降噪算法的效果分析
文章目录
- 1. 写在最前面
- 2. 算法分析方向
- 2.1 信噪比概念
- 2.1.1 学术概念
- 2.1.2 举例应用
- 2.2 频谱分析
- 2.2.1 学术概念
- 2.2.2 举例应用
- 2.2.3 深入思考一下
- 2.3 时域特征分析
- 2.3.1 学术概念
- 2.3.2 举例应用
- 2.4 VAD 检测
- 2.4.1 学术概念
- 2.4.2 举例应用
- 3. 碎碎念
1. 写在最前面
最近在给一个新服务做客户支持,然后支持过程中有很多关于「背景降噪效果」的分析需求,比如客户在嘈杂的环境中说了一段话,业务能够对其有效的降噪。当前这类问题的分析有个比较痛苦的点,是需要:
-
先听一下原始音频
-
再听一下背景降噪后的音频
然后对比两端音频,感受一下降噪后的音频是否符合预期。
注:总觉得这种分析的方式,略反人类,因为人类是会受情绪波动影响的,无法 100% 保持客观理性。
专业的事情交给专业的人来做,算法效果好坏,应该已经有相对成熟的方法,来试试 AI 评估一个算法落地好坏的思路如何。
2. 算法分析方向
AI 在如下几个方向组合的分析建议:
-
信噪比分析
-
频谱分析
-
时域特征分析
-
VAD 活动检查
注:无一例外,笔者对上述的概念都不懂,但是好处是 AI 确实省去了部分搜索分析的前置工作,可以一击即中的命中分析的核心点
不懂的坏处只是当下不懂,但是不懂装懂的坏处是以为自己懂了,然后永远不认真学习,所以永远都不懂,所以做人还是得虚心,希望自己永远做一个勇于承认自己不懂的大人。
以下是分析的图表数据,但是由于很多属于不懂,还是得学习一下。
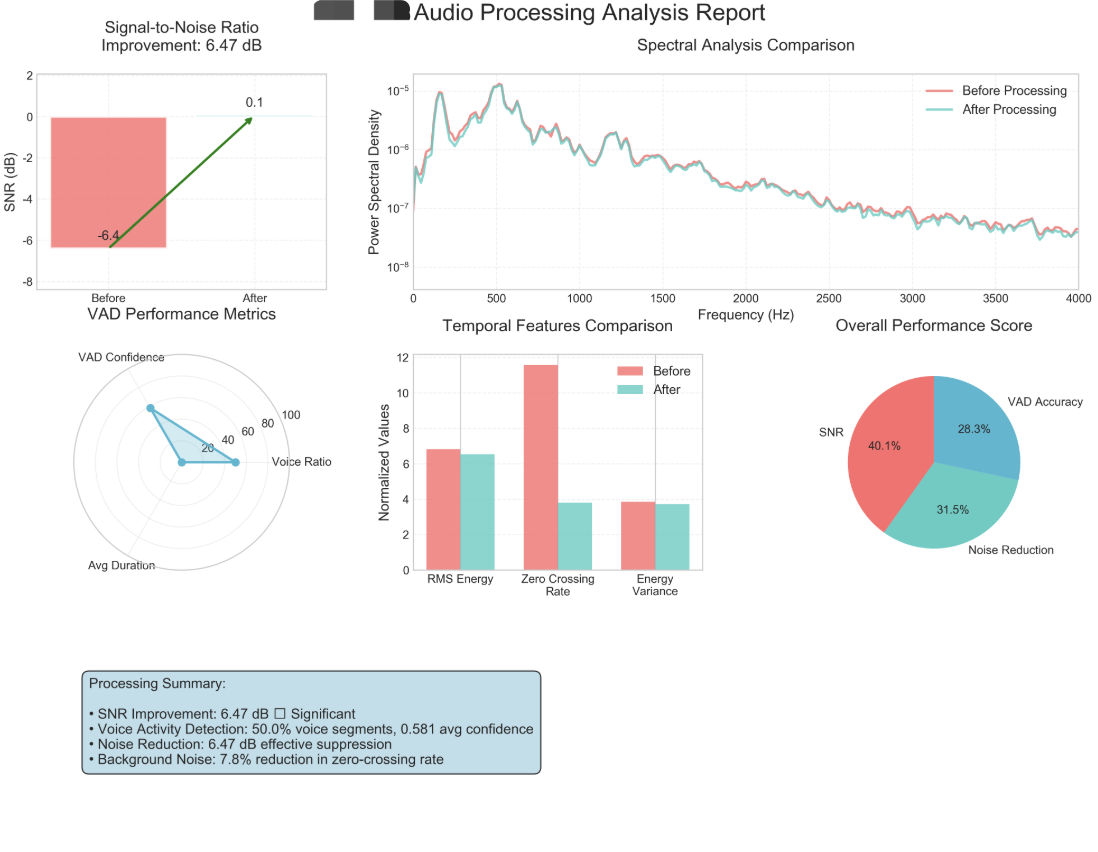
2.1 信噪比概念
2.1.1 学术概念
信噪比:(Signal-to-Noise Ratio,简称SNR)信号功率与噪声功率的比值,以分贝(dB)表示
SNR = 10 * log10(信号功率 / 噪声功率)
注:算法让人望而却步的原因之一可能就是其中掺杂了太多的数学概念和公式,但是不怕,可以现将其转换为容易理解的生活概念在理解。
2.1.2 举例应用
信噪比就像是在嘈杂的餐厅里听朋友说话的能力。
信号(Signal):你想要听到的声音,比如朋友的话语
噪声(Noise):你不想要的干扰声音,比如餐厅里其他人的谈话声、餐具碰撞声等
举例:
-
信噪比高 = 听得很清楚:即朋友说话声很清楚(信号强) & 周围很安静(噪声小)
-
信噪比低 = 听不清楚,需要大声喊:即朋友说话声被掩盖(信号相对弱)& 周围很吵闹(噪声大)
简单总结:信噪比通常用分贝(dB)表示:
-
高信噪比(比如30dB以上)= 信号很清晰
-
低信噪比(比如10dB以下)= 信号模糊不清
2.2 频谱分析
2.2.1 学术概念
频谱分析:(Spectrum Analysis)是信号处理领域的核心技术,用于将时域信号转换到频域,分析信号在不同频率成分上的分布特性。
-
时域信号:是以时间为自变量的信号表示方法,描述信号幅度随时间的变化关系。
-
频域信号:是以频率为自变量的信号表示方法,描述信号在不同频率成分上的分布。
2.2.2 举例应用
-
音乐的例子
-
时域视角:
-
就像听一首歌,你听到的是声音随时间的变化
-
能感受到音乐的节奏、强弱变化
-
但很难分辨具体有哪些乐器
-
-
频域视角:
-
就像看乐谱或调音台的均衡器
-
能清楚看到有钢琴(低频)、小提琴(中频)、笛子(高频)
-
每种乐器的音量大小一目了然
-
-
-
彩虹的例子
-
时域:看到白光随时间闪烁
-
频域:用三棱镜分解白光,看到红橙黄绿蓝靛紫各种颜色成分
-
时域和频域是同一个信号的两种不同表示方法:
-
时域:告诉我们「什么时候发生了什么」
-
频域:告诉我们「信号由哪些频率成分组成」
2.2.3 深入思考一下
虽然上述的说明解释了一部分,但是笔者还是没有更清晰,对于频谱好坏的判断,那就只能让 AI 再进一步的给我解释一下了!
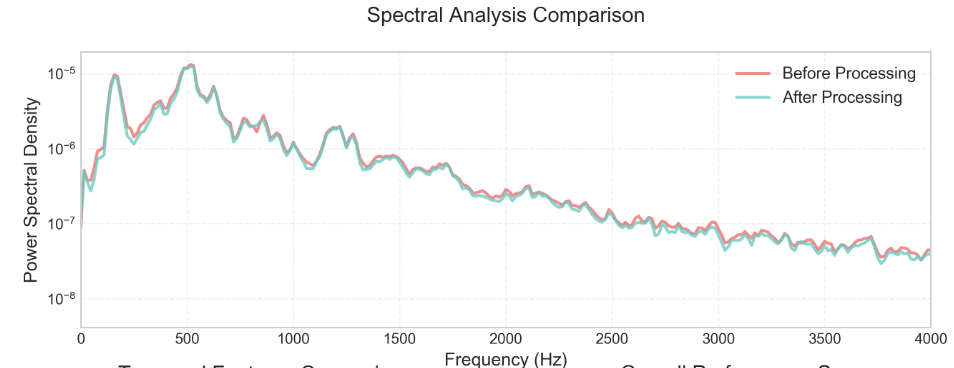
频谱的横轴和纵轴含义理解:
横轴(X轴)- 频率
-
表示内容:频率(Frequency)
-
单位:赫兹(Hz)或千赫兹(kHz)
-
含义:表示音频信号中不同频率成分的分布
-
范围:通常从0 Hz开始,上限取决于采样率(根据奈奎斯特定理,最高频率为采样率的一半)
纵轴(Y轴)- 幅度/功率
-
表示内容:幅度(Amplitude)或功率(Power)
-
单位:
-
线性刻度:通常是相对单位或归一化值
-
对数刻度:分贝(dB)
-
含义:表示每个频率成分的强度或能量大小
再将其套入到生活中更通俗的理解,想象一架钢琴:
频率【x 轴】 = 音调种类(钢琴的不同琴键)
振幅【Y 轴】= 每种音调的强度(每个琴键按得多用力)
音频处理:
-
保持了所有"琴键"(频率成分)
-
只是把某些琴键按得轻了一点
-
整首"曲子"(语音)还是完整的,但更悦耳了
2.3 时域特征分析
2.3.1 学术概念
时域特征分析:(Time-Domain Feature Analysis)是指在时间域内对信号或数据序列进行特征提取和分析的方法。它直接从原始时间序列数据中提取能够反映信号本质特性的统计量和描述符。
常用的特征分析维度:
-
统计特征
-
均值(Mean):信号的平均水平
-
方差(Variance):信号的离散程度
-
标准差(Standard Deviation):信号波动的标准化度量
-
偏度(Skewness):信号分布的不对称性
-
峰度(Kurtosis):信号分布的尖锐程度
-
-
幅度特征
-
最大值/最小值:信号的极值
-
峰峰值(Peak-to-Peak):最大值与最小值的差
-
RMS(Root Mean Square):信号的有效值
-
波峰因子(Crest Factor):峰值与RMS的比值
-
-
形状特征
-
过零率(Zero Crossing Rate):信号穿越零点的频率
-
能量(Energy):信号的总能量
-
功率(Power):单位时间内的平均能量
-
2.3.2 举例应用
时域特征的分析维度有很多,下面以常用的三个举例说明:
-
RMS Energy(均方根能量)- “声音的音量大小”
-
Zero Crossing Rate(过零率)- “声音的粗糙程度”
-
Energy Variance(能量方差)- “声音的稳定程度”
用做菜来比喻:
-
RMS Energy:菜的分量(没有减少,还稍微多了点)
-
Zero Crossing Rate:菜的口感(从粗糙变光滑了)
-
Energy Variance:火候控制(从忽大忽小变成火候均匀)
一句话总结:就像把一段嘈杂不清的录音变成了广播级别的清晰音质!
2.4 VAD 检测
2.4.1 学术概念
VAD: Voice Activity Detection (VAD) 是一种信号处理技术,用于检测音频信号中是否包含人类语音活动。VAD的核心目标是区分音频流中的语音段和非语音段(如静音、噪声、音乐等)。
2.4.2 举例应用
-
场景描述:
- 用户在开会时,系统需要自动检测谁在说话
-
VAD工作流程:
-
输入:连续的音频流
-
处理:实时分析音频特征
-
输出:语音/非语音标签
-
-
具体例子:
-
时间轴:0-2秒 静音(背景噪声) → VAD输出:0(无语音)
-
时间轴:2-5秒 “大家好,我是…” → VAD输出:1(有语音)
-
时间轴:5-7秒 静音(思考停顿) → VAD输出:0(无语音)
-
用一句话总结VAD:就像一个"声音判断者",专门负责判断:“现在有没有人在说话?”
-
为什么需要VAD?省电省流量,没人说话时,设备可以"偷懒" & 不用一直全速工作
-
提高准确性:只处理真正的语音 & 避免把咳嗽、音乐当成说话
-
反应更快:知道什么时候开始听 & 知道什么时候停止听
3. 碎碎念
生活中遇到讨厌的人如果一直跟他较劲、过不去似乎不是最好的处理方式,更好的处理方式是将愤怒的情绪用于学习,然后远离那些让自己讨厌的人,笔者周六学习的动力也大概来源于此了。今日份学习就先到这里吧,我要享受假期啦!
-
不要取悦谁,不要委屈自己,不要被别人牵着鼻子走,不要表演,也不要迎合别人的表演,不要在消极的情绪里自我拉扯,也不要在妄想中自我沉醉,更不要与自己处处为敌。
-
人活着就难免会遇到不公、误解,会被批评、指责,以及无端揣测。遇到了,别回应,别解释,别自责,别纠缠,要学会无视,要直接拉黑,要趁早远离,要把宝贵的时间和精力用在做好眼前的事、过好眼前的生活、哄自己开心和努力搞钱上。