[Linux系统编程——Lesson16.Ext系列⽂件系统]



目录
前言
本节重点
一、💾磁盘
1-1💧认识磁盘
1-2 🔥磁盘的存储结构
1-3 🤔如何定位扇区
二、🐧磁盘存储的逻辑抽象结构
2-1 🕵️♀️理解过程
2-2 真实过程
🔥CHS && LBA地址
三、📂⽂件系统
3-1🍕 引⼊"块"概念(Block)
3-2 🍔引⼊"分区"概念
3-3 🍟引⼊"inode"概念
四、📂ext2 ⽂件系统
4-1 🍕宏观认识
格式化:
4-2🍔 Block Group
4-3 🍟块组内部构成
4-3-1 🦌超级块(Super Block)
1️⃣核心功能
2️⃣存储的关键信息
3️⃣容错机制:多副本备份
4️⃣核心重要性
4-3-2 🐕GDT(Group Descriptor Table)(组描述)
1️⃣核心功能
2️⃣每个块组描述符存储的关键信息
3️⃣冗余设计:多副本备份
4️⃣与超级块的配合关系
总结
4-3-3 🐈⬛块位图(Block Bitmap)
1️⃣核心功能
2️⃣工作原理
3️⃣关键特性
4️⃣与其他结构的协同工作
5️⃣核心重要性
总结
4-3-4 🐎inode位图(Inode Bitmap)
1️⃣核心功能
2️⃣工作原理
3️⃣关键特性
4️⃣与其他结构的协同工作
5️⃣核心重要性
总结
4-3-5🦬 i节点表(Inode Table)
1️⃣核心功能
2️⃣存储的关键信息(文件属性)
3️⃣关键特性
4️⃣与其他结构的协同工作
5️⃣核心重要性
总结
4-3-6 🐘数据块(Data Block)
1️⃣核心功能
2️⃣关键特性
3️⃣不同文件类型的数据存储方式
4️⃣与其他结构的协同工作
5️⃣核心重要性
总结
4-4 🍕inode和datablock映射(弱化)
1️⃣基本结构与设计逻辑
小结
五、🔥核心回顾🔥
1️⃣“增”:基于 inode 号创建新文件(或扩展文件)
2️⃣“删”:删除 inode 号对应的文件
3️⃣“查”:查询 inode 号对应的文件信息
4️⃣“改”:修改 inode 号对应的文件
总结
六、🕵️♀️结论
1️⃣格式化的本质:构建文件系统的 “管理骨架”
2️⃣inode 号:文件在分区内的 “全局唯一标识”
3️⃣inode:文件的 “全景信息枢纽”
总结:文件系统的核心逻辑链
七、📂创建文件的整体步骤
1️⃣ 存储属性:分配并初始化 inode
2️⃣存储数据:分配数据块并写入内容
3️⃣记录分配情况:建立 inode 与数据块的映射
4️⃣添加文件名到目录:建立 “文件名→inode 号” 的映射
总结:创建文件的逻辑闭环
八、 🤔重新认识⽬录与⽂件名
1️⃣为什么日常访问文件不用直接操作 inode 号?
2️⃣目录的本质:特殊的「映射文件」
1. 目录是文件的核心依据
2. 目录的关键特性(与普通文件的区别)
3️⃣延伸思考:当前工作目录的作用
总结
8-1 🍕路径解析的底层逻辑:从根目录到目标文件的「递归寻址」
1️⃣路径解析的核心:从根目录开始的「逐层查表」
2️⃣当前工作目录(CWD)的作用:简化路径的「相对起点」
3️⃣路径的起源:系统与用户共同构建的「目录树」
总结:路径解析的本质是「从根目录出发的索引链」
九、🔥路径缓存(dentry 机制):内存中的目录树与性能优化
十、🐧挂载分区:跨分区文件访问的底层逻辑
1️⃣inode 的「分区边界」:为何不能跨分区?
2️⃣挂载(mount):分区与目录的「绑定桥梁」
3️⃣路径前缀:判断文件所属分区的「钥匙」
4️⃣总结:挂载让多分区融入统一目录树
十一、🔥⽂件系统总结🔥
结束语:
前言
在前一篇文章中我们谈到了操作系统如何管理进程打开的文件,通过一个struct files_struct来对文件进行描述,组织和管理的。
但是并不是所有的文件都是打开的,上一篇文章中讲到的内容都是文件系统管理被打开的文件的操作,但是大部分文件都是未被打开的,这些未打开的文件都存在于磁盘中,这些文件同样也需要被管理,那么接下来要讲解文件系统对于在磁盘中未被打开的文件的管理,对于这部分文件,文件系统最重要的工作就是快速定位这些文件,也就是通过路径快速找到我们所以需要处理的文件。接下来我们将学习Ext系列⽂件系统
本节重点
- 理解磁盘物理结构
- 掌握CHS和LBA地址
- 掌握Ext系列文件系统原理
- 理解分区,格式化,路径解析,挂载等过程和操作
- 理解软硬连接使用和用途
一、💾磁盘
1-1💧认识磁盘
磁盘是一种用于存储和检索数据的数据存储设备,通常是计算机系统中的重要组成部分。它是一种非易失性存储设备,意味着它可以在断电后保持数据的存储状态。磁盘以其数据存储介质为基础,根据其工作原理和使用场景的不同,可以分为多种类型,包括硬盘驱动器(Hard Disk Drive,HDD)和固态硬盘(Solid State Drive,SSD)等。
磁盘是电脑上的唯一机械设备,磁盘是永久性介质,掉电数据不会丢失。
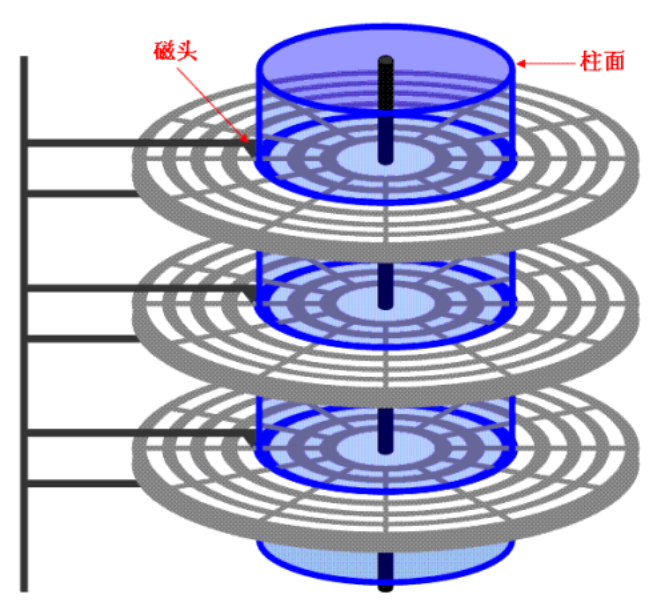
其中一个磁盘有很多盘片,一个盘片又有两个盘面,盘面上可以进行读写数据。
- 磁盘主要分为六个部分组成:马达,盘面,磁头,磁力臂,永磁铁,控制电路。
上图也可以看到,盘面其实不止一个,有多个盘面,每个盘面上都记录着数据,每个盘面都搭配一个磁头。
下图为一个盘面的示意图。

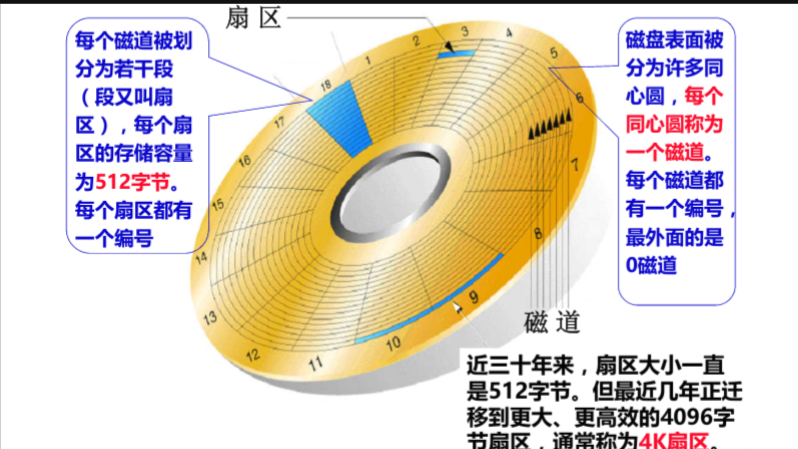
1-2 🔥磁盘的存储结构
- 磁盘上的数据都是0,1序列,计算机只能读懂0和1。可以将盘面理解为由上亿个小吸铁石组成的,而因为每个小吸铁石都有南北极之分,就可以用南极表示0,用北极表示1的方式来存储0,1序列;而通过电池脉冲的方式可以将南北逆置,进而实现0,1序列的写入。表示0和1的方式有很多,磁盘选取的是南北极的方式,其他存储介质就不一定了。
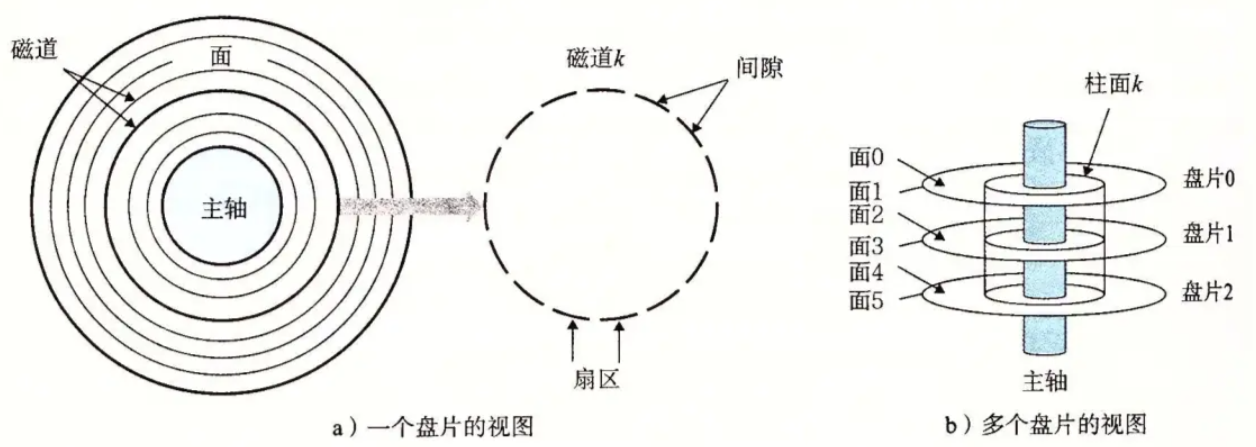
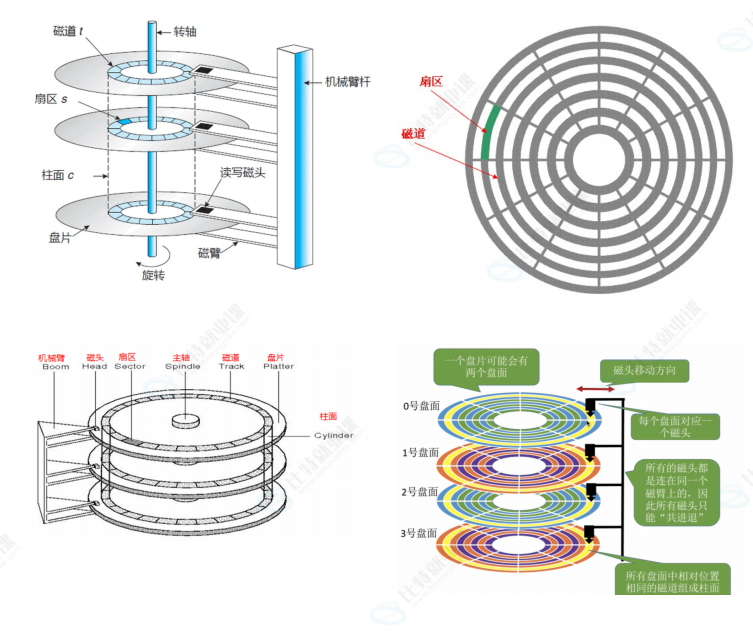
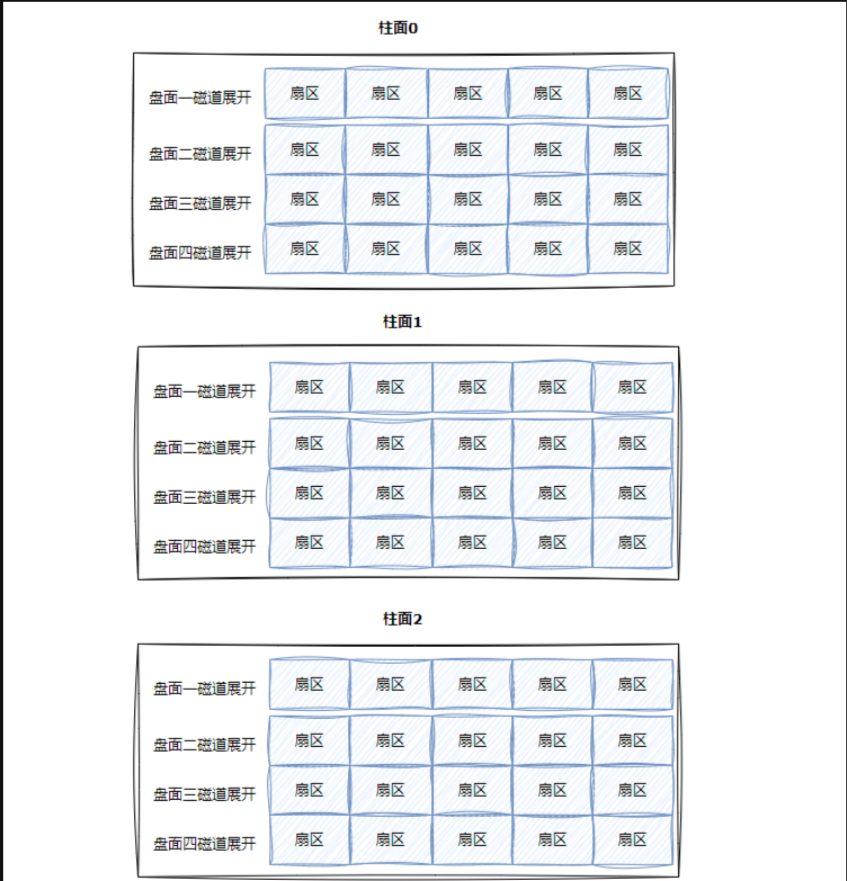
- 一个磁盘中有多个盘片,一个盘片有两个盘面,每一面对应着有一个磁头,一个盘面由许多同心磁道组成,一个磁道中又对应则多个扇区,通过磁臂的左右移动与磁盘的旋转,磁头可以读取到磁盘的任意位置,我们将磁盘上所有相同半径的磁道的集合叫做柱面。
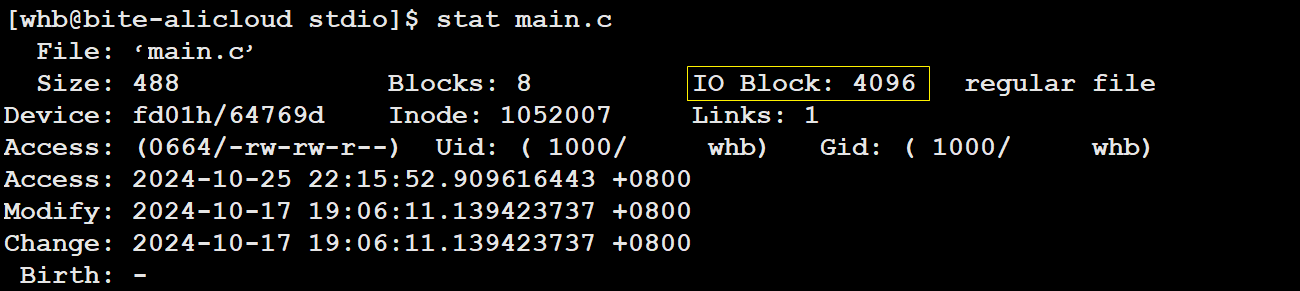
- 扇区:磁盘访问时最基本的单位是扇区,扇区的大小一般是512字节(目前也有4kb的),也就是说从磁盘上拿或写时最少要512字节。
- 磁道:以主轴为圆心的同心圆,就是磁道。可以理解为由扇区组成的圆环;
- 柱面:因为盘面有一组,所以对于半径相同的同心圆也有一组,其整体被称为柱面。是由多个半径相同的磁道组成的;
- 盘面:由所有磁道组成的。
1-3 🤔如何定位扇区
因为磁盘访问的最基本的单位是扇区,所以在先磁盘中写入数据的时候,第一件事就是定位扇区,如何定位扇区呢❓
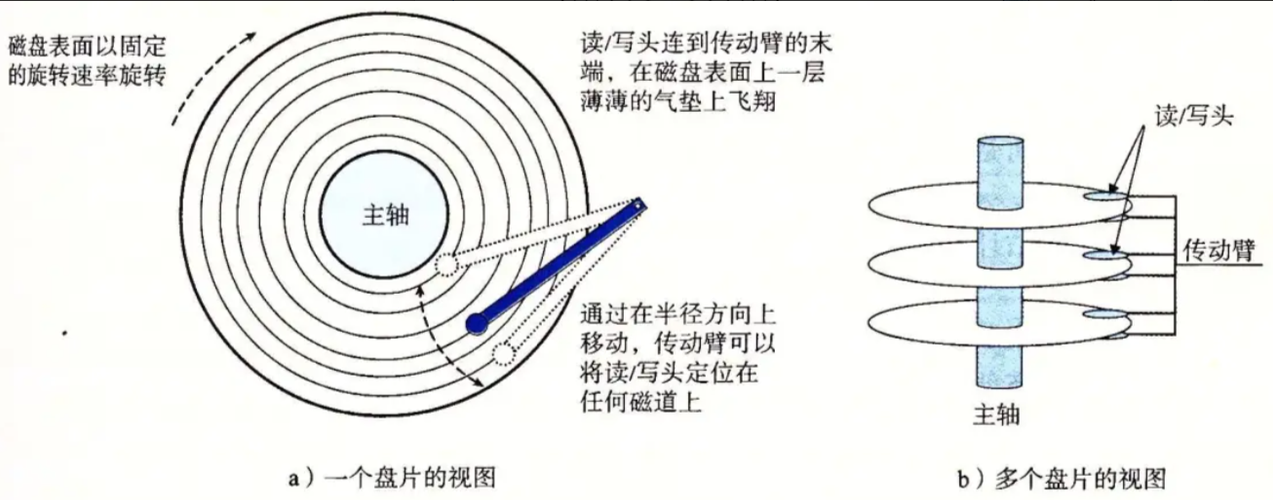
- 1️⃣定位柱面(Cylinder)—— 通过磁力臂带动磁头左右移动就可以定位要当问哪一个磁道;
- 2️⃣定位磁头(Head)——用磁头来确定在哪一个盘面上,因为磁头较少,所以可以对磁头进行编号,这样通过编号与磁头一一对应,就可以确定磁头;
- 3️⃣定位扇区(Sector)—— 通过主轴带动盘面旋转,使得磁头可以移动到磁道的所有位置,使得可以确定具体扇区。
这种确定位置的方式被称为:CHS寻址(Cylinder-Header-Sector,柱面,磁头,扇区)。
⽂件 = 内容+属性都是数据,无非就是占据那几个扇区的问题!能定位一个扇区了,能不能定位多个扇区呢🤔
- 当然可以!文件的内容和属性本质上都是存储在硬盘扇区中的数据,而一个文件(尤其是较大的文件)往往需要占用多个不连续的扇区。只要能定位单个扇区,就能通过 “扇区地址的有序组合” 定位多个扇区 —— 这正是文件系统(如 FAT32、NTFS、EXT4 等)的核心功能之一:通过 “索引结构” 记录文件所占用的所有扇区地址,最终实现对多个扇区的定位和管理。
- 扇区是从磁盘读出和写入信息的最小单位,通常大小为 512 字节。
- 磁头(head)数:每个盘片一般有上下两面,分别对应1个磁头,共2个磁头
- 磁道(track)数:磁道是从盘片外圈往内圈编号0磁道,1磁道...,靠近主轴的同心圆用于停靠磁头,不存储数据
- 柱⾯(cylinder)数:磁道构成柱面,数量上等同于磁道个数
- 扇区(sector)数:每个磁道都被切分成很多扇形区域,每道的扇区数量相同
- 圆盘(platter)数:就是盘片的数量
- 磁盘容量=磁头数 × 磁道(柱面)数 × 每道扇区数 × 每扇区字节数
- 细节:传动臂上的磁头是共进退的(这点比较重要,后面会说明❗)
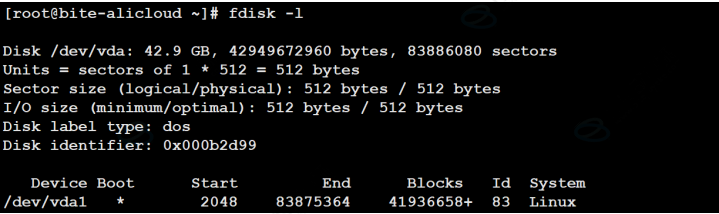
二、🐧磁盘存储的逻辑抽象结构
2-1 🕵️♀️理解过程
- 磁带相信很多人都见过,磁带与磁盘是同一时代的产物,磁带中黑色的线就是用来存储信息的,可以通过录音机来读取到磁带中的信息
- 磁带上⾯可以存储数据,我们可以把磁带“拉直”,形成线性结构
- 那么磁盘本质上虽然是硬质的,但是逻辑上我们可以把磁盘想象成为卷在⼀起的磁带,那么磁盘的逻辑存储结构我们也可以类似于:
 这样每⼀个扇区,就有了⼀个线性地址(其实就是数组下标),这种地址叫做 LBA
这样每⼀个扇区,就有了⼀个线性地址(其实就是数组下标),这种地址叫做 LBA


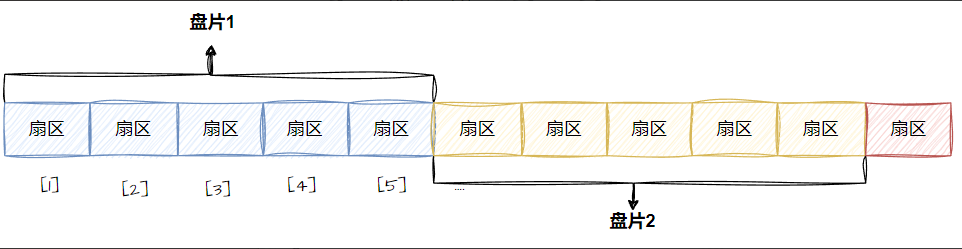
2-2 真实过程
- 这里又提到了我们之前讲过的⼀个细节:传动臂上的磁头是共进退的
- 柱⾯是⼀个逻辑上的概念,其实就是每⼀⾯上,相同半径的磁道逻辑上构成柱⾯。 所以,磁盘物理上分了很多⾯,但是在我们看来,逻辑上,磁盘整体是由“柱⾯”卷起来的
所以,磁盘的真实情况是:磁道:我们可以将每一个磁道展开或将其拉成直的
这不就是一维数组嘛!!!
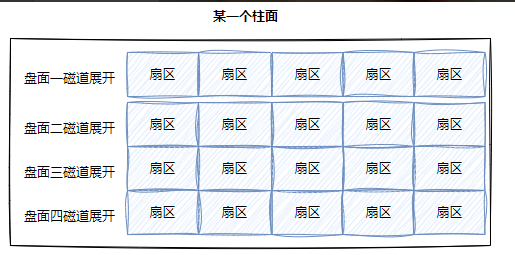
而每一个同心圆的磁道又可以构成柱面,如下图:
这不就是二维数组嘛!!!
再有多个柱面就可以形成磁盘的所有盘面了,如下图:
整个磁盘不就是多张⼆维的扇区数组表(三维数组?)
所以,寻址⼀个扇区:先找到哪⼀个柱⾯(Cylinder) ,在确定柱⾯内哪⼀个磁道(其实就是磁头位置, Head),在确定扇区(Sector),所以就有了 CHS 。
- 我们之前学过C/C++的数组,在我们看来,其实全部都是⼀维数组
现在就成功的将磁盘抽象为了一个以扇区为基本单位的数组。
所以如果现在对每个位置进行编号,每个扇区都有了自己的地址位置。我们称这种地址叫做LBA地址 (Logical Block Address),该地址是线性地址,是在依次递增的,与CHS地址天差地别。
操作系统使用LBA地址,而磁盘上使用的是CHS地址,那么这两种地址之间必定需要进行转换,如何进行转换❓
- OS只需要使⽤LBA就可以了!!LBA地址转成CHS地址,CHS如何转换成为LBA地址。谁做啊??磁盘 ⾃⼰来做!固件(硬件电路,伺服系统)




🔥CHS && LBA地址
CHS转成LBA:
- 磁头数*每磁道扇区数 = 单个柱⾯的扇区总数
- LBA = 柱⾯号C*单个柱⾯的扇区总数 + 磁头号H*每磁道扇区数 + 扇区号S - 1
- 即:LBA = 柱⾯号C*(磁头数*每磁道扇区数) + 磁头号H*每磁道扇区数 + 扇区号S - 1
- 扇区号通常是从1开始的,⽽在LBA中,地址是从0开始的
- 柱⾯和磁道都是从0开始编号的
- 总柱⾯,磁道个数,扇区总数等信息,在磁盘内部会⾃动维护,上层开机的时候,会获取到这些参 数。
LBA转成CHS:
- 柱⾯号C = LBA // (磁头数*每磁道扇区数)【就是单个柱⾯的扇区总数】
- 磁头号H = (LBA % (磁头数*每磁道扇区数)) // 每磁道扇区数
- 扇区号S = (LBA % 每磁道扇区数) + 1 "//": 表⽰除取整
- 所以:从此往后,在磁盘使⽤者看来,根本就不关⼼CHS地址,⽽是直接使⽤LBA地址,磁盘内部⾃⼰ 转换。
所以:从现在开始,磁盘就是⼀个 元素为扇区 的⼀维数组,数组的下标就是每⼀个扇区的LBA地址。OS使⽤ 磁盘,就可以⽤⼀个数字访问磁盘扇区了。
补充:磁道的长度是不同的,扇区的大小是一样的,那么怎么保证每一个磁道上扇区的个数是一样的❓
每一个磁道的周长不一样,但是可以通过控制每一个磁道存放0,1序列的密度来实现每一个磁道上扇区个数一样。现在的技术也可以实现对不同大小磁道的定位,只不过使用的算法不同而已。
三、📂⽂件系统
3-1🍕 引⼊"块"概念(Block)
- 其实硬盘是典型的“块”设备,操作系统读取硬盘数据的时候,其实是不会⼀个个扇区地读取,这样 效率太低,⽽是⼀次性连续读取多个扇区,即⼀次性读取⼀个”块”(block)。
- 硬盘的每个分区是被划分为⼀个个的”块”。⼀个”块”的⼤⼩是由格式化的时候确定的,并且不可 以更改,最常⻅的是4KB,即连续⼋个扇区组成⼀个 ”块”。”块”是⽂件存取的最⼩单位。
注意 :
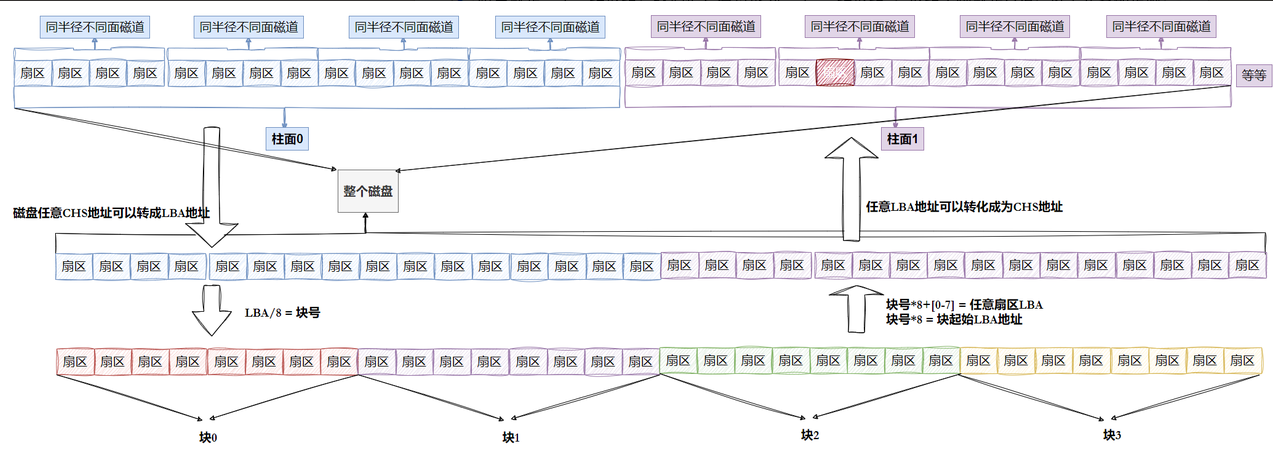
- 磁盘就是⼀个三维数组,我们把它看待成为⼀个"⼀维数组",数组下标就是LBA,每个元素都是扇 区
- 每个扇区都有LBA,那么8个扇区⼀个块,每⼀个块的地址我们也能算出来。
- 知道LBA:块号 = LBA/8
- 知道块号:LAB=块号*8 + n. (n是块内第⼏个扇区)
3-2 🍔引⼊"分区"概念
其实磁盘是可以被分成多个分区(partition)的,以Windows观点来看,你可能会有⼀块磁盘并且将 它分区成C,D,E盘。那个C,D,E就是分区。分区从实质上说就是对硬盘的⼀种格式化。但是Linux的设备 都是以⽂件形式存在,那是怎么分区的呢?
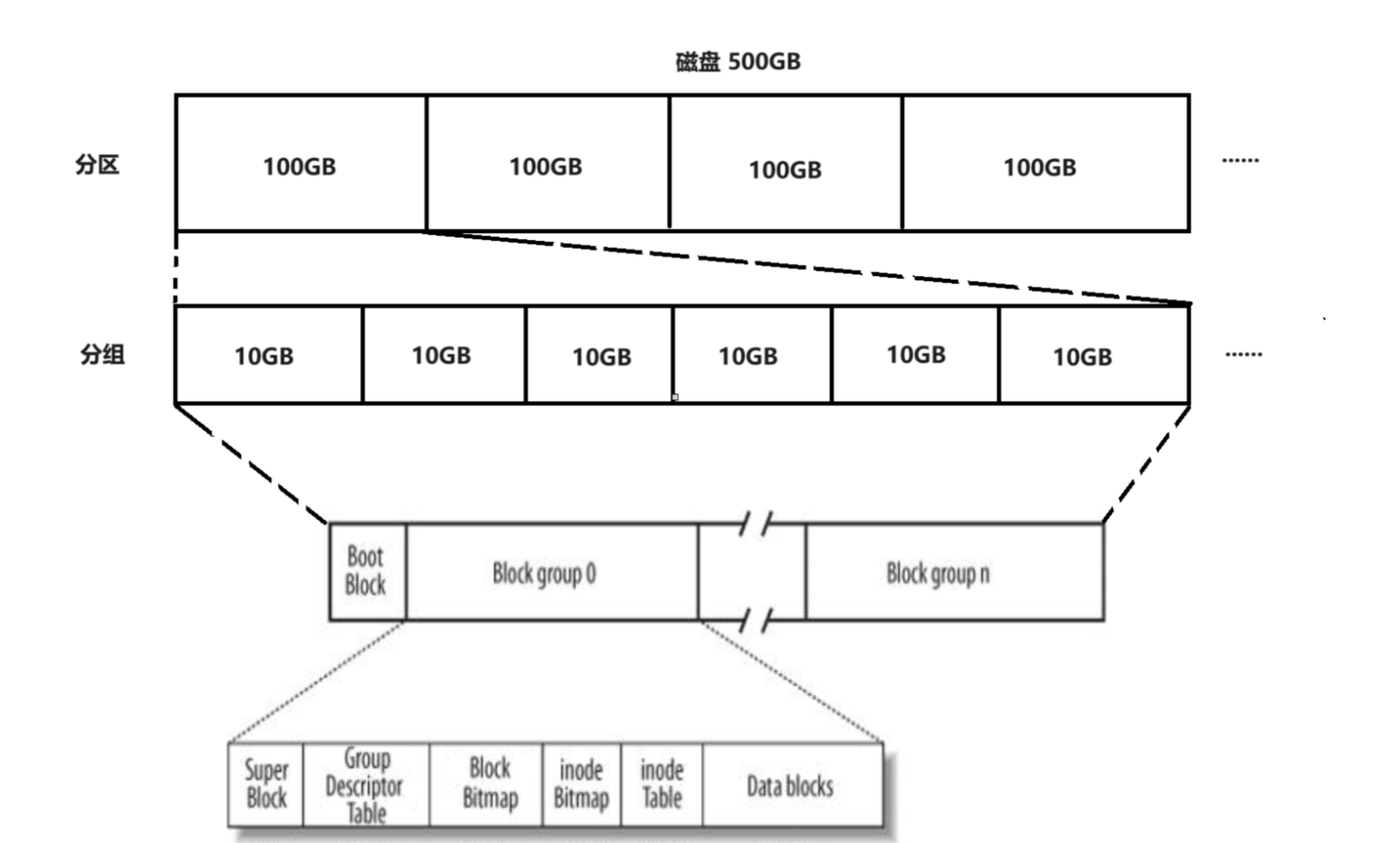
- 一个磁盘的大小通常512G以上,那么磁盘中就有非常多的4KB,为了方便管理整个磁盘,通常会将磁盘分为几个区域,我们电脑中的C/D/E/…盘就是分区后的结果,每一个分区的结构都是相同的,所以我们只要管理好一个分区,其他分区就可以使用同样的方法被管理好。
- 将磁盘分区后,一个分区的大小大概为一两百G左右,这里以100G举例,但是我们发现一个区有100G也并不是很好管理,那就将分区再进行分组,假设一个组是2G,就可以将一个分区分为50个组,又每一个组的结果也是相同的,所以我们只需要管理好一个组,其他组就可以使用同样的方法被管理好,最终要把磁盘的512个G管理好,转换为了将一个组2G管理好。
柱⾯是分区的最⼩单位,我们可以利⽤参考柱⾯号码的⽅式来进⾏分区,其本质就是设置每个区的起 始柱⾯和结束柱⾯号码。 此时我们可以将硬盘上的柱⾯(分区)进⾏平铺,将其想象成⼀个⼤的平⾯,如下图所⽰:
注意:柱⾯⼤⼩⼀致,扇区个位⼀致,那么其实只要知道每个分区的起始和结束柱⾯号,知道每⼀个柱⾯多少个扇区,那么该分区多⼤,其实和解释LBA是多少也就清楚了

3-3 🍟引⼊"inode"概念
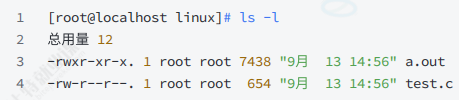
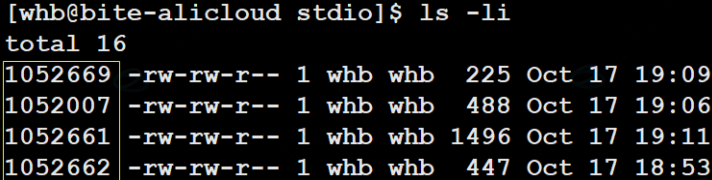
之前我们说过 ⽂件=数据+属性 ,我们使⽤ ls -l 的时候看到的除了看到⽂件名,还能看到⽂件元数据(属性)。
每⾏包含7列:
- 模式
- 硬链接数
- ⽂件所有者
- 组
- ⼤⼩
- 最后修改时间
- ⽂件名
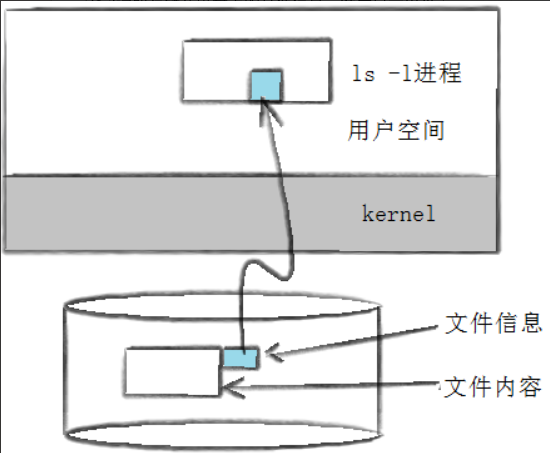
ls -l读取存储在磁盘上的⽂件信息,然后显⽰出来
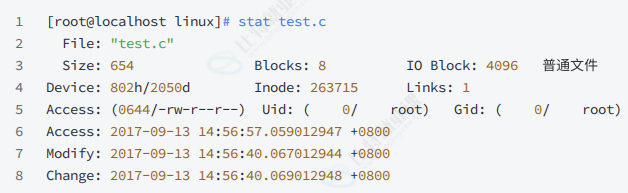
其实这个信息除了通过这种⽅式来读取,还有⼀个stat命令能够看到更多信息
到这我们要思考⼀个问题,⽂件数据都储存在”块”中,那么很显然,我们还必须找到⼀个地⽅储存 ⽂件的元信息(属性信息),⽐如⽂件的创建者、⽂件的创建⽇期、⽂件的⼤⼩等等。这种储存⽂件 元信息的区域就叫做inode,中⽂译名为”索引节点”。
每⼀个⽂件都有对应的inode,⾥⾯包含了与该⽂件有关的⼀些信息。为了能解释清楚inode,我们需 要是深⼊了解⼀下⽂件系统。
注意:
- Linux下⽂件的存储是属性和内容分离存储的
- Linux下,保存⽂件属性的集合叫做inode,⼀个⽂件,⼀个inode,inode内有⼀个唯⼀ 的标识符,叫做inode号
所以⼀个⽂件的属性inode⻓什么样⼦呢?
再次注意:
- ⽂件名属性并未纳⼊到inode数据结构内部
- inode的⼤⼩⼀般是128字节或者256,我们后⾯统⼀128字节
- 任何⽂件的内容⼤⼩可以不同,但是属性⼤⼩⼀定是相同的
1️⃣我们已经知道硬盘是典型的“块”设备,操作系统读取硬盘数据的时候,读取的基本单位是”块”。“块”⼜是硬盘的每个分区下的结构,难道“块”是随意的在分区上排布的吗?那要怎么找到“块”呢?2️⃣还有就是上⾯提到的存储⽂件属性的inode,⼜是如何放置的呢?
⽂件系统就是为了组织管理这些的❗
四、📂ext2 ⽂件系统
4-1 🍕宏观认识
所有的准备⼯作都已经做完,是时候认识下⽂件系统了。我们想要在硬盘上储⽂件,必须先把硬盘格 式化为某种格式的⽂件系统,才能存储⽂件。⽂件系统的⽬的就是组织和管理硬盘中的⽂件。在 Linux 系统中,最常⻅的是 ext2 系列的⽂件系统。其早期版本为 ext2,后来⼜发展出 ext3 和 ext4。 ext3 和 ext4 虽然对 ext2 进⾏了增强,但是其核⼼设计并没有发⽣变化,我们仍是以较⽼的 ext2 作为演⽰对象。
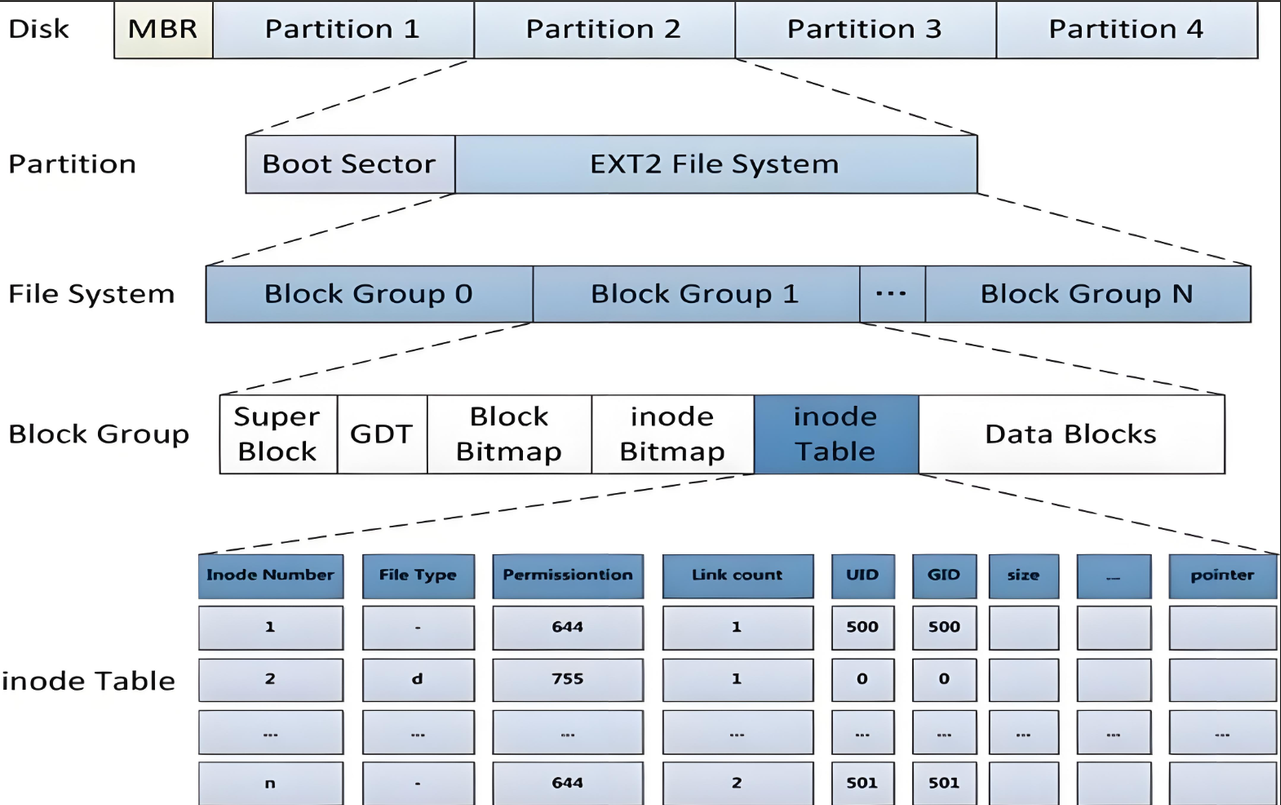
ext2⽂件系统在每个区域中又对存储的数据进行划分,将每个区划分成一个个的数据块Block group,进而对更小的区域进行管理就行了,类似于分治:先对小区域进行管理,每一个小区域管理好了,其整体部分也就管理好了。示意图如下:
上图中启动块(Boot Block/Sector)的⼤⼩是确定的,为1KB,由PC标准规定,⽤来存储磁盘分区信息和启动信息,任何⽂件系统都不能修改启动块。启动块之后才是ext2⽂件系统的开始。
格式化:
- 我们在磁盘中只会存储两类东西:我们自己的文件和很多文件管理的数据。
- 我们自己的文件分为内容和属性,内容和属性都是数据需要分开存储。
这里我举个例子来帮助大家理解文件管理的数据,
- 我们在上学的时候,就会有普通的学生,还有管理学生的学生(班长、副班长…),而这些管理者通常是很早之前就会被选取出来,只有这些管理者被选取出来后,一个班级才能够正常的运行,对应到我们这里所讲的内容,所以一个文件系统要被运行起来,首先要将管理信息先写入到块组中。
当我们要使用整个磁盘之前,需要进行分区,在使用每个分区之前还需要向分区中写入管理数据,这个工作我们称之为格式化。格式化只会将用户的信息进行清除,并不会清除管理数据。
4-2🍔 Block Group
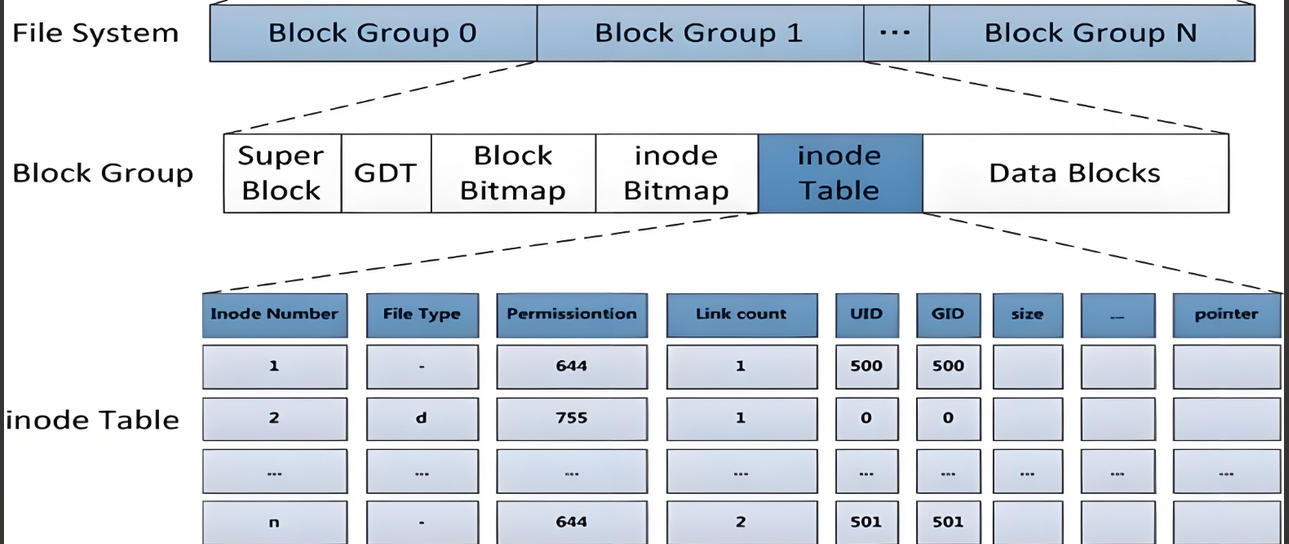
Block Group是用来对磁盘文件进行描述和管理的,文件=文件内容+文件属性,所以Block Group中必定有存储文件内容和文件信息的区域。实际上在磁盘上对于文件内容和文件属性的存储是分开的,所以Block Group内部一定也存在着各种区域的划分。Block Group的内部结构见下图:
如上图所示,每个 Block Group 都由下面几个组成部分:
- Superblock(超级块);
- Group Description(组描述);
- Block bitmap(块位图);
- Inode bitmap(inode 位图);
- Inode table(inode 表);
- Data Blocks(数据块);
inode在一个分区中的分配是从小到大的,也就是说:如果假设一个Block Group中有100个inode,那么Block Group 0中可以使用编号为0-99的inode,Block Group 1中可以使用编号为100-199的inode…
因为inode编号在分区中是依次递增的,所以在每个Block Group中不能直接将inode映射到inode Bitmap上,还需要减去该Block Group的起始inode编号。
4-3 🍟块组内部构成
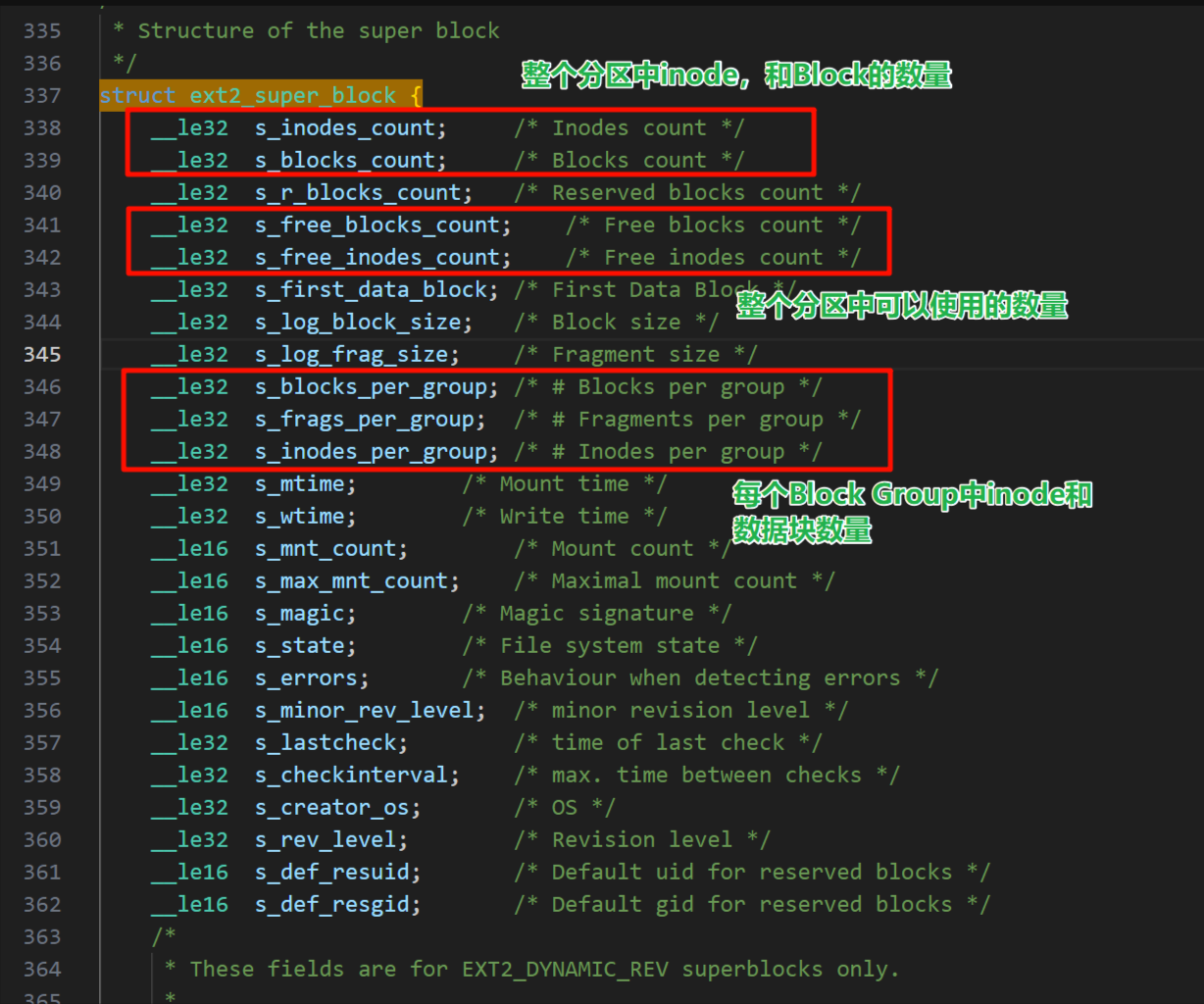
4-3-1 🦌超级块(Super Block)
超级块(Super Block)是文件系统的核心元数据结构,是文件系统正常运行的 “基石”,其设计直接关系到文件系统的完整性和可靠性。
1️⃣核心功能
超级块是文件系统的 “全局信息注册表”,负责记录和管理整个分区的基础结构参数和状态信息,是操作系统挂载、识别、操作文件系统的首要依据。操作系统在挂载文件系统时,首先会读取超级块信息,以此了解文件系统的组织方式(如块大小、inode 结构等),进而管理文件和目录。
2️⃣存储的关键信息
超级块记录的信息覆盖文件系统的 “全局属性”,主要包括:
①资源总量与状态:
- 块(block)的总数量、已使用数量、未使用数量;
- 索引节点(inode)的总数量、已使用数量、未使用数量;
- 单个块和单个 inode 的大小(决定文件系统的存储粒度)。
②时间戳信息:
- 最近一次挂载(mount)文件系统的时间;
- 最近一次向文件系统写入数据的时间;
- 最近一次对磁盘进行完整性检验(如 fsck)的时间。
③其他元数据:
- 文件系统的魔数(magic number,用于标识文件系统类型,如 ext4、XFS 等);
- 块组的数量(针对分块组管理的文件系统,如 ext 系列);
- 日志信息(部分文件系统用于崩溃恢复,如 ext4 的日志块位置)。
3️⃣容错机制:多副本备份
为避免超级块因磁盘物理损坏(如扇区故障)而丢失,文件系统采用多副本冗余设计:
- 第一个块组(Block Group)必须包含超级块(主副本);
- 后续块组中会选择性存储超级块的副本(数量和位置依文件系统类型而定,如 ext4 会在特定块组中备份);
- 所有副本保持数据一致,当主超级块损坏时,操作系统可通过读取副本恢复信息,保障文件系统不失效。
4️⃣核心重要性
超级块是文件系统的 “骨架”,其信息一旦丢失或损坏,整个文件系统的结构将无法识别 —— 操作系统无法确定块和 inode 的分布、文件与 inode 的对应关系,导致文件和目录彻底 “失联”。因此,超级块的完整性是文件系统可用性的前提,多副本设计是其可靠性的核心保障。
4-3-2 🐕GDT(Group Descriptor Table)(组描述)
块组描述符表(GDT,Group Descriptor Table)是文件系统中用于管理块组(Block Group)的关键元数据结构,与超级块配合实现对整个文件系统的分区化管理。
1️⃣核心功能
GDT 是块组的 “属性清单”,文件系统将整个分区划分为多个块组(类似 “分区中的小分区”),每个块组对应 GDT 中的一个块组描述符(Group Descriptor)。GDT 的作用是集中记录所有块组的基础信息,让操作系统能快速定位每个块组内的关键结构(如 inode 表、数据块)及资源使用状态。
2️⃣每个块组描述符存储的关键信息
单个块组描述符针对某一特定块组,记录的信息包括:
①结构位置:
- inode 表(inode Table)在该块组中的起始位置(块地址);
- 数据块(Data Blocks)在该块组中的起始位置(块地址);
- 块位图(Block Bitmap)和 inode 位图(inode Bitmap)的位置(用于标识块组内空闲 / 已使用的块和 inode)。
②资源状态:
- 该块组中空闲 inode 的数量;
- 该块组中空闲数据块的数量;
- (部分文件系统)最近一次分配的块和 inode 位置(优化分配效率)。
③其他属性:
- 块组是否被标记为 “损坏”(用于故障隔离);
- 预留块的数量(用于系统紧急操作)等。
3️⃣冗余设计:多副本备份
与超级块类似,GDT 为保障可靠性,在每个块组的开头都存储一份完整副本。这是因为 GDT 本身是描述块组结构的核心元数据,若其损坏,操作系统将无法识别块组内的 inode 表和数据块位置,导致整个块组失效。多副本设计确保即使某块组的 GDT 损坏,仍可通过其他块组的副本恢复信息。
4️⃣与超级块的配合关系
- 超级块记录文件系统的全局信息(如总块数、总 inode 数、块组数量等);
- GDT 则记录每个块组的局部信息(如该块组的 inode 表位置、空闲资源等);
- 操作系统挂载文件系统时,先读取超级块获取块组总数,再通过 GDT 定位每个块组的具体结构,实现对整个分区的分层管理。
总结
GDT 是文件系统 “分区化管理” 的核心工具,通过为每个块组建立描述符,精确记录块组内关键结构的位置和资源状态,配合多副本冗余设计,保障了文件系统对块组的高效访问和故障恢复能力。在 ext 系列等经典文件系统中,GDT 与超级块、inode 表共同构成了文件系统的基础骨架。
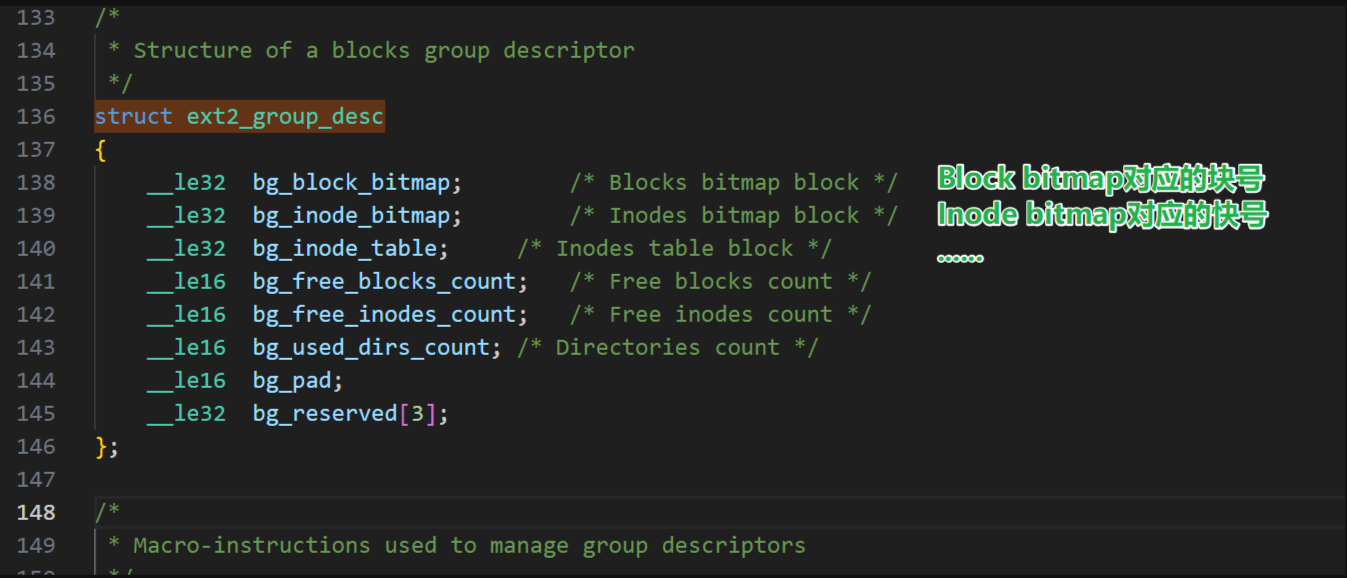
4-3-3 🐈⬛块位图(Block Bitmap)
块位图(Block Bitmap)是文件系统中用于高效管理数据块(Data Block)分配与释放状态的核心数据结构,是实现数据块快速查询、分配和回收的关键技术
1️⃣核心功能
块位图的核心作用是追踪块组内所有数据块的使用状态,本质是一个 “二进制状态标记表”。操作系统通过查询块位图,可快速判断某个数据块是否空闲,进而高效完成数据块的分配(给新文件 / 文件扩展)和回收(删除文件后释放空间),避免遍历所有数据块带来的性能开销。
2️⃣工作原理
①存储形式:块位图以二进制位(bit)为最小单位,每个 bit 对应一个数据块。
②状态标记规则:
- 标记为
1:对应的 data block 已被占用(存储了文件数据、元数据等);- 标记为
0:对应的 data block 处于空闲状态,可分配给新文件使用。③空间效率:由于采用位级存储,块位图的空间开销极小。例如,一个包含 1024 个数据块的块组,仅需 1024bit(即 128 字节)就能完整记录所有数据块的状态,大幅节省存储空间。
3️⃣关键特性
高效性:
- 分配数据块时,操作系统只需遍历块位图中的 bit 位,找到第一个值为
0的位,对应的块即为可分配块,时间复杂度接近 O (n) 但实际开销极低(因位操作速度快);- 释放数据块时,仅需将对应 bit 位设置为
0,操作原子性强,效率极高。与块组的绑定关系:
- 块位图通常按块组划分,每个块组对应一份独立的块位图,仅管理本块组内的数据块状态;
- 这种设计避免了全局位图的过大开销,同时便于并行管理多个块组的资源。
冗余备份机制:
- 与超级块、GDT 类似,块位图也会在多个块组中存储副本(具体策略依文件系统而定);
- 目的是防止单个块位图损坏导致无法识别数据块状态,保障文件系统的容错能力。
4️⃣与其他结构的协同工作
块位图需与超级块、块组描述符表(GDT)配合完成数据块管理:
- 超级块提供整个文件系统的总块数、块大小等全局信息,确定块组的划分规则;
- GDT 记录每个块组内块位图的起始位置,操作系统通过 GDT 快速定位目标块组的块位图;
- 块位图提供具体的数据块状态,供操作系统执行分配 / 回收操作。
例如:创建新文件时,流程为「读取超级块获取块组数量 → 通过 GDT 定位目标块组的块位图 → 遍历块位图找到空闲块 → 分配块并将对应 bit 设为
1→ 写入文件数据」。
5️⃣核心重要性
块位图是文件系统空间管理的 “基石”:
- 若无块位图,操作系统需逐个检查每个数据块的状态才能完成分配,效率极低(尤其在大容量磁盘中);
- 块位图的存在使数据块的分配、回收和查询操作高效可控,直接决定了文件系统的 I/O 性能和空间利用率;
- 其损坏可能导致数据块状态混乱,出现 “重复分配”(同一数据块分配给多个文件)或 “空间泄漏”(已删除文件的块未被释放)等严重问题,进而破坏文件完整性。
总结
块位图是一种基于位操作的高效空间管理工具,通过二进制标记精准记录数据块状态,以极小的空间开销实现了数据块的快速分配与回收。它与超级块、GDT 共同构成了文件系统的底层资源管理体系,是保障文件系统高效、稳定运行的关键组件之一。
4-3-4 🐎inode位图(Inode Bitmap)
inode 位图(Inode Bitmap)是文件系统中专门用于管理索引节点(inode)分配与释放状态的核心数据结构,与块位图的设计思想同源,但聚焦于 inode 资源的高效管控,是保障文件元数据正常管理的关键组件。
1️⃣核心功能
inode 位图的核心作用是精准追踪块组内所有 inode 的使用状态,本质是 inode 资源的 “二进制状态注册表”。操作系统通过它可快速判断某个 inode 是否空闲,从而高效完成 inode 的分配(创建新文件 / 目录时)和回收(删除文件 / 目录时),避免遍历所有 inode 带来的性能损耗,确保文件元数据管理的高效性。
2️⃣工作原理
①存储形式:以二进制位(bit)为最小单位,每个 bit 唯一对应一个 inode(即 bit 的索引与 inode 的编号一一对应)。
②状态标记规则:
- 标记为
1:对应的 inode 已被占用(已关联到某个文件 / 目录,存储其元数据);- 标记为
0:对应的 inode 处于空闲状态,可分配给新创建的文件 / 目录使用。③空间效率:位级存储的设计使其空间开销极小。例如,一个包含 4096 个 inode 的块组,仅需 4096bit(即 512 字节)就能完整记录所有 inode 的状态,大幅节省磁盘空间。
3️⃣关键特性
①高效的资源管控:
- 分配 inode 时,操作系统遍历 inode 位图,找到第一个值为
0的 bit,对应的 inode 编号即为可分配资源,位操作的高速性让该过程效率极高;- 回收 inode 时,仅需将对应 bit 位设置为
0,操作原子性强,能快速释放资源供后续使用。②与块组的绑定关系:
- 采用 “按块组分片管理” 策略,每个块组对应一份独立的 inode 位图,仅负责管理本块组内的 inode 状态;
- 这种设计避免了全局 inode 位图过大导致的查询延迟,同时支持多块组并行管理,提升整体效率。
③冗余备份机制:
- 与超级块、GDT、块位图一致,inode 位图也会在多个块组中存储副本(具体备份策略因文件系统而异,如 ext 系列);
- 目的是防止单个块组的 inode 位图损坏后,无法识别该块组内的 inode 状态,保障文件系统的容错能力和数据完整性。
4️⃣与其他结构的协同工作
inode 位图需与超级块、块组描述符表(GDT)、inode 表协同完成 inode 的全生命周期管理:
- 超级块提供文件系统的总 inode 数、inode 大小等全局信息,确定块组内 inode 的分配规则;
- GDT 记录每个块组内 inode 位图和 inode 表的起始位置,操作系统通过 GDT 快速定位目标块组的 inode 位图;
- inode 位图提供 inode 的空闲状态,操作系统根据其状态分配 / 回收 inode,再通过 inode 表存储具体的文件元数据。
例如:创建新文件的流程中,inode 管理环节为「读取超级块获取 inode 全局信息 → 通过 GDT 定位目标块组的 inode 位图 → 遍历位图找到空闲 inode → 分配 inode 并将对应 bit 设为
1→ 在 inode 表中写入文件元数据(如权限、大小、数据块指针等)」。
5️⃣核心重要性
inode 位图是文件系统元数据管理的 “基石”:
- 若无 inode 位图,操作系统需逐个检查每个 inode 的状态才能完成分配,在大容量文件系统中会导致严重的性能瓶颈;
- 其状态的准确性直接影响 inode 资源的正常使用,若 inode 位图损坏,可能出现 “inode 重复分配”(多个文件共用一个 inode)或 “inode 泄漏”(已删除文件的 inode 未被释放,导致 inode 资源耗尽)等问题,进而引发文件丢失、系统异常等故障;
- 作为 inode 资源的 “总览表”,它是保障文件系统元数据一致性和可用性的关键前提。
总结
inode 位图是基于位操作的高效元数据资源管理工具,通过二进制标记精准记录 inode 的空闲 / 占用状态,以极小的空间开销实现了 inode 的快速分配与回收。它与超级块、GDT、块位图共同构成了文件系统的底层管理体系,是支撑文件元数据高效管控、保障文件系统稳定运行的核心组件。
4-3-5🦬 i节点表(Inode Table)
i 节点表(Inode Table,简称 inode 表)是文件系统中存储所有索引节点(inode)的核心数据结构,是文件元数据的 “集中存储仓库”。它与 inode 位图、超级块、GDT 协同工作,共同支撑文件属性的管理和文件数据的定位,是理解文件系统底层逻辑的关键组件。
1️⃣核心功能
inode 表的核心作用是集中存储一个块组内所有 inode 的具体内容。每个 inode 对应一个文件 / 目录(目录本质是特殊文件),记录该文件的完整属性信息和数据块的定位指针。操作系统通过 inode 编号可快速在 inode 表中找到对应的 inode,进而获取文件的所有元数据,实现对文件的读写、权限校验等操作。
2️⃣存储的关键信息(文件属性)
每个 inode 是文件的 “身份档案”,存储的信息可分为两大类:文件基本属性和数据块定位信息,具体包括:
①文件基本属性:
- 文件大小(以字节为单位,区分实际数据大小和占用磁盘块的大小);
- 所有者 ID(uid)和所属组 ID(gid)(用于权限控制);
- 文件权限(读 r、写 w、执行 x,分别针对所有者、所属组、其他用户);
- 时间戳(三个核心时间戳):
- atime(访问时间):最近一次读取文件内容的时间;
- mtime(修改时间):最近一次修改文件内容的时间;
- ctime(状态修改时间):最近一次修改文件属性(如权限、所有者)的时间;
- 文件类型(普通文件、目录、设备文件、符号链接等);
- 链接数(硬链接的数量,删除文件时需链接数为 0 才会释放 inode 和数据块)。
②数据块定位信息:
- inode 中包含指向文件数据块的指针(直接指针、一级间接指针、二级间接指针、三级间接指针等,依文件系统设计而定);
- 操作系统通过这些指针,可快速找到存储文件实际数据的数据块位置,完成文件的读写操作。
3️⃣关键特性
①按块组划分存储:
- inode 表与块组强绑定,每个块组对应一份独立的 inode 表,仅存储本块组内分配的 inode;
- 这种设计可分散存储压力,同时让操作系统能通过 GDT 快速定位目标 inode 所在的块组,提升查询效率。
②inode 编号的全局唯一性:
- inode 编号以整个分区为单位统一分配,而非按块组单独编号,确保一个分区内的每个 inode 都有唯一的标识;
- 重要限制:inode 编号不可跨分区,即不同分区的 inode 可能存在相同编号,但彼此独立(因为文件系统的管理以分区为单位)。
③固定大小与预分配:
- 每个 inode 的大小在文件系统格式化时确定(如 ext4 默认 inode 大小为 256 字节或 512 字节),且大小固定;
- 文件系统会在格式化时预分配一定数量的 inode(总数量记录在超级块中),若 inode 耗尽,即使磁盘还有空闲数据块,也无法创建新文件。
4️⃣与其他结构的协同工作
inode 表的正常运作依赖与超级块、GDT、inode 位图的紧密配合,典型协同流程如下:
①创建文件时:
- 超级块提供 inode 总数量、inode 大小等全局参数;
- 通过 GDT 定位目标块组的 inode 位图;
- 遍历 inode 位图找到空闲 inode,将对应 bit 设为
1(标记为占用);- 在 inode 表中对应位置写入新文件的属性和初始数据块指针。
②访问文件时:
- 操作系统通过文件路径找到对应的 inode 编号(如目录文件中存储文件名与 inode 编号的映射关系);
- 借助 GDT 定位该 inode 所在块组的 inode 表;
- 读取 inode 表中的对应条目,获取文件权限、数据块指针等信息;
- 根据数据块指针找到文件实际数据,完成访问操作。
③删除文件时:
- 减少文件的硬链接数,若链接数降至 0;
- 将 inode 表中对应 inode 的内容标记为无效;
- 在 inode 位图中把该 inode 对应的 bit 设为
0(释放 inode 资源);- 同时在块位图中释放该文件占用的数据块,完成资源回收。
5️⃣核心重要性
inode 表是文件系统元数据管理的 “核心载体”,其地位至关重要:
- 若无 inode 表,文件的属性将无法集中存储,操作系统无法识别文件的权限、大小、数据位置等关键信息,文件将无法被有效管理;
- inode 表的完整性直接决定文件的可用性,若 inode 表损坏,可能导致文件属性丢失、数据块无法定位(即 “文件存在但无法访问”)等严重问题;
- inode 的预分配数量决定了文件系统能创建的最大文件数量,若 inode 耗尽,将直接限制新文件的创建,即使磁盘仍有剩余空间。
总结
inode 表是块组内 inode 的 “集中存储中心”,通过固定结构存储文件的属性信息和数据块定位指针,与超级块、GDT、inode 位图共同构成了文件元数据管理的完整体系。其按块组划分、inode 编号全局唯一的设计,既保障了管理效率,又确保了文件系统的一致性。理解 inode 表的工作机制,是掌握文件系统如何组织和管理文件的关键。
4-3-6 🐘数据块(Data Block)
数据块(Data Block,简称块)是文件系统中用于存储文件实际内容的最小物理存储单元,是文件数据的 “载体”。它与超级块、inode 表等元数据结构协同工作,直接决定文件系统的存储效率和 I/O 性能,是理解文件系统数据存储机制的核心组件
1️⃣核心功能
Data Block 的核心作用是存储文件的实际内容,包括普通文件的数据、目录的文件名映射关系等。操作系统通过 inode 中的数据块指针定位到具体的 Data Block,进而完成文件的读写操作。作为文件系统与磁盘物理存储的 “接口”,Data Block 的大小和管理方式直接影响磁盘空间的利用率和数据访问速度。
2️⃣关键特性
①固定大小与预分配:
- Data Block 的大小在文件系统格式化时确定(如 ext4 常见的 4KB、8KB,可根据需求配置),且一旦格式化后不可修改;
- 文件系统会将整个分区的空闲空间划分为若干个大小相同的 Data Block,每个块有唯一的块号(用于定位)。
②块号的全局唯一性:
- 块号以整个分区为单位统一分配,确保一个分区内的每个 Data Block 都有唯一标识;
- 重要限制:块号不可跨分区,不同分区的 Data Block 可能存在相同编号,但彼此独立(因文件系统的管理以分区为边界)。
③空间分配规则:
- 一个文件的数据可能占用一个或多个 Data Block(取决于文件大小);
- 若文件大小不足一个 Data Block,也会占用整个块(剩余空间无法被其他文件共享,可能导致磁盘空间浪费,即 “内部碎片”);
- 为提升访问效率,文件系统会尽量为连续的文件数据分配连续的 Data Block(减少磁盘寻道时间)。
3️⃣不同文件类型的数据存储方式
Data Block 根据文件类型的不同,存储的内容存在差异,这是文件系统实现 “统一管理所有文件(含目录)” 的关键设计:
普通文件:
- 文件的实际数据(如文本内容、图片数据、可执行程序代码等)直接存储在 Data Block 中;
- 若文件较大,inode 会通过 “直接指针 + 间接指针” 的方式关联多个 Data Block(如 ext4 的 12 个直接指针、1 个一级间接指针、1 个二级间接指针、1 个三级间接指针),实现大文件的存储。
目录文件:
- 目录本质是 “特殊的文件”,其 Data Block 中存储的是该目录下的文件名与对应 inode 编号的映射关系(键值对:文件名→inode 号);
ls命令仅读取目录 Data Block 中的文件名列表;ls -l命令则需要先通过目录 Data Block 获取文件名对应的 inode 号,再读取 inode 表中的属性信息(如权限、大小、时间戳等),最终展示完整的文件详情。其他特殊文件:
- 符号链接:若链接目标路径较短,直接存储在 inode 中(节省 Data Block);若路径较长,则占用 Data Block 存储目标路径;
- 设备文件、管道文件等:不存储实际数据,Data Block 通常为空,其核心功能通过 inode 中的文件类型和设备号等元数据实现。
4️⃣与其他结构的协同工作
Data Block 的分配、定位和回收依赖与 inode 表、块位图、GDT 的紧密配合,典型流程如下:
写入文件数据时:
- 操作系统先为文件分配 inode(通过 inode 位图和 inode 表完成);
- 通过 GDT 定位目标块组的块位图,找到空闲的 Data Block,将对应 bit 设为
1(标记为占用);- 将文件数据写入该 Data Block,并在 inode 中记录该块的块号(通过指针关联);
- 若文件较大,重复上述步骤分配多个 Data Block,形成连续或离散的块链。
读取文件数据时:
- 操作系统通过文件路径找到对应的 inode 编号,读取 inode 表中的数据块指针;
- 根据指针中的块号,定位到对应的 Data Block;
- 从 Data Block 中读取数据,返回给应用程序。
删除文件数据时:
- 当文件的硬链接数降至 0 时,操作系统会释放该文件占用的 Data Block;
- 在块位图中,将这些 Data Block 对应的 bit 设为
0(标记为空闲),以便后续分配给其他文件;- 同时清空 inode 中对应的块指针,完成资源回收。
5️⃣核心重要性
Data Block 是文件系统存储能力的基础,其设计直接影响文件系统的核心性能:
- 块大小的选择需权衡空间利用率和 I/O 效率:小 Block(如 1KB)适合存储大量小文件(减少内部碎片),但会增加 inode 和块位图的开销;大 Block(如 8KB)适合存储大文件(减少块数量,提升连续访问速度),但小文件的空间浪费更严重;
- Data Block 的完整性直接决定文件数据的可用性,若块损坏(如磁盘物理故障),可能导致文件部分数据丢失;
- 块的分配策略(如连续分配、链式分配、索引分配)影响文件的访问速度和磁盘碎片的产生,是文件系统优化的关键方向。
总结
Data Block 是文件系统中存储实际数据的最小单元,通过固定大小的设计和与元数据结构的协同,实现了对不同类型文件内容的高效管理。其块号全局唯一、按文件类型差异化存储的特性,既保障了数据定位的准确性,又适配了多样化的文件存储需求。理解 Data Block 的工作机制,是掌握文件系统数据存储和 I/O 操作的核心前提。
4-4 🍕inode和datablock映射(弱化)
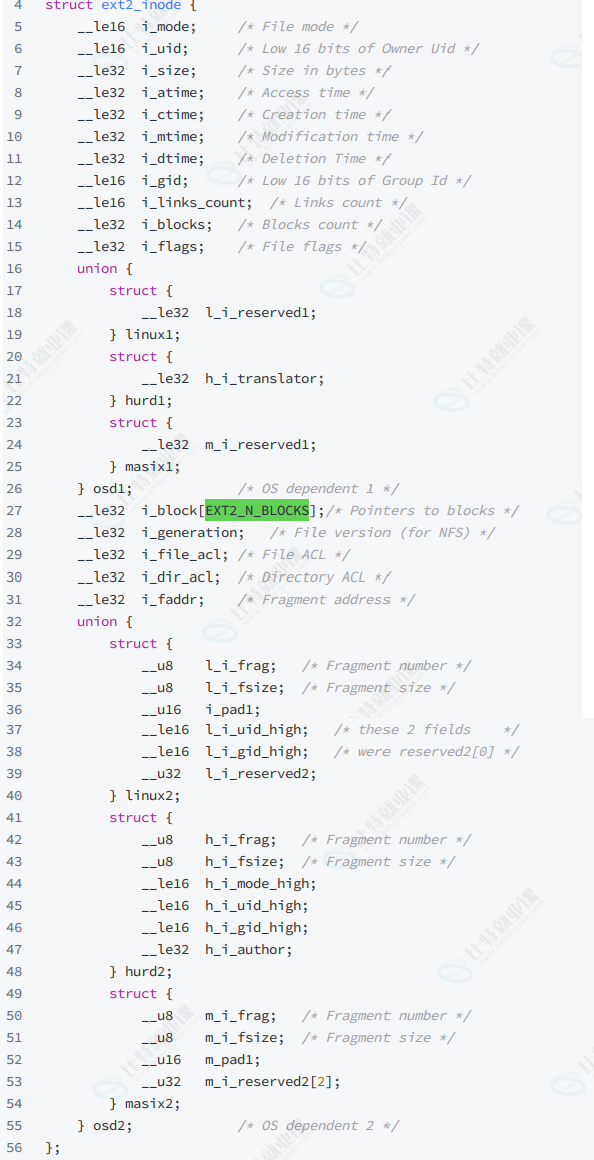
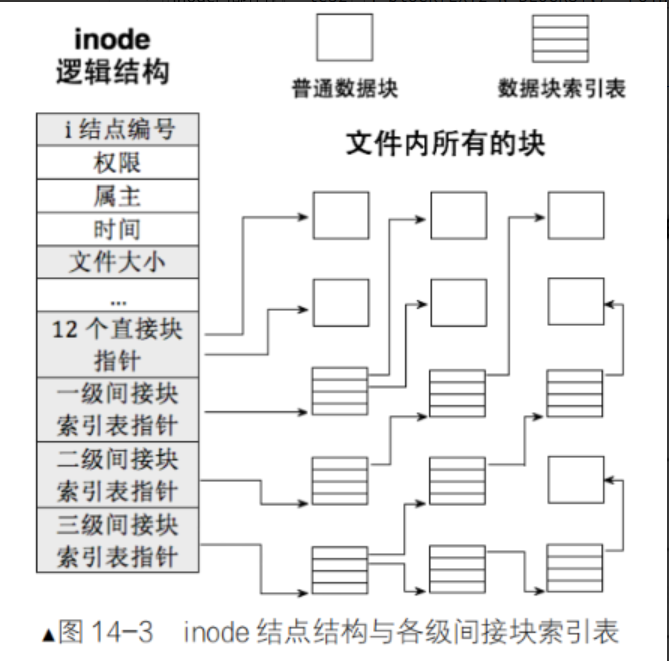
在 ext2/ext3/ext4 等经典文件系统中,
__le32 i_block[EXT2_N_BLOCKS]是 inode 结构中用于关联文件数据块(Data Block)的关键字段,其核心作用是通过指针数组建立 inode 与存储文件内容的物理块之间的映射关系,最终实现 “文件 = 属性(inode)+ 内容(数据块)” 的完整管理。
1️⃣基本结构与设计逻辑
①数组定义:
i_block是一个长度为EXT2_N_BLOCKS的数组(EXT2_N_BLOCKS固定为 15),每个元素是 32 位的小端序(__le32)整数,代表一个数据块的编号(块号)。这 15 个元素并非简单的 “直接指针”,而是采用 “直接 + 间接” 的分层设计,以高效支持不同大小的文件存储。②核心目的:解决 “文件大小不确定” 与 “inode 固定大小” 的矛盾 —— 通过分层指针设计,让固定大小的 inode(如 256 字节)能够关联任意大小的文件数据块,避免 inode 因存储大量直接指针而体积膨胀。
在大多数文件系统中,inode中维护的15个指针通常会分配如下:
- 直接指针(Direct Pointers):通常占前12个指针,每个指针直接指向一个数据块,因此可以直接访问的数据块大小为 12 * 数据块大小(在4KB数据块的情况下是48KB)。这是直接指向数据块的区域,用于存储小文件的数据。
- 单级间接指针(Single Indirect Pointer):第13个指针指向一个“间接块”,间接块中存储的是指向数据块的指针。假设一个数据块大小为4KB,每个指针大小为4字节,则一个间接块可以存放 4KB / 4B = 1024 个数据块指针。因此,单级间接指针可以增加 1024 * 数据块大小 的存储能力(约4MB)。
- 双级间接指针(Double Indirect Pointer):第14个指针指向一个“双间接块”,该块指向多个单间接块,每个单间接块指向多个数据块。根据前述计算,一个双间接指针可以增加 1024 * 1024 * 数据块大小 的存储能力(约4GB)。
- 三级间接指针(Triple Indirect Pointer):第15个指针指向一个“三间接块”,该块指向多个双间接块。一个三级间接指针可以增加 1024 * 1024 * 1024 * 数据块大小 的存储能力(约4TB)。
小结
- 因此,通过多级间接指针机制,文件系统可以有效地管理大文件。直接块、单级间接、双级间接和三级间接指针共同扩展了inode可以管理的数据量,远超过最初的15个指针直接映射数据块的限制。
- 一个组能存储的文件大小是有限的,若是一个文件的大小超过了一个组能存储的大小,那么文件系统就会采取跨块组存储机制,在实际存储过程中,文件系统可以通过inode结构来跟踪每个数据块的位置,即使这些数据块位于不同的块组。inode中记录了文件数据块的具体地址,无论这些数据块分布在哪个块组,inode都可以通过指针来引用它们,保证文件的完整性和可访问性。
五、🔥核心回顾🔥
思考🤔:
•请解释:知道inode号的情况下,在指定分区,请解释:对⽂件进⾏增、删、查、改是在做什么❓
答:在已知 inode 号且限定分区的情况下,文件的 “增、删、查、改” 本质是围绕 inode 及关联的数据块、元数据结构(如 inode 位图、块位图、目录项等)进行的一系列操作。
1️⃣“增”:基于 inode 号创建新文件(或扩展文件)
这里的 “增” 需区分两种场景:创建新文件并关联 inode 号,或为已有 inode 号的文件扩展数据。
①创建新文件(假设 inode 号已指定且空闲):
- 验证 inode 可用性:检查 inode 位图中该 inode 号对应的 bit 是否为
0(空闲),若已占用则返回错误。- 初始化 inode:在 inode 表中找到该 inode 号对应的条目,写入文件基本属性(权限、所有者、时间戳等),并将 inode 位图中对应 bit 设为
1(标记为占用)。- 分配数据块:根据文件初始大小,通过块位图找到空闲数据块,将块号记录到 inode 的
i_block数组中(直接指针或间接指针),同时更新块位图(标记块为占用)。- 关联目录项:在父目录的数据块中添加一条 “文件名→inode 号” 的映射(目录项),使文件可通过路径访问。
②扩展已有文件(为 inode 号对应的文件增加内容):
- 检查 inode 的
i_block数组是否有剩余指针:若直接指针未满,直接分配新数据块并记录块号;若已满,则使用一级 / 二级 / 三级间接指针扩展。- 分配新数据块:通过块位图找到空闲块,更新
i_block数组中的指针,同时更新块位图和文件大小(inode 中的 size 字段)。
2️⃣“删”:删除 inode 号对应的文件
删除操作的核心是释放 inode 和数据块资源,并清除目录关联,具体步骤:
- 减少硬链接数:inode 中记录的 “链接数” 减 1(硬链接通过共享 inode 实现,只有链接数为 0 时才真正删除)。
- 释放数据块:若链接数降至 0,遍历 inode 的
i_block数组,找到所有关联的数据块,将块位图中对应 bit 设为0(标记为空闲),释放磁盘空间。- 释放 inode:将 inode 位图中该 inode 号对应的 bit 设为
0(标记为空闲),并清空 inode 表中该条目的内容(或标记为无效)。- 清除目录项:在父目录的数据块中删除 “文件名→inode 号” 的映射条目,使文件无法通过路径访问。
3️⃣“查”:查询 inode 号对应的文件信息
查询操作是读取 inode 属性和数据块内容的过程,分为 “查属性” 和 “查内容”:
①查询文件属性(如权限、大小、时间戳等):
- 定位 inode:通过 inode 号在 inode 表中找到对应条目(结合块组描述符 GDT 定位 inode 表所在块组),直接读取其中的元数据(uid、gid、权限、时间戳、大小等)。
②查询文件内容:
- 定位数据块:读取 inode 的
i_block数组,根据指针类型(直接 / 间接)解析出所有数据块的块号(如直接指针直接取块号,一级间接指针需先读间接块再取块号)。- 读取数据:根据块号找到对应的 Data Block,读取其中存储的文件实际内容(如文本、二进制数据等)。
4️⃣“改”:修改 inode 号对应的文件
修改操作分为修改文件属性和修改文件内容,分别操作 inode 和数据块:
①修改文件属性(如权限、所有者、时间戳等):
- 直接更新 inode 表中该 inode 号对应的字段:例如,修改权限时更新
i_mode字段,修改所有者时更新i_uid/i_gid字段,同时更新ctime(状态修改时间)。②修改文件内容(如覆盖、插入、截断数据):
- 覆盖已有数据:直接定位到目标数据块(通过
i_block数组),写入新数据(不改变块分配,仅更新块内内容)。- 插入 / 追加数据:若现有数据块空间不足,需分配新数据块(同 “扩展文件” 流程),更新
i_block数组和文件大小,再写入新数据。- 截断数据:删除尾部数据时,释放超出长度的数据块(更新块位图为空闲),并修改 inode 中的
size字段和mtime(内容修改时间)。总结
在已知 inode 号和分区的情况下,文件的 “增删查改” 本质是:
- 围绕 inode:操作 inode 位图(标记空闲 / 占用)、inode 表(读写属性)、
i_block数组(关联数据块);- 围绕数据块:通过块位图分配 / 释放块,读写块内实际内容;
- 依赖目录项:创建 / 删除时维护 “文件名→inode 号” 的映射,确保文件可被路径访问。
这一系列操作通过文件系统的元数据结构(超级块、GDT、位图等)协同完成,最终实现对文件 “属性” 和 “内容” 的完整管理。
六、🕵️♀️结论
1️⃣格式化的本质:构建文件系统的 “管理骨架”
分区后的格式化操作(如
mkfs.ext4)并非简单的 “清空数据”,而是按规则划分块组并写入管理元数据,具体包括:
- 划分块组(Block Group):将分区空间分割为大小相等的块组(类似 “管理单元”),平衡存储压力和效率;
- 写入核心元数据:在每个块组的固定位置写入超级块(SB)、块组描述符表(GDT)、块位图、inode 位图、inode 表等结构,这些结构共同构成 “文件系统” 的管理逻辑 —— 它们就像分区的 “目录索引” 和 “资源账本”,确保操作系统能识别、分配、回收存储资源。
- 初始化状态:将位图标记为 “空闲”,超级块记录总资源量,inode 表预留空条目,为后续文件存储做好准备。
2️⃣inode 号:文件在分区内的 “全局唯一标识”
inode 号以分区为单位全局唯一,其核心作用是定位文件的元数据和数据,具体逻辑链为:
- 确定块组:inode 号与块组存在映射关系(可通过 inode 总数和每个块组的 inode 数量计算)。例如,若每个块组含 1024 个 inode,则 inode 号 1-1024 属于块组 0,1025-2048 属于块组 1,以此类推;
- 定位 inode:找到对应块组后,通过块组描述符表(GDT)获取该块组 inode 表的起始位置,再根据 inode 号在组内的偏移量(如 inode 号 1025 在块组 1 中的偏移量为 0),精准定位到 inode 表中的目标 inode 条目。
3️⃣inode:文件的 “全景信息枢纽”
一旦通过 inode 号定位到 inode,文件的所有信息即可完整获取:
- 属性信息:直接从 inode 表的条目中读取(权限、所有者、时间戳、大小、链接数等);
- 内容信息:通过 inode 中的
i_block数组(15 个指针)解析出数据块的块号,再根据块号找到对应的数据块,读取文件实际内容。因此,inode 是连接 “文件属性” 与 “文件内容” 的核心枢纽,而 inode 号则是打开这个枢纽的 “唯一钥匙”。
总结:文件系统的核心逻辑链
分区格式化 → 建立块组及元数据结构(SB/GDT/ 位图等) → 文件创建时分配 inode 号和数据块 → 通过 inode 号定位块组→定位 inode→获取属性和数据块指针→访问文件内容。
这一逻辑链清晰展现了 “为何 inode 号是文件的唯一标识”“为何格式化是文件系统的基础”,是理解 Unix/Linux 文件系统设计的核心框架。
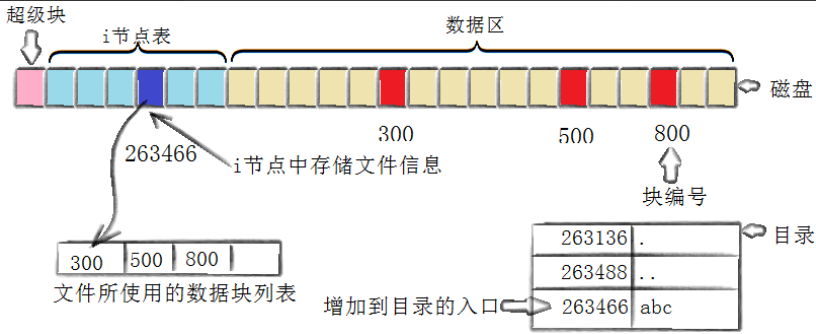
七、📂创建文件的整体步骤
1️⃣ 存储属性:分配并初始化 inode
核心操作:找到空闲 inode 并写入文件元数据。
- 如何找空闲 inode:操作系统遍历当前分区的 inode 位图(按块组依次检查),找到第一个值为
0的 bit 位,其对应的 inode 号(如 263466)即为可用。同时将 inode 位图中该 bit 设为1(标记为占用),防止被重复分配。- 写入哪些属性:在 inode 表中对应位置(通过 inode 号计算块组和偏移量)写入初始属性:
- 权限(默认继承父目录权限,受 umask 影响)、所有者(创建者的 uid/gid);
- 时间戳(atime、mtime、ctime 均设为当前时间);
- 初始大小(0,因尚未写入数据)、链接数(1,初始硬链接数);
- 文件类型(普通文件、目录等,此处为普通文件)。
2️⃣存储数据:分配数据块并写入内容
核心操作:为文件数据分配空闲块,并将内存缓冲区的数据写入磁盘。
- 如何找空闲数据块:操作系统通过块位图(按块组查找,优先分配与 inode 同组的块以减少寻道)找到 3 个值为
0的 bit 位,对应块号 300、500、800。将块位图中这些 bit 设为1(标记为占用)。- 数据写入流程:应用程序写入的数据先暂存在内核缓冲区(Page Cache),达到一定条件(如缓冲区满、主动 sync)后,内核通过块设备驱动将缓冲区数据按顺序写入 300、500、800 块中。
3️⃣记录分配情况:建立 inode 与数据块的映射
核心操作:在 inode 的
i_block数组中记录数据块的位置。
- 具体记录方式:由于文件仅占用 3 个块(小于 12 个直接指针),直接使用
i_block数组的前 3 项(i_block[0]=300,i_block[1]=500,i_block[2]=800)。此时 inode 中的size字段更新为 3× 块大小(如 3×4KB=12KB),mtime(内容修改时间)同步更新。- 为何需要记录:数据块可能不连续(如 300、500、800 分散),inode 通过
i_block数组 “记住” 块的顺序,确保读取时能按正确顺序拼接数据。
4️⃣添加文件名到目录:建立 “文件名→inode 号” 的映射
核心操作:在父目录的数据块中添加目录项(dentry)。
- 目录的本质:目录是一种特殊文件,其数据块中存储的是 “文件名→inode 号” 的键值对列表(目录项)。
- 具体操作:内核在父目录的数据块中找到空闲空间,写入一条新目录项:
(inode=263466, 文件名="abc")。若父目录数据块已满,则会为目录分配新的数据块(类似文件扩展流程),并更新目录 inode 的i_block数组。- 关键作用:文件名仅用于 “人类可读” 的标识,实际文件操作(如读写)依赖 inode 号。目录项通过映射关系,将用户输入的 “文件名” 转换为文件系统可识别的 “inode 号”,完成从 “路径” 到 “实际数据” 的跳转。
总结:创建文件的逻辑闭环
整个过程围绕 “inode 为核心” 展开:
- 分配 inode → 记录文件 “属性”;
- 分配数据块 → 存储文件 “内容”;
- inode 关联数据块 → 建立 “属性→内容” 的映射;
- 目录项关联 inode 号与文件名 → 建立 “用户标识→系统标识” 的映射。
这四个步骤环环相扣,最终实现 “用户创建一个名为 abc 的文件” 这一操作在底层的完整落地,体现了 Unix “一切皆文件” 及 “inode 为文件唯一标识” 的设计哲学。
八、 🤔重新认识⽬录与⽂件名
问题❓:
- 我们访问⽂件,都是⽤的⽂件名,没⽤过inode号啊?
- ⽬录是⽂件吗?如何理解?
答案🕵️♀️:
- ⽬录也是⽂件,但是磁盘上没有⽬录的概念,只有⽂件属性+⽂件内容的概念。
- ⽬录的属性不⽤多说,内容保存的是:⽂件名和Inode号的映射关系
1️⃣为什么日常访问文件不用直接操作 inode 号?
这是文件系统为用户提供的「抽象层便利」,底层实际仍依赖 inode 实现,具体流程如下:
①用户层面:我们通过「路径 + 文件名」(如
/home/user/test.txt)访问文件,这是操作系统封装后的友好接口;②底层流程:
- 操作系统先解析路径,从根目录(
/)开始,逐个打开路径中的每个目录文件;- 每个目录文件的内容是「文件名 → inode 号」的映射表,操作系统通过文件名查询到对应文件的 inode 号;
- 拿到 inode 号后,再通过 inode 找到文件的实际数据块(存储文件内容的磁盘空间),最终完成文件访问。
简单说:文件名是 inode 号的「人性化别名」,目录则是「别名到 inode 号的映射字典」,操作系统帮我们隐藏了直接操作 inode 的复杂细节。
2️⃣目录的本质:特殊的「映射文件」
1. 目录是文件的核心依据
在 Unix/Linux 等类 Unix 系统中,「一切皆文件」是核心设计哲学,目录也不例外:
- 目录拥有独立的 inode(存储目录的属性,如创建时间、权限、所属用户组等);
- 目录的「文件内容」并非普通数据,而是一张结构化的映射表,记录该目录下所有子文件 / 子目录的「文件名」与对应的「inode 号」。
2. 目录的关键特性(与普通文件的区别)
- 内容结构化:普通文件的内容是字节流,而目录的内容是固定格式的键值对(文件名→inode),由操作系统维护,不允许用户直接修改(需通过
mkdir、rm、mv等系统调用间接操作);- 权限控制特殊:目录的读权限(
r)允许查看目录内的文件名列表,写权限(w)允许在目录内创建 / 删除文件,执行权限(x)允许进入该目录(即通过该目录访问子文件)。
3️⃣延伸思考:当前工作目录的作用
我们在终端中执行命令时,操作系统需要知道「当前工作目录」,本质原因是:
- 当使用相对路径(如
./test.txt)访问文件时,操作系统需要以「当前工作目录」为起点,打开该目录文件,查询目标文件名对应的 inode 号;- 如果没有当前工作目录,所有文件访问都必须使用绝对路径(从根目录开始),底层流程不变,但用户体验极差。🙈
例如,执行
cat test.txt时的底层流程:
- 操作系统获取当前工作目录的 inode(通过进程控制块中的
cwd指针);- 打开该目录文件,查询文件名「test.txt」对应的 inode 号;
- 通过 inode 号找到文件的数据块,读取内容并输出。
总结
①inode 是文件的「身份证」:文件的核心标识是 inode 号,而非文件名,文件名仅用于用户识别和查询;
②目录是「inode 映射索引」:目录作为特殊文件,其核心作用是建立文件名与 inode 号的关联,为文件访问提供「寻址桥梁」;
③用户操作的抽象与底层的关联:日常操作的文件名和路径,都是操作系统提供的上层抽象,底层所有文件访问最终都归结为「通过 inode 号定位数据块」的过程。
8-1 🍕路径解析的底层逻辑:从根目录到目标文件的「递归寻址」
问题 ❓:
- 打开当前⼯作⽬录⽂件,查看当前⼯作⽬录⽂件的内容?当前⼯作⽬录不也是⽂件吗?我们访问 当前⼯作⽬录不也是只知道当前⼯作⽬录的⽂件名吗?要访问它,不也得知道当前⼯作⽬录的inode 吗?
- 可是路径谁提供?
- 可是最开始的路径从哪⾥来?
1️⃣路径解析的核心:从根目录开始的「逐层查表」
当访问一个文件(如
/home/whb/code/test.c)时,操作系统的底层流程是递归式的目录解析,核心逻辑如下:①起点:根目录(
/)根目录是路径解析的「锚点」,它的 inode 号是固定的(由文件系统在初始化时写入,系统启动后直接加载到内存),无需通过其他目录查询。例如,ext4 文件系统中,根目录的 inode 号通常是2,这是硬编码在文件系统结构中的。②逐层解析目录
简言之:每一层目录都是下一层的「索引表」,根目录是整个索引体系的起点,没有根目录就无法启动这个递归解析过程。
- 第一步:打开根目录文件(已知 inode 号),其内容中包含「
home文件名 → 对应 inode 号」的映射,通过「home」查询到/home目录的 inode 号;- 第二步:用
/home的 inode 号打开该目录文件,在其内容中查询「whb文件名 → inode 号」,得到/home/whb的 inode 号;- 第三步:重复上述过程,依次解析
code目录,最终找到test.c文件名对应的 inode 号,完成文件定位。
2️⃣当前工作目录(CWD)的作用:简化路径的「相对起点」
「当前工作目录也是文件,如何访问它?」其实是一个视角问题:
- 当前工作目录(CWD)是进程的一个属性(存储在进程控制块 PCB 中),本质是该目录的 inode 号(而非文件名)。
- 当使用相对路径(如
./test.c)时,进程直接用 CWD 的 inode 号打开当前目录文件,无需从根目录重新解析,这是一种「路径解析的优化」,而非绕过解析流程。例如,进程的 CWD 是
/home/whb(已知其 inode 号),访问code/test.c时:
- 直接用 CWD 的 inode 号打开
/home/whb目录文件;- 查询「
code文件名 → inode 号」,得到/home/whb/code的 inode;- 打开该目录,查询「
test.c→ inode 号」,完成定位。核心:CWD 是进程保存的「中间结果」,避免了每次访问文件都从根目录解析的开销,但底层仍依赖目录文件的「文件名→inode」映射。
3️⃣路径的起源:系统与用户共同构建的「目录树」
①根目录的必然性
操作系统必须预设根目录(
/),因为它是路径解析的起点 —— 没有根目录,所有文件都无法被索引(就像一本书没有目录,无法找到具体章节)。根目录下的默认目录(如/bin、/etc、/home)是系统预先创建的「基础索引节点」,用于标准化文件存储结构(如可执行程序放/bin,配置文件放/etc)。②用户操作的本质:扩展目录树
用户新建目录(如
mkdir mydir)本质是在某个已有目录(如当前工作目录)中,新增一条「mydir文件名 → 新 inode 号」的映射记录。这个新目录会成为后续文件 / 目录的「索引节点」,自然融入整个目录树结构,因此任何新文件都天生拥有路径(从根目录到它的层级关系)。③进程与路径的关联
进程访问文件时提供的路径(绝对路径或相对路径),本质是告诉操作系统「从哪个起点(根目录或 CWD)开始解析,以及逐层的目录 / 文件名是什么」。路径的每一级都是对「目录文件内容」的查询指令,最终通过递归解析找到目标文件的 inode 号。
总结:路径解析的本质是「从根目录出发的索引链」
- 根目录是锚点:固定 inode 号,无需查询,是所有路径解析的起点;
- 目录是索引表:每个目录的内容是「子文件名→inode」的映射,用于逐层定位下一级;
- CWD 是优化:进程保存的当前目录 inode 号,简化相对路径的解析流程;
- 路径是指令:用户 / 进程提供的路径,本质是指导操作系统「如何从起点开始,逐层查询索引表」的步骤说明。
理解这一点,就能明白:无论是访问文件还是目录,底层都是通过「inode 号→文件内容」的映射实现的,而路径只是这个过程的「人性化指令集」。
九、🔥路径缓存(dentry 机制):内存中的目录树与性能优化
问题1 ❓:Linux磁盘中,存在真正的⽬录吗?答案 :不存在,只有⽂件。只保存⽂件属性+⽂件内容
问题2 ❓:访问任何⽂件,都要从/⽬录开始进⾏路径解析?答案 :原则上是,但是这样太慢,所以Linux会缓存历史路径结构
问题3 ❓:Linux⽬录的概念,怎么产⽣的?答案 :打开的⽂件是⽬录的话,由OS⾃⼰在内存中进⾏路径维护
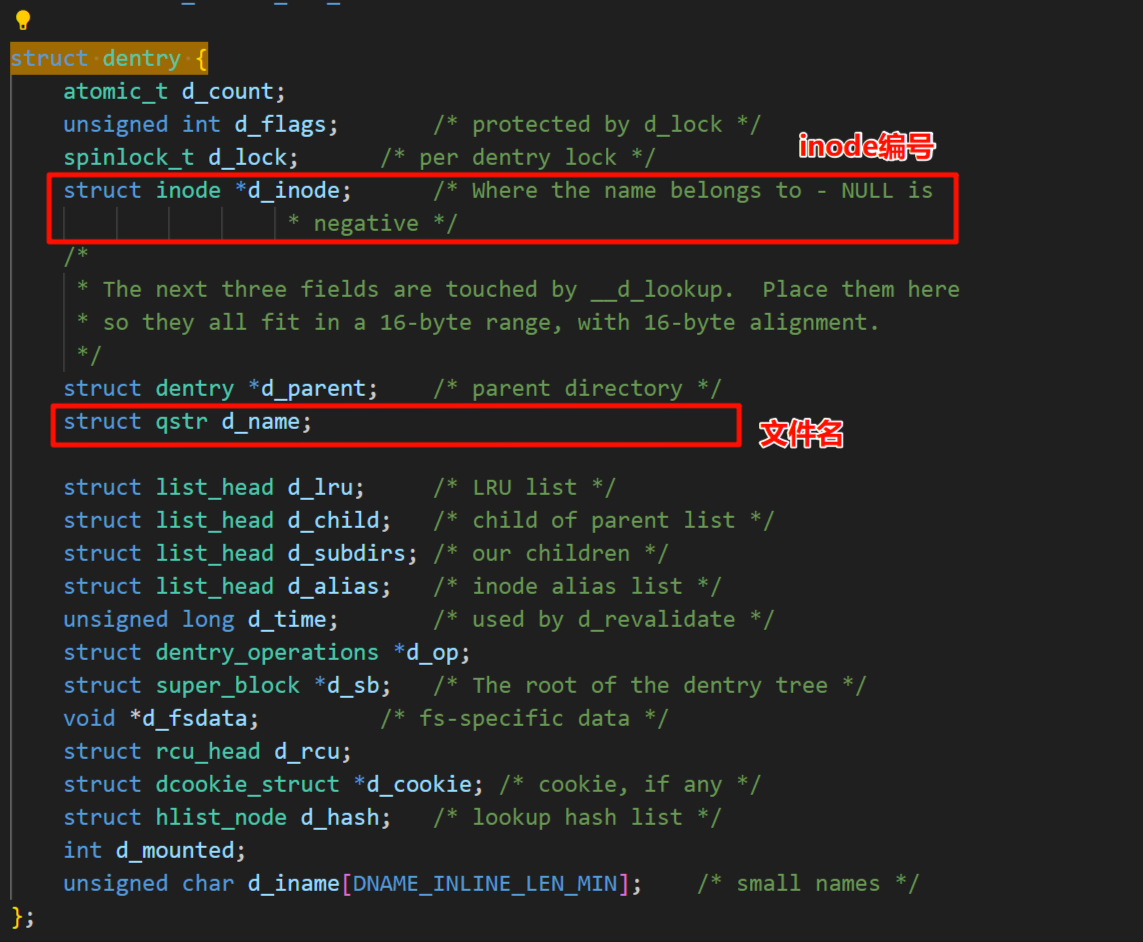
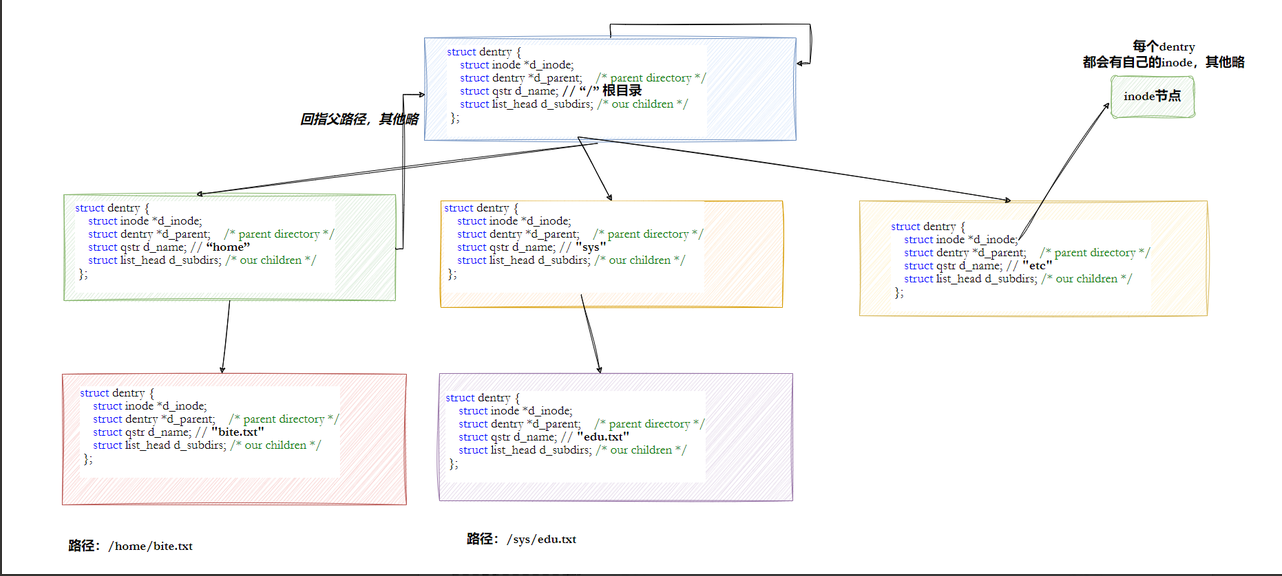
在上面一次次的递归查找的过程中,都要到查找目录的内容来看inode和文件名的映射关系,所以每一次都要读取磁盘上的数据,要多次与外设进行交互,而我们都知道与外设进行交互的效率很低 。所以操作系统中有一个结构体 struct dentry{} 目录项缓存,其中存储着常用的文件的文件名和inode的映射关系,而缓存时内存级别的,读取就更快,效率也就更高了。
注意💡 :
- 每个⽂件其实都要有对应的dentry结构,包括普通⽂件。这样所有被打开的⽂件,就可以在内存中 形成整个树形结构
- 整个树形节点也同时会⾪属于LRU(Least Recently Used,最近最少使⽤)结构中,进⾏节点淘汰
- 整个树形节点也同时会⾪属于Hash,⽅便快速查找
- 更重要的是,这个树形结构,整体构成了Linux的路径缓存结构,打开访问任何⽂件,都在先在这 棵树下根据路径进⾏查找,找到就返回属性inode和内容,没找到就从磁盘加载路径,添加dentry 结构,缓存新路径
十、🐧挂载分区:跨分区文件访问的底层逻辑
我们已经能够根据inode号在指定分区找⽂件了,也已经能根据⽬录⽂件内容,找指定的inode了,在 指定的分区内,我们可以为所欲为了。可是:问题❓:inode不是不能跨分区吗?Linux不是可以有多个分区吗?我怎么知道我在哪⼀个分区???
1️⃣inode 的「分区边界」:为何不能跨分区?
每个分区(如
/dev/sda1、/dev/loop0)都是一个独立的文件系统,其内部维护一套完整的inode 编号体系:
- 同一分区内,inode 号是唯一的(类似小区内的门牌号,唯一标识一个文件);
- 不同分区的 inode 号是「独立编号」的(就像两个小区可能有相同的门牌号,但属于不同社区)。
因此,仅通过 inode 号无法定位跨分区的文件 —— 必须先明确「这个 inode 属于哪个分区」,才能找到对应的文件数据。
2️⃣挂载(mount):分区与目录的「绑定桥梁」
挂载的核心作用是将一个独立分区的文件系统,关联到现有目录树的某个节点上,让多个分区的文件系统融入统一的路径结构。
①挂载的本质:目录作为「分区入口」
- 假设系统已有根分区(
/),其文件系统包含/mnt目录;- 将新分区(如
/dev/loop0,内含test.txt文件)挂载到/mnt目录后:
/mnt就成为新分区的「入口」,访问/mnt/test.txt时,系统会自动定位到/dev/loop0分区;- 原
/mnt目录下的内容会被临时隐藏(卸载后恢复),转而指向新分区的根目录。②挂载信息的存储:内核中的「挂载点映射表」
内核会维护一张「挂载点→分区」的映射表(如
vfsmount结构体),记录:
- 挂载点目录(如
/mnt)的 dentry/inode(属于原分区);- 对应的分区设备(如
/dev/loop0)及该分区的文件系统信息。3️⃣路径前缀:判断文件所属分区的「钥匙」
当访问一个文件(如
/mnt/test.txt)时,系统通过路径前缀匹配挂载点,确定文件所在分区:
- 解析路径时,先检查
/(根分区),发现/mnt是一个挂载点;- 根据内核映射表,
/mnt对应/dev/loop0分区,因此后续解析(test.txt)会切换到该分区的文件系统;- 在
/dev/loop0分区内,通过其内部的目录文件和 inode 体系,找到test.txt的具体数据。简言之:路径中的挂载点前缀(如
/mnt),就是分区的「标识牌」,系统通过它判断该从哪个分区的 inode 体系中查找文件。4️⃣总结:挂载让多分区融入统一目录树
- 分区独立性:每个分区有独立的 inode 体系,无法直接跨分区通过 inode 访问文件;
- 挂载的作用:将分区与目录绑定,使分区成为全局目录树的一部分,突破物理分区的隔离;
- 路径的关键:通过路径中的挂载点前缀,系统能快速定位文件所属分区,再结合该分区的 inode 体系完成访问。
这就是为什么 Linux 支持多分区,却能让用户通过统一路径访问所有文件的底层逻辑。
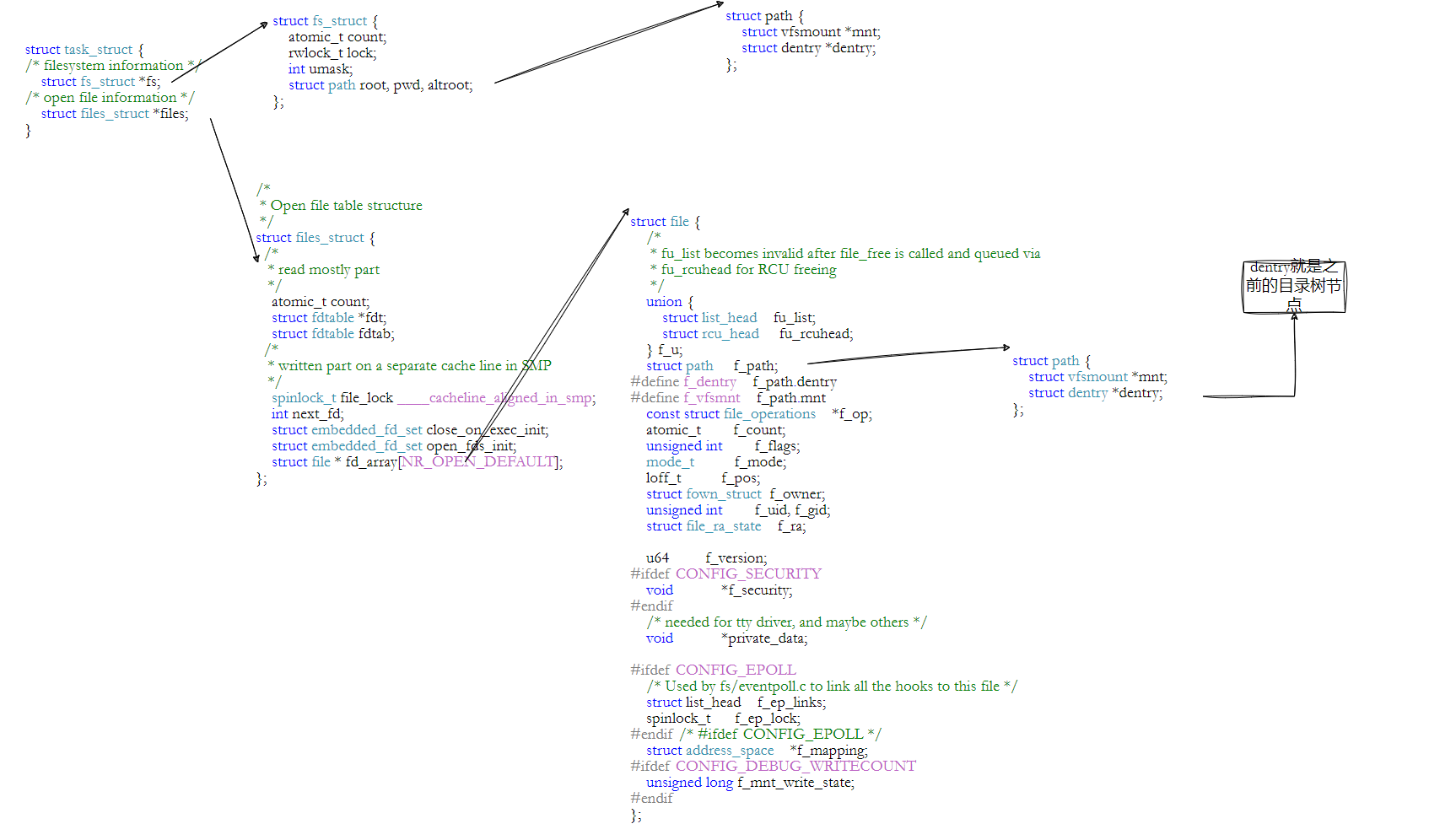
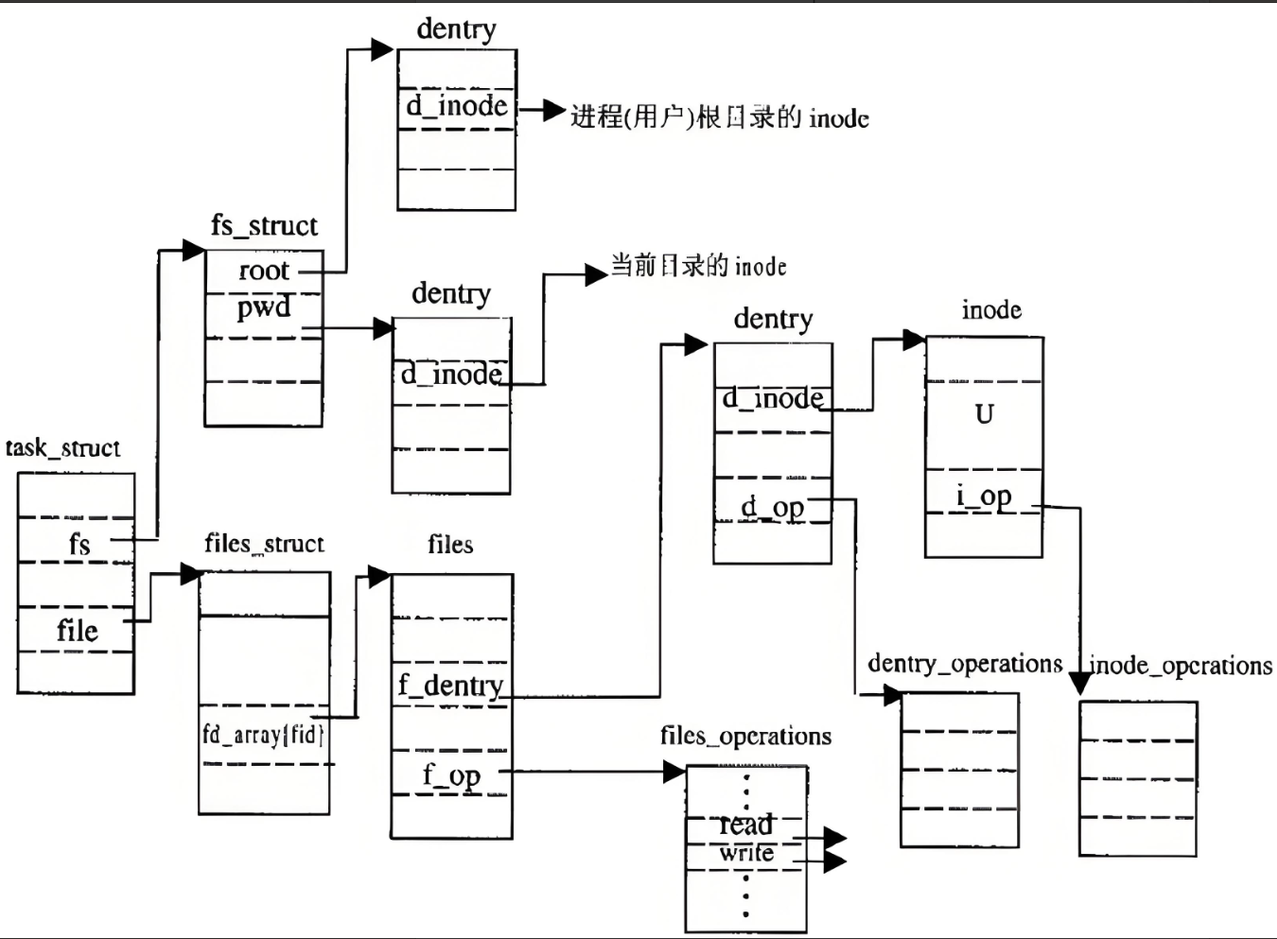
十一、🔥⽂件系统总结🔥
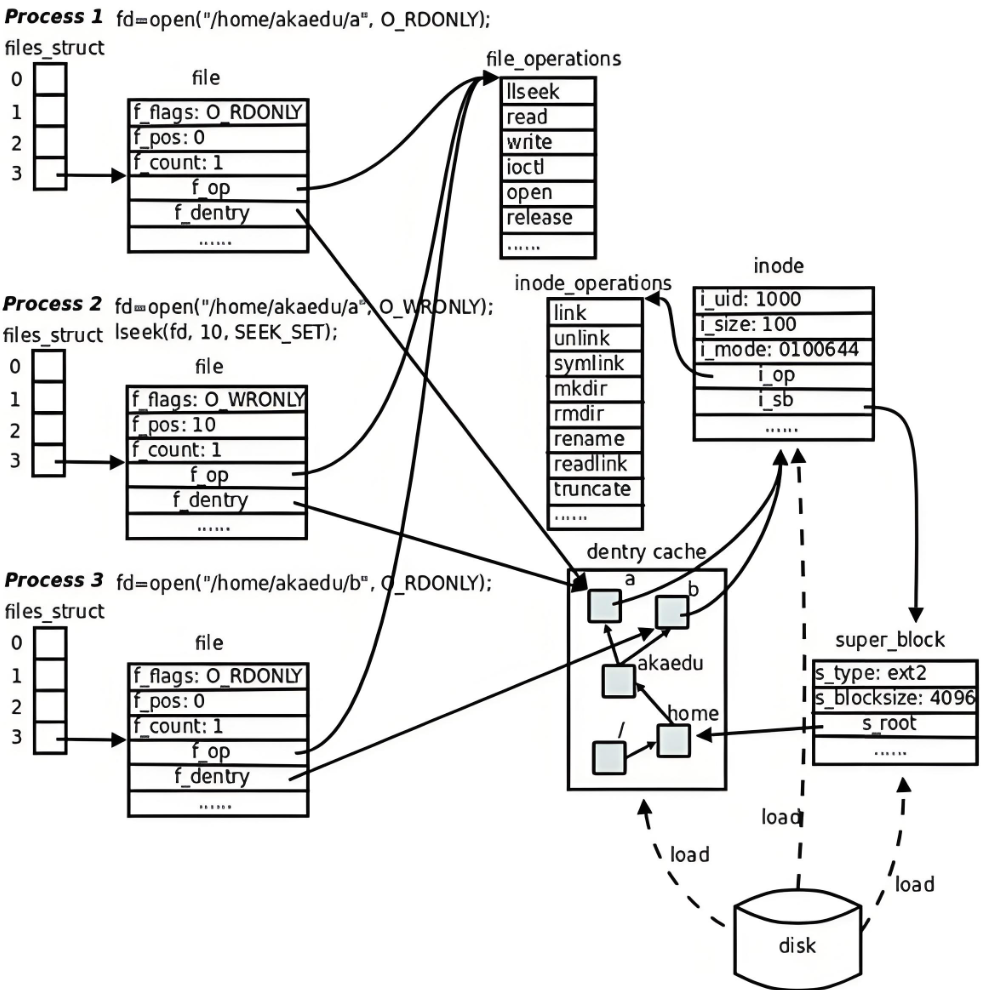
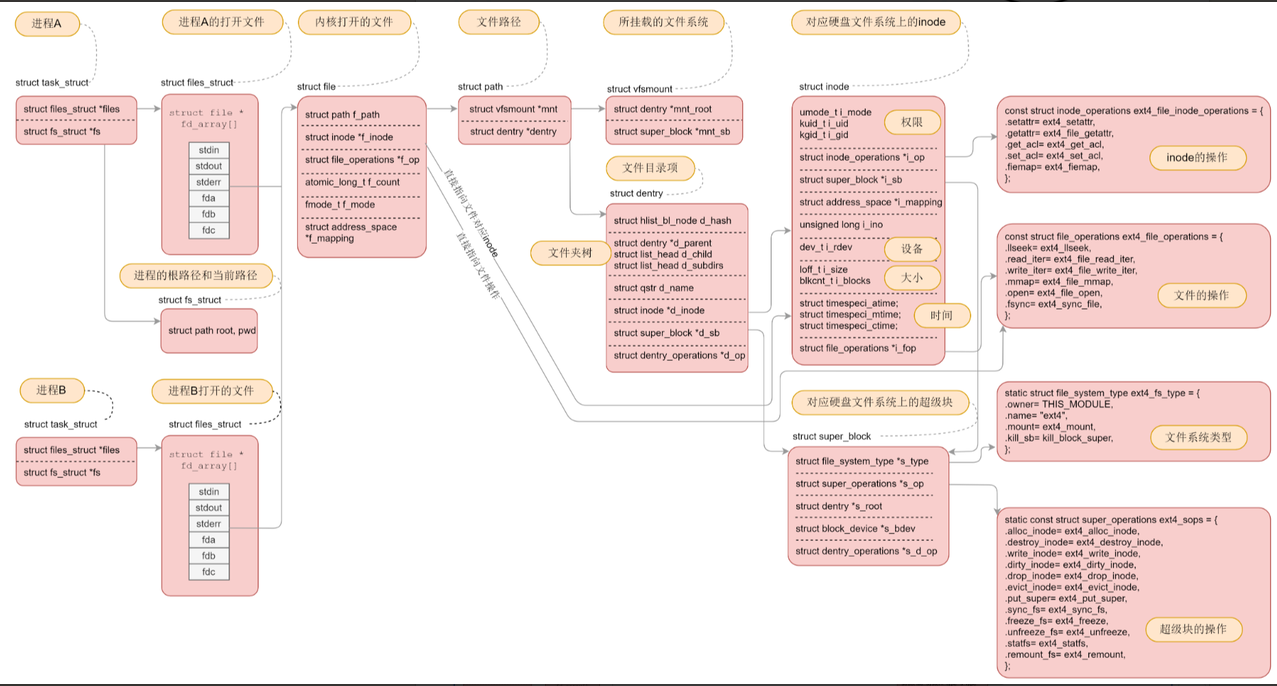
结束语:
以上就是我对于【Linux系统编程】⽂件系统的理解
感谢你的三连支持!!!
