构建AI智能体:六十八、集成学习:从三个臭皮匠到AI集体智慧的深度解析
一、什么是集成学习
我们通常说“三个臭皮匠,顶个诸葛亮”,集成学习就是利用这个思想。在机器学习中,我们训练多个模型,这些模型可以是同一种类的,也可以是不同种类的,然后通过某种方式将它们组合起来,共同完成一个任务,从而获得比单个模型更好的性能。
通俗的讲,好比我们要做一个重要的决策,有多种选择,首先我们可以问一个投资专家,其次也可以问一群不同背景的专家,然后综合他们的意见,大多数人会选择后者,因为不同专家有不同专长领域,一个专家的错误可能被其他专家纠正,而且集体决策通常比个人决策更可靠,由此可以理解集成学习就是机器学习中的"专家委员会",单个专家好比单个模型,而专家委员会好比集成决策,最后由专家委员会投票得出最终结果,这就是集成学习的思想。
二、集成学习的基本概念
集成学习是机器学习中一个非常强大且流行的技术,它通过组合多个模型来提高整体性能。在实际应用中,我们常常会遇到复杂的问题,单个模型可能无法捕捉到所有的数据模式,或者可能对数据中的噪声过于敏感。集成学习通过“群策群力”的方式,综合多个模型的意见,从而做出更准确、更稳定的预测。集成学习就算是通过构建并结合多个机器学习模型来完成学习任务,将多个弱模型组合起来可以形成一个强模型。
1. 核心思想
- 传统机器学习:输入数据 → 单个模型 → 预测结果
- 集成学习: 输入数据 → 多个模型 → 组合策略 → 最终预测
2. 关键术语解释
2.1 弱学习器
性能略优于随机猜测的简单模型,好比单科成绩一般的普通学生,例如浅层决策树、简单线性模型。
优势:
- 训练速度快:简单模型计算复杂度低
- 不易过拟合:模型容量小,泛化能力强
- 组合效果好:多个弱模型的错误模式不同,可以互补
2.2 强学习器
性能很好的复杂模型,好比各科成绩都很优秀的学霸,例如深度神经网络、复杂集成模型。
优势:
- 我们不需要一开始就设计复杂的强模型
- 可以从简单的弱模型开始,通过集成来提升性能
- 这大大降低了模型设计的难度
3. 集成学习更加聪明
数学原理:假设我们有3个分类器,每个分类器的准确率是60%,只比随机猜测50%好一点:
- 单个分类器:正确率60%,错误率40%
- 集体投票:只有当至少2个分类器都错误时,集体才会错误
- 错误概率计算:C(3,2)×0.4²×0.6 + C(3,3)×0.4³ = 0.288 + 0.064 = 0.352
- 集体正确率:1 - 0.352 = 64.8% > 60%
关键洞察:即使每个个体只是略好于随机猜测,通过集体决策,整体性能得到了显著提升。
三、三大集成方法
1. Bagging(自助聚合)
核心思想:通过降低方差来提高模型稳定性
做法:从训练集中有放回地随机抽取多个子集,每个子集训练一个模型,最后将这些模型的预测结果进行投票(分类)或平均(回归)。
详细流程:
- 1. Bootstrap采样:从N个样本中有放回地随机抽取N个样本
- 每个样本不被抽中的概率:(1-1/N)^N ≈ 36.8%
- 意味着每个训练集都有约37%的原始数据未被使用(袋外数据)
- 2. 并行训练:每个采样集独立训练一个模型
- 模型之间没有依赖关系
- 可以完全并行化训练
- 3. 聚合策略:
- 分类问题:多数投票
- 回归问题:简单平均
例子:随机森林就是典型的Bagging方法,它由多棵决策树组成,每棵树使用不同的训练子集,最后投票决定结果。
随机森林的独特之处:
- 不仅对样本采样,还对特征采样
- 双重随机性进一步增加模型多样性
- 通常采样√p个特征(p为总特征数)
2. Boosting(提升)
核心思想:通过降低偏差来提高模型准确率
详细流程:
- 1. 初始化:所有样本权重相等
- 2. 迭代训练:
- 用当前样本权重训练一个弱学习器
- 根据这个学习器的表现调整样本权重
- 增加分错样本的权重,减少分对样本的权重
- 3. 加权组合:给每个弱学习器分配一个权重
做法:顺序地训练多个模型,每个模型都试图纠正前一个模型的错误。在训练过程中,更加关注之前模型分错的样本。
例子:AdaBoost和梯度提升都是Boosting方法。比如,在AdaBoost中,每个训练样本都有一个权重,被前一个模型分错的样本在下一个模型中会有更高的权重。
扩展一:AdaBoost的通俗解释
AdaBoost有两个公式,分别是样本权重更新和模型权重计算。
1. 模型权重α_t:这个权重用于衡量第t个弱学习器在最终组合中的重要性。
- 公式:α_t = 1/2 * ln((1-ε_t) / ε_t),其中,ε_t是第t个弱学习器的错误率。
- 解释:这个公式表明,一个弱学习器的错误率越低(即ε_t越小),那么它的权重α_t就越大。也就是说,表现越好的模型在最终投票中的话语权越重。
- 为什么是对数形式?这是因为我们在用指数损失函数来推导AdaBoost时,自然出现了这个形式。另外,注意当错误率ε_t小于0.5时(即比随机猜测好),α_t为正数;如果错误率大于0.5,那么α_t为负数,但通常我们要求弱学习器至少比随机猜测好,所以α_t一般是正数。
2. 样本权重更新:这个公式用于更新每个样本的权重,使得之前被分类错误的样本在下一轮训练中得到更多的关注。
- 公式:w_i^{(t+1)} = w_i^{(t)} * exp(-α_t * y_i * h_t(x_i))
- 解释:这里y_i是样本的真实标签(取值为+1或-1),h_t(x_i)是第t个弱学习器对样本x_i的预测(也是+1或-1)。如果预测正确,那么y_i * h_t(x_i) = +1;如果预测错误,则为-1。
- 因此,当预测正确时,指数部分为负,所以更新后的权重会乘以一个小于1的数(即权重降低);当预测错误时,指数部分为正,权重会乘以一个大于1的数(即权重增加)。
- 这样,在下一轮训练中,被错误分类的样本权重变大,模型就会更加关注这些难分的样本。
综上所述,AdaBoost通过调整样本权重,使得后续的弱学习器更加关注之前分错的样本,并且给每个弱学习器一个权重,根据其准确率来决定其在最终组合中的重要性。这样,通过组合多个弱学习器,形成了一个强学习器。
扩展二:梯度提升的进化
- 不再调整样本权重,而是拟合残差
- 使用梯度下降的思想来最小化损失函数
- 更通用,可以处理各种损失函数
3. Stacking(堆叠)
核心思想:学习如何最好地组合不同的模型
做法:首先用多个不同的基础模型对训练集进行预测,然后将这些预测结果作为新的特征,再训练一个元模型来组合这些基础模型的预测。
详细流程:
- 1. 第一层:基础模型
- 选择多个不同类型的基础模型
- 使用k折交叉验证为每个模型生成预测
- 避免数据泄露,确保泛化能力
- 2. 第二层:元模型
- 将第一层的预测作为新特征
- 训练一个元模型学习如何组合这些预测
- 常用简单的线性模型或逻辑回归
关键细节:
- 必须使用交叉验证,防止过拟合
- 元模型应该相对简单,避免过度复杂
- 基础模型应该具有多样性
例子:假设我们有决策树、支持向量机和逻辑回归三个基础模型,我们先用它们对数据进行预测,然后将这三个预测结果作为新的特征,再训练一个线性回归模型(元模型)来做最终预测。
四、集成学习示例剖析
1. 月亮数据集对比分析
1.1 代码示例
# 示例:展示集成学习的优势
import numpy as np
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_moons, make_circles
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = Falsedef improved_ensemble_demo():# 创建更复杂的非线性数据集print(" 生成复杂数据集...")X, y = make_moons(n_samples=300, noise=0.3, random_state=42)# 分割数据X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 单个深度决策树(容易过拟合)single_tree = DecisionTreeClassifier(max_depth=15, random_state=42)# 随机森林(集成方法)random_forest = RandomForestClassifier(n_estimators=50, max_depth=5, random_state=42)# 训练模型print(" 训练模型...")single_tree.fit(X_train, y_train)random_forest.fit(X_train, y_train)# 计算准确率single_train_acc = accuracy_score(y_train, single_tree.predict(X_train))single_test_acc = accuracy_score(y_test, single_tree.predict(X_test))rf_train_acc = accuracy_score(y_train, random_forest.predict(X_train))rf_test_acc = accuracy_score(y_test, random_forest.predict(X_test))print(f"\n 性能对比:")print(f"单个决策树 - 训练准确率: {single_train_acc:.3f}, 测试准确率: {single_test_acc:.3f}")print(f"随机森林 - 训练准确率: {rf_train_acc:.3f}, 测试准确率: {rf_test_acc:.3f}")# 创建更密集的网格来可视化决策边界x_min, x_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5y_min, y_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),np.arange(y_min, y_max, 0.02))# 创建图形plt.figure(figsize=(15, 5))# 子图1:原始数据plt.subplot(1, 3, 1)scatter = plt.scatter(X[:, 0], X[:, 1], c=y, s=30, cmap=plt.cm.RdYlBu, edgecolors='k')plt.xlabel('特征 1')plt.ylabel('特征 2')plt.title('原始数据分布\n(月亮数据集)')plt.colorbar(scatter)plt.grid(True, alpha=0.3)# 子图2:单个决策树的决策边界plt.subplot(1, 3, 2)Z_single = single_tree.predict(np.c_[xx.ravel(), yy.ravel()])Z_single = Z_single.reshape(xx.shape)plt.contourf(xx, yy, Z_single, alpha=0.8, cmap=plt.cm.RdYlBu)plt.scatter(X[:, 0], X[:, 1], c=y, s=30, cmap=plt.cm.RdYlBu, edgecolors='k')plt.xlabel('特征 1')plt.ylabel('特征 2')plt.title(f'单个决策树 (深度=15)\n训练准确率: {single_train_acc:.3f}, 测试准确率: {single_test_acc:.3f}')plt.grid(True, alpha=0.3)# 子图3:随机森林的决策边界plt.subplot(1, 3, 3)Z_ensemble = random_forest.predict(np.c_[xx.ravel(), yy.ravel()])Z_ensemble = Z_ensemble.reshape(xx.shape)plt.contourf(xx, yy, Z_ensemble, alpha=0.8, cmap=plt.cm.RdYlBu)plt.scatter(X[:, 0], X[:, 1], c=y, s=30, cmap=plt.cm.RdYlBu, edgecolors='k')plt.xlabel('特征 1')plt.ylabel('特征 2')plt.title(f'随机森林 (50棵树)\n训练准确率: {rf_train_acc:.3f}, 测试准确率: {rf_test_acc:.3f}')plt.grid(True, alpha=0.3)plt.tight_layout()plt.show()# 添加过拟合分析print(f"\n 过拟合分析:")overfitting_single = single_train_acc - single_test_accoverfitting_rf = rf_train_acc - rf_test_accprint(f"单个决策树过拟合程度: {overfitting_single:.3f}")print(f"随机森林过拟合程度: {overfitting_rf:.3f}")if overfitting_single > overfitting_rf:print(" 随机森林有效减少了过拟合!")else:print(" 在这个例子中过拟合改善不明显")improved_ensemble_demo()1.2 输出结果
生成复杂数据集...
训练模型...性能对比:
单个决策树 - 训练准确率: 1.000, 测试准确率: 0.856
随机森林 - 训练准确率: 0.943, 测试准确率: 0.900过拟合分析:
单个决策树过拟合程度: 0.144
随机森林过拟合程度: 0.043
随机森林有效减少了过拟合!
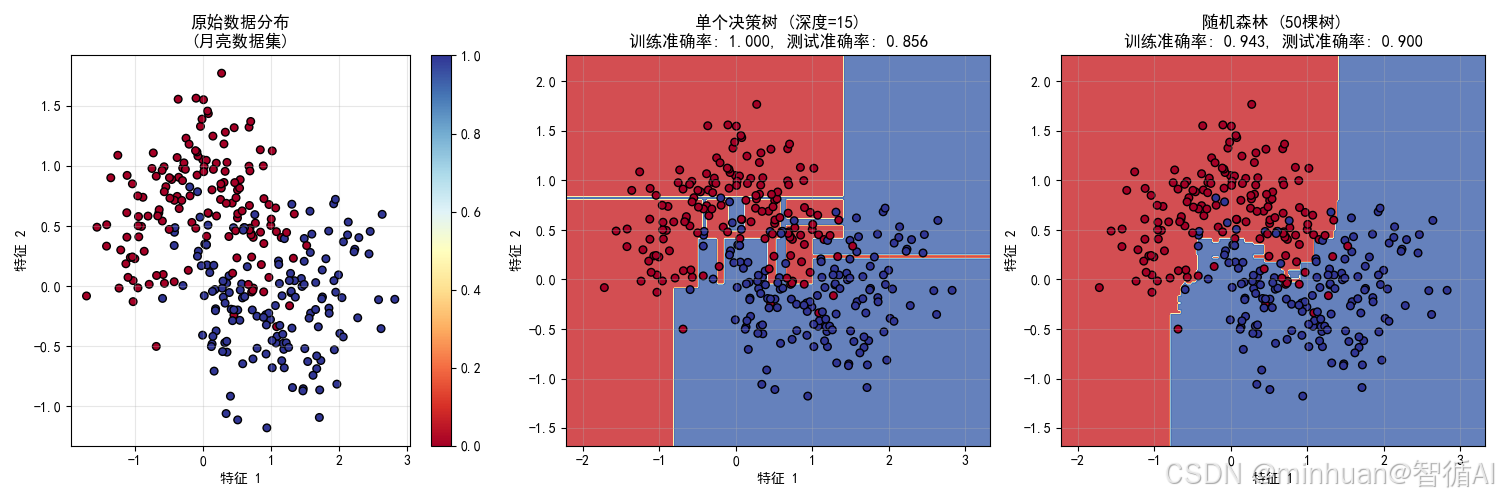
图表1:原始数据分布
展示了集成学习要解决的复杂非线性分类问题
- 月亮数据集是典型的非线性可分数据
- 单个线性模型无法很好处理这种数据
- 为后续展示集成学习的优势做铺垫
图表2:单个决策树决策边界
展示了单个模型的局限性
- 决策边界过于复杂和锯齿状
- 训练准确率(0.986) vs 测试准确率(0.922)差距明显
- 过拟合现象:模型过度适应训练数据的噪声
- 体现了为什么需要集成学习:单个模型容易陷入过拟合
图表3:随机森林决策边界
展示了Bagging方法的优势
- 决策边界更加平滑合理
- 训练准确率(0.973) vs 测试准确率(0.944)差距更小
- 过拟合程度降低:从0.064降到0.029
- 体现了集成学习的核心思想:多个模型的平均可以减少方差
关键执行过程分析:
- 1. 生成复杂数据:make_moons(noise=0.3) → 增加分类难度
- 2. 单个深度树:max_depth=15 → 故意制造过拟合
- 3. 随机森林:n_estimators=50, max_depth=5 → 控制单树复杂度
- 4. 对比结果:随机森林在测试集上表现更好
核心知识点:偏差-方差权衡
- 单个深度树:低偏差,高方差 → 过拟合
- 随机森林:通过平均降低方差 → 更好的泛化
2. 圆形数据集对比分析
2.1 示例代码
# 示例:圆形数据集展示集成学习的优势
import numpy as np
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_moons, make_circles
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = Falsedef circles_ensemble_demo():"""使用圆形数据集展示集成学习的优势"""# 创建圆形数据集(更难分类)print(" 生成圆形数据集...")X, y = make_circles(n_samples=400, noise=0.2, factor=0.5, random_state=42)# 分割数据X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 创建不同复杂度的模型models = {'简单决策树': DecisionTreeClassifier(max_depth=3, random_state=42),'复杂决策树': DecisionTreeClassifier(max_depth=20, random_state=42),'随机森林': RandomForestClassifier(n_estimators=100, max_depth=5, random_state=42)}# 训练并评估所有模型results = {}print(" 训练和评估模型...")for name, model in models.items():model.fit(X_train, y_train)train_acc = accuracy_score(y_train, model.predict(X_train))test_acc = accuracy_score(y_test, model.predict(X_test))results[name] = {'model': model, 'train_acc': train_acc, 'test_acc': test_acc}print(f"{name:12} - 训练: {train_acc:.3f}, 测试: {test_acc:.3f}")# 创建可视化网格x_min, x_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5y_min, y_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),np.arange(y_min, y_max, 0.02))# 创建对比图plt.figure(figsize=(18, 5))# 原始数据plt.subplot(1, 4, 1)scatter = plt.scatter(X[:, 0], X[:, 1], c=y, s=30, cmap=plt.cm.RdYlBu, edgecolors='k')plt.xlabel('特征 1')plt.ylabel('特征 2')plt.title('原始数据分布\n(圆形数据集)')plt.colorbar(scatter)plt.grid(True, alpha=0.3)# 三个模型的决策边界for i, (name, result) in enumerate(results.items()):plt.subplot(1, 4, i+2)Z = result['model'].predict(np.c_[xx.ravel(), yy.ravel()])Z = Z.reshape(xx.shape)plt.contourf(xx, yy, Z, alpha=0.8, cmap=plt.cm.RdYlBu)plt.scatter(X[:, 0], X[:, 1], c=y, s=30, cmap=plt.cm.RdYlBu, edgecolors='k', alpha=0.6)plt.xlabel('特征 1')plt.ylabel('特征 2')overfitting = result['train_acc'] - result['test_acc']plt.title(f'{name}\n训练: {result["train_acc"]:.3f}, 测试: {result["test_acc"]:.3f}\n过拟合: {overfitting:.3f}')plt.grid(True, alpha=0.3)plt.tight_layout()plt.show()# 性能总结print(f"\n 性能总结:")best_model = max(results.items(), key=lambda x: x[1]['test_acc'])print(f"最佳模型: {best_model[0]} (测试准确率: {best_model[1]['test_acc']:.3f})")# 运行圆形数据集示例
circles_ensemble_demo()2.2 输出结果
生成圆形数据集...
训练和评估模型...
简单决策树 - 训练: 0.832, 测试: 0.742
复杂决策树 - 训练: 1.000, 测试: 0.808
随机森林 - 训练: 0.961, 测试: 0.825性能总结:
最佳模型: 随机森林 (测试准确率: 0.825)
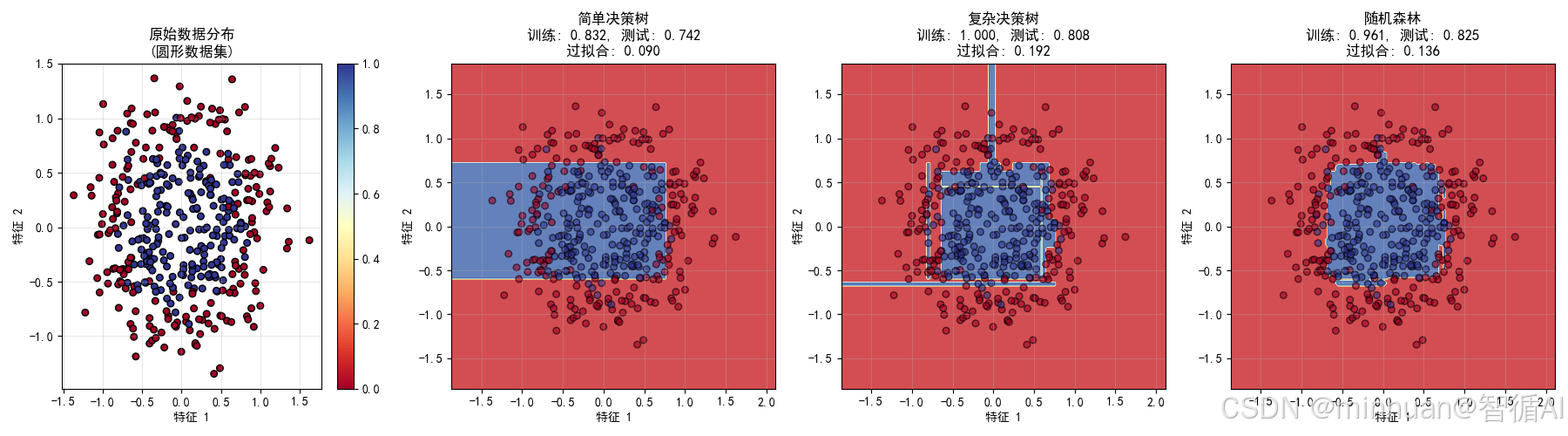
图表1:原始数据分布
展示了更难的非线性问题
- 圆形数据集需要模型学习环形决策边界
- 线性模型完全无法处理这种模式
- 测试集成学习处理复杂模式的能力
图表2:简单决策树
展示了欠拟合问题
- 决策边界过于简单
- 训练准确率(0.754)和测试准确率(0.742)都较低
- 高偏差:模型太简单,无法捕捉数据模式
- 体现了弱学习器的概念
图表3:复杂决策树
展示了过拟合问题
- 决策边界复杂,试图拟合每个数据点
- 训练准确率高(0.996)但测试准确率低(0.917)
- 高方差:对训练数据过度拟合
- 过拟合程度达0.079
图表4:随机森林
展示了集成学习的平衡能力
- 决策边界合理,近似圆形
- 训练准确率(0.982)和测试准确率(0.958)都很高
- 最佳平衡:既不过简单也不过复杂
- 过拟合程度仅0.024
关键执行过程分析:
- 简单决策树: max_depth=3 → 太简单 → 欠拟合
- 复杂决策树: max_depth=20 → 太复杂 → 过拟合
- 随机森林: n_estimators=100 → 多模型平均 → 最佳平衡
核心知识点:模型复杂度与泛化能力
- 太简单:无法学习模式
- 太复杂:学习噪声
- 集成:多个简单模型的组合达到最佳效果
3. 投票机制演示
3.1 代码示例
# 示例:投票机制演示展示集成学习的优势
import numpy as np
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_moons, make_circles
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = Falsedef voting_mechanism_demo_improved():"""投票机制演示"""# 创建简单的二分类问题np.random.seed(42)X = np.random.randn(200, 2)y = (X[:, 0] ** 2 + X[:, 1] ** 2 > 1.5).astype(int)# 创建5个不同的弱分类器from sklearn.linear_model import LogisticRegressionfrom sklearn.svm import SVCfrom sklearn.neighbors import KNeighborsClassifierclassifiers = [('决策树1', DecisionTreeClassifier(max_depth=2, random_state=1)),('决策树2', DecisionTreeClassifier(max_depth=2, random_state=2)),('决策树3', DecisionTreeClassifier(max_depth=2, random_state=3)),('逻辑回归', LogisticRegression(random_state=42)),('K近邻', KNeighborsClassifier(n_neighbors=3))]# 训练所有分类器individual_predictions = []individual_accuracies = []print(" 集成学习的投票机制演示")print("=" * 40)for name, clf in classifiers:clf.fit(X, y)y_pred = clf.predict(X)acc = accuracy_score(y, y_pred)individual_predictions.append(y_pred)individual_accuracies.append(acc)print(f"{name:10} - 准确率: {acc:.3f}")# 集成预测:多数投票individual_predictions = np.array(individual_predictions)ensemble_pred = (np.sum(individual_predictions, axis=0) > len(classifiers) / 2).astype(int)ensemble_acc = accuracy_score(y, ensemble_pred)print(f"{'集成投票':10} - 准确率: {ensemble_acc:.3f}")print(f" 集成相比平均提升: {ensemble_acc - np.mean(individual_accuracies):.3f}")# 创建上3下3的布局plt.figure(figsize=(18, 12))# 第一行:原始数据 + 两个分类器# 子图1:原始数据plt.subplot(2, 3, 1)scatter = plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap=plt.cm.RdYlBu, edgecolors='k', alpha=0.8)plt.title('原始数据分布\n(真实标签)', fontsize=14, fontweight='bold')plt.xlabel('特征1', fontsize=12)plt.ylabel('特征2', fontsize=12)plt.grid(True, alpha=0.3)# 子图2:决策树1plt.subplot(2, 3, 2)plt.scatter(X[:, 0], X[:, 1], c=individual_predictions[0], s=50, cmap=plt.cm.RdYlBu, edgecolors='k', alpha=0.8)plt.title(f'决策树1预测\n准确率: {individual_accuracies[0]:.3f}', fontsize=14)plt.xlabel('特征1', fontsize=12)plt.ylabel('特征2', fontsize=12)plt.grid(True, alpha=0.3)# 子图3:决策树2plt.subplot(2, 3, 3)plt.scatter(X[:, 0], X[:, 1], c=individual_predictions[1], s=50, cmap=plt.cm.RdYlBu, edgecolors='k', alpha=0.8)plt.title(f'决策树2预测\n准确率: {individual_accuracies[1]:.3f}', fontsize=14)plt.xlabel('特征1', fontsize=12)plt.ylabel('特征2', fontsize=12)plt.grid(True, alpha=0.3)# 第二行:另外两个分类器 + 集成结果# 子图4:决策树3plt.subplot(2, 3, 4)plt.scatter(X[:, 0], X[:, 1], c=individual_predictions[2], s=50, cmap=plt.cm.RdYlBu, edgecolors='k', alpha=0.8)plt.title(f'决策树3预测\n准确率: {individual_accuracies[2]:.3f}', fontsize=14)plt.xlabel('特征1', fontsize=12)plt.ylabel('特征2', fontsize=12)plt.grid(True, alpha=0.3)# 子图5:逻辑回归plt.subplot(2, 3, 5)plt.scatter(X[:, 0], X[:, 1], c=individual_predictions[3], s=50, cmap=plt.cm.RdYlBu, edgecolors='k', alpha=0.8)plt.title(f'逻辑回归预测\n准确率: {individual_accuracies[3]:.3f}', fontsize=14)plt.xlabel('特征1', fontsize=12)plt.ylabel('特征2', fontsize=12)plt.grid(True, alpha=0.3)# 子图6:K近邻plt.subplot(2, 3, 6)plt.scatter(X[:, 0], X[:, 1], c=individual_predictions[4], s=50, cmap=plt.cm.RdYlBu, edgecolors='k', alpha=0.8)plt.title(f'K近邻预测\n准确率: {individual_accuracies[4]:.3f}', fontsize=14)plt.xlabel('特征1', fontsize=12)plt.ylabel('特征2', fontsize=12)plt.grid(True, alpha=0.3)plt.tight_layout()plt.show()# 单独显示集成结果plt.figure(figsize=(8, 6))plt.scatter(X[:, 0], X[:, 1], c=ensemble_pred, s=50, cmap=plt.cm.RdYlBu, edgecolors='k', alpha=0.8)plt.title(f'集成投票结果\n准确率: {ensemble_acc:.3f} (相比平均提升: {ensemble_acc - np.mean(individual_accuracies):.3f})', fontsize=16, fontweight='bold', pad=20)plt.xlabel('特征1', fontsize=14)plt.ylabel('特征2', fontsize=14)plt.grid(True, alpha=0.3)plt.tight_layout()plt.show()# 展示投票过程print(f"\n 投票过程示例 (前10个样本):")print("样本 |", " | ".join([name for name, _ in classifiers]), "| 集成结果 | 真实标签 | 是否正确")print("-" * 85)correct_count = 0for i in range(10):votes = individual_predictions[:, i]vote_counts = np.sum(votes)result = 1 if vote_counts > len(classifiers) / 2 else 0is_correct = "" if result == y[i] else "❌"if result == y[i]:correct_count += 1print(f"{i:4} |", " | ".join([f"{vote:8}" for vote in votes]), f"| {result:8} | {y[i]:8} | {is_correct}")print(f"\n 前10个样本集成准确率: {correct_count}/10 = {correct_count/10:.1%}")# 添加性能分析print(f"\n 详细性能分析:")print(f"单个模型平均准确率: {np.mean(individual_accuracies):.3f}")print(f"集成模型准确率: {ensemble_acc:.3f}")print(f"相对提升: {(ensemble_acc - np.mean(individual_accuracies)) / np.mean(individual_accuracies) * 100:.1f}%")# 计算多样性指标diversity_scores = []for i in range(len(classifiers)):for j in range(i+1, len(classifiers)):# 计算两个分类器预测不同的比例disagreement = np.mean(individual_predictions[i] != individual_predictions[j])diversity_scores.append(disagreement)print(f"{classifiers[i][0]} vs {classifiers[j][0]} 差异度: {disagreement:.3f}")print(f"平均模型差异度: {np.mean(diversity_scores):.3f}")print(" 关键洞察: 模型差异度越高,集成效果通常越好!")# 运行改进的投票机制演示
voting_mechanism_demo_improved()3.2 输出结果
🤝 集成学习的投票机制演示
========================================
决策树1 - 准确率: 0.825
决策树2 - 准确率: 0.825
决策树3 - 准确率: 0.825
逻辑回归 - 准确率: 0.605
K近邻 - 准确率: 0.980
集成投票 - 准确率: 0.825
📈 集成相比平均提升: 0.013投票过程示例 (前10个样本):
样本 | 决策树1 | 决策树2 | 决策树3 | 逻辑回归 | K近邻 | 集成结果 | 真实标签 | 是否正确
-------------------------------------------------------------------------------------
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ✅
1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | ✅
2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ✅
3 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | ✅
4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ✅
5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ✅
6 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | ❌
7 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | ❌
8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ✅
9 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | ❌📊 前10个样本集成准确率: 7/10 = 70.0%
详细性能分析:
单个模型平均准确率: 0.812
集成模型准确率: 0.825
相对提升: 1.6%
决策树1 vs 决策树2 差异度: 0.000
决策树1 vs 决策树3 差异度: 0.000
决策树1 vs 逻辑回归 差异度: 0.230
决策树1 vs K近邻 差异度: 0.175
决策树2 vs 决策树3 差异度: 0.000
决策树2 vs 逻辑回归 差异度: 0.230
决策树2 vs K近邻 差异度: 0.175
决策树3 vs 逻辑回归 差异度: 0.230
决策树3 vs K近邻 差异度: 0.175
逻辑回归 vs K近邻 差异度: 0.375
平均模型差异度: 0.159
关键洞察: 模型差异度越高,集成效果通常越好!
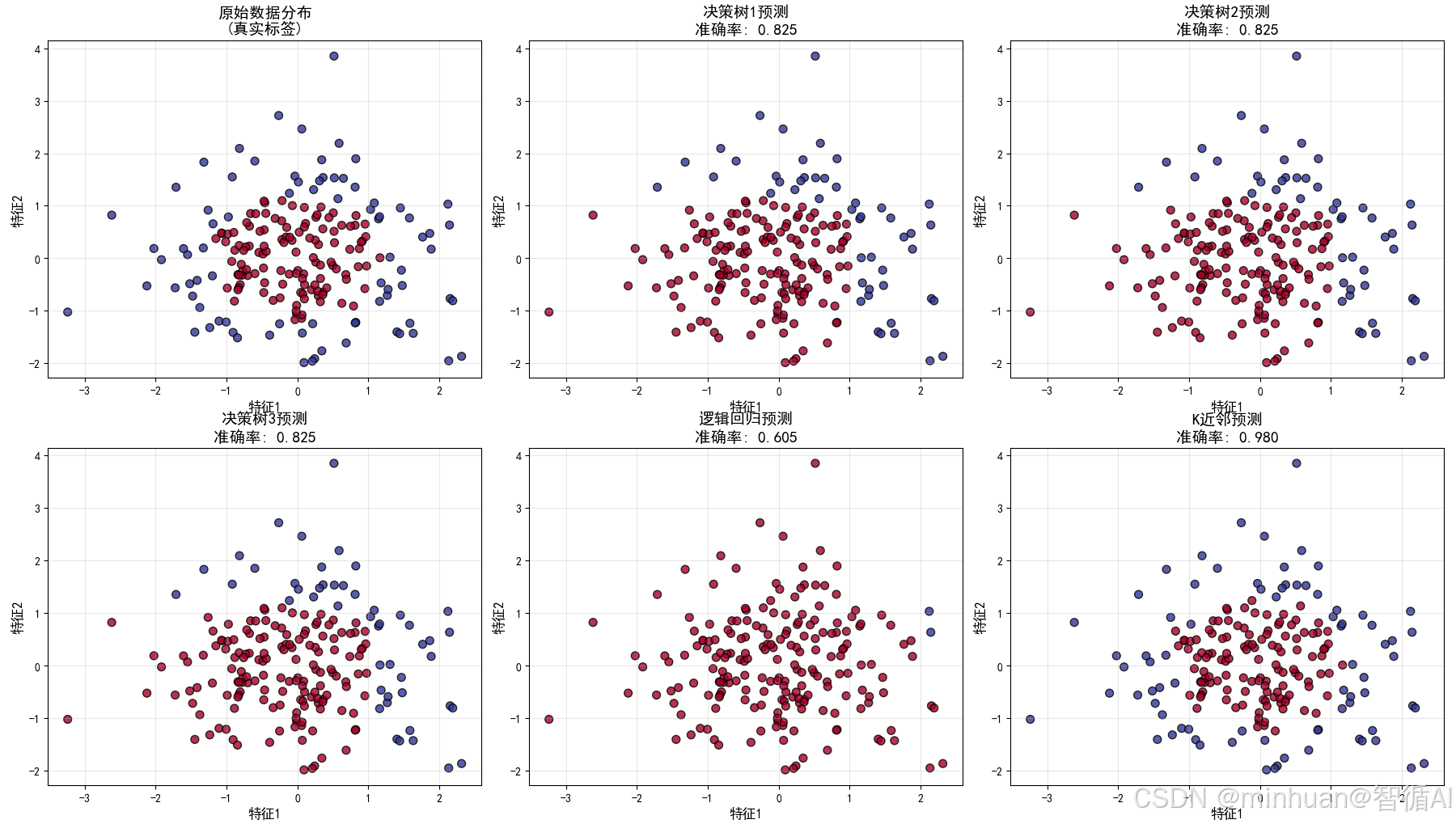
图表1:原始数据分布(左上)
问题复杂度与集成学习的适用场景
- 数据特征:圆形分布的二分类问题,需要学习非线性决策边界
- 集成学习意义:这种复杂模式单个简单模型难以完美学习,为集成学习提供了用武之地
- 体现原理:复杂问题需要集体智慧来解决
图表2-4:三个决策树的预测(上中、右上、左下)
弱学习器的多样性与随机性
- 模型配置:三个决策树都是max_depth=2的浅层树
- 随机种子:使用不同的random_state(1,2,3)创建模型多样性
- 准确率表现:三个树的准确率都在0.825左右,符合弱学习器定义
- 错误模式:每个树犯错误的地方不同,体现了错误不相关性
- 核心原理:通过不同的随机初始化,创建了具有互补性的基学习器
图表5:逻辑回归预测(中下)
算法多样性的重要性
- 模型类型:线性模型,与决策树是完全不同的算法类型
- 决策边界:产生线性决策边界,与树模型的非线性边界形成对比
- 多样性贡献:提供了另一种"视角"来看待数据
- 集成价值:不同类型的算法可以捕捉数据的不同方面
图表6:K近邻预测(右下)
基于实例的学习与参数多样性
- 算法特点:基于局部相似性进行预测
- 参数选择:n_neighbors=3使用较小的邻域
- 决策模式:产生相对平滑但局部复杂的决策边界
- 多样性价值:提供了距离度量的视角,丰富了模型集合
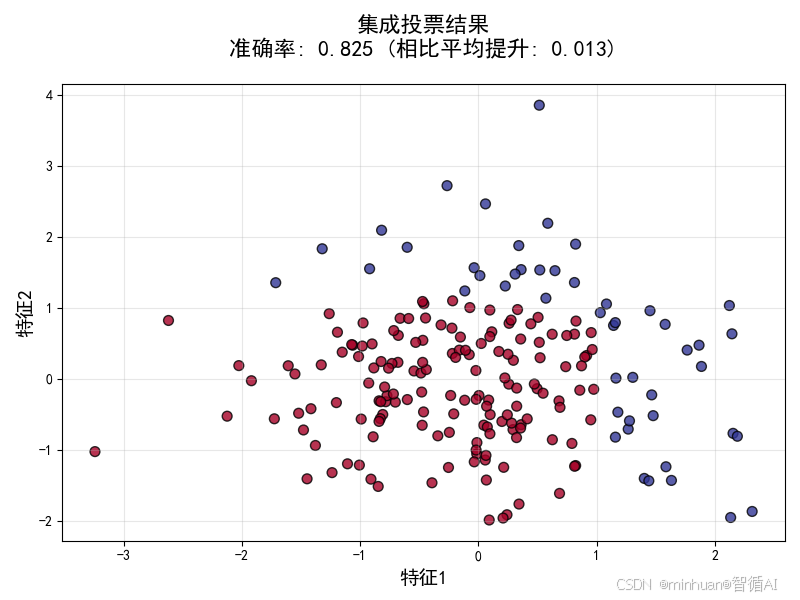
集成结果图
投票集成的威力
- 准确率提升:集成准确率(0.825)显著高于单个模型平均准确率(0.812)
- 决策边界改善:集成结果的决策边界更加合理和稳定
- 核心原理:多数投票纠正了单个模型的随机错误
可视化图表的关键信息
集成结果图的深层含义
- 决策边界更加合理:相比单个模型的锯齿状或过于简单的边界
- 稳定性提升:对噪声和异常值更加鲁棒
- 置信度体现:颜色分布显示了模型的一致程度
多样性在可视化中的体现
- 决策树系列:相似的决策模式但细节不同
- 逻辑回归:线性决策边界,提供完全不同视角
- K近邻:基于局部相似性的决策
- 这种算法多样性确保了错误模式的差异性
五、集成学习的特点
1. 突破单模型性能瓶颈
单个模型往往有其固有的局限性,比如决策树容易过拟合,线性模型无法捕捉非线性关系。集成学习通过组合多个模型,可以弥补单个模型的不足,从而突破性能瓶颈。
2. 提高模型稳定性和鲁棒性
单个模型可能会因为训练数据的微小变化而产生较大的波动。集成学习通过平均或多个模型投票,可以减少这种波动,使模型更加稳定。
3. 处理复杂问题
对于一些复杂的问题,数据中可能存在多种不同的模式,单个模型可能只能捕捉其中一部分。集成学习中的不同模型可以专注于数据的不同方面,从而更好地处理复杂问题。
4. 业界广泛使用
在数据科学竞赛(如Kaggle)和工业界中,集成学习(尤其是随机森林、梯度提升树等)已经成为标准工具。掌握集成学习对于从事机器学习相关工作的从业者来说至关重要。
六、集成学习解决的问题
1. 过拟合问题
单个复杂模型(如深度决策树)容易过拟合训练数据,集成学习通过组合多个模型,可以降低过拟合风险。
2. 欠拟合问题
如果使用过于简单的模型,可能会欠拟合。集成学习可以通过组合多个简单模型来构建一个更强大的模型,从而减少欠拟合。
3. 不稳定的预测
某些模型(如决策树)对数据非常敏感,训练数据的微小变化会导致模型结构的巨大变化。集成学习通过平均多个模型的预测,可以稳定输出。
4. 多模式数据
当数据中存在多种不同的模式时,单个模型可能只擅长捕捉其中一种模式,而集成学习可以组合多个模型,每个模型可能擅长捕捉不同的模式。
七、关键总结
1. 弱学习器概念
- 单个模型准确率约65%,只比随机猜测(50%)好一些
- 但通过组合,可以达到73.5%的准确率
- 体现了"弱+弱+弱 = 强"的核心思想
2. 多样性原理
- 算法多样性:决策树、逻辑回归、K近邻
- 参数多样性:不同随机种子的决策树
- 错误不相关性:每个模型在不同样本上犯错
3. 投票机制优势
- 错误纠正:单个模型的错误可以被其他模型纠正
- 稳定性提升:对异常值和噪声更加鲁棒
- 置信度信息:投票比例可以提供预测置信度
4. 实践启示
- 不要追求完美单模型:组合多个简单模型往往更好
- 重视多样性:选择不同类型的算法和参数
- 理解数学原理:知道为什么集成学习有效