n_Bytes );cudaMalloc( (float**)&d_c,n_Bytes );cudaMemcpy( d_a,h_a ,n_Bytes , cudaMemcpyHostToDevice);cudaMemcpy( d_b,h_b ,n_Bytes , cudaMemcpyHostToDevice);dim3 block(nElem);dim3 grid(nElem / block.x);printf("nElem/block.x = %d\n",(nElem / block.x)); //32/32sumArrayOnDevice<<<grid,block>>>(d_a,d_b,d_c,nElem);printf("config for gpu <<<%d,%d>>>\n",grid.x,block.x);//1,32cudaMemcpy( gpuRef,d_c ,n_Bytes , cudaMemcpyDeviceToHost);sumArrayOnHost(h_a,h_b,hostRef,nElem);cudaFree(d_a);cudaFree(d_b);cudaFree(d_c);free(h_a);free(h_b);free(hostRef);free(gpuRef);return 0;
}2.2 给核函数计时
2.2.1 用cpu计时器计时
#include<cuda_runtime.h>
#include<stdio.h>
#include<sys/time.h>
#define CHECK(call) \do { \const cudaError_t error = call; \if (error != cudaSuccess) { \printf("CUDA Error: %s:%d, ", __FILE__, __LINE__); \printf("code: %d, reason: %s\n", error, cudaGetErrorString(error)); \exit(1); \} \} while (0)
double cpuSecond() {struct timeval tp;gettimeofday(&tp,NULL);return ((double)tp.tv_sec + (double)tp.tv_usec*1e-6);}
void checkResult(float* hostRef, float* gpuRef,const int n) {double ep = 1.0E-8;bool match = 1;for(int i = 0; i < n; ++i) {if(abs(hostRef[i] - gpuRef[i]) > ep) {match = 0;printf("array not match\n");break;}}if(match) {printf("array match\n");}
}
void initData(float* ip,const int size) {time_t t;srand((unsigned)time(&t));for(int i = 0; i < size; ++i) {ip[i] = (float)(rand() & 0xFF ) /10;}
}
void sumArrayOnHost(float* a, float* b,float* c,const int size) {for(int i = 0; i < size; ++i) {c[i] = a[i] + b[i];}
}
__global__ void sumArrayOnDevice(float* a ,float* b,float* c,const int size) {int i = blockIdx.x * blockDim.x + threadIdx.x;if(i < size) {c[i] = a[i] + b[i];}}
int main() {int dev = 0;/*struct cudaDeviceProp {char name[256]; // GPU 名称size_t totalGlobalMem; // 全局内存总量(单位:字节)size_t sharedMemPerBlock; // 每个 Block 的共享内存大小int regsPerBlock; // 每个 Block 可用的寄存器数量int warpSize; // 一个 warp 中线程数量(通常是 32)size_t memPitch; // 最大可分配的内存宽度int maxThreadsPerBlock; // 每个 Block 支持的最大线程数int maxThreadsDim[3]; // 每个 Block 支持的最大维度int maxGridSize[3]; // 每个 Grid 支持的最大维度int clockRate; // 时钟频率(单位:kHz)size_t totalConstMem; // 常量内存总量int major; // Compute Capability 主版本号int minor; // Compute Capability 次版本号size_t textureAlignment; // 纹理对齐要求size_t texturePitchAlignment; // 纹理行对齐要求int deviceOverlap; // 是否支持设备重叠int multiProcessorCount; // SM 多处理器数量int kernelExecTimeoutEnabled; // 内核执行是否超时(仅限图形设备)int integrated; // 是否为集成显卡int canMapHostMemory; // 是否可以映射主机内存int computeMode; // 计算模式int maxTexture1D; // 最大 1D 纹理尺寸int maxTexture2D[2]; // 最大 2D 纹理尺寸int maxTexture3D[3]; // 最大 3D 纹理尺寸int concurrentKernels; // 是否支持多个并发 Kernelint pciBusID; // PCI 总线 IDint pciDeviceID; // PCI 设备 IDint tccDriver; // 是否是 TCC 驱动int memoryClockRate; // 内存时钟频率int memoryBusWidth; // 内存总线宽度(单位:bit)int l2CacheSize; // L2 缓存大小int maxThreadsPerMultiProcessor; // 每个 SM 可运行的最大线程数int unifiedAddressing; // 是否支持统一内存寻址int computeCapabilityMajor; // 与 major 重复(不同 CUDA 版本可能使用此字段)int computeCapabilityMinor; // 与 minor 重复// 还有其他字段,视 CUDA 版本而定
};*/cudaDeviceProp deviceProp;cudaGetDeviceProperties( &deviceProp,dev );//获取第一个gpu的信息。CHECK(cudaSetDevice(dev));//测试gpu是否可用int nElem = 1 << 27;printf("vector size : %d\n",nElem);size_t nBytes = nElem * sizeof(float);float* h_a ,*h_b,*hostRef,*gpuRef;h_a =(float*) malloc(nBytes);h_b =(float*) malloc(nBytes);hostRef =(float*) malloc(nBytes);gpuRef =(float*) malloc(nBytes);double iStart,iElaps;iStart = cpuSecond();initData(h_a,nElem);initData(h_b,nElem);iElaps = cpuSecond() - iStart;memset(hostRef,0,nBytes);memset(gpuRef,0,nBytes);clock_t start = clock();sumArrayOnHost(h_a,h_b,hostRef,nElem);clock_t end = clock();double cpu_time_used = (double)(end - start) / CLOCKS_PER_SEC;printf("cpu cost : %f sec\n",cpu_time_used);float* d_a,*d_b,*d_c;cudaMalloc((float**)&d_a ,nBytes );cudaMalloc((float**)&d_b ,nBytes );cudaMalloc((float**)&d_c ,nBytes );cudaMemcpy( d_a,h_a ,nBytes , cudaMemcpyHostToDevice);cudaMemcpy( d_b,h_b ,nBytes , cudaMemcpyHostToDevice);int iLen = 1024;dim3 block(iLen);dim3 grid((nElem + block.x - 1) / block.x);start = clock();sumArrayOnDevice<<<grid,block>>>(d_a,d_b,d_c,nElem);cudaDeviceSynchronize();end = clock();cpu_time_used = (double)(end - start) / CLOCKS_PER_SEC;printf("sumArrayOnDevice<<<%d,%d>>>:cost:%f sec\n",grid.x,block.x,cpu_time_used);cudaMemcpy( gpuRef,d_c ,nBytes , cudaMemcpyDeviceToHost);checkResult(hostRef,gpuRef,nElem);cudaFree(d_a);cudaFree(d_b);cudaFree(d_c);free(h_a);free(h_b);free(hostRef);free(gpuRef);return 0;}
//
vector size : 134217728
cpu cost : 0.540000 sec
sumArrayOnDevice<<<131072,1024>>>:cost:0.000000 sec
array match
2.2.2 nvprof工具计时–已弃用
nvprof --help
nvprof [nvprof_args] [application_args]
用这个:
需要配置,在个人账户~/.bashrc 里面:export PATH=/usr/local/cuda/nsight-compute-2020.2.1/${PATH:+:${PATH}}
ncu ./jishi --》需要sudo,没有sudo运行不了。
2.3 组织并行线程
2.3.1 使用块和线程建立矩阵索引
一般情况下,我们需要管理3个索引:
- 线程和块的索引
- 矩阵中给定点的坐标。
- 全局线性内存中的偏移量。
step1:用以下公式把线程和块索引映射到矩阵坐标上。
ix = threadIdx.x + blockIdx.x * blockDim.x //当前线程在 x 方向的全局坐标
iy = threadIdx.y + blockIdx.y * blockDim.y //当前线程在 y 方向的全局坐标
step2:用以下公式将矩阵坐标映射到全局内存的索引/存储单元上。
idx = iy*nx + ix (nx 表示x 的方向数)
#include<stdio.h>
#include<cuda_runtime.h>
#define CHECK(call) \do { \const cudaError_t error = call; \if (error != cudaSuccess) { \printf("CUDA Error: %s:%d, ", __FILE__, __LINE__); \printf("code: %d, reason: %s\n", error, cudaGetErrorString(error)); \exit(1); \} \} while (0)
void init_data(float *p,const int size) {for(int i = 0;i < size; ++i) {p[i] = i;}
}
void print_check(float *c ,const int nx, const int ny) {float* ic = c;printf("nx : %d \t ny :%d \n",nx,ny);for(int i = 0 ;i < ny ; ++i) {for(int y = 0; y < nx; ++y) {printf("%f\t",ic[y]);}ic += nx;printf("\n");}printf("\n");
}
__global__ void printThreadIndex(float *a,const int nx, const int ny) {int ix = blockIdx.x * blockDim.x + threadIdx.x;int iy = blockIdx.y * blockDim.y + threadIdx.y;unsigned int idx = iy * nx + ix;printf("thread_id :(%d,%d) block_id:(%d,%d),coordinate:(%d,%d) global_index :%2d,ival :%2f\n",threadIdx.x,threadIdx.y,blockIdx.x,blockIdx.y,ix,iy,idx,a[idx]);
}
int main() {int dev = 0;cudaDeviceProp deviceProp;CHECK(cudaGetDeviceProperties( &deviceProp,dev ));printf("using device :%d\t name :%s \n",dev,deviceProp.name);CHECK(cudaSetDevice(dev));int nx = 6;int ny = 8;int nxy = nx * ny;int nBytes = nxy * sizeof(float);float *h_a;h_a = (float*) malloc(nBytes);memset(h_a,0,nBytes);init_data(h_a,nxy);print_check(h_a,nx,ny);float* d_a;cudaMalloc( (void**)&d_a,nBytes);cudaMemcpy( d_a, h_a,nBytes , cudaMemcpyHostToDevice);dim3 block(4,2);dim3 grid((nx + block.x - 1)/block.x, (ny + block.y -1)/ block.y);printThreadIndex<<<grid,block>>>(d_a,nx,ny);cudaDeviceSynchronize();cudaFree( d_a);free(h_a);cudaDeviceReset();return 0;}using device :0 name :GeForce RTX 3090
nx : 6 ny :8
0.000000 1.000000 2.000000 3.000000 4.000000 5.000000
6.000000 7.000000 8.000000 9.000000 10.000000 11.000000
12.000000 13.000000 14.000000 15.000000 16.000000 17.000000
18.000000 19.000000 20.000000 21.000000 22.000000 23.000000
24.000000 25.000000 26.000000 27.000000 28.000000 29.000000
30.000000 31.000000 32.000000 33.000000 34.000000 35.000000
36.000000 37.000000 38.000000 39.000000 40.000000 41.000000
42.000000 43.000000 44.000000 45.000000 46.000000 47.000000thread_id :(0,0) block_id:(0,1),coordinate:(0,2) global_index :12,ival :12.000000
thread_id :(1,0) block_id:(0,1),coordinate:(1,2) global_index :13,ival :13.000000
thread_id :(2,0) block_id:(0,1),coordinate:(2,2) global_index :14,ival :14.000000
thread_id :(3,0) block_id:(0,1),coordinate:(3,2) global_index :15,ival :15.000000
thread_id :(0,1) block_id:(0,1),coordinate:(0,3) global_index :18,ival :18.000000
thread_id :(1,1) block_id:(0,1),coordinate:(1,3) global_index :19,ival :19.000000
thread_id :(2,1) block_id:(0,1),coordinate:(2,3) global_index :20,ival :20.000000
thread_id :(3,1) block_id:(0,1),coordinate:(3,3) global_index :21,ival :21.000000
thread_id :(0,0) block_id:(1,1),coordinate:(4,2) global_index :16,ival :16.000000
thread_id :(1,0) block_id:(1,1),coordinate:(5,2) global_index :17,ival :17.000000
thread_id :(2,0) block_id:(1,1),coordinate:(6,2) global_index :18,ival :18.000000
thread_id :(3,0) block_id:(1,1),coordinate:(7,2) global_index :19,ival :19.000000
thread_id :(0,1) block_id:(1,1),coordinate:(4,3) global_index :22,ival :22.000000
thread_id :(1,1) block_id:(1,1),coordinate:(5,3) global_index :23,ival :23.000000
thread_id :(2,1) block_id:(1,1),coordinate:(6,3) global_index :24,ival :24.000000
thread_id :(3,1) block_id:(1,1),coordinate:(7,3) global_index :25,ival :25.000000
thread_id :(0,0) block_id:(1,0),coordinate:(4,0) global_index : 4,ival :4.000000
thread_id :(1,0) block_id:(1,0),coordinate:(5,0) global_index : 5,ival :5.000000
thread_id :(2,0) block_id:(1,0),coordinate:(6,0) global_index : 6,ival :6.000000
thread_id :(3,0) block_id:(1,0),coordinate:(7,0) global_index : 7,ival :7.000000
thread_id :(0,1) block_id:(1,0),coordinate:(4,1) global_index :10,ival :10.000000
thread_id :(1,1) block_id:(1,0),coordinate:(5,1) global_index :11,ival :11.000000
thread_id :(2,1) block_id:(1,0),coordinate:(6,1) global_index :12,ival :12.000000
thread_id :(3,1) block_id:(1,0),coordinate:(7,1) global_index :13,ival :13.000000
thread_id :(0,0) block_id:(1,3),coordinate:(4,6) global_index :40,ival :40.000000
thread_id :(1,0) block_id:(1,3),coordinate:(5,6) global_index :41,ival :41.000000
thread_id :(2,0) block_id:(1,3),coordinate:(6,6) global_index :42,ival :42.000000
thread_id :(3,0) block_id:(1,3),coordinate:(7,6) global_index :43,ival :43.000000
thread_id :(0,1) block_id:(1,3),coordinate:(4,7) global_index :46,ival :46.000000
thread_id :(1,1) block_id:(1,3),coordinate:(5,7) global_index :47,ival :47.000000
thread_id :(2,1) block_id:(1,3),coordinate:(6,7) global_index :48,ival :0.000000
thread_id :(3,1) block_id:(1,3),coordinate:(7,7) global_index :49,ival :0.000000
thread_id :(0,0) block_id:(0,2),coordinate:(0,4) global_index :24,ival :24.000000
thread_id :(1,0) block_id:(0,2),coordinate:(1,4) global_index :25,ival :25.000000
thread_id :(2,0) block_id:(0,2),coordinate:(2,4) global_index :26,ival :26.000000
thread_id :(3,0) block_id:(0,2),coordinate:(3,4) global_index :27,ival :27.000000
thread_id :(0,1) block_id:(0,2),coordinate:(0,5) global_index :30,ival :30.000000
thread_id :(1,1) block_id:(0,2),coordinate:(1,5) global_index :31,ival :31.000000
thread_id :(2,1) block_id:(0,2),coordinate:(2,5) global_index :32,ival :32.000000
thread_id :(3,1) block_id:(0,2),coordinate:(3,5) global_index :33,ival :33.000000
thread_id :(0,0) block_id:(0,3),coordinate:(0,6) global_index :36,ival :36.000000
thread_id :(1,0) block_id:(0,3),coordinate:(1,6) global_index :37,ival :37.000000
thread_id :(2,0) block_id:(0,3),coordinate:(2,6) global_index :38,ival :38.000000
thread_id :(3,0) block_id:(0,3),coordinate:(3,6) global_index :39,ival :39.000000
thread_id :(0,1) block_id:(0,3),coordinate:(0,7) global_index :42,ival :42.000000
thread_id :(1,1) block_id:(0,3),coordinate:(1,7) global_index :43,ival :43.000000
thread_id :(2,1) block_id:(0,3),coordinate:(2,7) global_index :44,ival :44.000000
thread_id :(3,1) block_id:(0,3),coordinate:(3,7) global_index :45,ival :45.000000
thread_id :(0,0) block_id:(1,2),coordinate:(4,4) global_index :28,ival :28.000000
thread_id :(1,0) block_id:(1,2),coordinate:(5,4) global_index :29,ival :29.000000
thread_id :(2,0) block_id:(1,2),coordinate:(6,4) global_index :30,ival :30.000000
thread_id :(3,0) block_id:(1,2),coordinate:(7,4) global_index :31,ival :31.000000
thread_id :(0,1) block_id:(1,2),coordinate:(4,5) global_index :34,ival :34.000000
thread_id :(1,1) block_id:(1,2),coordinate:(5,5) global_index :35,ival :35.000000
thread_id :(2,1) block_id:(1,2),coordinate:(6,5) global_index :36,ival :36.000000
thread_id :(3,1) block_id:(1,2),coordinate:(7,5) global_index :37,ival :37.000000
thread_id :(0,0) block_id:(0,0),coordinate:(0,0) global_index : 0,ival :0.000000
thread_id :(1,0) block_id:(0,0),coordinate:(1,0) global_index : 1,ival :1.000000
thread_id :(2,0) block_id:(0,0),coordinate:(2,0) global_index : 2,ival :2.000000
thread_id :(3,0) block_id:(0,0),coordinate:(3,0) global_index : 3,ival :3.000000
thread_id :(0,1) block_id:(0,0),coordinate:(0,1) global_index : 6,ival :6.000000
thread_id :(1,1) block_id:(0,0),coordinate:(1,1) global_index : 7,ival :7.000000
thread_id :(2,1) block_id:(0,0),coordinate:(2,1) global_index : 8,ival :8.000000
thread_id :(3,1) block_id:(0,0),coordinate:(3,1) global_index : 9,ival :9.000000
2.3.2 使用二维网格和二维块对矩阵求和
#include<stdio.h>
#include<cuda_runtime.h>
#include<sys/time.h>
#define CHECK(call) \do { \const cudaError_t error = call; \if (error != cudaSuccess) { \printf("CUDA Error: %s:%d, ", __FILE__, __LINE__); \printf("code: %d, reason: %s\n", error, cudaGetErrorString(error)); \exit(1); \} \} while (0)
void init_data(float *p,const int size) {for(int i = 0;i < size; ++i) {p[i] = i;}
}
void print_check(float *c ,const int nx, const int ny) {float* ic = c;printf("nx : %d \t ny :%d \n",nx,ny);for(int i = 0 ;i < ny ; ++i) {for(int y = 0; y < nx; ++y) {printf("%f\t",ic[y]);}ic += nx;printf("\n");}printf("\n");
}
__global__ void printThreadIndex(float *a,const int nx, const int ny) {int ix = blockIdx.x * blockDim.x + threadIdx.x;int iy = blockIdx.y * blockDim.y + threadIdx.y;unsigned int idx = iy * nx + ix;printf("thread_id :(%d,%d) block_id:(%d,%d),coordinate:(%d,%d) global_index :%2d,ival :%2f\n",threadIdx.x,threadIdx.y,blockIdx.x,blockIdx.y,ix,iy,idx,a[idx]);
}
void SumOnHost(float* a, float* b,float*c ,const int nx, const int ny) {float* ia = a;float* ib = b;float* ic = c;for(int i = 0; i < ny; ++i) {for(int j = 0; j < nx; ++j) {ic[j] = ia[j] + ib[j]; }ic += nx;ib += nx;ia += nx;}
}
__global__ void SumOnDevice(float* a, float* b,float* c,const int nx,const int ny) {unsigned int ix = blockIdx.x * blockDim.x + threadIdx.x;unsigned int iy = blockIdx.y * blockDim.y + threadIdx.y;int idx = iy * nx + ix;if(ix < nx && iy < ny) {c[idx] = a[idx] + b[idx];}
}
void checkResult(float* hostRef, float* gpuRef,const int n) {double ep = 1.0E-8;bool match = 1;for(int i = 0; i < n; ++i) {if(abs(hostRef[i] - gpuRef[i]) > ep) {match = 0;printf("array not match\n");break;}}if(match) {printf("array match\n");}
}
int main() {int dev = 0;cudaDeviceProp deviceProp;CHECK(cudaGetDeviceProperties( &deviceProp,dev ));printf("using device :%d\t name :%s \n",dev,deviceProp.name);CHECK(cudaSetDevice(dev));int nx = 1 << 14;int ny = 1 << 14;int nxy = nx * ny;int nBytes = nxy * sizeof(float);float *h_a,*h_b,*hostRef,*gpuRef;h_a = (float*) malloc(nBytes);h_b = (float*) malloc(nBytes);hostRef = (float*) malloc(nBytes);gpuRef = (float*) malloc(nBytes);memset(h_a,0,nBytes);init_data(h_a,nxy);init_data(h_b,nxy);memset(hostRef,0,nBytes);double start = clock();SumOnHost(h_a,h_b,hostRef,nx,ny);double end = clock();double cpu_time_used = (double)(end - start) / CLOCKS_PER_SEC;printf("cpu cost : %f sec\n",cpu_time_used);// print_check(h_a,nx,ny);float* d_a,*d_b,*d_c;cudaMalloc( (void**)&d_a,nBytes);cudaMemcpy( d_a, h_a,nBytes , cudaMemcpyHostToDevice);cudaMalloc( (void**)&d_b,nBytes);cudaMemcpy( d_b, h_b,nBytes , cudaMemcpyHostToDevice);cudaMalloc( (void**)&d_c,nBytes);int dimx = 32,dimy = 16;dim3 block(dimx,dimy);dim3 grid((nx + block.x - 1)/block.x, (ny + block.y -1)/ block.y);start = clock();printf("grid:<%d,%d>,block:<%d,%d>\n",grid.x,grid.y,block.x,block.y);SumOnDevice<<<grid,block>>>(d_a,d_b,d_c,nx,ny);cudaDeviceSynchronize();CHECK(cudaGetLastError());cudaMemcpy(gpuRef,d_c ,nBytes , cudaMemcpyDeviceToHost);end = clock();double gpu_time_used = (double)(end - start) / CLOCKS_PER_SEC;printf("gpu cost : %f sec\n",gpu_time_used);checkResult(hostRef,gpuRef,nxy);cudaFree( d_a);cudaFree( d_b);cudaFree( d_c);free(h_a);free(h_b);free(hostRef);free(gpuRef);cudaDeviceReset();return 0;}
如果是使用一维网格的话,
dim3 block(32);
dim3 grid((nx + block.x -1) / block.x , ny);
核函数:
__global__ void sumOnDevice() {
unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;
unsigned int iy = blockIdx.x;
int idx = iy * nx + ix;
}
为什么 iy = blockIdx.y?
因为 block 是 一维的,所以没有 threadIdx.y,每个 block 只占一行。
2.4 补充
怎么查询gpu
nvidia-smi
cudaDeviceSynchronize();
CHECK(cudaGetLastError());
cudaMemcpy(gpuRef,d_c ,nBytes , cudaMemcpyDeviceToHost);
end = clock();
double gpu_time_used = (double)(end - start) / CLOCKS_PER_SEC;
printf(“gpu cost : %f sec\n”,gpu_time_used);
checkResult(hostRef,gpuRef,nxy);
cudaFree( d_a);
cudaFree( d_b);
cudaFree( d_c);
free(h_a);
free(h_b);
free(hostRef);
free(gpuRef);
cudaDeviceReset();
return 0;
}
如果是使用一维网格的话,dim3 block(32);dim3 grid((nx + block.x -1) / block.x , ny);核函数:\_\_global\_\_ void sumOnDevice() { unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x; unsigned int iy = blockIdx.x; int idx = iy * nx + ix; }为什么 `iy = blockIdx.y`?因为 block 是 **一维的**,所以没有 `threadIdx.y`,每个 block 只占一行。## 2.4 补充怎么查询gpunvidia-smi