临床研究标志物发现与机制探索:纯数据挖掘与“实验+服务”一站式方案,如何选择?
在临床研究中,你是否也曾面临这样的困惑:
有人基于48万人的大规模队列做临床数据挖掘,最终成果仅发表于4区期刊;有人投入大量精力构建药物疗效预测模型,却得到不足0.7的AUC,且无法解释“为何药物对部分患者无效”;渴望开展高价值研究,却苦于难以突破“临床指标关联”的局限,无法深入揭示疾病的分子机制……
本文将通过3篇真实研究文献,系统对比【纯临床数据挖掘】与我们公司推出的【临床蛋白质组学解决方案】(涵盖感染、癌症、诊断、预后等多个临床产品),帮助你明确何种方案能够真正支撑你的研究目标——无论是发表高分论文,还是发现具备转化潜力的生物标志物。
一、首先明确:两者本质区别是什么?
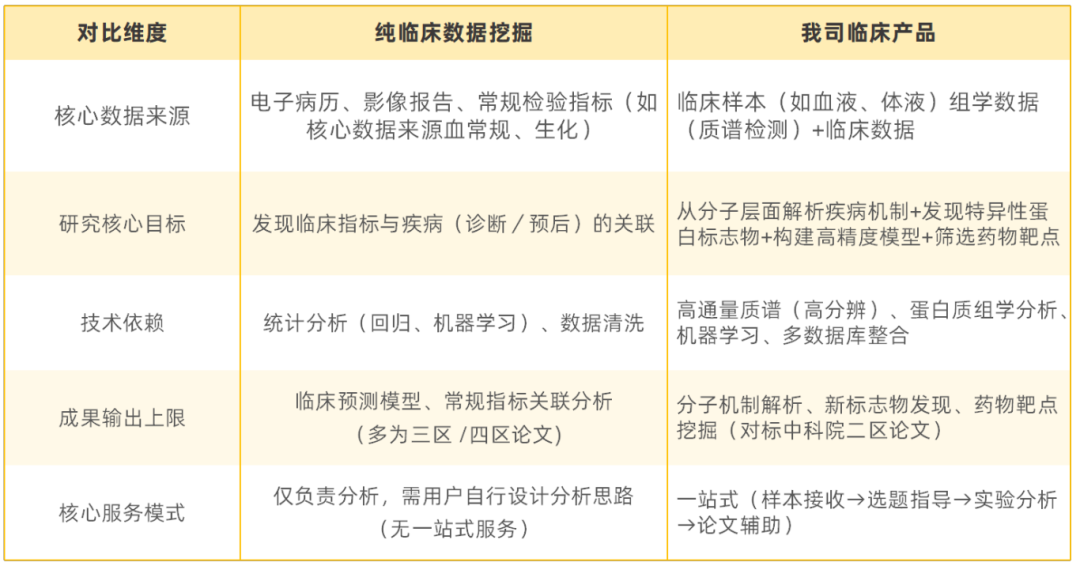
在深入比较之前,我们首先厘清两者在核心理念上的差异——主要体现在数据来源与研究价值两个层面:
1. 纯临床数据挖掘
该方法基于医院现有的临床数据(如电子病历、检验指标、影像报告、随访记录等),运用统计分析(如回归分析、生存分析)或机器学习算法,挖掘数据间的关联性(例如某一检验指标升高与疾病预后不良相关),进而筛选潜在标志物或推测疾病相关因素。
其核心是干数据分析——不产生新的实验数据,仅通过算法盘活已有临床信息,研究边界通常局限于“临床指标间的关联推测”。
2. 我们的临床产品(蛋白质组学解决方案)
该方案以生物标志物发现+分子机制探索为核心,走湿实验+干分析+全流程服务路线:
✦ 首先通过高通量质谱技术从临床样本中获取新的分子数据(蛋白质表达谱);
✦ 进而结合临床数据(检验结果、随访信息等)进行整合分析,利用机器学习方法(如Lasso回归、XGBoost)筛选可靠标志物,并通过通路分析、蛋白互作网络、免疫微环境等深入探索分子机制;
✦ 此外,提供从“选题指导→样本处理→实验设计→数据分析→论文撰写辅助”的一站式服务,并针对不同产品(感染/癌症/诊断/预后/体液/组织)进行个性化分析适配。
二、四大核心维度,系统对比两者差异
维度1:研究深度
“关联推测”VS“实证+机制”
纯临床数据挖掘的最大短板,是难以触及“分子机制”的本质,哪怕队列再大、分析流程再完整,也难掩研究深度上的不足。
以下两项纯数据挖掘研究即是例证:
◆ 一项研究利用UK Biobank 48万人的大队列,整合饮食调查与感染诊断数据,进行了多变量回归、中介分析(探索HbA1c、WBC、BMI的介导效应)。流程看似完整规范,但所谓的机制分析,不过是“饮食→临床指标→感染”的关联链,本质还是临床指标的相互作用,最终文章只能发表在4区期刊[1];
◆ 另一项针对1314例下呼吸道感染患者的研究,构建了机器学习模型以预测哌拉西林-他唑巴坦(TZP)的疗效。结果模型AUC仅为0.69,更关键的是,由于缺乏分子层面数据,研究无法解释“为何TZP对部分患者无效”,既未能识别耐药相关靶点,也无法优化给药方案,研究价值大打折扣,影响因子自然不高(IF 2.8)[2]。
相比之下,我们的临床产品从分子实验切入,将研究推向更深层次:
◆ 标志物更直接:比如感染性疾病方案,用高分辨质谱检测患者样本的蛋白质表达,直接筛选出与感染诊断/预后强相关的蛋白标志物,比临床检验指标更具特异性;
◆ 机制更透彻:不只是找标志物,更通过多维度分析探索机制。比如感染方案的宿主-病毒互作网络(揭示病毒蛋白与人体蛋白的相互作用)、癌症方案的免疫微环境评估,直接给出疾病发生发展的分子线索;
◆ 对标高分论文:交付报告对标中科院二区文章90%的工作量,比如差异蛋白的GO/KEGG/DO富集、机器学习建模、趋势聚类分析、药物靶点筛选等,这些都是高分论文的核心内容。
维度2:数据价值
“盘活旧数据”VS“产生新数据+多维度整合”
纯临床数据挖掘的优势在于有效利用现有数据,但其数据维度存在固有局限:
◆ 依赖已收集的临床数据(自建或公开数据库),多为宏观指标(如年龄、性别、实验室检验),缺乏微观分子数据(如蛋白、基因),难以满足深度机制研究的需求;
◆ 数据创新性不足,若仅使用常规临床数据进行挖掘,易导致研究同质化,创新意义易受质疑,且面临被同类研究抢先发表的风险,难以支撑高水平论文。
我们的临床产品则致力于创造新数据+整合多维度信息,显著提升研究的创新性:
◆ 生成独家分子数据:通过质谱、蛋白质检测等实验,获取临床样本的蛋白质组数据(或其他分子数据),这些数据是研究者独有,能为论文提供核心创新点;
◆ 多维度数据整合:将分子数据(如蛋白表达)+临床数据(如检验、随访)+表型数据(如疾病分期)相结合进行综合分析。例如,在感染方案的预测模型中同时纳入临床数据和蛋白标志物,可获得更优的临床预测性能;
◆ 数据可复用性强:获取的蛋白组数据可用于其他分析(如基于DGIdb数据库进行药物靶点筛选,寻找蛋白靶向药物),延伸研究价值。
维度3:服务落地性
“仅提供分析”VS“从选题到论文全程支持”
临床研究常见的痛点在于多环节相互脱节:收集样本、做实验、联系分析公司、撰写论文,每个环节都要踩坑试错。
纯临床数据挖掘的服务边界很清晰——只负责数据分析,剩下的全靠研究者自己:
◆ 研究者需自行确定研究方向、处理样本、解读分析结果,并承担因“选题不当、样本不合格”导致研究失败的风险;
◆ 在论文撰写阶段,仅能获得分析图表,缺乏对结果的深度解读和论文框架的专业指导,新手很难独立完成高分论文。
我们的临床产品则是一站式服务,帮助研究者规避所有中间环节的困扰:
◆ 前期:提供选题指导(结合你的临床方向推荐创新点)、样本方案设计、样本匹配等支持;
◆ 中期:全流程实验+分析(从质谱检测到生信分析,比如感染方案应用多种机器学习算法构建预测模型,并对差异蛋白进行信号通路探索);
◆ 后期:交付可直接用于论文撰写的素材。包括高质量图表、详细的结果描述(中英文对照且按期刊论文格式撰写)、结果摘要等,其内容深度与工作量对标中科院二区论文标准,大大降低论文撰写难度。
维度4:转化潜力
“初步筛选”VS“从发现到验证雏形”
临床研究的最终目标在于成果转化(如开发诊断试剂、建立预后模型、发现药物靶点)。
然而,纯临床数据挖掘在转化应用方面能力较弱:
◆ 其所筛选的“标志物”多为关联线索,缺乏实验验证(如蛋白水平的验证、独立队列的验证),距离实际临床应用仍有较大差距;
◆ 难以提供“可直接落地的工具”——例如,基于纯临床指标构建的预后预测模型,其泛化能力往往较差,难以在不同医疗机构间推广应用。
一项发表于中科院一区的研究对比了纯临床指标与蛋白分类器在预测COVID-19患者28天死亡率方面的表现[3]:
◆ 基于纯临床指标(CRP、NLR、年龄)的模型AUC仅为0.60-0.74,即便是常用的国际综合评分(如4C Mortality评分、E-CURB65评分),本质仍是临床指标的加权组合,最高AUC仅达0.8,标志物价值有限且泛化能力欠佳;
◆ 而基于血浆蛋白质组学构建的蛋白分类器,在发现队列和验证队列中AUC均超过0.8,不仅预测准确性更高,还能通过蛋白质功能分析阐释“为何该蛋白能预测死亡”,为后续诊断试剂的开发提供了明确靶点。
这正是我们临床产品的核心优势所在——设计之初即充分考虑转化需求:
◆ 标志物具备实验支撑:通过高通量实验发现的蛋白标志物,可直接进入后续验证阶段(如WB、ELISA);
◆ 提供可落地的模型/靶点:例如,临床产品所构建的预测模型可直接在独立队列中进行验证;通过数据库(如DGIdb、DrugBank)筛选药物靶点,为后续药物研发提供方向;
◆ 符合临床转化逻辑:蛋白质组学数据来源于真实临床样本,模型基于真实世界数据构建,这些特性使得研究成果更易于向临床实践转化。
为清晰总结两者的核心差异,请见下图:纯数据挖掘VS“实验+服务”方案:
三、我们的临床产品矩阵:总有一款契合你的研究需求
我们的临床产品已全面覆盖研究目的(诊断、预后)、样本类型(体液、组织)、高发疾病(感染、癌症)等核心应用场景。所有产品均以“生物标志物发现+分子机制探索”为核心,服务模式一致,并通过“个性化分析”适配不同研究定位。具体产品信息请参阅各产品主页链接:
◆ 按研究目的:诊断产品聚焦高特异性标志物筛选与诊断模型构建(诊断生物标志物研究一站式解决方案);预后产品侧重患者生存预测模型构建(预后生物标志物研究一站式解决方案);
◆ 按样本类型:体液样本产品(血液、尿液、唾液)适配无创/微创研究需求,重点挖掘体液特异性标志物及免疫反应相关特征(体液生物标志物研究一站式解决方案);组织样本产品(冻存组织、FFPE、活检组织)聚焦局部微环境探索,获取病灶特异性蛋白,发现疾病亚型(临床组织样本蛋白质组研究一站式解决方案);
◆ 按疾病领域:感染产品致力于筛选诊断/预后标志物、药物靶点,解析感染免疫机制、宿主-病毒互作关系(感染性疾病研究一站式解决方案);癌症产品注重预后评估、肿瘤微环境分析及网络药理学分析(癌症分子机制研究一站式解决方案)。
以下为我司临床产品支持下已成功发表的部分学术论文:

若你正在开展临床研究,并期望:
✦ 发现有实验支撑的可靠生物标志物、深入揭示疾病分子机制;
✦ 进行疾病诊断、预后预测/研究特定疾病/利用已有的体液、组织样本;
✦ 发表中科院二区及以上论文;
✦ 省却选题、样本处理、数据分析、论文撰写中的繁琐环节;
✦ 推动研究成果向临床转化(如诊断模型、药物靶点开发);