LLMs:nanochat(仿照GPT-3 Small)的简介、安装和使用方法、案例应用之详细攻略
LLMs:nanochat(仿照GPT-3 Small)的简介、安装和使用方法、案例应用之详细攻略
目录
nanochat的简介
1、特点
2、主要功能与模块组成
3、训练成本与性能梯度
nanochat的安装与使用方法
1、安装
2、使用方法
2.1、快速体验(speedrun,作者推荐)
2.2、完整训练 / 更大模型(run1000、run1000.sh)
使用细节与常见命令(摘自仓库)
2.3、在线演示
nanochat的案例应用
nanochat的简介
2025年10月13日,nanochat 是 Andrej Karpathy 发布的一个 “full-stack”(端到端)最小化实现,目的是把一个类似 ChatGPT 的大语言模型(LLM)流水线放在一个清洁、最小、可 hack 的代码库里:从分词/tokenization、预训练、微调、中期训练(mid-training)、评估、推理到一个简单的 Web UI 全都包含在内,可以在单台 8×H100 节点上运行完成整条流水线。
作者把它称为 “The best ChatGPT that $100 can buy.”($100 可训练出一个可对话的微型 ChatGPT),并配有供演示的在线实例(nanochat.d32)。这是一个教学/实践导向的工程作品,强调可复现、可改造、低依赖、方便从头训练并部署一个属于你自己的对话模型。
>> 教育与探索为主:作者反复强调这是教学与实验工具,不代表可与最新商业 SOTA 模型抗衡;输出会出现大量错误/幻觉,这是预期之内。
>> 资源与成本意识:尽管有“$100 speedrun”示例,但更大/更强模型需要更多 token、更多时间与更高成本(README 举例了 $300、$1000 档位对应的时间/深度)。在动手前请确认云算力与预算。
>> 可扩展性:README 提供了如何通过修改参数、增加数据 shards、调整 batch size 等来扩大模型或提高质量的说明(适合进阶用户)。
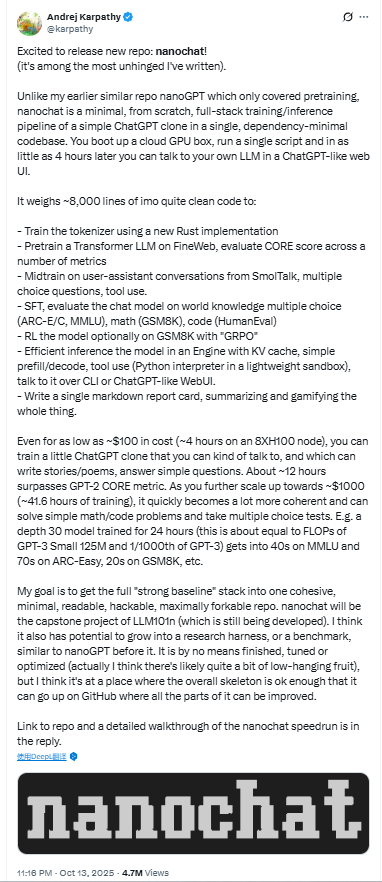
nanochat 是一个用 ~8000 行代码构建的最小可行 ChatGPT 克隆框架,集成了从分词到强化学习、推理和 WebUI 的全栈流水线。在仅约 $100 成本下,你就能在 4 小时内训练出一个可聊天的小型 LLM。随着训练规模扩大,它能逐步接近 GPT-2/GPT-3 小模型级别性能。该项目旨在成为教育与研究用途的“强基线”实现 —— 简洁、可读、可扩展、可复现。
作者认为 nanochat 未来可以演化为一个 研究基准(research harness) 或 评测平台(benchmark),类似 nanoGPT 之前的作用。
GitHub地址:https://github.com/karpathy/nanochat
在 Karpathy 的 X 帖子中,他以较为轻松/夸张的口吻介绍了 nanochat(例如“Excited to release new repo: nanochat! (it's among the most unhinged I've written).”),并强调这是一个可在低成本上体验端到端 LLM 流程的项目(即 “the best ChatGPT that $100 can buy” 的定位)。
1、特点
>> 端到端、单仓库实现:一个 repo 覆盖 tokenization → pretrain → midtrain → finetune → eval → inference → web serving。适合学习和完整复现一个 LLM 流程。
>> 极简、可 hack:作者刻意把代码写得干净、可读、约 8k 行左右(手写实现),便于教学与改造。([AI Engineer Guide][2])
>> 支持“$100 speedrun”模式:提供 `speedrun.sh` 脚本,可在一台 8×H100 节点(示例给出 $24/hr 的租用价格)上在 ~4 小时内跑出一个可对话的微型模型(所谓“$100 案例”),便于快速体验端到端训练与部署。
>> 示例可访问的在线实例:作者托管了 `nanochat d32`(32 层 Transformer、约 1.9B 参数、以 `run1000.sh` 训练得到,使用 ~38B tokens,训练成本作者示例约 $800/33 小时),你可以直接去看 demo 聊天效果以理解模型能力与局限。
>> 教育定位:repo 将成为课程 LLM101n 的 capstone 项目,强调可读性与教学用途,而非追求 SOTA。作者也明确提醒:这种规模远不及 GPT-5,容易出错/幻觉,但非常适合“属于你自己的可调试模型”实践。
2、主要功能与模块组成
nanochat 的 8k 行代码实现了一个完整的 LLM 训练与推理堆栈,具体包括以下功能模块:
| 模块 | 功能描述 |
| 1、分词训练(Tokenizer) | 使用全新的 Rust 实现 训练分词器,以提高速度与效率。 |
| 2、预训练(Pretraining) | 在 FineWeb 数据集 上训练 Transformer LLM,并计算 “CORE” 分数(一个综合性能指标)以评估多项任务表现。 |
| 3、中期训练(Midtraining) | 在多类型任务上继续训练,包括: |
| 4、指令微调(SFT) | 进一步针对下列任务评估并改进模型: |
| 5、强化学习(RL) | 可选地使用 GRPO(一种轻量级 RL 技术)在 GSM8K 上强化模型。 |
| 6、推理与引擎(Inference Engine) | - 高效推理,包含 KV 缓存、prefill/decode 循环; |
| 7、结果报告生成 | 自动生成一份 Markdown 格式的“成绩单”(report card),对整个训练过程进行总结和游戏化展示。 |
3、训练成本与性能梯度
nanochat 设计为可根据预算灵活缩放。作者指出该 d30 模型的计算量约等于 GPT-3 Small(125M 参数),约为 GPT-3 总算力的 1/1000。
| 预算档位 | 时间(8×H100) | 训练规模 / 模型深度 | 结果表现(典型指标) | 能力示例 |
| 约 $100 | ~4 小时 | 小模型 | 可进行基础对话,写诗、讲故事、回答简单问题 | “$100 ChatGPT 克隆” |
| 约 $300 | ~12 小时 | 更深模型(约 d26) | 超越 GPT-2 的 CORE 指标 | 更连贯、更智能 |
| 约 $800–$1000 | ~24–41 小时 | 深度约 d30 模型(≈ GPT-3 Small 125M 的 FLOPs) | MMLU 达 40+;ARC-Easy 达 70+;GSM8K 达 20+ | 能解基础数学、代码题、多选题 |
nanochat的安装与使用方法
1、安装
在实际机器(建议 8×H100)执行并注意安全与资源配置。
GitHub地址:https://github.com/karpathy/nanochat
2、使用方法
2.1、快速体验(speedrun,作者推荐)
启动一台 8×H100 GPU 的机器(作者示例提到 Lambda 等云供应商),保证可以运行多卡训练。在该机器上克隆仓库并进入(假定你已 git clone 仓库并进入目录)。(仓库中包含 `speedrun.sh` 等脚本。)
运行快速脚本(会执行从数据准备到训练到快速推理的一套流水线):
bash speedrun.sh
作者提示:在屏幕会话中运行比较方便,示例:screen -L -Logfile speedrun.log -S speedrun bash speedrun.sh
tail -f speedrun.log
该脚本在 8×H100、以作者估算的租价情况下约需 ≈4 小时 完成(即所谓“$100”档体验)。完成后,激活虚拟环境并启动 Web 服务(README 示范):source .venv/bin/activate
python -m scripts.chat_web
然后使用浏览器访问脚本输出的地址(在云机上通常是 `http://<public-ip>:8000/`)。2.2、完整训练 / 更大模型(run1000、run1000.sh)
README 提到可通过 `run1000.sh` 等脚本训练更长时间/更多数据的模型(示例:d32 1.9B 参数的模型就是通过 `run1000.sh` 在 38B tokens 上训练得到,成本作者示例约 $800)。如果要训练 GPT-2 级别或更大模型,README 给出如何修改 `speedrun.sh` 中的参数(如 depth、数据 shards、batch size 等)并使用 `torchrun` 的指令示例。
| 步骤 | 命令 | 目的 | 关联文件 | 注意 | 预期时间 / 估算成本 |
| 0. 启动云机器 | ——(在云控制台选 8×H100) | 准备硬件:一台含 8 个 H100 GPU 的节点(作者示例)。 | — | README 推荐 8×H100;作者提到使用 Lambda 等供应商。GitHub | — |
| 1. 克隆仓库 | git clone https://github.com/karpathy/nanochat.git && cd nanochat | 把项目拉下来并进入目录。 | — | 确保网络通畅,git 有权限。 | 几分钟 |
| 2. 查看 README | sed -n '1,200p' README.md | 快速阅读仓库说明与 quick start。 | README.md | README 包含 speedrun、run1000 等说明与示例。GitHub | — |
| 3. 创建/激活 Python venv(示例) | python -m venv .venv && source .venv/bin/activate | 建议在虚拟环境中运行仓库脚本(README 中 .venv 被引用在 Web serve 示例)。 | — | 若使用 system python,注意依赖冲突。 | 1–2 分钟 |
| 4. (可选)查看 speedrun 脚本 | sed -n '1,240p' speedrun.sh | 预览 speedrun 做了哪些事情(pretrain、midtrain、finetune、eval、serve)。 | speedrun.sh | 若需修改参数(如 depth、batch size),可在该脚本中调整。 | — |
| 5. 运行 speedrun(一键体验) | bash speedrun.sh | 执行 README 推荐的“$100 tier”端到端流水线(从数据到训练到 inference + report)。 | speedrun.sh | 默认脚本设计在 8×H100 上约 4 小时完成(README 估算基于 $24/hr)。若想后台运行,见下一行。 | 约 4 小时(README 估) / 约 $100(README 示例) |
| 6. 在 screen 中运行(推荐) | screen -L -Logfile speedrun.log -S speedrun bash speedrun.sh # 然后可 detach:Ctrl-a d tail -f speedrun.log | 在可断开会话中启动并记录日志,便于长时间运行监控。 | — | README 明确建议使用 screen 并示范 tail speedrun.log 查看进度。 | 同上 |
| 7. 完成后查看运行报告 | cat report.md | speedrun 结束会生成 report.md,包含 metrics(CORE、ARC、GSM8K、HumanEval、MMLU、ChatCORE 等)与总体时间。 | report.md | README 给出示例表格与 Total wall clock time(示例:3h51m)。 | — |
| 8. 启动 Web UI(本地/云) | source .venv/bin/activate python -m scripts.chat_web | 启动 ChatGPT 风格的简单 Web 服务,供浏览器交互(将展示模型对话界面)。 | scripts/chat_web.py | 在云节点上访问 http://<public-ip>:8000/(README 示例)。确保安全组/防火墙允许该端口访问。 | 几秒到几分钟 |
| 9. 访问 demo(作者托管示例) | 在浏览器打开 https://nanochat.karpathy.ai | 查看作者托管的 d32 模型示例(32 层、1.9B 参数,训练于 ~38B tokens)。 | README 引用 | 只是演示:实际复现需要运行 speedrun 或 run1000。 | — |
| 10. 放大训练示例(d26 / run1000) | 修改 speedrun.sh 或直接使用: python -m nanochat.dataset -n 450 & torchrun --standalone --nproc_per_node=8 -m scripts.base_train -- --depth=26 --device_batch_size=16 | 说明如何把 speedrun 升级到 d26(GPT-2 品质附近)或更大训练:改变 depth,增加数据 shards,调整 batch size 以避免 OOM。 | speedrun.sh, run1000.sh, scripts/base_train.py, nanochat/dataset | README 示例指出需要下载更多数据 shards(示例 -n 450),并按参数调整 --depth 与 --device_batch_size。 | d26 示例:约 12 小时、~$300(README 估) |
| 11. 用 run1000.sh 训练更强模型 | bash run1000.sh | run1000 脚本用于训练更长时间/更多 token(例如 README 的 d32 示例是通过 run1000.sh 得到的 1.9B 模型)。 | run1000.sh | run1000 会消耗更多 token 与时间(README 示例:d32 1.9B 用 ~38B tokens,约 $800/33 小时 on 8×H100)。 | 示例:~33 小时 / ~$800(README 示例) |
| 12. 检查或调整超参(示例) | 在训练命令后加 --depth=26 --device_batch_size=16 --... | README 给出示例如何用 --depth、--device_batch_size 等 CLI 参数调整模型规模/显存占用。 | scripts/base_train.py(接收参数) | 若显存不足,请减小 device_batch_size 或降低 --depth。README 举例:将 device batch size 从 32 -> 16。 | — |
| 13. 常见调试命令 | tail -f speedrun.log nvidia-smi `ps aux | grep python` | 查看日志、GPU 使用、进程状态。 | — | — |
| 14. 结束/清理 | 停止脚本、关机云机、保存模型文件(模型权重通常在项目目录的 out/ 子目录或 scripts 指定位置) | 保存产物并停止计费。 | — | README 未强制约定输出路径;查看脚本内 --out_dir、--checkpoint_dir 等参数。 |
使用细节与常见命令(摘自仓库)
* `report.md`:speedrun 完成后仓库目录会出现 `report.md`,包含本次运行的评估表与指标(例如 CORE、ARC、GSM8K、HumanEval、MMLU 等);作者在 README 中举了一个示例表与运行时间(例如 Total wall clock time: 3h51m)。这有助于检查训练质量与性能基准。
* 训练快速体验:`bash speedrun.sh`。
* 查看训练进度:用 `screen` + `tail speedrun.log`。
* 启动 Web UI:`python -m scripts.chat_web`(使用 `.venv` 中的 Python, README 明确要求激活虚拟环境 `source .venv/bin/activate`)。
* 若要扩展到更大规模(如 d26、GPT-2 级别),README 给出要点:增加 `--depth`、下载更多数据 shards、调整 `device_batch_size`、在 `torchrun` 中使用 `--nproc_per_node=8` 等指令(README 中有示例片段)。
2.3、在线演示
作者托管了 `nanochat d32`(可在线交互 demo),这是一个 32 层、约 1.9B 参数 的模型,训练用了 ~38B tokens,用 `run1000.sh` 完成;作者给出的训练成本示例约 $800(≈33 小时 on 8×H100)。这用于展示模型的实际对话行为(会出现幼稚回复、幻觉等)。
* speedrun 的 report.md:speedrun 结束会输出 `report.md`,其中包含字符数、行数、文件数、token 数估算以及一系列评测指标(示例中列出的 CORE、ARC、GSM8K、HumanEval、MMLU、ChatCORE 等具体分数)。README 直接给了示例表格和运行时间(示例:Total wall clock time: 3h51m)。这些可作为复现后检视训练效果的参考。
nanochat的案例应用
更新中……