Rethinking SSIM-Based Optimization in Neural Field Training
重新思考神经场训练中基于SSIM的优化
摘要
结构相似性(SSIM)指数是一种广泛使用的图像质量评估指标,在图像恢复、三维重建和新视图合成等领域有着广泛的应用。许多先前的研究工作已经将基于SSIM的优化引入神经场训练中,以提升模型的性能。尽管SSIM被广泛使用,但关于如何有效地将SSIM损失纳入训练过程的研究却相对较少。在本研究中,我们探索了这一空白,并提供了SSIM损失在神经场训练中作用的见解。我们的关键发现是,SSIM损失在训练的早期阶段特别有益,即在模型完全学习到亮度信息之前。我们表明,在初始训练阶段,SSIM损失是一种有效的“引导”机制,而在模型学习到亮度信息之后将其移除并不会损害最终性能——事实上,它可能会提升性能。我们的实验验证了我们策略的有效性,为SSIM损失在神经场训练中的更高效使用提供了新的见解。我们相信,这些发现不仅将增强SSIM在神经场训练中的应用,还将激发对深度学习模型中更自适应损失函数的进一步研究。
I. INTRODUCTION
隐式神经表示(INRs)作为一种强大的方法,通过学习将输入坐标映射到信号值的连续函数来表示复杂信号,已经得到了广泛的应用,例如2D图像拟合[1]、[2]、[3]、[4],3D场景重建[5]、[6]、[7]等,显示了其重要的影响。
结构相似性(SSIM)指数[14]、[15]是评估高质量重建的关键组成部分,这是一种通常用于评估图像质量的感知度量。与传统的像素级度量(如均方误差MSE)不同,SSIM通过比较图像之间的亮度、对比度和结构相似性来关注结构信息的保持。鉴于其能够更好地反映人类对图像质量的感知,基于SSIM的优化已广泛应用于图像恢复[16]、[17],去噪[18]、[19]以及3D重建任务[20]、[21]、[22]。通常,基于SSIM的优化涉及最小化(1 - SSIM)以改善预测图像和参考图像之间的结构对齐;一些工作[23]、[24]、[25]、[26]提出了不同的修改。
在最近的发展中,基于SSIM的优化已被纳入隐式神经表示(INRs)[10]、[7]、[27]中,以增强所学表示的结构保真度。然而,尽管采用了这种方法,但在训练过程中对SSIM损失的最优使用仍缺乏了解。大多数现有方法在整个训练过程中均匀地应用SSIM损失,而没有考虑其在模型学习的不同阶段的不同影响。
我们的研究旨在通过深入分析如何在神经场训练过程中更有效地使用SSIM损失来填补这一空白。我们发现了一个关键的见解:在训练的早期阶段,当模型尚未完全学会重建目标信号的亮度时,SSIM损失特别有用。在这个阶段,SSIM起到了引导机制的作用,帮助模型在过度拟合亮度细节之前优先考虑结构信息。一旦模型充分学会了整体亮度(即亮度收敛之后),继续使用SSIM损失的效果就会减弱,而且在某些情况下,它甚至会阻碍进一步的改进。我们的实验表明,在这一点之后移除SSIM损失不仅可以保持最终性能,还可以通过防止模型以牺牲其他重要特征为代价过度强调结构相似性,从而增强最终性能。

(a)使用TensoRF [9]对副本数据集[8]的场景1进行新颖的视图合成。我们使用如[10]中的训练配置,并在测试集上比较PSNR。“在迭代 70 时删除”的性能接近“w/”。 w/o PSNR 65.42 在迭代 30 时删除 PSNR 68.37 在迭代 30 时删除

(b)使用SIREN [12]对DIV2K的单张图像[11]进行二维图像回归。我们使用如[13]中的训练配置,并在测试集上比较PSNR。“在迭代 70 时删除”比“w/”产生更好的性能。
图1:结构相似性(SSIM)损失与神经场训练中的“引导”机制很好地配对。当学习了亮度后,消除 SSIM 损耗不会影响最终性能,甚至可能提高最终性能。“w/o”:训练过程中不使用 SSIM 丢失;“remove at iteration M ”:SSIM 损失在训练开始时应用,但在迭代 M 时删除;w/“:SSIM 损失在整个训练过程中应用。
以图1a中的实验为例,所有这些实验都运行了30K次迭代。当在整个训练过程中使用SSIM损失时,PSNR为37.12 dB;而在第70次迭代时移除SSIM损失也可以达到36.93 dB,对最终性能几乎没有影响。在图1b中,对于使用SIREN [1]的2D图像回归任务,我们比较了在前3000次迭代期间获得的最高PSNR。结果显示,某种操作(“在第70次迭代时移除”)得到了更好的结果(PSNR 110.35 dB),相比之下,“w/”(PSNR 46.78 dB);在整个训练过程中优化SSIM损失并没有为模型训练带来显著的好处;相反,它可能会在一定程度上对模型的性能产生不利影响。换句话说,SSIM损失与“引导”机制很搭配,不会对最终性能产生负面影响,甚至可能增强它。
我们通过在Kodak [28]和DIV2K [11]数据集上进行一系列实验来验证这一机制,证明我们战略性地将SSIM损失作为早期阶段的引导,可以显著改善神经场训练。我们相信这些发现不仅将增强SSIM在INRs中的应用,还将激发对深度学习模型中更自适应损失函数的进一步研究。
II. Related Work
A. Implicit Neural Representation
隐式神经表示(INRs)在神经场景表示中起着关键作用,利用多层感知器(MLPs)来编码将坐标映射到信号(如图像[12]、[4]、[2]、[3],视频[29]、[30]以及3D场景[5]、[31]、[32]、[33])的连续函数。一些工作直接将坐标作为输入传递给多层感知器(MLPs),以拟合目标信号,例如3D形状的符号距离场(SDF)[6]。然而,这些方法在捕捉目标信号中的高频细节方面存在困难,这导致了在各种应用中的性能降低和效果减弱。为了应对这一问题,人们提出了不同的方法。例如,NeRF [5]引入了位置编码来处理输入,以重建场景的辐射场。同样,SIREN [1]使用周期性激活函数,使MLPs能够更有效地表示高频细节,而RFF [34]则采用傅里叶特征映射来处理点。此外,在[35]、[2]、[4]中还进一步探索了与其他编码方案相关的研究,如伽伯小波、傅里叶或伽伯或径向基函数等。然而,与我们的工作不同,这些研究主要集中在探索更好的性能编码方法上。
B. SSIM-Related Optimization
与基于像素的优化(例如使用均方误差或交叉熵损失)不同,基于SSIM的优化倾向于将结构信息纳入过程中,捕捉空间依赖性,而不仅仅是关注单个像素的差异。一些先前的研究已经将基于SSIM的优化应用于各种任务中,以增强感知到的图像和视频质量,包括图像去噪[36]、[18]、[19],均衡器设计[37],图像恢复[16]、[17],率失真优化[38]、[39],图像分割[40],深度估计[20],图像融合[21]、[41],去雨[42],图像生成[22]。最近,随着新视图合成任务的发展,SSIM基础的优化也被各种工作采用,包括NeRF系列[10]、[43]和3DGS系列[7]、[44]、[45]。S3IM [10]将结构相似性损失引入NeRF训练过程,以挖掘随机渲染图像中的非局部信息,显示出卓越的性能提升。PlaNeRF [43]提出使用块SSIM损失来初始化所学体积表示的几何形状,从而提高渲染质量。3DGS [7]及其变体[44]、[45]也将SSIM损失纳入训练过程,以提高新视图图像的质量,在自动驾驶中发挥着重要作用。
此外,一些工作已经将基于SSIM的优化扩展到使其适合特定应用。LWSSIM [23]通过用加法代替亮度乘法,并在不同滤波器尺寸上计算加权平均值,为卷积自编码器引入了层次加权结构相似性损失。[24]使用SSIM的重要组成部分构建了一系列归一化和广义(向量值)度量。为了实现更平滑的梯度,[25]使用加法而不是乘法来组合SSIM中的亮度、对比度和结构相似性相关组件,以在无监督深度估计中实现更高性能。[26]提出了一种强调对比度的增强型SSIM损失函数,通过突出预测深度和真实深度之间的对比度来改进学习过程。然而,上述工作主要关注SSIM损失的直接应用或对其公式的修改。很少有研究探讨如何在神经场训练过程中有效地整合SSIM损失,以增强模型的性能,而不改变其公式。
III. Background
A. Structural Similarity Index and the Loss
结构相似性(SSIM)指数[14]、[15]被广泛用于评估生成图像的质量,通过考虑三个关键组成部分来捕捉图像的感知质量:亮度相似性( l )、对比度相似性( c )和结构相似性( s )。给定成对的图像( X )和( Y ),其中( X )表示真实图像,( Y )表示预测图像。我们从( X )和( Y )中对应的空间位置提取大小为( )的图像块,将这些提取的块分别表示为列向量( x )和( y )。我们用(
)和(
)表示( x )和( y )的均值,用(
)和(
)表示( x )和( y )的方差,用(
)表示( x )与( y )的协方差。
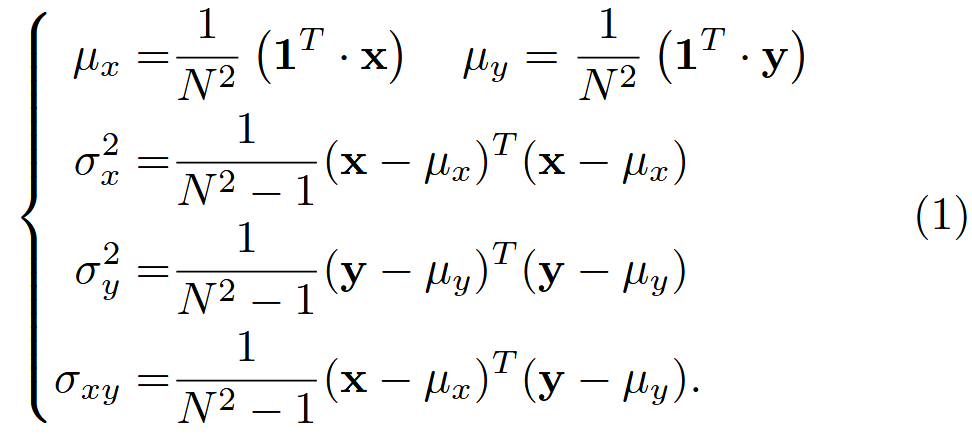
为了简化,设 ,
,
,
,
,
,然后我们可以得到SSIM(x,y)如下所示:
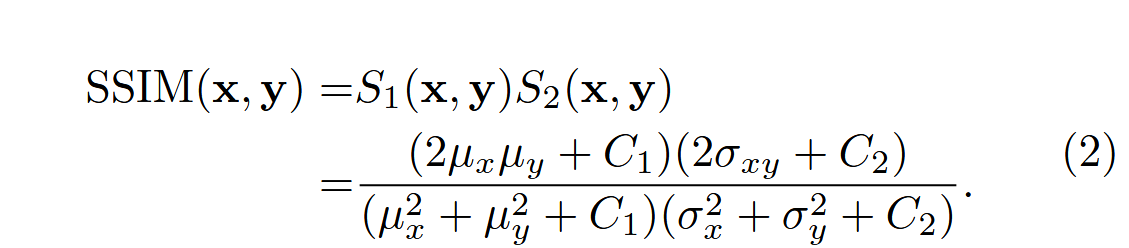
相应地,结构相似性损失(SSIM损失)可以表述为:
![]()
SSIM损失通常与均方误差损失以特定的权重
结合:
![]()
这种组合在不同的任务中被广泛使用。
B. Implicit Neural Representations
一般来说,隐式神经表示函数可以表示为 ,将
维坐标映射到
维输出
,其中
是多层感知器(MLP)的参数。给定
表示对特定信号
的一个操作,神经场参数使得
能够近似
。恒等映射
意味着
将坐标映射到像素值。
IV. SSIM损失在神经场训练中的作用
在本节中,我们专注于探索如何有效地整合SSIM损失以及它在神经场训练中的作用。首先,我们介绍一个关键发现,即SSIM损失在神经场训练的早期阶段起着至关重要的作用;随后,我们展示这一现象与模型是否已经完全学习到亮度信息密切相关;之后,我们讨论SSIM损失在不同训练阶段的作用。
A. Experimental Setup
2D图像回归。这项任务涉及学习一个2D函数 F ,该函数将2D像素坐标映射到颜色值。在本文中,我们主要遵循[13]中的实验,该实验引入了有效的数据转换以加速神经场训练。具体来说,我们使用随机像素排列(RPP)进行数据增强实验,这是基于在不同算法中观察到的RPP带来的显著改进;随机像素排列(RPP)数据增强涉及在图像内打乱像素的位置。
为了评估性能,我们采用了[13]中提出的成本(cost)和准确度(acc)指标。 被定义为达到目标训练PSNR(峰值信噪比)M dB所需的SGD(随机梯度下降)步骤数。因此,我们可以通过方程5获得相应的加速因子,

这里,代表在恒等图像上训练的成本,而
指的是使用各种操作(例如应用于图像的数据转换)进行训练的成本。
我们主要在Kodak数据集[28]和DIV2K验证集[11]上进行相应的实验。图像的处理方法遵循[13]中的描述。在训练过程中,批量大小设置为218。对于每张(转换后的)图像,我们根据[13]的建议调整学习率,目的是搜索可能的参数配置以最小化运行时间。
神经辐射场学习:新视角合成是一项基本任务,它涉及根据一组捕获的输入图像,从未捕获的视角渲染场景的真实图像。作为隐式神经表示的关键应用,NeRFs[46]在解决这一任务方面展示了强大的能力。在本文中,我们遵循S3IM[10]并选择加速的NeRF变体,TensoRF[9]和DVGO[47]进行实验。在训练期间,我们保持与他们原始论文相同的训练配置。我们主要使用具有挑战性的Replica数据集[8]作为性能评估的基准。Replica数据集包含8个真实世界的大规模室内场景,只有少量的训练图像。可以使用几种指标进行性能评估,如峰值信噪比(PSNR)、结构相似性指数(SSIM)[48]和学习感知图像块相似性(LPIPS)[49]。
B. SSIM Loss is Particularly Beneficial in the Early Training Phase
二维图像回归
遵循[13],我们使用SIREN[12]来拟合来自DIV2K数据集的单张图像,应用随机像素排列(RPP)进行数据转换,遵循他们的配置,同时在不同的迭代中通过添加或移除SSIM损失来修改它。具体来说,“添加”意味着我们在不使用SSIM损失的情况下开始网络训练,然后在特定的迭代中引入它。相反,“移除”意味着我们开始时与SSIM损失一起训练,但在某个迭代中将其移除。
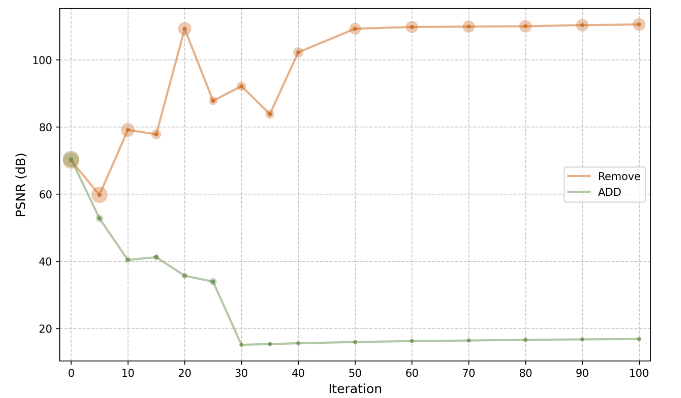
(a)使用SIREN对单个DIV2K图像进行二维图像回归。每个点的半径表示获得最高PSNR的训练迭代。
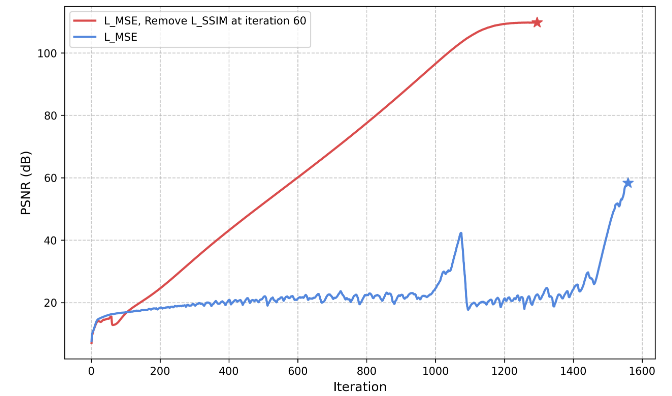
(b)使用具有不同损失配置的SIREN对单个DIV2K图像进行二维图像回归。蓝线表示在训练过程中仅应用 MSE 损失。红线表示SSIM损失在开始时使用,在迭代60时删除。性能比较:迭代 1295 (PSNR 109 dB) 与迭代 1560 (PSNR 58 dB)
(c)使用TensoRF对副本数据集场景1进行新颖的视图合成。所有实验均进行了 30k 次迭代
图2:SSIM损失在早期训练阶段至关重要。橙色线表示最初采用SSIM损失但在特定迭代时被删除的实验结果,而绿线表示SSIM损失在开始时未使用,但在指定迭代时引入训练过程的实验结果
如图2a和2b所示,在某些迭代中从训练过程中移除SSIM损失可以使优化“更快”和“更好”。例如,当在迭代60时移除SSIM损失时,PSNR在迭代1295时达到大约109 dB。相比之下,在某些迭代中将SSIM损失添加到训练过程中可能会损害性能;似乎网络的某些属性已经建立,添加SSIM损失可能不再提供显著的正向改进。基于图2a中呈现的实验比较,在整个训练阶段使用SSIM损失并没有带来性能的提升,这表明使用SSIM损失的方式可能对于最大化其益处至关重要。此外,如图2b所示,与仅依赖整个训练过程中的MSE损失相比,额外使用SSIM损失并在迭代60时移除它有助于神经场参数快速找到一个更好的“线性快车道”,从而实现更高的性能。
神经辐射场学习
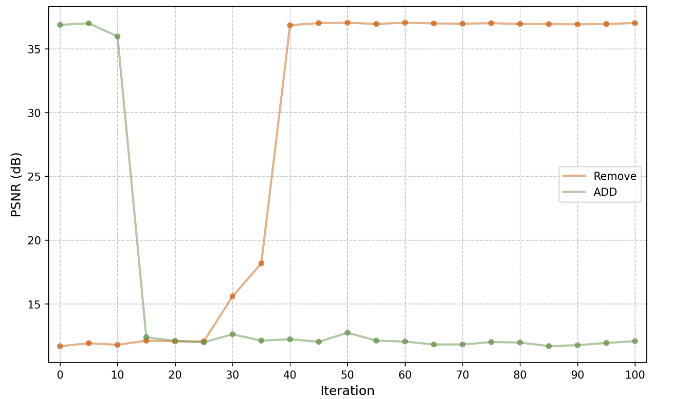
此外,在神经辐射场学习中也存在类似的现象。按照[10]的方法,我们在Replica数据集的场景1上使用TensoRF进行实验,保持与他们原始论文相同的实验设置。每次实验运行30k次迭代,并观察相应的测试集PSNR。在这里,“添加”和“移除”对应于之前定义的相同术语。如图2c所示,从“添加”的角度来看,如果在早期训练阶段添加SSIM损失,测试集PSNR可以达到大约37.0 dB;在经过一个特定的迭代范围后,无论是否使用SSIM损失,测试集PSNR都会下降到大约12.0 dB。从“移除”的角度来看,如果在早期训练阶段移除SSIM损失,测试集PSNR大约为12.0 dB;在经过一个特定的迭代范围后,无论是否包含SSIM损失,测试集PSNR都能达到大约37.0 dB。这种现象也可以在Replica数据集的其他场景中使用TensoRF[9]和DVGO[47]观察到,如表I所示。
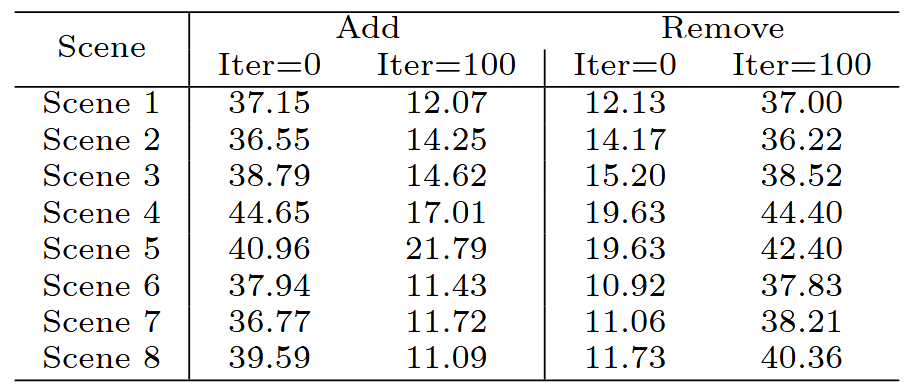
(a) 使用 TensoRF [9] 对 8 个 Scenes of Replica 数据集 [8] 进行实验
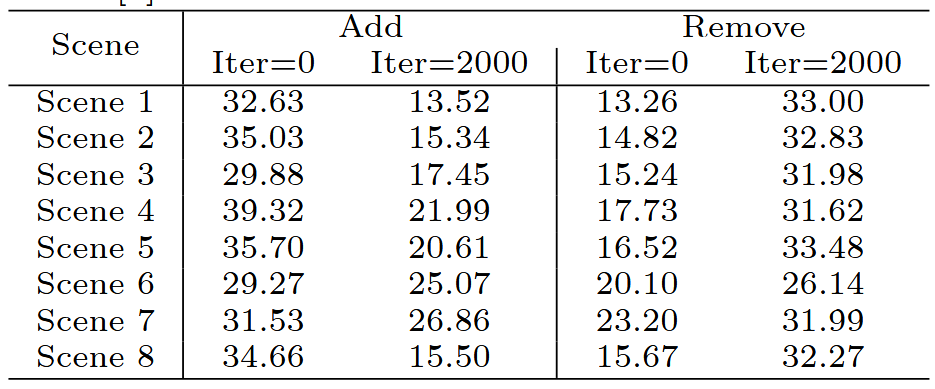
(b) 使用 DVGO 对 8 个 Scenes of Replica 数据集 [8] 进行实验 [47]
表一:SSIM丢失在早期训练阶段至关重要。使用TensoRF [9]和DVGO [47]对副本数据集进行实验
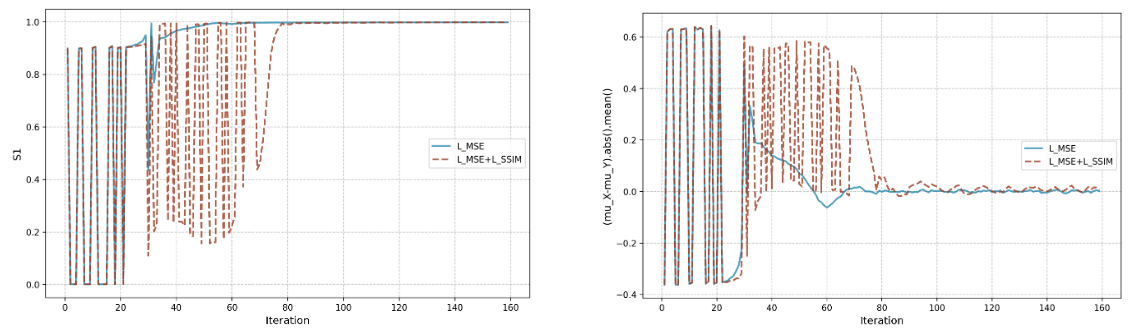
C. Convergence of Luminance
在IV-B小节的实验基础上,我们进一步分析了不同变量的收敛趋势,包括图的平均值、
图、
图等。我们发现
或
的收敛趋势与IV-B小节中描述的现象密切相关,如图3所示。结合图2可以看出:SSIM损失在训练过程中,在亮度收敛之前(即亮度收敛)起着至关重要的作用。通过比较仅使用
(蓝色曲线)与同时使用
和
(红色曲线)的训练过程,可以看出两种设置下的
曲线在相似的迭代次数下收敛。换句话说,尽管
的收敛迭代次数大致相同,但它们的收敛方式不同。此外,基于图2c中的实验,我们比较了在不同损失设置下测试集上的渲染结果,如图4所示,其中使用SSIM损失有助于在早期阶段捕捉对比模糊,而不是整体模糊效果。
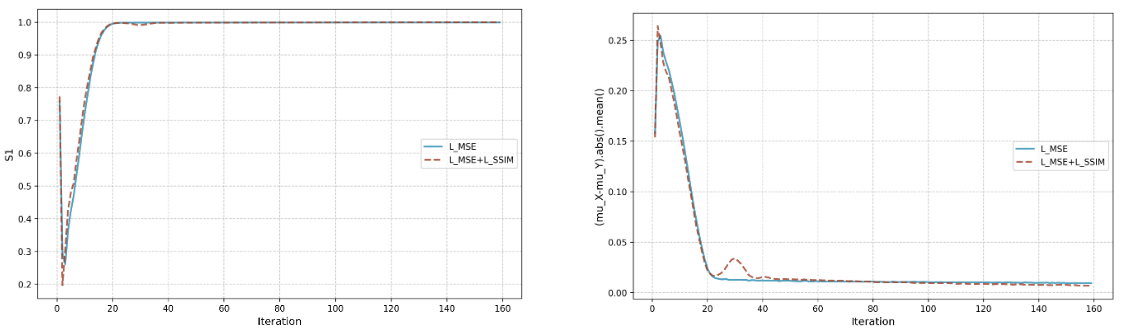
(b)使用SIREN对单个DIV2K图像进行二维图像回归实验时(μx−μy)的收敛曲线
(d)使用TensoRF在Replica数据集的场景1上进行新视图合成实验时(μx − μy)的收敛曲线
图3:神经场训练过程中S1和(μx−μy)的收敛曲线
D. SSIM Loss vs. Different Training Stages
我们将局部图像块中的 个元素视为一个组。基于第III-A节中对 x 和 y 的定义,我们可以获得方程3中结构相似性损失关于 y的导数 [50],记作
,如方程6中详细说明的(为了简化,我们对每个元素应用平均权重
)。
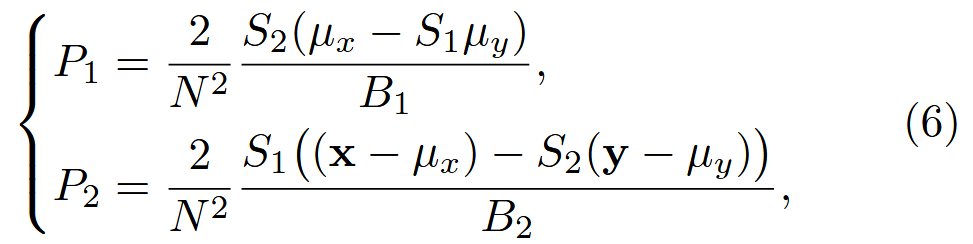
在方程6中,、
、
、
、x 和 y 本质上代表了该组的整体统计信息;我们可以将
、
、
、
视为调制因子。
反映了集体影响,这是组内所有元素都采用的。具体来说,
受到 x 和调制后的 y 之间差异的影响。相比之下,
展示了个体-集体影响;它受到
和调制后的
之间差异的影响。
早期阶段(亮度收敛之前的阶段):根据方程6,当亮度尚未被学习,且 不接近1,x 和 y 之间存在误差时,
的影响不能被忽视。组内的每个元素在一定程度上都会受到
的相同影响,而
的影响将允许每个元素展现其独特的作用。
后期阶段(亮度收敛后的阶段):一旦亮度学习完成,接近1,
接近
;此时,
的影响减弱。与
相比,
的收敛速度较慢;在接下来的训练阶段中,
的影响力更大。
V. Experiments
基于上述分析,我们遵循[3]并在2D图像回归任务中使用RPP数据转换进行实验,并提出使用SSIM损失作为“引导”角色,称为“引导+RPP”。我们使用Kodak[28]和DIV2K[11]进行性能评估,和SGD步数可以根据数据集在引导机制中使用。


表 II:“引导 + RPP”使用 SIREN 实现 2D 图像回归的“更快”和“更高”性能
结果。我们重新运行他们的官方代码,并使用指标acc50、acc55和acc60比较表IIa中的加速因子;此外,我们还在表IIb中比较了实现目标PSNR所需的平均步数。“引导”机制提高了性能,使其在Kodak和DIV2K数据集上都“更快”和“更好”。随着目标PSNR的增加,我们的方法显示出更大的性能增益。当目标PSNR设置为60 dB时,Kodak数据集上的平均cost60为221.42,对于“引导+RPP”,而“RPP”为2786。相应地,acc60指标为1.55对比14.89。这可以归因于SSIM损失帮助找到“引导+RPP”中神经场参数空间的更好“线性表达”。

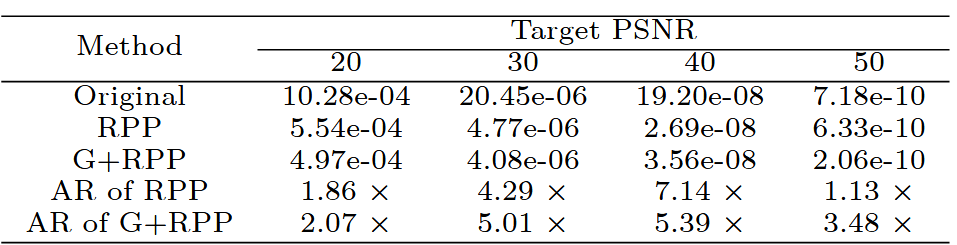
误差模式。图5显示了不同策略的误差图。“原始”表现出更厚的波纹模式,而“RPP”引入了细粒度噪声。“引导+RPP”呈现出结构化模式以及细粒度噪声。表III显示了不同方法在不同目标PSNR水平下的像素损失方差。与“RPP”相比,“引导+RPP”在PSNR 50 dB时导致较低的误差,尽管在PSNR 40 dB时显示出较高的误差;“引导+RPP”学习特定模式并找到更有效的方法,尽管在此过程中经历了暂时的误差增加,但最终导致改进的结果
VI. CONCLUSIONS
在这项工作中,我们研究了如何在神经场训练期间有效地使用SSIM损失,这使我们的方法与以往的SSIM相关优化方法有所区别。我们的关键发现是,在模型学习亮度之前的早期训练阶段,SSIM损失至关重要。我们揭示了这种损失与“引导”机制配合得很好,在亮度收敛之前应用SSIM损失,之后移除它不会损害最终性能,甚至可能提高性能。相应的实验证实了我们策略的有效性。我们相信这些发现将改善SSIM在图像复原(INRs)中的使用,并激发更多关于自适应损失函数的研究。