机器学习18:扩散模型(Diffusion Model)与Stable Diffusion
摘要
本周课程介绍了扩散模型(Diffusion Model)的基本原理及其在生成式人工智能中的关键作用。扩散模型通过前向过程逐步向数据添加噪声,再通过反向过程从噪声中逐步恢复出清晰图像,实现高质量的内容生成。课程以 Stable Diffusion 为例,详细讲解了其文本编码器、生成模型与解码器的协同工作机制,并阐述了如何通过潜空间优化和条件控制(如文本提示)提升生成效果。此外,课程还对比了扩散模型与生成对抗网络(GAN)、变分自编码器(VAE)在训练稳定性、生成质量与速度等方面的差异,凸显了扩散模型在图像生成领域的优势与演进意义。
Abstract
This week's lesson introduces the fundamental principles of the Diffusion Model and its pivotal role in generative artificial intelligence. The diffusion model progressively adds noise to data in the forward process and then gradually reconstructs clear images from noise in the reverse process, achieving high-quality content generation. Using Stable Diffusion as an example, the course explains in detail the collaborative mechanism among its text encoder, generation model, and decoder, and describes how latent space optimization and conditional control (such as text prompts) enhance the generation results. Furthermore, the lesson compares the diffusion model with Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs) in terms of training stability, generation quality, and speed, highlighting the advantages and evolutionary significance of diffusion models in the field of image generation.
一.概念理解
1.扩散模型(Diffusion Model)
扩散模型这是当前人工智能领域,尤其是生成式AI中最为火热和强大的技术之一。它彻底改变了图像、音频、视频生成领域的技术格局,是DALL·E、Midjourney、Stable Diffusion等著名生成工具的核心基石。
而其核心思想就是
前向过程:遵循确定公式,像图像中添加噪声。

反向过程:从噪声中“提炼”图像。
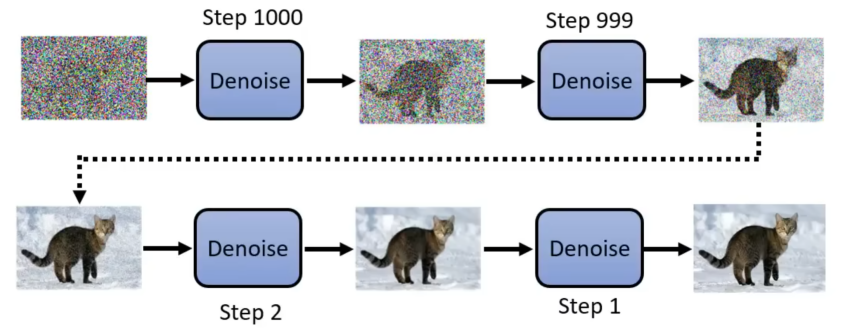
就如上图,先从高斯噪声中随机抽取一个向量(向量维度与要生成的图片大小相同),得到一个纯噪声的图。接着通过去噪模型(Denoise Model),其将会过滤掉部分噪声,从而得到第二张有一个模糊的猫的形状图片。再通过多次去噪,最终就可以得到一个清晰的猫的图片。其中去噪的次数是固定好的,同时也会给每一次去噪一个编号,而这个编号代表了噪声的严重程度,越小表示结果越好,但最小是1。
这就像一位雕塑家:他面对的是一块形状不规则的石料(纯噪声),然后通过不断地凿除多余的部分(去噪),最终雕出一尊精美的雕像(目标图像)。
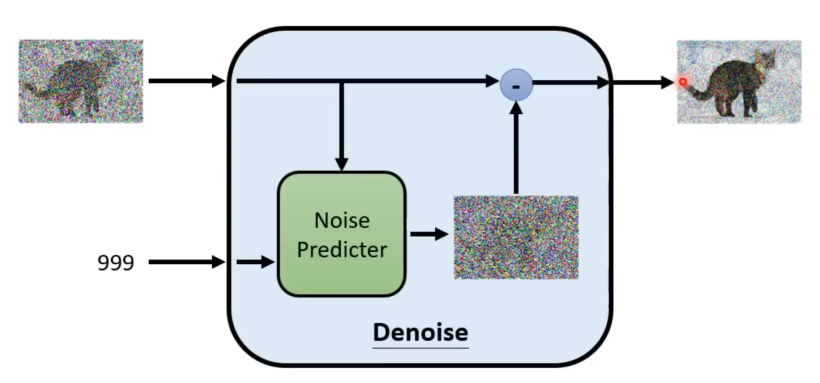
(1)去噪模型(Denoise Model)
在上面过程中,可以看到去噪模型反复多次使用,但是由于每次输入的图片都不一样,若使用同一个参数模型则结果就不一定可以像上面一样。所以为了去噪模型能够“因材施教”,其输入除了一个图片外还要再增加一个数字输入,这个输入代表现在噪声的严重程度。从而去噪模型通过这个新增输入,不断调整去噪程度。

了解了去噪模型大概原理,现在看其内部如何工作的。
在其内部有一个噪声预测器(Noise Predictor),其任务就是根据输入的图片和数值预测当前图片中混入多少,什么样的噪声。然后输出一个噪声图,再将输入的图片减去这个噪声图便得到去噪后的图片。