基于高通跃龙 QCS6490 平台的Sherpa快速部署
文章介绍
Sherpa-onnx工具如何在 Linux 系统上构建和安装,是该文档介绍的重点。用户可根据硬件环境选择 CPU 或 GPU 加速方式。而在此以CPU方式为例,分别对构建和安装步骤进行完整的介绍。整体而言,这是一份面向开发者的实用指南,帮助用户快速上手并将 sherpa-onnx 集成到语音交互系统、智能设备或嵌入式应用中,提升语音处理能力与响应效率。
本文还分别以语音转文字、文字转语音等预训练模型的使用步骤为示例,展示了如何在部署Sherpa-onnx工具后快速上手工具中所包含的模型与功能。
前置条件
- 高通跃龙 QCS6490 平台 (RubikPi)
- 各平台账号,如:GitHub等
1. 为 QCS6490 构建和安装 Sherpa-onnx
- 源码编译构建安装
Linux-CPU Installation
此构建过程为CPU(Linux x64 or Linux arm64),按照如下命令分别执行:
git clone https://github.com/k2-fsa/sherpa-onnx
cd sherpa-onnx
mkdir build
cd build
cmake -DCMAKE_BUILD_TYPE=Release ..
make –j6注意:如果你的 GCC 编译器版本小于或等于10(例如使用 Ubuntu ≤ 18.04 或 CentOS ≤ 7),请使用以下命令来构建共享库,否则你可能会遇到来自 libonnxruntime.a 的链接错误
cmake -DCMAKE_BUILD_TYPE=Release -DBUILD_SHARED_LIBS=ON ..构建进度100%且无报错即表示安装成功。
- Python安装库及依赖包
Python-CPU Installation
在设备终端中运行以下命令:
pip install sherpa-onnx sherpa-onnx-bin
python3 -c "import sherpa_onnx; print(sherpa_onnx.__file__)"
which sherpa-onnx
sherpa-onnx --help
ls -lh $(dirname $(which sherpa-onnx))/sherpa-onnx*运行指令后无报错得到对应输出即可。
注:可以在以下位置找到以前的版本 https://k2-fsa.github.io/sherpa/onnx/cpu.html
若无法访问 huggingface 的用户,请访问 https://k2-fsa.github.io/sherpa/onnx/cpu-cn.html。
可以使用:
pip install sherpa-onnx sherpa-onnx-bin -f https://k2-fsa.github.io/sherpa/onnx/cpu.html或:
pip install sherpa-onnx sherpa-onnx-bin -f https://k2-fsa.github.io/sherpa/onnx/cpu-cn.html2. 预训练模型示例
- 语音转文字 - Speech recognition (speech to text, ASR)
Sherpa-onnx ASR
在终端窗口输入以下命令:
cd sherpa-onnx
wget https://github.com/k2-fsa/sherpa-onnx/releases/download/asr-models/sherpa-onnx-streaming-zipformer-zh-xlarge-int8-2025-06-30.tar.bz2
tar xvf sherpa-onnx-streaming-zipformer-zh-xlarge-int8-2025-06-30.tar.bz2
rm sherpa-onnx-streaming-zipformer-zh-xlarge-int8-2025-06-30.tar.bz2
ls -lh sherpa-onnx-streaming-zipformer-zh-xlarge-int8-2025-06-30检查下载的文件大小,可以得到以下结果正常:

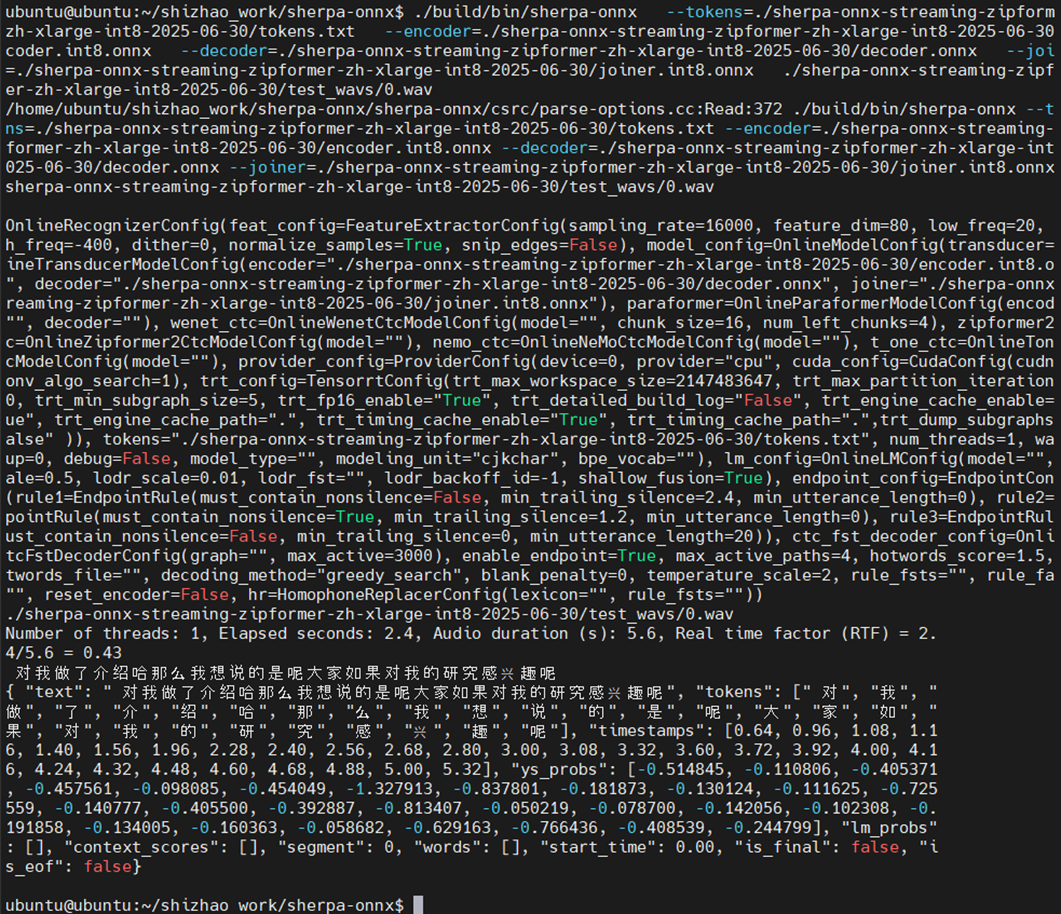
预训练模型准备好后,按照下面的参数格式执行命令:
./build/bin/sherpa-onnx \--tokens=./sherpa-onnx-streaming-zipformer-zh-xlarge-int8-2025-06-30/tokens.txt \--encoder=./sherpa-onnx-streaming-zipformer-zh-xlarge-int8-2025-06-30/encoder.int8.onnx \--decoder=./sherpa-onnx-streaming-zipformer-zh-xlarge-int8-2025-06-30/decoder.onnx \--joiner=./sherpa-onnx-streaming-zipformer-zh-xlarge-int8-2025-06-30/joiner.int8.onnx \./sherpa-onnx-streaming-zipformer-zh-xlarge-int8-2025-06-30/test_wavs/0.wav最终可以得到以下语音识别的结果:
- 文字转语音 - Text to speech (TTS)
Sherpa-onnx TTS
在终端窗口输入以下命令:
cd sherpa-onnx
wget https://github.com/k2-fsa/sherpa-onnx/releases/download/tts-models/matcha-icefall-en_US-ljspeech.tar.bz2
tar xvf matcha-icefall-en_US-ljspeech.tar.bz2
rm matcha-icefall-en_US-ljspeech.tar.bz2
wget https://github.com/k2-fsa/sherpa-onnx/releases/download/vocoder-models/vocos-22khz-univ.onnx同样检查下载的文件大小,看到结果正常即可。
ls -lh matcha-icefall-en_US-ljspeech/预训练模型准备好后,按照下面的参数格式执行命令:
./build/bin/sherpa-onnx-offline-tts \--matcha-acoustic-model=./matcha-icefall-en_US-ljspeech/model-steps-3.onnx \--matcha-vocoder=./vocos-22khz-univ.onnx \--matcha-tokens=./matcha-icefall-en_US-ljspeech/tokens.txt \--matcha-data-dir=./matcha-icefall-en_US-ljspeech/espeak-ng-data \--num-threads=2 \--output-filename=./matcha-ljspeech-0.wav \--debug=1 \"Today as always, men fall into two groups: slaves and free men. Whoever does not have two-thirds of his day for himself, is a slave, whatever he may be: a statesman, a businessman, an official, or a scholar."最终可以得到一个音频文件: matcha-ljspeech-0.wav
检查文件信息亦可播放进行检查:
soxi ./matcha-ljspeech-0.wav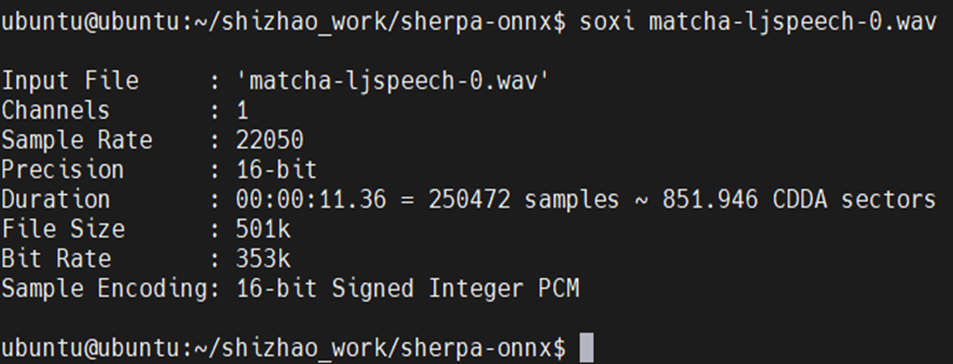
作者:
高通工程师,赵世朝(Shizhao Zhao)