算法笔记 05
1 哈希表和 Map 键值对
哈希表(Hash Table)和 Map 键值对在概念和应用上既有联系又有区别,主要体现在以下几个方面:
1. 定义与本质
- 哈希表:是一种数据结构,底层通过哈希函数将键(Key)映射到数组的索引位置,实现高效的插入、查询和删除操作(平均时间复杂度为 O (1))。它是一种具体的存储和组织数据的方式,核心是利用哈希函数解决键与值的映射关系。
- Map:是一种抽象数据类型(ADT) 或接口,定义了 “键值对” 的集合,支持通过键查找、添加、删除值等操作。它描述的是 “键唯一对应值” 的逻辑关系,不规定具体的实现方式。
2. 实现与被实现的关系
- Map 作为接口,需要具体的实现类来完成功能。哈希表是实现 Map 的常见方式之一(例如 Java 中的
HashMap、Python 中的dict本质上都是基于哈希表实现的 Map)。 - 除了哈希表,Map 还可以通过其他数据结构实现,例如:
- 平衡二叉搜索树(如 Java 中的
TreeMap,基于红黑树实现,保证键的有序性); - 链表(效率较低,较少直接使用)。
- 平衡二叉搜索树(如 Java 中的
3. 功能与特性
- 哈希表:核心特性是 “哈希映射”,强调通过哈希函数快速定位元素,通常不保证键的顺序(插入顺序或自然顺序)。
- Map:作为键值对集合的抽象,更关注 “键唯一” 和 “键值关联” 的逻辑,不同实现类会附加不同特性:
- 基于哈希表的 Map(如
HashMap):高效但无序; - 基于树的 Map(如
TreeMap):有序但效率略低(O (log n)); - 部分 Map(如 Java 的
LinkedHashMap):通过链表维护插入顺序,底层仍依赖哈希表。
- 基于哈希表的 Map(如
4. 术语使用场景
- 在讨论数据结构实现时,常用 “哈希表” 描述具体的存储方式(如解决哈希冲突的链地址法、开放寻址法等)。
- 在讨论键值对操作接口时,常用 “Map” 表示这种键值映射的抽象(如调用
put(key, value)、get(key)等方法)。
总结
- 哈希表是具体的存储结构,通过哈希函数实现高效的键值映射;
- Map 是键值对集合的抽象接口,哈希表是其最常用的实现方式之一。
简单说:Map 是 “键值对功能” 的定义,哈希表是实现该功能的一种高效手段。
2 哈希冲突
哈希表核心原理 | labuladong 的算法笔记![]() https://labuladong.online/algo/data-structure-basic/hashmap-basic/#%E5%93%88%E5%B8%8C%E5%86%B2%E7%AA%81如果两个不同的
https://labuladong.online/algo/data-structure-basic/hashmap-basic/#%E5%93%88%E5%B8%8C%E5%86%B2%E7%AA%81如果两个不同的 key 通过哈希函数得到了相同的索引,怎么办呢?这种情况就叫做「哈希冲突」。
哈希冲突是否可以避免?
哈希冲突不可能避免,只能在算法层面妥善处理出现哈希冲突的情况。
哈希冲突是一定会出现的,因为这个 hash 函数相当于是把一个无穷大的空间映射到了一个有限的索引空间,所以必然会有不同的 key 映射到同一个索引上。
就好比三维物体映射到二维影子一样,这种有损压缩必然会出现信息丢失,有损信息本就无法和原信息一一对应。
3 我的理解与细节纠正
我的理解是:
hash表底层是一个table数组,例如java里面会通过hashcode来查找有关值存放的内存地址,所以如果要查找元素用hash表会很高效率,本质上是一个直接访问的数组。
map键值对是一个接口,接口也就是一个蓝图,没有具体的实例方法,而具体实例里面的键值对是人为规定的,和底层table数组无关,类似于一种可以直接检索的字典。
你的理解方向是对的,尤其是对哈希表底层实现和 Map 接口本质的把握,不过可以再补充一些细节让认知更完整:
-
关于哈希表的底层实现你说哈希表底层是
table数组(比如 Java 中HashMap的table字段),且通过hashCode定位内存地址,这一点很准确。但需要注意:- 哈希表并非直接用
hashCode作为数组索引(因为hashCode可能是很大的整数,超出数组长度),而是会对hashCode进行哈希运算(比如取模、高位扰动等),得到一个落在数组长度范围内的索引,再通过这个索引访问数组元素。 - 当多个键的哈希结果冲突时(即索引相同),哈希表会通过 “链地址法”(链表或红黑树)或 “开放寻址法” 解决冲突,这也是哈希表实现中很重要的部分。
- 你说它 “本质上是一个直接访问的数组”,核心是对的 —— 通过哈希函数将 “键” 转化为类似 “数组下标” 的索引,从而实现 O (1) 级别的快速访问,这是哈希表高效的根本原因。
- 哈希表并非直接用
-
关于 Map 接口与键值对的关系你说 Map 是 “蓝图”(接口),没有具体实现,而具体实例的键值对是 “人为规定的”,这一点没错。但需要明确:
- Map 接口定义的 “键值对” 逻辑(键唯一、通过键访问值),其具体实现必然依赖底层数据结构,而不是 “和底层数组无关”。比如:
HashMap依赖哈希表(数组 + 链表 / 红黑树)存储键值对;TreeMap依赖红黑树(一种平衡二叉树)存储键值对,此时底层就不是数组,而是树结构。
- 你将 Map 类比为 “可直接检索的字典”,这个比喻很贴切 —— 无论底层用哈希表还是树,Map 给用户的都是 “通过键查值” 的统一体验,底层细节对用户透明。
- Map 接口定义的 “键值对” 逻辑(键唯一、通过键访问值),其具体实现必然依赖底层数据结构,而不是 “和底层数组无关”。比如:
总结来说,你的理解抓住了核心:哈希表是具体的高效存储结构(基于数组和哈希运算),Map 是键值对操作的抽象接口(定义 “字典” 式的功能),而哈希表是实现 Map 的最常用方式之一。补充细节后,对两者的关系和本质会更清晰。
4 注意hash表的key是无序的
由于 hash 函数要把你的 key 进行映射,所以 key 在底层 table 数组中的分布是随机的,不像数组/链表结构那样有个明确的元素顺序。
哈希表的 key 之所以 “无序”(通常指不保证插入顺序或自然顺序),本质上是由其底层存储和查找的核心机制决定的,具体原因如下:
1. key 的存储位置由哈希函数计算,与插入顺序无关
哈希表的核心是通过 哈希函数 将 key 映射到数组的索引位置。这个映射过程完全由 key 自身的特征(如 hashCode)和哈希函数的逻辑决定,与 key 的插入顺序毫无关系。例如:
- 先插入的 key A 可能被哈希函数映射到索引 10;
- 后插入的 key B 可能被映射到索引 2;
- 再插入的 key C 可能被映射到索引 15。
最终 key 在底层数组中的存储位置是 “随机” 分布的(由哈希函数决定),自然无法保证与插入顺序一致。
2. 哈希冲突处理进一步打破顺序
即使两个 key 的哈希值不同,也可能因数组长度限制(通过取模等操作压缩索引范围)导致 哈希冲突(映射到同一个数组索引)。此时哈希表会通过 “链地址法”(链表或红黑树)或 “开放寻址法” 处理冲突:
- 链地址法中,冲突的 key 会被放入同一个索引下的链表 / 树中,它们的顺序取决于插入和扩容时的调整,与原始插入顺序无关;
- 开放寻址法中,冲突的 key 会被放到下一个空闲位置,进一步打乱顺序。
冲突处理机制使得 key 的实际存储位置更加 “无序”。
3. 扩容机制会打乱已有 key 的位置
哈希表的数组长度(容量)是动态扩容的(如 Java HashMap 负载因子达到阈值时扩容)。扩容时,所有 key 会被重新计算哈希值并映射到新的数组中,原有位置被彻底打乱。例如,原本在索引 2 的 key,扩容后可能被映射到新数组的索引 5 或 10,导致顺序完全改变。
4. “无序” 是为了换取高效性能
哈希表的设计目标是 O (1) 级别的插入、查询、删除效率。
为了实现这一点,它必须通过哈希函数直接定位 key 的位置,而不是维护一个有序结构(如链表的前后指针、树的父子关系)。
维护顺序需要额外的开销(如红黑树的旋转、链表的插入排序),会降低操作效率。
因此,哈希表选择牺牲 “顺序性” 来换取高效的随机访问能力。(有得必有失啊~)
例外:有序的哈希表实现
需要注意的是,“哈希表的 key 无序” 是一般情况,并非绝对。有些哈希表变种会通过额外结构维护顺序,例如:
- Java 的
LinkedHashMap:底层仍是哈希表,但通过额外的双向链表记录插入顺序或访问顺序; - Python 3.7+ 的
dict:优化了底层实现,保证插入顺序(但本质仍是哈希表,通过额外数组记录顺序)。
这些实现的 “有序” 是通过增加额外存储和维护成本实现的,并非哈希表的原生特性。
总结
哈希表的 key 无序,是因为其底层通过哈希函数随机映射存储位置,且受冲突处理、扩容等机制影响,无法保证与插入顺序或自然顺序一致。这种 “无序” 是哈希表为了追求高效性能而做出的设计取舍。
5 用链表加强哈希表(LinkedHashMap)
一、先明确:为什么要用链表 “加强” 哈希表?
普通哈希表(如 HashMap)的核心问题是 “无序”,而实际开发中经常需要 “按插入顺序遍历” 或 “按访问频率排序”(比如 LRU 缓存)。(key无序)
但哈希表的底层是数组 + 链表 / 红黑树,其存储位置由哈希函数决定,天然无法保证顺序。
这时候,链表的 “有序性” 就成了完美补充 —— 用链表记录元素的顺序,用哈希表保证查询效率,两者结合就是 LinkedHashMap 的核心思路。
二、底层结构:哈希表 + 双向链表,怎么 “缝合” 的?
LinkedHashMap 本质是 “哈希表的骨架 + 双向链表的灵魂”,底层结构可以拆解为两部分:
1. 继承 HashMap,复用哈希表核心功能
LinkedHashMap 继承自 HashMap,所以它底层同样有:
- 一个
table数组(哈希桶数组),每个元素是链表或红黑树的头节点(解决哈希冲突); - 通过
hashCode()和哈希函数计算索引,实现 O (1) 级别的get/put操作; - 动态扩容机制(负载因子超过阈值时扩容)。
这意味着 LinkedHashMap 完全拥有哈希表的高效查询能力,和 HashMap 的核心操作逻辑一致。
2. 新增双向链表,记录 “顺序”
为了实现 “有序”,LinkedHashMap 在 HashMap 的基础上,给每个键值对(Entry)增加了两个指针:before 和 after,用来串联所有元素形成 双向链表。
可以理解为:每个键值对不仅 “挂在” 哈希表的某个桶里(数组 + 链表 / 红黑树),还 “串在” 一条双向链表上。
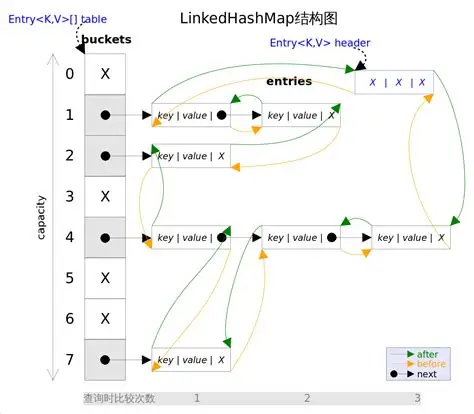
想象一个场景:
哈希表的每个桶里有一堆元素,同时所有元素又像穿珠子一样用一条线串起来,这条线就是双向链表)
- 双向链表的作用:严格记录元素的插入顺序或访问顺序(二选一,由参数控制)。
- 每个 Entry 的结构(简化版):
static class Entry<K,V> extends HashMap.Node<K,V> {Entry<K,V> before, after; // 双向链表的前后指针Entry(int hash, K key, V value, Node<K,V> next) {super(hash, key, value, next); // 继承 HashMap.Node 的哈希表相关字段(hash、key、value、next)} }next指针:属于哈希表的一部分,指向当前桶中冲突的下一个元素(解决哈希冲突);before/after指针:属于双向链表的一部分,指向前后元素(维护顺序)。
三、核心特性:两种 “顺序” 怎么实现的?
LinkedHashMap 的有序性体现在遍历顺序上,有两种模式,由构造函数的 accessOrder 参数控制:
1. 插入顺序(默认,accessOrder = false)
- 规则:元素在双向链表中的位置,严格按照插入的先后顺序排列。先插入的在链表前面,后插入的在后面;修改已有元素的值(
put已存在的 key)不改变顺序。 - 举例:
遍历结果:LinkedHashMap<String, Integer> map = new LinkedHashMap<>(); map.put("A", 1); // 链表:A map.put("B", 2); // 链表:A -> B map.put("C", 3); // 链表:A -> B -> C map.put("A", 10); // 链表不变(仍为 A -> B -> C),仅更新值A -> B -> C(和插入顺序完全一致)。
2. 访问顺序(accessOrder = true)
-
规则:每次 “访问” 元素(
get或put已存在的 key)后,该元素会被移到双向链表的末尾(成为 “最近访问” 的元素);新插入的元素仍放在链表末尾。 -
举例:
// 构造时指定 accessOrder = true LinkedHashMap<String, Integer> map = new LinkedHashMap<>(16, 0.75f, true); map.put("A", 1); // 链表:A map.put("B", 2); // 链表:A -> B map.get("A"); // 访问 A,移到末尾 → 链表:B -> A map.put("C", 3); // 新插入,放末尾 → 链表:B -> A -> C map.put("B", 20); // 访问 B(修改已有key),移到末尾 → 链表:A -> C -> B遍历结果:
A -> C -> B(最近访问的 B 在最后)。 -
关键:这种模式是实现 “LRU 缓存” 的核心(LRU 即 “最近最少使用”,淘汰链表头部的元素即可)。
四、关键操作:如何维护双向链表的顺序?
LinkedHashMap 对 HashMap 的核心改造,是在 put get 等操作时,额外维护双向链表的顺序。我们拆解开来看:
1. 插入元素(put 方法)
HashMap 的 put 方法会调用 newNode 创建新节点,LinkedHashMap 重写了这个方法,在创建节点时把它加到双向链表的末尾:
// LinkedHashMap 重写 newNode,新增双向链表操作
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {LinkedHashMap.Entry<K,V> p = new LinkedHashMap.Entry<>(hash, key, value, e);linkNodeLast(p); // 把新节点加到双向链表的最后return p;
}// 私有方法:将节点 p 链接到链表末尾
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {LinkedHashMap.Entry<K,V> last = tail; // 记录当前尾节点tail = p; // 新节点成为新的尾节点if (last == null) // 如果链表为空,新节点也是头节点head = p;else { // 否则,把新节点接在原尾节点后面p.before = last;last.after = p;}
}
这就是 “插入顺序” 的核心:新节点一定放在链表末尾。
2. 访问元素(get 方法)
当 accessOrder = true 时,get 方法会触发 “将元素移到链表末尾” 的操作:
public V get(Object key) {Node<K,V> e;if ((e = getNode(hash(key), key)) == null) // 先调用 HashMap 的 getNode 查元素return null;if (accessOrder) // 如果是访问顺序模式afterNodeAccess(e); // 把访问的节点移到链表末尾return e.value;
}// 关键:将节点 e 移到链表末尾
void afterNodeAccess(Node<K,V> e) {LinkedHashMap.Entry<K,V> last;if (accessOrder && (last = tail) != e) { // 当 e 不是尾节点时LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e;LinkedHashMap.Entry<K,V> b = p.before; // e 的前节点LinkedHashMap.Entry<K,V> a = p.after; // e 的后节点p.after = null;// 从原位置移除 eif (b == null) // e 是头节点head = a;elseb.after = a;if (a != null)a.before = b;else // e 是尾节点(但上面已判断 last != e,所以这里不会触发)last = b;// 把 e 接到尾节点后面if (last == null)head = p;else {p.before = last;last.after = p;}tail = p; // e 成为新的尾节点}
}
简单说:先把节点从原来的位置 “拆下来”,再 “接到” 链表的最后,这就是 “访问顺序” 的核心。
3. 扩容时的链表维护
HashMap 扩容时会把旧数组的元素重新哈希到新数组,LinkedHashMap 重写了扩容的 transfer 方法,确保在转移元素时,双向链表的顺序不变(因为链表顺序和哈希表的桶位置无关,只和插入 / 访问顺序有关)。
五、常见疑惑:和 HashMap 比,有什么代价?
“加强” 是有成本的,LinkedHashMap 比 HashMap 多了这些开销:
- 内存开销:每个节点多了
before和after两个指针,占用更多内存; - 时间开销:
putget操作时需要额外维护双向链表(调整指针),效率略低于HashMap(但日常使用中差距不大); - 遍历效率:虽然遍历
LinkedHashMap是按顺序的,但本质是遍历双向链表,时间复杂度仍是 O (n),和HashMap遍历哈希桶的 O (n) 相当(只是顺序不同)。
六、实际应用:什么时候用 LinkedHashMap?
- 需要按插入顺序遍历:比如日志记录(按时间顺序输出)、配置项存储(按定义顺序读取);
- 实现 LRU 缓存:利用
accessOrder = true,链表头部就是 “最久未使用” 的元素,淘汰时直接删头部即可(Java 中可重写removeEldestEntry方法自动淘汰);// 简易 LRU 缓存:最多存 3 个元素,满了就删最久未用的 LinkedHashMap<String, Integer> lruCache = new LinkedHashMap<>(16, 0.75f, true) {@Overrideprotected boolean removeEldestEntry(Map.Entry<String, Integer> eldest) {return size() > 3; // 当 size 超过 3 时,自动删除最久未用的元素(链表头部)} }; - 需要稳定的遍历顺序:
HashMap遍历顺序可能因扩容改变,LinkedHashMap的顺序则绝对稳定(插入顺序模式下)。
七、总结:一句话说清 LinkedHashMap
用哈希表保证 get/put 的高效性(O (1)),用双向链表记录元素的插入 / 访问顺序,代价是稍多的内存和时间开销,换来有序性和缓存等实用功能。
⭐初学者可以这样记:
LinkedHashMap = HashMap 的效率 + 链表的顺序,是哈希表 “有序化” 的最佳实践。
6 “HashMap”“、哈希表数据结构”、“抽象接口”
【哈希表的接口就是hashmap吗,就是java前面那个键值对,又不是hash表这种数据结构,所以说hashmap的api应该就是泛指各个编程语言的hash原理的实现,一种抽象接口?】
你的理解已经很接近核心了,但需要把 “HashMap”“哈希表数据结构”“抽象接口” 这几个概念的关系再捋顺,避免混淆。
简单说:HashMap 是 “哈希表数据结构” 的一种具体实现,而 “哈希表的接口” 是所有哈希表实现都要遵守的 “操作规范”,不是 “泛指实现”,而是 “定义实现要满足的功能”。
一、先破误区:HashMap ≠ 抽象接口,而是 “哈希表数据结构” 的 Java 实现
你说 “HashMap 是 Java 前面那个键值对”,这个没错 —— 但要明确:
- HashMap 的本质:是 Java 语言中,对 “哈希表数据结构” 的具体实现类。它底层用 “数组 + 链表 / 红黑树” 实现了哈希表的核心逻辑(哈希映射、冲突解决),同时遵循了 Java 中的
Map接口(这才是 “抽象接口”)。 - 它不是接口:接口是 “只定义方法,没有具体代码” 的(比如 Java 的
Map接口,里面只有put()get()的方法声明,没有实现);而 HashMap 是 “写了具体代码” 的实现类,能直接new HashMap<>()创建对象来用。 - 类比理解:如果把 “哈希表” 看作 “手机”(一种设备类型),那么:
- “哈希表的接口” 就是 “手机的功能规范”(能打电话、能上网、能发短信);
- HashMap 就是 “某品牌的具体手机”(比如苹果 15),它符合 “手机功能规范”,同时有自己的硬件实现(比如用了 A17 芯片);
- Java 中的
Map接口,就是 “手机功能规范” 的书面定义(写清楚 “必须有打电话方法、必须有上网方法”)。
二、再明确:“哈希表的接口” 不是 “泛指实现”,而是 “统一功能约定”
你说 “HashMap 的 api 应该就是泛指各个编程语言的 hash 原理的实现,一种抽象接口”,这里有个小偏差:
- “哈希表的接口” 不是 “泛指实现”:而是 “所有哈希表实现都要遵守的功能约定”。比如 “必须支持存键值对、必须支持按键取值、必须支持删键值对”—— 不管是 Java 的 HashMap、Python 的 dict、C++ 的 unordered_map,都要满足这个约定,这才是 “哈希表的接口” 的核心。
- HashMap 的 API 是 “具体实现的操作方法”:比如 HashMap 的
put(K key, V value)方法,是 Java 中对 “存键值对” 这个接口约定的具体实现代码;而 Python dict 的dict[key] = value,是 Python 中对同一个 “存键值对” 约定的另一种实现语法。它们都遵循 “哈希表接口” 的功能约定,但实现方式(语法、底层细节)不同。 - 抽象接口是 “跨语言的功能共识”:比如 “按 key 取 value” 这个功能,Java 叫
get(key),Python 叫dict.get(key),JavaScript 叫map.get(key)—— 虽然方法名 / 语法略有差异,但功能完全一致,这就是 “哈希表抽象接口” 在不同语言中的体现。
三、关键关系图:一句话理清所有概念
为了让你一眼看明白,用 “功能约定→具体实现” 的逻辑串起来:
plaintext
哈希表的核心功能约定(抽象接口)
├─ 必须支持:存键值对、按键取值、按删除键值对、判断键是否存在
│
├─ Java 中的体现:
│ ├─ 抽象接口:java.util.Map(写死上述功能的方法声明,如 put()、get())
│ └─ 具体实现:HashMap(遵守 Map 接口,用“数组+链表/红黑树”实现哈希表逻辑)
│
├─ Python 中的体现:
│ ├─ 抽象接口:无明确的“Map 接口”类,但 dict 遵守上述功能约定
│ └─ 具体实现:dict(用哈希表逻辑实现,支持 dict[key]=value、dict.get(key) 等操作)
│
└─ C++ 中的体现: ├─ 抽象接口:无单独接口类,unordered_map 遵守哈希表功能约定 └─ 具体实现:unordered_map(哈希表实现,支持 insert()、find() 等操作)
总结:纠正两个小偏差,理解就通了
- 不是 “HashMap 的 API 是抽象接口”:而是 HashMap 遵守 “哈希表的抽象接口”(Java 中对应
Map接口),并实现了接口约定的所有功能; - 不是 “泛指各个语言的 hash 实现”:而是 “各个语言的 hash 实现(如 HashMap、dict),都遵循同一个‘哈希表抽象接口’的功能约定”—— 约定是统一的,实现是多样的。
比如你用 Java 的 HashMap 会 map.put(key, value),换成 Python 的 dict 用 dict[key] = value,本质都是在做 “存键值对” 这个接口约定的操作 —— 这就是抽象接口的价值。
7 用数组加强哈希表(ArrayHashMap)
在学过普通哈希表(数组 + 链表解决冲突)和链表加强哈希表(LinkedHashMap,用双向链表维护顺序)之后,我们来理解 “用数组加强哈希表”(暂称 ArrayHashMap)。
它的核心思路是:用两个平行数组分别存储键和值,通过简化哈希映射实现高效操作,同时利用数组特性轻松支持随机访问键(randomKey())。
一、为什么需要 “数组加强”?—— 解决普通哈希表的两个痛点
普通哈希表(如 HashMap)和链表加强哈希表(LinkedHashMap)虽然高效,但有两个场景处理起来不够直观:
- 随机获取一个键(
randomKey()):普通哈希表的键分布在哈希桶中,随机访问需要遍历所有桶找非空元素,效率低; - 避免复杂的冲突处理:普通哈希表需要用链表 / 红黑树解决哈希冲突,代码复杂,而
ArrayHashMap通过 “键的哈希值直接作为索引”(或简单映射),配合数组的连续存储空间,简化实现。
数组加强的核心优势:利用数组的 “索引直接访问” 特性,让 put/get/remove 操作更简单,同时天然支持 O (1) 级别的随机键访问。
二、底层结构:两个平行数组 + 哈希映射
ArrayHashMap 的底层不依赖 “哈希桶数组 + 链表”,而是用 两个平行数组 和 简单哈希函数 实现:
1. 核心存储:键数组和值数组
keys数组:专门存储所有键(key),索引由哈希函数计算得出;values数组:专门存储对应的值(value),values[i]对应keys[i]的值;- 数组容量固定:初始化时指定容量(如 1000),假设所有键的哈希值都能映射到
[0, 容量-1]范围内,且不冲突(如何保证?后面讲)。
例:keys = [null, "a", null, "b", ...]values = [null, 10, null, 20, ...]表示键 "a" 对应值 10(索引 1),键 "b" 对应值 20(索引 3)。
2. 哈希函数:简化到 “直接映射”
普通哈希表的哈希函数需要 “扰动 + 取模”(如 index = (hashCode ^ (hashCode >>> 16)) & (n-1)),目的是压缩索引并减少冲突。但 ArrayHashMap 为了简化,哈希函数设计为:index = key.hashCode() % capacity(capacity 是数组容量)且要求 所有键的哈希值经过取模后不重复(即无哈希冲突)。
疑惑点 1:如何保证无冲突?实际使用中,
ArrayHashMap适合键的哈希值分布均匀且已知范围的场景(如键是整数0~999,直接用index = key即可)。如果键可能冲突,需提前处理(如选择更大的容量,或手动确保键的唯一性)。
3. 与普通哈希表的结构对比
| 结构 | 普通哈希表(HashMap) | ArrayHashMap |
|---|---|---|
| 底层存储 | 哈希桶数组 + 链表 / 红黑树 | 两个平行数组(keys + values) |
| 冲突处理 | 链表 / 红黑树 | 要求无冲突(设计时保证) |
| 索引计算 | 复杂哈希函数(扰动 + 取模) | 简单取模(或直接映射) |
| 随机访问键 | 需遍历所有桶(低效) | 直接随机访问数组非空元素(高效) |
三、核心 API 实现:从基础操作到 randomKey()
1. 初始化(构造函数)
需要指定数组容量,并初始化 keys 和 values 数组,同时用一个 size 变量记录实际存储的键值对数量(非空元素数)。
public class ArrayHashMap<K, V> {private K[] keys; // 存储键的数组private V[] values; // 存储值的数组private int capacity; // 数组容量private int size; // 实际存储的键值对数量// 构造函数:指定容量@SuppressWarnings("unchecked")public ArrayHashMap(int capacity) {this.capacity = capacity;this.keys = (K[]) new Object[capacity]; // 泛型数组初始化this.values = (V[]) new Object[capacity];this.size = 0;}
}
疑惑点 2:为什么用泛型数组?因为要支持任意类型的键和值(如
String、Integer),泛型数组可以保证类型安全,避免强制转换错误。
2. 插入键值对(put 方法)
步骤:
① 计算键的哈希索引;
② 检查该索引是否已存在键(若存在且不是当前键,说明冲突,抛出异常);
③ 存入键和值,更新 size。
public void put(K key, V value) {if (key == null) {throw new IllegalArgumentException("键不能为null");}int index = hash(key); // 计算索引// 检查冲突:索引已有其他键if (keys[index] != null && !keys[index].equals(key)) {throw new RuntimeException("哈希冲突:键 " + key + " 与现有键 " + keys[index] + " 冲突");}// 若索引为空,说明是新键,size+1if (keys[index] == null) {size++;}// 存入键值对keys[index] = key;values[index] = value;
}// 哈希函数:计算索引(简化版)
private int hash(K key) {// 确保哈希值为非负数,再取模return (key.hashCode() & 0x7FFFFFFF) % capacity;
}
疑惑点 3:
hashCode() & 0x7FFFFFFF有什么用?因为hashCode()可能返回负数(如字符串"a"的哈希值是 97,而"A"是 65,但有些对象的哈希值可能为负),与0x7FFFFFFF(二进制最高位为 0,其余为 1)按位与后,可将负数转为正数,避免取模后得到负索引。
3. 获取值(get 方法)
步骤:① 计算键的哈希索引;② 若索引处的键与目标键一致,返回对应值;否则返回 null。
public V get(K key) {if (key == null) {return null;}int index = hash(key);// 检查索引处的键是否匹配if (keys[index] != null && keys[index].equals(key)) {return values[index];}return null; // 键不存在
}
4. 删除键值对(remove 方法)
步骤:① 计算键的哈希索引;② 若索引处的键与目标键一致,清空该位置的键和值,更新 size。
public V remove(K key) {if (key == null) {return null;}int index = hash(key);if (keys[index] != null && keys[index].equals(key)) {V oldValue = values[index];keys[index] = null; // 清空键values[index] = null; // 清空值size--;return oldValue;}return null; // 键不存在,返回null
}
5. 随机获取一个键(randomKey 方法)—— 数组加强的核心优势
普通哈希表要随机获取键,需要遍历所有哈希桶找非空元素,时间复杂度 O (n)。而 ArrayHashMap 利用数组的随机访问特性,可实现 O (1) 级别的随机键访问:
步骤:
① 生成一个随机索引(0 ~ capacity-1);
② 若该索引处的键不为 null,直接返回;否则重复
③(直到找到非空键)。
import java.util.Random;public K randomKey() {if (size == 0) {return null; // 空表返回null}Random random = new Random();while (true) {int index = random.nextInt(capacity); // 随机生成索引if (keys[index] != null) {return keys[index]; // 返回非空键}}
}
疑惑点 4:如果数组中空位置很多,
randomKey()会不会效率低?会。因此ArrayHashMap适合 “负载因子较高” 的场景(即数组利用率高,空位置少)。如果空位置多,可维护一个 “非空索引列表”,随机访问时直接从列表中取索引(优化版见下文)。
6. 其他辅助方法
public int size() {return size; // 返回实际键值对数量
}public boolean isEmpty() {return size == 0;
}public boolean containsKey(K key) {return get(key) != null; // 利用get方法判断键是否存在
}
四、优化:解决 randomKey() 在低负载因子下的效率问题
当数组容量大但实际存储的键值对少(负载因子低)时,randomKey() 可能多次生成空索引,效率下降。优化方案:维护一个 nonNullIndices 列表,记录所有非空索引。
import java.util.ArrayList;
import java.util.List;
import java.util.Random;public class ArrayHashMapOptimized<K, V> {private K[] keys;private V[] values;private int capacity;private int size;private List<Integer> nonNullIndices; // 存储所有非空索引@SuppressWarnings("unchecked")public ArrayHashMapOptimized(int capacity) {this.capacity = capacity;this.keys = (K[]) new Object[capacity];this.values = (V[]) new Object[capacity];this.size = 0;this.nonNullIndices = new ArrayList<>();}// 重写put方法:新增键时记录索引到nonNullIndicespublic void put(K key, V value) {if (key == null) {throw new IllegalArgumentException("键不能为null");}int index = hash(key);if (keys[index] != null && !keys[index].equals(key)) {throw new RuntimeException("哈希冲突");}if (keys[index] == null) {size++;nonNullIndices.add(index); // 新增非空索引}keys[index] = key;values[index] = value;}// 重写remove方法:删除键时从nonNullIndices移除索引public V remove(K key) {if (key == null) {return null;}int index = hash(key);if (keys[index] != null && keys[index].equals(key)) {V oldValue = values[index];keys[index] = null;values[index] = null;size--;nonNullIndices.remove((Integer) index); // 移除非空索引return oldValue;}return null;}// 优化后的randomKey:直接从nonNullIndices中随机取索引public K randomKey() {if (size == 0) {return null;}Random random = new Random();int randomIndexInList = random.nextInt(nonNullIndices.size()); // 随机取列表中的索引int actualIndex = nonNullIndices.get(randomIndexInList); // 得到实际数组索引return keys[actualIndex];}private int hash(K key) {return (key.hashCode() & 0x7FFFFFFF) % capacity;}
}
疑惑点 5:
nonNullIndices为什么用ArrayList?因为ArrayList支持 O (1) 级别的随机访问(get方法)和 O (n) 级别的删除(remove方法)。对于put操作,新增索引是 O (1)(尾部添加);对于randomKey,直接随机访问列表元素,效率极高。
五、ArrayHashMap 的适用场景与局限性
适用场景:
- 需要高效随机获取键:如抽奖程序(随机从参与用户中选一个)、随机推荐系统(随机返回一个商品);
- 键的哈希值分布已知且无冲突:如键是连续整数(
0~999),可直接用键作为索引,无需处理冲突; - 追求简单实现:比普通哈希表少了链表 / 红黑树的复杂逻辑,适合初学者理解哈希表核心原理。
局限性:
- 空间利用率低:为了避免冲突,数组容量通常大于实际存储的键值对数量,浪费空间;
- 无法处理哈希冲突:设计时必须保证键的哈希值无冲突,否则会抛出异常;
- 不适合动态扩容:数组容量固定,若键数量超过容量,需要手动重建更大的数组,操作繁琐。
六、总结:ArrayHashMap 的核心价值
ArrayHashMap 是 “用数组特性简化哈希表实现” 的典型案例:
- 用 两个平行数组 存储键值对,省去了普通哈希表的冲突处理逻辑;
- 利用数组的 随机访问特性,轻松实现
randomKey()等普通哈希表难以高效支持的操作; - 适合 键分布已知、需要随机访问 的场景,是对普通哈希表和链表加强哈希表的补充。
理解它的设计后,你会更清晰地认识到:数据结构的 “加强” 并非一定要复杂化,有时利用基础结构(如数组)的特性,就能针对性解决特定问题。
8 一点疑惑:我感觉hash在java的语言里面比较多,像C语言,js,就不怎么讨论这个,为什么?
你的感觉很准!
不是 C 语言、JavaScript 不重视哈希,而是它们对 “哈希” 的处理方式、场景需求和 Java 有本质差异,导致 “讨论频率” 和 “呈现形式” 不同。
核心原因可以拆成「语言设计目标」「哈希功能的载体」「使用场景侧重」三个维度,我们一个个嚼碎了说:
一、先破误区:C/JS 不是不讨论哈希,而是 “不提‘哈希’这两个字,但一直在用”
首先要明确:所有需要 “高效键值映射” 的场景,都离不开哈希原理。
C 和 JS 不是没有哈希,而是它们没有像 Java 那样,把 “哈希” 封装成一个明确的、叫 HashMap 的类,也没有强制要求开发者理解 “哈希表数据结构” 才能用 —— 而是把哈希功能 “藏” 在了更贴合自身语言特性的载体里。
比如:
- JS 里你天天用的
Object/Map,底层就是哈希表实现; - C 里你可能用过的
uthash库、glib库的GHashTable,本质也是哈希表; - 甚至 C 里手动写 “数组 + 链表” 实现键值映射,只要用到 “键→哈希值→索引” 的逻辑,就是在玩哈希。
只是它们不刻意强调 “这是哈希”,而是让你 “直接用结果”—— 就像你用手机不用天天说 “我在用电信号传输”,但你一直在用一样。
二、核心原因 1:语言设计目标不同,决定了 “哈希功能的封装程度”
Java 和 C/JS 的设计目标完全不同,这直接导致了 “哈希” 的呈现形式差异:
(1)Java:“强类型 + 面向对象”,必须把哈希封装成 “标准类”
Java 是 强类型、纯面向对象 的语言,追求 “万物皆对象” 和 “接口统一”。
它的核心目标是让开发者在 “复杂项目” 中,能快速复用标准化的容器(比如存储键值对),不用重复造轮子。
所以 Java 会:
- 专门设计
Map接口(定义哈希表的操作规范),再提供HashMap(哈希表实现)、LinkedHashMap(带链表的哈希表)等具体类; - 强制开发者理解 “哈希表的特性”(比如键唯一、无序 / 有序、冲突处理),因为你要明确选择用
HashMap还是TreeMap; - 甚至在面试中频繁考察
HashMap底层(数组 + 链表 / 红黑树、哈希函数、扩容机制),因为这是 “面向对象 + 容器设计” 的典型案例。
简单说:Java 把 “哈希” 做成了 “标准化的工具包”,你必须认识这个工具包,才能用好它。
(2)C:“底层 + 高性能”,哈希需要 “手动搭骨架”
C 是 面向过程、贴近硬件 的语言,核心目标是 “高性能” 和 “灵活控制内存”。它没有 “类” 的概念,也不提供现成的 “容器库”(标准库只有数组、链表等基础结构),所有复杂结构都需要开发者手动实现。
所以 C 里的 “哈希” 是这样的:
- 没有现成的 “哈希表类”,你要自己写 “哈希函数(比如
hash(key) = key % capacity)+ 数组 + 链表(解决冲突)” 的逻辑; - 或者用第三方库(比如
uthash)—— 但这些库本质是 “用宏定义封装的结构体 + 函数”,不是 “类”,你还是要理解底层的结构体设计(比如存储键、值、下一个节点指针的结构体); - 开发者讨论的不是 “怎么用哈希表”,而是 “怎么写一个高效的哈希函数”“怎么用链表解决冲突更省内存”—— 因为你在 “造轮子”,而不是 “用轮子”。
简单说:C 里的 “哈希” 是 “一堆零散的零件”,你要自己拼出哈希表,所以不常提 “哈希表” 这个整体,而是提 “零件怎么拼”。
(3)JS:“弱类型 + 脚本化”,哈希功能 “藏在日常用法里”
JS 是 弱类型、脚本语言,核心目标是 “快速开发前端 / 简单后端逻辑”,追求 “易用性”—— 让开发者不用关心底层,一行代码就能实现功能。
所以 JS 里的 “哈希” 是这样的:
- 用
Object存键值对(const obj = { name: 'a' }),底层是哈希表,但你不用知道 —— 你只需要知道 “用obj.name能取到值”; - 后来新增的
Map虽然更像 “标准哈希表”(支持任意类型键、可遍历),但开发者用它时,关注的是 “能存非字符串键”“能按插入顺序遍历”,而不是 “它的底层是哈希表”; - 甚至 JS 引擎(比如 V8)会偷偷优化
Object/Map的底层(比如小数据量用数组,大数据量用哈希表),但开发者完全感知不到 —— 你只用关心 “能不能存、能不能取”。
简单说:JS 把 “哈希” 做成了 “隐形的底层能力”,你一直在用,但不用知道它叫 “哈希”。
三、核心原因 2:使用场景侧重不同,决定了 “哈希的讨论频率”
不同语言的主流使用场景,也决定了 “哈希” 是否会被频繁讨论:
(1)Java:高频用于 “后端业务开发”,哈希表是 “核心容器”
Java 主要用来写后端(比如电商系统、管理系统),这些场景里大量需要 “存储键值对”:
- 存用户信息(键:用户 ID,值:用户对象);
- 存缓存数据(键:缓存 Key,值:缓存内容);
- 存配置项(键:配置名,值:配置值)。
这些场景都需要用 HashMap,而且为了优化性能(比如避免扩容、减少冲突),开发者必须讨论 HashMap 的底层细节 —— 比如 “初始容量设多少”“负载因子为什么是 0.75”“红黑树什么时候转链表”。
所以 Java 里 “哈希” 的讨论频率高,本质是 “后端开发离不开 HashMap,且需要优化它”。
(2)C:高频用于 “底层开发”,哈希不是 “首选工具”
C 主要用来写操作系统、驱动、嵌入式程序 —— 这些场景的核心需求是 “内存可控”“速度极致”,而哈希表的 “随机访问”“冲突处理” 反而可能带来额外开销(比如哈希函数计算时间、链表节点的内存开销)。
所以 C 里更常用的是:
- 数组(直接用索引访问,比哈希表快);
- 链表(内存连续,适合动态增删);
- 二叉搜索树(适合有序遍历,比哈希表省内存)。
只有在 “必须用键值映射” 的场景(比如数据库索引、缓存),才会手动实现哈希表 —— 但这种场景少,所以 “哈希” 的讨论频率自然低。
(3)JS:高频用于 “前端交互”,哈希功能 “够用就行”
JS 主要用来写前端(比如页面交互、表单处理),这些场景里 “键值映射” 的需求很简单:
- 存页面状态(比如
const state = { isShow: true }); - 存临时数据(比如
const user = { id: 1, name: 'a' });
这些需求用 Object 就能满足,而且数据量通常很小(最多几百条),完全不用关心 “哈希冲突”“扩容”—— 哪怕底层有性能问题,用户也感知不到。
就算用 Map,也只是因为 “需要存非字符串键”(比如用对象当键),而不是 “需要优化哈希性能”。所以 JS 里几乎没人讨论 “Map 的底层哈希实现”,因为 “够用就行”。
四、总结:不是 “不讨论”,而是 “以不同形式融入语言”
用一句话概括三者的差异:
- Java:把 “哈希” 做成了 “需要深入理解的标准工具”,所以讨论多;
- C:把 “哈希” 做成了 “需要手动拼接的零件”,所以讨论少(场景也少);
- JS:把 “哈希” 做成了 “不用关心的隐形能力”,所以没人讨论(感知不到)。
本质上,所有语言只要需要 “高效键值映射”,都离不开哈希原理 —— 只是呈现形式和讨论频率,由语言的设计目标和使用场景决定。