简述深度学习中的四种数据并行方法(DP,DDP,TP,PP)
DP (data parallelism, 数据并行)
下图计算GPU称为Worker,梯度聚合GPU称为Server
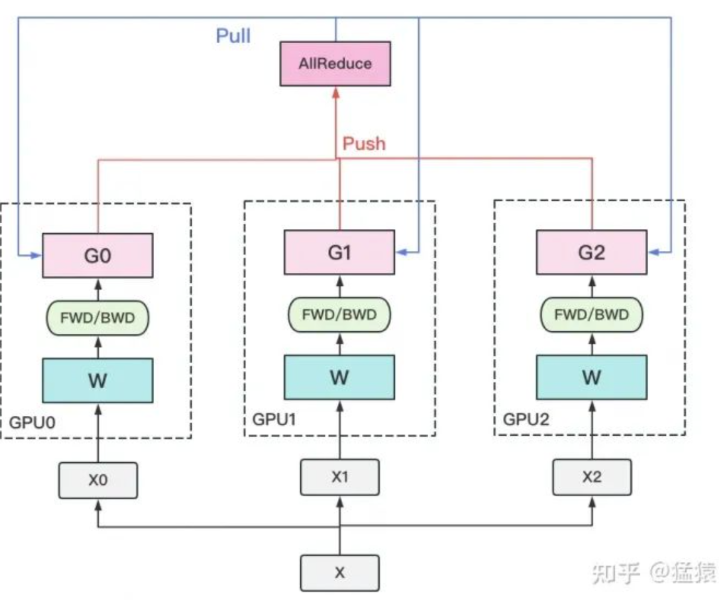
1. 若干块计算GPU,如图中GPU0~GPU2;1块梯度收集GPU,如图中AllReduce操作所在GPU。
2. 在每块计算GPU上都拷贝一份完整的模型参数。
3. 把一份数据X(例如一个batch)均匀分给不同的计算GPU。
4. 每块计算GPU做一轮FWD和BWD后,算得一份梯度G。
5. 每块计算GPU将自己的梯度push给梯度收集GPU,做聚合操作。这里的聚合操作一般指梯度累加。当然也支持用户自定义。
6. 梯度收集GPU聚合完毕后,计算GPU从它那pull下完整的梯度结果,用于更新模型参数W。更新完毕后,计算GPU上的模型参数依然保持一致。
7. 聚合再下发梯度的操作,称为**AllReduce**。
将每批输入的训练数据都在 DP 的 worker 之间进行平分。反向传播之后,需要进行通信来保证优化器在各个 worker 上可以得到相同的更新参数
优势,计算效率高,工程上易于实现
不足:会在所有 worker 之间复制模型和优化器,因此显存效率不高。且随着并行度的提高,每个 worker 执行的计算量是恒定的。 DP 可以在小规模上实现近乎线性扩展。但是,因为在 worker 之间规约梯度的通信成本跟模型大小成正相关,所以当模型很大或通信带宽很低时,计算效率会受到限制
DDP 分布式数据并行
去Server,留Worker
DP一般用于单机多卡场景。因此,DDP作为一种更通用的解决方案出现了,既能多机,也能单机。
使用Ring-AllReduce
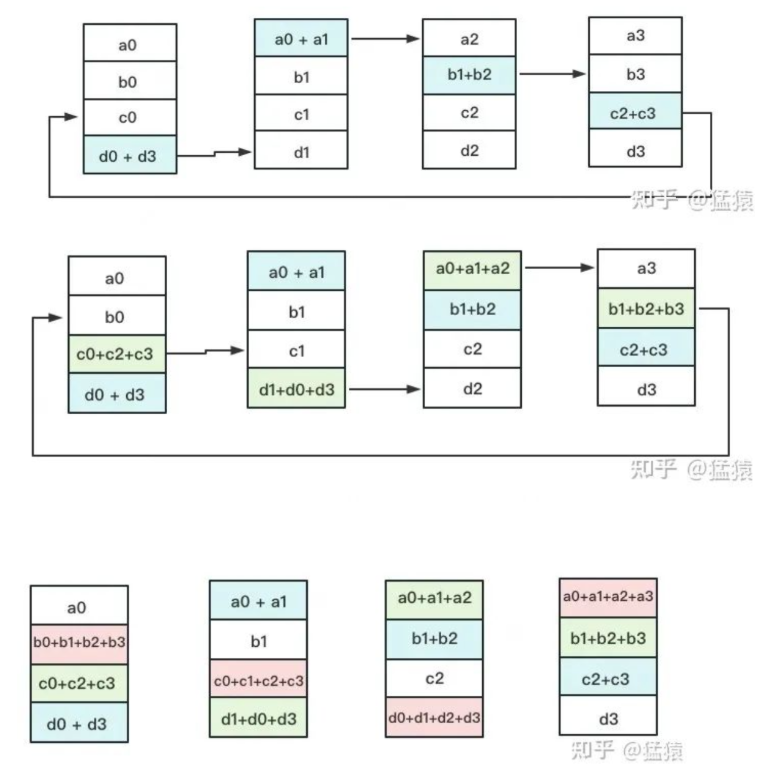
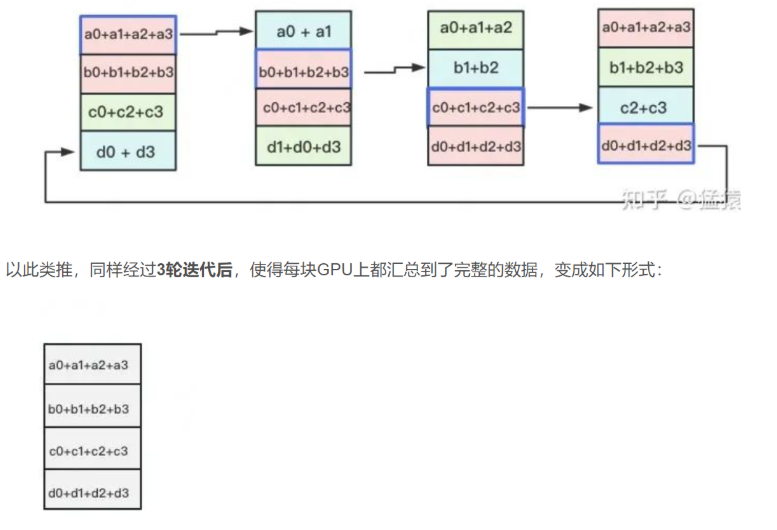
Ring-ALLReduce则分两大步骤:Reduce-Scatter和All-Gather。
Ring-AllReduce
Reduce-Scatter
定义网络拓扑关系,使得每个GPU只和其相邻的两块GPU通讯。每次发送对应位置的数据进行**累加**。每一次累加更新都形成一个拓扑环,因此被称为Ring。一次累加完毕后,蓝色位置的数据块被更新,被更新的数据块将成为下一次更新的起点,继续做累加操作
All-Gather
All-Gather阶段。目标是把红色块的数据广播到其余GPU对应的位置上。
TP(tensor model parallelism, 张量模型并行)
由于模型巨大,无法装入单个GPU,此时需要模型并行
模型并行会在多个 worker 之间划分模型的各个层,模型并行会根据 worker 数量成比例地减少显存使用量
DeepSpeed 利用了 Megatron-LM 来构建基于 Transformer的大规模模型并行语言模型
优势:会根据 worker 数量成比例地减少显存使用,这是这三种并行模式中显存效率最高的。且可以通过在模型并行 worker 之间划分激活显存,减少显存占用
不足:每次前向和反向传播中都需要额外通信来传递激活,模型并行的计算效率很低。
PP(pipline parallelism, 流水线并行)
流水线并行的核心思想是:在模型并行的基础上,进一步引入数据并行的办法(将模型的各层划分为可以并行处理的阶段),即把原先的数据再划分成若干个batch,送入GPU进行训练。未划分前的数据,叫mini-batch。在mini-batch上再划分的数据,叫micro-batch
优势:流水线并行减少的显存与流水线的阶段数成正比,这使模型的大小可以随 worker 的数量线性扩展,并且通过 micro-batch 可以有效减少 bubble。此外,流水线的通信量只和阶段边界的各层的激活值大小成正比,所以流水线并行的通信量最低
不足:每个 worker 必须同时存储并运行的各个 micro-batch 的激活值,导致流水线第一阶段的激活内存与单个 mirco-batch 的总激活内存大致相同。不断增加流水线大小会减少每个流水线阶段的计算量,降低计算通信效率。流水线并行还对每个阶段的负载均衡有很高的要求。