SD comfy:教程1
目录
- 0 基本原理
- 1 操作简介:从 文生图 开始
- 1.1 基本概念、操作
- 1.2 K采样器
- 1.3 工作流程举例
- 2. 关于面部修复
- 2.1. 下载结点库
- 2.2 准备模型
- 2.3 关键流程
- 3. 手部修复
- 3.1 下载结点库
- 3.2 下载模型
- 3.3 代码修复
- 3.4 工作流程举例
- 4. 扩充边缘
- 4.1 下载模型
- 4.2 工作流程举例
- 5. 图像放大-潜在空间放大后重绘
- 5.1 下载模型
- 5.2 工作流程举例
- 6. 图像放大-使用模型放大图像
- 6.1 下载模型
- 6.2 工作流程举例
- 6.3 放大模型补充
- 7. LoRa
- 7.1 简单示意
- 8. Control net
- 8.1 模型
- 8.2 工作流程举例
- 9. 从图像获取 深度图、姿态图等
- 9.1 深度图为例
- 9.2 结点快速查阅
- 注1:首次运行会自动下载东西
- 9.3 工作流程举例
- 9.4 关于 control net 模型
- 9.4.1 复用 WebUI 的
- 9.4.2 下载
- 9.4.3 类型
- 几何类(形状 / 空间)
- 边缘 / 线稿类
- 语义 / 区块类
- 像素级重绘类
- 风格 / 抽象类
- 10. 局部重绘(以脸部一致为例)
- 10.1 结点下载
- 10.2 模型下载
- 10.3 流程举例
- 10.4 注:问题修复
0 基本原理
本章介绍的内容是为了在搭建 Comfy UI 流程中,进行节点组合时提供一个思考的原点。
-
一句话说明生图原理
在stable diffusion Comfy UI 中:
(1)K采样器负责调用“去噪模型”,处理的是潜在空间的张量。
(2)VAE编码、译码负责像素空间与潜在空间之间的转换。
(3)CLIP 是文本“编码器”,用于将字符串转为语义张量,在生图过程中通过核心是通过 cross-attention 来将语义融入“去噪模型”的中间层的张量中。 -
补充1:空间
| 名称 | 说明 |
|---|---|
像素空间 | 指图像的原始 RGB 表示,每个像素用 3×8 bit 存储,分辨率多大就占多少显存;所有「可见」操作(裁切、调色、放大)都发生在这里。 |
潜在空间 | 扩散模型为节省算力把 512×512×3 图像经 VAE 压缩成 64×64×4 的隐向量网格,所有去噪迭代在此低维空间完成,生成后再解码回像素。 |
| 语义空间 | CLIP 把任意文本或图像映射到的 77×768 向量空间,距离≈语义相似度;文本提示、负面提示、图像反推都在此比较。 |
- 补充2:基础结构
| 名称 | 说明 |
|---|---|
| 去噪模型 | 通常指 U-Net / DiT 等可学习网络,负责在潜在空间预测每一步该减多少噪声;权重最大,也是微调/LoRA/ControlNet 的改造对象。 |
| K采样器 | ComfyUI/Stable-Diffusion 对「扩散采样算法」的封装节点,内置 Euler、DPM++、UniPC 等 Schedule,把去噪模型当黑盒反复调用直至 T=0。 |
| VAE编码 | 把像素图→潜在图:VAE-Encoder 做 8×8 卷积下采样 + 量化,输出均值/方差,再采样得到 64×64×4 潜码;图生图、img2img 第一步即此。 |
| VAE译码 | 把潜在图→像素图:VAE-Decoder 做 8×8 转置卷积上采样,得到 512×512×3 RGB;文生图最后一步、潜图放大后均须调用。 |
- 补充3:其他
| 名称 | 说明 |
|---|---|
| CLIP | OpenAI 训练的双塔模型,文本塔把提示词变语义向量,图像塔把图片变语义向量;扩散模型只用文本塔输出作为条件,驱动去噪方向。 |
| LoRa | Low-Rank Adaptation:对 Attention 的 Q/K/V/FFN 矩阵增加可训练低秩旁路 A×B,主权重冻结;用极少量参数让模型“记住”新风格/人物/对象。 |
| ControlNet | 给去噪模型加一条“条件图”旁路,用零卷积/零映射把边缘、深度、姿态等空间信息逐层注入 U-Net 特征,实现结构控制而不改语义。 |
| Mask(像素) | 单通道 0-1 图,白色=要重绘的区域;直接在像素层涂黑留白,用于手修或 Photoshop 导入。 |
| Mask(潜在) | 把 512×512 mask 下采样 8 倍成 64×64,与潜码同分辨率;ComfyUI 的 Set Latent Noise Mask 即此,节省显存且避免边缘色差。 |
| 局部重绘 (Inpainting) | 流程:①用 mask 标记待改区域→②将其潜码置纯噪或部分噪→③仅对白区去噪,黑区保持原潜码→④解码后得到“只改 mask 内”的新图。 |
| 蒙版模糊 (Mask Blur) | 对 mask 边缘做高斯模糊,使新旧边界过渡自然;值越大融合区越宽,可防止“硬边”或“接缝”。 |
| 蒙版扩展 (Mask Grow/Shrink) | 按像素级膨胀/腐蚀 mask,用于“多画一点”或“少画一点”;常与模糊配合使用,控制重绘安全区。 |
| Inpaint Model | SD 官方发布的专用 inpainting 版 U-Net,输入通道 9 个(原 4+mask 1+噪 4),能更好理解“哪些像素该保留”;ComfyUI 可直接加载。 |
| IPAdapter | 本质上是 将一张参考图像的视觉特征“注入”到扩散模型的交叉注意力层中,从而让生成图像在风格、构图或人物面貌上“参考”这张图,而不需要像 LoRA 那样额外训练。 |
1 操作简介:从 文生图 开始
1.1 基本概念、操作
| 名称 | 作用 | 操作方法 |
|---|---|---|
| 结点 | ComfyUI 的最小功能单元,封装了“做什么”与“怎么做”。 常见类型: • 模型加载器(Checkpoint Loader):载入 .safetensors/.ckpt 大模型; • CLIP 文本编码器:把正向/负向提示词转为条件向量; • 空 Latent:指定出图尺寸、批次; • K 采样器:执行去噪循环,输出潜空间图像; • VAE 解码/编码:潜空间⇄像素空间; • 保存图像:把结果写入硬盘; • 自定义节点:IPAdapter、ControlNet、LoRA 等扩展功能。 | 1. 添加:① 双击空白处→搜索节点名;② 或右键空白→“新建节点”→选类别。 2. 配置:点击节点右侧参数框,输入数值/下拉选择模型或路径。 3. 删除:选中节点→Delete;复制:Ctrl+C / Ctrl+V。 4. 替换模型:在“Checkpoint Loader”等节点下拉框直接切换,无需重建流程。 |
| 连线 | 定义数据流向与执行顺序,左侧“输入端口”接收数据,右侧“输出端口”发送数据;颜色/形状相同的端口才能相连,确保类型匹配(MODEL、CLIP、LATENT、IMAGE 等)。 | 1. 连线:按住左键从输出端口拖到输入端口,出现高亮提示后松开即可。 2. 改线:先点连线→Delete,再重新拖线;或按住 Alt 用鼠标拖出新线覆盖旧线。 3. 多线输出:同一输出端口可拖向多个输入端口,实现并行分支。 4. 隐藏/显示:底部工具栏“小眼睛”图标或快捷键 C,可隐藏/恢复全部连线,方便查看复杂流程。 |
| 工作流 | 由节点与连线构成的完整“配方”,描述从模型加载、条件输入、采样到出图的整个 pipeline。可保存为 *.json 模板,一键复现或分享。 | 1. 新建:启动 ComfyUI 自动给出默认文生图流程;或点击“清除”后自行搭建。 2. 保存:菜单“Export”→命名.json,存到本地;或拖入画布直接加载。 3. 载入:① 菜单“Load”;② 直接拖 .json 文件到界面;③ 从社区(如 OpenArt、Civitai)复制 JSON 粘贴。 4. 管理:安装 ComfyUI-Manager 插件,可“一键安装缺失节点”“更新工作流依赖”。 |
| 组 | 把多个节点打包成一块彩色区域,用于逻辑分块、注释说明、批量移动,提升大型流程可读性。 | 1. 创建:框选节点→右键→“新建组”→输入标题、选颜色。 2. 编辑:双击组标题可改名;拖动边缘调整大小;右键可改颜色/删除组(不删节点)。 3. 嵌套:组内可再选子节点建子组,形成层级结构。 4. 折叠:点击组标题栏左侧小三角,可收起/展开,提高画布利用率。 |
1.2 K采样器
可以先创建一个K采样器结点。
- 关于 K采样器的 sampler 和 scheuler 常用组合
| sampler | scheduler | 效果 |
|---|---|---|
| euler_ancestral | normal(线性降噪) | 常规出图 |
| dpmpp_2m | karras(形如逻辑斯蒂曲线) | 质量高一些 |
| dpmpp_2m_sde | karras | 有一些变化 |
1.3 工作流程举例
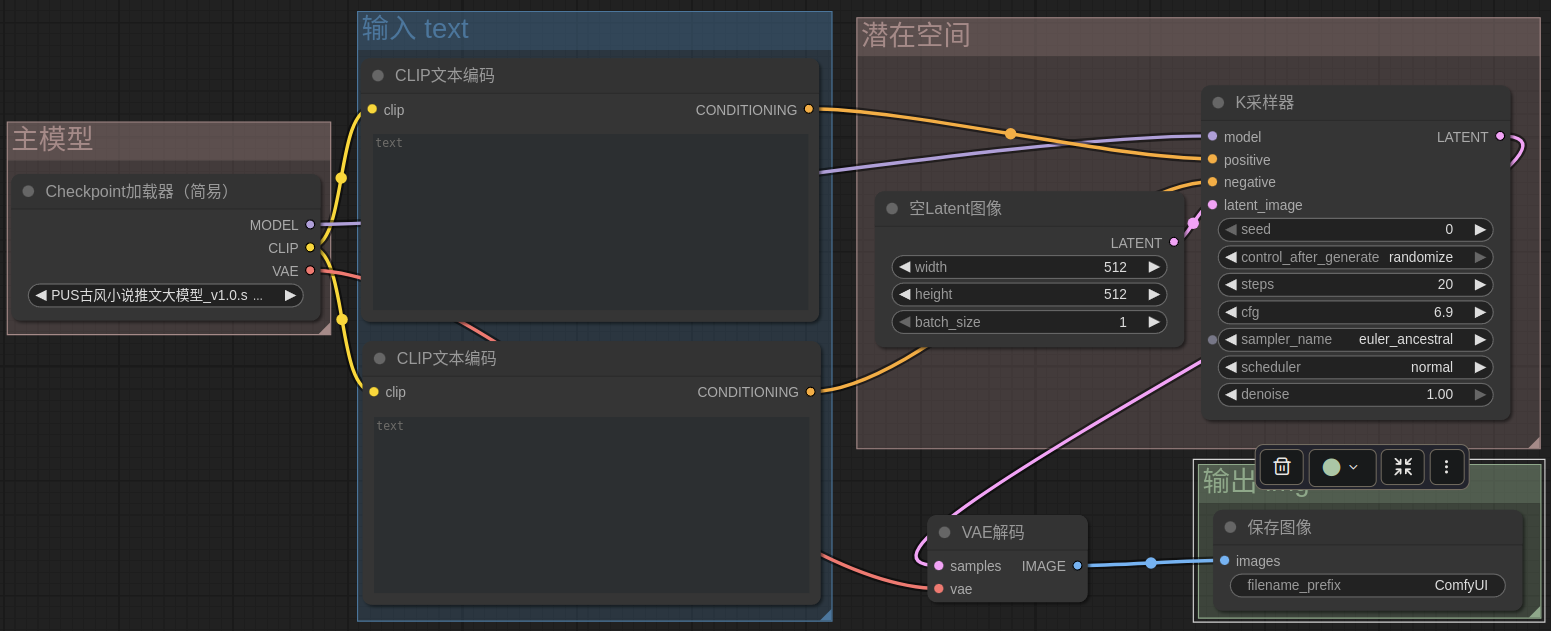
- 注
letent_image结点
潜在空间图像,可用于控制基础图像大小、出几张图VAE 解码结点
有些模型没有自带 VAE 的,也可以从结点的● vae输入端口拉出专门加载 vae 的结点- 输出结点
可以用预览图片代替
2. 关于面部修复
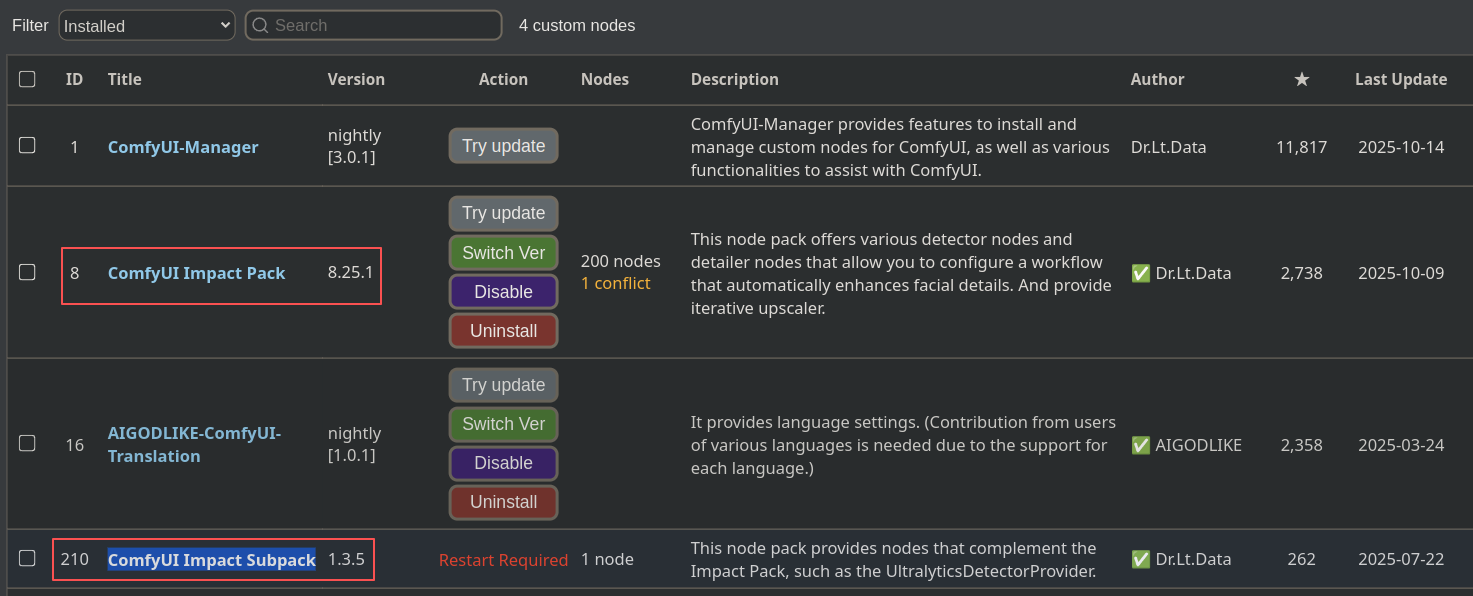
2.1. 下载结点库
搜索 Impact Pack,下载 ComfyUI Impact Pack 和 ComfyUI Impact Subpack
2.2 准备模型
- SAM 分割模型
cd ComfyUI安装位置# 新建 sam 目录
mkdir -p models/sams# 任选其一下载(vit_b 省显存,vit_h 精度高)
wget -P models/sams https://dl.fbaipublicfiles.com/segment_anything/sam_vit_b_01ec64.pth
# 或
wget -P models/sams https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth
- yolo 脸部模型
原先在 SD WebUI 中有,尝试找一下:
(1)用 find 命令在 web ui 所在文件夹没搜到
find -L . -type f -iname "*face*.pt"
(2)后查询得知可能在 ~/.cache/huggingfase 目录下
~/.cache$ ll huggingface/hub/models--Bingsu--adetailer/snapshots/53cc19de382014514d9d4038601d261a7faa9b7b/
总计 28
drwxrwxr-x 2 zkding zkding 4096 10月 4 11:50 ./
drwxrwxr-x 4 zkding zkding 4096 10月 4 13:13 ../
lrwxrwxrwx 1 zkding zkding 76 10月 4 11:50 face_yolov8n.pt -> ../../blobs/70b640f8f60b1cf0dcc72f30caf3da9495eb2fb6509da48c53374ad6806e6a9c
lrwxrwxrwx 1 zkding zkding 76 10月 4 11:50 face_yolov8s.pt -> ../../blobs/c7237eff25787377de196961140ceaed324d859ee8de5a775d93d33a0e3fab78
lrwxrwxrwx 1 zkding zkding 76 10月 4 11:50 hand_yolov8n.pt -> ../../blobs/3991202eb69e9ddcb3b9ba80cdeb41e734ffaf844403d6c9f47d515cd88c6f29
lrwxrwxrwx 1 zkding zkding 76 10月 4 11:50 person_yolov8n-seg.pt -> ../../blobs/38fc8aaae97cb6e70be4ec44770005b26ed473471362afcda62a0037d7ccf432
lrwxrwxrwx 1 zkding zkding 76 10月 4 11:50 person_yolov8s-seg.pt -> ../../blobs/53c54aec2239355faffc6c5b70d0f3d05042f386f956cbec39cec46ad456f050
(3)拷贝
mkdir -p models/ultralytics/bbox把缓存里的 5 个模型硬拷进来(去掉软链接)
cp ~/.cache/huggingface/hub/models--Bingsu--adetailer/snapshots/*/face_yolov8n.pt models/ultralytics/bbox/
cp ~/.cache/huggingface/hub/models--Bingsu--adetailer/snapshots/*/face_yolov8s.pt models/ultralytics/bbox/
cp ~/.cache/huggingface/hub/models--Bingsu--adetailer/snapshots/*/hand_yolov8n.pt models/ultralytics/bbox/
2.3 关键流程
- 关键结点:FaceDetailer,由此衍生出输入输出
- 输出的
image ●即为整体修复后的结果 - 输入的
● positive和● negative是对脸部的描述
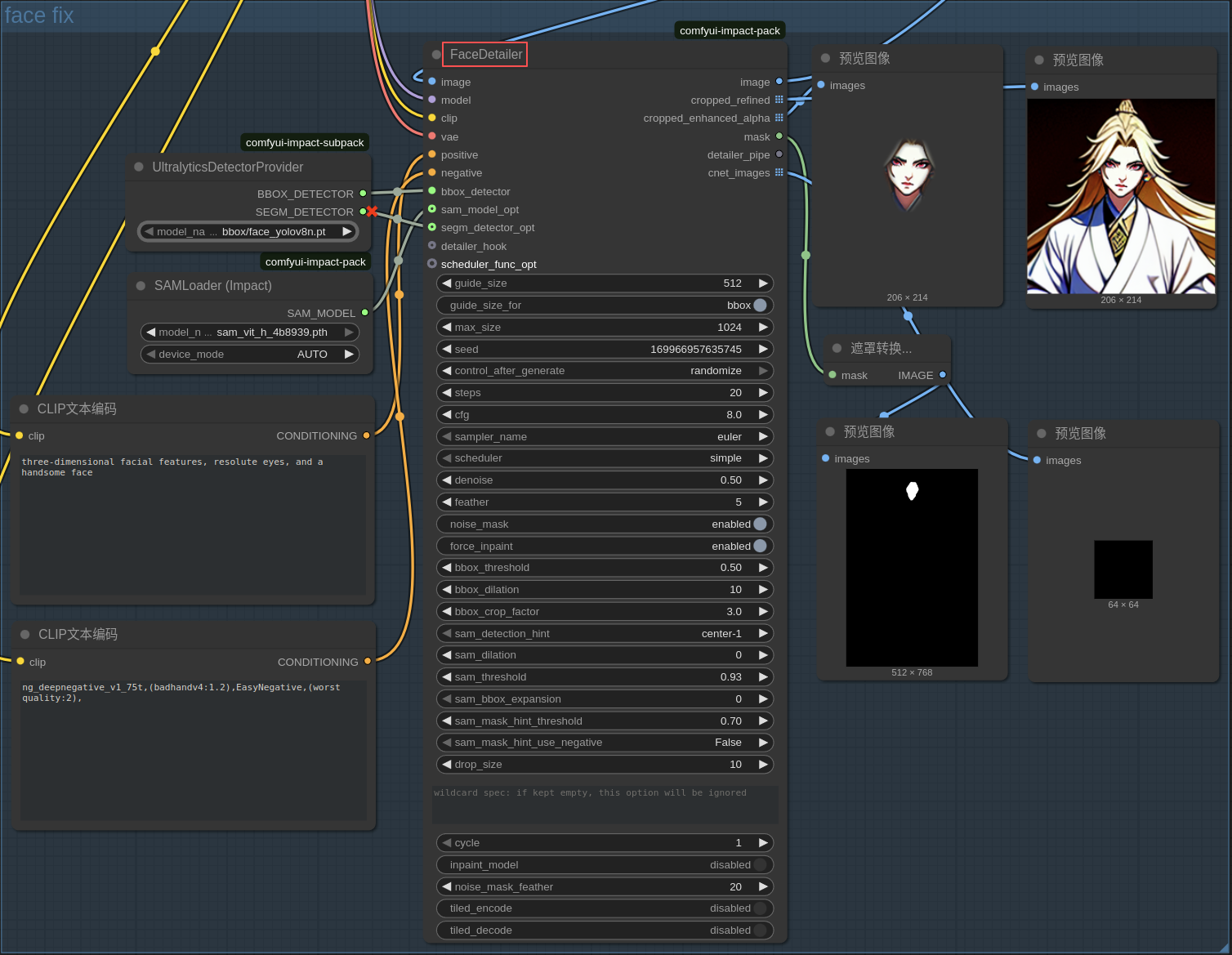
- 输出的
3. 手部修复
3.1 下载结点库
3.2 下载模型
-
模型1
- 下载地址
https://huggingface.co/hr16/ControlNet-HandRefiner-pruned/resolve/main/control_sd15_inpaint_depth_hand_fp16.safetensors - 存放位置
ComfyUI/models/controlnet/
- 下载地址
-
模型2
- 下载地址
https://hf-mirror.com/hr16/ControlNet-HandRefiner-pruned/resolve/main/hrnetv2_w64_imagenet_pretrained.pth - 存放位置
custom_nodes/comfyui_controlnet_aux/ckpts/hr16/ControlNet-HandRefiner-pruned/
- 下载地址
-
文件3
- 下载地址
https://hf-mirror.com/hr16/ControlNet-HandRefiner-pruned/resolve/main/graphormer_hand_state_dict.bin - 存放位置
custom_nodes/comfyui_controlnet_aux/ckpts/hr16/ControlNet-HandRefiner-pruned/
- 下载地址
-
其他问题
- 如果没有手动下载,而运行时自动下载失败,后面又补充手动下载,仍可能有问题:缓存了失败文件
- 修复方式:删除失败的缓存
cd custom_nodes/comfyui_controlnet_aux/ckpts/hr16/ControlNet-HandRefiner-pruned/
rm *.incomplete
rm .cache/huggingface/download/*.lock
3.3 代码修复
-
代码位置
custom_nodes/comfyui_controlnet_aux/src/custom_mesh_graphormer/modeling/bert/modeling_utils.py -
修复前
from transformers.modeling_utils import *
- 修复后
from transformers.modeling_utils import * # keep the original import# ------------------------------------------------------------------------------
# Compatibility exports: prune_linear_layer / prune_layer / Conv1D
# ------------------------------------------------------------------------------# 1) Try to import prune_linear_layer from transformers
try:from transformers.pytorch_utils import prune_linear_layer as _hf_prune_linear_layer
except Exception:try:from transformers.modeling_utils import prune_linear_layer as _hf_prune_linear_layerexcept Exception:_hf_prune_linear_layer = None# 2) Fallback implementation
try:import torchimport torch.nn as nn
except Exception:torch = Nonenn = Nonedef _local_prune_linear_layer(layer, index, dim=0):if torch is None or nn is None:raise ImportError("prune_linear_layer not available and torch missing.")W = layer.weight.index_select(dim, index).clone()out_features, in_features = W.size(0), W.size(1)new = nn.Linear(in_features, out_features, bias=(layer.bias is not None)).to(layer.weight.device)new.weight.data.copy_(W)if layer.bias is not None:if dim == 0:new.bias.data.copy_(layer.bias.data.index_select(0, index).clone())else:new.bias.data.copy_(layer.bias.data.clone())return new# 3) Expose prune_linear_layer
if _hf_prune_linear_layer is not None:def prune_linear_layer(layer, index, dim=0):return _hf_prune_linear_layer(layer, index, dim=dim)
else:prune_linear_layer = _local_prune_linear_layer# 4) Expose prune_layer (alias)
def prune_layer(layer, index, dim=0):return prune_linear_layer(layer, index, dim=dim)# 5) Conv1D compatibility
try:from transformers.modeling_utils import Conv1D as Conv1D # Use directly if still available
except Exception:if torch is not None and nn is not None:class Conv1D(nn.Module):def __init__(self, nf, nx):super().__init__()self.nf, self.nx = nf, nxself.weight = nn.Parameter(torch.empty(nx, nf))self.bias = nn.Parameter(torch.zeros(nf))nn.init.normal_(self.weight, std=0.02)def forward(self, x):size_out = x.size()[:-1] + (self.nf,)x = torch.addmm(self.bias, x.view(-1, self.nx), self.weight)return x.view(*size_out)else:class Conv1D: # Placeholder if torch is missingdef __init__(self, *a, **k):raise ImportError("Conv1D requires torch.")# 6) Ensure these symbols appear in __all__
try:__all__
except NameError:__all__ = []
for _name in ("prune_linear_layer", "prune_layer", "Conv1D"):if _name not in __all__:__all__.append(_name)
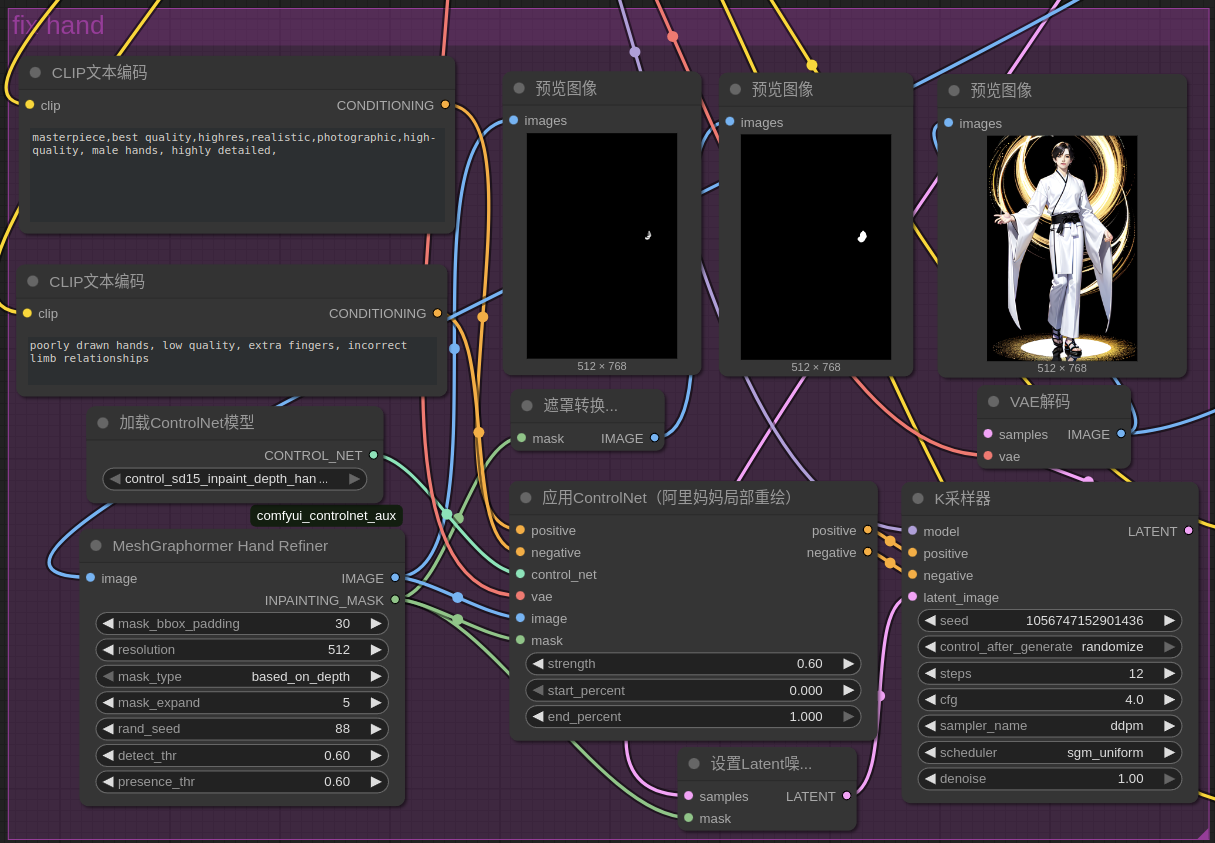
3.4 工作流程举例
- 注意参数
- 效果一般
- 仅适用于3D
4. 扩充边缘
在原图周围补充像素并绘制。
4.1 下载模型
-
网址
https://huggingface.co/stabilityai/stable-diffusion-2-inpainting/resolve/main/512-inpainting-ema.safetensors -
保存位置
ComfyUI/models/checkpoints
4.2 工作流程举例
这是在模版里找到的,可以看到这里的注释说这个模型训练的图像是 512512,因此这个模版里用的缩放图像是以像素总数为限制的,易知,512512≈0.25M
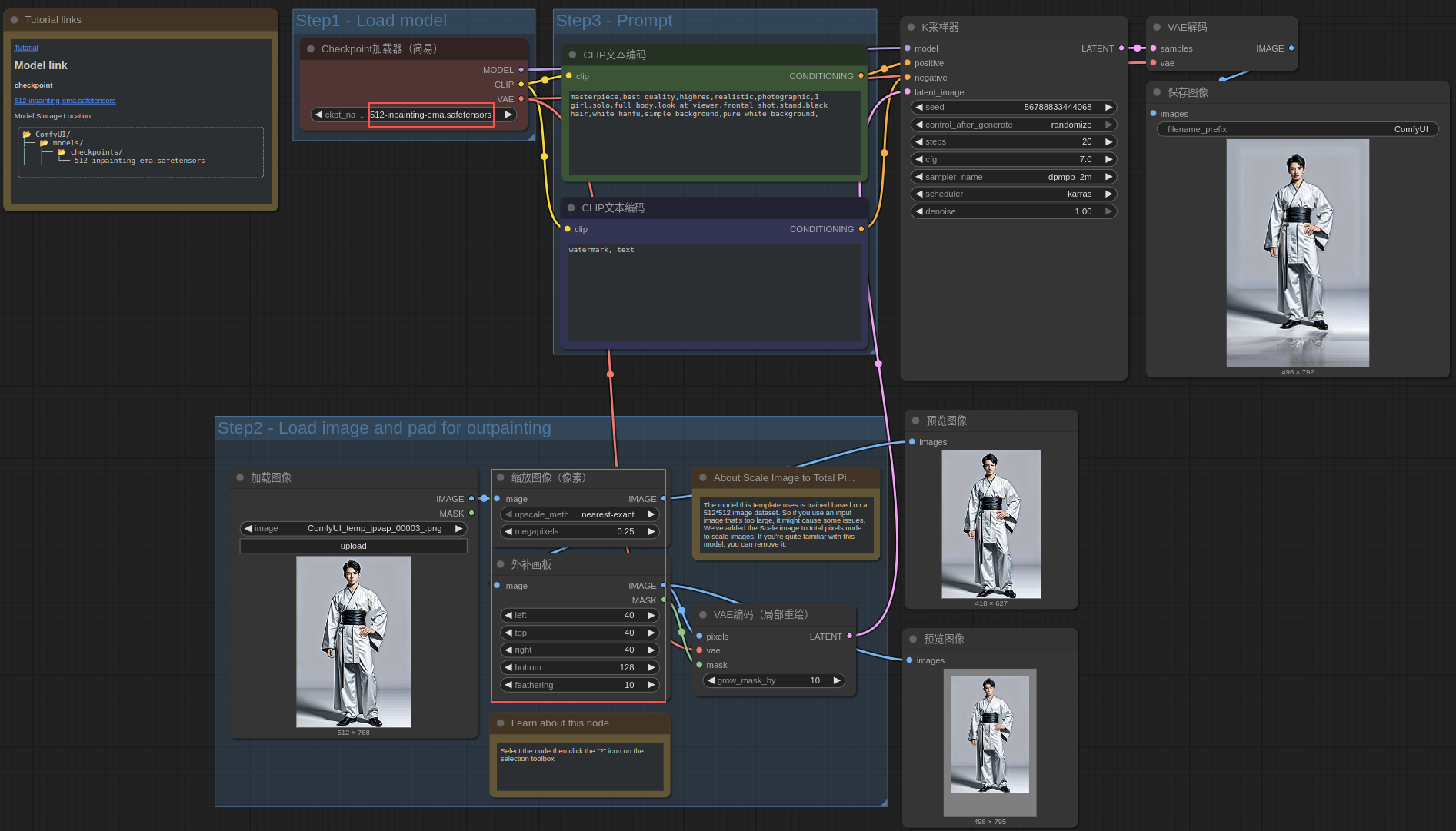
5. 图像放大-潜在空间放大后重绘
5.1 下载模型
-
网址
https://huggingface.co/Lykon/DreamShaper/resolve/main/DreamShaper_8_pruned.safetensors -
保存位置
ComfyUI/models/checkpoints
5.2 工作流程举例
可以放在刚完成初步文生图的后面!
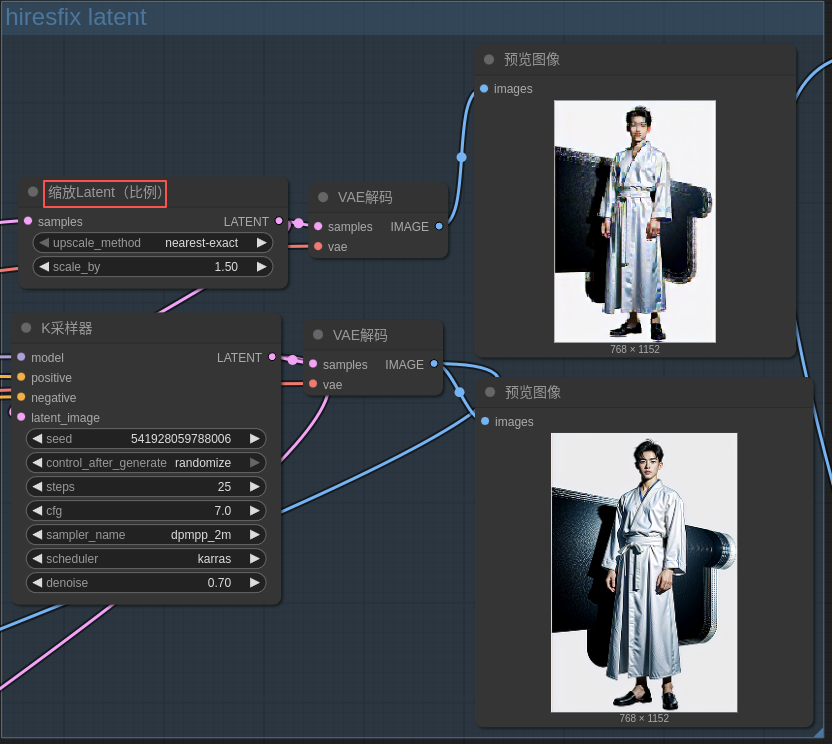
6. 图像放大-使用模型放大图像
6.1 下载模型
- 网址
https://huggingface.co/Comfy-Org/Real-ESRGAN_repackaged/resolve/main/RealESRGAN_x4plus.safetensors - 保存位置
ComfyUI/models/upscale_models
6.2 工作流程举例
可以放在整个流程的最后面!
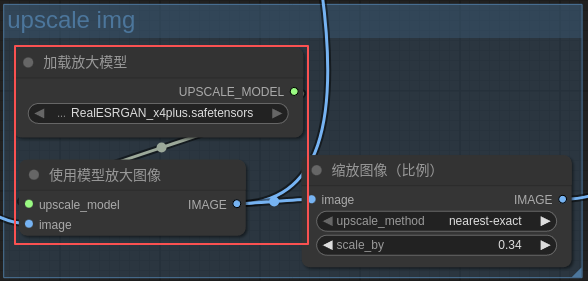
6.3 放大模型补充
-
RealESRGAN_x4plus_anime_6B
直链(HF):
https://huggingface.co/Comfy-Org/Real-ESRGAN_repackaged/resolve/main/RealESRGAN_x4plus_anime_6B.safetensors
特点:6 个残差块,专为动漫线条优化,色块边缘更干净,伪影最少。 -
RealESRGAN_AnimeSharp_x4(社区也叫 AnimeSharp)
直链(GitHub):
https://github.com/cszn/Real-ESRGAN/releases/download/v0.2.2.1/RealESRGAN_x4plus_animeSharp.pth
说明:官方只做 .pth,ComfyUI 也能读;想要 .safetensors 可自行转换(python convert.py xxx.pth xxx.safetensors),或者直接使用,无需改名。 -
RealESRGAN_AnimeVideo v3(做动插/视频番剧放大)
直链:
https://github.com/xinntao/Real-ESRGAN/releases/download/v0.2.5.0/RealESRGAN_AnimeVideo-v3.pth
说明:针对 720p→1080p 番剧,降噪+锐化平衡,适合做短视频或 GIF。 -
其它可选(真人、低噪、8× 等)
- RealESRGAN_x2plus(2× 放大,细节更少,显存省一半)
https://huggingface.co/Comfy-Org/Real-ESRGAN_repackaged/resolve/main/RealESRGAN_x2plus.safetensors - RealESRGAN_x8(8×,极吃显存,适合打印需求)
https://huggingface.co/Comfy-Org/Real-ESRGAN_repackaged/resolve/main/RealESRGAN_x8.pth
- RealESRGAN_x2plus(2× 放大,细节更少,显存省一半)
7. LoRa
7.1 简单示意

8. Control net
8.1 模型
由于我之前安装过 WebUI 的 control net,这里只需要复用。
- 复用方法
在上一篇文章《SD:在一个 Ubuntu 系统安装 stable diffusion ComfyUI》第3节介绍了如何配置 extra_model_paths.yaml.example
在此基础上,修改如下内容
controlnet: extensions/sd-webui-controlnet/modelscontrolnet_preprocessors: extensions/sd-webui-controlnet/annotator
- 注 - 模型位置
- WebUI
stable-diffusion-webui/extensions/sd-webui-controlnet/models - ComfyUI
ComfyUI/models/controlnet/
- WebUI
8.2 工作流程举例
- 关键结点:应用ControlNet(旧版高级)
- 作用位置:介于 正负提示词 和 K采样器 之间
- 辨析:
- ControlNet 不是改语义,而是“在 UNet 的卷积特征层里做空间硬约束”,让像素结构跟着你的条件图走
- 文本继续负责“画什么”,ControlNet 负责“怎么摆”
- ControlNet 的灵魂是“零初始化残差注入”
- SD ComfyUI 中的图形是数据流顺序
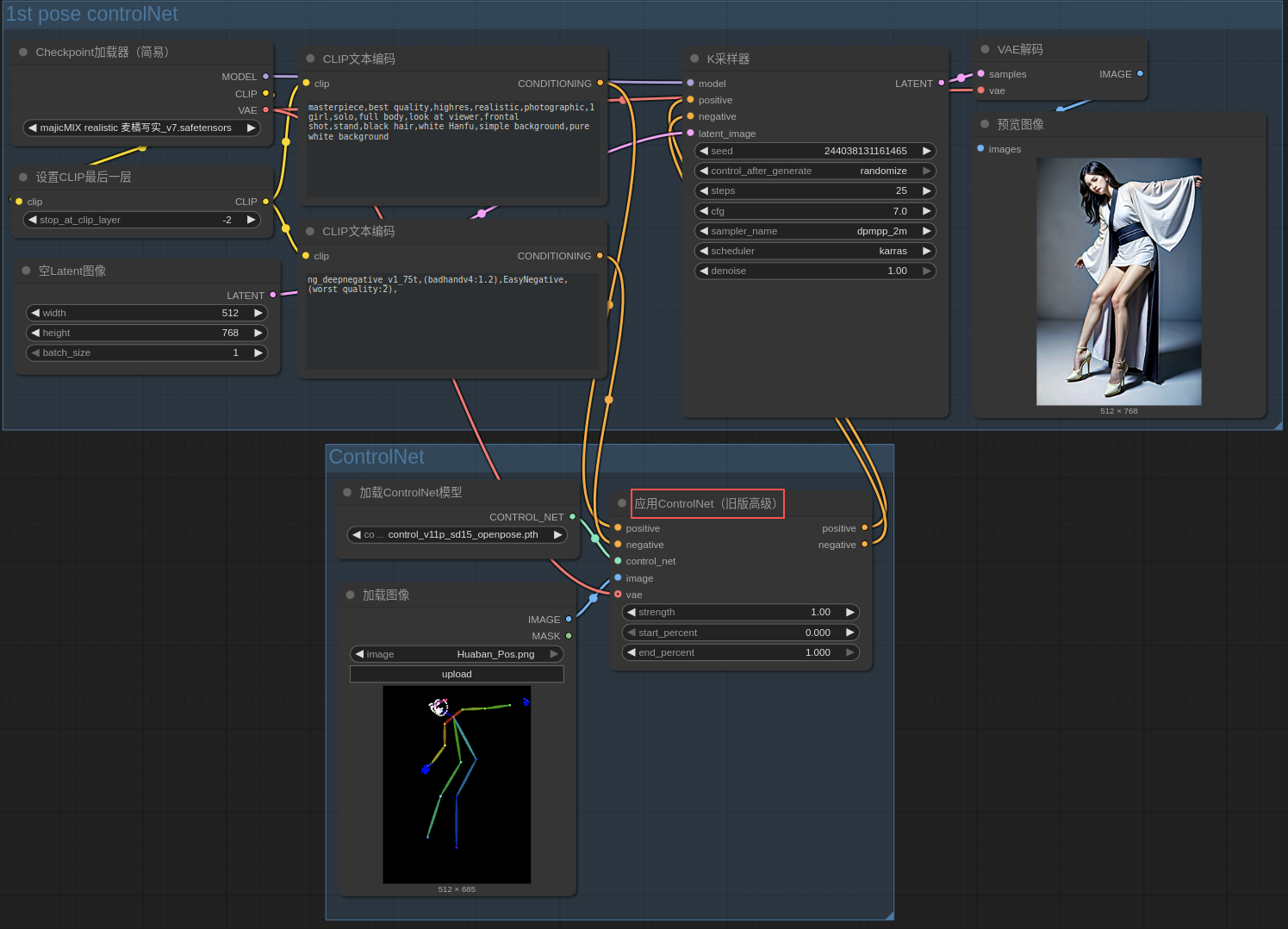
9. 从图像获取 深度图、姿态图等
9.1 深度图为例
-
结点
搜 zoe,选 Zoe Depth Map
-
下载内容
- 自动下载
需要走代理,注意启动软件时配置 proxy
- 自动下载
export https_proxy=http://127.0.0.1:7890
export http_proxy=http://127.0.0.1:7890
保存在 huggingface 缓存:
~/.cache/huggingface/hub/models–Intel–zoedepth-nyu-kitti/snapshots/f364d4c7936e91f465abba182208dd68142bf0ca
- 手动下载(不是很确定)
保存在 custom_nodes/comfyui_controlnet_aux/ckpts/Intel/zoedepth-nyu-kitti/
| 文件名 | 下载地址1 | 下载地址2 |
|---|---|---|
config.json | https://huggingface.co/Intel/zoedepth-nyu-kitti/resolve/main/config.json | https://hf-mirror.com/Intel/zoedepth-nyu-kitti/resolve/main/config.json |
pytorch_model.bin | https://huggingface.co/Intel/zoedepth-nyu-kitti/resolve/main/pytorch_model.bin | https://hf-mirror.com/Intel/zoedepth-nyu-kitti/resolve/main/pytorch_model.bin |
preprocessor_config.json | https://huggingface.co/Intel/zoedepth-nyu-kitti/resolve/main/preprocessor_config.json | https://hf-mirror.com/Intel/zoedepth-nyu-kitti/resolve/main/preprocessor_config.json |
9.2 结点快速查阅
深度: MiDaS / Zoe / LeReS → depth
法线: NormalMap → normalbae
姿态: OpenPose / HandRefiner → openpose
线稿: Canny / SoftEdge / LineArt / Scribble → canny/softedge/lineart/scribble
语义: SegOf / OneFormer → seg
超分: Tile → tile
重绘: Inpaint / Shuffle → inpaint/shuffle
面部: MediapipeFace → mediapipe_face
配色: Color → color
注1:首次运行会自动下载东西
-
tips
- 使用了代理
- 一些在 ~/.cache/huggingface/hub
- 一些在 custom_nodes/comfyui_controlnet_aux/ckpts/
-
注2:法线贴图依赖 python 包:
pip install -U timm
9.3 工作流程举例
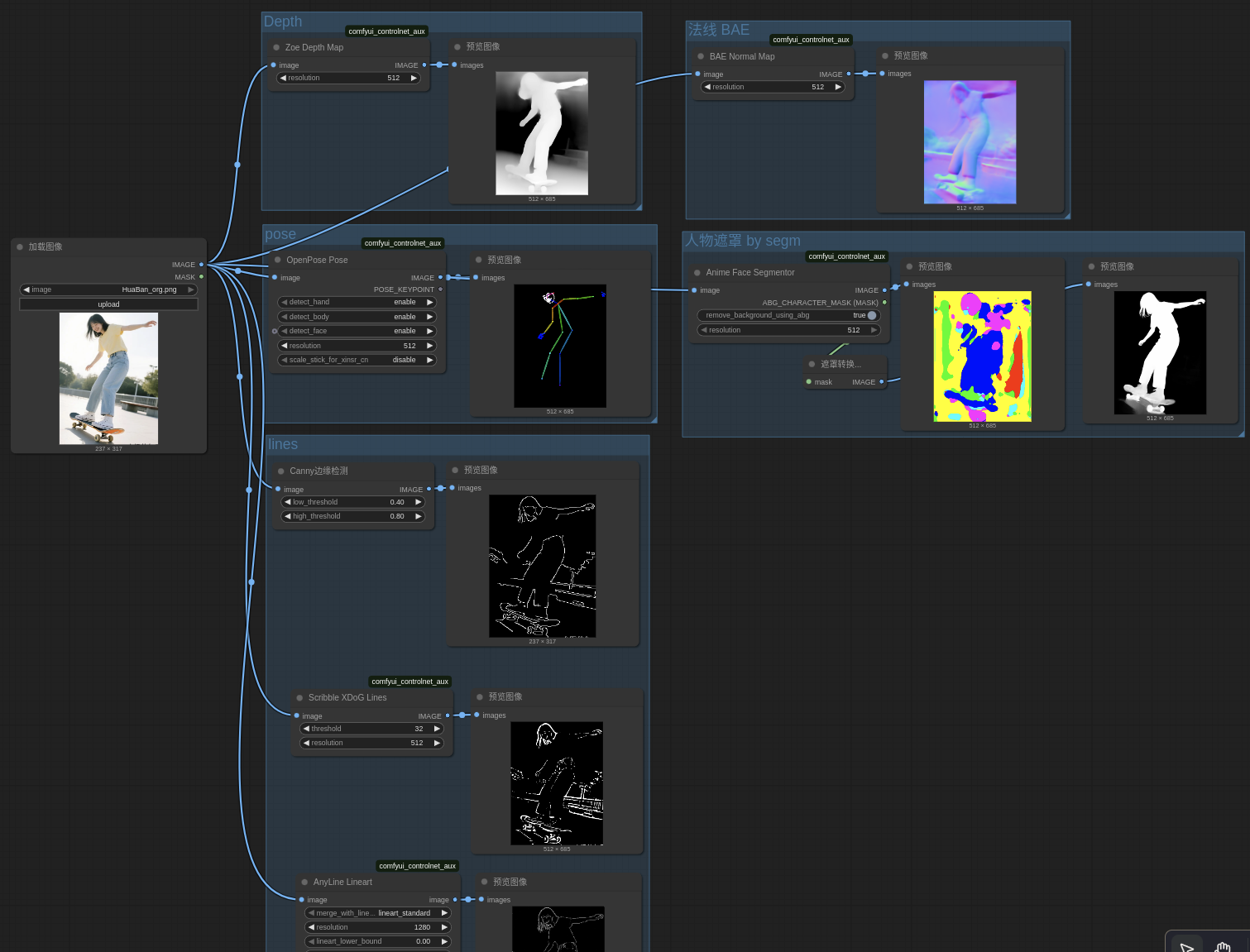
- 补充:最小工作流模板(通用)
[Load Image] ↓
【任意 Preprocessor 节点】(上面列表里选一个)↓
[ControlNet Apply](model 选对应 fp16 模型)↓
[KSampler] + [Save Image]
把 preprocessor 和 controlnet 模型同名对应即可,权重 0.7–1.0 先跑一张看效果,再微调。
9.4 关于 control net 模型
9.4.1 复用 WebUI 的
如 8.1 节所属
9.4.2 下载
模型下载地址(全部 fp16,一次拖完)
| 类型 | 网址 |
|---|---|
| 科学 | https://huggingface.co/comfyanonymous/ControlNet-v1-1_fp16_safetensors/tree/main/ |
| 国内 | https://hf-mirror.com/comfyanonymous/ControlNet-v1-1_fp16_safetensors/tree/main |
# 镜像站一键脚本(Linux / macOS)
cd ComfyUI/models/controlnet
for m in depth normalbae openpose canny softedge scribble lineart seg tile inpaint mediapipe_face color shuffle; dowget https://huggingface.co/comfyanonymous/ControlNet-v1-1_fp16_safetensors/tree/main/control_v11*${m}*_fp16.safetensors
done
9.4.3 类型
几何类(形状 / 空间)
| 预处理器节点 | 输出图例 | 对应 ControlNet 模型(下载放 models/controlnet) | 用途一句话 |
|---|---|---|---|
| MiDaS-DepthMapPreprocessor Zoe-DepthMapPreprocessor LeReS-DepthMapPreprocessor | 灰度深度图 | control_v11f1p_sd15_depth_fp16.safetensors | 远近/立体感 |
| NormalMapPreprocessor(Bae 或 MiDaS) | 法线贴图(蓝紫) | control_v11p_sd15_normalbae_fp16.safetensors | 表面朝向、凹凸 |
| OpenPosePreprocessor(人脸/手/身体) | 骨骼棍图 | control_v11p_sd15_openpose_fp16.safetensors | 人物动作 |
| HandRefinerPreprocessor | 21 手骨关键点 | control_v11p_sd15_openpose_fp16 + hand_refiner.pth(放 annotator/downloads/hand_refiner) | 精准改手 |
边缘 / 线稿类
| 预处理器节点 | 输出图例 | 对应 ControlNet 模型 | 用途一句话 |
|---|---|---|---|
| CannyEdgePreprocessor(硬边缘) | 白底黑线 | control_v11p_sd15_canny_fp16.safetensors | 通用线稿 |
| PidiNetPreprocessor / HEDPreprocessor | 软边缘 | control_v11p_sd15_softedge_fp16.safetensors | 带粗细变化的线 |
| ScribblePreprocessor / ScribbleXDoGPreprocessor | 手绘涂鸦 | control_v11p_sd15_scribble_fp16.safetensors | 随手画也能控 |
| LineArtPreprocessor(写实线) | 干净线稿 | control_v11p_sd15_lineart_fp16.safetensors | 动漫/插画勾线 |
| AnimeLineArtPreprocessor | 纯黑线透明底 | 同上 | 二次元专用 |
| MangaLinePreprocessor | 漫画网点效果 | 同上 | 黑白漫画 |
语义 / 区块类
| 预处理器节点 | 输出图例 | 对应 ControlNet 模型 | 用途一句话 |
|---|---|---|---|
| SegOfade20kPreprocessor SegUfade20kPreprocessor | 色块语义分割 | control_v11p_sd15_seg_fp16.safetensors | 换天空、换草地 |
| OneFormerADE20kPreprocessor | 更高精度分割 | 同上 | 建筑/街景 |
| BinaryPreprocessor(阈值分割) | 纯黑纯白 | 无专用模型,常配合 Depth/Canny | 遮罩 |
像素级重绘类
| 预处理器节点 | 输出图例 | 对应 ControlNet 模型 | 用途一句话 |
|---|---|---|---|
| TilePreprocessor(分块模糊) | 低清原图 | control_v11f1e_sd15_tile_fp16.safetensors | 超分/加细节 |
| InpaintPreprocessor | 蒙版区域 | control_v11p_sd15_inpaint_fp16.safetensors | 局部重绘 |
| ShufflePreprocessor | 随机打乱色块 | control_v21_sd15_shuffle_fp16.safetensors | 风格迁移 |
风格 / 抽象类
| 预处理器节点 | 输出图例 | 对应 ControlNet 模型 | 用途一句话 |
|---|---|---|---|
| MediapipeFacePreprocessor | 468 面部网格 | control_v11p_sd15_mediapipe_face_fp16.safetensors | 换脸/表情 |
| ColorPreprocessor(L颜色) | 原图降采样色块 | control_v21_sd15_color_fp16.safetensors | 严格保持配色 |
| T2IAdapterStylePreprocessor | 整张风格图 | t2iadapter_style_sd14v1.pth | 参考风格 |
10. 局部重绘(以脸部一致为例)
10.1 结点下载
- 手绘遮罩
安装 ComfyUI-MaskEditor-Extension 后重启 ComfyUI。在加载图像结点通过右键可以找到 MaskEditor
- IPAdapter
安装 ComfyUI_IPAdapter_plus 后重启 ComfyUI。
10.2 模型下载
参考:https://github.com/cubiq/ComfyUI_IPAdapter_plus
- CILP
- 下载网址:
- https://huggingface.co/h94/IP-Adapter/resolve/main/models/image_encoder/model.safetensors
重命名:CLIP-ViT-H-14-laion2B-s32B-b79K.safetensors - https://huggingface.co/h94/IP-Adapter/resolve/main/sdxl_models/image_encoder/model.safetensors
重命名:CLIP-ViT-bigG-14-laion2B-39B-b160k.safetensors
- https://huggingface.co/h94/IP-Adapter/resolve/main/models/image_encoder/model.safetensors
- 保存位置:ComfyUI/models/clip_vision
- 下载网址:
- IPAdapter
- 下载网址:
- https://huggingface.co/InvokeAI/ip_adapter_plus_sd15/tree/main
- https://huggingface.co/h94/IP-Adapter/tree/main/models
- https://huggingface.co/h94/IP-Adapter/tree/main/sdxl_models
- 保存位置:ComfyUI/models/ipadapter
- 下载网址:
10.3 流程举例
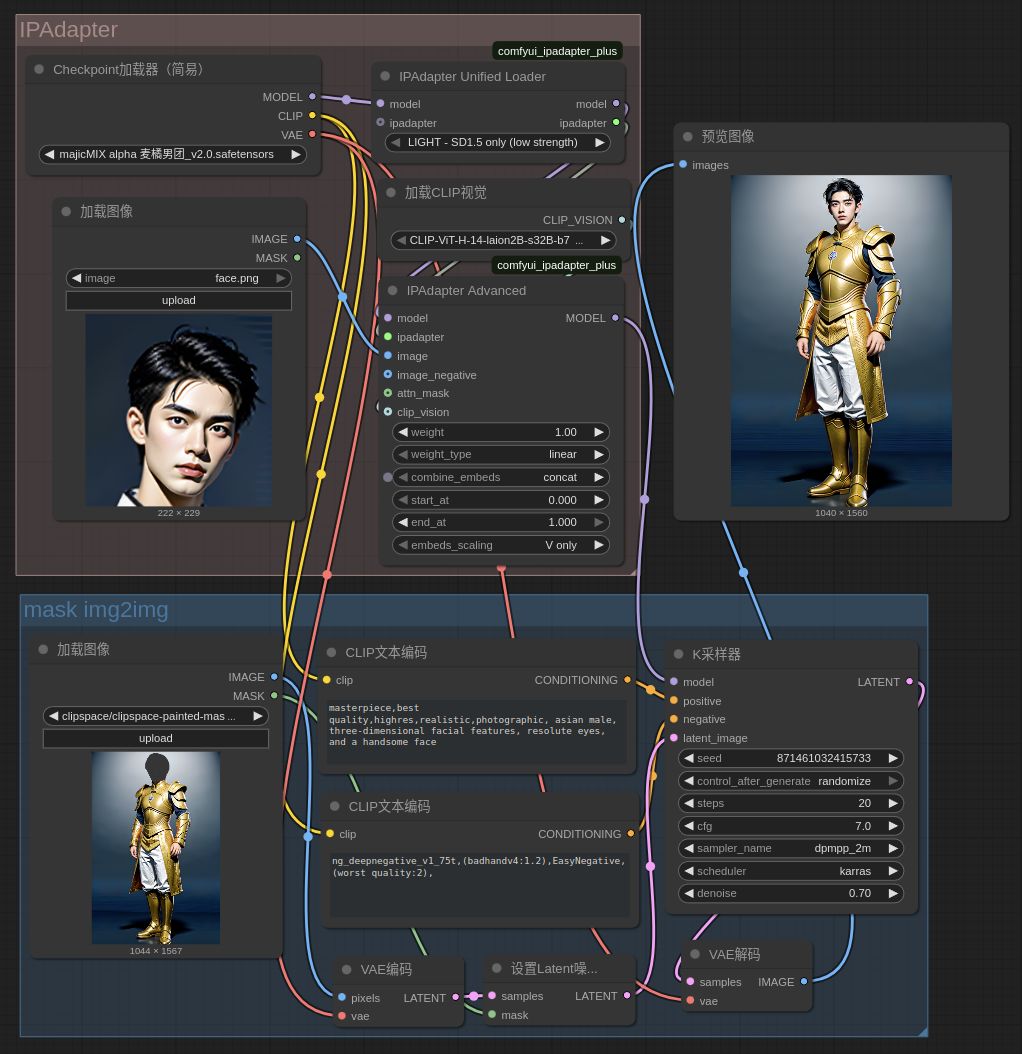
- 这里以脸部迁移为例
- 脸部特写作为参考,使用 IPAdapter 相关结点,最终出口是 model
- 待重绘的图,可以使用局部手绘或其他方式生成mask,然后转为带遮罩的潜在空间,最终传入 K 采样器 进行重绘
10.4 注:问题修复
- 报错:找不到 IPAdapter 模型
File "/xxx/programs/ComfyUI/custom_nodes/comfyui_ipadapter_plus/IPAdapterPlus.py", line 515, in load_modelsraise Exception("IPAdapter model not found.")
Exception: IPAdapter model not found.
- 分析 & 排查:模型路径不对
根据报错找到:IPAdapterPlus.py 的 515 行。尝试打印路径:
print("===> preset:",preset, "\n is_sdxl:",is_sdxl,"\n clipvision_file:", clipvision_file, "\n pipeline:", pipeline, "\n folder_paths.folder_names_and_paths['ipadapter']:",folder_paths.folder_names_and_paths["ipadapter"])
发现 ipadapter 路径配置的是 /xxx/stable-diffusion-webui/
- 修复:extra_model_paths.yaml
extra_model_paths.yaml 中增加新的 ipadapter 路径
a111:base_path: /xxx/stable-diffusion-webui/models/IpAdapter # <=== 老的checkpoints: models/Stable-diffusionvae: models/VAEloras: |models/Loramodels/LyCORISclip_vision: models/clip_visiongligen: models/GLIGENcontrolnet: extensions/sd-webui-controlnet/modelscontrolnet_preprocessors: extensions/sd-webui-controlnet/annotatoripadapter: models/IpAdapter # <=== 老的instantid: models/InstantIDupscale_models: models/ESRGANembeddings: embeddingshypernetworks: models/hypernetworkscomfyui_extra:base_path: /xxx/ComfyUI/ # <=== 新的ipadapter: models/ipadapter # <=== 新的