mysql基础【多表查询经典案例】
📌 数据表结构说明
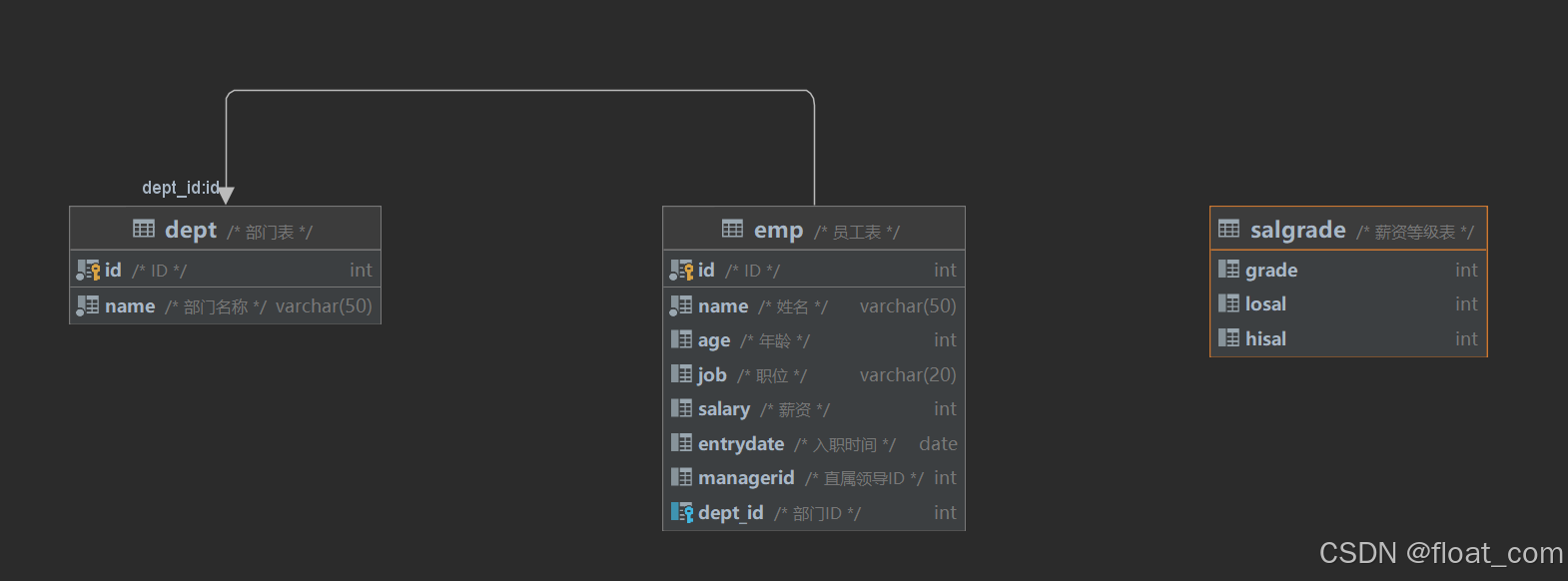
为便于理解,先明确涉及的三张表结构:
-
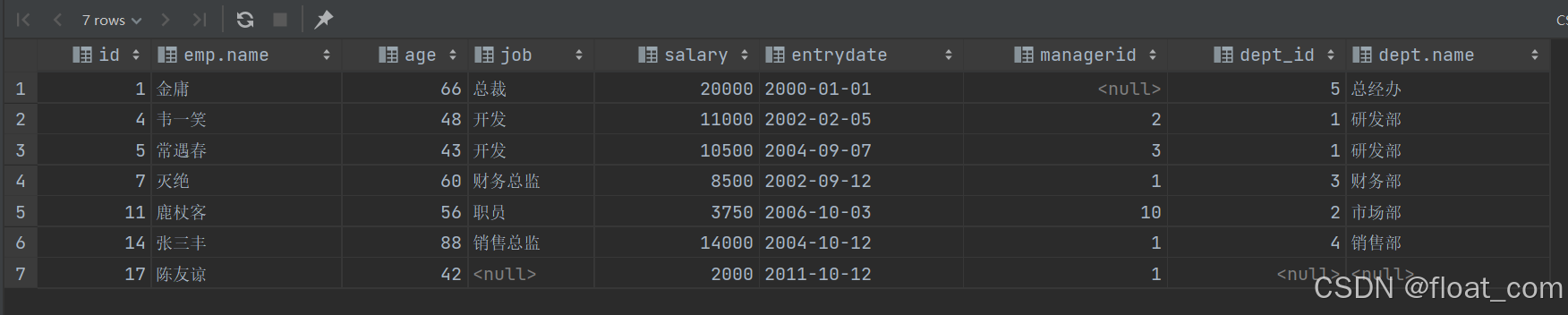
emp(员工表)
字段:id,name,age,job,salary,dept_id,entrydate,managerid
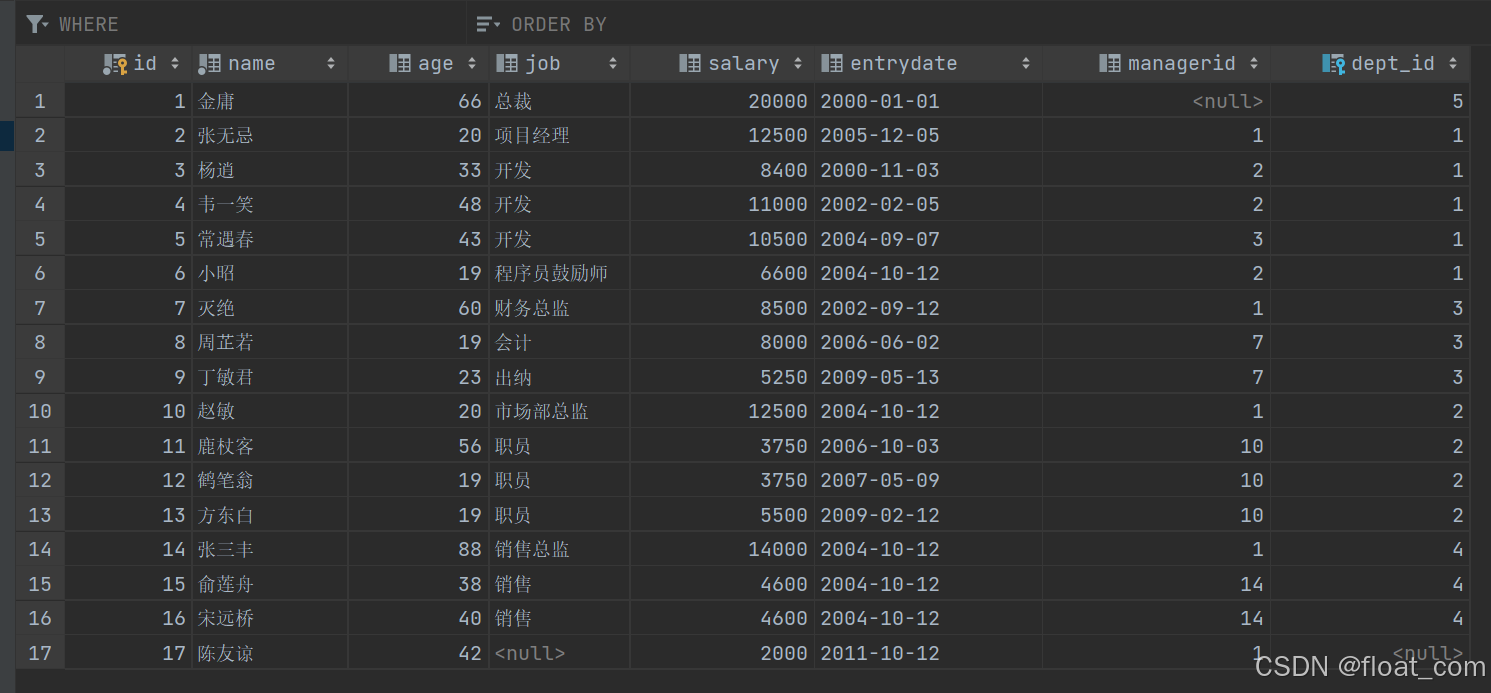
-
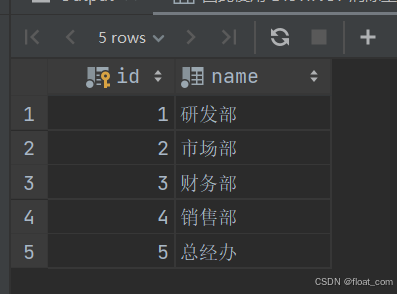
dept(部门表)
字段:id,name
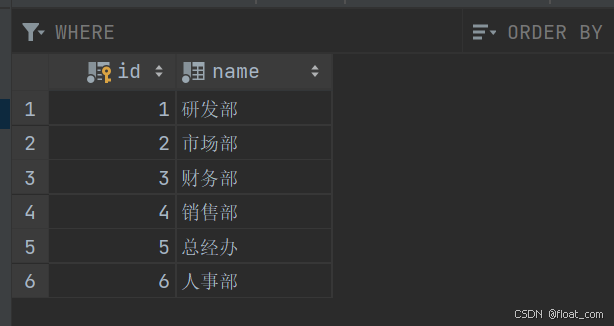
-
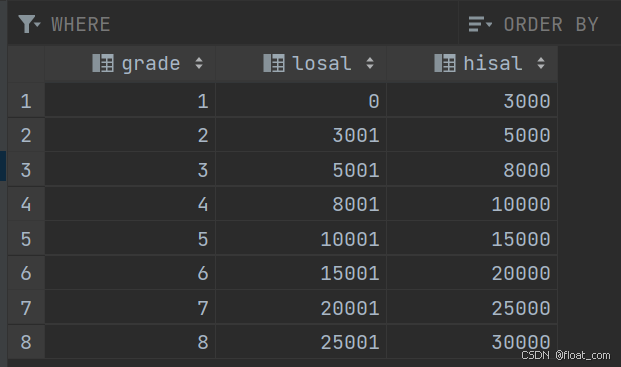
salgrade(薪资等级表)
字段:grade,losal(最低工资),hisal(最高工资)
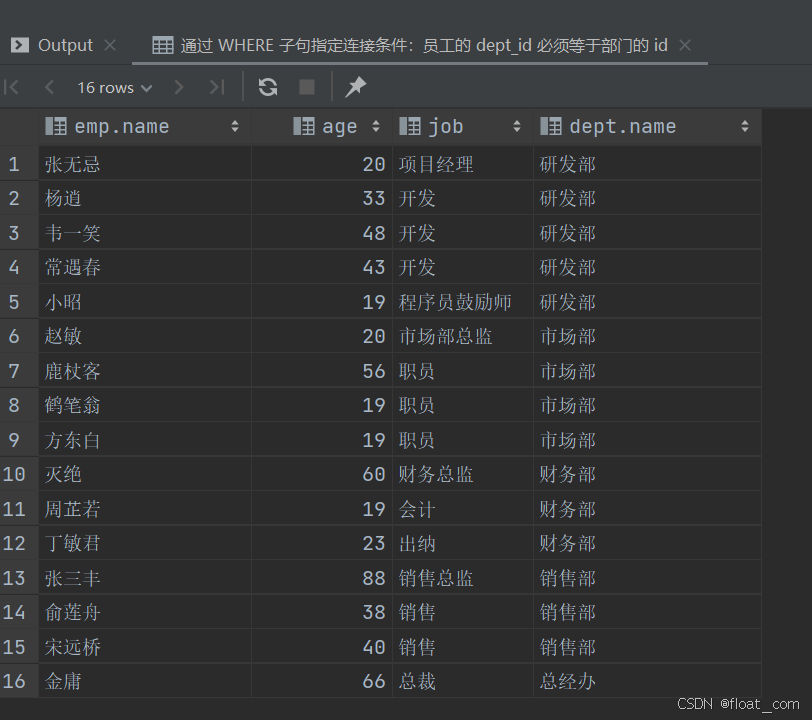
案例 1:查询所有已分配部门的员工基本信息及其所属部门名称
-- 使用隐式内连接(逗号连接)方式关联 emp 和 dept 表
-- 通过 WHERE 子句指定连接条件:员工的 dept_id 必须等于部门的 id
SELECTemp.name, -- 员工姓名emp.age, -- 员工年龄emp.job, -- 员工职位dept.name -- 所属部门名称
FROM emp, dept -- 隐式连接两张表(笛卡尔积)
WHERE emp.dept_id = dept.id; -- 过滤出有效关联记录(等价于 INNER JOIN)
⚠️ 说明:
- 这是 SQL-89 标准的写法,语法简单但可读性差;
- 现代开发推荐使用显式 JOIN 以提高代码可维护性。
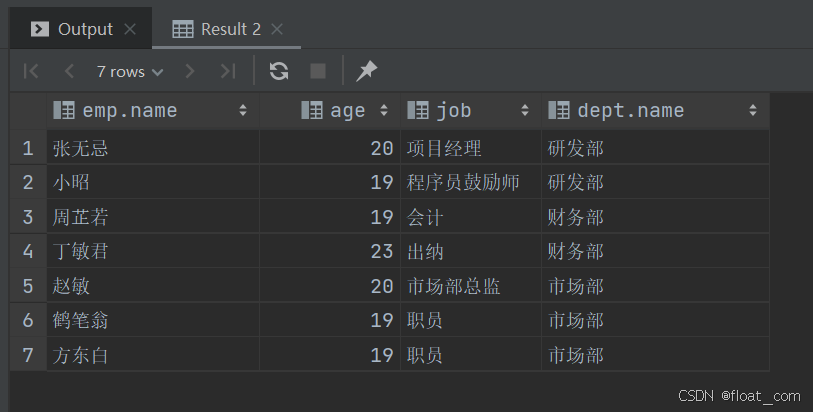
案例 2:查询年龄小于30岁且已分配部门的员工详细信息
-- 使用显式 INNER JOIN 明确表达连接逻辑,提高可读性和可维护性
-- 先连接员工与部门表,再通过 WHERE 过滤年龄条件
SELECTemp.name, -- 员工姓名emp.age, -- 员工年龄emp.job, -- 员工职位dept.name -- 所属部门名称
FROM emp
INNER JOIN dept ON emp.dept_id = dept.id -- 显式内连接:仅保留有部门的员工
WHERE emp.age < 30; -- 业务条件:年龄小于30岁
💡 建议:
- 使用显式 JOIN 提高代码清晰度;
- 将过滤条件放在 WHERE 中,避免混淆。
案例 3:查询至少有一名员工的部门信息(去重)
-- 使用 INNER JOIN 确保只返回存在员工关联的部门
-- 由于一个部门可能对应多名员工,直接查询会产生重复行
-- 因此使用 DISTINCT 消除重复,确保每个部门仅出现一次
SELECT DISTINCTdept.id, -- 部门IDdept.name -- 部门名称
FROM dept
INNER JOIN emp ON emp.dept_id = dept.id; -- 仅保留有员工的部门
🔍 关键点:
- 使用
DISTINCT或GROUP BY来消除重复记录;INNER JOIN只会返回有匹配记录的行。
案例 4:查询年龄大于40岁的所有员工信息,包括未分配部门者(部门显示为 NULL)
-- 使用 LEFT JOIN 以 emp 为主表,确保即使 dept_id 为 NULL 也能保留员工记录
-- ⚠️ 注意:年龄过滤条件必须放在 WHERE 中,而非 ON 中
-- 若放在 ON 中,会导致 ≤40 岁员工也被保留(仅部门为 NULL),不符合需求
SELECTemp.*, -- 员工全部字段dept.name -- 所属部门名称(未分配则为 NULL)
FROM emp
LEFT JOIN dept ON emp.dept_id = dept.id -- 保留所有员工,尝试关联部门
WHERE emp.age > 40; -- 业务过滤:仅保留年龄 > 40 的员工
🚨 重点解析:
LEFT JOIN的核心是保留左表所有记录;- 若将
emp.age > 40放在ON中,只会过滤右表匹配逻辑,左表仍会返回所有员工(包括 ≤40 岁的);- 正确做法:先完成连接,再用
WHERE筛选结果。
案例 5:为每位员工匹配对应的薪资等级(基于 salary 落在 [losal, hisal] 区间)
-- 使用 LEFT JOIN 确保即使某员工薪资不在任何等级范围内,也能显示其信息
-- 此时 salgrade 相关字段为 NULL,避免因无匹配而丢失员工数据
SELECTemp.*, -- 员工全部信息salgrade.losal, -- 该等级最低工资salgrade.hisal, -- 该等级最高工资salgrade.grade -- 对应薪资等级编号
FROM emp
LEFT JOIN salgradeON emp.salary BETWEEN salgrade.losal AND salgrade.hisal; -- 区间匹配薪资等级
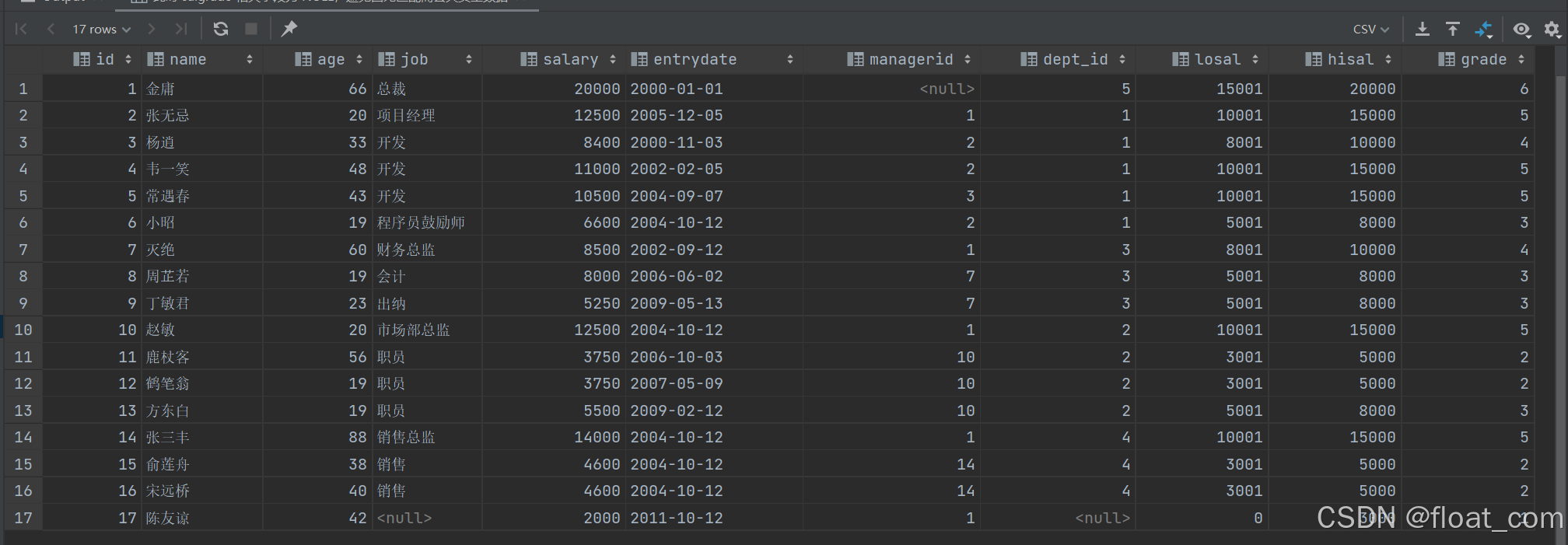
💡 技巧:
- 使用
BETWEEN实现区间匹配;LEFT JOIN确保不丢失任何员工记录。
案例 6:查询“研发部”员工的完整信息及其对应的薪资等级
-- 需要同时关联三张表:emp(员工)、dept(部门)、salgrade(薪资等级)
-- 先 LEFT JOIN salgrade:保留所有员工的薪资等级(即使无匹配)
-- 再 INNER JOIN dept:因需限定“研发部”,未分配部门者可排除
-- 最后通过 WHERE 精确筛选部门名称
SELECTemp.*, -- 员工全部字段salgrade.losal, -- 薪资等级下限salgrade.hisal, -- 薪资等级上限salgrade.grade -- 薪资等级编号
FROM emp
LEFT JOIN salgrade ON emp.salary BETWEEN salgrade.losal AND salgrade.hisal
INNER JOIN dept ON emp.dept_id = dept.id
WHERE dept.name = '研发部'; -- 精确匹配部门名称

🔍 执行顺序:
- 先关联
emp和salgrade;- 再关联
dept并筛选“研发部”。
案例 7:计算“研发部”员工的平均薪资
-- 通过 INNER JOIN 关联部门表,限定员工范围为“研发部”
-- 使用聚合函数 AVG() 计算平均值,并通过 AS 起别名提升可读性
SELECTAVG(emp.salary) AS '研发部平均薪资' -- 聚合结果并命名
FROM emp
INNER JOIN dept ON emp.dept_id = dept.id
WHERE dept.name = '研发部'; -- 限定部门范围
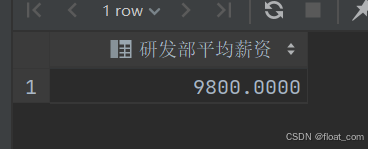
💡 核心:
- 使用
AVG()聚合函数计算平均值;AS给结果列起别名,提升可读性。
案例 8:查询薪资高于员工“灭绝”的所有员工信息
-- 使用标量子查询:子查询必须返回单个值(一行一列)
-- 假设“灭绝”是唯一存在的员工名,否则子查询将报错(返回多行)
-- 主查询将每位员工的 salary 与“灭绝”的 salary 进行比较
SELECTemp.* -- 所有字段
FROM emp
WHERE emp.salary > (SELECT emp.salaryFROM empWHERE emp.name = '灭绝' -- 获取“灭绝”的工资(标量值)
);
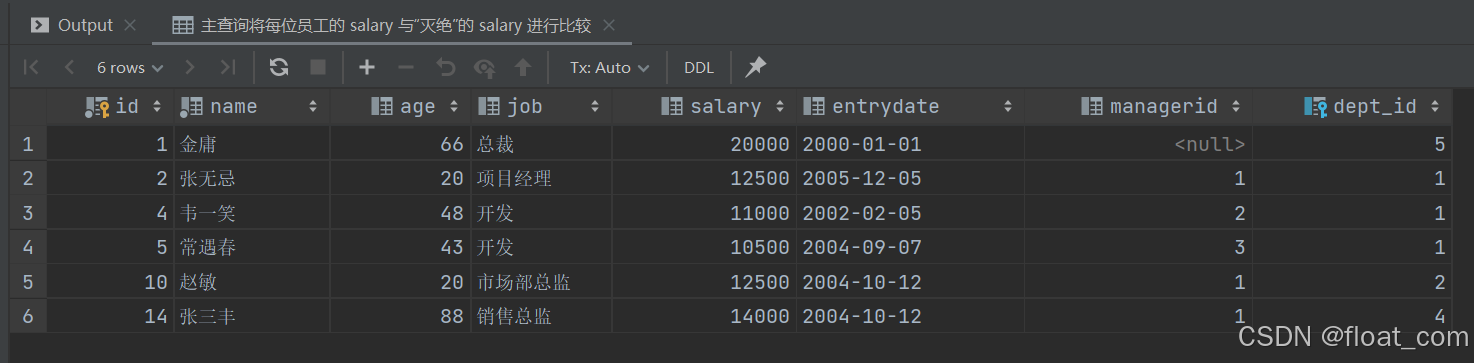
💡 标量子查询特点:
- 返回单个值;
- 用于动态生成比较基准。
案例 9:查询薪资高于公司整体平均工资的员工
-- 子查询计算全公司员工的平均薪资(AVG(salary))
-- 主查询将每位员工 salary 与该平均值比较
-- 常用于“高于平均水平”的筛选场景(如高绩效员工识别)
SELECTemp.* -- 员工全部信息
FROM emp
WHERE emp.salary > (SELECT AVG(emp.salary) -- 标量子查询:公司平均工资FROM emp
);
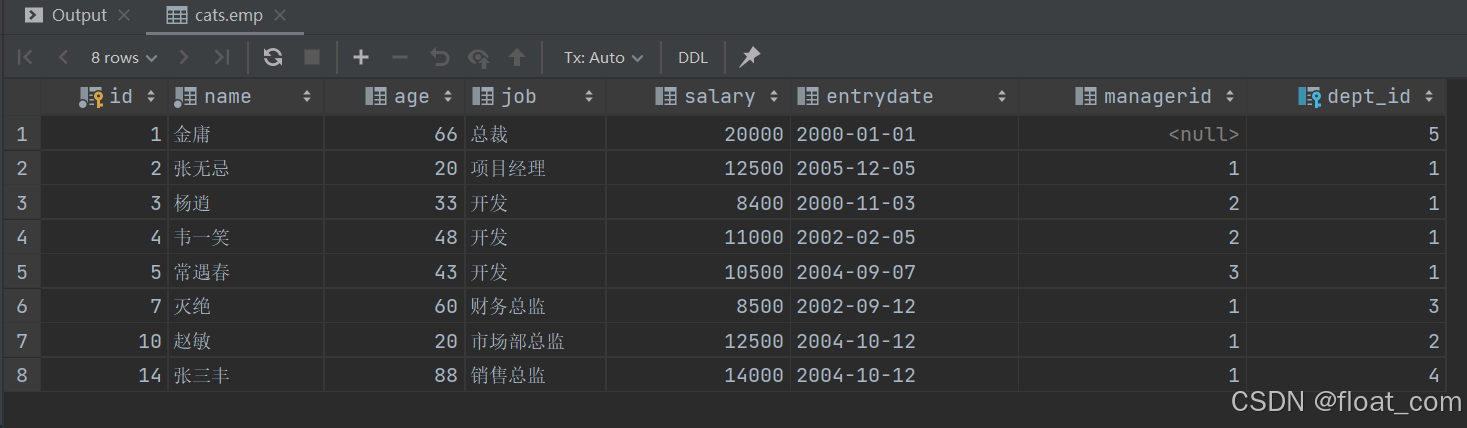
💡 应用场景:
- 适用于需要与总体水平对比的场景;
- 标量子查询简洁高效。
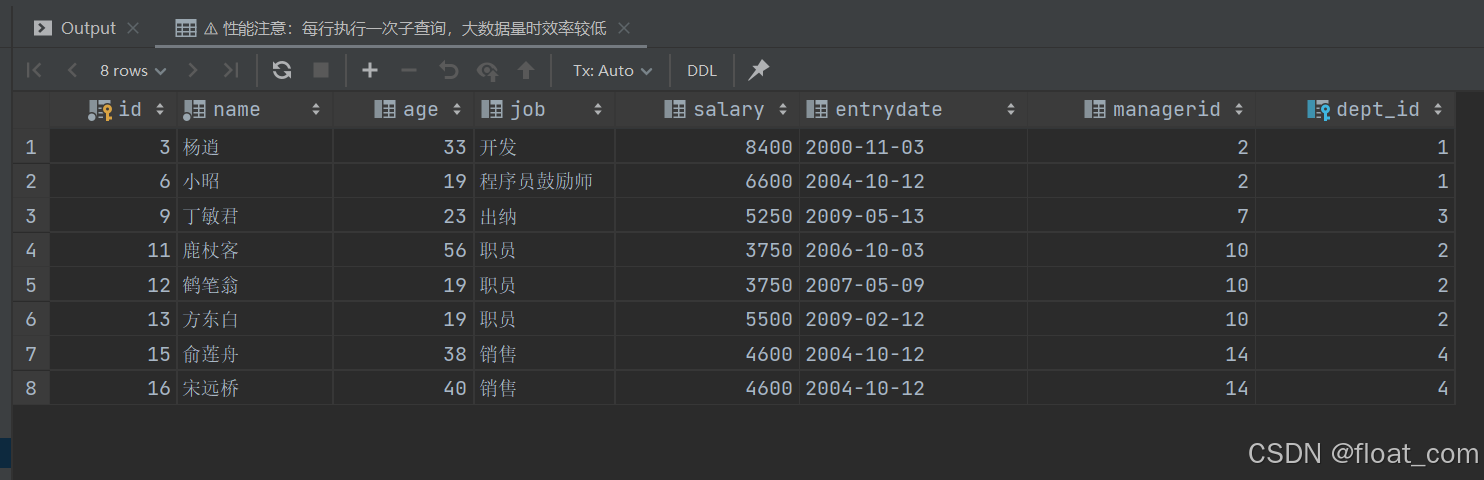
案例 10:查询薪资低于其所在部门平均工资的员工
法一:相关子查询(性能较低)
-- 使用相关子查询:子查询依赖外层查询的 dept_id
-- 对每位员工 e1,动态计算其所在部门的平均工资
-- 若 e1.salary 小于该平均值,则保留该记录
-- ⚠️ 性能注意:每行执行一次子查询,大数据量时效率较低
SELECTe1.* -- 外层员工记录(别名 e1)
FROM emp AS e1
WHERE e1.salary < (SELECT AVG(e2.salary) -- 计算同部门平均工资FROM emp AS e2WHERE e2.dept_id = e1.dept_id -- 关联条件:与外层员工同部门
);
-- 等价伪代码逻辑:(实际上就是O(n*n)的for循环)
-- for 每个员工 e1 in emp:
-- avg_sal = SELECT AVG(salary) FROM emp WHERE dept_id = e1.dept_id
-- if e1.salary < avg_sal:
-- output e1
法二:分组聚合 + 内连接(推荐)
-- 等价高性能写法:先计算各部门平均工资,再与员工表关联筛选
-- 子查询按 dept_id 分组,一次性计算所有部门的平均薪资
-- 将结果作为临时表 dept_avg 与 emp 表连接
-- 最后筛选 salary < 部门平均工资 的员工
-- ✅ 优点:子查询仅执行一次,符合集合操作思想,适合大数据场景
SELECTemp.*
FROM emp
INNER JOIN (SELECTemp.dept_id,AVG(emp.salary) AS avg_salary -- 每个部门的平均工资FROM empGROUP BY emp.dept_id -- 按部门分组聚合
) AS dept_avg ON emp.dept_id = dept_avg.dept_id
WHERE emp.salary < dept_avg.avg_salary; -- 筛选低于部门平均的员工
💡 优化建议:
- 尽量避免使用相关子查询,改用聚合 + JOIN 方案;
- 提升查询性能,尤其在大数据集上表现更佳。
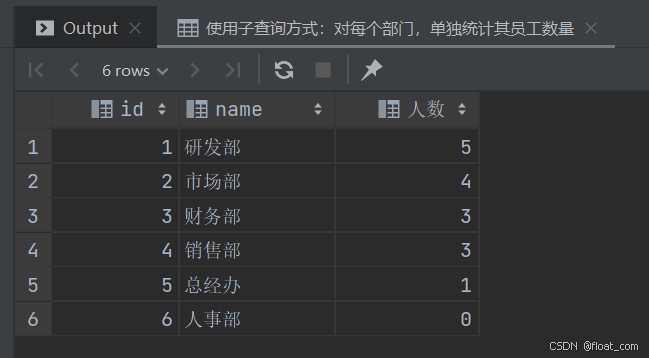
案例 11:查询所有部门信息,并统计每个部门的员工人数
法一:子查询方式
-- 使用子查询方式:对每个部门,单独统计其员工数量
SELECTdept.id, -- 部门IDdept.name, -- 部门名称(SELECT COUNT(*) -- 子查询:统计员工表中属于当前部门的员工数量FROM emp -- 从员工表 emp 中查询WHERE emp.dept_id = dept.id -- 条件:员工的 dept_id 等于当前部门的 id) AS '人数' -- 将统计结果命名为“人数”
FROM dept; -- 从部门表 dept 中查询所有部门
法二:LEFT JOIN + GROUP BY 方式(推荐)
-- 使用 LEFT JOIN + GROUP BY 方式,确保即使没有员工的部门也会显示(人数为0)
SELECTdept.id, -- 部门IDdept.name, -- 部门名称COUNT(emp.id) AS '人数' -- 统计每个部门关联的员工数量(使用 COUNT(emp.id) 而非 COUNT(*))
FROMdept
LEFT JOIN emp ON dept.id = emp.dept_id -- 左连接:保留所有部门,即使没有员工
GROUP BYdept.id, dept.name; -- 按部门分组,确保每个部门一行
💡 最佳实践:
- 使用
LEFT JOIN保留所有部门,即使无员工;COUNT(emp.id)统计非空记录数,避免误计入 NULL 值。
📌 数据表结构说明
-
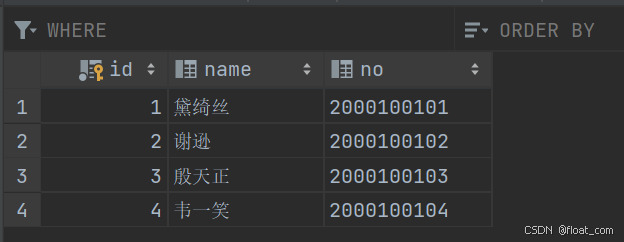
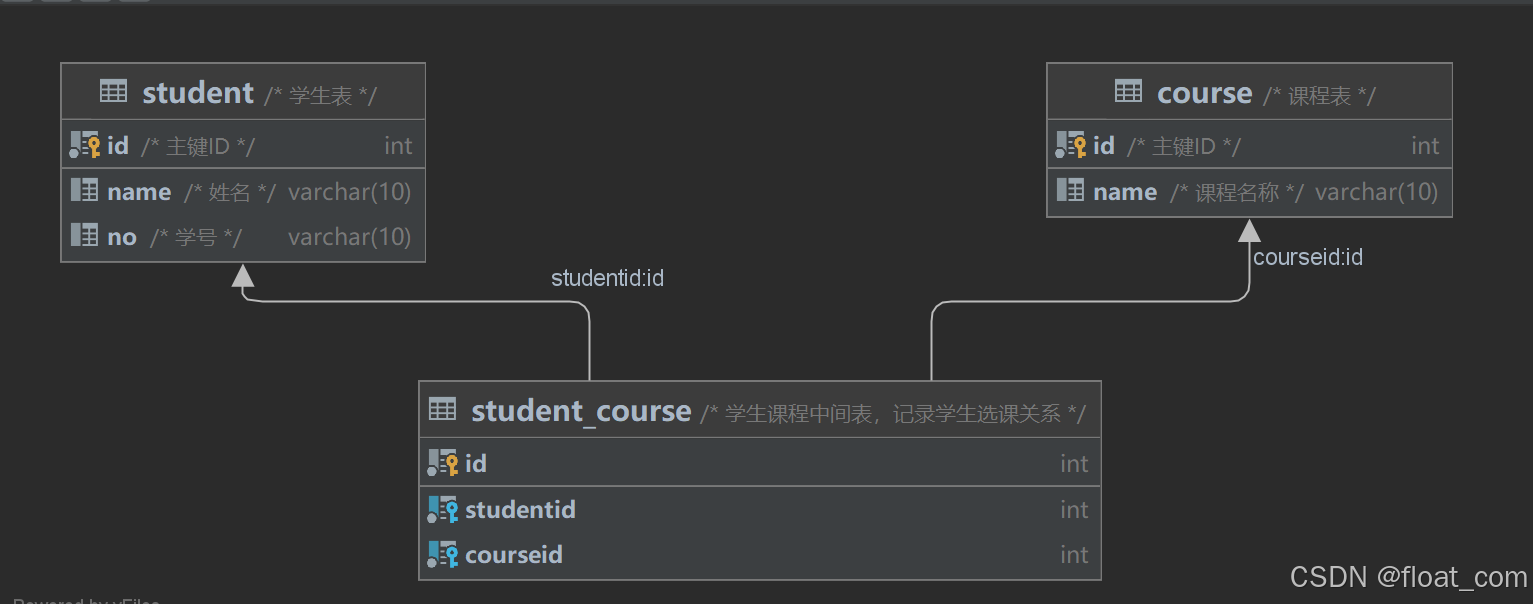
student(学生表)
字段:id,name,no
-
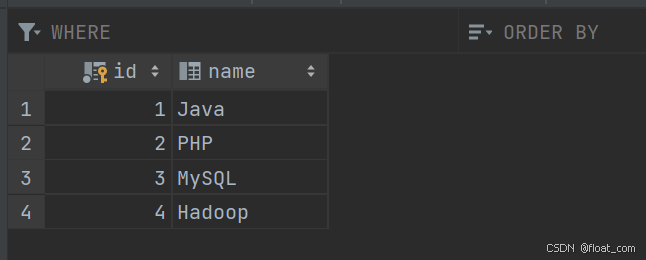
course(课程表)
字段:id,name
-
student_course(选课中间表,实现多对多关系)
字段:studentid,courseid
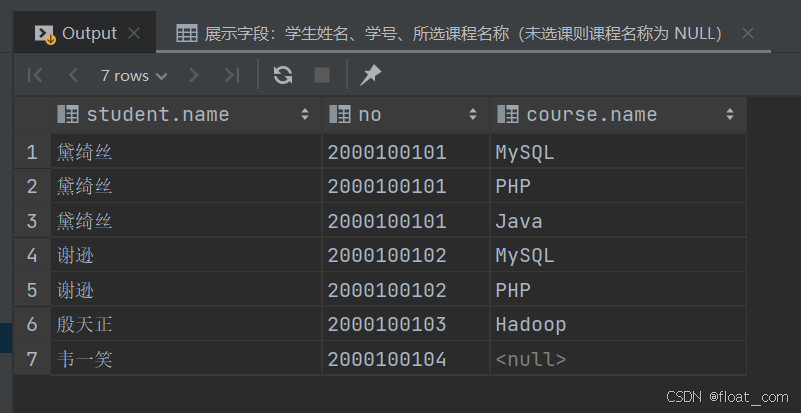
案例 12:查询所有学生的选课情况,展示学生姓名、学号及所选课程名称
-- 12.查询所有学生的选课情况,展示出学生名称,学号,课程名称
-- 外连接
-- 展示字段:学生姓名、学号、所选课程名称(未选课则课程名称为 NULL)
SELECTstudent.name, -- 学生姓名student.no, -- 学生学号course.name -- 所选课程名称(若学生未选课,则此字段为 NULL)
FROM student
-- 第一步:将学生表与选课中间表关联,通过学生ID匹配选课记录
LEFT JOIN student_course ON student.id = student_course.studentid
-- 第二步:将选课记录与课程表关联,通过课程ID获取课程名称
LEFT JOIN course ON student_course.courseid = course.id;
关键设计:
- 使用 两次 LEFT JOIN:
student→student_course:确保即使学生没有选课记录,也能保留其基本信息;student_course→course:通过选课记录中的courseid获取课程名称;- 若某学生无任何选课记录,则
student_course和course表的字段均为NULL,但学生信息仍会显示。