Mysql笔记13
一、Redis数据库的数据类型
1.key操作
(1)相关命令
| 命令语法 | 描述 |
| DEL key | 该命令用于在 key 存在时删除 key |
| DUMP key | 序列化key(二进制) RESTORE mynewkey 0 "序列化值" [replace] |
| EXISTS key | 检查给定 key 是否存在,存在返回1,否则返回0 |
| EXPIRE key seconds | 为给定 key 设置过期时间,以秒计 |
| EXPIREAT key timestamp | EXPIREAT 的作用和 EXPIRE 类似,都用于为 key 设置过期时间。不同在于 EXPIREAT 命令接受的时间参数是 UNIX 时间戳 |
| PEXPIRE key milliseconds | 设置 key 的过期时间以毫秒计 |
| PEXPIREAT key milliseconds-timestamp | 设置 key 过期时间的时间戳(unix timestamp) 以毫秒计 |
| KEYS pattern | 查找所有符合给定模式( pattern)的 key * ? [] |
| MOVE key db | 将当前数据库的 key 移动到给定的数据库 db 当中 |
| PERSIST key | 移除 key 的过期时间,key 将持久保持 |
| PTTL key | 以毫秒为单位返回 key 的剩余的过期时间 |
| TTL key | 以秒为单位,返回给定 key 的剩余生存时间(TTL, time to live) |
| RANDOMKEY | 从当前数据库中随机返回一个 key |
| RENAME key newkey | 修改 key 的名称 |
| RENAMENX key newkey | 仅当 newkey 不存在时,将 key 改名为 newkey |
| TYPE key | 返回 key 所储存的值的类型 |
| SELECT db | 选择数据库 数据库为0-15(默认一共16个数据库) |
| DBSIZE | 查看数据库的key数量 |
| FLUSHDB | 清空当前数据库 |
| FLUSHALL | 清空所有数据库 |
| ECHO | 打印命令 |
说明:
KEYS * 匹配数据库中所有 key
KEYS h?llo 匹配 hello,hallo,hxllo 等
KEYS h*llo 匹配 hllo和 heeello 等
KEYS h[ae]llo 匹配 hello 和 hallo
(2)示例
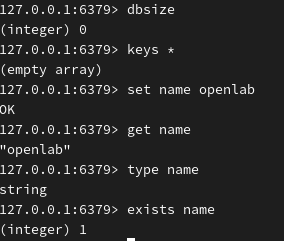
查看 key 数量和所有 key值 ,添加一些 key 值(命令不区分大小写,但键 key 区分):
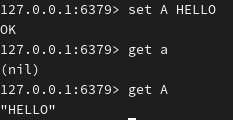
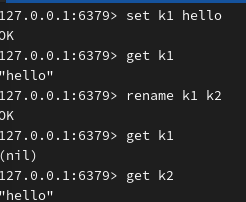
key 改名:
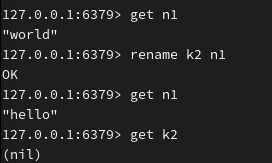
若新改的key名早已存在,此时这个key会被覆盖:
删除 key (删除没有的会返回0):
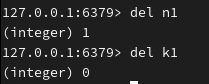
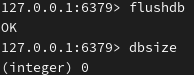
清库:
Unix 时间戳(常用于 key 的过期策略、数据版本管理或基于时间的业务逻辑):
将指定日期装换为时间戳16961...,秒数从 1970 年 1 月 1 日 00:00:00 UTC 开始计算。再将时间戳装换回日期格式:

2.String
(1)概念
类型特性:是二进制安全的,可存储任何数据(如图片、序列化对象等),一个 key 对应一个 value ,单值最大存储 512MB。
典型应用:常用于缓存(存储业务数据)、限流(控制请求频率)、计数器(统计访问量等)、分布式锁(通过 SETNX 实现进程间互斥)、分布式 Session(存储用户登录状态、购物车等临时信息)等场景。
(2)结构图
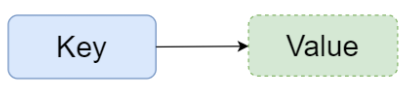
(3)相关命令
| 命令语法 | 描述 |
| SET key value | 设置指定 key 的值 |
| GET key | 获取指定 key 的值 |
| GETRANGE key start end | 返回 key 中字符串值的子字符,end=-1时表示全部 |
| SETBIT key offset value | 用于对指定 key 所存储的字符串值,设置或清除指定偏移量上的位(bit) setbit lisi 1 0 用用户 ID 作为键名,偏移量代表日期,位值为 1 表示签到,0 表示未签到。 |
| GETBIT key offset | 获取lisi 周1 的状态 |
| MSET key value [key value ...] | 同时设置一个或多个 key-value 对 |
| MGET key1 [key2..] | 获取所有(一个或多个)给定 key 的值 |
| GETSET key value | 将给定 key 的值设为 value ,并返回 key 的旧值(old value) |
| SETEX key seconds value | 将值 value 关联到 key ,并将 key 的过期时间设为 seconds (以秒为单位) |
| SETNX key value | 只有在 key 不存在时设置 key 的值 |
| SETRANGE key offset value | 用 value 参数覆写给定 key 所储存的字符串值,从下标 offset 开始 |
| STRLEN key | 返回 key 所储存的字符串值的长度 |
| MSETNX key value [key value ...] | 同时设置一个或多个 key-value 对,当且仅当所有给定 key 都不存在 |
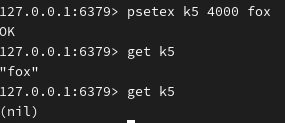
| PSETEX key milliseconds value | 与 SETEX 命令相似,但它以毫秒为单位设置 key 的生存时间 |
| INCR key | 将 key 中储存的数字值增一 |
| INCRBY key increment | 将 key 所储存的值加上给定的增量值(increment) |
| INCRBYFLOAT key increment | 将 key 所储存的值加上给定的浮点增量值(increment) |
| DECR key | 将 key 中储存的数字值减一 |
| DECRBY key decrement | key 所储存的值减去给定的减量值(decrement) |
| APPEND key value | 如果 key 已经存在并且是一个字符串,APPEND 命令将指定的 value 追加到该 key 原来值 value 的末尾 |
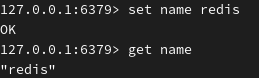
(4)示例
设置 String 类型的 key 值:
如果值是中文,则需要在连接客户端时指定规则:
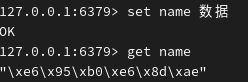
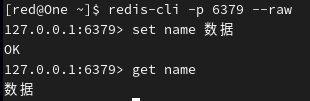
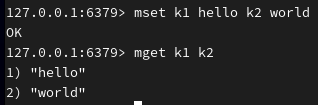
同时设置多个键值对,并显示多个值:
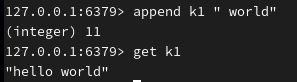
给 k1 键对应的值尾部追加字符串,有空格加引号:
设置 k1 的新值,并返回旧值:
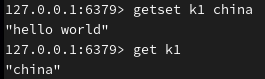
setnx 是一个用于设置键值对的命令,仅在键不存在时才能设置该键并赋值:
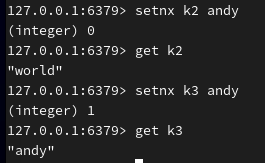
设置键 k4 的值为 jenny ,过期时间是4秒:
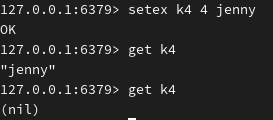
设置键 k5 的值为 fox ,过期时间单位为4000毫秒:
返回字符串长度:
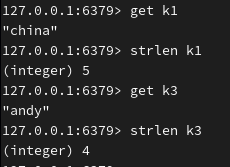
对 k4 键对应的值自增1:
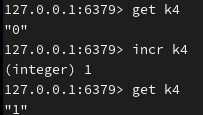
给 k4 键的对应值减去1:
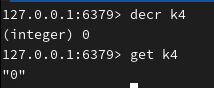
减去指定的值:
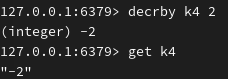
增加一个浮点数,此时不能运行整数操作:

截取子串,下标从0开始,闭区间(若超出下标范围,会自动将下标截断到有效范围):
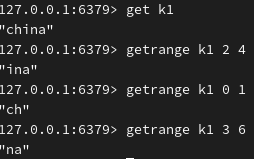
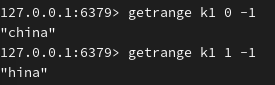
end (最后一个字)为-1,表示截取到最后:
(5)优缺点
优点:简单直观,每个属性都支持 更新操作。
缺点:占用过多的键,内存占用量 较大,同时用户信息内聚性比较差
(6)应用场景
例如统计一篇文章的阅读量,在业务场景上来说用户打开一篇文章则+1,那么可以使用redis的计数器。使用incr article:readcount:1000,每执行一次表示文章ID为1000的累加一次。article:readcount是我们自定义的前缀,为了更好的见名识义。
Web集群 session 共享,spring session + redis 实现 session 共享
分布式全局序列号,使用redis批量生成序列号提升性能,INCRBY orderId 1
3.List
(1)概念
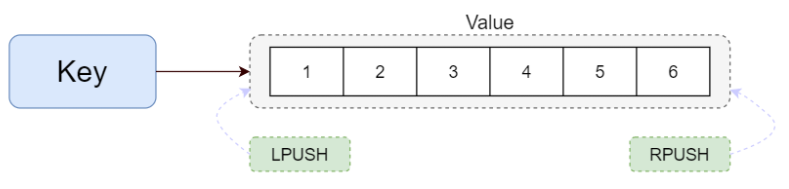
Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)一个列表最多可以包含 2^32^ - 1 个元素 (4294967295, 每个列表超过40亿个元素)。List类型一般用于关注人、简单队列等。
(2)结构图
(3)相关命令
| 命令语法 | 描述 |
| LPUSH key value1 [value2] | 将一个或多个值插入到列表头部 |
| LPOP key | 左弹出一个值 |
| LRANGE key start stop | 获取列表指定范围内的元素 |
| LPUSHX key value | 仅当键已存在将一个值插入到已存在的列表头部 |
| RPUSH key value1 [value2] | 在列表中添加一个或多个值 |
| RPOP key | 移除列表的最后一个元素,返回值为移除的元素 |
| RPUSHX key value | 为已存在的列表添加值 |
| LLEN key | 获取列表长度 |
| LINSERT key BEFORE|AFTER pivot value | 在列表的元素前或者后插入元素 |
| LINDEX key index | 通过索引获取列表中的元素 |
| LSET key index value | 通过索引设置列表元素的值 |
| LREM key count value | 移除列表中指定数量个[字符/字符串] |
| LTRIM key start stop | 对一个列表进行修剪,就是让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除 |
| BLPOP key1 [key2 ] timeout | 移出并获取列表的第一个元素,如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止 |
| BRPOP key1 [key2 ] timeout | 移出并获取列表的最后一个元素,如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止 |
| BRPOPLPUSH source destination timeout | 从列表中弹出一个值,将弹出的元素插入到另外一个列表中并返回它;如果列表没有元素会阻塞列表直到等待超时或发现可lpu弹出元素为止 |
| RPOPLPUSH source destination | 移除列表的最后一个元素,并将该元素添加到另一个列表并返回 |
(4)示例
先查看当前 key 的数据类型是否和 list 一致,不一致的话可以清理或装换 key ,避免数据类型不匹配导致错误。
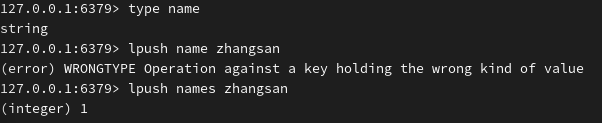
再向 list 类型的 key 左侧添加元素:
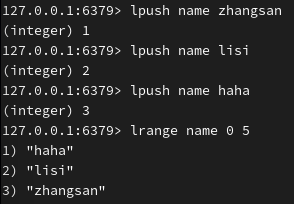
lrange 用于获取 key 为 name 的 list 中索引从几到几的元素(下标从0开始):
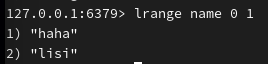
查询第一个到最后一个、第一个到倒数第二个:
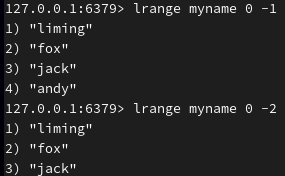
向右插入元素:
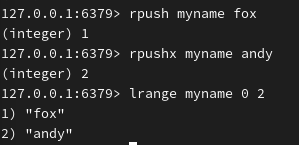
在指定值之前插入:
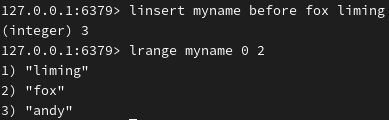
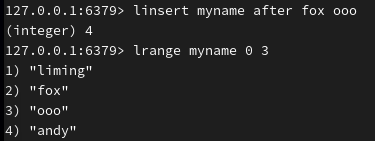
在指定值之后插入:
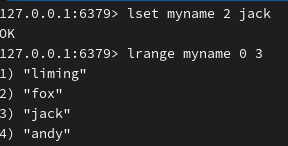
更新指定下标的数据:
获取 list 的长度:

移除左侧或右侧的第一个值:
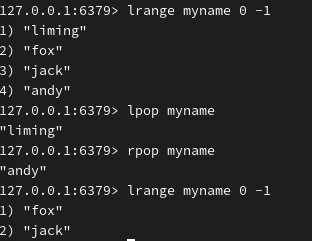
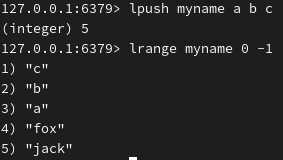
左或右补上几个值:
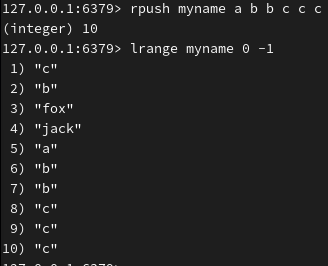
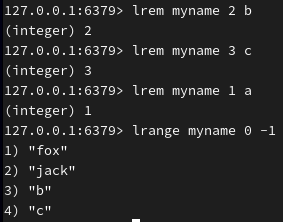
删除(2个b、3个c、1个a):
裁剪列表,保留下标0 1 2的值:
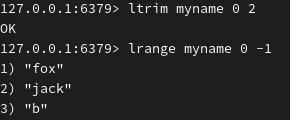
从原有列表的右端弹出元素到新列表(向左端添加到新列表):
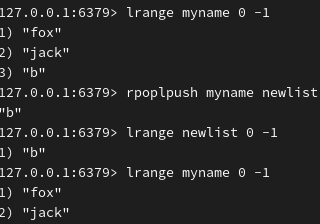
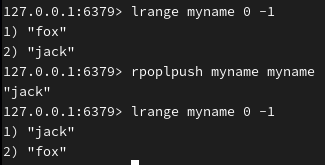
从原有列表的右端弹出元素到原有列表(向左端添加到原有列表)
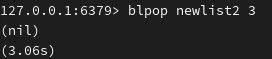
阻塞:
从 newlist2 右端弹出元素(左推入 newlist ),若 newlist2 为空列表,会阻塞等待最多3秒,超时后返回 nil :

从 newlist2 左端弹出元素,若 newlist2 为空列表,阻塞等待3秒,超时退出(blpop 就相当于一个监听器,监听 list 中的消息,有数据就返回,没有就一直监听):
(6)应用场景
数据结构实现:
栈(Stack):通过 LPUSH (左入)+ LPOP (左出)实现先进后出的栈结构。
队列(Queue):通过 LPUSH (左入)+ RPOP (右出)实现后进先出的队列结构。
阻塞队列(BlockingMQ):通过 LPUSH + BRPOP (阻塞右出)实现阻塞式消息队列,常用于异步任务处理等场景。
消息流场景:
在微博、微信朋友圈、公众号等业务中,利用 List 的 LPUSH (保证最新消息在队首)+ LRANGE (获取指定范围消息)实现按时间顺序的消息流展示,比如最新发布的内容优先显示,同时可通过 LRANGE 快速获取最近几条内容进行回显,相比数据库方案更简单高效。
4.Set
(1)概念
Redis 的 Set 是 String 类型的无序集合。集合中成员是唯一的,这就意味着集合中不能出现重复的数据。Redis 中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。 集合中最大的成员数为 2^32^ - 1 (4294967295, 每个集合可存储40多亿个成员)。Set类型一般用于赞、踩、标签、好友关系等。
(2)结构图

(3)相关命令
| 命令语法 | 描述 |
| SADD key member1 [member2] | 向集合添加一个或多个成员 |
| SMEMBERS key | 返回集合中的所有成员 |
| SCARD key | 获取集合的成员数 |
| SRANDMEMBER key [count] | 返回集合中一个或多个随机数 |
| SISMEMBER key member | 判断 member 元素是否是集合 key 的成员 |
| SREM key member1 [member2] | 移除集合中一个或多个成员 |
| SDIFF key1 [key2] | 返回给定所有集合的差集 |
| SDIFFSTORE destination key1 [key2] | 返回给定所有集合的差集并存储在 destination 中 |
| SINTER key1 [key2] | 返回给定所有集合的交集 |
| SINTERSTORE destination key1 [key2] | 返回给定所有集合的交集并存储在 destination 中 |
| SUNION key1 [key2] | 返回所有给定集合的并集 |
| SUNIONSTORE destination key1 [key2] | 所有给定集合的并集存储在 destination 集合中 |
| SMOVE source destination member | 将 member 元素从 source 集合移动到 destination 集合 |
| SPOP key | 移除并返回集合中删除的元素 |
| SSCAN key cursor [MATCH pattern] [COUNT count] | 迭代集合中的元素 |
| cursor | 游标 |
| MATCH pattern | 查询 Key 的条件 |
| Count count | 返回的条数,默认值为 10 |
注意:
SCAN 是一个基于游标的迭代器,需要基于上一次的游标延续之前的迭代过程。SCAN 以 0 作为游标,开始一次新的迭代,直到命令返回游标 0 完成一次遍历。 此命令并不保证每次执行都返回某个给定数量的元素,甚至会返回 0 个元素,但只要游标不是 0,程序都不会认为 SCAN 命令结束,但是返回的元素数量大概率符合 Count 参数。另外,SCAN 支持模糊查询。
例:SSCAN names 0 MATCH test* COUNT 10 # 每次返回10条以 test 为前缀的 key
(4)示例
添加 set 元素,不可重复添加:
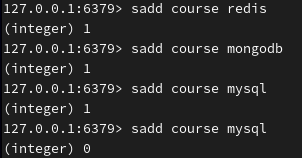
查询 set 所有成员(无序):
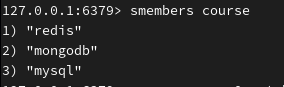
返回集合成员总个数:
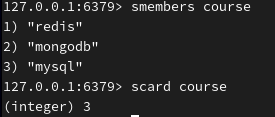
随机返回2个成员:

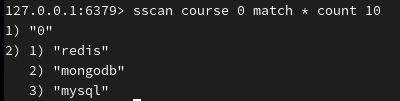
set 的模糊查询(尝试匹配以1开头的元素,无匹配结果所以未显示):

set 的分页查询(从游标0开始,扫描所有元素,每次最多返回10个):
判断集合中某个成员是否存在,存在返回1:
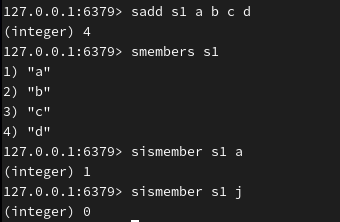
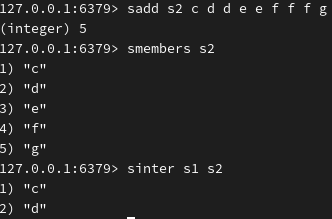
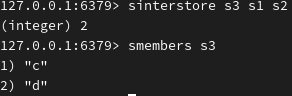
返回交集(s1与s2),并将其交集存储在 s3 中:
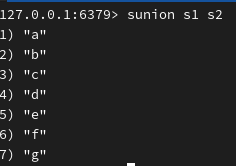
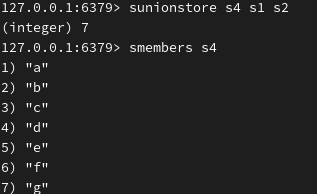
返回并集,并将其并集存储在 s4 中:
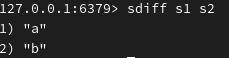
返回差集,并将其差集存储在 s5 中:
(与 s1 相比, s2 中少了什么)
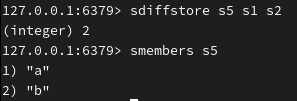
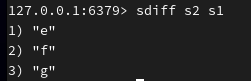
(与 s2 相比, s1 中少了什么)
移动 s1 集合中的 a 到集合 newset 中:
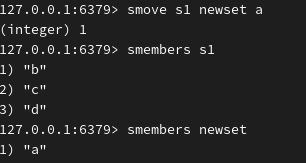
随机删除 s1 集合的1个成员:
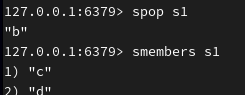
删除指定成员:
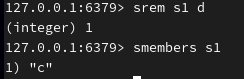
(5)应用场景
抽奖活动:
一次抽奖多个用户,例如参与抽奖的用户有10个,一次抽取2个用户作为中奖用户,使用 SMEMBERS key 查看所有抽奖成员,使用 SRANDMEMBER key [count] 抽取2个成员。
多次抽奖,被开奖的用户不可再次参与。使用 SPOP key [count] 抽取成员作为开奖用户,同时会移除已开奖的用户。
微信点赞、评论:
存储的结构为—— 消息 ID 为 key ,例如:like:msgID
用户 ID 为 field ,例如:10000
朋友圈消息点赞时使用 SADD key member 添加一条记录,例如 sadd like:1 1000 。取消点赞 srem like:1 1000 。消息点赞后的图标高亮,使用 SISMEMBER key member 查询成员是否存在,存在则高亮。使用 SCARD key 获得点赞成员数量。
朋友圈消息点赞成员列表,在微信朋友圈中,当我点赞朋友的一条消息时,会在下方显示点赞成员列表,这个列表只显示与我是好友的点赞成员,不是好友则不显示。那么此时可以使用交集查询。
电商系统购买电脑时配置选择:
Redis Set 用于管理可选配置集合(如 CPU、内存、硬盘的合法选项),通过 SISMEMBER 验证用户选择合法性,利用无重复特性避免配置冲突,还可通过集合运算实现配置组合推荐。
5.Zset
(1)概念
Redis Zset(有序集合)是不允许重复成员的字符串集合,每个成员关联一个 double 类型分数,Redis 通过分数对成员进行从小到大排序(成员唯一,分数可重复)。它基于哈希表实现,添加、删除、查找操作复杂度为 O(1),单个集合最多可存储约 40 多亿个成员,主要用于排行榜等需有序展示数据的场景。
(2)结构图

(3)相关命令
| 命令语法 | 描述 |
| ZADD key score1 member1 [score2 member2] | 向有序集合添加一个或多个成员,或者更新已存在成员的分数 |
| ZCARD key | 获取有序集合的成员数 |
| ZCOUNT key min max | 计算在有序集合中指定区间分数的成员数 |
| ZINCRBY key increment member | 有序集合中对指定成员的分数加上增量 increment |
| ZLEXCOUNT key min max | 在有序集合中计算指定字典(集合对象按照字符串比较需要同[ (开闭区间匹配)区间内成员数量 [wangmazi (zhangsan |
| ZRANGEBYLEX key min max [LIMIT offset count] | 通过字典区间返回有序集合的成员 |
| ZRANGE key start stop [WITHSCORES] | 通过索引区间返回有序集合指定区间内的成员 |
| ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT] | 通过分数返回有序集合指定区间内的成员 |
| ZRANK key member | 返回有序集合中指定成员的索引 |
| ZREM key member [member ...] | 移除有序集合中的一个或多个成员 |
| ZREMRANGEBYLEX key min max | 移除有序集合中给定的字典区间的所有成员 |
| ZREMRANGEBYRANK key start stop | 移除有序集合中给定的下标区间的所有成员 |
| ZREMRANGEBYSCORE key min max | 移除有序集合中给定的分数区间的所有成员 |
| ZREVRANGE key start stop [WITHSCORES] | 返回有序集中指定区间内的成员,通过索引,分数从高到低 |
| ZREVRANGEBYSCORE key max min [WITHSCORES] | 返回有序集中指定分数区间内的成员,分数从高到低排序 |
| ZREVRANK key member | 返回有序集合中指定成员的排名有序集成员按分数值递减(从大到小)排序 |
| ZSCORE key member | 返回有序集中,成员的分数值 |
| ZINTERSTORE destination numkeys key [key ...] | 目标集合保存 指定集合的个数(numkeys)通过集合名计算交集的成员成绩是相加 |
| ZUNIONSTORE destination numkeys key [key ...] | 计算给定的一个或多个有序集的并集,并存储在新的 key 中 |
(4)示例
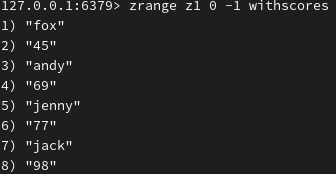
添加 zset 元素及分数(默认升序查看):
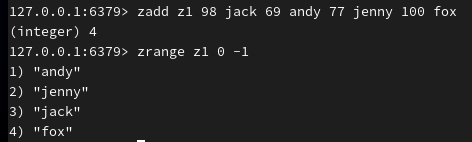
修改分数:
(存在则直接修改)

(不存在则添加)
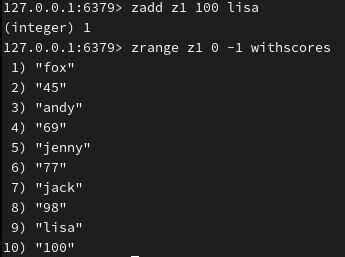
降序查看:
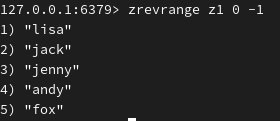
统计成员个数:
![]()
统计指定分数区间的成员个数:

给 fox 成员增加15分:
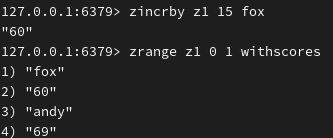
查询成员分数(或者查询分数在80分-100分范围内的成员):
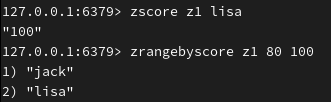
删除成员:
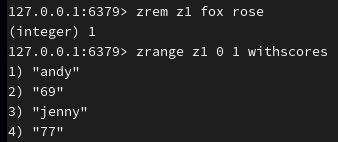
(5)应用场景
体育赛事排行榜、新闻热度排行榜。任意打开一个新闻网站,总有块区域显示排行前10的新闻,排行版一般都是根据点击数来排行的,这个点击数就可以使用 ZINCRBY key increment member 指令来实现。例如: zincrby hotNews:currentDate 1 newsTopic ,每点击一次 newsTopic+1 (新闻主题的分值+1)。
6.Hash
(1)概念
Redis hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。Redis 中每个 hash 可以存储 2^32^ - 1 键值对(40多亿)。
(2)结构图
(3)相关命令
| 命令语法 | 描述 |
| HSET key field value | 将哈希表 key 中的字段 field 的值设为 value |
| HGET key field | 获取存储在哈希表中指定字段的值 |
| HGETALL key | 获取在哈希表中指定 key 的所有字段和值 |
| HEXISTS key field | 查看哈希表 key 中,指定的字段是否存在 |
| HSETNX key field value | 只有在字段 field 不存在时,设置哈希表字段的值 |
| HKEYS key | 获取所有哈希表中的字段 |
| HVALS key | 获取哈希表中所有值 |
| HLEN key | 获取哈希表中字段的数量 |
| HMGET key field1 [field2] | 获取所有给定字段的值 |
| HMSET key field1 value1 [field2 value2] | 同时将多个 field-value (域-值)对设置到哈希表 key 中 |
| HINCRBY key field increment | 为哈希表 key 中的指定字段的整数值加上增量 increment |
| HINCRBYFLOAT key field increment | 为哈希表 key 中的指定字段的浮点数值加上增量 increment |
| HDEL key field1 [field2] | 删除一个或多个哈希表字段 |
(4)示例
批量设置 hash 字段及对应的值,再查询所有字段和值:
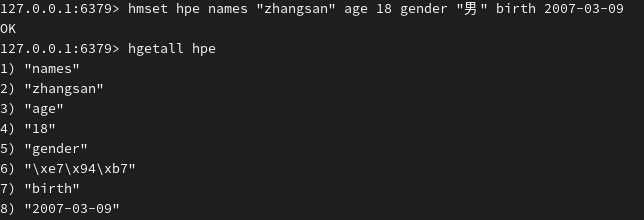
应用场景:
电商系统购物车数据存储,存储的结构为:
用户ID为key ,例如:cart:userId 商品ID为field,例如:10000 商品数量为value,例如:1
举例:
商品加入购物车使用:hmset key field1 value1 [field2 value2 ...] (也可用 hset 多个添加)
![]()
物车商品数量+1使用 hincrby key field increment(购物车1001的商品+1,由原来的1个变成2个)
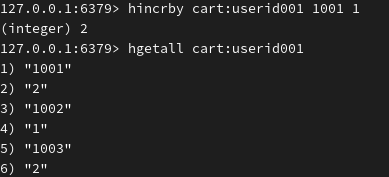
由上图可知购物车的商品总数是3条(1001 1002 1003),使用HLEN key 获得

如果要删除一个商品,使用hdel key
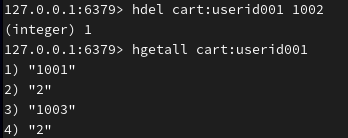
注:不要使用大 key 存储(单个 key 对应的 value 数据量过大的情况),如果大 key 存储需要分段存储。 这是因为→
性能下降:Redis 是单线程执行命令,操作大key时会占用大量时间,阻塞其他命令执行,导致响应延迟增加。
网络开销大:大key在网络传输中会消耗更多带宽,增加延迟,甚至可能导致超时。
内存问题:大key会占用大量内存,容易引发内存碎片化,且在删除或迁移时可能导致 Redis 实例内存不足甚至宕机。
持久化与主从同步受影响:生成 RDB 快照或 AOF 重写时,大key会使持久化过程变慢;主从同步大key时,会阻塞同步链路,导致主从延迟暴增。
(5)优缺点
优点:同类数据归类存储方便管理。从底层结果来说,比 string 操作消耗内存更小,也比 string 存储更节省空间。
缺点:有效时间只能设置在 key 上,不能设置在 field 字段上。 Redis 集群架构下不适合大规模使用。
7.Bitmaps
(1)概念
现代计算机用二进制(位) 作为信息的基础单位, 1个字节等于8位, 例如“abc”字符串是由3个字节组成, 但实际在计算机存储时将其用二进制表示, “abc”分别对应的ASCII码分别是97、 98、 99, 对应的二进制分别是01100001、 01100010和01100011,如:

合理地使用操作位能够有效地提高内存使用率和开发效率。
Redis 6 中提供了 Bitmaps 这个“数据类型”可以实现对位的操作:
Bitmaps本身不是一种数据类型,实际上它就是字符串(key-value),但是它可以对字符串的位进行操作。
Bitmaps单独提供了一套命令,所以在Redis中使用Bitmaps和使用字符串的方法不太相同。 可以把Bitmaps想象成一个以位为单位的数组, 数组的每个单元只能存储0和1, 数组的下标在Bitmaps中叫做偏移量。

(2)相关命令
setbit
这个命令用于设置 Bitmaps 中某个偏移量的值(0或1),offset偏移量从0开始。格式为:
setbit <key> <offset> <value>
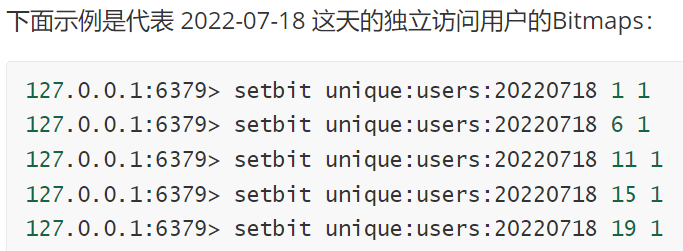
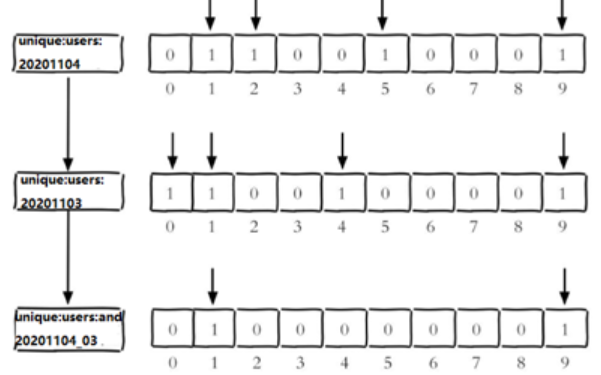
例如,把每个独立用户是否访问过网站存放在 Bitmaps 中, 将访问的用户记做1,没有访问的用户记做0,用偏移量作为用户的 id 。
设置键的第offset个位的值(从0算起) , 假设现在有20个用户,userid=1,6,11,15,19的用户对网站进行了访问, 那么当前Bitmaps初始化结果如图:

很多应用的用户id以一个指定数字(例如10000) 开头, 直接将用户id和Bitmaps的偏移量对应势必会造成一定的浪费, 通常的做法是每次做setbit操作时将用户id减去这个指定数字。
在第一次初始化Bitmaps时, 假如偏移量非常大, 那么整个初始化过程执行会比较慢, 可能会造成Redis的阻塞。
getbit
这个命令用于获取Bitmaps中某个偏移量的值。格式为:
getbit <key> <offset>
获取键的第offset位的值(从0开始算)。例如获取id=6的用户是否在2022-07-18这天访问过, 返回0说明没有访问过:

bitcount
这个命令用于统计字符串被设置为1的bit数。一般情况下,给定的整个字符串都会被进行计数,通过指定额外的 start 或 end 参数,可以让计数只在特定的位上进行。start 和 end 参数的设置,都可以使用负数值:比如 -1 表示最后一个位,而 -2 表示倒数第二个位,start、end 是指bit组的字节的下标数,二者皆包含。格式为:
bitcount <key> [start end]
字节的编号从 0 开始,一个字节有 8 位。第 1 个字节涵盖偏移量 8 - 15,第 2 个字节涵盖偏移量 16 - 23,第 3 个字节涵盖偏移量 24 - 31。例如,统计id在第1个字节到第3个字节之间的独立访问用户数, 对应的用户id是11, 15, 19。
![]()
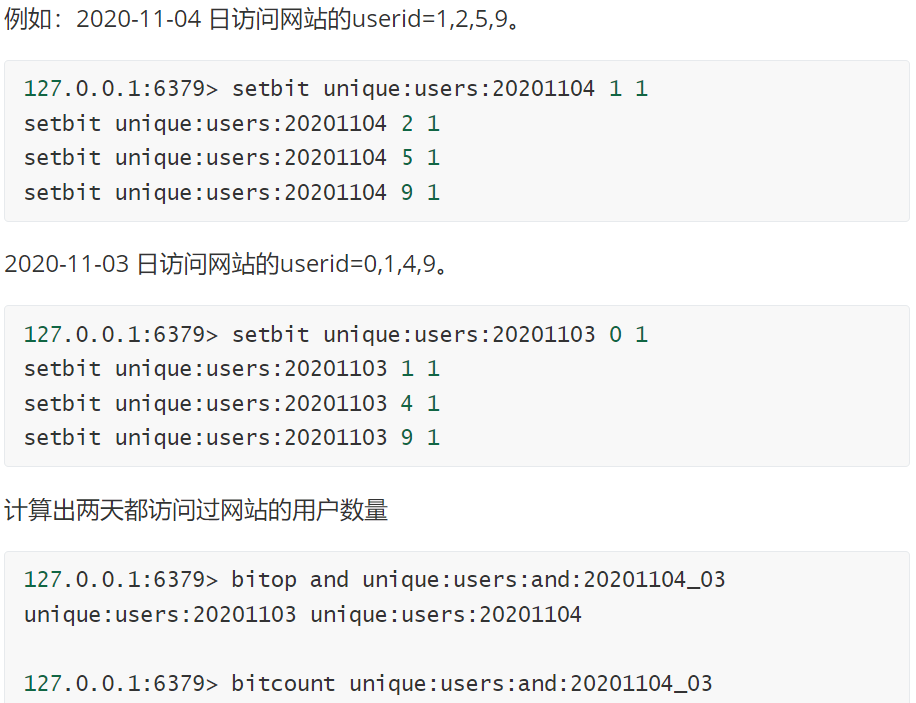
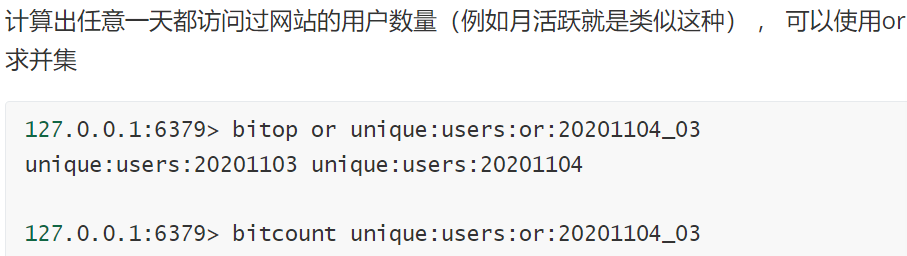
bitop
这个命令是一个复合操作, 它可以做多个Bitmaps的and(交集) 、 or(并集) 、 not(非) 、 xor(异或两个二进制位相同则异或结果为 0,不同为1) 操作并将结果保存在destkey中。格式为:
bitop and(or/not/xor) <destkey> [key…]
8.HyperLogLog
(1)概念
场景需求:
工作中常需统计网站PV(用 incr / incrby 易实现),但UV、独立IP数等“去重计数”的基数问题,传统方案有局限。
传统方案:
存MySQL用 distinct count ;
用Redis的Hash、Set、Bitmaps等。这些方案结果精确,但数据量增大时,占用空间会持续膨胀,不适合超大数据集。
HyperLogLog 算法:为平衡精度与存储空间,Redis 推出该算法。它的优势是,即便输入元素数量/体积极大,计算基数所需空间固定且极小( Redis 中每个 HyperLogLog 键仅需12KB内存,可计算近2^{64}个不同元素的基数)。不过,它只计算基数,不存储输入元素本身,无法像集合那样返回具体元素。
基数:如数据集 {1, 3, 5, 7, 5, 7, 8}中,它的基数集为 {1, 3, 5 ,7, 8},基数(不重复元素)为5。而基数估计就是在误差可接受的范围内,快速计算基数。
注:
伯努利试验
哈希处理:当有元素要加入到 HyperLogLog 结构中时,首先会对这个元素进行哈希运算,就好像给每个元素都分配一个独一无二的 “编码”,不管元素本身是什么,都能变成一个固定长度的二进制数字串。
分桶与统计:把这些哈希值的二进制串分成多个部分,每个部分对应一个 “桶”。然后,观察每个桶里的二进制串,找到从左到右第一个出现1的位置。比如,一个二进制串是00010110,那第一个1出现在第 4 位(从左往右数,从 0 开始计数)。HyperLogLog 会记录下每个桶中第一个1出现的最大位置。
估算基数:最后,根据所有桶中记录的这些最大值,利用一个特定的数学公式来估算集合中不同元素的数量。这个公式会综合考虑桶的数量、每个桶中最大位置等因素,通过一些复杂的计算,得出一个对集合基数的估计值。
(2)相关命令
| 命令语法 | 描述 |
| PFADD key element [element ...] | 添加指定元素到 HyperLogLog 中 |
| PFCOUNT key [key ...] | 返回给定 HyperLogLog 的基数估算值 |
| PFMERGE destkey sourcekey [sourcekey ...] | 将多个 HyperLogLog 合并为一个 HyperLogLog |
(3)示例
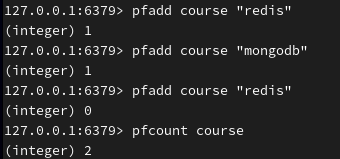
将字符串添加到 HLL 数据结构 course 集合中,计算基数,若基数变化(是新元素)则返回1否则返回0。并统计基数数量(去重):
合并多个 HyperLogLog 结构,将多个集合的基数统计结果合并到一个集合中(将 course1 合并到 course ):
![]()
9.Geospatial
(1)概念
Redis 3.2 中增加了对GEO类型的支持。GEO,Geographic,地理信息的缩写。该类型,就是元素的2维坐标,在地图上就是经纬度。redis 基于该类型,提供了经纬度设置,查询,范围查询,距离查询,经纬度 Hash 等常见操作。
(2)相关命令
| 命令语法 | 描述 |
| geoadd key longitude latitude member [longitude latitude member...] | 添加地理位置(经度,纬度,名称) |
| geopos key member [member...] | 获得指定地区的坐标值 |
| geodist key member1 member2 [m|km|ft|mi] | 获取两个位置之间的直线距离 |
| georadius key longitude latitude radius [m|km|ft|mi] | 以给定的经纬度为中心,找出某一半径内的元素 |
(3)示例
添加城市坐标
如设置上海、重庆、深圳和北京的坐标:

有效的经度从 -180 度到 180 度。有效的纬度从 -85.05112878 度到 85.05112878 度。当坐标位置超出指定范围时,该命令将会返回一个错误。已经添加的数据,是无法再次往里面添加的。
获取城市坐标
如获取上海的坐标:
![]()
获取两个位置之间的直线距离
如获取北京和深圳的直线距离:
![]()
单位:
m:表示单位为米[默认值]
km:表示单位为千米
mi:表示单位为英里
ft:表示单位为英尺
获取指定坐标半径内的元素
如获取经度为 110,纬度为 30,半径为 1000KM 的所有城市:
![]()