【SayCan】LLM+价值函数:以言为引,量力而行
本系列目前的考量是以论文为基础,逐步解读机器人感知与决策相关的算法(决策为主,感知为辅),并且聚焦核心技术,论文中细节性、基础性的工作仅作必要补充。博客作为我的学习笔记,其写作的过程即为博主知识体系构建的过程,希望能凭此特点给读者提供循序渐进的阅读体验,但也难免存在局限性,如有疏漏欢迎指正。
论文标题:Do As I Can, Not As I Say:Grounding Language in Robotic Affordances
论文发表时间:2022年8月
研究背景
大语言模型(Large Language Model,LLM)凭借其超大规模的参数量,从网上庞大的语料库中汲取了大量的知识,已经能够完成复杂的语言处理与生成任务。这样的能力对于机器人接收人类下达的自然语言作为指令完成任务至关重要,我们自然期望将LLM直接应用于机器人执行自然语言指令任务。
但是LLM仅仅基于上下文完成任务,无法直接获得来自物理世界的信息,包括机器人处于什么样的环境与状态,某个行动会对现实产生什么样的影响等等。LLM具有分析并响应自然语言指令的能力,即“Say”,但机器人能不能理解其响应,进而又能不能在现实世界中执行,即“Can”,LLM自身则无法保证。
早期的LLM针对“饮料洒了”,GPT3回应“试试使用真空吸尘器”,但场景中可能没有真空吸尘器或机器人无法使用;LaMDA和FLAN的回复“要我找个真空吸尘器吗?”“对不起,我不是故意的”仅仅从对话意义上来看是合理的。
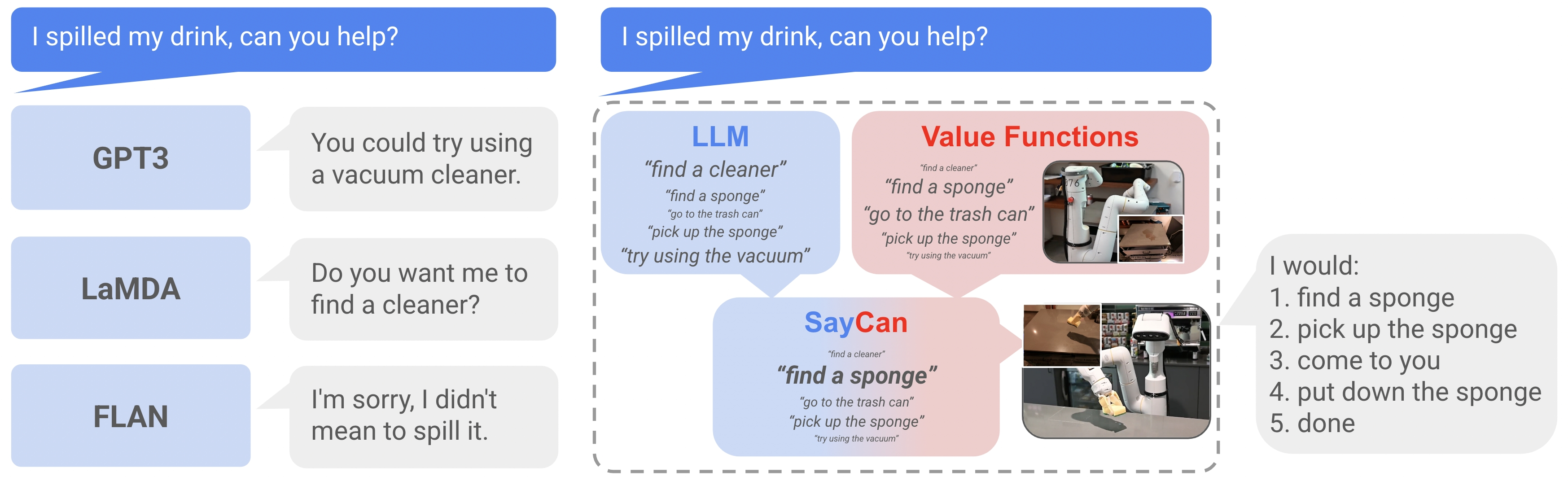
为此,SayCan先给智能体训练一系列配备了语言描述的技能单元,规范LLM的“Say”使之输出机器人可以理解的低级技能序列,再学习与技能对应策略的价值函数作为衡量“Can”的指标。通过将LLM的“Say”和现实世界的“Can”结合起来作为机器人高层决策的依据,SayCan让机器人完成了简单的自然语言指令任务,成为了LLM+Robotics的开山之作。
SayCan:Do As I Can, Not As I Say
问题陈述
系统接收用户提供的自然语言指令iii,描述机器人应该执行的任务,可以是长的、抽象的或模糊的。
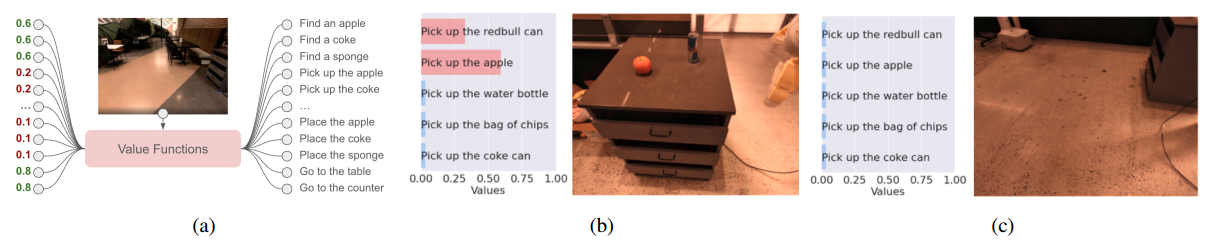
智能体被赋予一个技能库Π\PiΠ,其中每个技能π∈Π\pi\in\Piπ∈Π执行一个简短的任务,并附带一个简短的语言描述lπ\mathscr l_\pilπ和示能函数(affordance function)p(cπ∣s,lπ)p(c_\pi|s,\mathscr l_\pi)p(cπ∣s,lπ),表示在状态sss下语言描述为lπ\mathscr l_\pilπ的技能可以被完成(complete,cπc_\picπ)的概率。本质上示能函数是p(cπ∣s,π)p(c_\pi|s,\pi)p(cπ∣s,π),使用lπ\mathscr l_\pilπ主要是为了在形式上与LLM的输入输出保持统一。在RL中,示能函数可以是技能的价值函数,成功完成的奖励为1,否则为0。
下图展示了不同状态下的示能空间{p(cπ∣s,lπ)}π∈Π\{p(c_\pi|s,\mathscr l_\pi)\}_{\pi\in\Pi}{p(cπ∣s,lπ)}π∈Π。当场景中出现苹果和红牛罐头时,拾取苹果和红牛罐头具有较高的价值,且距离近者价值更高。
LLM给出技能的语言描述lπ\mathscr l_\pilπ是用户指令iii的有效下一步的概率p(lπ∣i)p(\mathscr l_\pi|i)p(lπ∣i),那么对于我们关注的某项技能可以被成功执行,并朝着完成指令的方向取得进展的概率p(ci∣i,s,lπ)p(c_i|i,s,\mathscr l_\pi)p(ci∣i,s,lπ)有
p(ci∣i,s,lπ)∝p(cπ∣s,lπ)p(lπ∣i)p(c_i|i,s,\mathscr l_\pi)\propto p(c_\pi|s,\mathscr l_\pi)p(\mathscr l_\pi|i) p(ci∣i,s,lπ)∝p(cπ∣s,lπ)p(lπ∣i)
其中p(lπ∣i)p(\mathscr l_\pi|i)p(lπ∣i)被称为任务基础(task-grounding),p(cπ∣s,lπ)p(c_\pi|s,\mathscr l_\pi)p(cπ∣s,lπ)被称为世界基础(world-grounding)。
连接LLM到机器人
一个原始的LLM能够合理地响应我们给出的指令,但它不知道如何以机器人可以理解的方式,即低级技能序列作为响应。一种方法是依赖提示词工程,但这仍然无法对其输出进行严格的约束。为此,SayCan没有让LLM直接生成技能文本,而是为给定的文本计算可能性。
首先,设计提示词,通过少样本学习来引导LLM,让LLM学会以特定的格式和结构来回答“How would you …”,这是LLM后续给出合理概率打分的重要基础。
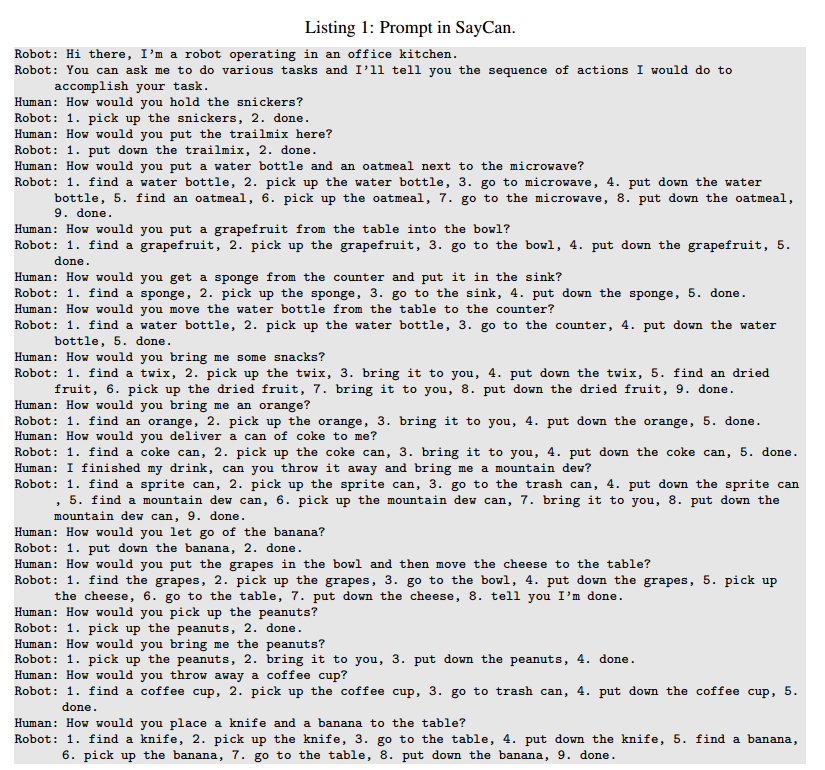
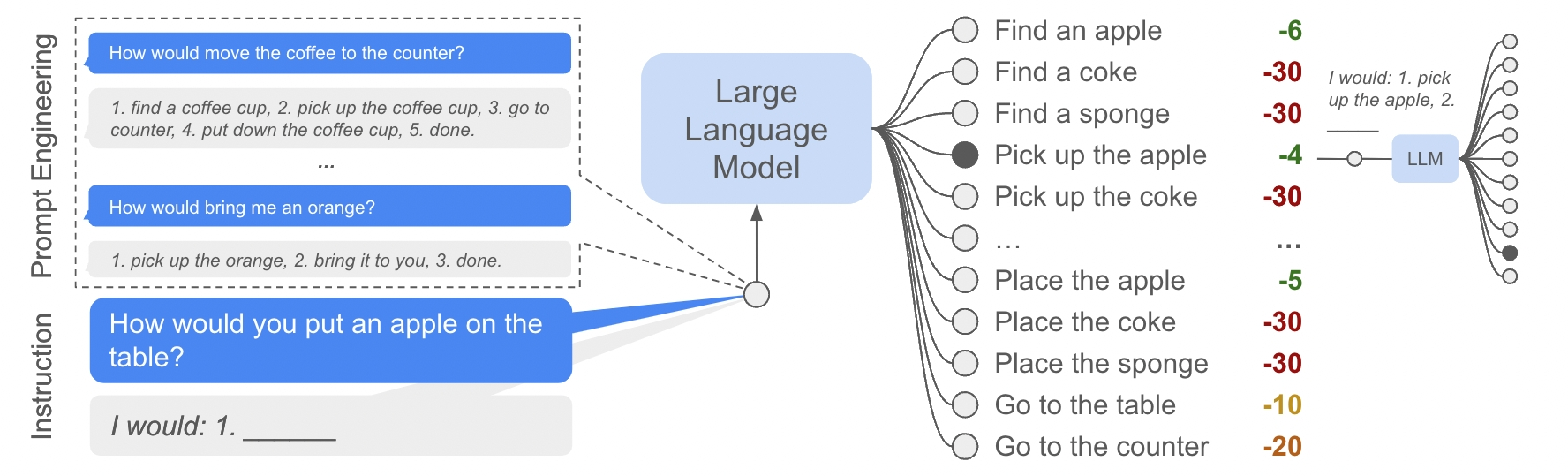
接下来,以用户指令iii作为上文,给定一系列候选技能的语言描述lΠ\mathscr l_\PilΠ,LLM将计算每个候选技能描述lπ∈lΠ\mathscr l_\pi\in\mathscr l_\Pilπ∈lΠ被预测为指令iii的下文的概率p(lπ∣i)p(\mathscr l_\pi|i)p(lπ∣i)。如果该概率很高,则意味着这个技能与用户指令的关联性很强,因而可以自然而然地成为了衡量技能对完成指令的推动作用的指标。
遍历完第一步的候选动作后,LLM将选取概率最高的候选技能lπ=argmaxlπ∈lΠp(lπ∣i)\mathscr l_\pi=\mathrm{argmax}_{\mathscr l_\pi\in\mathscr l_\Pi}p(\mathscr l_\pi|i)lπ=argmaxlπ∈lΠp(lπ∣i)执行,并将其附加到指令iii中用于对下一步候选动作进行打分,直至LLM认为指令已完成。
直接使用概率进行计算会导致数值下溢,因此LLM实际上给出的是对数概率。
策略训练
本小节简要介绍策略训练的具体实现,非核心内容
SayCan同时使用了基于BC-Z方法的行为克隆(Behavior Cloning,BC)和基于MT-Opt的RL来获取技能的策略。实验人员发现,BC策略在当前的数据集和实验条件下的成功率更高,但是BC策略在短期内的高成功率会使其训练得到的价值函数对失败边界的认识不足,相比之下RL策略训练出的价值函数更为可靠。所以最终,BC策略被选为执行器,而RL策略的价值函数则用于近似估计BC策略的示能函数。
奖励采用稀疏奖励函数,即技能执行成功为1,失败为0。关于成功的判定,实验人员采取了3人投票多数表决的方法,因为机器人判定难度太大。虽然人工方法效率较低,但是对于证明算法的可行性来说已经足够。
博主暂未学习BC这类模仿学习算法,将考虑在后续其他系列讲述
SayCan
现在我们将LLM的Say与示能函数的Can结合。在每一步技能决策,LLM根据指令上文给出技能的任务基础p(lπ∣i)p(\mathscr l_\pi|i)p(lπ∣i),示能函数根据机器人物理状态给出技能的世界基础p(cπ∣s,lπ)p(c_\pi|s,\mathscr l_\pi)p(cπ∣s,lπ)。最终二者相乘得到的概率(在工程实践中采取对数概率相加)是SayCan选择技能的依据
π=argmaxπ∈Πp(cπ∣s,lπ)p(lπ∣i)\pi=\mathrm{argmax}_{\pi\in\Pi}p(c_\pi|s,\mathscr l_\pi)p(\mathscr l_\pi|i) π=argmaxπ∈Πp(cπ∣s,lπ)p(lπ∣i)
为了在合适的尺度下直观对比,论文图中LLM列出对数概率,示能函数列出原始概率
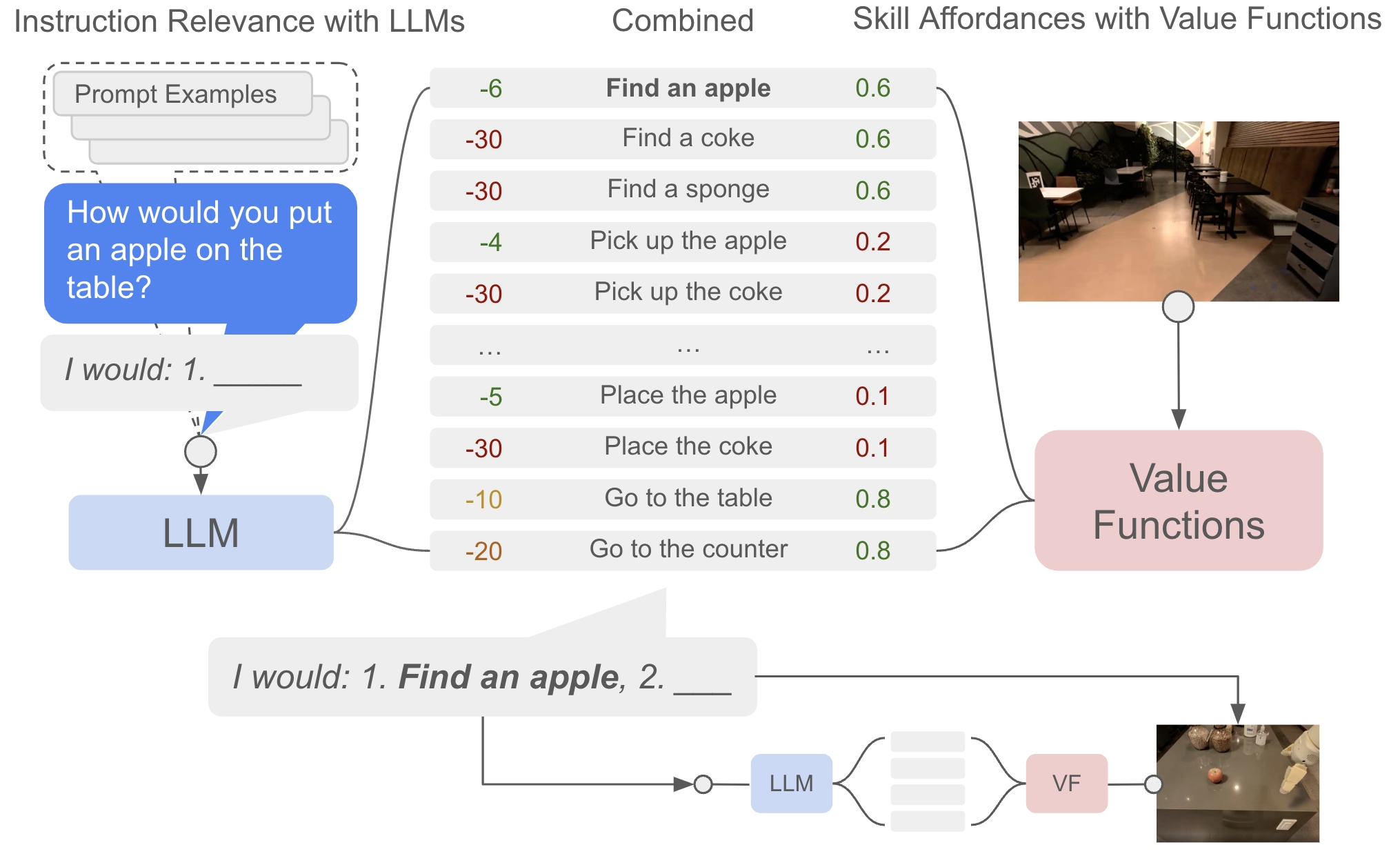
技能选择完毕后,智能体执行对应的策略,LLM将对应的技能描述纳入指令,随后进行下一轮决策,直至SayCan选择了终止技能。整个SayCan算法的伪代码如下

成果与展望
论文针对实验采用了两个指标,均采用3人投票多数表决判定:
- 规划成功率:LLM针对自然语言指令选择的技能是否正确,无论其是否被成功执行;
- 执行成功率:整个SayCan系统是否真正成功地执行了所需指令。
最终,SayCan在模拟厨房环境下针对简单的自然语言指令实现了84%的规划成功率和74%的执行成功率(101次任务)。
在寻找清理工具的指令下,SayCan对各个技能的打分

实验的其他对比:
- 从实验室模拟厨房推广到其他真实厨房:规划成功率降低了3%,执行成功率降低了14%,问题主要在BC策略的迁移;
- 无示能函数:规划成功率降低了14%,毕竟物理环境和技能集合较为简单;
- 无LLM:仅在自然语言指令就是单个技能的情况有60%的执行成功率,其余情况完全不行。
- 不同LLM:更大的模型表现得更好,尤其是在更具挑战性的指令上体现的更明显。
SayCan的可行性得到了初步的证明,但也有很多可想而知的局限性:
- LLM本身的局限性与偏差将会继承到系统中;
- 系统的主要瓶颈在于单元技能的范围和能力;
- 系统不易对某一步偶然执行失败的情况作出反应。
论文指出下一步的工作在于:
- 将机器人在现实世界的经验用于改进LLM本身;
- 考虑结合价值函数以外的方式来计算示能函数;
- 研究自然语言是否适合作为机器人编程的范式;
- 开展更多将自然语言与机器人技术结合(规划、策略学习、人机交互等)的研究。