论文学习_PalmTree: Learning an Assembly Language Model for Instruction Embedding
标题: PalmTree: Learning an Assembly Language Model for Instruction Embedding (Xuezixiang Li,2021)
作者: Xuezixiang Li, Yu Qu, Heng Yin
期刊: Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security
摘要
深度学习在众多二进制分析任务中已展现出其优势,例如函数边界检测、二进制代码搜索、函数原型推断和值集分析等。在将深度学习应用于二进制分析任务时,我们需要确定应向神经网络模型输入何种数据。更具体地说,需要解决如何将一条指令表示为固定长度向量的问题。自动学习指令表示的想法颇具吸引力,但现有方案未能捕捉到反汇编代码的独有特征。这些方案忽略了指令内部复杂的结构,并且主要依赖控制流信息,而控制流中的上下文信息存在噪声且易受编译器优化影响。
本文提出了一种名为PalmTree的预训练汇编语言模型,旨在通过在大规模未标记二进制语料库上进行自监督训练,来生成通用指令嵌入。PalmTree利用三个预训练任务来捕捉汇编语言的各种特性。这些训练任务克服了现有方案存在的问题,从而有助于生成高质量的指令表示。我们进行了内部指标和外部任务两方面的评估,并将PalmTree与其他指令嵌入方案进行了比较。结果表明,PalmTree在内部指标上表现最佳,并且在所有下游任务中均优于其他指令嵌入方案。
引言
近年来,我们见证了利用深度学习技术解决各类二进制分析任务的研究热潮,应用领域涵盖函数边界识别、二进制代码相似性检测、函数原型推断、值集分析、恶意软件分类等。与传统程序分析方法及机器学习方法相比,深度学习在这些任务中展现出显著更优的性能表现。
在将深度学习应用于这些二进制分析任务时,首先需要确定的设计选择是:应向神经网络模型输入何种类型的数据?总体而言,有三种选择:可以直接将原始字节码输入神经网络;或者输入人工设计的特征;亦或是利用表示学习模型自动学习生成每条指令的向量表示,再将生成的表示嵌入向量输入下游模型。
与前两种方案相比,自动学习指令级别的表示更具吸引力,原因有二:其一,它避免了需要专家知识且可能繁琐易错的人工设计工作;其二,它能学习到更高级别的语义特征而非纯粹的语法特征,从而为下游任务提供更好的支持。为学习指令级别的表示,研究人员借鉴了自然语言处理领域的算法,通过将二进制汇编代码视为自然语言文本来进行处理。
尽管指令表示学习领域近期取得了令人鼓舞的进展,但仍存在一些未解决的问题,这些问题可能严重影响指令嵌入的质量并限制下游模型的性能:首先,现有方法忽略了指令复杂的内部格式。例如,在x86汇编代码中,操作数的数量可以从零到三个不等;一个操作数可以是CPU寄存器、内存地址表达式、立即数或字符串符号;某些指令甚至包含隐式操作数。现有方法要么将整条指令视为一个单词而忽略其结构信息,要么仅考虑简单的指令格式。其次,现有方法利用控制流图来捕捉指令间的上下文信息。然而,基于控制流的上下文信息可能因编译器优化而产生噪声,且无法反映指令间实际的依赖关系。
此外,近年来,预训练深度学习模型在计算机视觉和自然语言处理等领域日益受到关注。预训练的直观理念在于,随着深度学习的发展,模型参数数量快速增长,需要更大规模的数据集来充分训练参数并防止过拟合。因此,利用大规模无标注语料库和自监督训练任务的预训练模型在某些领域已非常流行。自然语言处理中代表性的深度预训练语言模型包括BERT、GPT、RoBERTa、ALBERT等。考虑到包括汇编语言在内的编程语言同样具有"自然性",为不同二进制分析任务预训练一个汇编语言模型具有巨大潜力。
为解决指令表示学习中存在的现有问题并捕捉指令的底层特征,本文提出了一种名为PalmTree的预训练汇编语言模型,用于通用指令表示学习。PalmTree基于BERT模型架构,但通过利用汇编语言固有特性而新设计的训练任务进行预训练。我们并非首个在二进制分析中应用BERT模型的研究。例如,有研究提出以控制流图作为输入,并利用BERT对标记嵌入和基本块嵌入进行预训练,旨在实现二进制代码相似性检测。另一项研究则采用BERT的掩码语言模型预训练任务,从函数的微轨迹中学习程序执行语义,以进行二进制代码相似性检测。
与现有方法相比,我们的目标是开发一个预训练的汇编语言模型,用于通用指令表示学习。PalmTree并非仅仅在控制流上应用掩码语言模型,而是通过三项训练任务来挖掘汇编语言的特性。这三项训练任务在不同粒度层级上协同工作,有效训练PalmTree模型以捕捉指令的内部格式、上下文控制流依赖关系以及数据流依赖关系。
研究背景
复杂多样的指令格式
指令(特别是复杂指令集架构中的指令)通常具有多种格式,并包含额外的复杂性。清单1展示了x86架构中的几条示例指令。

在x86架构中,一条指令可以包含0到3个操作数。每个操作数可以是CPU寄存器、内存地址表达式、立即数或字符串符号。内存操作数通过"基址+索引×比例因子+位移量"的表达式计算得出。其中基址和索引为CPU寄存器,比例因子为小的常数,位移量可以是常数或字符串符号。所有这些字段都是可选的,因此内存表达式变化多端。
部分指令具有隐式操作数。算术指令会隐式改变EFLAGS寄存器,而条件跳转指令则将EFLAGS作为隐式输入。优质的指令级表示必须理解每条指令的这些内部细节。
然而,现有的基于学习的编码方案未能妥善处理这些复杂性。先前研究采用的Word2vec方法将整条指令视为单个单词,完全忽略了这些内部细节。Asm2Vec方案对指令的解析程度非常有限,它将指令视为包含一个操作码和最多两个操作数(即最多三个标记)。带有表达式的内存操作数被当作单个标记处理,因此无法理解内存地址的计算方式。该方法也未考虑其他复杂因素,如指令前缀、第三个操作数、隐式操作数和EFLAGS等。
存在噪声的指令上下文
上下文被定义为控制流图上目标指令前后数量不多的若干指令。这些处于上下文中的指令通常与目标指令存在特定关联,因此有助于推断目标指令的语义。

尽管这一假设通常成立,但编译器优化往往会打破该假设以实现指令级并行性的最大化。具体而言,编译器优化旨在通过将寄存器或内存位置的加载操作与其最后一次存储操作间隔更远,并在其间插入不相关指令,来避免指令执行流水线的停顿。清单2提供了一个示例:第10行的test指令与其周围的call和mov指令并无关联。该test指令(其结果将存入EFLAGS)被编译器移至mov指令之前,使其与第14行使用(加载)该EFLAGS的je指令距离更远。由此可见,由于编译器优化的影响,控制流上的上下文关系可能包含噪声。
需注意的是,指令之间还通过数据流相互依赖(如清单2中第8行与第12行)。现有方法仅基于控制流工作,忽略了这一重要信息。另一方面,值得关注的是,大多数现有预训练模型无法处理超过512个标记的序列(能处理更长序列的预训练模型需要更多GPU内存)。因此,即使我们直接使用掩码语言模型在指令序列上训练这些预训练模型,它们也难以捕捉可能发生在不同基本块之间的长距离数据依赖关系。由此可见,设计能够捕获数据流依赖关系的新预训练任务十分必要。
研究内容
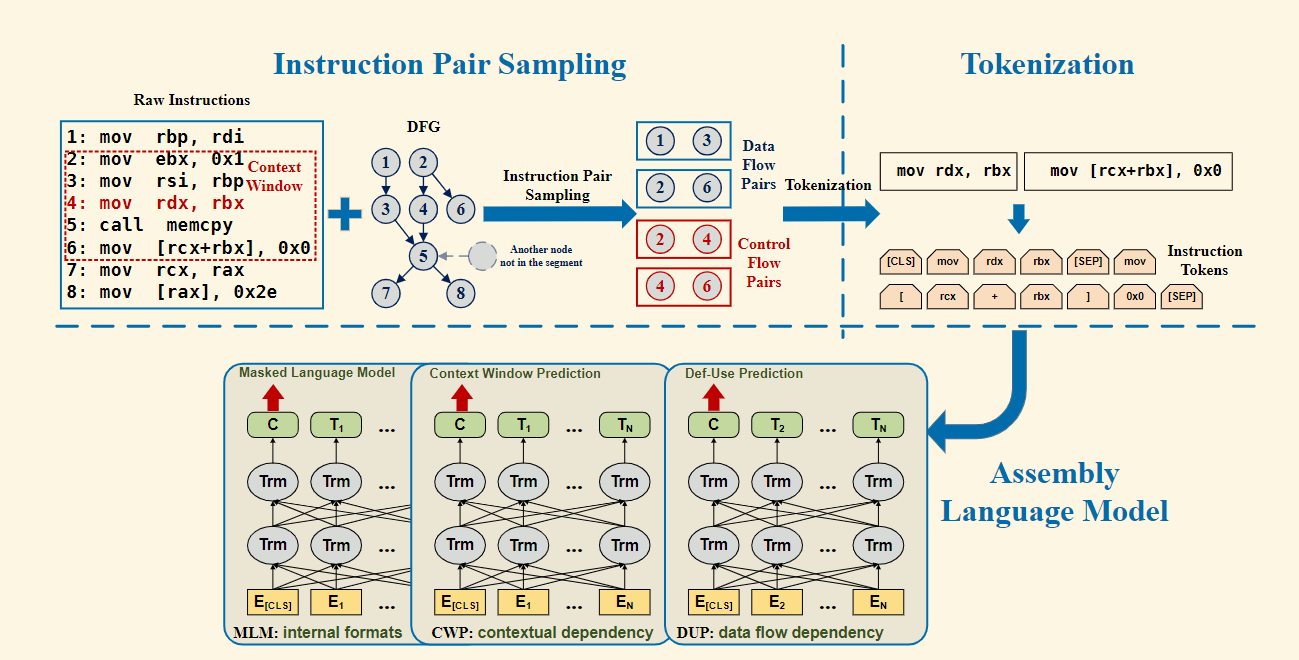
我们将每条指令视作一个句子并分解为基本标记(如操作码、寄存器等),通过三项创新训练任务预训练基于BERT架构的汇编语言模型PalmTree:首先采用掩码语言模型使模型理解指令内部结构;其次设计上下文窗口预测任务,通过判断控制流滑动窗口内指令的共现关系捕捉优化重排序后的语义关联;最后引入定义-使用预测任务,利用汇编指令明确的数据依赖关系提升语义表征精度。该框架通过指令对采样、标记化处理和多任务联合训练,最终生成能同时克服指令格式复杂性与控制流噪声的高质量指令嵌入表示。