Qwen3VL源码侧改进点及DeepStack核心思想概述
首先从源码角度看Qwen3VL的改进,核心围绕增强多模态融合深度(DeepStack)、优化视觉特征处理、提升时序建模精度(视频时间戳编码)以及精细化归一化设计(文本专用RMSNorm),整体更注重多模态任务中的特征对齐与深层交互。然后概述DeepStack用于多模态大模型的核心思想。
往期相关:Qwen-VL系列多模态大模型技术演进-模型架构、训练方法、数据细节
Qwen3VL源码侧改进点
代码侧改动如下:
hidden_act="silu"->hidden_act="gelu_pytorch_tanh"
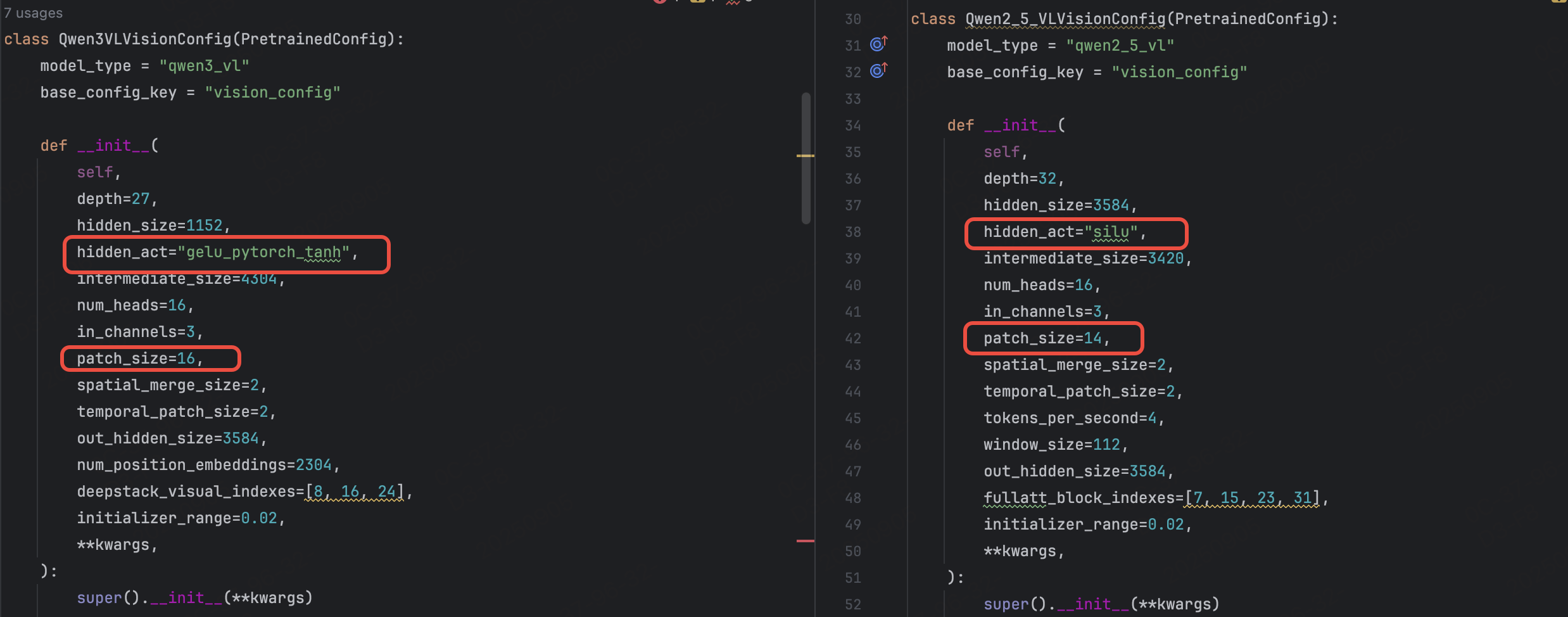
- Qwen3VLProcessor引入
Qwen3VLVideoProcessor,更加适配视频处理
- 视觉块归一化层调整
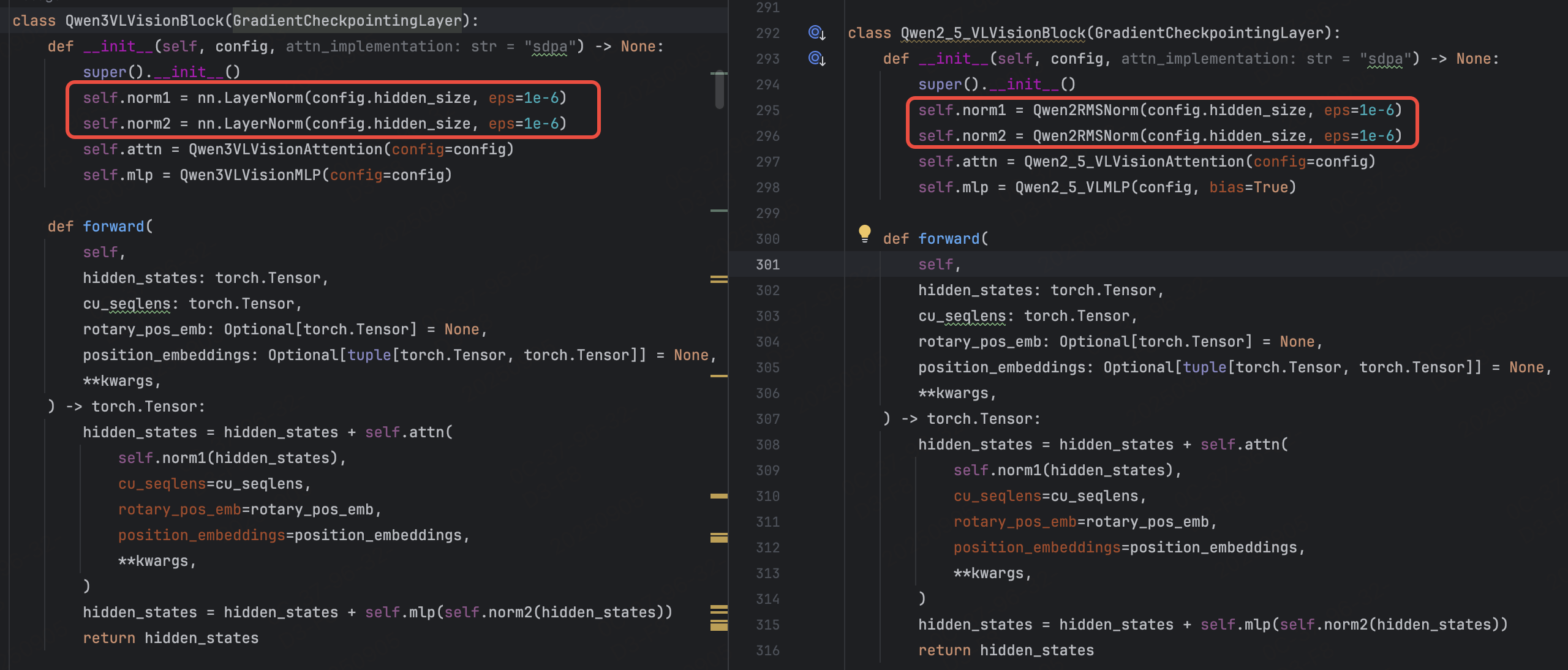
- Qwen2.5VL:视觉块(
Qwen2_5_VLVisionBlock)使用Qwen2RMSNorm作为归一化层(一种RMSNorm变体)。 - Qwen3VL:视觉块(
Qwen3VLVisionBlock)改用nn.LayerNorm(标准层归一化)。这一调整可能是为了更好地适配视觉特征的分布特性,提升训练稳定性或特征表达能力。
- 引入DeepStack多模态融合机制
-
Qwen3VL在文本模型(
Qwen3VLTextModel)中新增了DeepStack机制(DeepStack机制能让视觉信息更深度地参与文本解码过程,提升多模态理解的连贯性。),通过_deepstack_process方法将视觉特征(deepstack_visual_embeds)融入解码器的多个隐藏层。在解码器层的前向传播中,会在指定层将视觉特征叠加到对应位置的文本隐藏状态上:# Qwen3VLTextModel.forward if deepstack_visual_embeds is not None and layer_idx in range(len(deepstack_visual_embeds)):hidden_states = self._deepstack_process(hidden_states, visual_pos_masks, deepstack_visual_embeds[layer_idx]) -
Qwen2.5VL视觉特征仅在输入嵌入阶段替换占位符 token,未在解码器深层进行融合。
- 视频时序位置编码优化
-
Qwen2.5VL:在
get_rope_index中,视频的时序位置编码基于绝对时间间隔(如second_per_grid_t * tokens_per_second),直接计算时序索引。 -
Qwen3VL:修改了视频时序处理逻辑,通过时间戳(而非绝对时间位置)区分视频帧,将
video_grid_thw重复展开并强制时序维度为1(video_grid_thw[:, 0] = 1),时序信息通过外部时间戳 token 传递:# Qwen3VLModel.get_rope_index if video_grid_thw is not None:video_grid_thw = torch.repeat_interleave(video_grid_thw, video_grid_thw[:, 0], dim=0)video_grid_thw[:, 0] = 1 # 时序维度固定为1,依赖时间戳区分
- 视觉特征分层输出与融合
-
Qwen3VL:视觉模型(
Qwen3VLVisionModel)的get_image_features和get_video_features不仅返回最终视觉嵌入,还返回分层视觉特征(deepstack_image_embeds/deepstack_video_embeds),用于DeepStack机制在解码器多层融合:# Qwen3VLModel.get_image_features image_embeds, deepstack_image_embeds = self.visual(pixel_values, grid_thw=image_grid_thw) -
Qwen2.5VL:仅返回单一视觉嵌入,无分层特征输出。分层特征融合能让不同层级的视觉信息(如低级纹理、高级语义)分别参与文本解码,提升多模态对齐精度。
- 文本RMSNorm的独立优化
-
Qwen3VL:新增
Qwen3VLTextRMSNorm类,专门针对文本部分优化RMSNorm,明确注释其与T5LayerNorm等效,并通过@use_kernel_forward_from_hub("RMSNorm")引入可能的 kernel 优化:@use_kernel_forward_from_hub("RMSNorm") class Qwen3VLTextRMSNorm(nn.Module):def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:input_dtype = hidden_states.dtypehidden_states = hidden_states.to(torch.float32)variance = hidden_states.pow(2).mean(-1, keepdim=True)hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)return self.weight * hidden_states.to(input_dtype) -
Qwen2.5VL:文本和视觉共享
Qwen2RMSNorm,未针对文本单独优化。文本RMSNorm的独立设计可更精细地适配文本特征分布,提升语言建模能力。
DeepStack
大多数多模态模型通过将视觉 token 作为序列输入到LLM的第一层来实现。这种架构虽然简单,但显著增加了计算 和内存成本,因为其输入层需要处理大量额外的 token。DeepStack考虑到 LMMs 中语言和视觉 Transformer 的 N 层,将视觉 token 堆叠成 N 组,并将每组从下到上依次输入到其对应的 Transformer 层.
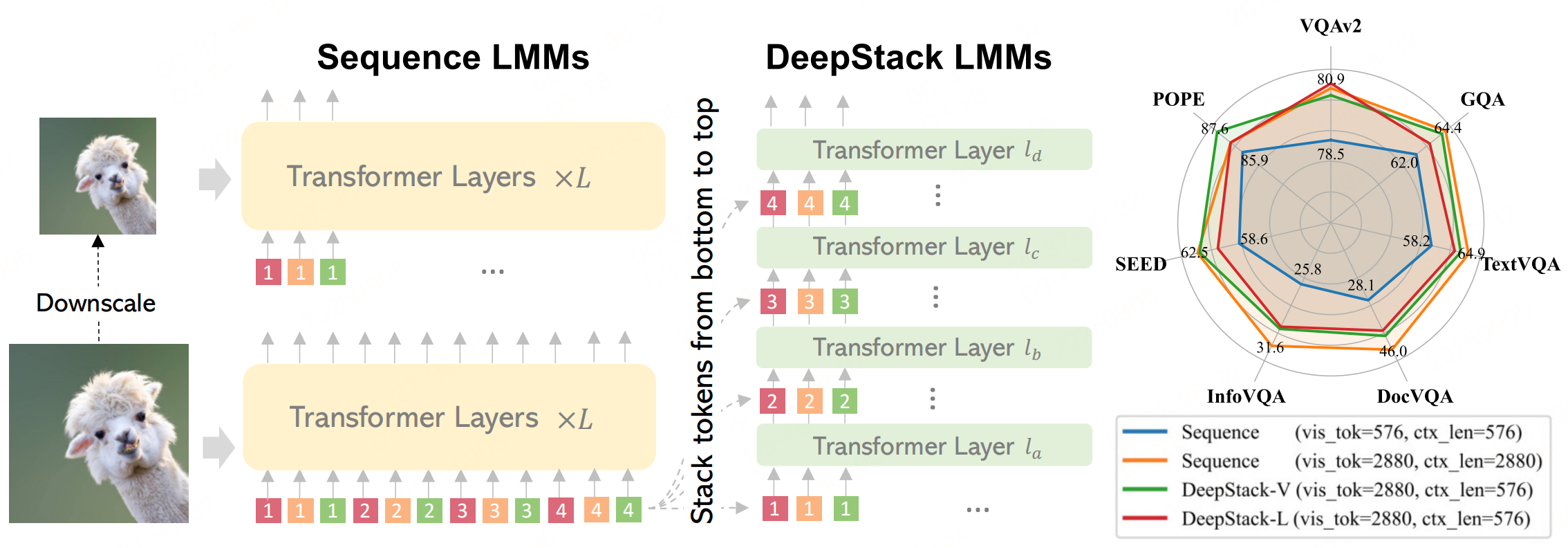
- 如上左图:传统的大型多模态模型将所有视觉 token 串接成一个序列,适用 于高分辨率和低分辨率图像。
- 中间图: DeepStack LMMs 将 token 堆叠成网格,并自下而上地将其注入到 Transformer 的前几层和中间层,仅通过残差连接实现。
- 右图:将 DeepStack 应用于 Vicuna-7B(DeepStack-L)和 CLIP ViT-L(DeepStack-V),模型能够接受 4× 倍的视觉 token,在相同的上下文长度下显著超 越序列式 LMM,并在广泛的基准测试中与使用更长上下文的模型相媲美。
架构
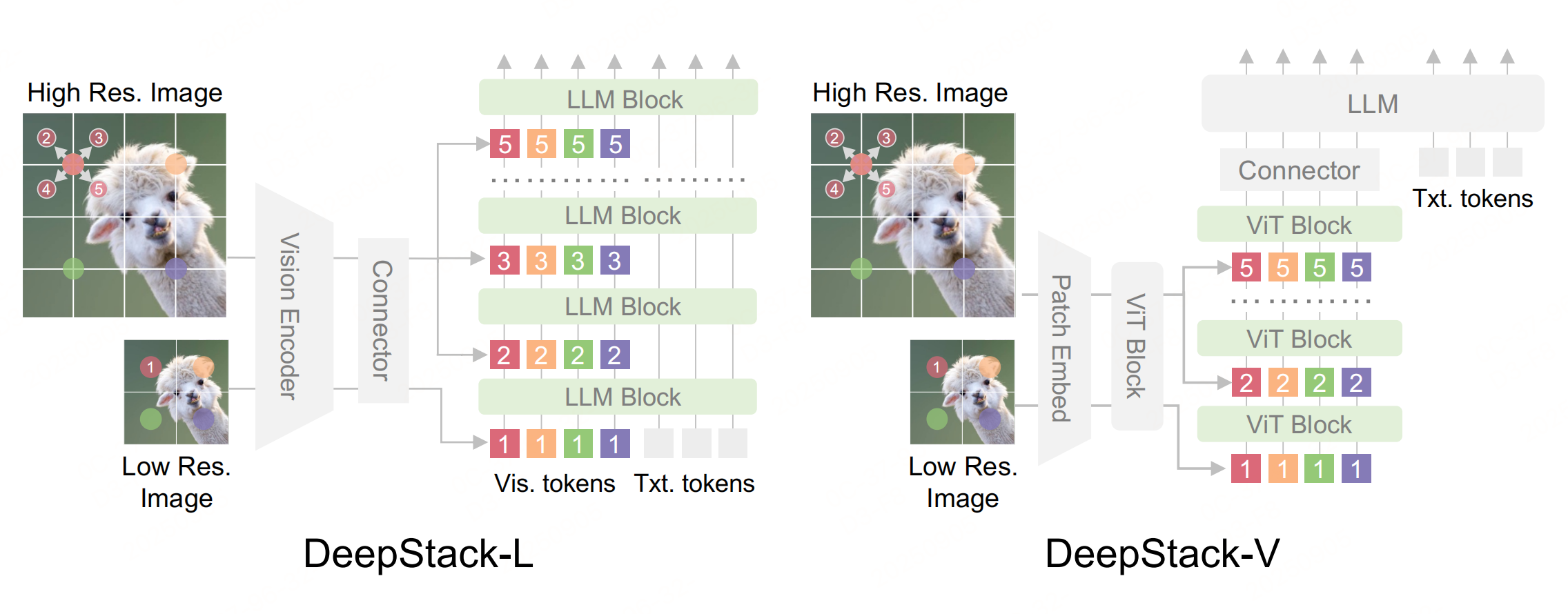
主要创新在于 DeepStack 策略(通过将图像特征抽取分为两个流来实现这一点:一个全局视图流用于捕捉全局信息,另一个高分辨率流通过在不同层的大模型中堆叠扩张的高分辨率图像特征来增强全局信息。),该策略将视觉 token 注入到不同的层中。大白话:DeepStack 的本质是利用 Transformer 的分层架构特性,将视觉 token 的 “整合过程” 分散到 LLM 的多层中。
-
左图:用于大模型的 DeepStack :给定输入图像,将从低分辨率版本中提取的 token 输入到大模型的输入层。考虑到图像的二维特性,从高分辨率版本中提取相邻区域,并将其重新组织为DeepStack ,然后将其输入到大模型的后续层中。
-
右图:用于 ViTs 的 DeepStack :采用类似的采样策略,但将视觉 token 输入到视觉编码器的 ViT 层中。DeepStack-V 的适配逻辑:利用 ViTs 的编码器分层结构,将高分辨率视觉 token 注入 ViTs 的中间层,而非仅在输入层(PatchEmbed)处理,增强 ViTs 的细粒度特征提取能力。
多模态大模型基于投影的连接模块获得了视觉标记,DeepStack策略就是如何在保持多模态处理有效的同时提供信息丰富的视觉标记。
DeepStack PyTorch伪代码:

def forward(H0, Xstack, lstart, n, vis_pos):H = H0 # LLM初始隐藏态(含全局视觉token+文本token)for (idx, TransformerLayer) in enumerate(self.layers):# 满足条件时,注入高分辨率堆叠token(残差连接)if idx >= lstart and (idx - lstart) % n == 0:stack_idx = (idx - lstart) // n # 对应Xstack的索引H[vis_pos] += Xstack[stack_idx] # vis_pos:视觉token在隐藏态中的位置# 正常执行LLM的Transformer层计算H = TransformerLayer(H)return H
参考文献
- https://github.com/huggingface/transformers/blob/cbb290ec23ccd9b5c1d1ff4d333477449891debb/src/transformers/models/qwen3_vl/processing_qwen3_vl.py#L37
- DeepStack: Deeply Stacking Visual Tokens is Surprisingly Simple and Effective for LMMs,https://arxiv.org/pdf/2406.04334