Large-scale CelebFaces Attributes (CelebA) 数据集生态:核心详解、免费下载与三大扩展应用全景
Large-scale CelebFaces Attributes (CelebA) Dataset

Sample Images

1. 前言
一、简介
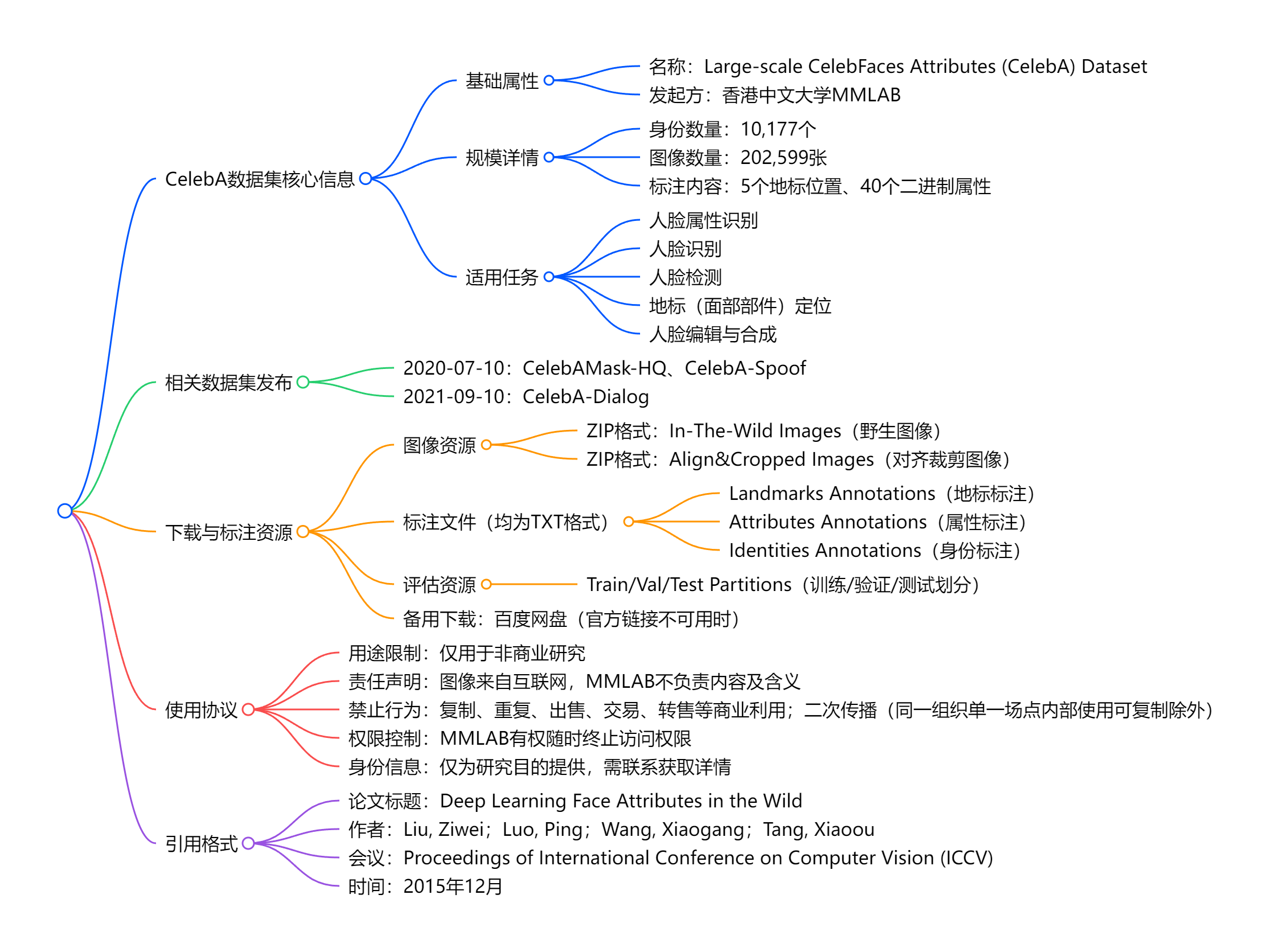
Large-scale CelebFaces Attributes (CelebA) Dataset 是由香港中文大学 MMLAB 推出的大型人脸属性数据集,包含202,599 张名人图像、10,177 个身份,每张图像标注了5 个地标位置和40 个二进制属性,图像涵盖大姿态变化与背景干扰,可用于人脸属性识别、人脸识别、人脸检测等计算机视觉任务;
| 类别 | 具体信息 | 数量 / 说明 |
|---|---|---|
| 身份覆盖 | 名人身份数量 | 10,177 个 |
| 图像规模 | 人脸图像总数 | 202,599 张 |
| 空间标注 | 面部关键点位置 | 5 个 (眼尖、嘴角、鼻尖) |
| 属性标注 | 图像属性标注类型 | 40 个二进制属性(如性别、是否微笑、是否戴眼镜等) |
| 图像特征 | 姿态与背景 | 涵盖大姿态变化、复杂背景干扰,更贴近真实场景 |
核心应用任务:
-
人脸属性识别:判断40种属性的存在与否。
-
人脸识别/验证:判断图像是否属于同一身份。
-
人脸检测与定位:基于关键点进行人脸及部件定位。
-
人脸编辑与合成:作为生成模型(如GANs)的训练数据,进行属性编辑。
后续于 2020 年 7 月发布相关数据集 CelebAMask-HQ 和 CelebA-Spoof,2021 年 9 月发布 CelebA-Dialog,数据集仅支持非商业研究使用,需引用论文《Deep Learning Face Attributes in the Wild》(ICCV 2015),若官方链接不可用可通过百度网盘下载。
-
CelebAMask-HQ (2020): 提供30,000张高分辨率图像的精细化19类语义分割掩码,专注于人脸解析与编辑。
-
CelebA-Spoof (2020): 大规模人脸活体检测数据集,包含超过62万张图像和丰富的反欺诈注解(如攻击类型、光照环境)。
-
CelebA-Dialog (2021): 创新性的视觉-语言对话数据集,将人脸图像与细粒度的编辑对话相关联,支持基于自然语言的交互式人脸编辑。
二、官网及下载地址
Celeb:https://mmlab.ie.cuhk.edu.hk/projects/CelebA.html
谷歌下载链接:https://drive.google.com/drive/folders/0B7EVK8r0v71pWEZsZE9oNnFzTm8?resourcekey=0-5BR16BdXnb8hVj6CNHKzLg&usp=sharing
百度下载链接(password: rp0s).:https://pan.baidu.com/s/1CRxxhoQ97A5qbsKO7iaAJg#list/path=%2F
2. 思维导图(mindmap)
3. 详细总结
一、数据集概述
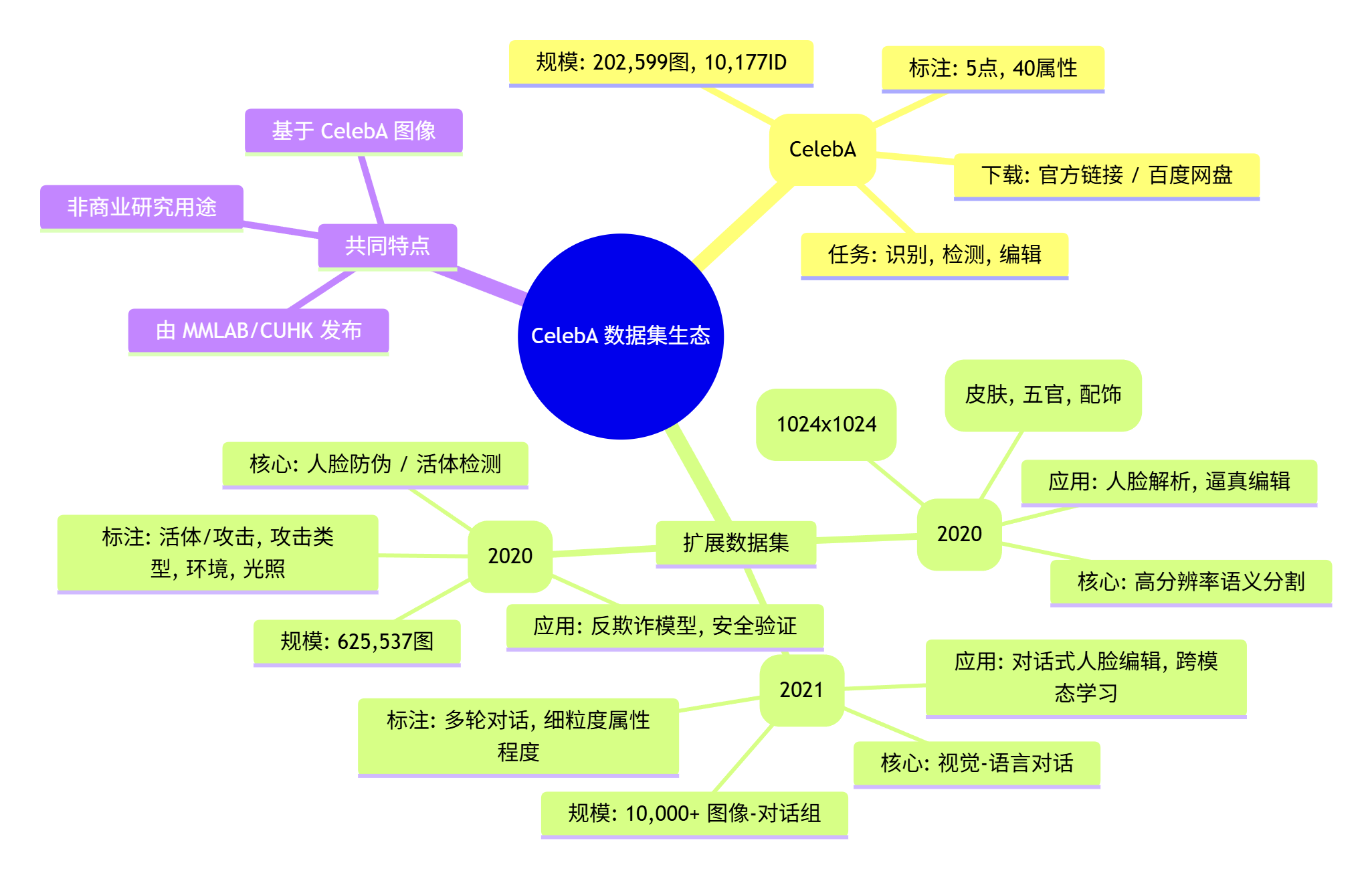
CelebA(Large-scale CelebFaces Attributes Dataset)是香港中文大学 MMLAB 构建的大型人脸属性数据集,核心特点为 “大多样性、大数量、丰富标注”,具体规模如下表所示:
| 类别 | 具体信息 | 数量 / 说明 |
|---|---|---|
| 身份覆盖 | 名人身份数量 | 10,177 个 |
| 图像规模 | 人脸图像总数 | 202,599 张 |
| 空间标注 | 面部地标位置数量 | 5 个 |
| 属性标注 | 图像属性标注类型 | 40 个二进制属性 |
| 图像特征 | 姿态与背景 | 涵盖大姿态变化、背景干扰 |
该数据集可作为训练集与测试集,支撑多种计算机视觉任务,包括:
- 人脸属性识别
- 人脸识别
- 人脸检测
- 地标(或面部部件)定位
- 人脸编辑与合成
二、相关数据集发布(News 板块)
MMLAB 后续基于 CelebA 扩展发布了多个相关数据集,具体信息如下:
- 2020 年 7 月 10 日:发布 2 个相关数据集 ——CelebAMask-HQ、CelebA-Spoof
- 2021 年 9 月 10 日:发布 1 个相关数据集 ——CelebA-Dialog
下表从核心定位、数据规模、标注内容、核心任务、关键特点及发布时间6 个维度,对 CelebAMask-HQ、CelebA-Spoof、CelebA-Dialog 三个扩展数据集进行全面对比:
| 对比维度 | CelebAMask-HQ | CelebA-Spoof | CelebA-Dialog |
|---|---|---|---|
| 核心定位 | 高分辨率人脸精细语义分割与编辑 | 人脸活体检测(反欺诈) | 人脸 - 多轮对话跨模态配对 |
| 数据规模 | 30,000 张 1024×1024 高分辨率人脸图像 | 500,000 + 张图像,覆盖 1,000 + 真实身份 | 10,000 + 组人脸 - 对话样本,含 50 + 轮对话 |
| 标注内容 | 19 类面部语义掩码(如头发、眼睛、嘴巴等)、人脸属性标签 | 活体 / 攻击二分类标签、攻击类型标签(如打印纸、电子屏、3D 模型)、光照 / 姿态标签 | 人脸身份标签、多轮对话文本、对话情感标签(如中性、开心、生气) |
| 核心任务 | 人脸语义分割、人脸编辑(如换发型、改妆容)、人脸生成 | 人脸活体检测(区分真实人脸与伪造攻击)、跨场景欺诈检测 | 视觉 - 语言跨模态检索、对话情感分析、人脸 - 对话关联生成 |
| 关键特点 | 首次提供高分辨率人脸精细掩码,解决低分辨率分割精度不足问题 | 覆盖多种常见攻击类型,支持复杂场景(如不同光照、姿态)下的模型训练 | 首次将人脸视觉信息与对话文本关联,填补跨模态数据空白 |
| 发布时间 | 2020 年 7 月 10 日 | 2020 年 7 月 10 日 | 2021 年 9 月 10 日 |
- 数据类型差异:CelebAMask-HQ 与 CelebA-Spoof 为纯视觉数据集,聚焦人脸外观与真实性;CelebA-Dialog 为视觉 - 语言跨模态数据集,新增对话文本维度。
- 核心任务差异:前两者服务于 “人脸分析与安全”(分割、编辑、反欺诈);后者服务于 “跨模态融合”(视觉与语言的关联任务)。
- 标注精细度差异:CelebAMask-HQ 以 “语义掩码” 为核心,标注最精细;CelebA-Spoof 以 “攻击类型” 为核心,标注侧重场景与安全性;CelebA-Dialog 以 “文本 - 视觉关联” 为核心,标注侧重语义与情感。
2.1 CelebAMask-HQ(https://github.com/switchablenorms/CelebAMask-HQ)
标注文件:
- 语义掩码标注(19 类面部部件):包含头发、眼睛、鼻子等精细区域划分,可通过 GitHub 仓库获取预处理脚本。
技术文档摘要
- 核心技术细节:
- 基于 CelebA-HQ 的高分辨率(1024×1024)人脸图像,通过专业标注工具生成像素级语义掩码,解决低分辨率分割精度不足问题。
- 支持人脸编辑任务(如换发型、改妆容),可与生成对抗网络(GAN)结合实现语义可控的图像合成。
- 数据划分:
- 包含 30,000 张图像,未明确划分训练 / 验证 / 测试集,建议根据任务自行拆分。
2.2 CelebA-Spoof(https://github.com/ZhangYuanhan-AI/CelebA-Spoof)
技术文档摘要
- 核心技术细节:
- 包含 625,537 张图像,覆盖 10,177 个身份,标注了活体 / 攻击二分类标签及 10 种攻击类型(如打印纸、电子屏、3D 模型),支持跨场景欺诈检测。
- 引入多任务框架 AENet,结合语义和几何信息提升模型泛化能力,在复杂光照和姿态下表现优异。
- 数据划分:
- 训练集包含 386,270 张图像,测试集包含 53,858 张图像,测试身份与训练身份完全独立。
2.3 CelebA-Dialog(https://github.com/yumingj/Talk-to-Edit)
技术文档摘要
- 核心技术细节:
- 包含 10,000 + 组人脸 - 对话样本,每组对话含 50 + 轮交互,标注了人脸身份、对话文本及情感标签(如中性、开心、生气),支持视觉 - 语言跨模态检索。
- 结合 LSTM 语言编码器和语义场(Semantic Field)技术,实现基于自然语言的高细粒度人脸编辑(如调整笑容程度、添加眼镜)。
- 数据划分:
- 未公开具体划分比例,建议根据任务需求(如对话生成或情感分析)自行拆分。
三、下载资源与标注文件
数据集提供多种格式的下载资源,涵盖图像、标注及评估划分,具体如下:
3.1 图像资源(ZIP 格式)
- In-The-Wild Images:“野生” 场景下的人脸图像(未经过多预处理)
- Align&Cropped Images:经过对齐与裁剪处理的人脸图像(便于标准化使用)
3.2 标注文件(均为 TXT 格式)
- Landmarks Annotations:面部 5 个地标位置的标注文件
- Attributes Annotations:每张图像 40 个二进制属性的标注文件
- Identities Annotations:图像对应 10,177 个身份的标注文件
3.3 评估资源(TXT 格式)
- Train/Val/Test Partitions:数据集的训练集、验证集、测试集划分文件,用于模型评估
3.4 备用下载渠道
若上述官方下载链接不可访问,可通过百度网盘下载数据集。
