监督微调(SFT)入门:从理论到动手实践
监督微调(SFT)入门:从理论到动手实践
监督微调(Supervised Fine-Tuning, SFT) 是赋予大型语言模型(LLM)特定技能的关键步骤,它通过模仿“问题-标准答案”的范例,让模型学会遵循指令。本文将从 SFT 的基本概念出发,结合 DataWhale 的 Lesson_3.ipynb 教程,带你完整走一遍 SFT 的理论、环境配置、代码实现与效果验证全流程。
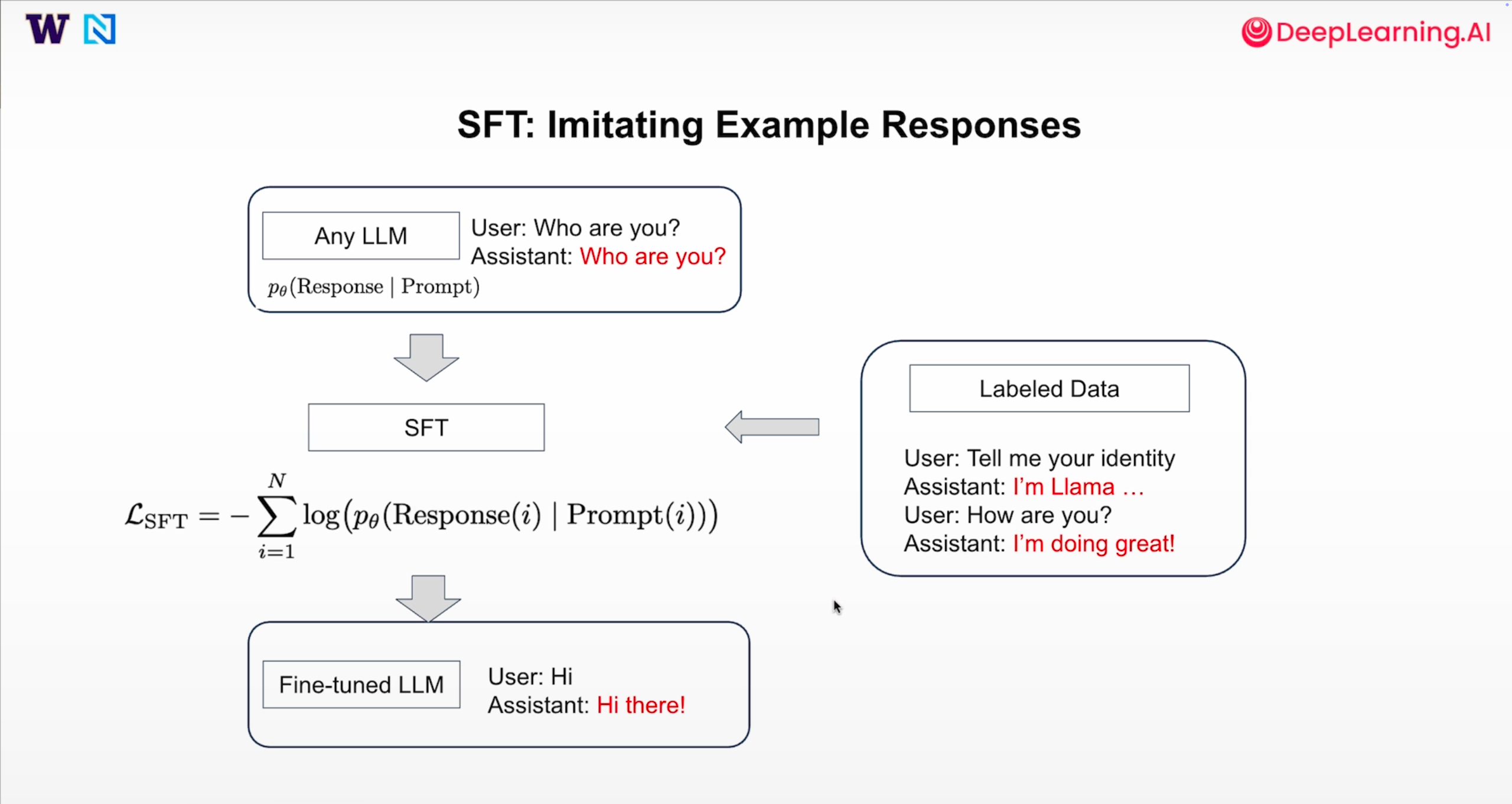
一、什么是 SFT?为什么要做 SFT?
1. SFT 的核心概念
SFT 是给大模型“上课”的过程。简单来说,就是用少量高质量的“提示(Prompt)-响应(Response)”数据集,对预训练好的大模型进行定向优化。
- 与预训练的区别: 预训练数据量巨大(万亿级),目标是学习通用语言规律;SFT 数据量小(几千到上亿),目标是学习特定任务(如数学解题、代码生成)或规范模型行为。
- 核心优势: 训练快、成本低,能快速让模型掌握基础指令能力。
2. SFT 的价值与目的
SFT 是 LLM 后训练的第一步,其目的主要有三:
- 赋予新技能: 让模型从只会聊天,变成能写代码、解数学题。
- 规范模型行为: 确保模型遵循特定格式或语言习惯(如必须用中文回复、必须按步骤解题)。
- 快速启动能力: 它是最简单有效的后训练方法,能让模型迅速从“无知”状态进入“可用”状态。
3. SFT 的损失函数(公式讲解)
SFT 的训练目标是最大化模型生成“标准答案”的概率,这通常通过最小化负对数似然损失(Negative Log-Likelihood Loss)来实现。SFT 的损失函数定义如下: L SFT = − 1 K ∑ t = 1 N I ( t ∈ Response ) ⋅ log p ( y t ∣ x 1 , . . . , x t ; θ ) \mathcal{L}_{\text{SFT}} = -\frac{1}{K} \sum_{t=1}^{N} \mathbb{I}(t \in \text{Response}) \cdot \log p(y_t | x_1, ..., x_t; \theta) LSFT=−K1t=1∑NI(t∈Response)⋅logp(yt∣x1,...,xt;θ)
其中:
- L SFT \mathcal{L}_{\text{SFT}} LSFT是 SFT 的损失函数。
- K K K是响应部分的长度。
- N N N 是整个序列(提示 + 响应)的长度。
- I ( t ∈ Response ) \mathbb{I}(t \in \text{Response}) I(t∈Response) 是指示函数,当 t t t属于响应部分时为 1,否则为 0。
- p ( y t ∣ x 1 , . . . , x t ; θ ) p(y_t | x_1, ..., x_t; \theta) p(yt∣x1,...,xt;θ)是模型在给定前 t t t个 token 的条件下生成第 t t t个 token 的概率。
- θ \theta θ是模型的参数。
公式理解:仅对响应(Response)部分计算损失
这个公式的核心是指示函数 I ( t ∈ Response ) \mathbb{I}(t \in \text{Response}) I(t∈Response)。它确保模型只学习如何生成“助手的标准答案”,而不对用户输入的“提示(Prompt)”部分计算损失。换句话说,模型只对生成的响应部分负责,而忽略输入的提示部分。
示例:理解损失的计算范围
假设训练数据是:
- Prompt: 用户问:2+3=?
- Response: 答案是5
整个序列 Token 如下:
- Prompt: [Token1, Token2, Token3, Token4, Token5]
- Response: [Token6, Token7, Token8]
其中,Token6 到 Token8 是响应部分。
在这种情况下,损失函数将只对 Token6 到 Token8 计算损失,而忽略 Token1 到 Token5。具体计算如下:
L SFT = − 1 3 ( log p ( Token6 ∣ Token1 , Token2 , Token3 , Token4 , Token5 ; θ ) + log p ( Token7 ∣ Token1 , Token2 , Token3 , Token4 , Token5 , Token6 ; θ ) + log p ( Token8 ∣ Token1 , Token2 , Token3 , Token4 , Token5 , Token6 , Token7 ; θ ) ) \mathcal{L}_{\text{SFT}} = -\frac{1}{3} \left( \log p(\text{Token6} | \text{Token1}, \text{Token2}, \text{Token3}, \text{Token4}, \text{Token5}; \theta) + \log p(\text{Token7} | \text{Token1}, \text{Token2}, \text{Token3}, \text{Token4}, \text{Token5}, \text{Token6}; \theta) + \log p(\text{Token8} | \text{Token1}, \text{Token2}, \text{Token3}, \text{Token4}, \text{Token5}, \text{Token6}, \text{Token7}; \theta) \right) LSFT=−31(logp(Token6∣Token1,Token2,Token3,Token4,Token5;θ)+logp(Token7∣Token1,Token2,Token3,Token4,Token5,Token6;θ)+logp(Token8∣Token1,Token2,Token3,Token4,Token5,Token6,Token7;θ))
通过这种机制,SFT 使得模型将全部的学习能力集中在“如何高效且准确地回应指令”上,从而提高了模型的指令遵循能力,同时避免了对输入指令格式的过度拟合。
二、动手实践:基于 Lesson_3.ipynb 的 SFT 全流程
本部分将完全围绕 Lesson_3.ipynb 的代码流程,涵盖环境配置、辅助函数编写、模型加载、数据处理和最终训练。
1. 准备环境与工具配置
SFT 需要 PyTorch、HuggingFace 的 Transformers、Datasets 以及 TRL 库。
# Warning controlimport warnings
warnings.filterwarnings('ignore')# 导入核心库
import torch # 处理张量、GPU计算的核心
import pandas as pd # 展示数据集用的表格工具
from datasets import load_dataset, Dataset # 加载和处理训练数据
from transformers import TrainingArguments, AutoTokenizer, AutoModelForCausalLM # 加载模型、分词器、训练参数配置
from trl import SFTTrainer, DataCollatorForCompletionOnlyLM, SFTConfig # SFT专用训练器和配置# 确保安装了依赖:
!pip install -r requirements.txt2. SFT 核心辅助函数
为了简化 SFT 流程,我们预先编写四个函数,分别负责模型推理、批量测试、模型加载和数据展示。
A. generate_responses:让模型生成回答
def generate_responses(model, tokenizer, user_message, system_message=None,max_new_tokens=100):# 1. 整理对话格式messages = []if system_message:messages.append({"role": "system", "content": system_message})messages.append({"role": "user", "content": user_message})# 2. 用分词器的模板转成模型能读的“prompt”prompt = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True,enable_thinking=False,)# 3. 把 prompt 转成张量,并移到模型设备inputs = tokenizer(prompt, return_tensors="pt").to(model.device)# 4. 模型生成回答with torch.no_grad():outputs = model.generate(**inputs,max_new_tokens=100,do_sample=False,pad_token_id=tokenizer.eos_token_id,eos_token_id=tokenizer.eos_token_id,)# 5. 提取并解码模型的回答input_len = inputs["input_ids"].shape[1]generated_ids = outputs[0][input_len:]response = tokenizer.decode(generated_ids, skip_special_tokens=True).strip()return responseB. test_model_with_questions:批量测试模型
def test_model_with_questions(model, tokenizer, questions,system_message=None, title="Model Output"):print(f"\n=== {title} ===")for i, question in enumerate(questions, 1):response = generate_responses(model, tokenizer, question, system_message)print(f"\nModel Input {i}:\n{question}\nModel Output {i}:\n{response}\n")C. load_model_and_tokenizer:加载模型和分词器
此函数包含了重要的分词器补全逻辑,确保模型能正确处理对话格式。
def load_model_and_tokenizer(model_name, use_gpu = False):# 1. 加载预训练模型和分词器tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForCausalLM.from_pretrained(model_name)# 2. 移到 GPU(如果可用)if use_gpu:model.to("cuda")# 3. 补全“对话模板”(确保模型能理解对话格式)if not tokenizer.chat_template:tokenizer.chat_template = """{% for message in messages %}{% if message['role'] == 'system' %}System: {{ message['content'] }}\n{% elif message['role'] == 'user' %}User: {{ message['content'] }}\n{% elif message['role'] == 'assistant' %}Assistant: {{ message['content'] }} <|endoftext|>{% endif %}{% endfor %}"""# 4. 补全“填充符号”(避免训练时报错)if not tokenizer.pad_token:tokenizer.pad_token = tokenizer.eos_tokenreturn model, tokenizerD. display_dataset:看数据集长啥样
def display_dataset(dataset):rows = []for i in range(3): # 只看前3个样本example = dataset[i]# 提取用户消息和助手消息user_msg = next(m['content'] for m in example['messages'] if m['role'] == 'user')assistant_msg = next(m['content'] for m in example['messages'] if m['role'] == 'assistant')rows.append({'User Prompt': user_msg,'Assistant Response': assistant_msg})# 转成表格展示df = pd.DataFrame(rows)pd.set_option('display.max_colwidth', None)display(df)3. SFT 实操:从小模型开始
为了让没有高性能 GPU 的用户也能跑通,我们选择一个参数量较小的模型 (SmolLM2-135M) 进行 SFT。
步骤 3.1:加载小模型
USE_GPU = False # 如果有GPU,可以改为 True# 测试问题(用于训前和训后效果对比)
questions = ["Give me an 1-sentence introduction of LLM.","Calculate 1+1-1","What's the difference between thread and process?"
]# 加载小模型(注意:路径需要根据实际下载情况调整)
model_name = "./models/HuggingFaceTB/SmolLM2-135M"
model, tokenizer = load_model_and_tokenizer(model_name, USE_GPU)# 训前模型测试(摸底)
test_model_with_questions(model, tokenizer, questions, title="Base Model (Before SFT) Output")核心现象: 训前模型对这些指令的回答往往是不准确或不完整的。
步骤 3.2:加载和展示训练数据
SFT 的训练数据是关键,格式必须是“用户问 + 助手答”的对话形式。
# 加载数据集(使用 DataWhale 教程指定的开源数据集)
train_dataset = load_dataset("banghua/DL-SFT-Dataset")["train"]# 非GPU环境下只选前100条(加速演示)if not USE_GPU:train_dataset = train_dataset.select(range(100))# 展示前3个样本,确认数据格式# display_dataset(train_dataset) # 在 Jupyter 环境中运行此行可以打印表格步骤 3.3:配置 SFT 训练参数
使用 SFTConfig 定义 SFT 的规则,参数设置考虑了 CPU 环境下的运行效率
sft_config = SFTConfig(output_dir="./sft_results", # 结果保存路径learning_rate=8e-5, # 学习率num_train_epochs=1, # 训练轮次per_device_train_batch_size=1, # 单设备批次大小(适合小内存)gradient_accumulation_steps=8, # 梯度累积(用小批次模拟大批次)gradient_checkpointing=False,logging_steps=2, # 日志打印频率
)步骤 3.4:初始化训练器并开始训练
SFTTrainer 是 TRL 库中专门用于 SFT 的工具,它简化了训练流程。
from trl import SFTTrainersft_trainer = SFTTrainer(model=model,args=sft_config,train_dataset=train_dataset,tokenizer=tokenizer,
)# 开始训练
print("\n--- SFT Training Started ---")
sft_trainer.train()
print("--- SFT Training Finished ---")核心逻辑: 训练过程中,模型只学习生成“助手响应部分”,忽略用户提示部分,正是损失函数在代码中的体现。
4. 效果验证:测试 SFT 后的模型
训练结束后,用同样的问题再次测试模型,对比效果。
# 非GPU环境下,把训好的模型移到CPUif not USE_GPU:sft_trainer.model.to("cpu")# 测试自己训的模型(与训前效果进行对比)
test_model_with_questions(sft_trainer.model, tokenizer, questions, title="Small Model (After SFT) Output")# 释放内存del sft_trainer.model, tokenizer核心结论: 尽管使用了小模型和小数据集,但 SFT 后的模型回答会更准确、更贴近指令(例如,计算题能答对、概念能讲清楚),验证了 SFT 的有效性。
三、总结与注意事项
SFT 是 LLM 从“通用语言理解”走向“指令遵循”的关键桥梁。通过 Lesson_3.ipynb 的实践,我们完成了 SFT 的理论认知、环境准备、数据加载、参数配置、模型训练和效果验证的全流程闭环。
核心注意事项:
- 数据质量是生命线: SFT 效果完全取决于训练样本的准确性和格式统一性。
- 避免过拟合: SFT 有可能让模型在没见过的任务上表现变差(灾难性遗忘)。因此,需要控制训练轮次(Epochs)和学习率。
- 硬件要求: 虽然 SFT 比预训练轻量,但训练大模型仍需要 GPU 支持。对于资源有限的用户,选择如本文中的小模型是一个很好的学习起点。
掌握了 SFT,你就能给任何预训练的 LLM 打下“基础技能”,为后续更高级的优化(如 DPO、RLHF)做好准备。
四、 一些错误总结
1. 导入相关工具包遇到错误
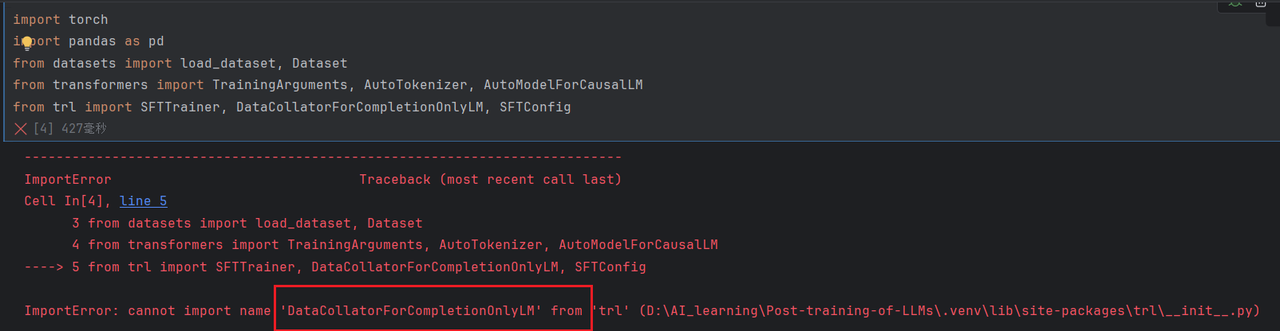
原因:未按照requirements.txt 说明的要求进行安装相关版本的依赖库
2. TypeError: argument of type ‘NoneType’ is not iterable
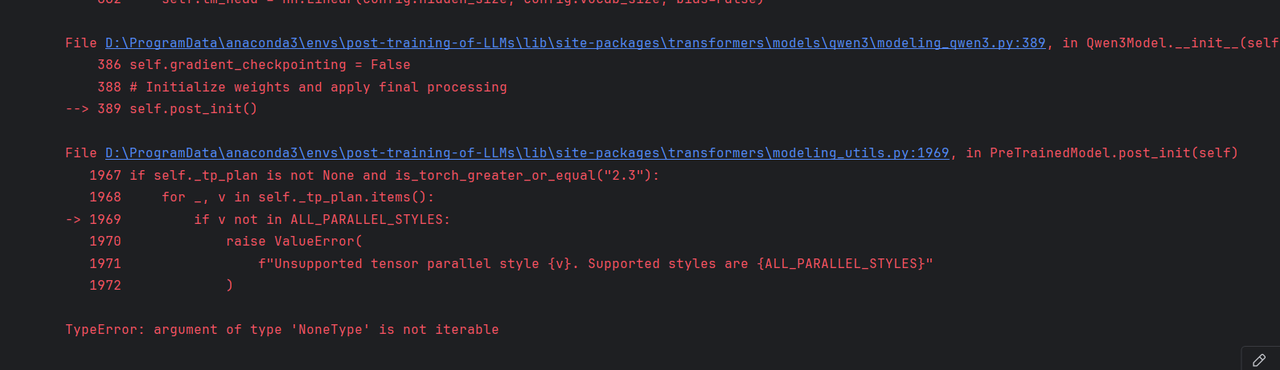
原因:transformers版本不兼容,requirements.txt中的版本为4.52.4,改成4.51.0即可
五、附录
1. 模型下载代码
from huggingface_hub import snapshot_download# 下载 HuggingFaceTB/SmolLM2-135M 模型
model_id_smol = "HuggingFaceTB/SmolLM2-135M"
local_dir_smol = "./models/HuggingFaceTB/SmolLM2-135M"snapshot_download(repo_id=model_id_smol,local_dir=local_dir_smol,revision="main", # 分支/版本号resume_download=True # 支持断点续传
)# 下载 banghua/Qwen3-0.6B-SFT 模型
model_id_qwen = "banghua/Qwen3-0.6B-SFT"
local_dir_qwen = "./models/banghua/Qwen3-0.6B-SFT"snapshot_download(repo_id=model_id_qwen,local_dir=local_dir_qwen,revision="main", # 分支/版本号resume_download=True # 支持断点续传
)# 下载 banghua/Qwen3-0.6B-SFT-Another 模型
model_id_qwen_another = "banghua/Qwen3-0.6B-SFT-Another"
local_dir_qwen_another = "./models/banghua/Qwen3-0.6B-SFT-Another"snapshot_download(repo_id=model_id_qwen_another,local_dir=local_dir_qwen_another,revision="main", # 分支/版本号resume_download=True # 支持断点续传
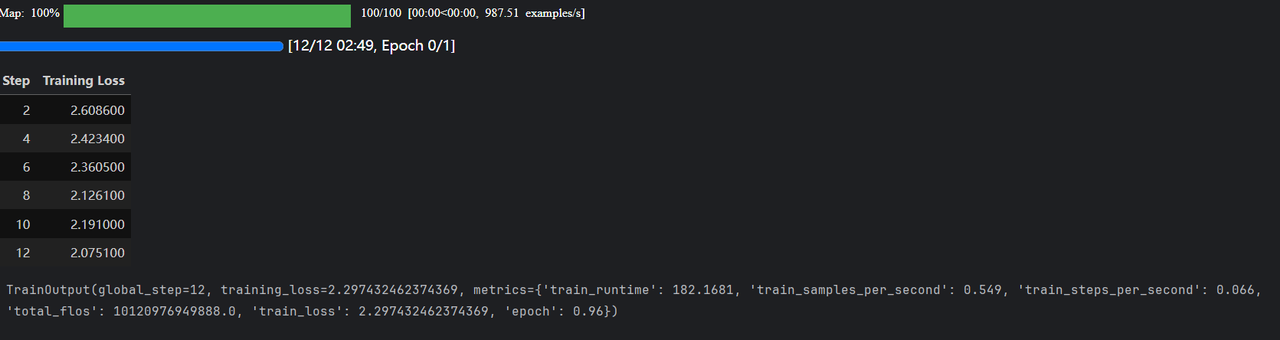
)2. 运行结果
无GPU,使用CPU(本地电脑GPU与tourch 版本冲突 故而未进行GPU训练)

六、参考资料
DataWhale-Post-training-of-LLms
DeepLearning课程