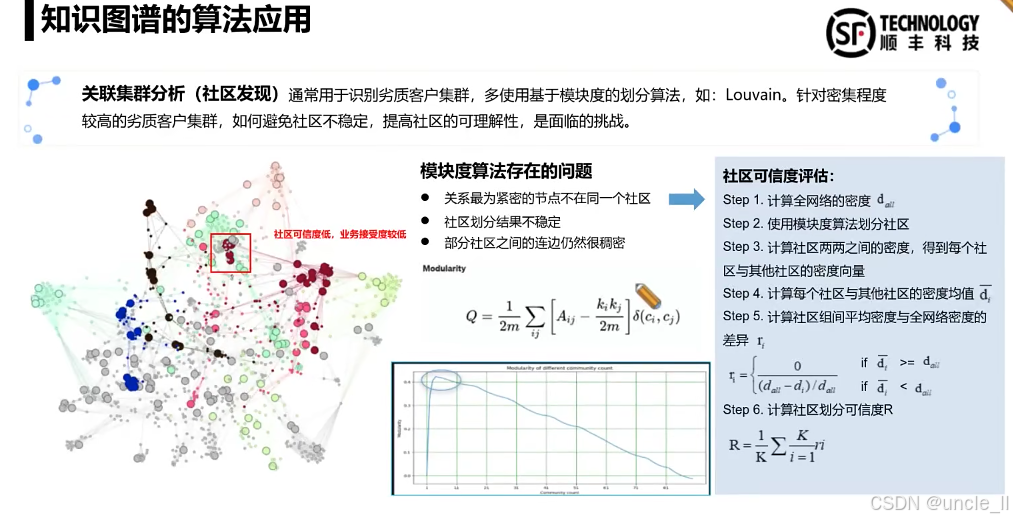
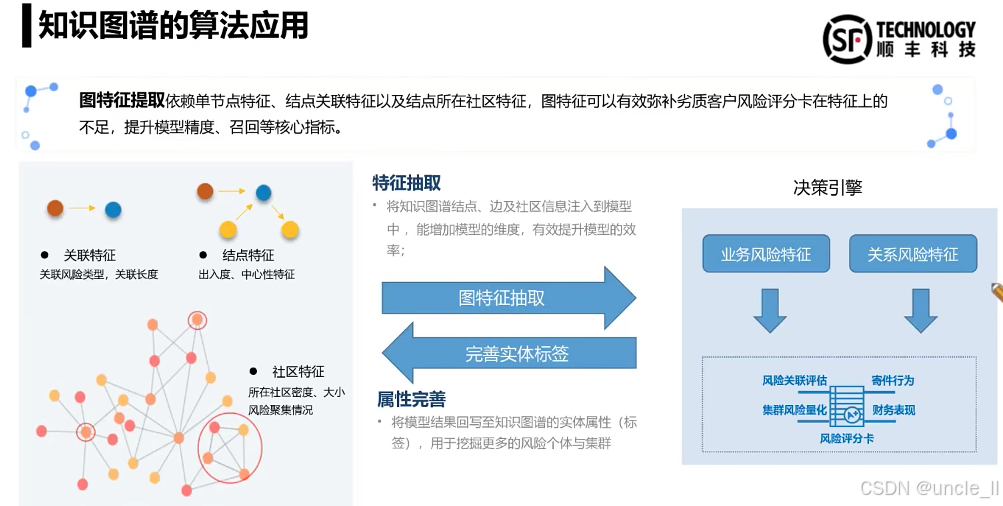
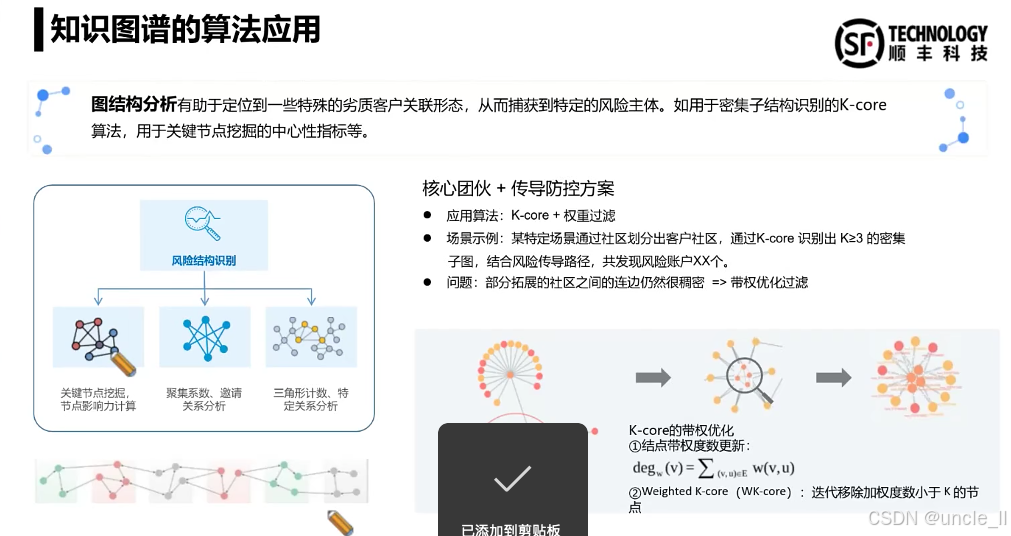
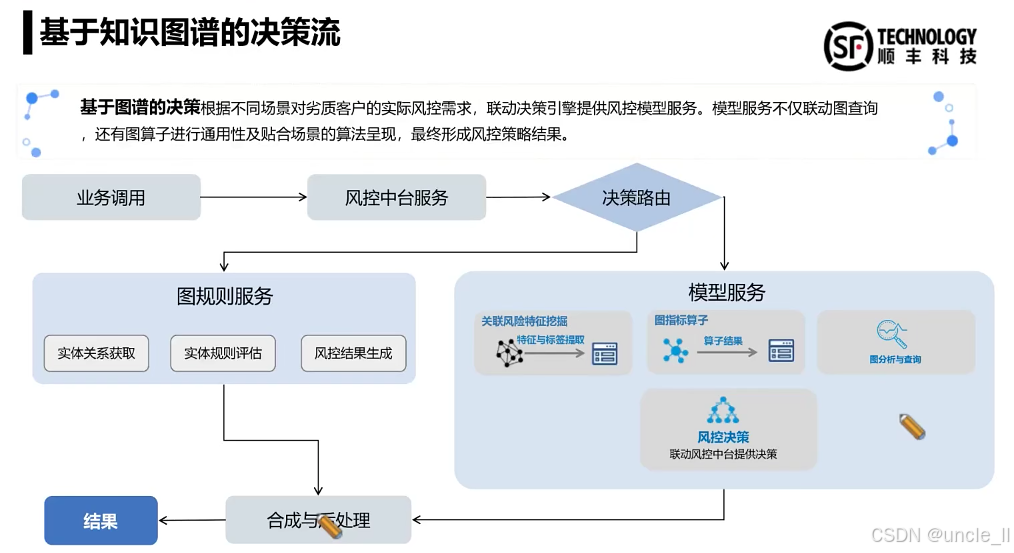
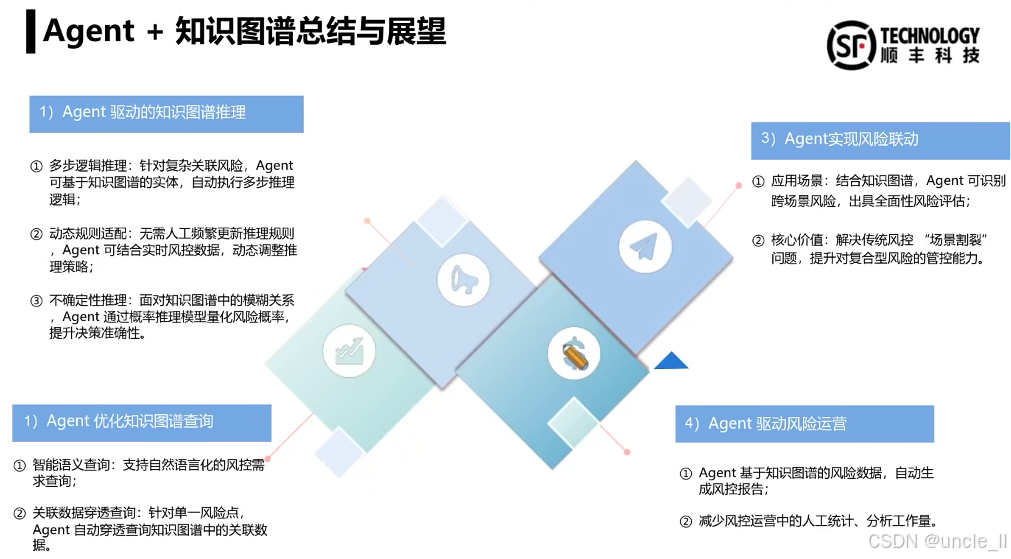
DataFun:智能风控与业务安全
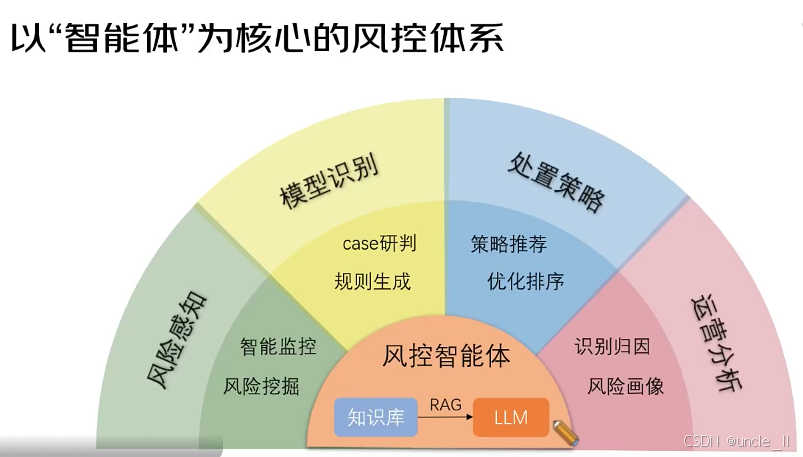
京东——以智能体为核心的风控体系
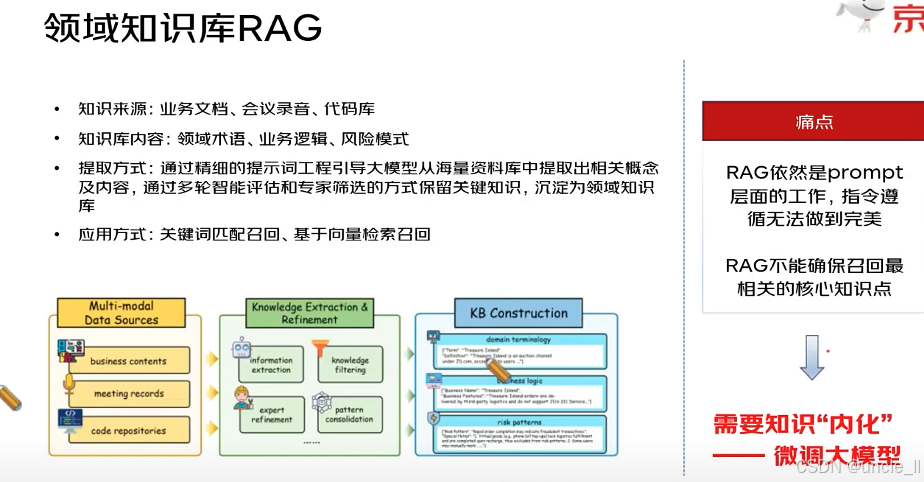
RAG 的核心是为大模型打造领域专属的知识库,辅助其生成更精准的领域内容。流程分为以下环节:
- 知识来源:从业务文档、会议记录、代码库等多模态数据源中获取原始信息,覆盖业务、沟通、技术等维度。
- 知识库内容:聚焦沉淀领域术语、业务逻辑、风险模式—— 这三类是领域内最核心的知识资产(专业概念、业务运转规则、风险规律)。
- 提取方式:通过 “提示词工程引导大模型提取 + 多轮智能评估 + 专家筛选” 的组合方式,从海量资料中提炼 “高价值知识”,确保知识的准确性和实用性。
- 应用方式:使用时,通过 “关键词匹配召回” 或 “基于向量检索召回”,从知识库中调取相关知识,为大模型生成内容提供依据。
目前 RAG 仍存在局限性,需进一步优化:
- 痛点:
- RAG 本质是 “prompt 层面的工作”,大模型对 prompt 指令的 “遵循度无法做到完美”—— 即靠 prompt 引导检索时,大模型不一定能精准执行指令,导致检索效果打折扣。
- RAG “无法确保召回最相关的核心知识点”—— 外部检索的精准度有限,可能漏掉或错配最关键的领域知识。
- 解决方向:需要让知识 “内化”—— 通过微调大模型,把领域知识直接融入模型参数中,让模型从 “外部检索依赖” 转向 “内部知识掌握”,从而提升领域任务的表现。
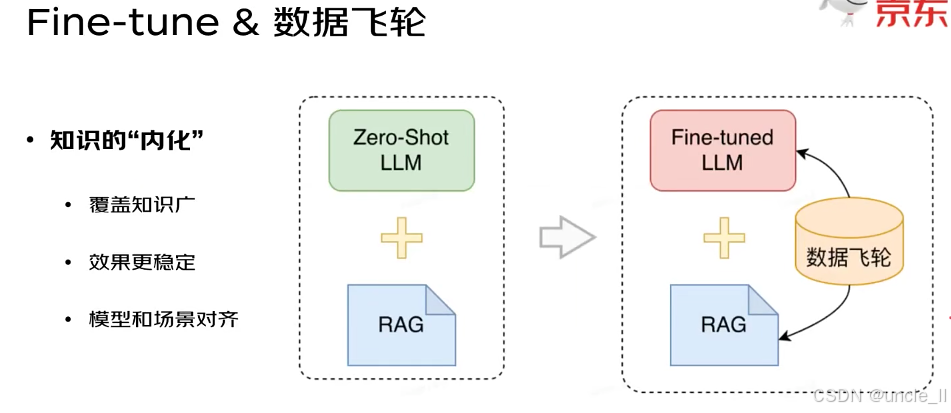
通过两个模块的对比,展现大模型应用的升级路径:
-
左模块(基础方案):
采用「Zero-Shot LLM(未微调的原始大模型) + RAG」。
大模型本身缺乏领域知识,完全依赖外部 RAG 检索知识库补充信息,局限性明显(如检索精度不足、知识覆盖有限)。
-
右模块(进阶方案):
采用「Fine-tuned LLM(微调后的大模型) + RAG + 数据飞轮」。
① 微调后的大模型已 “内化” 部分领域知识,结合 RAG 补充外部知识,知识覆盖与精准度双重提升;
② “数据飞轮” 是核心闭环:模型与 RAG 产生的结果、用户反馈等数据,会回流到 “数据飞轮” 中,用于持续优化微调模型或 RAG 知识库,形成「数据驱动→模型 / 知识库升级→更好效果→更多数据」的正向循环,让系统能力持续迭代。
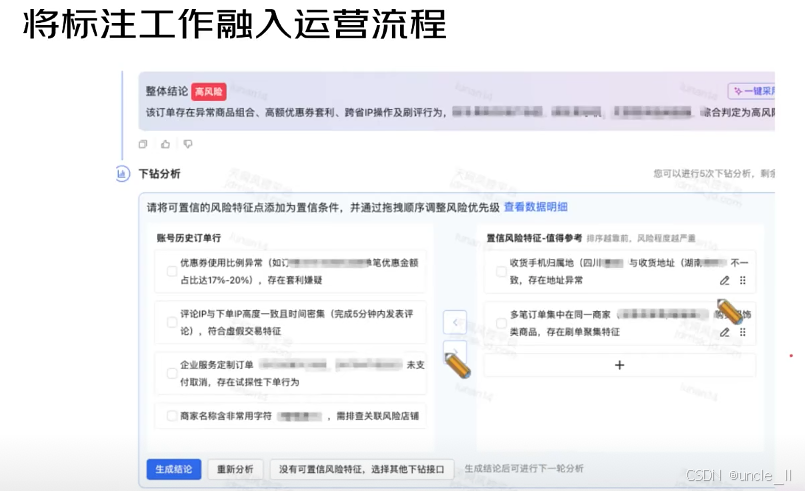
“将数据标注工作与业务运营流程深度融合” 的实践场景,核心是在 “订单风险审核” 这类运营环节中,同步完成 “风险特征标注”,让标注服务于业务决策,也为后续 AI 模型训练积累数据。
核心逻辑与界面解析:
-
业务场景锚定:聚焦 “订单风险判定”,顶部已给出 “整体结论:高风险”,并说明风险原因(异常商品组合、优惠券套利、跨省 IP、刷评等)。
-
“下钻分析” 实现 “标注 + 运营” 闭环:
把 “大而笼统的风险结论” 拆解为可量化、可标注的具体风险特征,让运营人员在审核时,同步完成 “风险特征的识别与标注”:
- 左侧 “账号历史订单”:列出从历史行为中提取的风险点(如 “优惠券使用比例异常(17%-20%,套利嫌疑)”“评论与下单 IP 高度一致且时间密集(刷交易特征)”),这些是需要标注 / 确认的 “风险特征标签”。
- 右侧 “置信风险特征 - 值得参考”:展示更具体的风险细节(如 “收货地址与手机归属地不一致”“多订单集中刷单”),且支持拖拽调整风险优先级(体现业务对不同风险的重视程度)。
-
操作闭环:底部 “生成结论”“重新分析” 等按钮,让运营人员在 “标注完风险特征” 后,可直接生成最终判定、或重新校验,实现 “分析风险→标注特征→业务决策” 的一体化,既完成了 “标注数据的生产”,又服务于当下的风控运营。
这种模式让 “数据标注” 从 “独立的后台工作”,变成业务流程的自然环节—— 运营人员在日常审核订单时,就同步完成了 “风险特征的识别与标注”,既提升了业务决策的精准度(基于更细粒度的特征),又为后续 AI 风控模型的训练,持续积累高质量的 “标注数据”。
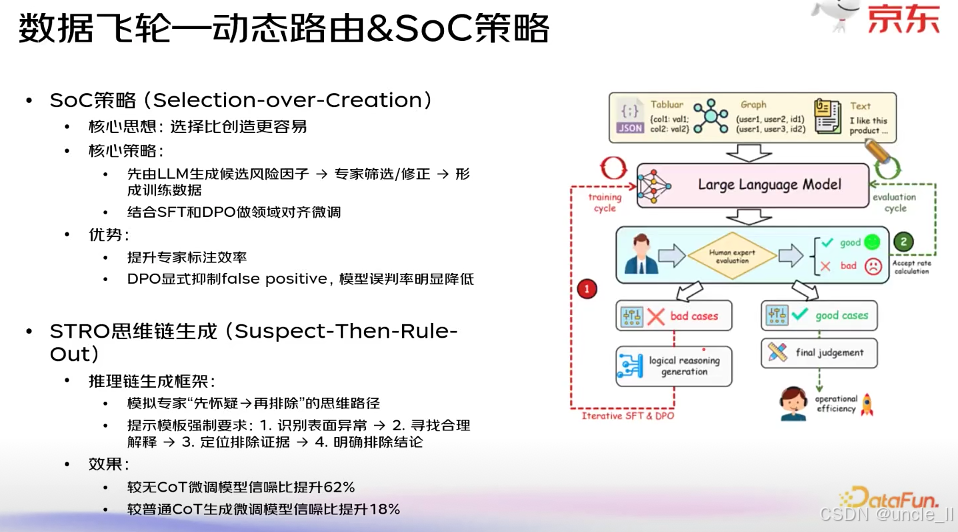
“数据飞轮 — 动态路由 & SoC 策略” ,通过策略设计、思维链引导、人机协同与模型微调,构建 “数据→模型→业务效果” 的正向循环,提升大模型在领域任务(如风险识别等场景)中的表现。
一、核心策略:SoC(Selection-over-Creation)
-
核心思想:选择比创造更容易—— 不让大模型 “从零创造” 领域知识,而是先生成 “候选方案”,再由人类专家 “筛选 / 修正”,以此高效生产训练数据。
-
执行流程:
大语言模型(LLM)生成「候选风险因子」→ 人类专家对候选进行筛选 / 修正 → 加工后的内容成为训练数据 → 结合「SFT(有监督微调)」和「DPO(直接偏好优化)」,对大模型做领域对齐微调(让模型更适配业务场景)。
-
优势:
-
提升专家标注数据的效率;
-
DPO 技术可显式抑制 “假阳性标注”(如错误判定风险),显著降低模型误判率。
-
二、推理增强:STRO 思维链生成(Suspect-Then-Rule-Out)
-
设计思路:模拟人类专家 “先怀疑异常,再逐步排除” 的推理逻辑,通过强制化的提示模板引导大模型生成精准推理链。
-
推理步骤(模板约束):
① 识别「表面异常」(如订单的可疑特征)→ ② 为异常寻找「合理解释」→ ③ 定位「能排除异常的证据」→ ④ 给出「明确的排除结论」。
-
效果验证:
相比 “无思维链(CoT)的微调模型”,推理的信噪比提升 62%;
相比 “普通思维链(CoT)的微调模型”,信噪比也提升 18%。
(“信噪比”:反映推理的 “有效信息纯度”,越高说明模型推理越精准、噪声越少)。
数据飞轮的闭环流程
通过 “多模态输入→模型生成→专家评估→数据反馈→模型迭代” 的循环,实现 “数据飞轮”:
-
多模态输入:表格(Tabular)、图(Graph)、文本(Text)等数据输入大语言模型;
-
人机协同评估:模型生成结果后,人类专家区分「好案例(good cases)」与「坏案例(bad cases)」;
-
模型迭代优化:坏案例用于优化「逻辑推理生成(logical reasoning generation)」,好案例支撑「最终判断(final judgement)」;再结合「Interactive SFT(交互式有监督微调)」和「DPO」,让模型持续学习、升级;
-
业务价值:通过 “数据反馈→模型优化→更高效的业务决策(如风险判定)” 的飞轮效应,提升运营效率(operational efficiency)。
整套方法通过「SoC 策略(高效产数)+ STRO 思维链(精准推理)+ 微调技术(SFT/DPO)+ 人机协同 + 数据循环」,让大模型在领域任务中持续进化,既解决了 “数据生产效率” 问题,又提升了 “模型推理精度” 与 “业务运营效率”。
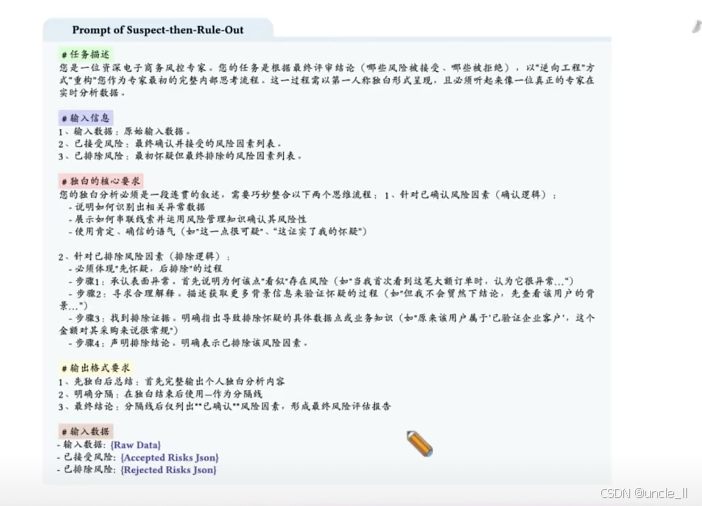
思维链的提示词(Prompt)设计 ,用于引导大模型模拟资深电商风控专家的思考过程,复现从 “风险怀疑” 到 “最终结论” 的完整逻辑。以下是分模块解析:
1. 任务描述
明确大模型的 “角色” 与 “任务”:
- 角色:资深电子商务风控专家。
- 任务:根据 “最终评审结论”(哪些风险被接受、哪些被拒绝),以 **“逆向工程”的方式,复现专家最初分析数据时的完整内部思考流程 **。
- 形式要求:用第一人称独白呈现,要听起来像真实专家在实际分析数据。
2. 输入信息
为大模型提供生成思考过程的 “原材料”:
- 原始输入数据(Raw Data);
- 已接受风险(最终确认的风险因素列表);
- 已排除风险(最初怀疑、但最终被排除的风险因素列表)。
3. 独白的核心要求(最关键:规定 “思考逻辑”)
强制大模型的思考过程整合 “确认风险”和“排除风险” 两条逻辑线:
-
确认风险的逻辑:
需解释 “如何识别异常数据→ 如何用风控知识串联线索→ 最终确认风险性”,语气要肯定、确信(如 “这一点很可疑”“这证实了我的怀疑”)。
-
排除风险的逻辑(核心是 “先怀疑,后排除” 的四步流程):
步骤 1:承认表面异常(说明最初为何觉得有风险,如 “当我首次看到这笔大额订单时,认为它很异常…”);
步骤 2:寻求合理解释(描述获取更多背景信息验证怀疑的过程,如 “但我不会贸然下结论,先查看该用户的背景…”);
步骤 3:找到排除证据(指出具体数据 / 业务知识,如 “原来该用户是‘已验证企业客户’,这个金额对其采购很常规”);
步骤 4:声明排除结论(明确表示 “已排除该风险因素”)。
4. 输出格式要求
规定生成内容的结构规范,确保输出可用:
- 先完整输出第一人称独白(模拟专家思考过程);
- 用 “—” 作为分隔线;
- 分隔线后仅列出 **“已确认” 的风险因素 **,形成 “最终风险评估报告”。
5. 输入数据示例
给出实际使用时的 “占位符”,比如原始数据、“已接受风险” 的 JSON、“已排除风险” 的 JSON,提示需替换为真实业务数据。
通过严格的 “角色设定、逻辑框架、格式约束”,引导大模型生成贴近人类专家的 “风险思考链”—— 既体现 “对风险的敏锐怀疑”,又展现 “基于证据的理性排除”,可用于辅助风控决策或生成高质量训练数据(让模型学习专家思维)。
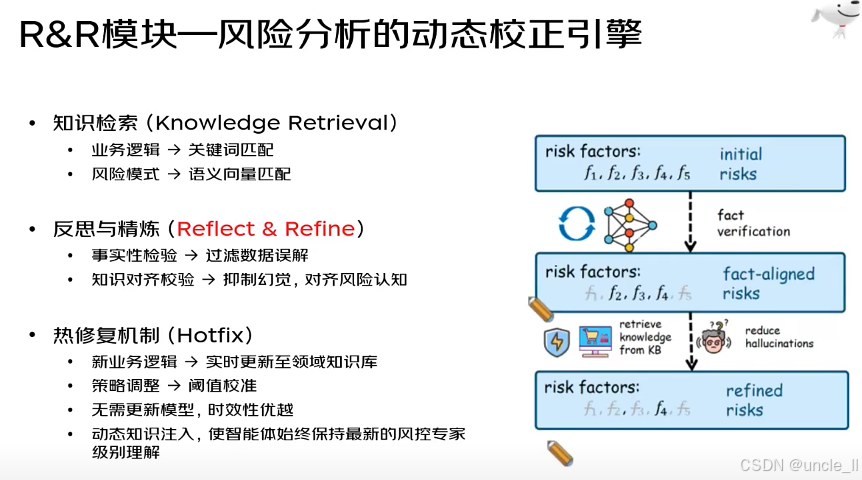
“R&R 模块 —— 风险分析的动态校正引擎”,通过 “知识检索→反思精炼→热修复” 的闭环,让风险分析系统能动态适应业务变化、提升判断准确性。以下是分模块解析:
一、核心环节 1:知识检索(Knowledge Retrieval)
为风险分析提供 “领域知识支撑”,分两类匹配逻辑:
- 业务逻辑:用 关键词匹配 快速定位与业务规则直接相关的知识(如 “跨区域订单 + 大额优惠券” 这类明确规则)。
- 风险模式:用 语义向量匹配 捕捉抽象风险特征(如 “用户行为序列异常” 这类难以用关键词描述的模式),覆盖更隐性的风险关联。
二、核心环节 2:反思与精炼(Reflect & Refine)
对 “初步风险判断” 进行准确性校验与优化,解决大模型常见问题:
- 事实性检验:验证风险因子的 “事实正确性”,过滤对数据的误解(比如错误解读订单金额、用户地址等信息)。
- 知识对齐校验:让风险认知与领域知识 “对齐”,抑制大模型 “幻觉”(即生成不符合真实业务的错误判断),确保风险分析贴合实际业务逻辑。
三、核心环节 3:热修复机制(Hotfix)
让系统无需重新训练模型,也能快速适配业务变化:
- 新业务逻辑:当业务规则更新(如新增 “直播间刷单” 风险场景),实时更新到领域知识库,不依赖模型重训。
- 策略调整:通过阈值校准(如把 “风险分数> 80 判定为高风险” 调整为 “>75”)微调风险判定标准。
- 核心优势:时效性极强,能让 “智能风控系统” 始终保持 “最新的专家级风险理解”,灵活应对业务迭代。
动态校正的过程可视化
- 初始风险(Initial Risks):基于风险因子(f₁, f₂, f₃, f₄, f₅),得到 “初步风险判断”。
- 事实验证(Fact Verification):校验风险因子的事实准确性,得到 “事实对齐的风险(Fact-Aligned Risks)”。
- 知识检索与幻觉抑制:从领域知识库(KB)检索知识,进一步减少 “幻觉”,最终生成 “精炼后的风险(Refined Risks)”,完成动态校正。
R&R 模块通过 “知识支撑→校验优化→动态更新” 的闭环,既提升了风险分析的准确性(减少错误 / 幻觉),又保证了时效性(快速适配业务变化),让风控系统成为 “能自我进化的动态校正引擎”。
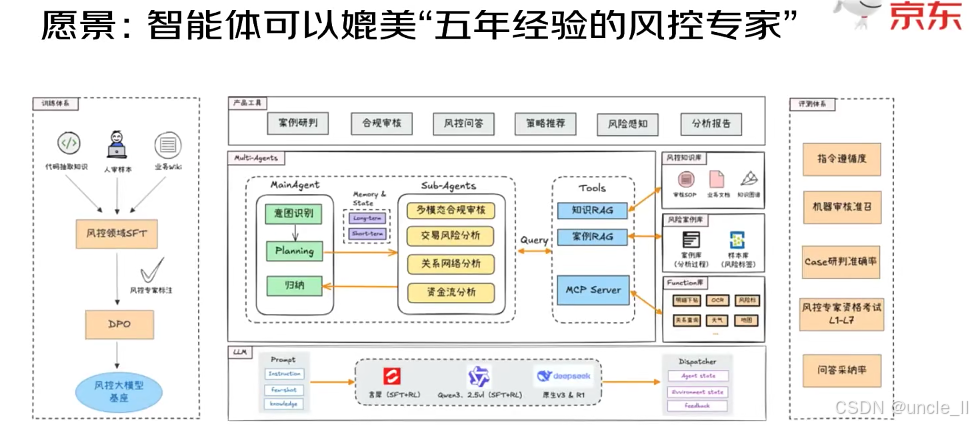
从模型训练、多智能体协同、工具支撑到效果评估,完整呈现了实现 “资深风控专家级智能体” 的路径:
一、风控大模型的 “训练链路”(打造智能体的 “大脑”)
要让智能体具备风控能力,需先训练 “风控领域专属大模型基座”:
- 输入知识源:整合「领域先验知识」(风控行业积累的规则、模式)、「人类样本」(专家过往的判断案例)、「业务 Unit」(具体业务场景的需求)。
- 训练步骤:
- 风控领域 SFT(有监督微调):让通用大模型先学习 “风控领域的基础逻辑、案例”,初步具备风控认知。
- 风控专家校验:人类专家对微调结果进行审核,确保模型学习方向符合实际业务。
- DPO(直接偏好优化):进一步让模型的判断 “对齐人类专家的偏好”(比如专家更关注哪些风险因子、如何权衡不同风险),最终得到 “风控大模型基座”—— 这是智能体的核心 “大脑”,提供风控领域的知识与推理能力。
二、中间:多智能体系统(让智能体 “分工协作处理任务”)
大模型基座之上,通过 “主智能体(MainAgent)+ 子智能体(Sub-agents)+ 工具(Tools)” 的协同,处理复杂风控任务:
- MainAgent(总协调者):负责「意图识别」(理解用户 / 业务的风控需求)、「Planning(任务规划)」(把复杂任务拆解为子任务)、「归纳总结」,还具备「Memory & State(记忆与状态管理)」(记住历史任务、维护当前状态)。
- Sub-agents(专精型子智能体):聚焦细分风控场景,比如「多模态合规审核」(审核图片、视频等多模态内容的合规性)、「交易风险分析」(识别异常订单、支付行为)、「关系网络分析」(挖掘团伙欺诈的关联关系)、「资金流分析」(追踪异常资金转移)。
- Tools(工具层):为智能体提供 “外部能力补充”,包括:
- 「知识 RAG」:检索 “领域知识库” 获取风控规则、术语;
- 「案例 RAG」:检索 “历史风控案例” 参考专家过往判断;
- 「MCP Server」:可能是模型服务 / 计算平台,提供算力或复杂逻辑支持。
- 上层产品工具:直接对接业务,提供「案例研判、合规审核、风险问答、策略推荐、风险感知、分析报告」等功能,让智能体的能力落地到实际风控工作中。
三、评估体系(验证 “是否媲美五年经验专家”)
通过多维度指标,全面检验智能体的风控能力,确保其达到 “人类专家水平”:
- 「指令遵循度」:检验智能体是否能准确执行用户 / 系统的指令;
- 「机器审核准召」:“准确率 + 召回率”,衡量智能体审核风险的精准度;
- 「Case 研判准确率」:对具体风控案例的判断是否正确;
- 「风控专家里考考试 L1-L7」:用人类专家的 “分级考核标准”(从初级 L1 到资深 L7)评估智能体;
- 「问答采纳率」:智能体回答风控问题时,被人类采纳的比例。
四、底部:大模型与调度层(支撑系统运转)
- LLM 层:采用「通义(SFT+RL)、Qwen(SFT+RL)、星火(SFT+RL)」等经过 “有监督微调(SFT)+ 强化学习(RL)” 的大模型,作为基础算力与推理引擎。
- Dispatcher(调度器):管理「Agent 状态、部署状态、反馈」,确保多智能体、工具、大模型之间的协同高效运转。
这套架构通过 “先训练‘领域专属大模型’打基础,再用‘多智能体分工协作’处理复杂任务,最后用‘多维度评估’验证效果”,最终目标是让智能体在风控领域的知识、判断、协作能力,达到 “拥有五年经验的人类风控专家” 水平,实现从 “模型智能” 到 “业务智能” 的落地。

从技术深化、应用扩展、生态构建三个维度,阐述了风控智能系统的未来发展方向:
一、技术深化方向(提升核心技术能力)
聚焦 “让风控技术更智能、高效、自主”:
- 优化知识流转效率:升级 “知识库召回算法”,并强化 “知识库” 与 “数据飞轮(数据循环优化机制)”、“反思模块(如 R&R 动态校正引擎)” 的联动,让 “知识检索→数据迭代→风险校正” 形成更高效的闭环。
- 扩展风险检测维度:融入图像、视频等多模态数据(如商品图合规性、用户行为视频轨迹),突破传统 “单一数据维度” 的局限,覆盖更隐蔽的风险场景(如视觉层面的欺诈行为)。
- 降低专家依赖:结合 “R&R 模块(反思与精炼)”,打造自动更新响应机制—— 系统可自主根据新业务、新风险调整策略,减少对人类专家 “手动标注、干预” 的依赖,提升自动化程度。
二、应用扩展计划(拓宽技术的应用边界)
从 “电商风控” 出发,做 “纵向深化” 与 “横向跨域”:
- 纵向:深化业务辅助:建立风险等级自动标定体系(不再只判断 “有 / 无风险”,而是细分 “高 / 中 / 低风险”),让风控从 “单纯检测” 升级为 “精准辅助决策”(如高风险直接拦截、中风险人工复核)。
- 横向:跨行业迁移:研发通用型 “数据飞轮” 框架(抽象 “数据循环优化模型” 的逻辑为通用工具),支持将电商风控的经验与能力,迁移到 ** 金融(如信贷欺诈检测)、医疗(如医保骗保识别)** 等其他需风险管控的领域。
三、生态构建愿景(从 “企业技术” 到 “行业生态”)
推动风控技术从 “单个企业的能力”,进化为 “全行业共享、共建的生态”:
- 开源协作:开发 “核心算法模块” 并开源,构建 **“电商风控大模型” 开发者社区 **—— 吸引更多开发者参与技术迭代,加速行业整体技术水平提升。
- 标准统一:建立电商风控领域的 Benchmark 评估体系(即 “模型效果好不好” 的统一测试标准),供业内研究者共享、对比,推动技术透明化与公平竞争。
- 产学研结合:促进企业(有业务场景、数据)与高校(有算法研究能力)合作,将 “实验室里的大模型算法” 与 “企业专家的实际风控经验” 深度融合,加速技术从 “理论” 到 “落地” 的转化。
整体来看,未来愿景是让 “风控智能系统” 不仅在技术上更强大、应用上更广泛,还能成为全行业共建、共享的基础设施。
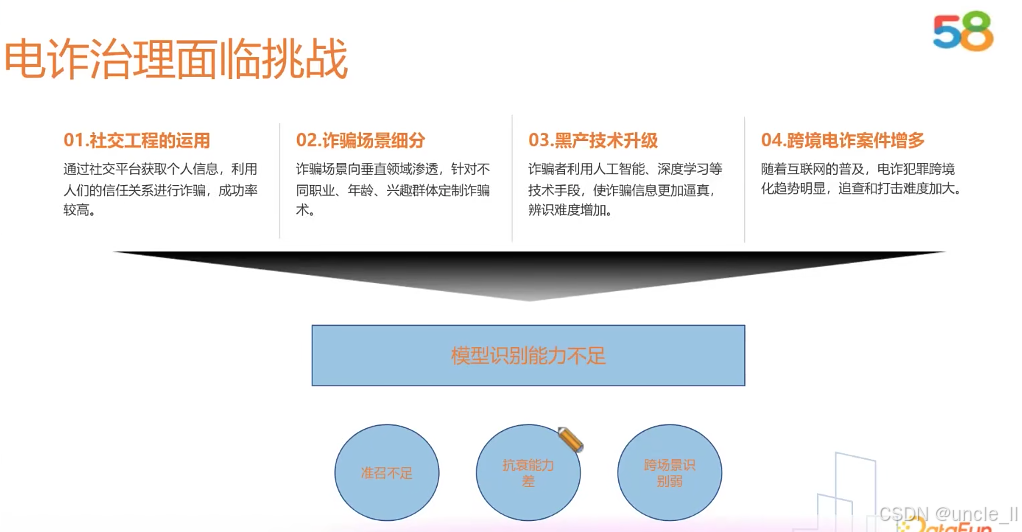
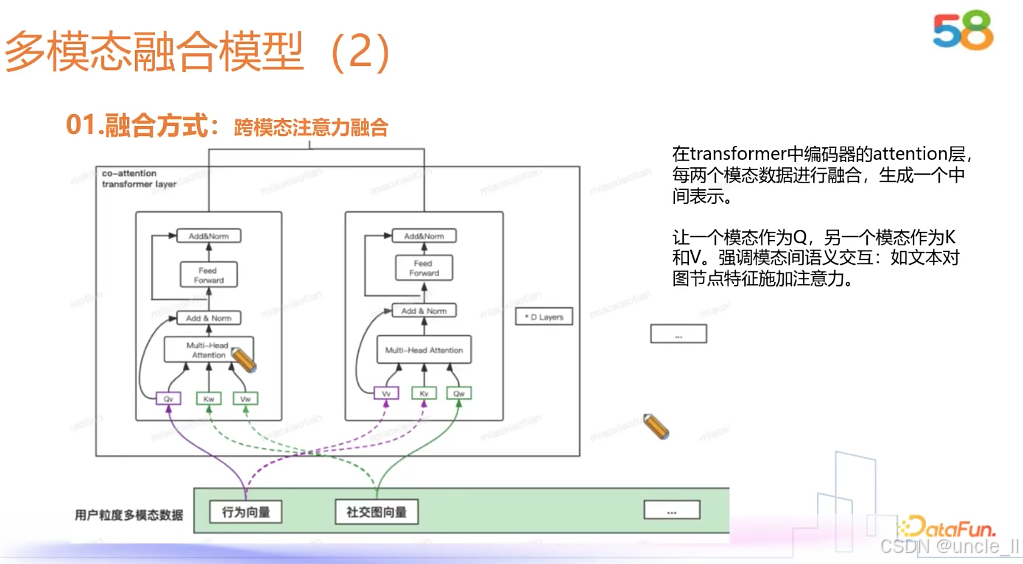
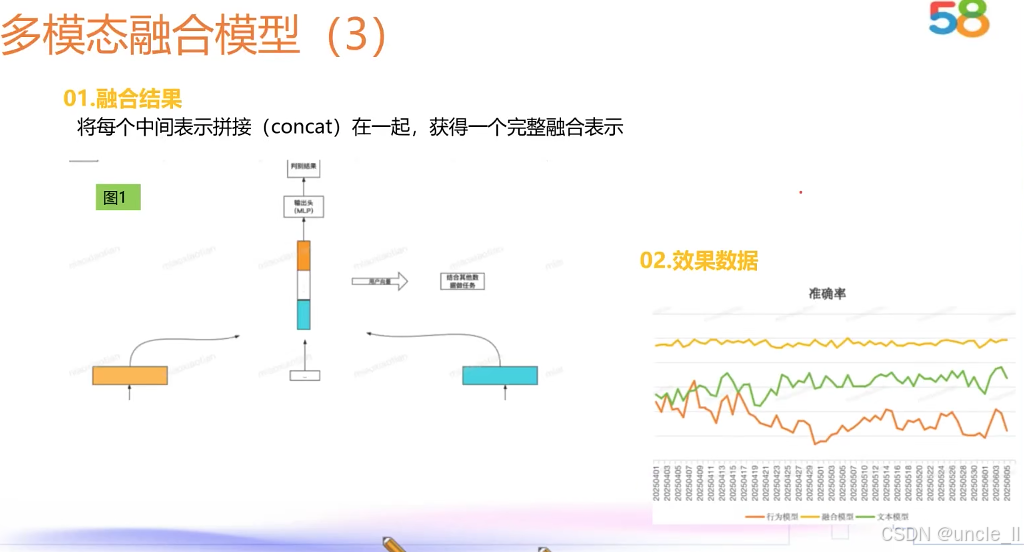
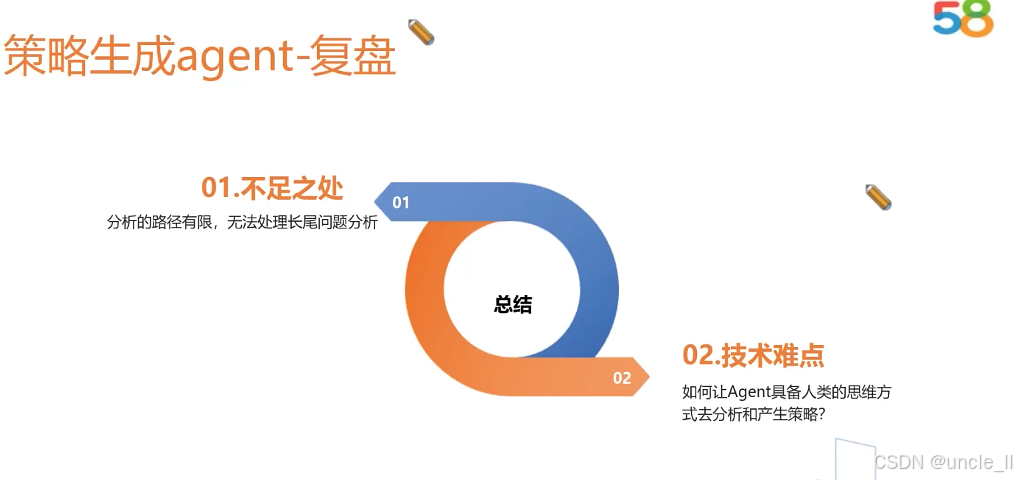
58金融——对抗黑产




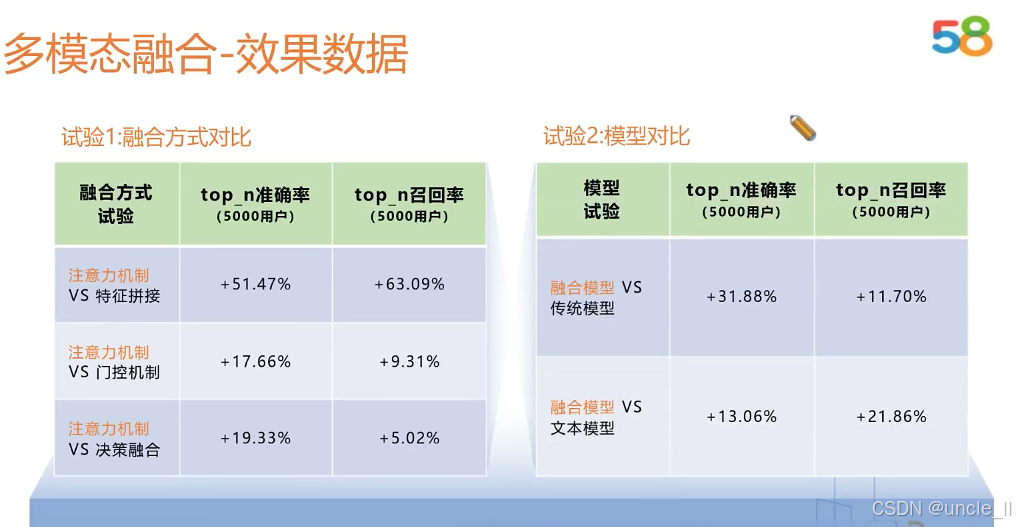
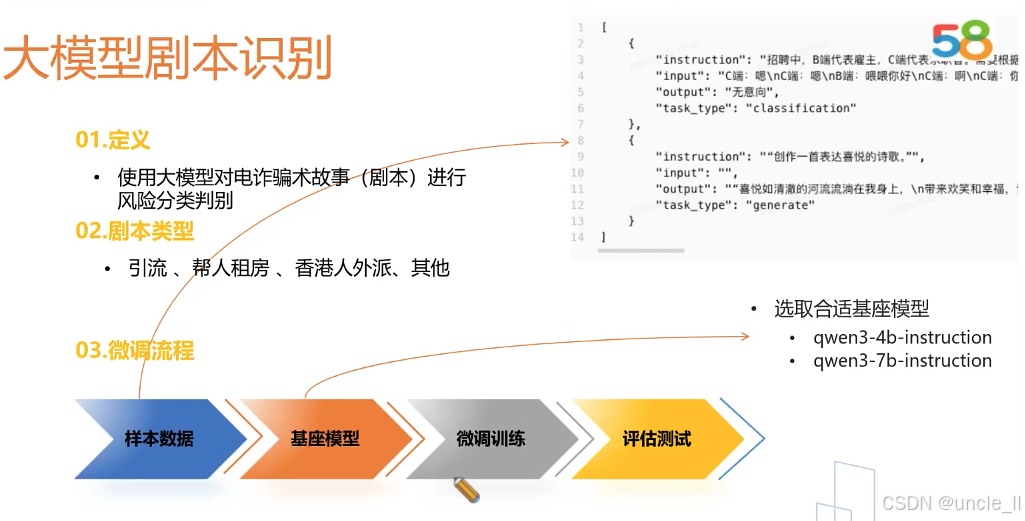
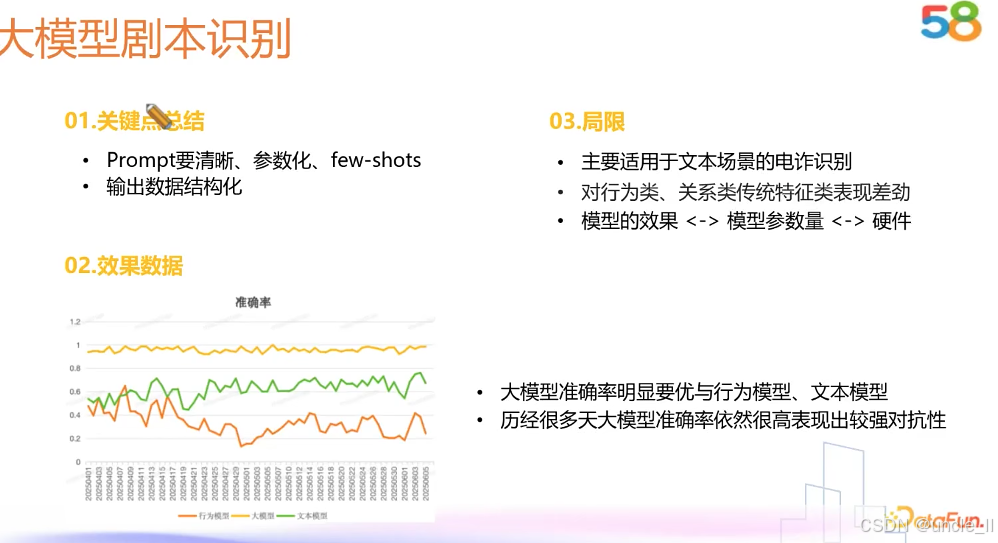
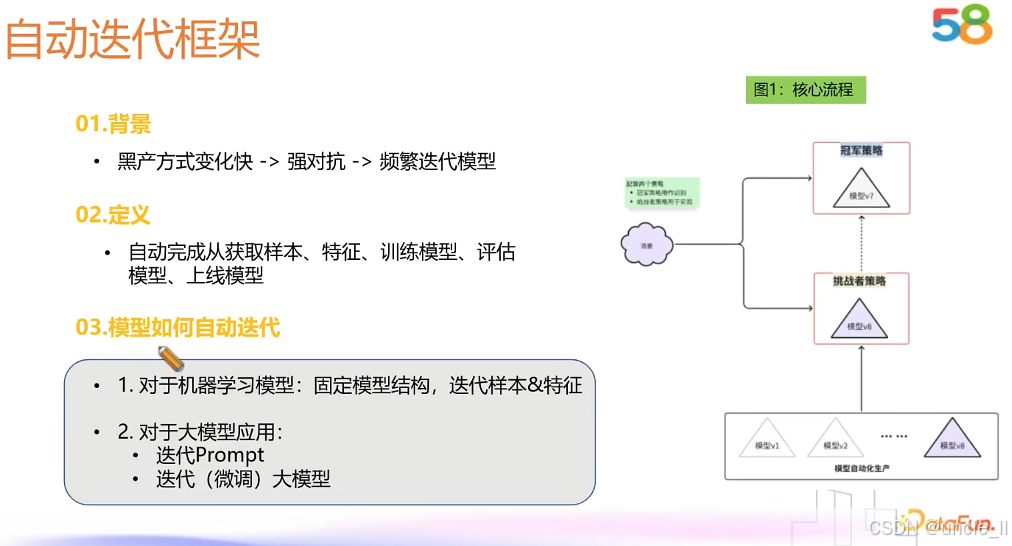
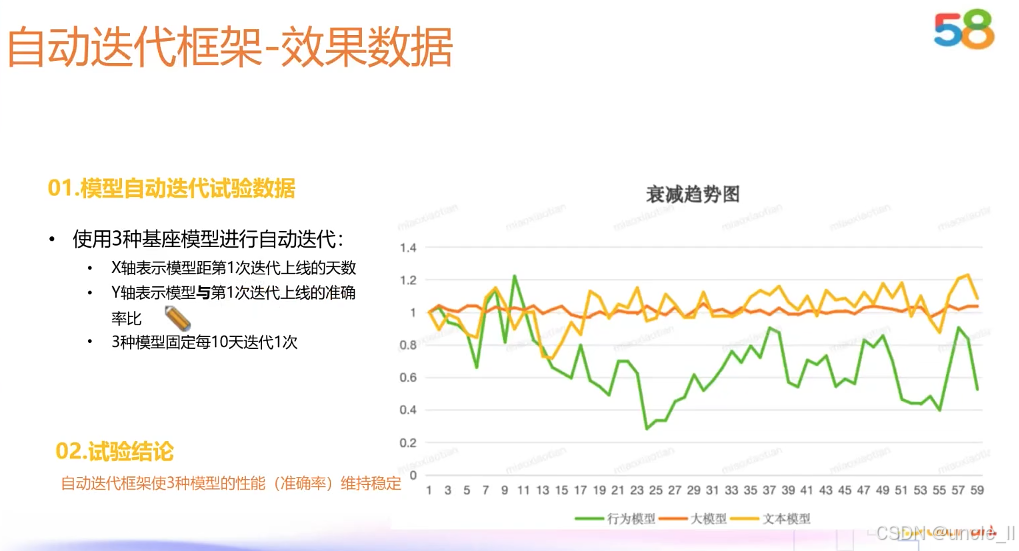

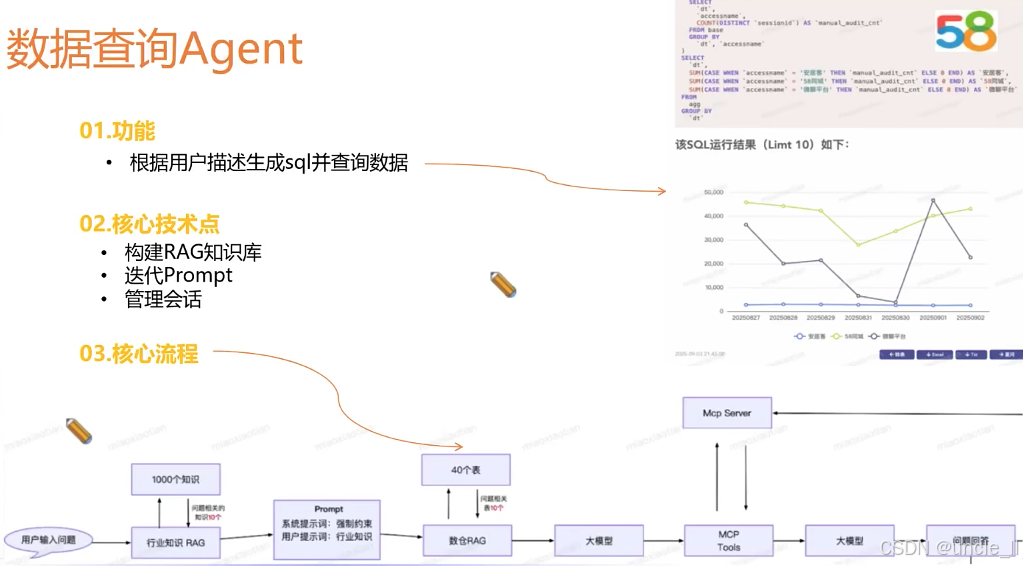


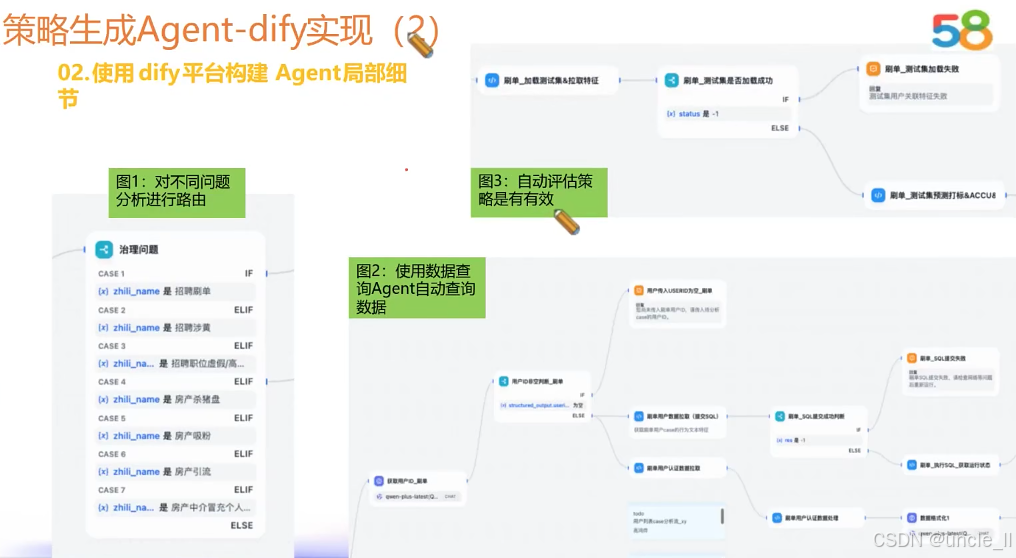

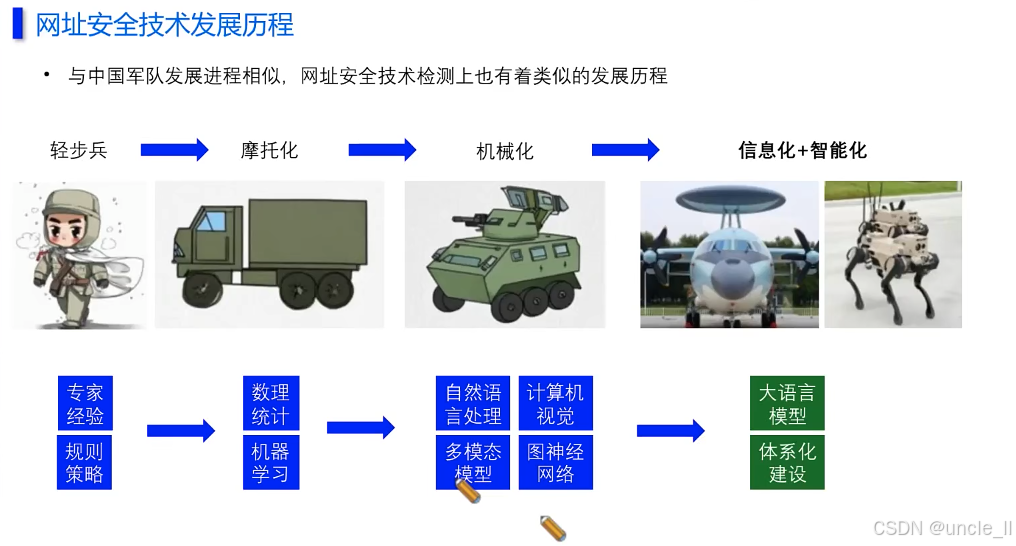
腾讯——网址安全

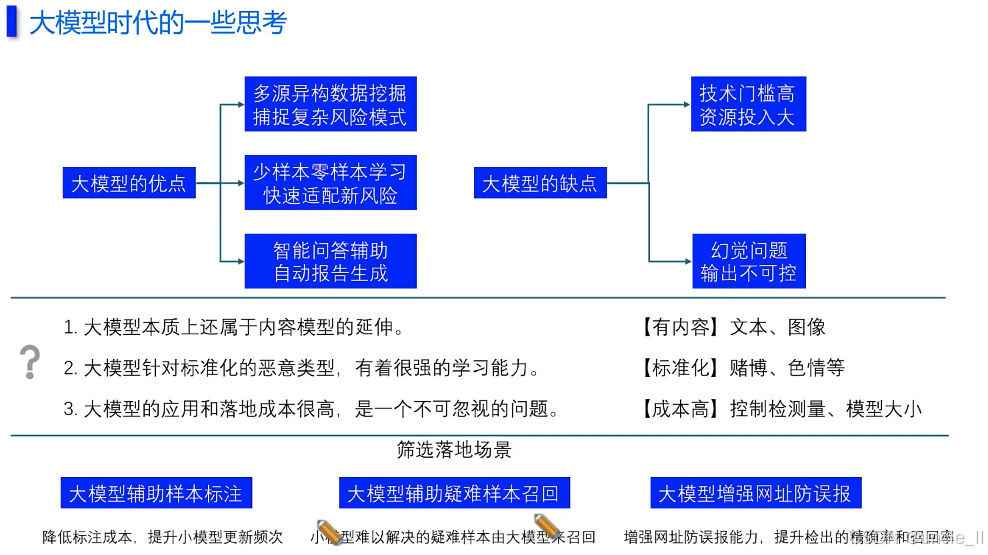
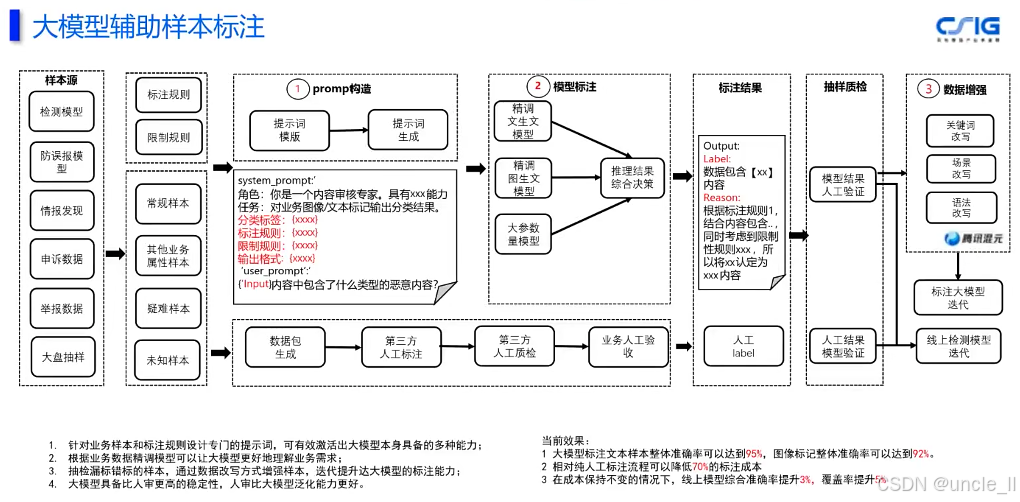
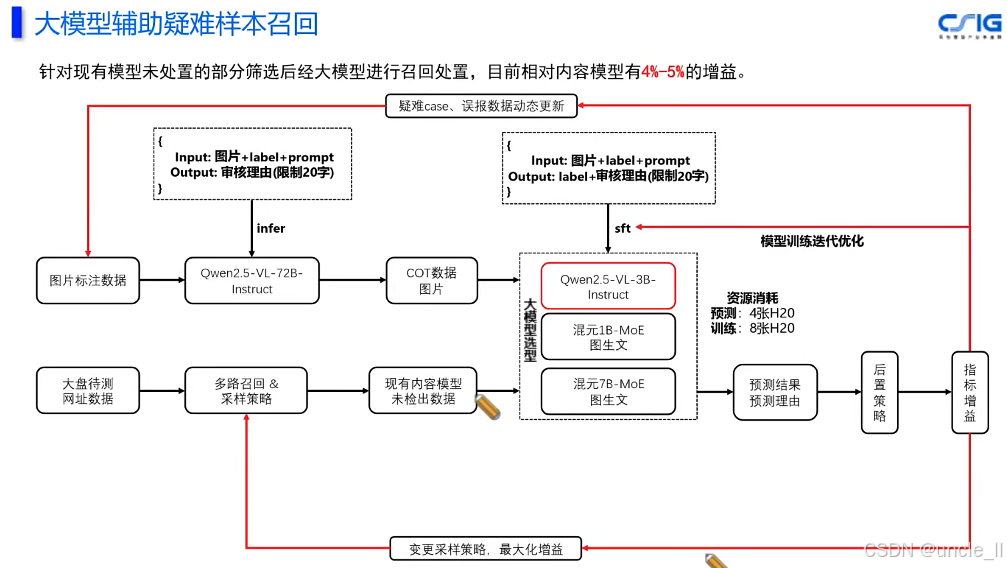
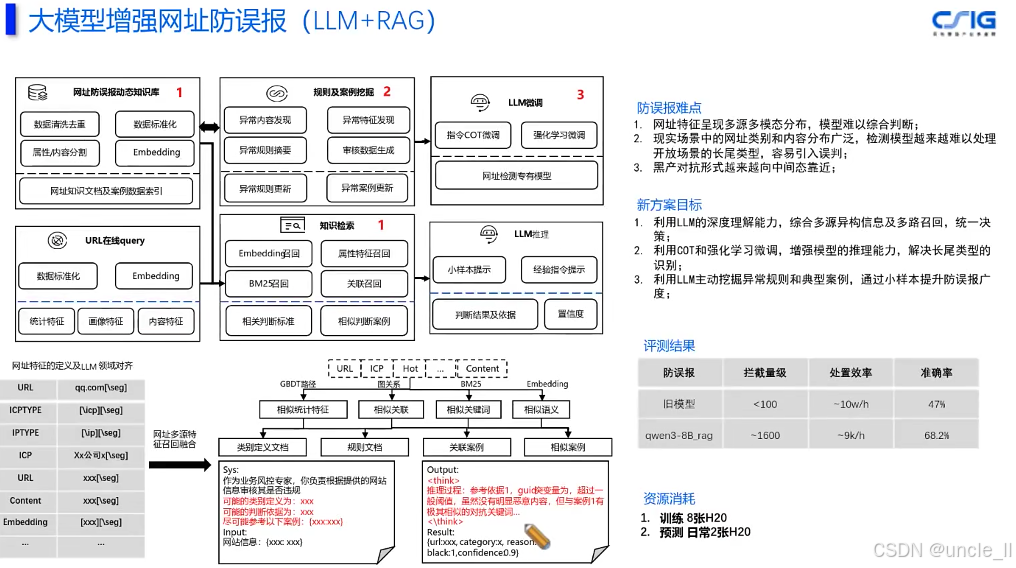

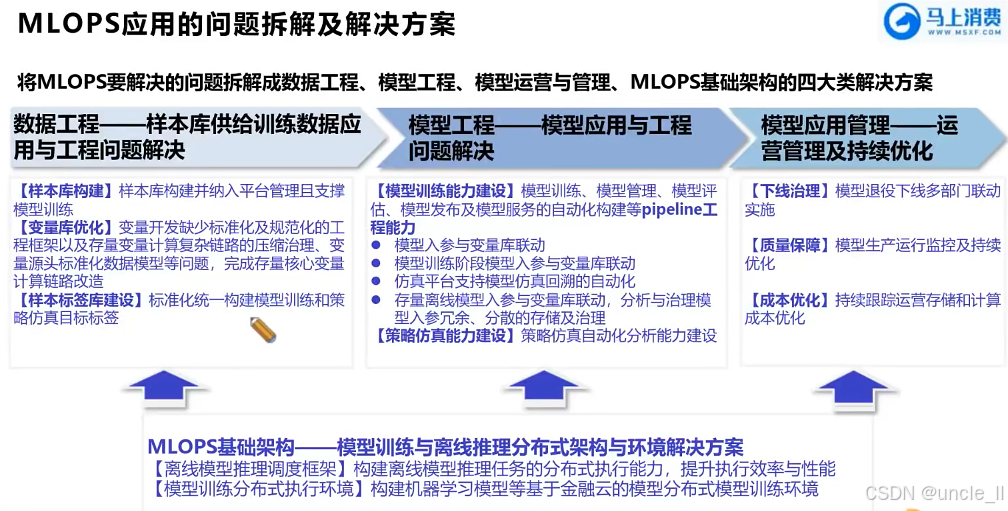
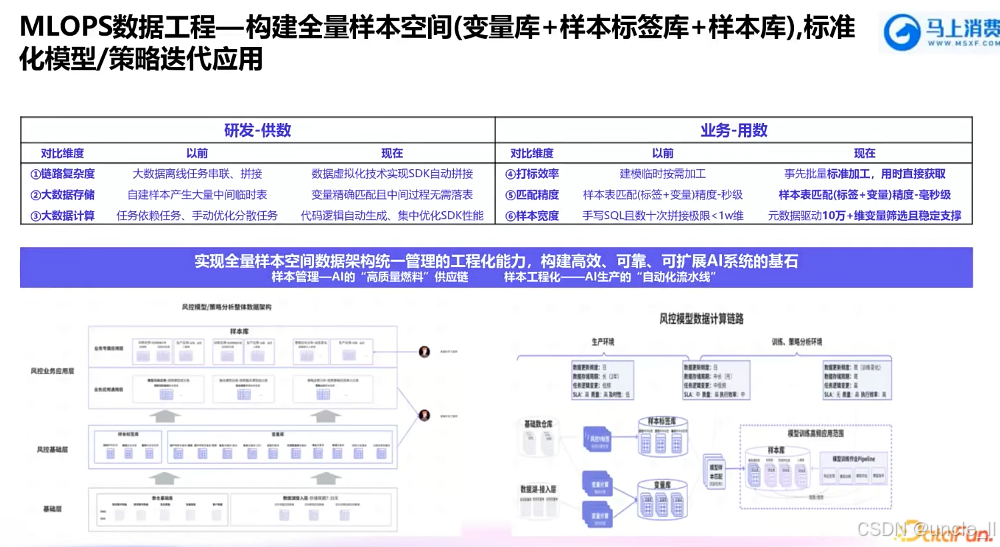
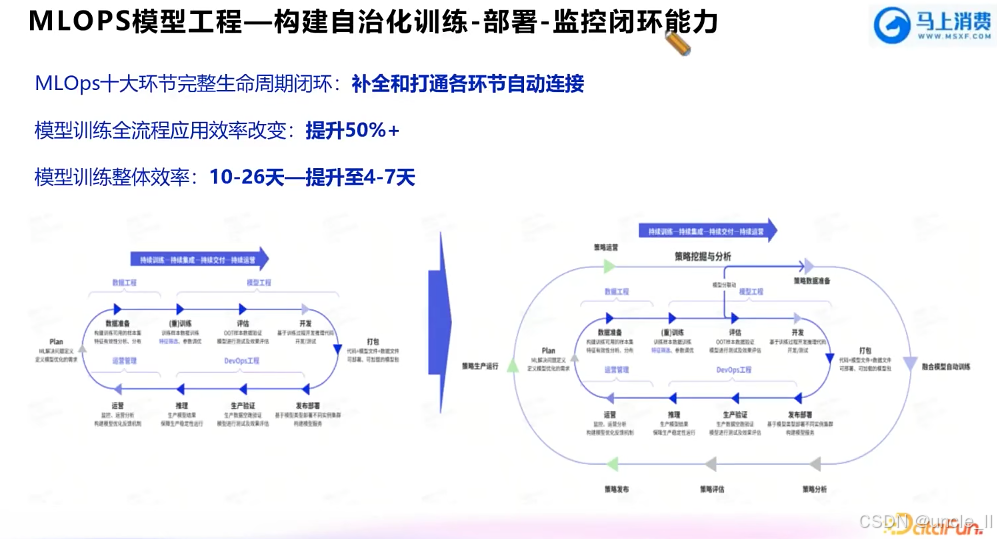
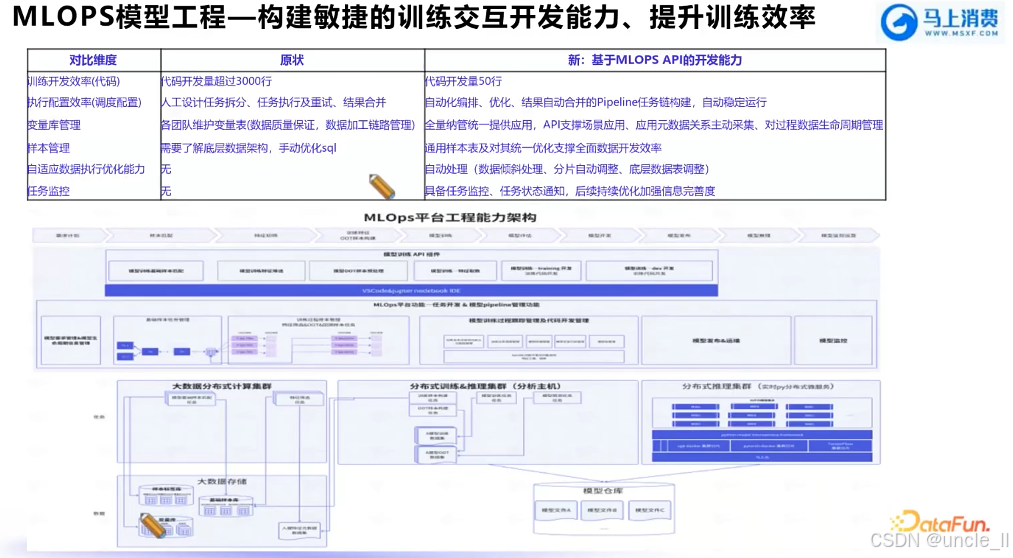
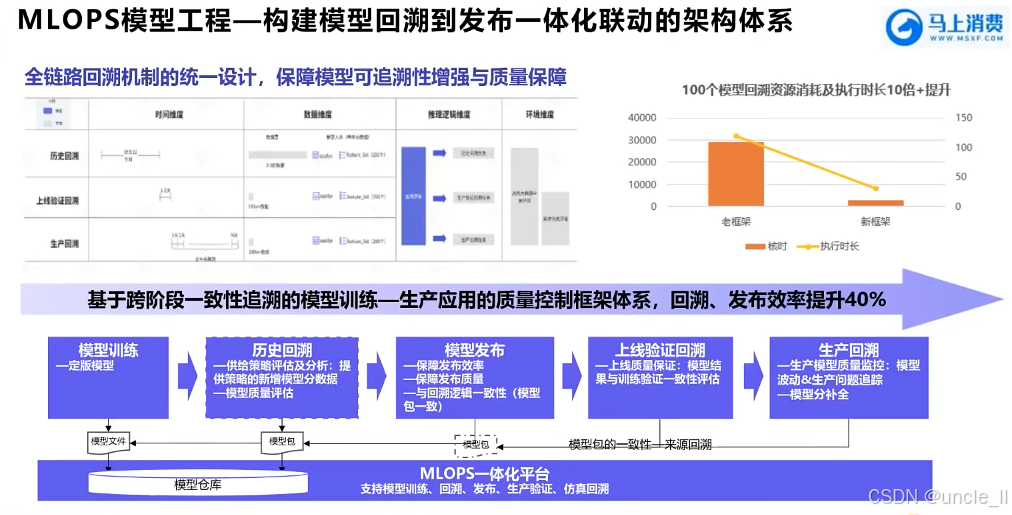
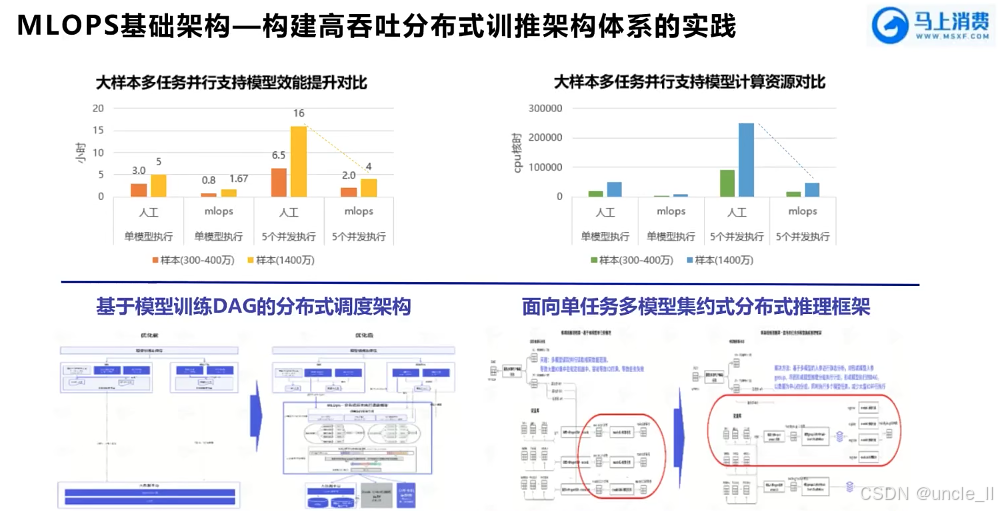
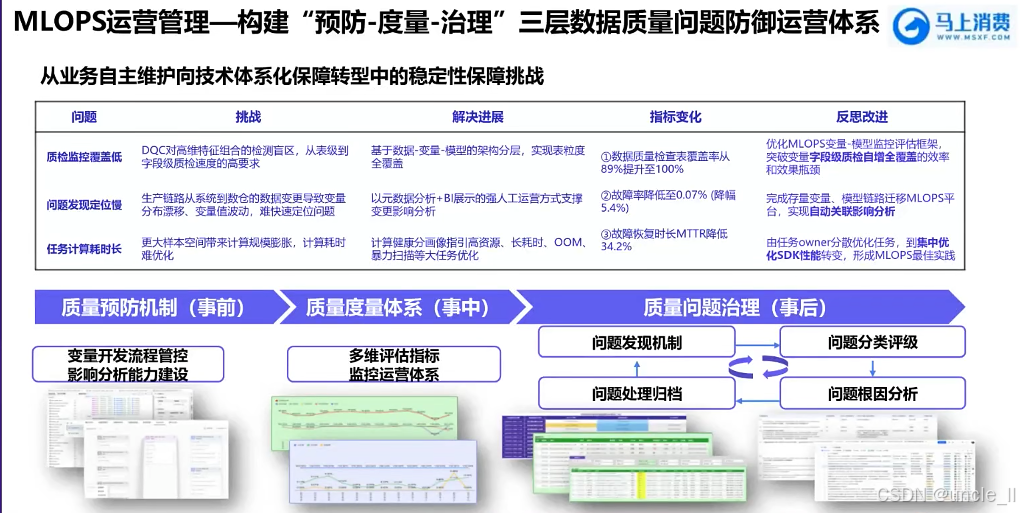
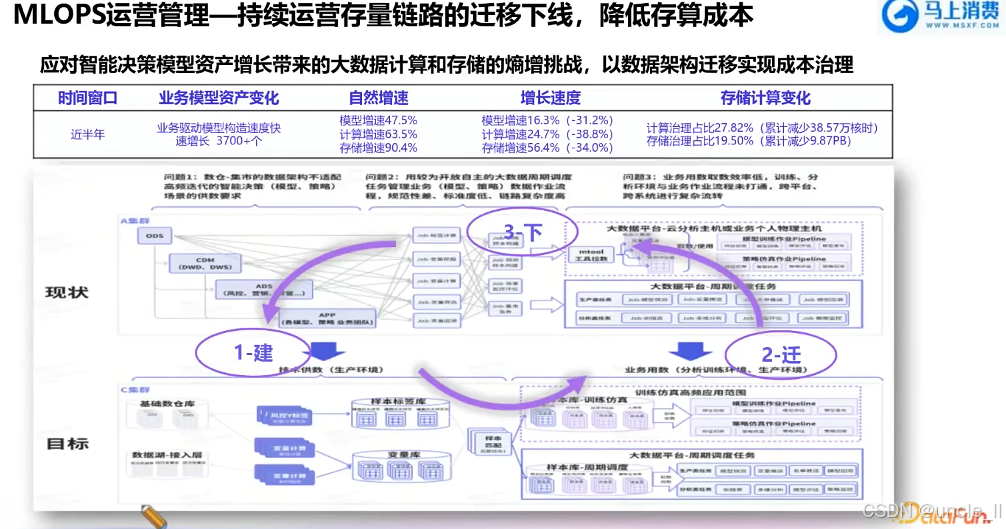
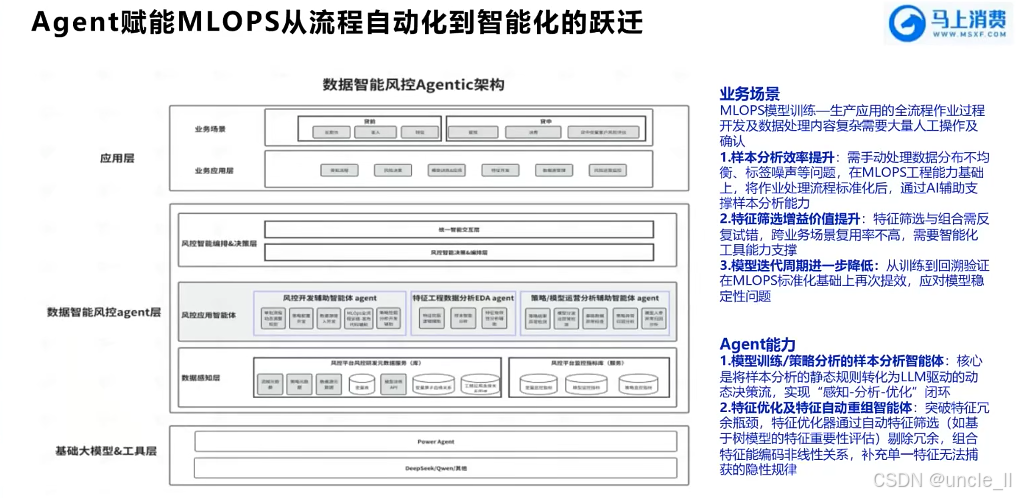
马上消费金融——MLOPS工程化能力建设实践
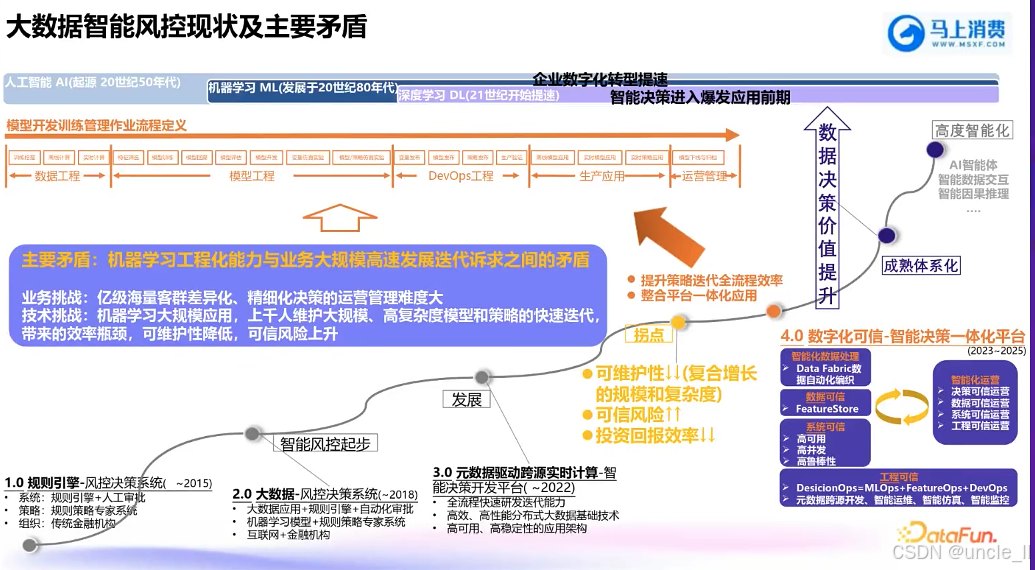
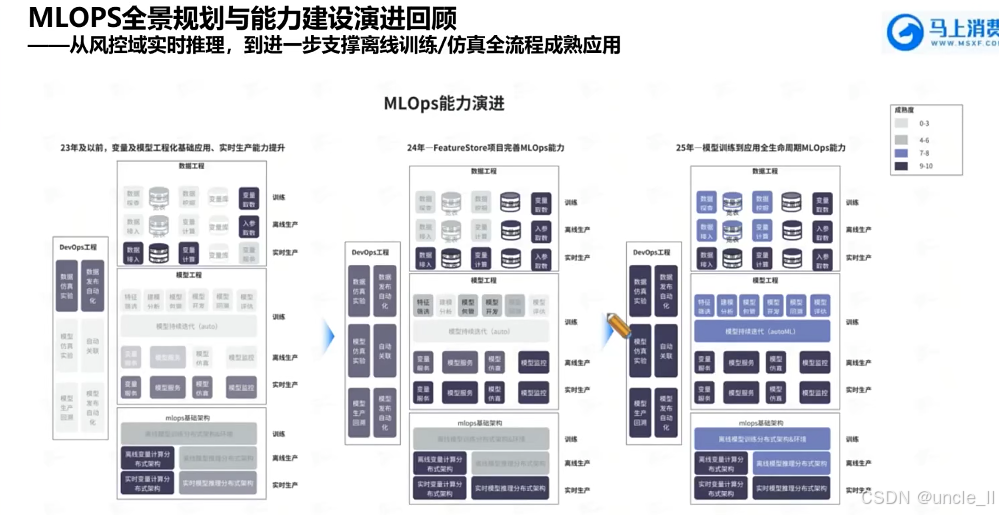

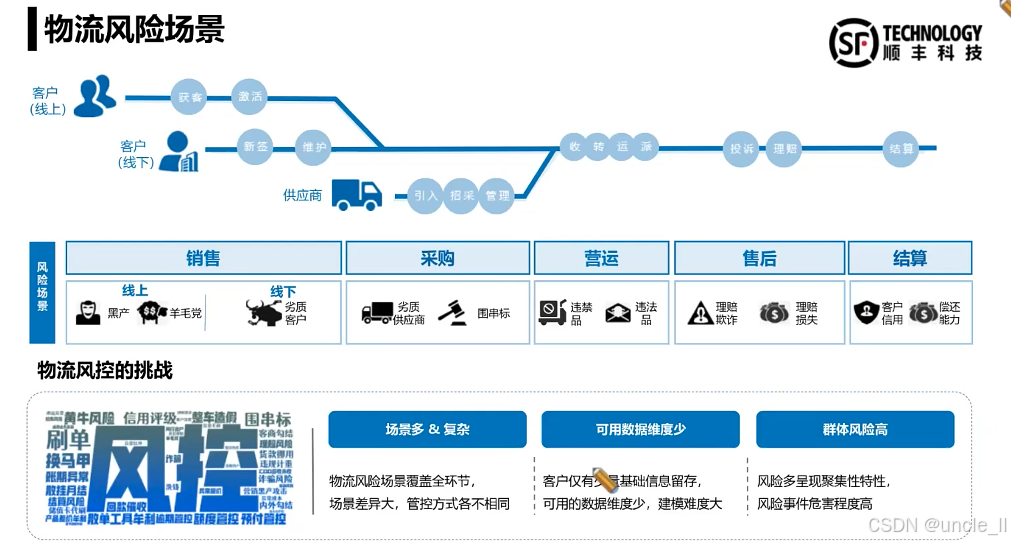
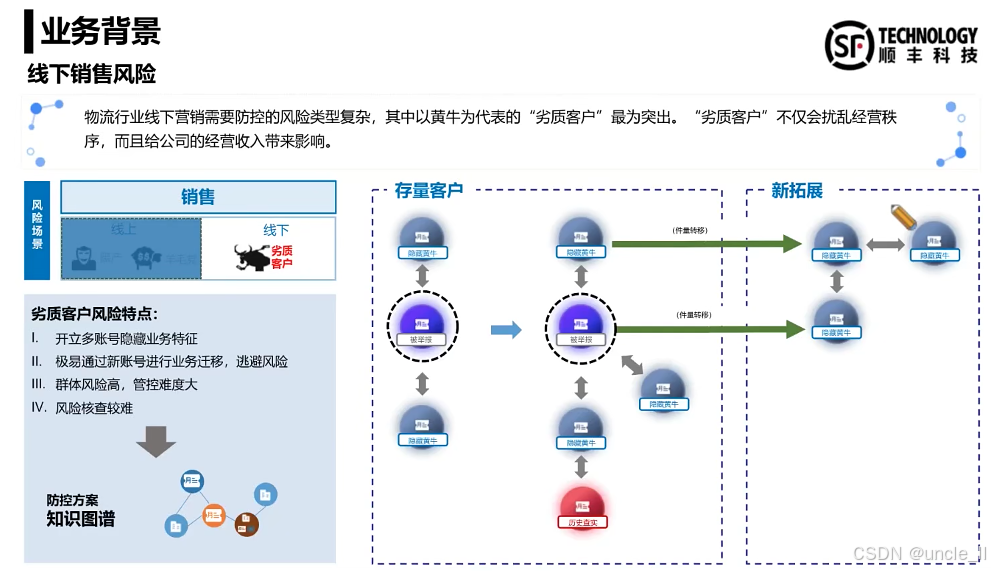
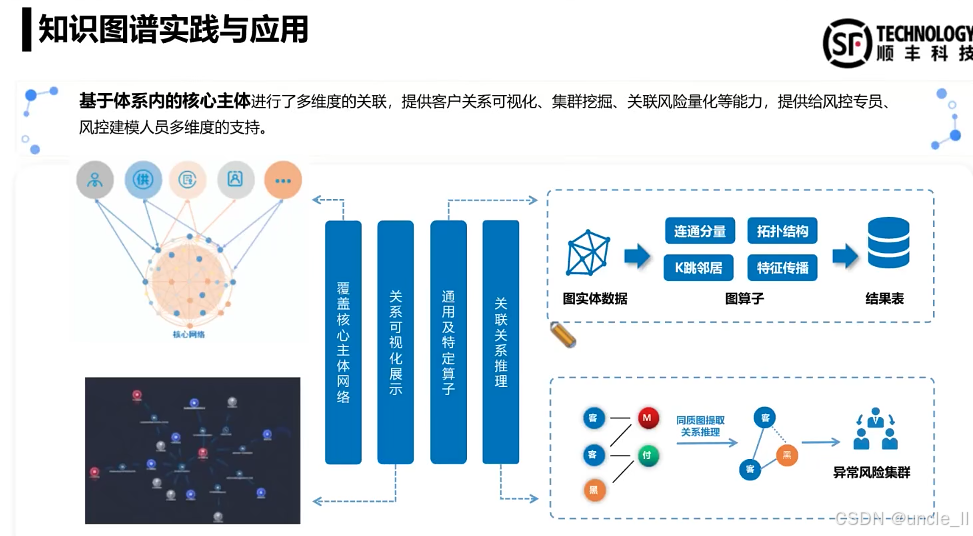
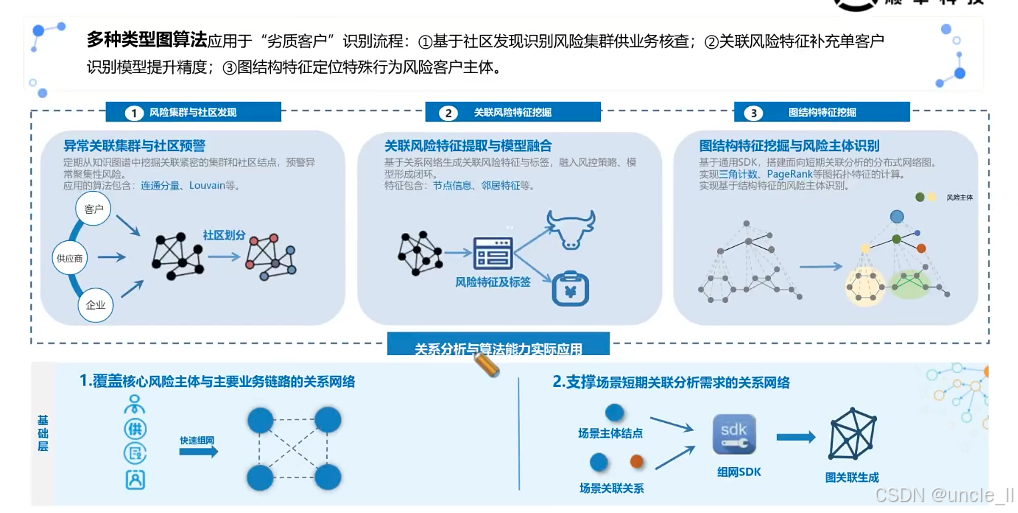
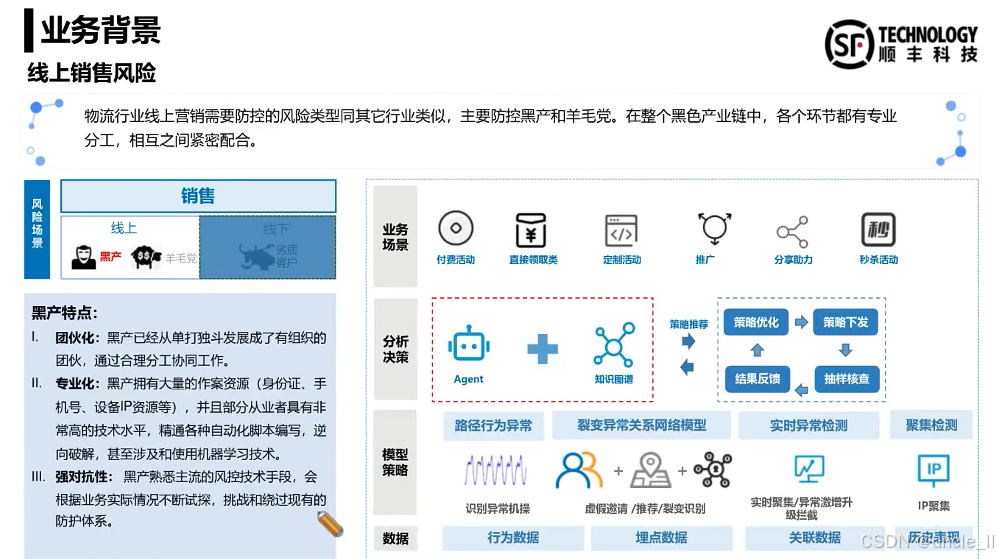
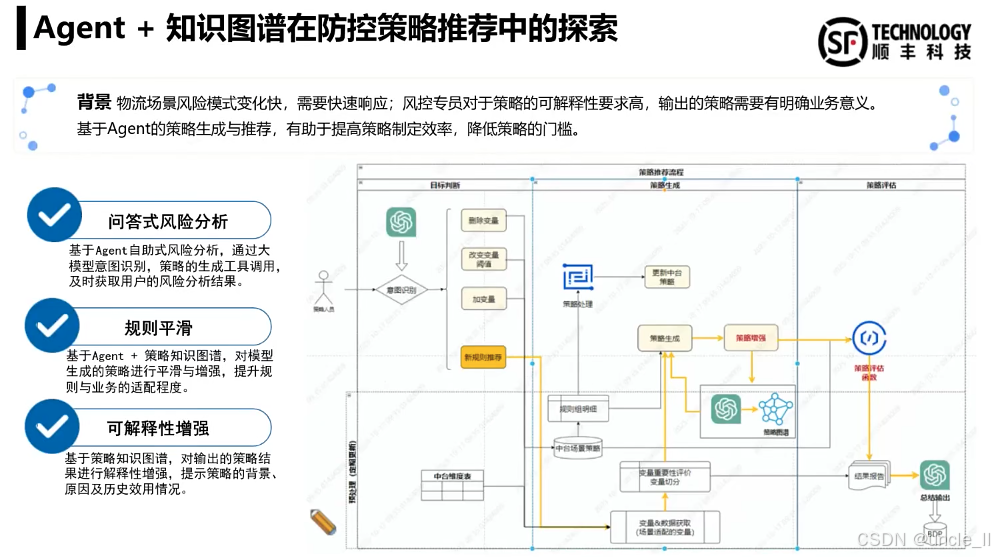
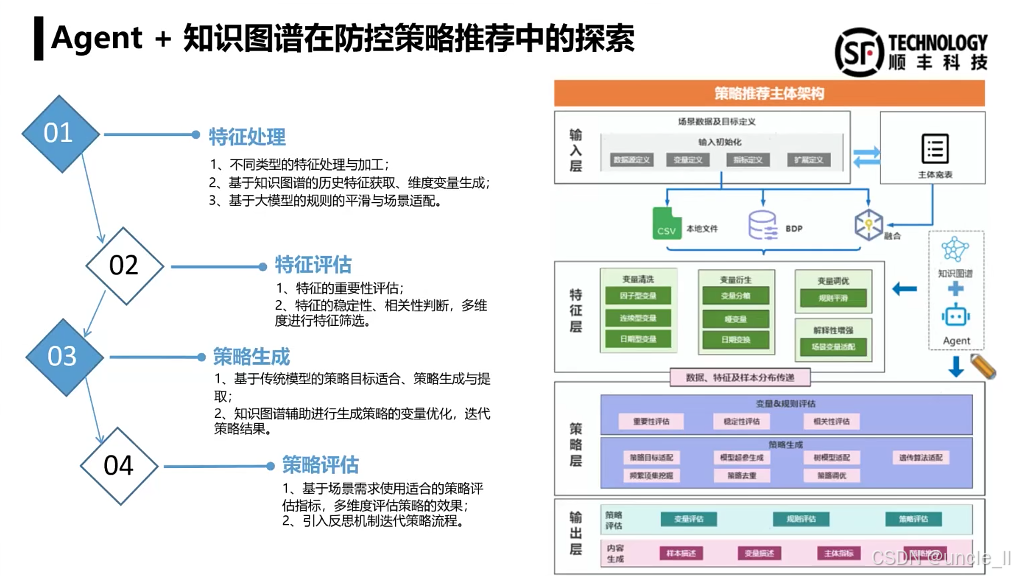
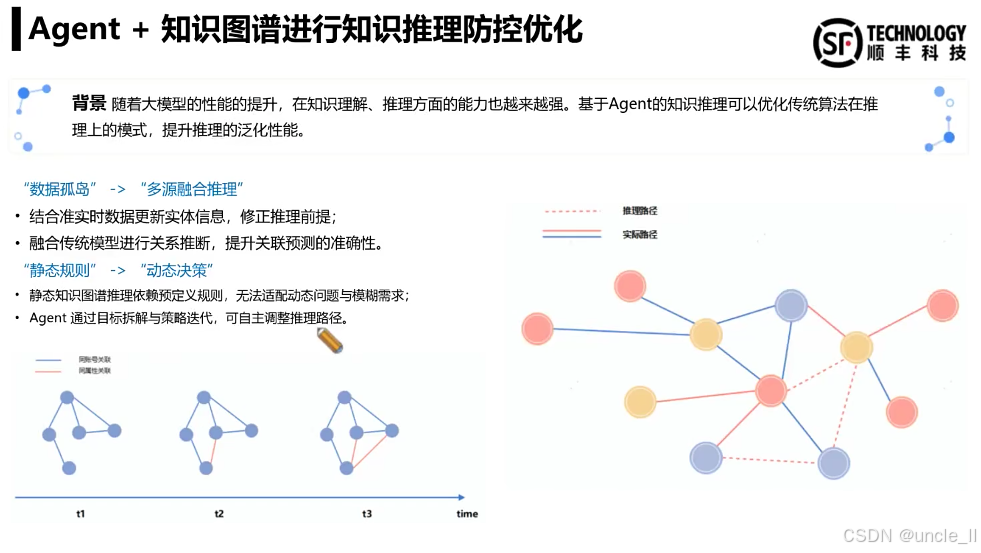
顺丰——物流风险