【Linux】 层层递进,抽丝剥茧:调度队列、命令行参数、环境变量

目录
编辑
一、Linux2.6内核进程O(1)调度队列
二、命令行参数
三、环境变量
前言:
⏩️Linux2.6内核采用O(1)调度算法,通过双优先级队列(active和expired)和位图操作实现高效进程调度。每个CPU维护runqueue结构,包含140个优先级队列,普通进程优先级映射为100-139的数组下标。调度时通过位图快速定位最高优先级进程,最多遍历5次即可找到。双队列机制通过交换active和expired指针解决进程饥饿问题。命令行参数和环境变量是进程重要属性:argv数组存储命令参数,环境变量表可通过main函数或environ变量获取,PATH变量决定可执行程序搜索路径。Linux通过配置文件(如.bashrc)初始化环境变量,用户可临时修改或永久保存。
一、Linux2.6内核进程O(1)调度队列
⏩️每个CPU都有一个调度队列:struct runqueue{};如下图:
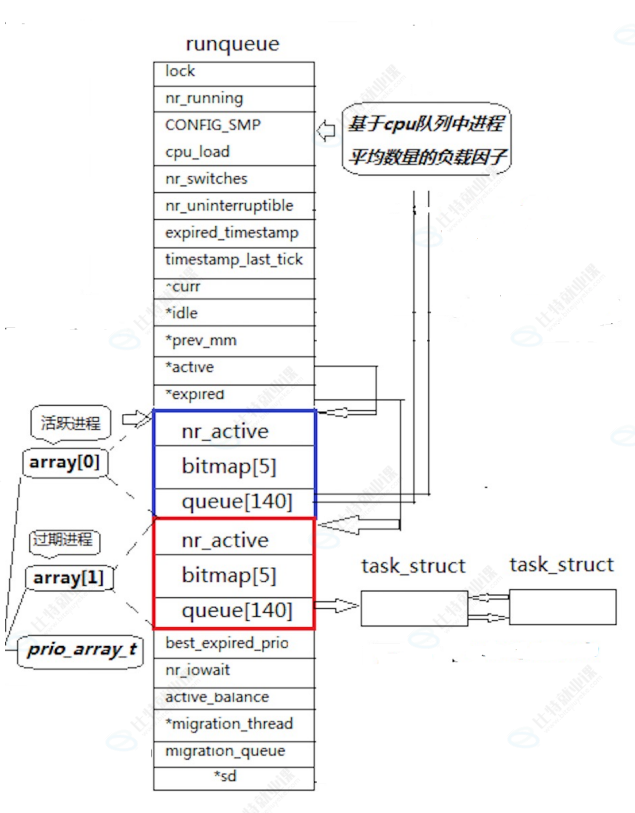
⏩️这个队列中有个queue[140],类型是struct list_head queue;它前数组下标0到99我们是不关心的,因为他是实时优先级,后面100到139,是普通优先级,对应的优先级的梯度,优先级的范围是:[ 60 , 99 ],60+40 = 100这不就是数组的下标吗,还有 99 + 40 = 139 这就是数组的下标。所以优先级数字本质上是 queue 数组的下标。
⏩️那么100到139这里面的40个优先级的梯度都是一个个的先进先出的队列,例如有10个进程的优先级都是111,就在下标为111的优先级梯度把进程PCB分别进入到这个队列中,然后进行调度,请看下图:
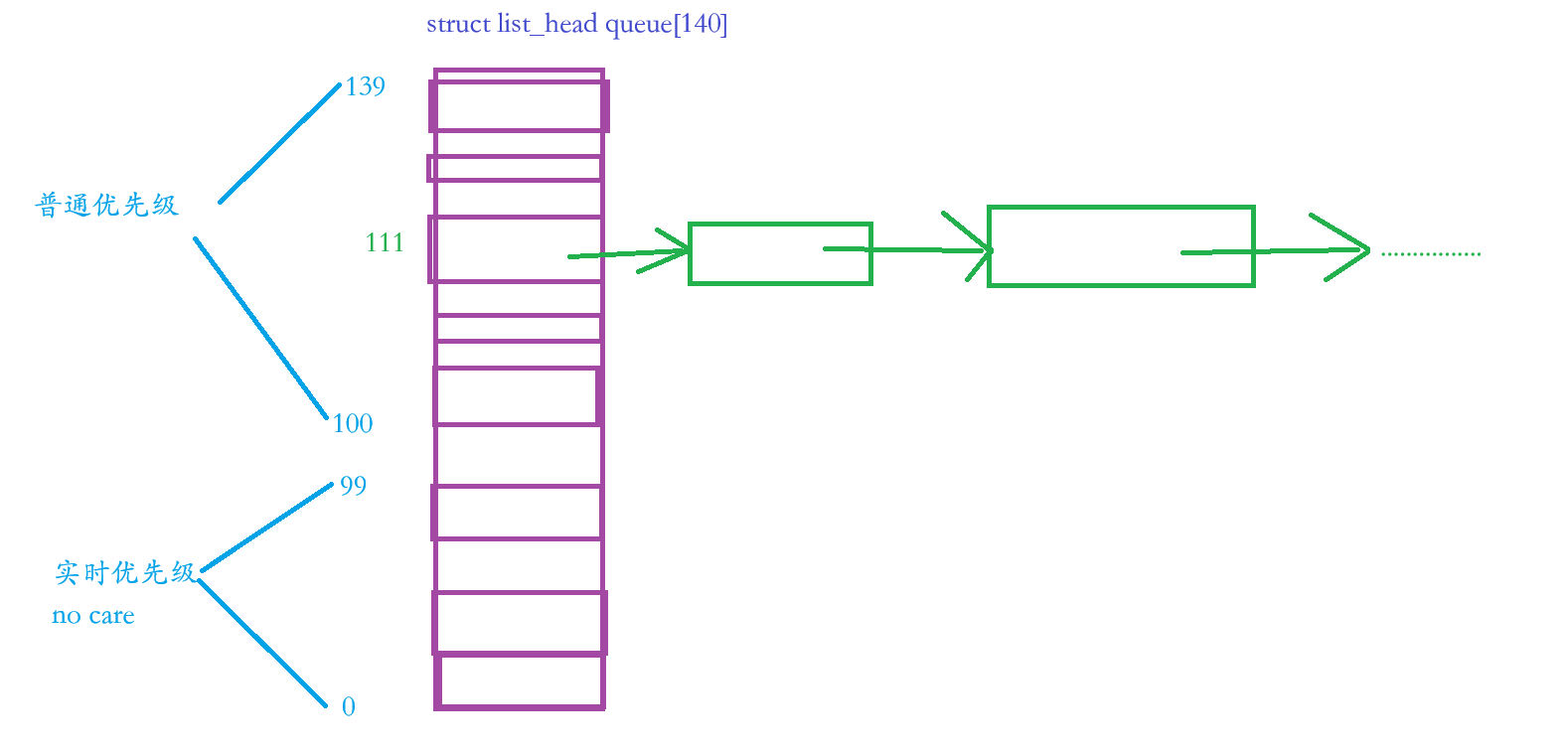
✅️结论:根据优先级选择进程的时候,本质就是一个hash的过程,其实就是给你优先级数字,例如61,然后再 61 + 40 = 101 ,最后在 queue 中找下标为101 (hash[101])队列里面的第一个进程,当然 hash[101] 前提是不为空。
⏩️如果我们要找优先级最高的进程,我们是先从数组下标100开始找,不为空第一个进程就是优先级最高的,为空那就到下一个梯度 101 来找,以此类推,我们最多遍历40次,时间复杂度为O(1),但是操作系统还是嫌慢所以弄了一大堆的比特位 000000......00000 来表示,这堆比特位的个数大于140个,从 queue 的数组下标一一对应到比特位上,例如下标为0对应到这一堆比特位的右边第一个,139对应到这一堆比特位的的第140个,如果数组数字对应的梯度里面不为空,则在这一堆比特位中找到对应的比特位显示为1,反之改为0,例如:hasn[ 101 ] 不为空,则这一堆的比特位第102个比特位为1,这就是位图操作。
⏩️那么操作系统为什么要转换成位图来找最高的优先级进程呢?
✅️答:使用位图,我们可以使用 char* 指针来访文8个比特位,看看能不能找得到这 8 个比特位中有其中有一个或者几个比特位为 1 的进程,找不到那就找下一个8个比特,如果找到有一个比特位为 1 再根据比特位的个数进而确定这是哪个数组下标的进程。所以我们只要遍历5次(我们只关心后面40个)就行找到优先级最高的进程,这不比找40次要快得多吗?所以 runqueue 中有个 bitmap[ 5 ] 位图操作,其中 bitmap 的类型是 long ,所以一次能访问 32 个比特位,访问5次可以把160个比特位访问完,这访问访问比 char 更加广。
⏩️如果 queue 数组里面一个进程都没有,那么我还要去访问位图5次呢,所以runque里面有个nr_active记录进程的个数。
⏩️runqueue 把上面的操作单独放到一个结构体中:
struct prio_arry_t
{nr_active;bitmap[50];queue[140];
};⏩️问题:根据上面的内容我们可以提出一个问题,如果CPU正在执行一堆低优先级的进程,都是不断的有高优先级的进程进来,那么就会执行完一个优先级低的进程然后不断的执行优先级高的进程,优先级低的进程永远不会被执行,这就是进程调度的饥饿问题。
✅️答:我们大部分的电脑都是分时操作系统,要以较为公平的方式,在一段时间内让所有的进程都要被CPU执行或者说获得CPU资源。所以我们先学习下面内容之后再回答这个问题。
⏩️我们如果把一个进程的优先级从80改成81,这意味该进程的PCB要在优先级下标为120的队列中剥离下来,移动到下标为121队列那里,这样的成本太高了。那么操作系统是怎么优化的呢?
⏩️实际上,上面 prio_arry_t 操作系统是有两套的,他们都放到一个叫 struct prio_arry_t arry[ 2 ] 数组里面。
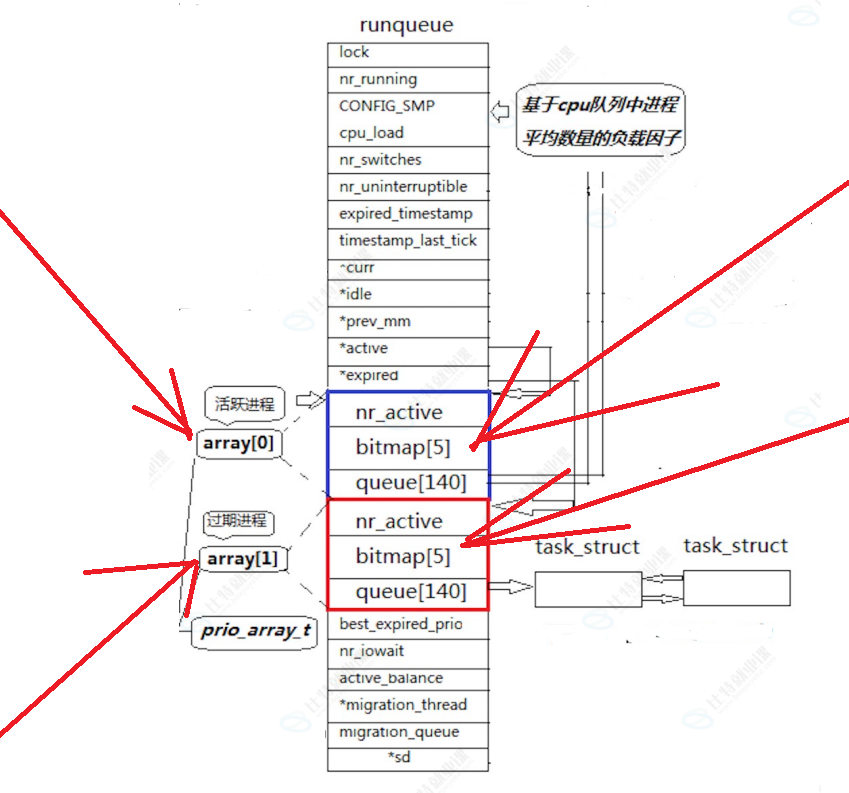
⏩️所以 requeue 队列里面有一个 *active 和 *expired 指针,他们指针的类型都是 struct prio_arr_t* ,active 指向 array[ 0 ],这个数组被成为活跃 140 队列,而 expired 指向 array[ 1 ],这个数组被成为过期 140 队列;CPU从 active 中找进程,不会从 expired 找,假设 acitive 指向的 queue 数组中下标为111有多个进程,CPU拿到第一个进程执行一段时间之后(时间片用完了),不是重新放回 active 指向的 queue 数组中下标为111的队列中(重新入队列),而是放到 expired 指向的 queue 数组中下标也是为111的队列中(入队列),如果再从 active 指向的 queue 数组下标为111的队列中选择进程(出队列)来执行,一旦把 active 中 queue 数组所有的进程都调度一遍(所有的进程的时间片都用完了,但是程序还没有执行完),就把 active 和 expired 指向的内容交换一下(swap(&active,&expired),重新从 active 中指向进程。
❌️注意:一开始 expired 指向的 queue 数组中什么都没有。
⏩️现在我们可以回答进程的饥饿问题了,当CPU正在执行低优先级队列的进程的时候,不断的有高优先级进程进来,是不会直接停止低优先级进程的,而是:当正在执行低优先级进程队列(active 的指向的queue)的时候,即使有高优先级的进程进来是不会直接进入到 active 指向的 queue 队列的,而是放到 expired 指向的 queue 中,当调度一轮(每个进程的时间片用完了) active 指向的进程之后,swap 之后此时就可以先运行高优先级的进程队列了。此时就解决进程的饥饿问题了。
✅️结论:Linux 没有进程的饥饿问题。
⏩️现在我们也能回答为什么不能直接把一个进程的优先级直接从80改成81了,首先在 active 的 queue 中有一个进程的优先级是 80 现在要改成 81 ,如果我们直接从 active 指向的 queue 中直接就修改该进程就会导致原来的优先级为80的进程要剥离原来的队列,然后移动到优先级为81的队列中,这样的代价太大了;所以Linux操作系统是怎么做的呢?
✅️答:首先引入一个 nice 值,该进程等于 1 ,然后改进程还是按原来的优先级为 80 的队列中调度,只要它在 active 指向的 queue 中的所有进程调度完毕(时间片用完了),准备进行 swap(&active,&expired) 时就让该进程的优先级数字改成 81 ,然后在放到(入队列) expired 指向的 queue 的对应优先级下标为 121 调度队列中。
❌️注意:前面讲的所有内容都是基于优先级队列 100 到 130,他是一个分时操作和0到99的实时操作无关,也就是说实时操作没有两套的 prio_array_t ,他只会一个一个的把优先级从高到低的进程,执行完,就是说例如:先执行完优先级为 99 的进程(没有时间片的概念),再执行优先级为 100 的,以此类推。执行完所有的进程之后,就执行完了,没有什么 active 和 expired 的交换什么的。
⏩️详细代码请看Linux内核代码:
struct rq {
spinlock_t lock;
/*
* nr_running and cpu_load should be in the same cacheline because
* remote CPUs use both these fields when doing load calculation.
*/
unsigned long nr_running;
unsigned long raw_weighted_load;
#ifdef CONFIG_SMP
unsigned long cpu_load[3];
#endif
unsigned long long nr_switches;
/*
* This is part of a global counter where only the total sum
* over all CPUs matters. A task can increase this counter on
* one CPU and if it got migrated afterwards it may decrease
* it on another CPU. Always updated under the runqueue lock:
*/
unsigned long nr_uninterruptible;
unsigned long expired_timestamp;
unsigned long long timestamp_last_tick;
struct task_struct *curr, *idle;
struct mm_struct *prev_mm;
struct prio_array *active, *expired, arrays[2];
int best_expired_prio;
atomic_t nr_iowait;
#ifdef CONFIG_SMP
struct sched_domain *sd;
/* For active balancing */
int active_balance;
int push_cpu;
struct task_struct *migration_thread;
struct list_head migration_queue;
#endif
#ifdef CONFIG_SCHEDSTATS
/* latency stats */
struct sched_info rq_sched_info;
/* sys_sched_yield() stats */
unsigned long yld_exp_empty;
unsigned long yld_act_empty;
unsigned long yld_both_empty;
unsigned long yld_cnt;
/* schedule() stats */
unsigned long sched_switch;
unsigned long sched_cnt;
unsigned long sched_goidle;
/* try_to_wake_up() stats */
unsigned long ttwu_cnt;
unsigned long ttwu_local;
#endif
struct lock_class_key rq_lock_key;
};
/*
* These are the runqueue data structures:
*/
struct prio_array {
unsigned int nr_active;
DECLARE_BITMAP(bitmap, MAX_PRIO+1); /* include 1 bit for delimiter */
struct list_head queue[MAX_PRIO];
};二、命令行参数
⏩️问题:main 函数可以有参数吗?
✅️答案是:可以。
#include<stdio.h>int main(int argc, char* argv[])
{return 0;
}
🚩argv:指针数组,俗称命令行参数列表
🚩argc:指针数组有多少个参数,俗称命令参数个数。
⏩️那么main函数的参数个数是多少,命令函数参数是什么呢?
#include<stdio.h>int main(int argc, char* argv[])
{int i = 0;printf("argc:%d\n",argc);for(;i < argc; i++){printf("argv[%d]->%s\n",i,argv[i]);}return 0;
}

⏩️所以我们由上面的图片可以得出结论:所谓的命令行参数个数其实就是我们输入的命令,通过分隔符来分割的字符串个数。而命令行参数列表其实就是每个字符串的的地址。
⏩️那么为什么要有命令行参数呢?
#include<stdio.h>
#include<string.h>int main(int argc, char* argv[])
{if(argc != 2){printf("该命令使用错误,你应该这么做:%s -a|-b|-c|-d\n",argv[0]);}if(strcmp(argv[1],"-a") == 0){printf("我现在执行的是该命令的的一种功能\n");}else if(strcmp(argv[1],"-b") == 0){printf("我现在执行的是该命令的的二种功能\n");}else if(strcmp(argv[1],"-c") == 0){printf("我现在执行的是该命令的的三种功能\n");}else if(strcmp(argv[1],"-d") == 0){printf("我现在执行的是该命令的的四种功能\n");}else{printf("我现在执行的是该命令的的默认种功能\n");}return 0;
}
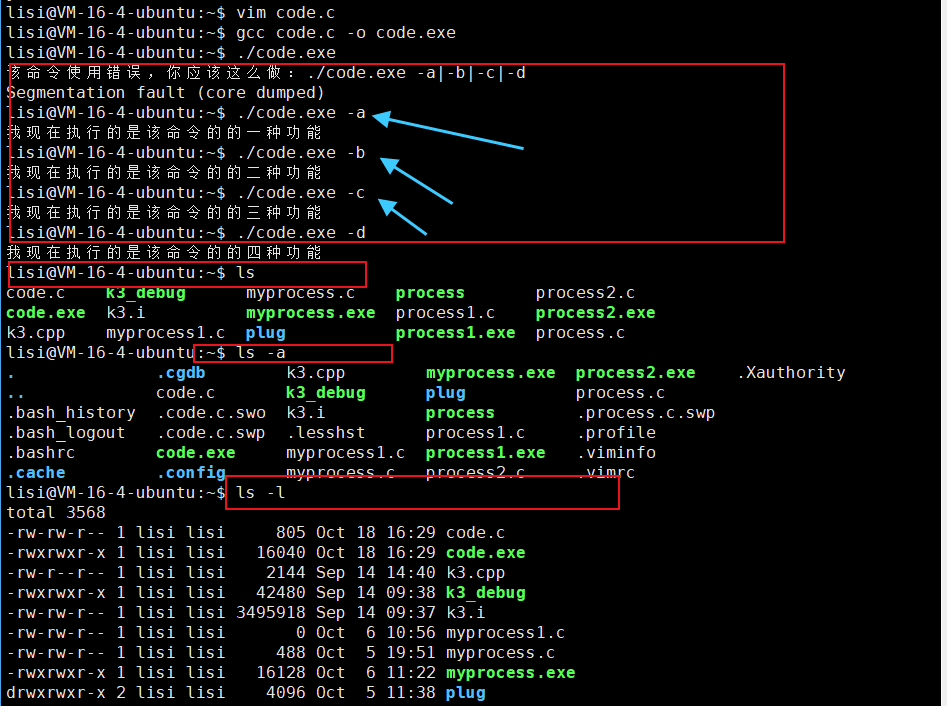
✅️答:命令行参数的本质应用,是为了实现一个命令可以根据不同的选项,实现不同的子功能,也是Linux中所有命令选项功能的实现方式。
🚩细节1:命令行参数至少是1,argv[0] 一定会有元素,而且指向的是程序名。
🚩细节2:选项是以空格分隔的字符串,一个字符也是字符串。
🚩细节3:argv[argc] 表示指针数组的最后一个元素为NULL。
#include<stdio.h>
#include<string.h>int main(int argc, char* argv[])
{printf("argv[argc] = %s\n",argv[argc]);return 0;
}

⏩️问题:vs2022或者Windows有没有命令行参数?
✅️答:有。
⏩️问题:为什么 cat + 文件名 可以打印文件内容?
✅️答:cat 也是C语言写的,可以在 cat 文件里面写代码(获取到文件名,如果打开文件,最后打印文件到 XShell 黑框框里面。
三、环境变量
⏩️问题:为什么我们执行我们自己写的可执行文件要带 ./ ?
✅️答:因为Linux默认是从 /usr/bin/ 路径来找可执行文件的,我们写的可执行文件没有放到这个路径下,我们可以把这个文件复制到这个路径,不带 ./ 也能执行该文件。./ 是相对路径,本质就是告诉OS,用户要执行的可以执行程序,就在当前路径下。
⏩️问题:Linux是怎么知道去 XShell 哪个路径找可执行程序呢?
✅️答:因为Linux系统,会存在所谓的环境变量:PATH,他是一个全局的环境变量。我们来查看一下这个环境变量的内容是什么?请看下面内容:
lisi@VM-16-4-ubuntu:~$ echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin
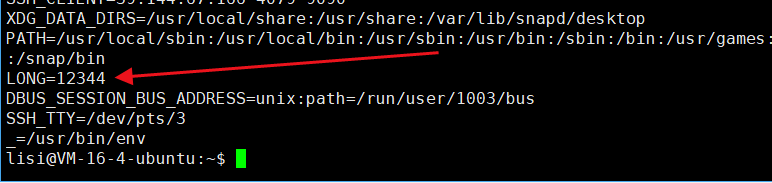
⏩️我们可以看到 PATH 的内容是以 : 号为分隔符的一堆的路径。所以PATH的本质是告诉Linux系统,如果用户执行可执行程序没有指定路径,就到该 PATH 去找。这意味着我们可以把可执行文件放到任何 PATH 的里面的任何一条路径,不用 ./ 就能执行可执行文件,也就意味着如果我们把我们的可执行文件的路径,添加到 PATH 里面,不用带 ./ 就能执行可执行文件,具体操作看下图:

⏩️如果想上面这么做的话,会覆盖原来的PATH的内容,导致一些命令执行不了,例如:ls
⏩️那么覆盖 PATH 之后怎么恢复原来的路径呢?
✅️答:退出 XShell ,重新打开 XShell。
⏩️那么正确添加可执行文件的路径到 PATH 的方法是什么?

⏩️问题:Windows有没有环境变量呢?
✅️答:有。在电脑打开控制面板查找环境变量:
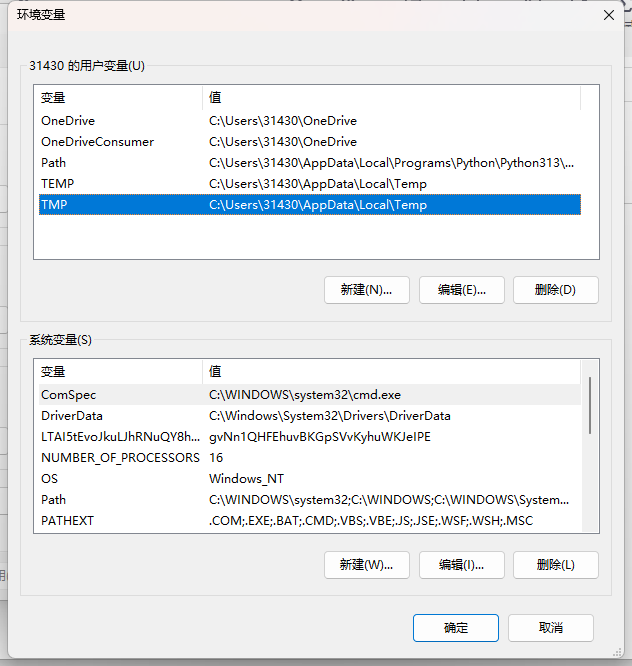
⏩️如果想像在 XShell 在 PATH 里面添加一条路径,实际上是在上图的用户变量的 path 里面添加的。关机之后我们添加的那条路径就没了。
⏩️我们在 XShell 输入指令:env ,表示查找有哪些环境变量?
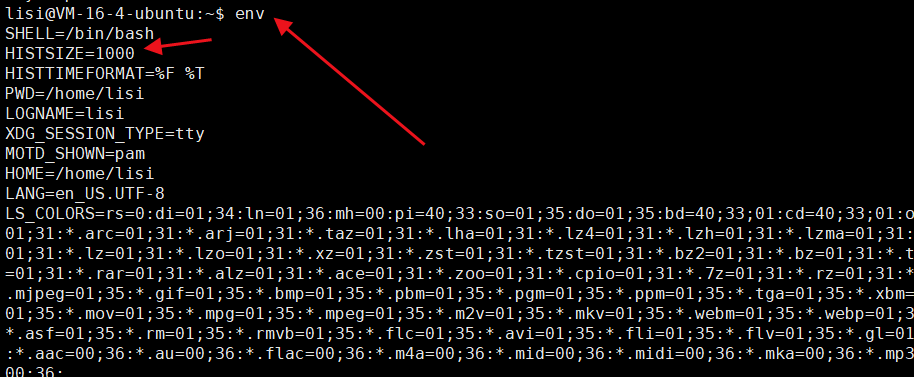
⏩️其中的 HISTSIZE 的环境变量默认的值是1000,表示记录我们最近输入的 1000 条指令,就像我们平常按下那个箭头向上的键,可以找到历史命令一样。

⏩️OLDPWD是记录最近我们待过的路径,是什么?例如:
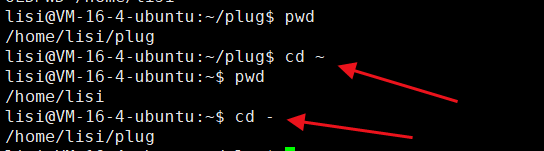
⏩️cd - 就是回到上一条路径下。
⏩️还要很多的环境没有解释但是最重要是下面三条:
🚩• PATH : 指定命令的搜索路径
🚩• HOME : 指定⽤⼾的主⼯作⽬录(即⽤⼾登陆到Linux系统中时,默认的⽬录)
🚩• SHELL : 当前Shell,它的值通常是/bin/bash
⏩️那么环境变量和我们平常写代码和进程有什么关系吗?
✅️答:
🚩1.可以通过写代码的方式获取到环境变量
⏩️main函数有三个参数,第三个参数可以获取到环境变量。
#include<stdio.h>int main(int argc, char* argv[],char* env[])
{(void)argc;(void)argv;//不用这么做到的话可能报错int i = 0;for(;env[i];i++){printf("env[%d]:&s\n",i,env[i]);}return 0;
}
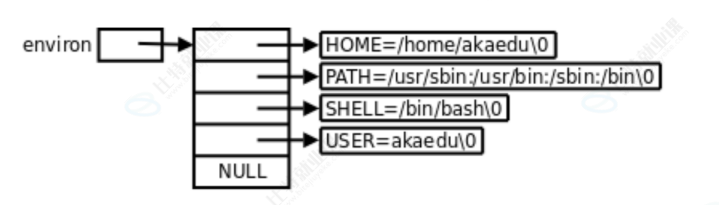
⏩️env:称为:环境变量表,可以获取到环境变量,跟 argv 一样也是以 NULL 结尾。本质是把环境变量表传递给进程。
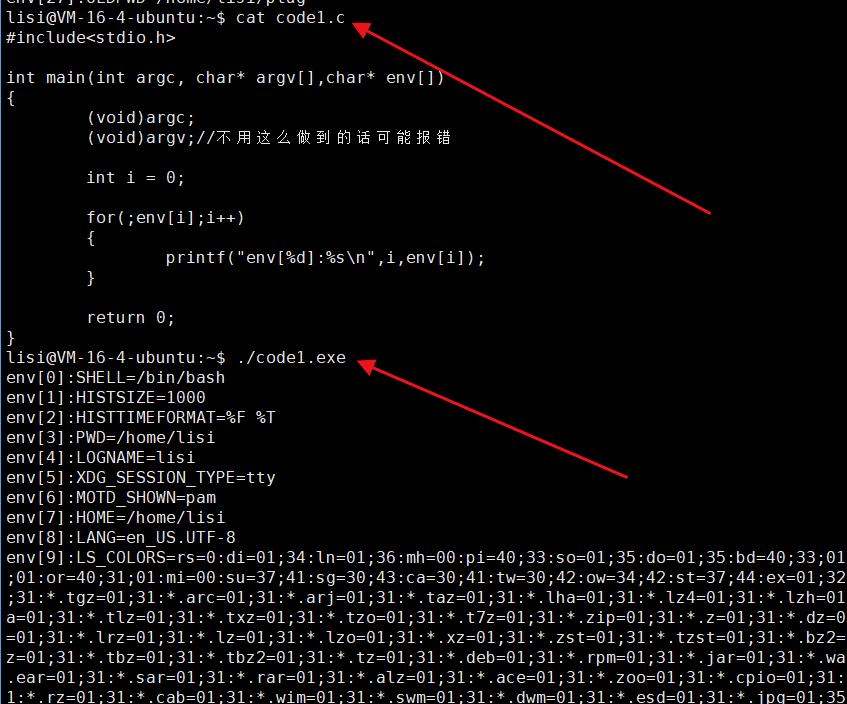
⏩️那么如果没有在main函数里面显示写这三个参数,还有什么办法可以获取到环境变量表吗?
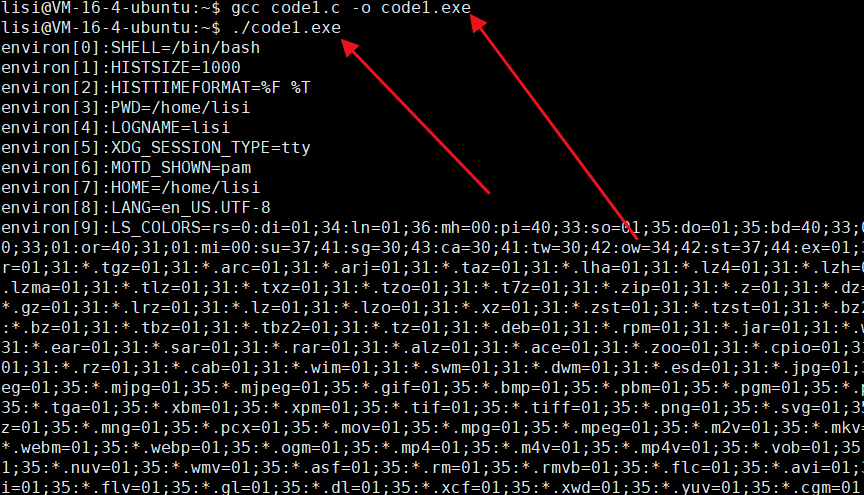
✅️答:当然有,我们可以通过库函数里面的 environ 变量来打印出来,他是跟 env 的使用方法也是一样的,也是以NULL结尾。
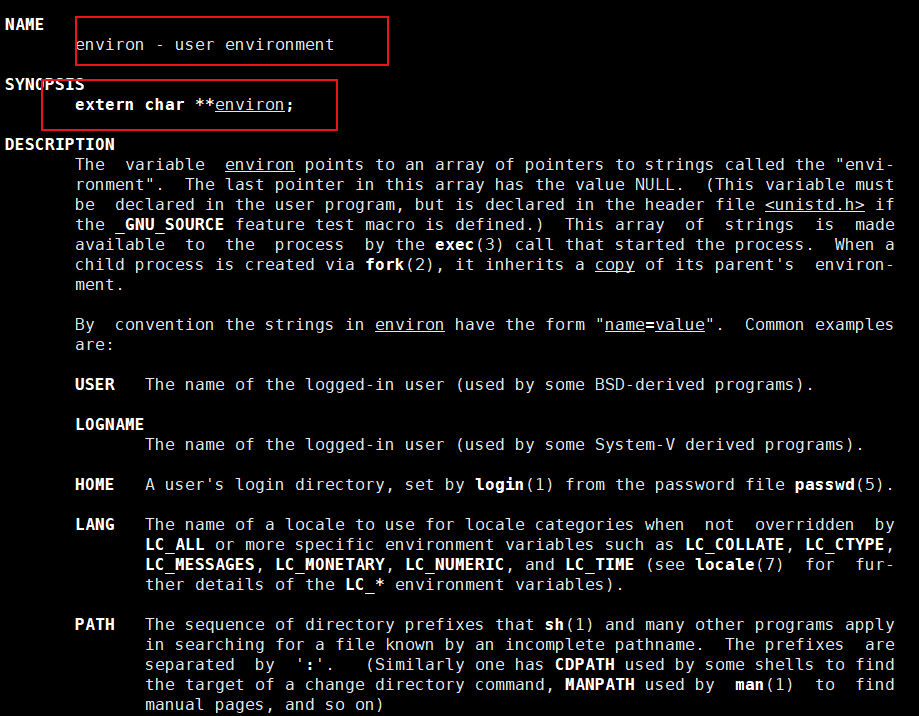
#include<stdio.h>
#include<unistd.h>
int main()
{extern char **environ;//声明一下int i = 0;for(; environ[i];i++){printf("environ[%d]:%s\n",i,environ[i]);}return 0;
}
⏩️上面的所有例子不重要,最重要的是下面这个:getenv 函数,可以通过指定环境变量的名字来获取指定环境的内容。
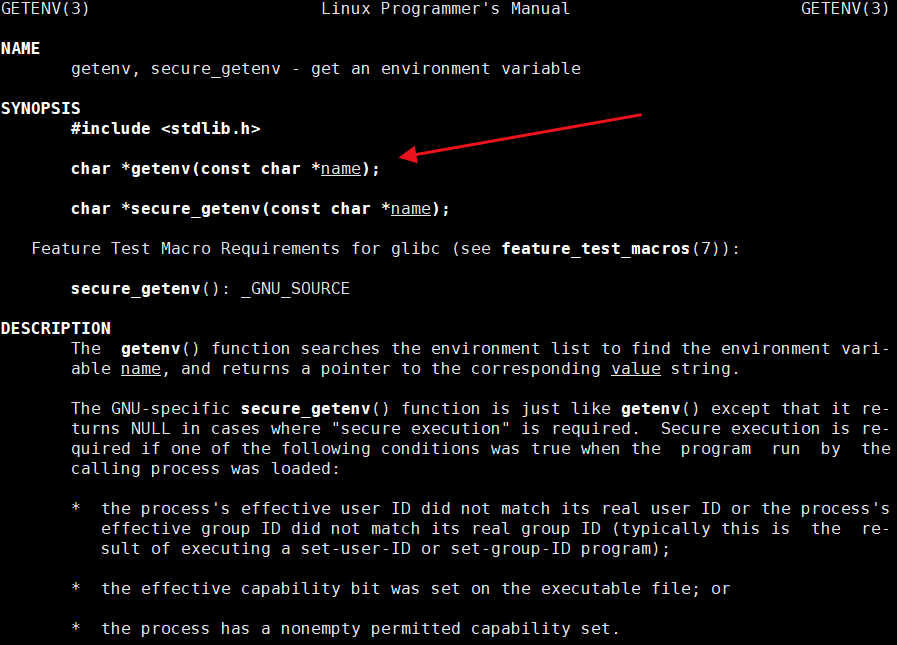
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<string.h>int main()
{char* whoami = getenv("USER");if(whoami == NULL){printf("没有该环境变量");}else if(strcmp(whoami,"lisi") == 0){printf("是我想要的whoami:%s\n",whoami);}else{return 0;}return 0;
}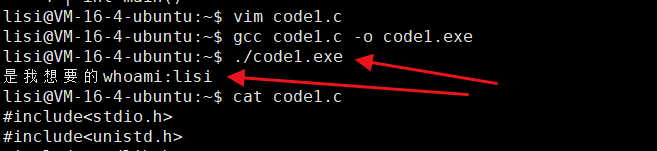
⏩️所以获取一个环境变量的有户名和我们文件指定用户一样的话就让该文件执行,不是就不允许执行。这就是环境变量的用处。
⏩️那么问题又来了,main函数的那三个参数是谁传给main函数的呢?
✅️答:首先main函数的三个参数的内容是默认在bash内部,而bash本身就是个进程,所以这三个参数的数据保存在内存中,我们执行的命令、程序等都是 bash 的子进程,那么父子进程的数据是共享的,所以这三个参数是bash传的。
✅️结论:环境变量具有全局性。
⏩️那么问题又来了,bash进程的环境变量又是从哪里来的?
✅️答:bash 的环境变量是从 Linux 系统的配置文件中来,这就解释了为什么我们更改环境变量(从内存中改)之后,退出又重新登录 XShell 恢复到原来默认的配置环境(其实就是结束bash进程,然后重新启动该进程)。
⏩️那么 Linux 系统的配置文件是什么呢?在哪里呢?
✅️答:存在在每个用户的家目录,而且这两个配置文件是隐藏文件分别是:.bash_profile 和 .bashrc,bash 先访问 .bash_profile ,然后 .bash_profile 再访问 .bashrc,最后 .bashrc 再访问 /etc/bashrc 文件,这个文件是用 shell 脚本写的,太复杂了,这里就不再多说;登录的 XShell 的时候不是要配置文件,我们可以在 .bashrc 或者 .bash_profile 文件里面添加一些内容,例如:打印一些信息,等我们重新登录这个用户的时候就会显示这些信息。
❌️注意:每个用户都有自己的 bash ,这意味着每个用户都有自己的配置文件。当我们登录用户的时候 .bashrc 和 .bash_profile 都会自动执行。这就意味着如果我们想保存自己写的环境变量,就在 .bashrc 或者 .bash_profile 文件里面写入就行。
⏩️问题:那么我们创建自己的环境变量呢?
✅️答:输入指令:变量名(大写)= 数字或者值,此时创建的是本地变量,在环境变量里面是没有该变量的,所以再输入指令:export 该变量名,此时就能在环境变量中找到这个变量了。

⏩️当然也可以一步到位:
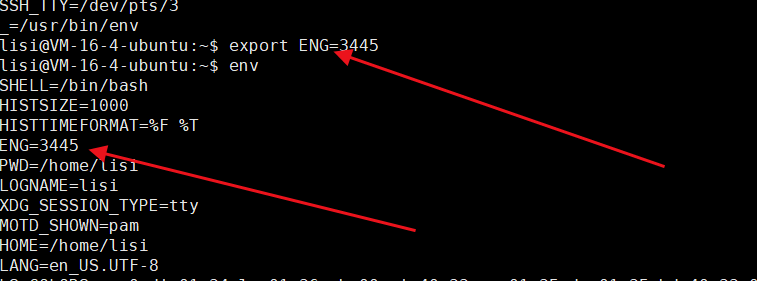
❌️注意:我们是在内存改的,所以重新登录 XShell 的时候就会默认的环境变量。
⏩️那么怎么删除自己写的环境变量呢?
✅️答:指令: unset 环境变量名。其实不删除也行,这都是在内存里面进行操作的。

⏩️上面我们提到了本地变量,本地变量:无法被子进程获取,不具有全局性,只能在 bash 内部可以访问。
⏩️本地变量的用处:在 XShell 里面输入指令有用,对指令的语法具有帮助。
⏩️指令:set ,可以显示环境变量和本地变量。
⏩️存在特定路径而且存在二进制文件的命令:普通命令。
⏩️在shell内部自己定义,bash自己内部的一次函数调用,不依赖第三方路径:内建命令。
四、总结
⏩️本文讲述进程是怎么调度,当然这个问题也是面试常问的,我们不可以把所有的知识点都记住但是我们可以记住每个知识点的逻辑,把每个知识点串联起来,形成完整的逻辑线有助于我们更好的记住知识点。
⏩️哦!对了,各位优秀的程序员觉得我博客给你带来帮助或者让你学到了知识,记得给博主一个关注哦~❤️❤️❤️
⏩️各位博友,下篇博客见🍁🍁🍁