强化学习入门-3(AC)
强化学习项目-3-CartPole-v1(AC)
环境
本环境是OpenAI Gym提供的一个经典控制环境。
官网链接:https://gymnasium.farama.org/environments/classic_control/cart_pole/
观测空间(状态S)
状态共包含444个参数:
- 车位置(Cart Position)
- 车速(Cart Velocity)
- 杆子的角度(Pole Angle)
- 角速度(Pole Angular Velocity)
动作空间(动作A)
- 0: 推动车向左移动
- 1: 推动车向右移动
奖励
每坚持一步,环境将会给出111点奖励,最大可以获得500500500奖励,同时只要达到200200200就视为达到通过门槛。
引入环境
下载包
pip install gymnasium
导入
import gymnasium as gym
env = gym.make("CartPole-v1", render_mode="human")
# 获取状态维度和动作维度
state_dim = env.observation_space.shape[0] if len(env.observation_space.shape) == 1 else env.observation_space.n
action_dim = env.action_space.n
AC算法(actor-critic)
区别于传统的DQNDQNDQN算法仅训练一个网络用于预测Q(s,a)Q(s,a)Q(s,a),ACACAC算法则分成两个网络:
- ActorActorActor : 针对状态sss,输出动作的概率分布
- CriticCriticCritic : 价值估计器,这里采用V(s)V(s)V(s),即从状态sss出发的期望奖励
Tips: V(s)=∑ai∈actionsV(si′)×ci,ci表示选择动作aiV(s) = \sum\limits_{a_i \in actions} V(s_{i}^{\prime}) \times c_{i}, c_{i}\text{表示选择动作} a_{i}V(s)=ai∈actions∑V(si′)×ci,ci表示选择动作ai的概率,si′s_{i}^{\prime}si′表示在状态sss选择动作aia_{i}ai到达的新状态
CriticCriticCritic通过预测的TDTDTD残差引导ActorActorActor更新,而CriticCriticCritic则通过TDTDTD目标更新
同时,Actor−CriticActor-CriticActor−Critic的训练不能像DQNDQNDQN算法一样使用历史经验用于训练,每轮训练的数据仅使用本次模型与环境交互的全部数据
Actor网络
这里采用两层隐藏层,同时输出层采用Softmax激活函数,以预测状态sss下动作aaa的概率分布
class Actor(nn.Module):def __init__(self, hidden_dim = 128):super(Actor, self).__init__()self.net = nn.Sequential(nn.Linear(state_dim, hidden_dim), nn.ReLU(),nn.Linear(hidden_dim, hidden_dim), nn.ReLU(),nn.Linear(hidden_dim, action_dim), nn.Softmax(dim=-1))def forward(self, x):return self.net(x)
Critic网络
这里采用两层隐藏层,输出层无激活函数且仅包含一个神经元,用于预测V(s)V(s)V(s)
class Critic(nn.Module):def __init__(self, hidden_dim = 128):super(Critic, self).__init__()self.net = nn.Sequential(nn.Linear(state_dim, hidden_dim),nn.ReLU(),nn.Linear(hidden_dim, hidden_dim),nn.ReLU(),nn.Linear(hidden_dim, 1))def forward(self, x):return self.net(x)
Actor-Critic
初始化
ACACAC算法的初始化较为简单,仅需初始化ACACAC两个神经网络,对应的优化器以及折扣因子即可
class ActorCritic():def __init__(self, gamma):self.actor = Actor().to(device)self.critic = Critic().to(device)self.optimizer_a = torch.optim.Adam(self.actor.parameters(), lr=actor_lr)self.optimizer_c = torch.optim.Adam(self.critic.parameters(), lr=critic_lr)self.gamma = gamma
动作选择
动作选择通过ActorActorActor网络传入状态sss后预测得到概率分布后采样得到
def act(self, states):states = torch.from_numpy(states).float().to(device)with torch.no_grad():probs = self.actor(states)disk = torch.distributions.Categorical(probs)return disk.sample().item()
模型训练
先通过CriticCriticCritic网络预测的结果计算得到TDTDTD目标以及TDTDTD残差,然后分别计算得到两个网络的损失函数用于更新模型。
Tips:
- 这里为了计算更加稳定,对选择当前动作的概率取对数,同时为了避免当一个动作选择概率为000时,此时取对数会出现无穷小NanNanNan的情况,计算时将概率加上10−910^{-9}10−9
- 对于表现好的动作(即V(s′)V(s^{\prime})V(s′)更大的动作),选择该动作的概率更高才能使得模型的表现更佳,因此ActorActorActor网络采取的是梯度上升
def train(self, states, actions, rewards, next_states, dones):td_target = rewards + self.gamma * self.critic(next_states) * (1 - dones)td_delta = td_target - self.critic(states)log_probs = torch.log(self.actor(states).gather(1, actions) + 1e-9)actor_loss = torch.mean(-log_probs * td_delta.detach())critic_loss = nn.functional.mse_loss(self.critic(states), td_target.detach())self.optimizer_c.zero_grad()self.optimizer_a.zero_grad()critic_loss.backward()actor_loss.backward()self.optimizer_c.step()self.optimizer_a.step()
环境交互
这里与DQNDQNDQN不同的是,每轮都需要重新收集训练数据,且在本轮交互结束后才对模型进行训练。
Hint: 注意训练前要将数据转换为Tensor
torch.manual_seed(0)
actor_lr = 1e-4
critic_lr = 1e-3
gamma = 0.99
scores = []
episodes = 2000
model = ActorCritic(gamma)
from tqdm import tqdm
pbar = tqdm(range(episodes), desc="Training")
for episode in pbar:score = 0state, _ = env.reset()done = Falsestates, actions, rewards, dones, next_states = [], [], [], [], []while not done:action = model.act(state)next_state, reward, done, truncated,_ = env.step(action)done = done or truncatedscore += rewardstates.append(state)actions.append(action)rewards.append(reward)next_states.append(next_state)dones.append(done)state = next_statestates = torch.FloatTensor(np.array(states)).to(device)actions = torch.LongTensor(np.array(actions)).view(-1, 1).to(device)rewards = torch.FloatTensor(np.array(rewards)).view(-1, 1).to(device)next_states = torch.FloatTensor(np.array(next_states)).to(device)dones = torch.FloatTensor(np.array(dones)).view(-1, 1).to(device)model.train(states, actions, rewards, next_states, dones)scores.append(score)pbar.set_postfix(ep=episode, score=score, avg100=np.mean(scores[-100:]))
if np.mean(scores[-100:]) > 200:torch.save(model.actor.state_dict(),'../../model/cartpole-a.pt')torch.save(model.critic.state_dict(),'../../model/cartpole-c.pt')
print(np.mean(scores[-100:]))
plt.plot(scores)
plt.show()
完整程序
import gymnasium as gym, torch, torch.nn as nn, numpy as np, matplotlib.pyplot as plt
from collections import dequeenv = gym.make("CartPole-v1", render_mode="human")
state_dim = env.observation_space.shape[0] if len(env.observation_space.shape) == 1 else env.observation_space.n
action_dim = env.action_space.n
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
class Actor(nn.Module):def __init__(self, hidden_dim = 128):super(Actor, self).__init__()self.net = nn.Sequential(nn.Linear(state_dim, hidden_dim), nn.ReLU(),nn.Linear(hidden_dim, hidden_dim), nn.ReLU(),nn.Linear(hidden_dim, action_dim), nn.Softmax(dim=-1))def forward(self, x):return self.net(x)class Critic(nn.Module):def __init__(self, hidden_dim = 128):super(Critic, self).__init__()self.net = nn.Sequential(nn.Linear(state_dim, hidden_dim),nn.ReLU(),nn.Linear(hidden_dim, hidden_dim),nn.ReLU(),nn.Linear(hidden_dim, 1))def forward(self, x):return self.net(x)class ActorCritic():def __init__(self, gamma):self.actor = Actor().to(device)self.critic = Critic().to(device)self.optimizer_a = torch.optim.Adam(self.actor.parameters(), lr=actor_lr)self.optimizer_c = torch.optim.Adam(self.critic.parameters(), lr=critic_lr)self.gamma = gammadef act(self, states):states = torch.from_numpy(states).float().to(device)with torch.no_grad():probs = self.actor(states)disk = torch.distributions.Categorical(probs)return disk.sample().item()def train(self, states, actions, rewards, next_states, dones):td_target = rewards + self.gamma * self.critic(next_states) * (1 - dones)td_delta = td_target - self.critic(states)log_probs = torch.log(self.actor(states).gather(1, actions) + 1e-9)actor_loss = torch.mean(-log_probs * td_delta.detach())critic_loss = nn.functional.mse_loss(self.critic(states), td_target.detach())self.optimizer_c.zero_grad()self.optimizer_a.zero_grad()critic_loss.backward()actor_loss.backward()self.optimizer_c.step()self.optimizer_a.step()torch.manual_seed(0)
actor_lr = 1e-4
critic_lr = 1e-3
gamma = 0.99
scores = []
episodes = 1000
model = ActorCritic(gamma)
from tqdm import tqdm
pbar = tqdm(range(episodes), desc="Training")
for episode in pbar:score = 0state, _ = env.reset()done = Falsestates, actions, rewards, dones, next_states = [], [], [], [], []while not done:action = model.act(state)next_state, reward, done, truncated,_ = env.step(action)done = done or truncatedscore += rewardstates.append(state)actions.append(action)rewards.append(reward)next_states.append(next_state)dones.append(done)state = next_statestates = torch.FloatTensor(np.array(states)).to(device)actions = torch.LongTensor(np.array(actions)).view(-1, 1).to(device)rewards = torch.FloatTensor(np.array(rewards)).view(-1, 1).to(device)next_states = torch.FloatTensor(np.array(next_states)).to(device)dones = torch.FloatTensor(np.array(dones)).view(-1, 1).to(device)model.train(states, actions, rewards, next_states, dones)scores.append(score)pbar.set_postfix(ep=episode, score=score, avg100=np.mean(scores[-100:]))
torch.save(model.actor.state_dict(),'../../model/cartpole-a.pt')
torch.save(model.critic.state_dict(),'../../model/cartpole-c.pt')
print(np.mean(scores[-100:]))
plt.plot(scores)
plt.show()
模型测试
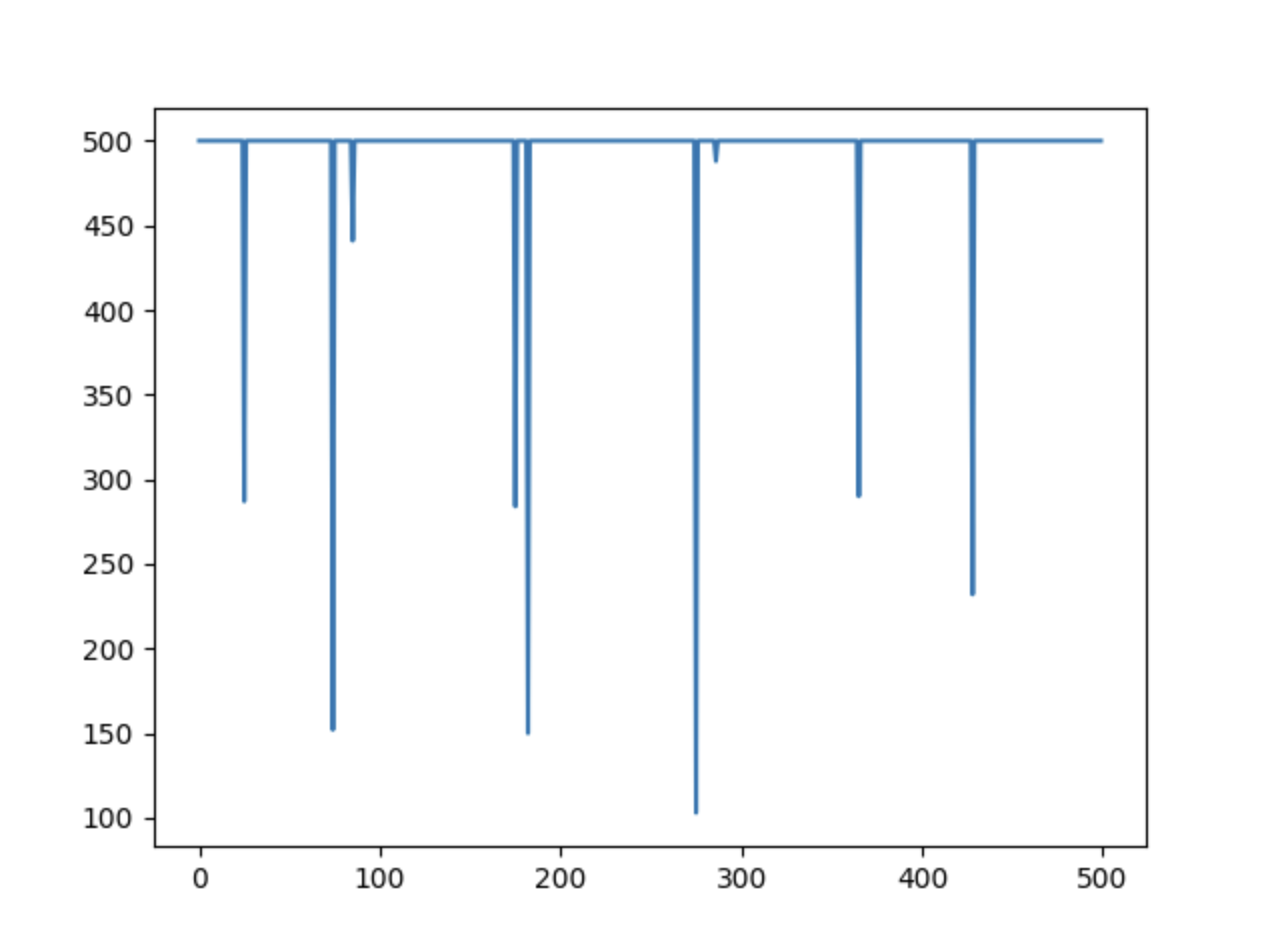
这里选择500500500轮测试,结果如下:
模型绝大部分时间可以保证到游戏结束才停止,即少部分时间才会出现波动,而采取DQNDQNDQN时可能仅能达到平均300300300到成绩