当大模型遇上 HTTP:一次“无状态”的相似性思考
“AI 不是魔法,它更像是一种协议。”
—— 这是我越来越深的体会。
一、背景:一个来自网络层的启示
过去十年,HTTP 协议几乎承载了整个互联网的繁荣。
而在最近两年,大模型(LLM)则成为新的“智能网络层”。
看似完全不同的两个世界——一个在传输数据,一个在生成语言——却都在用一种相似的哲学运行:无状态 (Statelessness)。
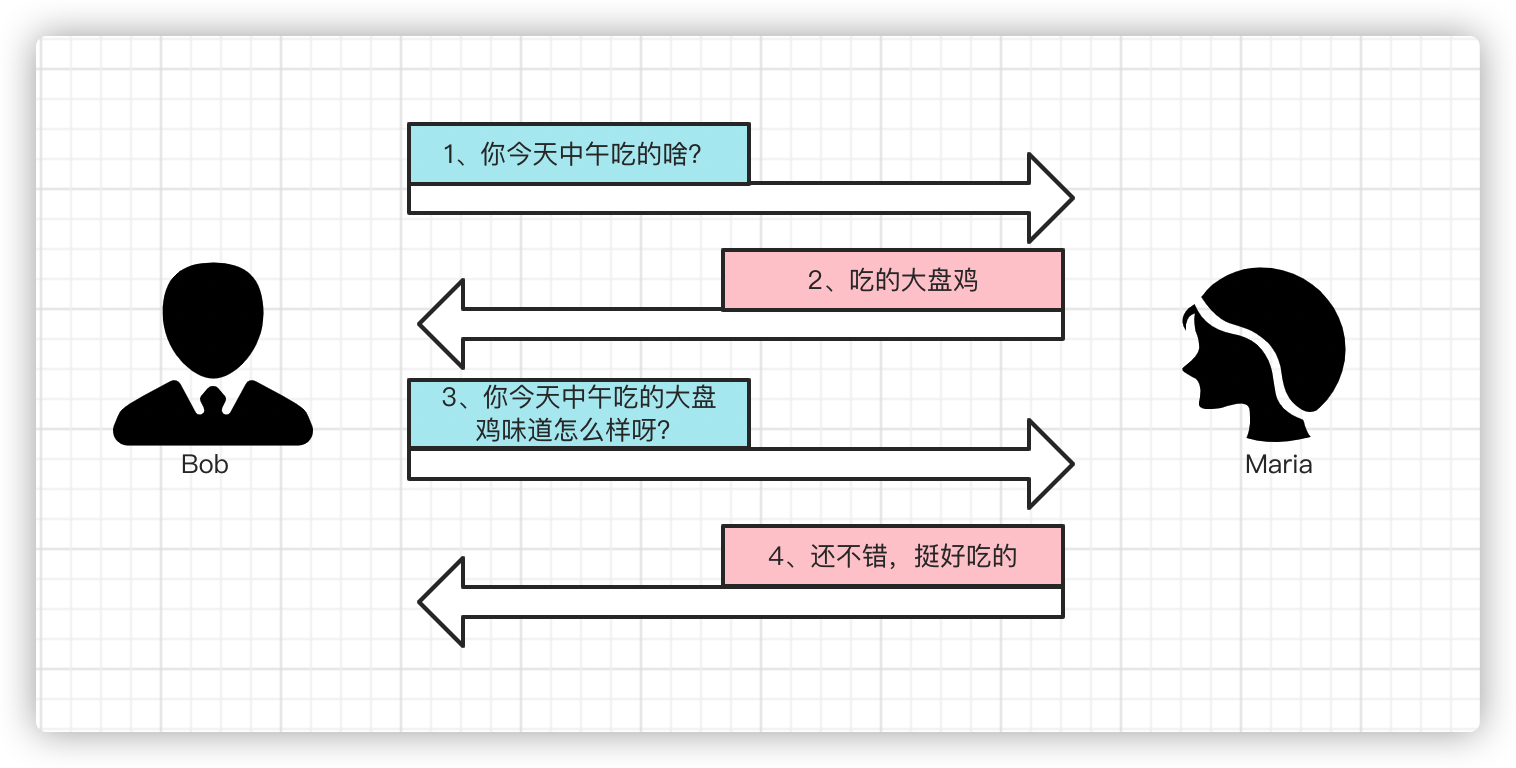
HTTP 的设计哲学是“每个请求都是独立的”。
这意味着服务器不会记得你上一次发了什么,除非你自己通过 Cookie 或 Token 告诉它。
而大模型,比如 GPT、Claude 或 DeepSeek,本质上也遵循同样的逻辑——模型不会“记得”之前的对话,它只是每次根据当前输入(Prompt + Context)推理出输出。
从这个角度看,大模型其实是一种“语义级的 HTTP 服务”。
只不过,它传输的不再是数据包,而是语义包(Semantic Packets)。
二、原理:无状态的核心逻辑
让我们先回到“无状态”这个词本身。
在 HTTP 协议里,“无状态”意味着:
服务器不会自动保存客户端的上下文信息。每一次请求,都是新的、独立的。
其优点在于:
-
结构简单(不需维护复杂会话);
-
可扩展性强(任何请求都可被任意服务器处理);
-
容错性好(节点宕机不会影响系统状态)。
对应到大模型,推理过程同样体现出这种“无状态逻辑”:
-
每一次推理(Inference)都是独立的计算
模型在输入 prompt 时,会将文本转化为 token 序列,经过注意力机制层层传播,输出结果后便“清空”内存状态。
除非用户主动提供上文(例如通过上下文拼接或系统提示),模型不会知道你之前说过什么。 -
状态模拟是“伪记忆”而非真正记忆
当我们觉得模型“记得之前说的话”,其实是因为我们把前文重新放进了输入(context window)。
这就像 HTTP 里通过 Cookie 模拟“有状态会话”一样——本质上仍是无状态,只是人为维护了状态。 -
无状态的代价:上下文窗口有限 + 记忆成本高
模型每次都要重新加载完整上下文,这带来了昂贵的计算成本(O(n²)注意力开销)。
这与 HTTP 请求频繁重复的 Header 一样——简单但冗余。
三、类比:当 HTTP 成为理解大模型的钥匙
这时候我们可以画出这样一个类比表格👇:
| 对比维度 | HTTP 协议 | 大模型 (LLM) |
|---|---|---|
| 核心单元 | Request / Response | Prompt / Completion |
| 传输内容 | 字节流 (Byte Stream) | 语义流 (Semantic Stream) |
| 状态管理 | 无状态(Stateless) | 无状态(Stateless) |
| 上下文保留方式 | Cookie / Session | Context Window / Memory Token |
| 协议层级 | 传输层(TCP之上) | 语义层(人类语言之上) |
| 性能瓶颈 | 带宽、延迟 | 上下文长度、计算复杂度 |
| 可扩展方案 | 缓存、负载均衡 | RAG、Memory、Agent Graph |
可以看到,大模型的发展路径,几乎就是 HTTP 协议在智能领域的“重演”。
📘 类比一:Cookie 与 Context
HTTP 的 Cookie 用于在多次请求之间“记住你是谁”。
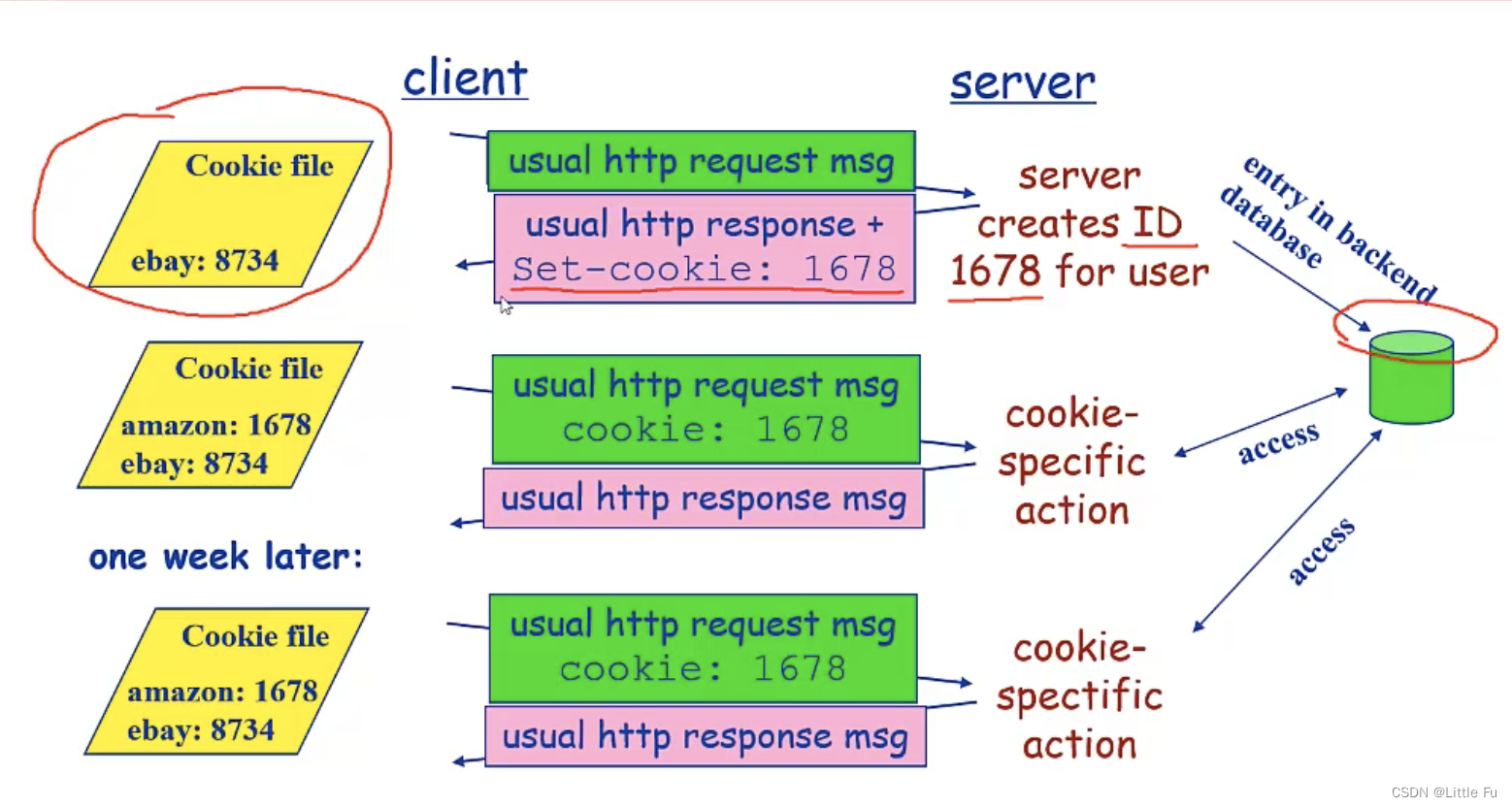
而在 LLM 世界,Context 起到了类似作用——用连续对话内容维持语义状态。
# 模拟“上下文记忆”的伪代码
conversation = []
while True:user_input = input("你:")conversation.append({"role": "user", "content": user_input})response = llm_api(conversation)print("模型:", response)conversation.append({"role": "assistant", "content": response})
这个循环,其实就像一个不断附带 Cookie 的 HTTP 请求。
每次调用 API 时,你都在告诉模型:这是“同一个会话”。
📘 类比二:Session 与长程记忆
当 HTTP 想突破无状态限制时,引入了 Session。
当 LLM 想跨越上下文限制时,引入了 Memory(记忆模块)。
我们现在看到的很多 AI Agent 框架(如 LangGraph、MCP)都在尝试 **“让模型有状态”** ——
让它像浏览器保持登录一样,记得你的目标、任务进度、甚至性格偏好。
# 模型“有状态化”的伪实现
class Memory:def __init__(self):self.state = {}def update(self, key, value):self.state[key] = valuedef recall(self, key):return self.state.get(key, None)memory = Memory()def smart_agent(input_text):goal = memory.recall("goal") or "未定义目标"print(f"当前任务:{goal}")if "设定目标" in input_text:memory.update("goal", input_text.split(":")[1])return "目标已保存。"else:return f"基于目标 {goal} 进行推理..."
这其实是HTTP → REST → GraphQL → WebSocket → AI Agent
的一次概念进化:从一次性请求,到持续交互。
📘 类比三:缓存与语义压缩
HTTP 通过缓存提升效率(比如 ETag、304 Not Modified)。
LLM 世界也在做“语义缓存”(Semantic Cache):
# 简单语义缓存逻辑
if hash(prompt) in cache:return cache[hash(prompt)]
else:result = llm(prompt)cache[hash(prompt)] = resultreturn result
未来,语义层的缓存将像 CDN 一样重要。
这就是为什么 Anthropic、OpenAI 都在研究“上下文压缩 (Context Compression)”与“检索增强 (RAG)”——
它们的目标就是:让无状态模型更像“有状态系统”。
四、实践:从 HTTP 思维构建智能系统
理解这种相似性之后,我们在工程上能做的事情就多了。
-
把大模型当作一个 HTTP 服务
每次调用就像一个请求,请求头是 Prompt,请求体是上下文,请求返回是响应。
这启发我们:-
需要规范化接口(Prompt Schema)
-
需要可复用的中间件(拦截器、过滤器)
-
需要日志与追踪(Prompt Trace)
-
-
设计“语义路由 (Semantic Routing)”机制
类似 HTTP 路由转发:-
/summary→ 调用 Text Summarizer 模型 -
/math→ 调用 Math Reasoner -
/report→ 调用 Report Generator
对应到 LangGraph 或 MCP 中,就是多智能体协作的“语义路由表”:
flowchart TDA[用户请求] --> B[语义路由器]B -->|/summary| S1[摘要模型]B -->|/math| S2[数学推理模型]B -->|/report| S3[报告生成模型]S1 & S2 & S3 --> C[结果聚合器]C --> D[返回输出] -
-
让“无状态”服务变得“可对话”
通过外部记忆(MemoryDB)、向量检索(RAG)、知识存储(Knowledge Base)等手段,
我们在应用层人为地补上了模型的“记忆模块”——
就像 HTTP 通过 Redis / Session Store 实现用户持久化。
五、启示:无状态的优雅与局限
从哲学层面讲,“无状态”是一种优雅的简化。
它让系统更纯粹、更容易扩展,但也带来了“短暂的智能”:
-
模型每次都“重新认识世界”;
-
所有记忆都依赖外部注入;
-
智能行为的连贯性依赖上下文维护。
然而正是这种无状态的纯净,让大模型具备了通用性。
它不被历史绑定,不携带情绪,也不陷入过往决策的偏见。
正因为“每次都重新开始”,它才能跨越语境、领域与身份的边界。
如果说 HTTP 解决了“机器与机器的通信”,
那么 LLM 正在解决“人类与机器的对话”。
二者之间,隔着的只是一层“语义协议栈”。
六、总结:从 HTTP 到 LLM,协议的回环
当我们从系统设计者的角度回望,会发现一个有趣的循环:
HTTP 是计算机之间的语言协议,LLM 是语言之间的计算协议。
两者都追求同一个目标:让信息自由流动。
| 时代 | 协议 | 目标 |
|---|---|---|
| Web 1.0 | HTTP | 实现万维网的互联 |
| Web 2.0 | REST / WebSocket | 实现应用的交互 |
| AI 时代 | LLM / MCP | 实现智能的协作 |
未来,当大模型与协议层真正融合,也许我们会迎来“HTTP/4”——
一个不再传输文件,而是传输思考结果的网络。
📚 延伸阅读
-
RFC 2616: Hypertext Transfer Protocol -- HTTP/1.1
-
OpenAI: Function Calling & Memory API Docs
-
Anthropic MCP Specification
-
LangGraph: Stateful Workflows on Top of LLMs
🧩 结语
我们终将意识到,智能不是魔法,而是连接。
HTTP 让信息流动,大模型让理解流动。
当这两种流动汇合,人机交互的“语义互联网”才会真正诞生。
如果你也觉得这种类比有启发,欢迎留言聊聊:
你觉得下一个“HTTP 时刻”,会不会就在 AI?