【论文精读】RD-Agent-Quant:基于多智能体框架的量化因子与模型研发自动化系统
标题:R&D-Agent-Quant: A Multi-Agent Framework for Automated Quantitative Research and Development
作者:Microsoft Research Asia论文链接:https://arxiv.org/pdf/2505.15155v1
代码链接:https://github.com/microsoft/RD-Agent
领域:人工智能 × 量化金融 × 多智能体系统 × 自动化研究
关键词:多智能体系统、量化因子设计、模型优化、LLM代理、自动化研究、Qlib集成
摘要:在量化金融领域,资产收益预测始终面临高维性、非平稳性与持续波动性的三重挑战。尽管大语言模型(LLMs)与多智能体系统持续发展,但现有量化研究流程仍受限于自动化程度低、可解释性弱、组件协同碎片化等问题。由微软亚洲研究院联合卡内基梅隆大学等机构提出的 R&D-Agent-Quant(简称 R&D-Agent (Q)),创新性地构建了数据驱动的多智能体框架,通过因子 - 模型协同优化,实现了量化策略全流程的自动化研发。本文将从研究背景、框架设计、核心组件、实验验证、相关工作与未来方向六个维度,对该论文进行全面解读。
一、研究背景与核心挑战
1.1 量化金融的核心痛点
金融市场本质是高维非线性动态系统,其收益序列具有重尾分布、时变波动性与复杂横截面相关性三大特征,这使得资产价格同时受宏观因子、微观结构信号与行为反馈影响,预测难度远超传统时间序列问题。
当前量化研究虽已从 “经验驱动” 转向 “数据驱动”,依托 Qlib 等工具简化了数据处理与回测流程,但核心环节仍存在三大关键局限:
- 自动化程度有限:假设生成、编码实现、参数调优等环节依赖大量人工干预,迭代速度慢且易引入主观偏差;半自动化系统无法满足快速变化市场的响应性与扩展性需求。
- 可解释性差:基于 LLM 的现有智能体常直接通过语言交互生成交易信号,缺乏可落地的因子构建与透明的模型逻辑,易产生 “幻觉”,难以应用于需风险控制与解释性的实盘交易。
- 优化碎片化:量化流程涵盖数据处理、因子挖掘、模型训练与评估,但现有方法缺乏系统的任务分解与智能体级协同,“孤岛式” 结构限制了跨阶段反馈与联合性能提升。
1.2 研究目标
针对上述问题,R&D-Agent (Q) 旨在实现三大目标:
- 全流程自动化:覆盖从假设生成到实盘回测的量化研发全链路,减少人工干预。
- 可解释性与鲁棒性平衡:通过可验证的因子与模型输出,降低 “幻觉” 风险,同时保证策略在不同市场环境下的稳定性。
- 因子 - 模型协同优化:打破组件壁垒,通过跨阶段反馈实现因子与模型的动态联合提升。
二、R&D-Agent (Q) 框架设计
R&D-Agent (Q) 将量化研究流程分解为研究(Research) 与开发(Development) 两大核心阶段,通过五个 LLM 驱动的功能单元形成闭环迭代(图 1、图 2)。框架以 “假设 - 实现 - 验证 - 反馈” 为核心逻辑,结合多臂老虎机调度器实现自适应优化方向选择,最终实现策略的持续进化。
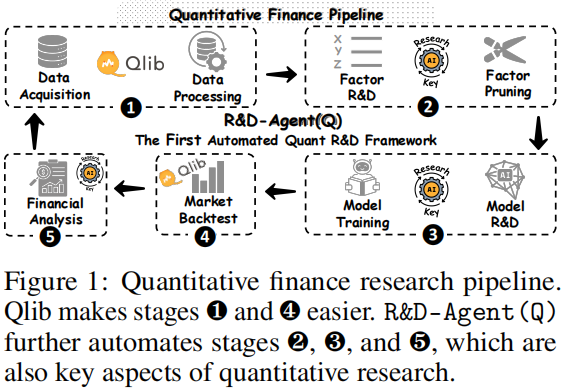
从文中的框架图(如上)可以直观看到:Qlib 简化了数据处理(阶段①)与回测(阶段④),而 R&D-Agent (Q) 进一步自动化了因子研发(阶段②)、模型研发(阶段③)与金融分析(阶段⑤)三大核心环节。
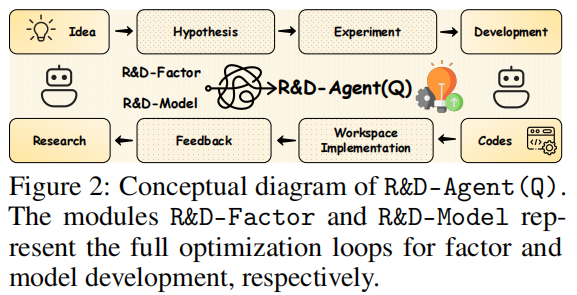
细化R&D-Agent (Q)框架图(如上)可知,方法通过 R&D-Factor(因子研发)与 R&D-Model(模型研发)两个子循环,实现假设生成、实验执行、代码实现与反馈的全链路闭环。
2.1 框架核心工作流
框架的闭环迭代流程可概括为四步:
- 目标对齐:Specification Unit 根据优化目标(如提升年化收益、降低最大回撤)动态生成任务上下文与约束。
- 假设与任务生成:Synthesis Unit 基于历史实验结果构建 “知识森林”,生成新的因子或模型假设,并映射为可执行任务。
- 代码实现与回测:Implementation Unit 通过 Co-STEER 智能体将任务转化为代码,Validation Unit 在 Qlib 平台完成实盘回测。
- 反馈与迭代:Analysis Unit 通过统一指标评估结果,利用多臂老虎机调度器选择下一轮优化方向(因子或模型),并将反馈传递至 Synthesis Unit 启动新迭代。
三、核心功能单元详解
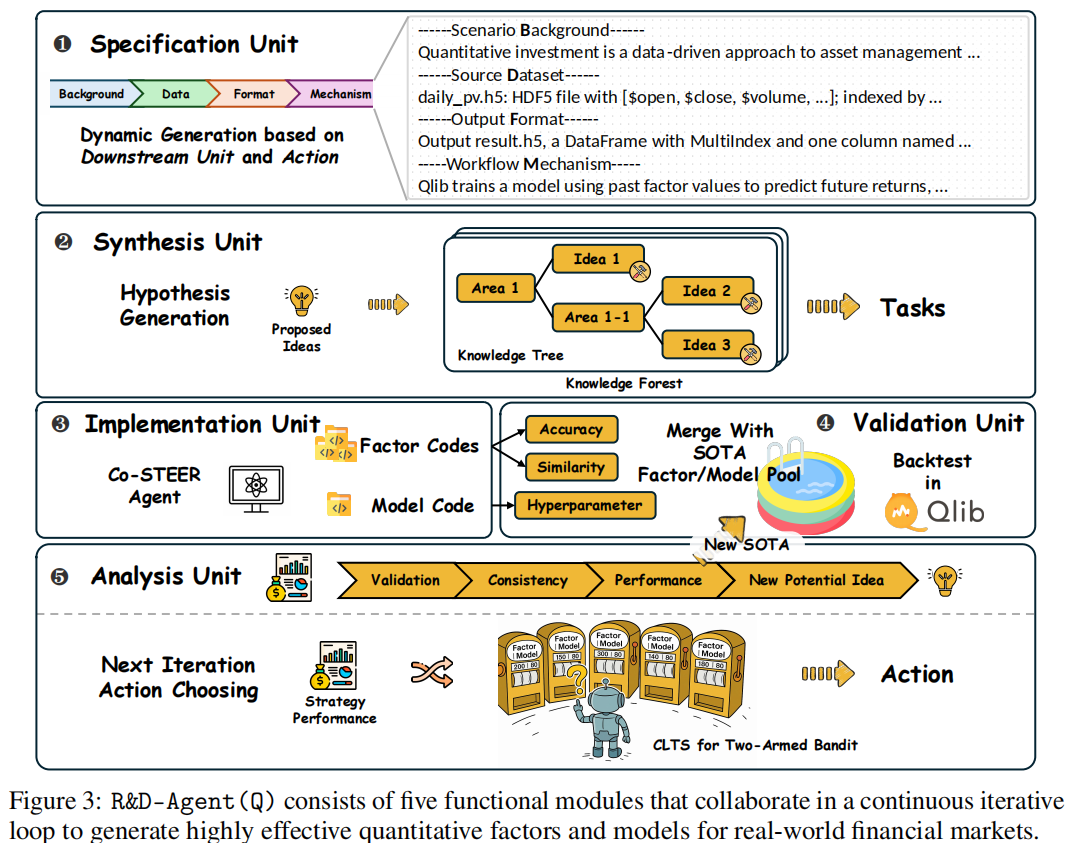
R&D-Agent (Q) 的五个功能单元各司其职且协同联动,每个单元均以 LLM 为核心驱动力,同时融入金融领域特性(如因子相关性过滤、回测标准化)。
3.1 Specification Unit(规格单元)
作为框架的 “顶层设计器”,Specification Unit 负责为下游模块动态配置任务上下文与约束,确保设计、实现与评估的一致性。其核心是定义一个四元组 ![]() :
:
- B:编码因子或模型的背景假设与先验知识(如 “动量因子需基于过去 10 日收益计算”)。
- D:定义市场数据接口(如 HDF5 格式的日度价量数据
daily_pv.h5,包含开盘价、收盘价、成交量等字段)。 - F:指定输出格式(如因子张量、收益预测值的 DataFrame 结构,需包含
datetime与instrument的多级索引)。 - M:定义外部执行环境(如基于 Qlib 的回测框架,屏蔽底层预处理与基础设施细节)。
该单元通过形式化定义,强制所有候选因子 / 模型满足 ![]() 且可在 M 中执行,确保跨组件的兼容性与可复现性。
且可在 M 中执行,确保跨组件的兼容性与可复现性。
3.2 Synthesis Unit(合成单元)
Synthesis Unit 模拟人类分析师的推理过程,基于历史实验结果生成新假设并分解为任务,是 “研究阶段” 的核心。其工作流程分为三步:
步骤 1:历史实验轨迹构建
定义第 轮实验为
,其中
为假设,
为 Analysis Unit 反馈的结果。维护当前最优解集合(SOTA),并基于当前优化方向
(因子或模型)提取相关历史子集:
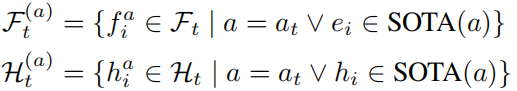
步骤 2:假设生成
通过生成式随机映射 结合历史子集与领域先验,生成新假设
![]() 。生成策略具备自适应性:
。生成策略具备自适应性:
- 若历史反馈
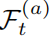 显示成功(如因子 IC 提升),则增加假设复杂度(如引入多周期组合因子)。
显示成功(如因子 IC 提升),则增加假设复杂度(如引入多周期组合因子)。 - 若反馈显示失败,则调整假设结构(如替换变量或简化公式),避免陷入局部最优。
步骤 3:任务分解
- 因子假设:因因子异质性与潜在交互性,将单个因子假设分解为多个子任务(如 “30 日累积收益因子” 需拆分为 “日度收益计算”“滚动窗口求和” 等子任务)。
- 模型假设:因模型结构连贯性,将单个模型假设映射为一个完整任务(如 “基于 LSTM 的收益预测模型” 包含网络结构定义、训练参数设置等)。
3.3 Implementation Unit(实现单元)
Implementation Unit 负责将 Synthesis Unit 生成的任务转化为可执行代码,核心是论文提出的Co-STEER 智能体—— 专为量化研究设计的代码生成与调度系统,具备 “任务调度 - 代码实现 - 知识积累” 三位一体的能力。
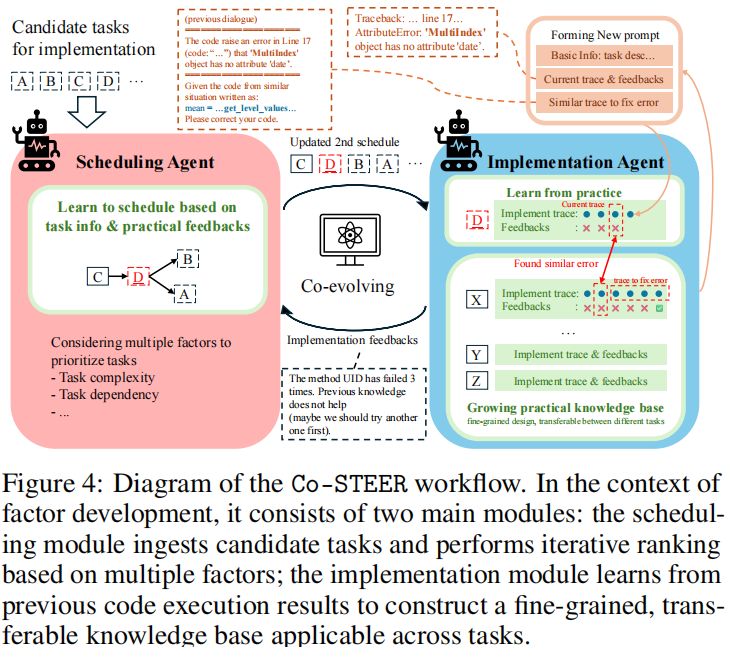
原文中图 4 显示:Co-STEER 包含调度智能体(基于任务复杂度与依赖排序)与实现智能体(基于历史知识生成代码),通过反馈持续优化任务执行顺序与代码质量。
Co-STEER 的核心设计
-
任务调度(Scheduling Agent):
- 构建有向无环图(DAG)表示任务依赖(如 “计算滚动波动率” 需先 “计算日度收益”)。
- 基于拓扑排序
与反馈动态调整优先级:若某任务反复失败,提升简单任务优先级以积累知识,降低后续实现难度。
-
代码实现(Implementation Agent):
- 基于任务描述与知识 base
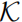 生成代码
生成代码 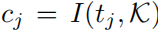 ,知识 base 记录 “任务 - 代码 - 反馈” 三元组
,知识 base 记录 “任务 - 代码 - 反馈” 三元组 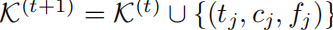 。
。 - 知识迁移:通过计算新任务与历史任务的相似度,复用成功代码如
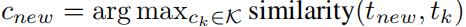 ,提升代码生成效率与正确性。
,提升代码生成效率与正确性。
- 基于任务描述与知识 base
-
迭代优化:目标是最大化累积代码质量
,其中
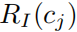 评估代码正确性(如是否通过语法检查)与性能(如计算效率)。
评估代码正确性(如是否通过语法检查)与性能(如计算效率)。
Co-STEER 与现有方法的对比
下表显示,Co-STEER 是首个整合 “调度 - 推理 - 反馈 - 知识积累” 的量化代码生成方案,远超现有孤立方法的能力:
| 方法 | 任务调度 | 实现前推理 | LLM 自反馈 | 实用知识增长 |
|---|---|---|---|---|
| Few-shot [71] | ✗ | ✓ | ✗ | ✗ |
| CoT [35] | ✗ | ✗ | ✓ | ✗ |
| Reflexion [72] | ✗ | ✗ | ✗ | ✓ |
| Self-Debugging [74] | ✗ | ✗ | ✗ | ✓ |
| Co-STEER(本文) | ✓ | ✓ | ✓ | ✓ |
3.4 Validation Unit(验证单元)
Validation Unit 评估因子与模型的实盘有效性,通过标准化流程确保评估结果的可比性,分为因子验证与模型验证两类:
因子验证流程
- 去重过滤:计算新因子与现有 SOTA 因子库的相关性(信息系数 IC),若新因子与任一 SOTA 因子的平均 IC 最大值
,则判定为冗余并剔除。
- 回测评估:将过滤后的新因子与当前 SOTA 模型(如 LightGBM)结合,在 Qlib 平台执行日度多空策略(基于预测收益排序选股),评估年化收益(ARR)、最大回撤(MDD)等指标。
模型验证流程
将候选模型与当前 SOTA 因子集结合,通过相同回测 pipeline 评估性能,确保模型提升源于结构优化而非因子贡献。
3.5 Analysis Unit(分析单元)
Analysis Unit 兼具 “研究评估器” 与 “策略分析师” 双重角色,是框架闭环的关键,核心功能包括:
1. 多维度结果评估
对每轮实验的假设 、任务
与结果
进行评估:
- 若结果优于当前 SOTA,则将其加入对应 SOTA 集合(如因子 SOTA 或模型 SOTA)。
- 若失败,诊断原因(如因子过拟合、模型泛化性差)并生成针对性改进建议(如 “增加因子的时间窗口多样性”)。
2. 自适应优化方向选择
通过上下文汤普森采样(Contextual Thompson Sampling) 解决 “因子优化” 与 “模型优化” 的二臂老虎机问题,动态选择下一轮优化方向:
- 状态向量:提取 8 维策略性能向量
(MDD 取负以 align 收益目标)。
- 奖励模型:为每个优化方向维护贝叶斯线性回归模型,采样奖励系数
,计算预期奖励
,选择奖励最高的方向。
- ** posterior 更新 **:根据实际实验结果更新模型 posterior,平衡 “探索”(尝试新方向)与 “沿用”(优化已知有效方向)。
四、实验验证与结果分析
论文在CSI 300(中国 A 股)、CSI 500(中国 A 股) 与NASDAQ 100(美股) 三个市场数据集上进行了全面实验,验证 R&D-Agent (Q) 的性能、通用性与成本效率。
4.1 实验设置
数据集与拆分
- CSI 300:2008.01-2014.12(训练)、2015.01-2016.12(验证)、2017.01-2020.08(测试)。
- CSI 500/NASDAQ 100:2008.01-2021.12(训练)、2022.01-2023.12(验证)、2024.01-2025.06(测试),确保 LLM 训练截止时间早于测试期,避免数据泄露。
基线与评测指标
- 因子基线:Alpha 101、Alpha 158、Alpha 360、AutoAlpha。
- 模型基线:传统机器学习(Linear、LightGBM、XGBoost)、深度学习(LSTM、Transformer、Mamba、TRA)。
- 评测指标:
- 因子预测能力:信息系数(IC)、IC 信息比(ICIR)、Rank IC。
- 策略性能:年化收益(ARR)、信息比(IR)、最大回撤(MDD)、Calmar 比(CR)。
框架配置
- R&D-Factor:固定模型为 LightGBM,优化因子集(从 Alpha 20 起步)。
- R&D-Model:固定因子集为 Alpha 20,优化模型结构。
- R&D-Agent(Q):联合优化因子与模型,总运行时间 12 小时(单组件各 6 小时)。
4.2 核心实验结果
1. 主结果:CSI 300 市场性能
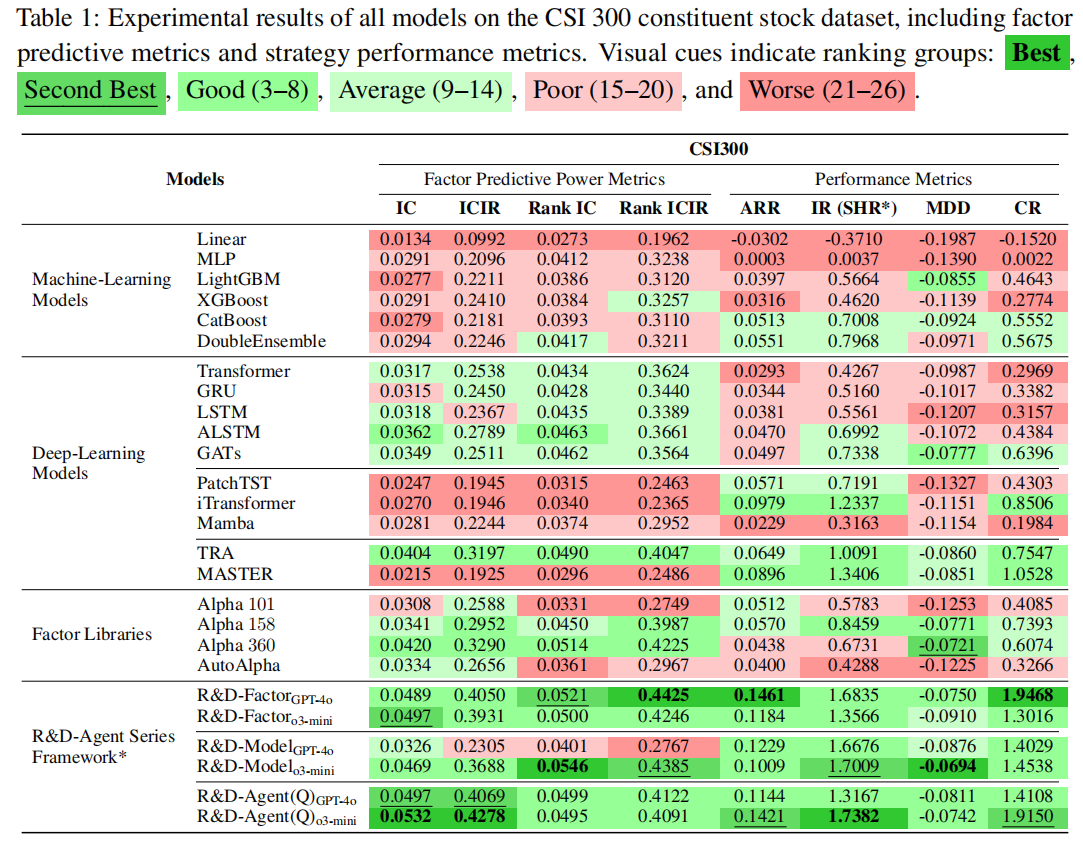
原文中表 1 显示,R&D-Agent (Q) 在所有指标上全面超越基线,核心亮点包括:
- R&D-Factor:仅优化因子,使用 70% 更少的因子实现更高 IC(最高 0.0497)与 ARR(最高 14.61%),远超 Alpha 158/360 等静态因子库。
- R&D-Model:仅优化模型,R&D-Model₀₃-mini 实现最优 Rank IC(0.0546)与最小 MDD(-6.94%),证明自适应模型结构比固定 ML/DL 架构更鲁棒。
- R&D-Agent(Q):联合优化实现综合最优,IC=0.0532、ARR=14.21%、IR=1.74,远超最强基线(如 Alpha 158 的 ARR=5.70%、TRA 的 IR=1.01)。
2. 研究组件分析:假设生成的探索与利用平衡
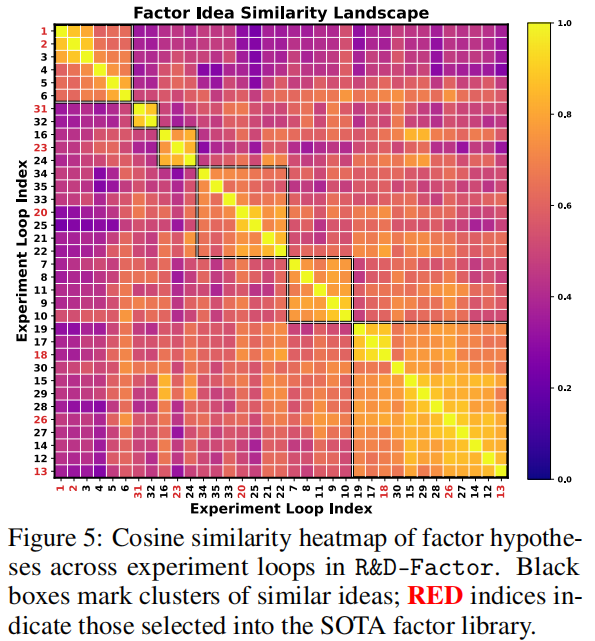
通过 Sentence-BERT 编码假设文本,计算余弦相似度并聚类(图 5,黑色框标注相似假设聚类,红色索引为入选 SOTA 的实验),发现 R&D-Factor 的假设生成呈现三大模式:
- 局部优化后转向:如实验 1-6、7-11 形成聚类块,表明在方法会在同一方向多轮优化后动态切换,平衡深度与创新性。
- 策略性重访:实验 26 与早期实验 12-14 聚类,证明智能体重访并优化早期有潜力的假设。
- 多路径协同:36 轮实验中 8 轮入选 SOTA,覆盖 5 个聚类,说明方法会多方向探索产生互补信号,提升最终因子库质量。
3. 开发组件分析:Co-STEER 代码生成能力
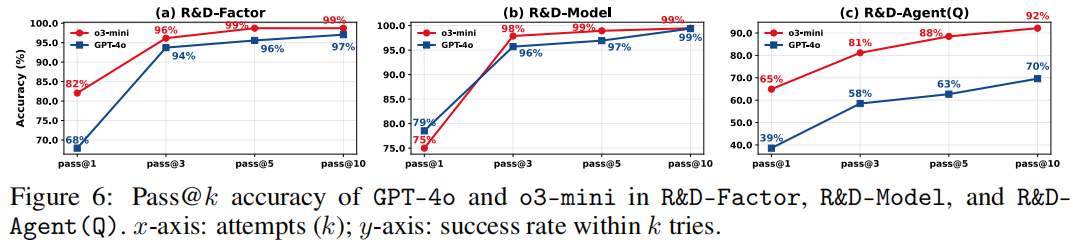
原文中图 6 显示(x 轴为尝试次数 k,y 轴为成功率),Co-STEER 在因子、模型与联合任务中,代码通过率(pass@k)快速收敛,证明了其迭代自修正能力:
- 复杂任务(如 R&D-Agent (Q) 联合优化)中,o3-mini 的 pass@k 始终高于 GPT-4o,因其更强的链式推理能力更适配结构化编码场景。
- 仅需 5-10 次尝试,通过率即可达 90% 以上,远高于现有无反馈代码生成方法。
4. 因子与模型单独优化效果
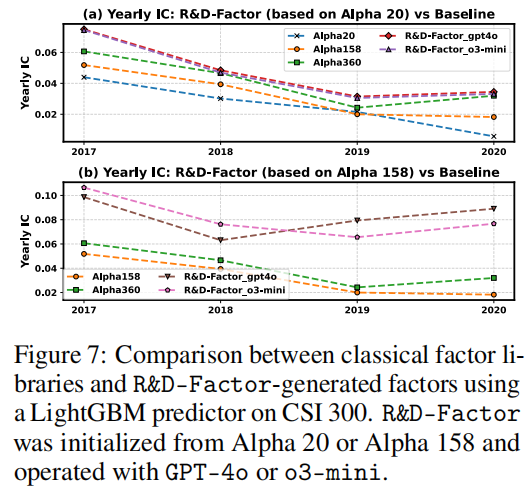
- 因子效果(图 7):即使从 Alpha 20 起步,R&D-Factor 也能快速达到 Alpha 158/360 的 IC 水平,2019-2020 年市场波动期仍保持稳定 IC(基线显著下降);如从 Alpha 158 起步时,IC 进一步提升至 0.07 以上。
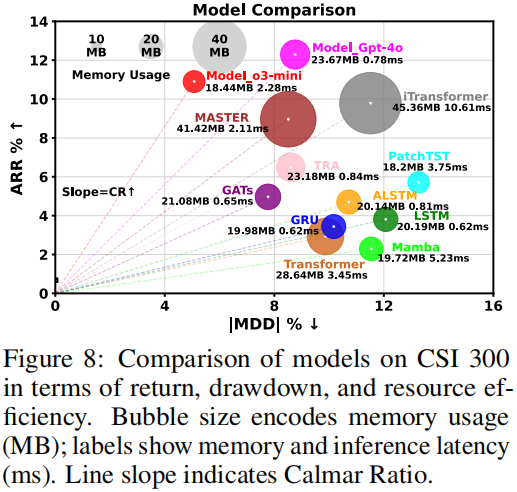
- 模型效果(图 8,气泡大小代表内存占用,斜率为 Calmar 比):R&D-Model 的两个变体均位于 “高收益 - 低回撤” 区域,R&D-Model₄₀实现 12% ARR 与 8% MDD,风险收益比(Calmar 比)最优;R&D-Model₀₃-mini 在更严格风险约束下仍保持 11% ARR,证明模型优化的风险平滑作用。
5. 通用性与成本效率
R&D-Agent (Q)₀₄-mini 在两个市场的 IR 与 MDD 指标均排名 Best,验证了其跨市场通用性。
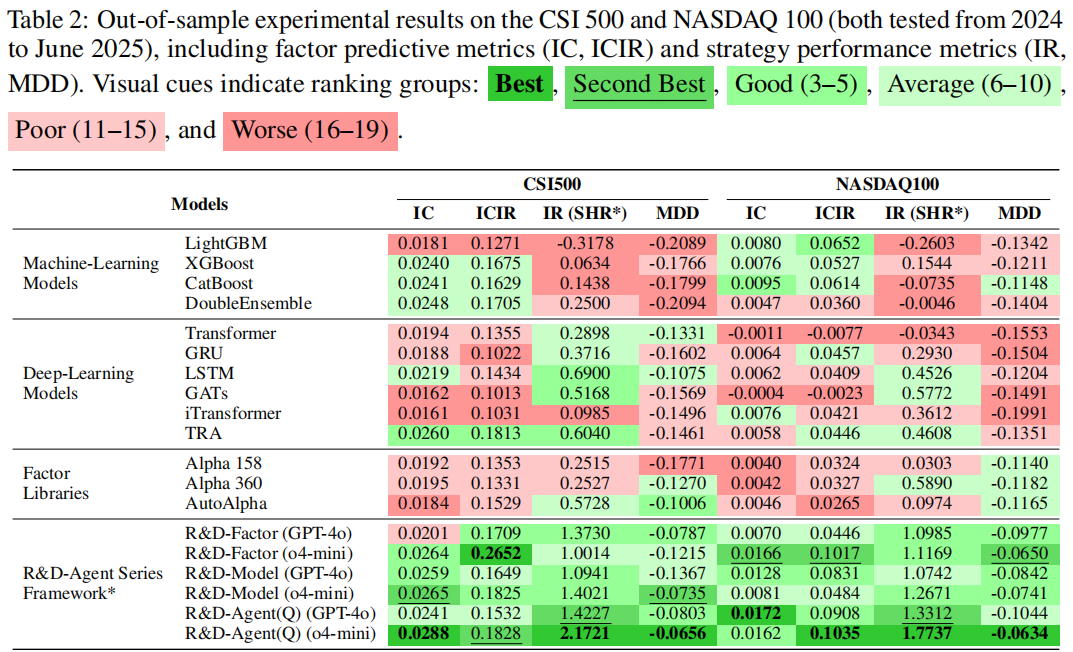
- 跨市场通用性:表 2 显示,R&D-Agent (Q) 在 CSI 500 与 NASDAQ 100 市场仍保持最优性能,如 NASDAQ 100 的 ARR=28.40%、MDD=-6.34%,证明框架不受市场地域限制。
- 成本效率:总运行成本低于 10 美元,远低于人工研发成本;单轮迭代平均耗时 15 分钟,支持快速策略迭代。
6. 消融实验:调度策略的影响
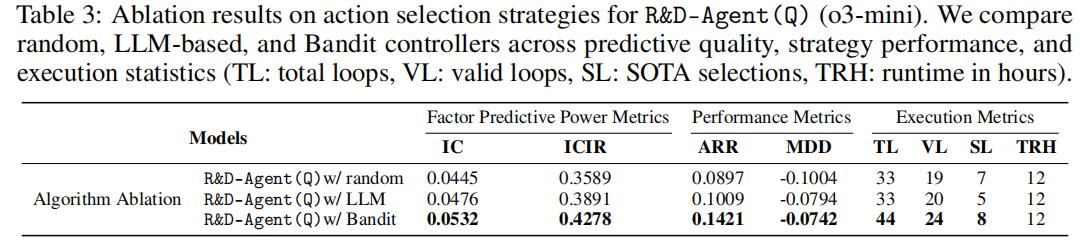
表 3 显示,多臂老虎机调度器是性能关键:
- 随机调度:性能最差,IC=0.0445、ARR=8.97%,证明无指导探索效率低。
- LLM 调度:性能中等,但因额外模型调用导致迭代次数少(有效循环 20 次)。
- 老虎机调度:最优,IC=0.0532、ARR=14.21%,有效循环 24 次,证明自适应调度能最大化资源利用率。
4.3 扩展实验:真实量化竞赛验证
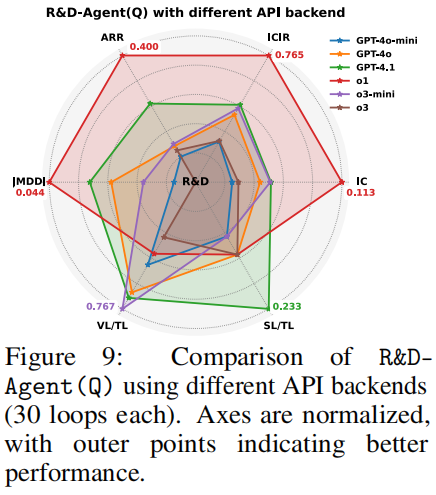
在 Kaggle Optiver 波动率预测竞赛中,R&D-Agent (Q) 通过 12 轮迭代即找到最优策略:
- 核心发现:捕捉买卖价差的时间演化特征(如 5/10/30 秒滚动统计)对短期波动率预测最有效。
- 性能:RMSPE(均方根百分比误差)降至 0.5 以下,优于竞赛基线,证明框架在真实量化任务中的实用性。
五、相关工作与对比
5.1 传统量化方法
- 因子挖掘:从 Fama-French 三因子(1993)到 Alpha 101/158(人工设计),再到 AutoAlpha(LLM 驱动),但均缺乏动态迭代与协同优化。
- 模型创新:从 ARIMA(传统时间序列)到 LSTM/Transformer(深度学习),再到 TRA/MASTER(金融专用模型),但固定结构难以适应市场 regime 变化。
R&D-Agent (Q) 的突破在于:将因子与模型视为协同系统,通过闭环迭代实现动态联合优化,而非孤立优化单个组件。
5.2 LLM 驱动的金融智能体
现有工作如 FinAgent、TradingAgents 聚焦于特定子任务(如新闻信号提取、组合更新),依赖语义信号易产生 “幻觉”;而 R&D-Agent (Q):
- 以数据为中心,所有输出均为可验证的代码与因子,降低 “幻觉” 风险。
- 实现全流程自动化,而非局部任务优化。
- 引入多臂老虎机等强化学习机制,动态平衡探索与利用。
六、局限性与未来方向
6.1 现有局限性
- 多模态数据融合不足:当前仅处理价量与基本面数据,未整合新闻情感、宏观经济等各类数据。
- 领域知识依赖 LLM 内置:假设生成依赖 LLM 的通用金融知识,未融入结构化领域专家知识(如学术论文、监管报告等)。
- 实时性差:批处理设计难以适应高频交易,无法实时响应市场异常。
6.2 未来研究方向
- 多模态数据集成:引入文本(新闻)、图像(财报图表)、高频数据,丰富因子信号来源。
- 检索增强生成(RAG):构建金融领域知识库(如论文、研报),通过 RAG 提升假设的领域合理性与生成效率。
- 实时自适应学习:结合事件驱动与增量学习,实现高频市场的动态策略调整。
- 跨领域迁移:将框架适配至医疗(药物研发)、材料科学(配方优化)等需 “假设 - 验证” 的领域,推动通用科研自动化。
七、总结
R&D-Agent-Quant 是量化金融领域首个数据驱动的多智能体协同优化框架,通过 “研究 - 开发” 闭环与五大功能单元,实现了量化策略全流程的自动化、可解释与高性能。其核心贡献包括:
- 技术创新:提出 Co-STEER 智能体解决量化代码生成问题,引入多臂老虎机调度器平衡探索与利用。
- 性能突破:在三大市场实现 2 倍于传统因子库的年化收益,使用 70% 更少因子,成本低于 10 美元。
- 实践价值:代码开源(https://github.com/microsoft/RD-Agent),支持快速复现与实盘适配,为量化研发提供标准化工具链。
该框架不仅推动量化金融的智能化升级,更为科研自动化提供了 “数据驱动 - 多智能体协同 - 闭环迭代” 的通用范式,具备广阔的跨领域应用前景。