LangExtract:基于LLM的信息抽取框架 学习笔记
Motivation
任务需求:在非标准的文本里面提取特定的字段(比如人物、时间、地点等等),以形成结构化的数据,如保存到 Excel 、数据库。
如果数据量较小,则人工就可以完成此项任务;
但如果数据量很大,则需要借助程序(使用规则匹配)来实现,但由于程序是固定写定的,只遵循设定好的规则,很容易由于不理解自然语言而得到错误答案。
Google 在 7 月 30 日开源的 LangExtract 正是为此而生——它利用 Gemini-family、OpenAI、乃至本地 Ollama 等多种 LLM,实现“按指令抽取+源文对齐+一键可视化”的完整闭环。
作者团队
Google ,发布于2025 年 7 月30日,持续更新ing。
Introduction
LangExtract是一个Python库,利用大型语言模型(LLMs),根据用户定义的指令从非结构化文本文档中提取结构化信息。它能处理临床笔记或报告等材料,识别并整理关键细节,同时确保提取的数据与源文本保持一致。
特点介绍
Precise Source Grounding
将每次的提取,映射到其在源文本中的具体位置,支持视觉高亮显示,便于追溯和验证。
Reliable Structured Outputs
通过 few-shot 和 Gemini 的 Controlled Generation,保证生成的结构化结果,严格遵循预定义的JSON Schema。
Optimized for Long Documents
通过优化的文本分块、并行处理和多轮提取策略,克服了大型文档提取中的“大海捞针”难题,从而提高召回率。
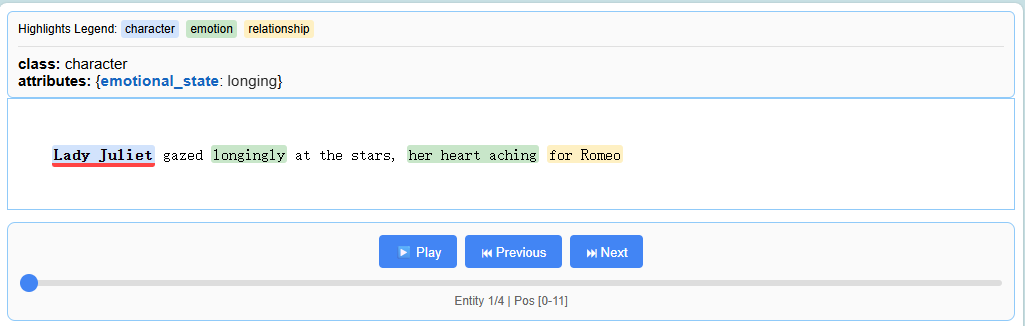
Interactive Visualization
即时生成一个独立的交互式HTML文件,以可视化和审查实体及其原始上下文,方便审核和错误分析。即便是千级实体亦可流畅浏览。
Flexible LLM Support
支持从 Google Gemini 系列等云端 LLM,到通过内置 Ollama 接口访问的本地开源模型。
Adaptable to Any Domai只需少量示例即可为任何领域定义提取任务。LangExtract 会适应需求,无需进行任何模型微调。
Leverages LLM World Knowledge
利用精确的提示词措辞和 Few-shot 示例来影响提取任务如何利用 LLM 知识。 推断信息的准确性及其对任务规范的遵守程度,取决于所选的 LLM、任务的复杂性、提示指令的清晰度以及提示示例的性质。
如何使用
环境配置
pip install langextract # PyPI 安装
# 或者源码开发模式
git clone https://github.com/google/langextract.git
cd langextract && pip install -e ".[dev]"Define Your Extraction Task
首先,创建一个prompt,可以清晰描述想要提取的内容。
然后,提供一个或若干个高质量的例子来引导模型。
# 1. Define the prompt and extraction rules
prompt = textwrap.dedent("""\Extract characters, emotions, and relationships in order of appearance.Use exact text for extractions. Do not paraphrase or overlap entities.Provide meaningful attributes for each entity to add context.""")# 2. Provide a high-quality example to guide the model
examples = [lx.data.ExampleData(text="ROMEO. But soft! What light through yonder window breaks? It is the east, and Juliet is the sun.",extractions=[lx.data.Extraction(extraction_class="character",extraction_text="ROMEO",attributes={"emotional_state": "wonder"}),lx.data.Extraction(extraction_class="emotion",extraction_text="But soft!",attributes={"feeling": "gentle awe"}),lx.data.Extraction(extraction_class="relationship",extraction_text="Juliet is the sun",attributes={"type": "metaphor"}),])
]Run the Extraction
将输入文本和提示材料提供给 lx.extract 函数。
# The input text to be processed
input_text = "Lady Juliet gazed longingly at the stars, her heart aching for Romeo"# Run the extraction
result = lx.extract(text_or_documents=input_text,prompt_description=prompt,examples=examples,model_id="gemini-2.5-flash",
)这里需要将密钥设置为环境变量。
模型选择:推荐默认使用 gemini-2.5-flash,它在速度、成本和质量之间提供了出色的平衡。
Visualize the Results
提取结果可以保存为.jsonl文件,这是一种常用于处理语言模型数据的流行格式。
随后,LangExtract可以从该文件生成交互式HTML可视化界面,以便在上下文中查看实体。
# Save the results to a JSONL file
lx.io.save_annotated_documents([result], output_name="extraction_results.jsonl", output_dir=".")# Generate the visualization from the file
html_content = lx.visualize("extraction_results.jsonl")
with open("visualization.html", "w") as f:if hasattr(html_content, 'data'):f.write(html_content.data) # For Jupyter/Colabelse:f.write(html_content)这将创建一个动态且交互式的HTML文件: