AI Agent概念 原理 实践
引言
互联网的新名词就没断过, 这个还没学会, 过几天又出来几个新的.
尤其在LLM流行开来之后, 新词又是一个接一个.
什么Prompt, Function Call, MCP, Agent, CoT, ReAct, RAG, Embedding …, 刚接触的时候有一种云里雾里的感觉.
不过万变不离其宗, 我们搞明白原理之后, 发现很多就是个壳子, 里面还是老一套或者是各种老技术的组合封装.
今天来学习下AI Agent(以下简称Agent)及相关的一些知识点.
Agent的历史
从我的个人经历来说起,主要是编程相关的一些东西。
记得刚开始是在2024年的时候正式接触LLM(Large Language Model), 那会openai的chat gpt特别火,
由于一些众所周知的原因, 国内想要访问openai的网站需要科学上网, 且要通过外国的手机号注册.
所以当时有很多帖子,标题如"超详细OpenAI账号注册教程"这种, 现在想想真是哭笑不得。
但是chat归chat,主要是解决一些问答类场景, 实用性不强。
后来工程界就研究这个东西怎么能解决实际问题, 比如我所在的软件行业,问题就变成了 GPT怎么帮我写代码, 而不只是回答我的问题。
接着就是见到或者参与的一些实践:
- vscode插件实现代码补全
如:根据注释然后按TAB键自动生成相应代码。这个一开始效果很差, 实现很多都是错的。
后来随着工程精细化及模型能力的提升,效果开始变好了,价值逐渐凸显。
代码自动补全功能,一开始大家用的也很happy,毕竟比起传统的IDE补全,能听懂人话,有了“灵性”,但是在实际工作中应用场景还是不够。我们要的是说一句话(可能是一个需求描述或者一个error stack msg), 然后AI帮我自动编写或者是修改好代码。 - 再到后来就发现了Cursor,也可能是接触比较晚,反正在当时就了解到有Cursor这个东西,然后就开始“大肆模仿”。
- 随即就出现了阿里的通义灵码插件,百度的Comate插件,字节的Trae, 腾讯的Code Buddy等等一大批产品。
然后我们就发现,可以通过自然语言实现一个相当复杂的需求。
这种能力,在LLM能力不变的情况下,Agent就变成一个至关重要的技术点了。
Agent的相关技术
Agent的雏形我理解就是上述说到的代码补全,一开始虽然效果差,但是其中的原理值得思考。
本质就是将LLM的回答内容通过一些工具(如echo / sed)转为需要的效果。
拿人来比划, LLM就是人的大脑,Agent就是人的眼睛、手、脚等,可以调动身边的各种工具来将大脑的想法落地。
一图胜千言:
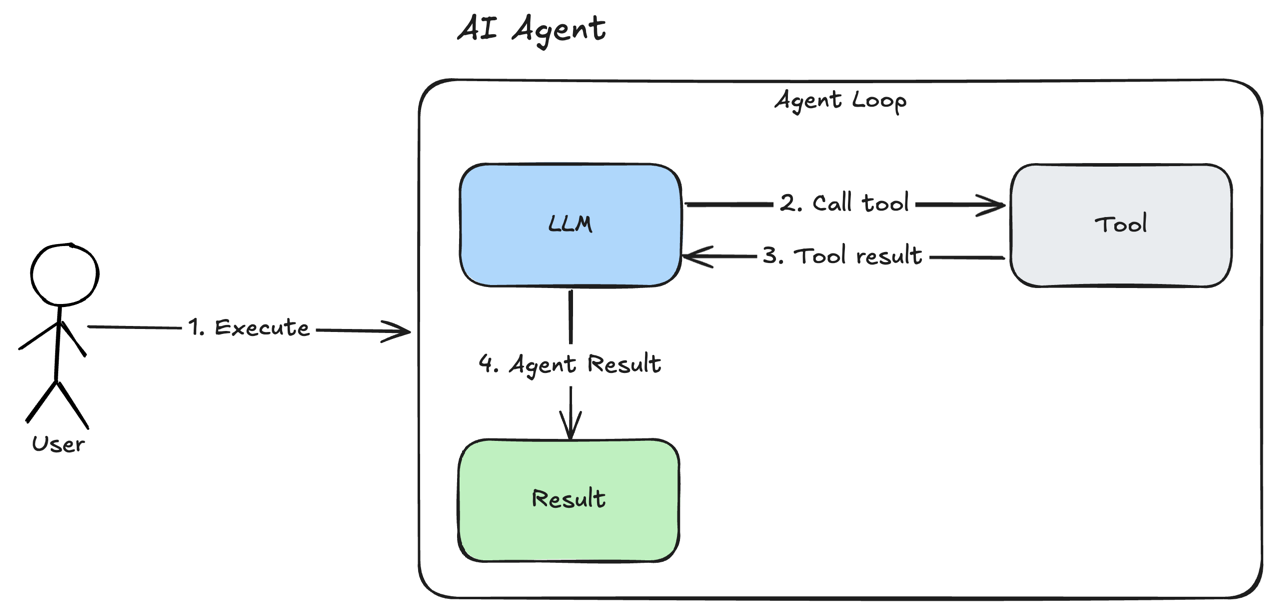
Function Call
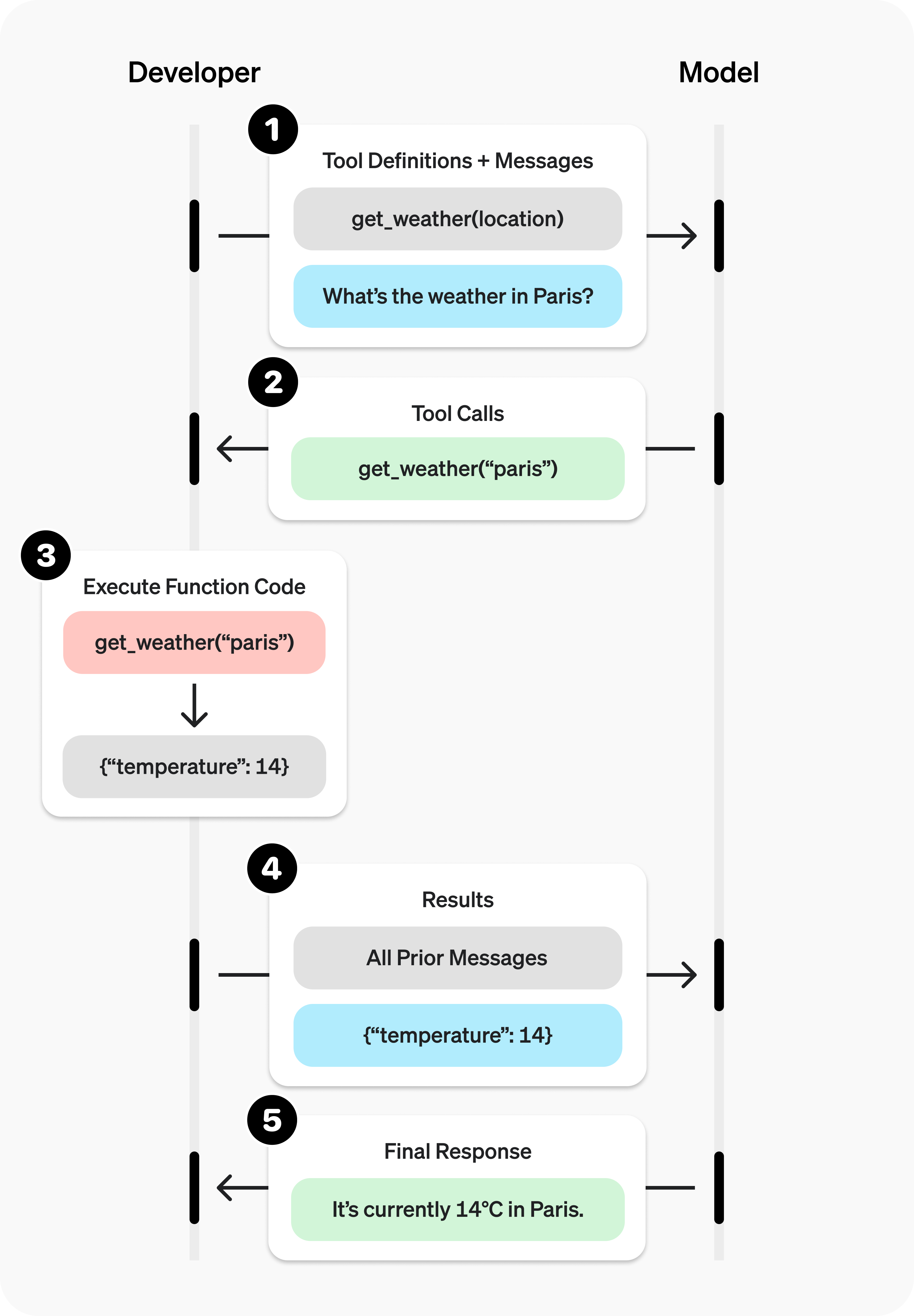
Function Call一开始是openai提出的,算是个厂商私有协议吧,毕竟在请求参数里。比如官网的例子https://platform.openai.com/docs/guides/function-calling:
from openai import OpenAI
import jsonclient = OpenAI()# 1. Define a list of callable tools for the model
tools = [{"type": "function","name": "get_horoscope","description": "Get today's horoscope for an astrological sign.","parameters": {"type": "object","properties": {"sign": {"type": "string","description": "An astrological sign like Taurus or Aquarius",},},"required": ["sign"],},},
]def get_horoscope(sign):return f"{sign}: Next Tuesday you will befriend a baby otter."# Create a running input list we will add to over time
input_list = [{"role": "user", "content": "What is my horoscope? I am an Aquarius."}
]# 2. Prompt the model with tools defined
response = client.responses.create(model="gpt-5",tools=tools,input=input_list,
)# Save function call outputs for subsequent requests
input_list += response.outputfor item in response.output:if item.type == "function_call":if item.name == "get_horoscope":# 3. Execute the function logic for get_horoscopehoroscope = get_horoscope(json.loads(item.arguments))# 4. Provide function call results to the modelinput_list.append({"type": "function_call_output","call_id": item.call_id,"output": json.dumps({"horoscope": horoscope})})print("Final input:")
print(input_list)response = client.responses.create(model="gpt-5",instructions="Respond only with a horoscope generated by a tool.",tools=tools,input=input_list,
)# 5. The model should be able to give a response!
print("Final output:")
print(response.model_dump_json(indent=2))
print("\n" + response.output_text)
原理也很简单,就是在向模型提问的时候再带上“我现在有这些工具(函数),每个函数的签名是这样这样的”,类似于人一样,
模型看到这些会思考用户的问题应该用哪些工具以及具体怎么用,将之(本质就是函数+实际参数)返回给Agent。
因为模型没有使用工具的能力,它只会思考;使用工具(本质是和环境交互)交给Agent, Agent再将工具的执行结果返回给模型做进一步处理。
Function Call看着挺好的,也比较简单,但是问题在于它是厂商私有协议,各家参数字段啥的可能并不兼容,所以并不通用。
MCP(Model Context Protocol)
由于Function Call存在着不通用的问题,所以有人提出了MCP – 这个是我自己想的,应该是合理猜测。因为历史往往就是这样,有问题出现,通常就会有人去解决,解决不了就发展新的机制替代旧的来变相解决。
MCP全称为Model Context Protocol,翻译过来是大模型上下文协议。
它建立一个连接LLM与外部资源的协议,使得遵循MCP的实现可以在不同的LLM之间使用,避免了Function Call不通用的问题。
MCP 的架构由四个关键部分组成:
- 主机(Host):主机是期望从服务器获取数据的人工智能应用,例如一个集成开发环境(IDE)、聊天机器人等。主机负责初始化和管理客户端、处理用户授权、管理上下文聚合等。
- 客户端(Client):客户端是主机与服务器之间的桥梁。它与服务器保持一对一的连接,负责消息路由、能力管理、协议协商和订阅管理等。客户端确保主机和服务器之间的通信清晰、安全且高效。
- 服务器(Server):服务器是提供外部数据和工具的组件。它通过工具、资源和提示模板为大型语言模型提供额外的上下文和功能。例如,一个服务器可以提供与Gmail、Slack等外部服务的API调用。
- 基础协议(Base Protocol):基础协议定义了主机、客户端和服务器之间如何通信。它包括消息格式、生命周期管理和传输机制等。
MCP 就像 USB-C 一样,可以让不同设备能够通过相同的接口连接在一起。
用过的mcp相关的库 mcp-go
Function Call vs MCP
MCP 是一个更底层、更通用的标准。Function Call 则是某些大模型专用的“增值服务”。
MCP 是通用协议层的标准化约定(更偏抽象和通用性)。
Function call 是某大模型厂商特定的实现方式和特性(更偏向具体实现)。
MCP存在的问题
在开始学习到MCP以及实现了一个demo后,我开始觉得,MCP太完美了,有了优秀的模型以及MCP,不就万能了吗?
但MCP也有它的问题,或者说不能应对所有应用场景。
MCP工具非常多,从https://mcpservers.org/all这里看已经上万了,鱼龙混杂。
- 相同功能的MCP实现方案往往存在多种版本,这些方案效果参差,难以统一标准;此外现有实现质量良莠不齐,真正适合生产环境部署的更是凤毛麟角。
- 企业基建衔接问题:当团队已建立统一的工具调用体系(如自研Agent框架或API网关)时,MCP协议层可能造成功能重叠,现有基建已涵盖工具管理、监控等核心功能,强行引入MCP反而会加重运维负担——这与服务网格(Service Mesh)在成熟技术架构中的推广困境如出一辙;
- 通用协议的适用性瓶颈:MCP的标准化设计在金融、工业等垂直领域面临适配难题(如特殊的安全审计要求或数据隔离需求),这种情况下直接开发专用工具链通常更具实操优势。
A2A (Agent-to-Agent)
随着任务越来越复杂,单个 Agent 能力有限,多 Agent 协作成为趋势。面向Agent间的协议主要是为了规范 Agent 之间的沟通、发现和协作。
2025年4月,Google联合50多家技术和服务合作伙伴,共同发布了全新的开放协议——A2A(Agent2Agent)。A2A协议旨在为AI智能体之间的互操作性和协作提供标准化的通信方式,无论底层框架或供应商如何,智能体都能安全、灵活地发现彼此、交换信息、协同完成复杂任务。A2A协议的核心功能包括:
- 能力发现:智能体通过JSON格式的"Agent Card"宣传自身能力,便于其他Agent发现和调用最合适的智能体。
- 任务和状态管理:以任务为导向,协议定义了任务对象及其生命周期,支持任务的分发、进度同步和结果(工件)输出,适配长短任务场景。
- 协作与消息交换:智能体之间可发送消息,交流上下文、回复、工件或用户指令,实现多智能体间的高效协作。
- 用户体验协商:每条消息可包含不同类型的内容片段(如图片、表单、视频等),支持客户端和远程Agent协商所需的内容格式和UI能力。
基于A2A协议,开发者可以构建能够与其他A2A智能体互联互通的系统,实现跨平台、跨厂商的多Agent协作。例如在软件工程中,一个Agent实现收集用户需求,第二个Agent实现编码测试上线,第三个Agent实现推广运营,所有流程通过A2A协议无缝衔接,大幅提升自动化和协作效率。
Agent思考框架
做事要讲方法,尤其是面对复杂的任务的时候。到了Agent这里也一样,要有合理的流程去解决问题。
思维链(Chain-of-Thought, CoT)、推理行动(Reasoning and Acting, ReAct)、计划执行(Plan-and-Execute)是三种重要的AI推理方法,它们通过不同的方式提升大语言模型的推理能力和任务执行效果。
CoT(Chain-of-Thought)
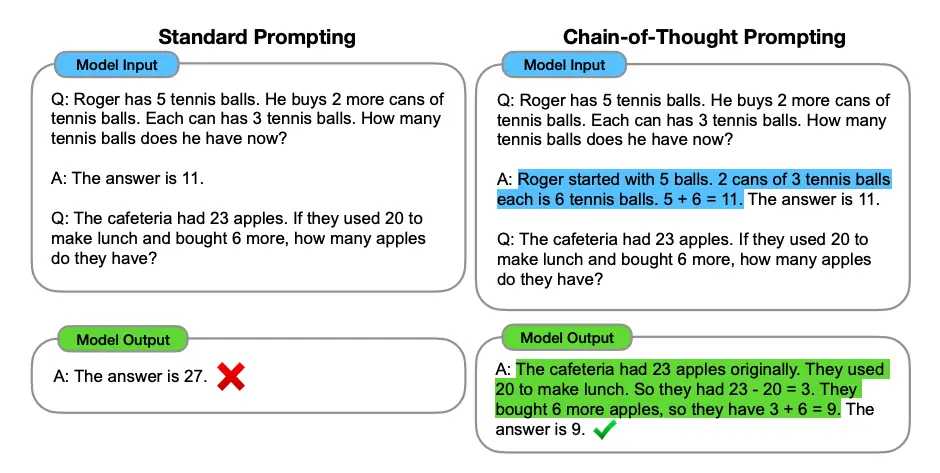
思维链方法通过逐步展示推理过程,引导模型生成更合理的回答。
相比直接给出答案,CoT要求模型先展示中间推理步骤,从而提升复杂问题的解决能力。
经典例子
ReAct(Reasoning and Action)
CoT虽然提升了模型的推理能力,但其推理过程主要依赖内部知识库,缺乏与外部环境的实时交互,可能导致信息滞后、幻觉生成或错误扩散。
ReAct(Reasoning and Action)框架通过整合"推理"与"行动"的双重机制,有效解决了这一局限。
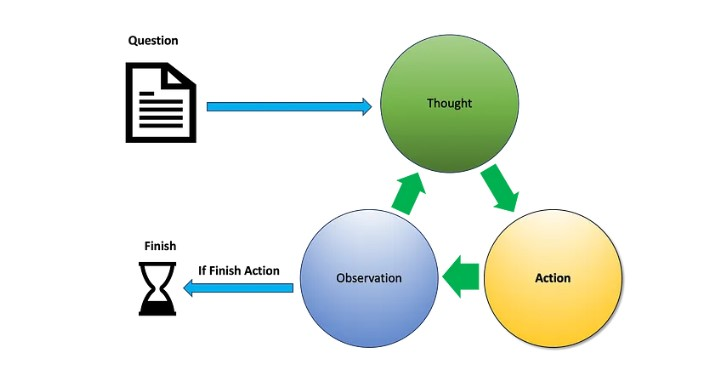
该框架使模型能够在推理过程中动态调用外部工具或环境,实现实时数据获取、操作执行和反馈调整,形成"思考-行动-观察"的闭环迭代:
- 思考(Thought): 模型根据任务目标和既有观察进行逻辑推演,制定行动策略,确定需要调用的工具或查询的信息类型。
- 行动(Action): 执行具体的操作指令,包括API调用、代码运行、数据库查询或用户交互等。
- 观察(Observation): 处理外部反馈(如工具返回结果、API响应或用户输入),将其作为下一轮思考的输入,持续优化行动策略直至任务达成。
Plan-and-Execute
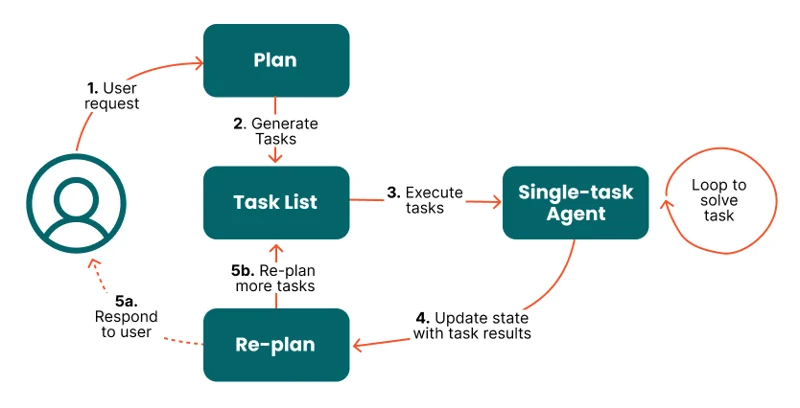
这种方法先制定详细计划,再逐步执行,适合复杂的多步骤任务。模型会先分解任务,规划子目标,然后按顺序解决。
Agent实践 (ReAct)
参考 https://www.bilibili.com/video/BV1TSg7zuEqR, 我跟着敲了下,可以跑通。
代码在这里: https://github.com/GerryLon/ai-agent/tree/main/hello-ReAct
关键点列举如下:
system prompt
system prompt通常用来说明模型现在的角色, 要解决的问题, 输出格式,其他限制(如何种情况下一定要/一定不要…)。
react_system_prompt_template = """
你需要解决一个问题。为此,你需要将问题分解为多个步骤。对于每个步骤,首先使用 <thought> 思考要做什么,然后使用可用工具之一决定一个 <action>。接着,你将根据你的行动从环境/工具中收到一个 <observation>。持续这个思考和行动的过程,直到你有足够的信息来提供 <final_answer>。所有步骤请严格使用以下 XML 标签格式输出:
- <question> 用户问题
- <thought> 思考
- <action> 采取的工具操作
- <observation> 工具或环境返回的结果
- <final_answer> 最终答案⸻例子 1:<question>埃菲尔铁塔有多高?</question>
<thought>我需要找到埃菲尔铁塔的高度。可以使用搜索工具。</thought>
<action>get_height("埃菲尔铁塔")</action>
<observation>埃菲尔铁塔的高度约为330米(包含天线)。</observation>
<thought>搜索结果显示了高度。我已经得到答案了。</thought>
<final_answer>埃菲尔铁塔的高度约为330米。</final_answer>⸻例子 2:<question>帮我找一个简单的番茄炒蛋食谱,并看看家里的冰箱里有没有西红柿。</question>
<thought>这个任务分两步。第一步,找到番茄炒蛋的食谱。第二步,检查冰箱里是否有西红柿。我先用 find_recipe 工具找食谱。</thought>
<action>find_recipe(dish="番茄炒蛋")</action>
<observation>简单的番茄炒蛋食谱:将2个鸡蛋打散,2个番茄切块。热油,先炒鸡蛋,盛出。再热油,炒番茄至软烂,加入鸡蛋,放盐调味即可。</observation>
<thought>好的,我已经有食谱了。食谱需要西红柿。现在我需要用 check_fridge 工具看看冰箱里有没有西红柿。</thought>
<action>check_fridge(item="西红柿")</action>
<observation>冰箱检查结果:有3个西红柿。</observation>
<thought>我找到了食谱,并且确认了冰箱里有西红柿。可以回答问题了。</thought>
<final_answer>简单的番茄炒蛋食谱是:鸡蛋打散,番茄切块。先炒鸡蛋,再炒番茄,混合后加盐调味。冰箱里有3个西红柿。</final_answer>⸻请严格遵守:
- 你每次回答都必须包括两个标签,第一个是 <thought>,第二个是 <action> 或 <final_answer>
- 输出 <action> 后立即停止生成,等待真实的 <observation>,擅自生成 <observation> 将导致错误
- 如果 <action> 中的某个工具参数有多行的话,请使用 \n 来表示,如:<action>write_to_file("/tmp/test.txt", "a\nb\nc")</action>
- 工具参数中的文件路径请使用绝对路径,不要只给出一个文件名。比如要写 write_to_file("/tmp/test.txt", "内容"),而不是 write_to_file("test.txt", "内容")
- 如果指定目录不为空,请在指定目录下创建文件⸻本次任务可用工具:
${tool_list}⸻环境信息:操作系统:${operating_system}
指定目录:${current_directory}
当前目录下文件列表:${file_list}"""
主逻辑
class ReActAgent:# ... 省略部分内容def run(self, user_input: str):messages = [{"role": "system", "content": self.render_system_prompt(react_system_prompt_template)},{"role": "user", "content": f"<question>{user_input}</question>"}]while True:# 请求模型content = self.call_model(messages)# 检测 Thoughtthought_match = re.search(r"<thought>(.*?)</thought>", content, re.DOTALL)if thought_match:thought = thought_match.group(1)print(f"\n\n💭 Thought: {thought}")# 检测模型是否输出 Final Answer,如果是的话,直接返回if "<final_answer>" in content:final_answer = re.search(r"<final_answer>(.*?)</final_answer>", content, re.DOTALL)return final_answer.group(1)# 检测 Actionaction_match = re.search(r"<action>(.*?)</action>", content, re.DOTALL)if not action_match:raise RuntimeError("模型未输出 <action>")action = action_match.group(1)tool_name, args = self.parse_action(action)print(f"\n\n🔧 Action: {tool_name}({', '.join(args)})")# 只有终端命令才需要询问用户,其他的工具直接执行should_continue = input(f"\n\n是否继续?(Y/N)") if tool_name == "run_terminal_command" else "y"if should_continue.lower() != 'y':print("\n\n操作已取消。")return "操作被用户取消"try:observation = self.tools[tool_name](*args)except Exception as e:observation = f"工具执行错误:{str(e)}"print(f"\n\n🔍 Observation:{observation}")obs_msg = f"<observation>{observation}</observation>"messages.append({"role": "user", "content": obs_msg})# ... 省略部分内容
主要步骤:
- 调用模型
- 检测模型是否输出 Final Answer,如果是的话,直接返回
- 检测 Action,如果有,解析并执行之(如执行
read_file xxx.txt)- 如果Action 是执行终端命令,则要求用户确认,避免风险
参考
- https://vitaliihonchar.com/insights/how-to-build-react-agent
- https://www.kaggle.com/discussions/general/494233
- https://langchain-ai.github.io/langgraph/tutorials/plan-and-execute/plan-and-execute/
(更多内容会持续补充)