YOLO-World 全面解析:实时开放词汇目标检测的新范式(附实践指南)
适用读者:计算机视觉工程师、算法研究员、边缘端部署工程师、业务产品经理
关键词:Open-Vocabulary Detection(开放词汇检测,OVD)、YOLO、CLIP、GroundingDINO、GLIP、LVIS、Objects365、ONNX/TensorRT
文章目录
-
前言
-
1. 为什么需要 YOLO-World
-
2. YOLO-World 的三大关键点
-
2.1 RepVL-PAN:让“语言”进到特征金字塔
-
2.2 区域-文本对比预训练(Region-Text Contrastive)
-
2.3 Prompt-then-Detect:离线词表,在线极速
-
-
3. 模型版本与能力概览
-
4. 与常见开源 OVD 的差异
-
5. 快速上手(Ultralytics 生态)
-
6. 进阶:官方仓库(MMYOLO/MMDet)全流程
-
7. 结语
-
参考与延伸阅读
前言
通过前边的 YOLO 检测器和文本编码器分别得到了特征图像和词向量,那么如何实现二者的融合,以达到开放词汇目标检测的目的?YOLO-World 中提出了新的网络架构 RepVL-PAN(Re-parameterizable Vision-Language Path Aggregation Network),它通过融合视觉信息和语言信息来提升检测性能并兼顾实时推理。
1. 为什么需要 YOLO-World
传统检测器(如经典 YOLO/RetinaNet/FCOS/DETR 等)只能识别训练集预定义的 固定类别(例如 COCO 的 80 类)。在真实业务中,我们往往需要快速扩展到长尾或临时的类别:\
-
交通安全:掉落物、路锥、反光三角牌、油渍、冒烟车辆、危化品标志……\
-
工业巡检:磨损件裂纹、异常阀门指针、临时告示牌……
**开放词汇检测(OVD)**的目标是“用文本提示/自然语言,检测训练集中未出现过的新类别”。
YOLO-World 的贡献在于:
-
把 YOLO 的实时性 与 视觉-语言预训练 结合;
-
引入 Prompt-then-Detect(先编码提示,再检测) 的高效推理策略;
-
通过 RepVL-PAN 与 区域-文本对比学习,在 V100 上 52 FPS 的同时在 LVIS 获得强劲零样本精度(论文原始报告)。
本文将从架构、训练范式、模型版本、对比评价、以及工程落地全方位解析。

2. YOLO-World 的三大关键点(详细版)
本章不使用任何公式,全部用文字、步骤与伪代码,确保 CSDN 复制后不乱码。
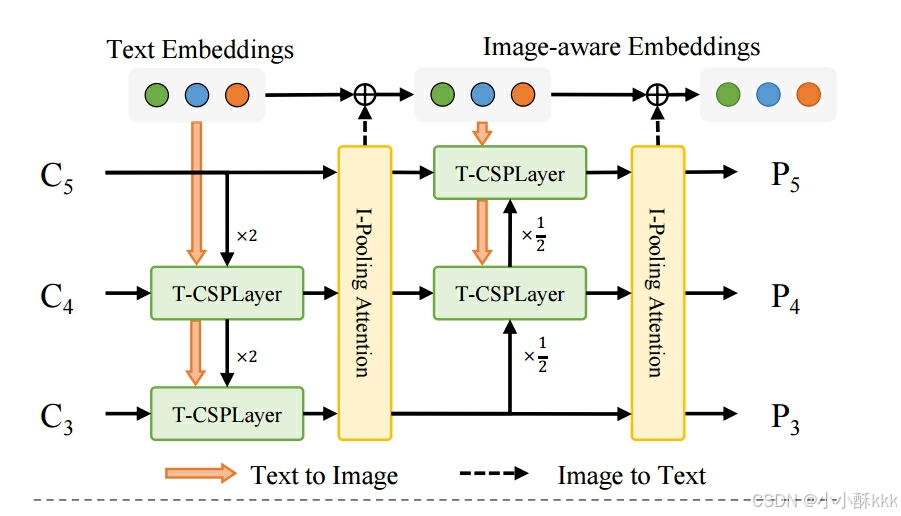
2.1 RepVL-PAN:让“语言”进到特征金字塔
目标:在 YOLO 的多尺度特征金字塔(PAN)里,把文本语义和图像特征双向对齐,做到:\
-
训练时:显式地让文本向量与多尺度图像特征交互;\
-
部署时:把离线词表对应的文本向量折叠进卷积/线性层权重(可重参数化),移除文本编码器,时延仍保持 YOLO 级别(论文在 LVIS 上报告约 52 FPS@V100)。
组成模块:
-
T-CSPLayer(Text-guided CSPLayer) —— “文字→图像”的引导
在常规 CSPLayer 的瓶颈后加入一个Max-Sigmoid 注意力门:
-
对每个空间位置,与所有词向量做相似度,取“最大相似度”作为该位置的响应;
-
把该响应过 Sigmoid 得到 0~1 的权重,逐点放大/抑制像素通道特征;
-
直觉:和词更相关的位置被“点亮”,与词不相关区域被抑制;
-
放置位置:通常在每层 PAN 融合后的 CSPLayer 末端、Dark Bottleneck 之后执行。
伪代码(仅示意):
# X: [H, W, C] 图像特征 Wtxt: [num_words, C] 离线文本向量
S = cosine_similarity(X, Wtxt) # 与所有词的相似度
G = S.max(axis=word_dim) # 每个像素取与最相关词的相似度
A = sigmoid(G) # 0~1 注意力门
X_out = X * A[..., None] # 按像素位置缩放通道
-
Image-Pooling Attention(I-Pooling) —— “图像→文字”的反哺
不是直接对整幅特征做 Cross-Attention,而是先对多尺度特征做最大池化,规则地切成 3×3 小块(每尺度 9 个),跨尺度拼成 27 个 patch tokens。用这些 tokens 作为键/值,通过多头注意力去更新文本向量(得到更“懂图像”的文本向量)。
为什么有效:
-
提前在中层把“语义”灌入视觉特征,利于小目标/遮挡;
-
文本被图像“提醒”当前场景含有哪些显著区域,减少歧义;
-
关键是可重参数化:部署时把这套交互折叠进权重,不增加端侧算子与时延。
实践提示:
-
词表尽量名词化(必要时中英并给),T-CSPLayer 的门控会更稳;
-
对易混淆概念(如 cone/barrier/pole),建议都放入词表,减少负面干扰;
-
I-Pooling 的 3×3 摘要可看成“低成本图像摘要”,对复杂场景下的词义消歧有帮助。
2.2 区域-文本对比预训练(Region-Text Contrastive)
统一监督形式:把检测、短语定位、图文对三类数据都整理成**“区域-文本对”:每个框都对应一个名词/短语(类别名或描述)。模型除了做框回归,还输出对象嵌入**,并与文本嵌入做相似度匹配,以此完成“开放词汇分类”。
训练头(直观版):
-
对对象向量与文本向量做归一化后计算相似度;
-
用交叉熵约束“正确框—正确词”的最高相似度;
-
框回归沿用常规检测损失(如 IoU Loss + DFL 等),容易并入现有 YOLO 训练管线。
数据配方:
-
检测数据(如 Objects365)、Grounding 数据(如 GQA/Flickr30k),再叠加从 CC3M 规则筛选得到的轻量图文框数据(常称 CC3M-Lite/改版);
-
文本编码器(如 CLIP-Text)在预训练阶段通常冻结;
-
训练时使用在线词表(正样本名词 + 随机负样本),上限常设为约 80 项,增强抗混淆能力。
实践提示:
-
行业落地可用“少量高信噪行业数据 + 通用开集数据”继续预训练;
-
在线词表要采样近义/易混负样本(如 cone/barrier/pole),能有效抑制误报;
-
数据少时先做Prompt Tuning(只学习词向量)即可拿到较大增益。
2.3 Prompt-then-Detect:离线词表,在线极速
传统 OVD 往往在线编码用户提示,类别一多速度就掉。YOLO-World 的做法:
-
启动/编译阶段:把类名/短语一次性编码成离线词表嵌入;\
-
导出/部署阶段:把这些嵌入重参数化到模型权重;\
-
在线推理:只跑一次轻量 YOLO 前向,不再触发任何文本编码,速度对类别数不敏感。
Ultralytics 已把这套流程封装为 set_classes() → predict() →(可选)export(),便于工程落地与多场景词表管理。
实践提示:
-
维护多份场景化离线词表(白天/夜晚/雨雾/桥隧/施工等),上线时按场景切换;
-
类别改动只需替换词表并重新导出一次(ONNX/TensorRT/NCNN 等),推理侧代码无需改。
3. 模型版本与能力概览
-
官方提供 S/M/L/X 多规格与 640/800/1280 输入分辨率,覆盖从边缘端到服务器的不同算力;\
-
从最初版本演进到 YOLO-World v2 / v2.1,在零样本 LVIS/COCO 等评测上持续提升(更高 AP、更快推理、更好的小目标表现);\
-
还提供 YOLO-World-Seg(开放词汇分割)与 高分辨率 1280 配置,增强小目标与密集场景的可用性。
训练数据卡片(示例):
PT=预训练,CPT=继续预训练,数据包含 Objects365 v1、GoldG、CC-LiteV2(CC3M-Lite 的改版)。
4. 与常见开源 OVD 的差异
| 模型 | 推理范式 | 速度 | 典型优势 | 典型劣势 |
|---|---|---|---|---|
| YOLO-World | 离线词表 + 轻量 YOLO | 快(实时) | 工业/视频实时、易部署、可重参数化 | 文本-图像交互相对简化,对长句/复杂短语的鲁棒性略逊于大型 Transformer |
| GroundingDINO | 在线文本编码 + 交互(Transformer) | 中/慢 | 短语级 Grounding 强、召回强 | 资源占用高、边缘端部署成本高 |
| GLIP | 大规模短语定位预训练 | 中 | 文本对齐充分 | 模型较重、实时性一般 |
| OWL-ViT | ViT + 文本对齐 | 中 | 端到端简洁 | 速度/部署与 YOLO 系不在一个量级 |
结论:在 “需要实时” 的业务(智能交通、零售监控、移动端等),YOLO-World 常是首选;在 “追求短语级 Grounding 召回” 的研究/离线场景,GroundingDINO 等依旧有价值。
5. 快速上手(Ultralytics 生态)
Ultralytics 已集成 YOLO-World(包含 v2),适合快速实验与小规模训练:
5.1 安装
pip install -U ultralytics
5.2 零样本推理(自定义词表)
from ultralytics import YOLOWorld# 选择轻/中/大:yolov8s-worldv2.pt / yolov8m-worldv2.pt / yolov8l-worldv2.pt / yolov8x-worldv2.pt
model = YOLOWorld("yolov8s-worldv2.pt")# 设置自定义类别(中英文均可;建议以"名词"为主,必要时给同义词)
model.set_classes(["traffic cone", "fallen rock", "spill", "smoke", "hazardous goods sign","road barrier", "tow truck", "broken-down car"
])# 单张图/目录/视频皆可
results = model.predict(source="/path/to/your/video_or_images")
经验贴士:\
使用名词而非形容词,如“smoking car”不如“smoke, car”;\
中文可用,但建议同时给英文同义词;\
类别过多会略降速,建议按业务分场景维护词表。
5.3 训练你自己的开放词汇检测器
from ultralytics import YOLOWorld# 建议使用 *worldv2* 款,支持可导出 ONNX/TensorRT
model = YOLOWorld("yolov8s-worldv2.pt")# data.yaml 按 YOLOv8 标准写:train/val 路径 +(可选)names/提示词
model.train(data="data.yaml", imgsz=640, epochs=100, batch=16, device=0)
5.4 导出与部署
# ONNX(静态输入);安装 onnxruntime-gpu 后即可推理
yolo export model=yolov8s-worldv2.pt format=onnx opset=12# TensorRT(需本机有 TensorRT)
yolo export model=yolov8s-worldv2.pt format=engine half=True
6. 进阶:官方仓库(MMYOLO/MMDet)全流程
若需完整的预训练/继续预训练/重参数化流程,建议使用官方仓库:
git clone --recursive https://github.com/AILab-CVC/YOLO-World.git
cd YOLO-World
pip install -e .# 8 卡示例(混合精度)
chmod +x tools/dist_train.sh
./tools/dist_train.sh \configs/pretrain/yolo_world_l_t2i_bn_2e-4_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py \8 --amp# 评测
chmod +x tools/dist_test.sh
./tools/dist_test.sh path/to/config path/to/weights 8
微调策略:
-
Normal Fine-tuning:常规微调;
-
Prompt Tuning:只学“提示词嵌入”(快,数据少时好用);
-
Reparameterized Fine-tuning:适用于与通用场景差距较大的垂直行业(如高速公路),对部署更友好。
仓库还提供 ONNX/TFLite/INT8 量化 说明与 Gradio/HF Space Demo;边缘端部署可优先尝试 ONNX/TFLite,满足功耗/时延约束。
7. 结语
YOLO-World 把开放词汇与实时检测“拉到了一起”:在不牺牲速度的前提下,显著扩展了可检类别。对追求实时与可部署的落地团队,这是一个非常实际的解决方案。建议先用 Ultralytics 做词表与零样本验证,再转官方仓库做继续预训练与重参数化,最后完成端上导出与量化。
参考与延伸阅读
-
论文(CVPR 2024):https://arxiv.org/abs/2401.17270
-
开源仓库(官方):https://github.com/AILab-CVC/YOLO-World
-
Ultralytics 模型页(含 worldv2 用法与权重):https://docs.ultralytics.com/models/yolo-world/
-
在线演示(Hugging Face Space):https://huggingface.co/spaces/TencentARC/YOLO-World
注:文中训练/部署命令基于官方/Ultralytics 文档撰写,请以实际版本为准。