K8s 核心架构是什么?组件怎么协同工作的?
在云原生技术浪潮中,Kubernetes(简称 K8s)已成为容器编排与集群管理的事实标准,如同 “云时代的操作系统”,支撑着大规模分布式应用的部署与运维。要真正掌握 K8s 的强大能力,必须深入理解其核心架构 —— 这套由 “控制中枢” 与 “工作单元” 组成的精密系统,是如何让成百上千的容器在服务器集群中实现 “自动化调度、故障自愈、弹性伸缩” 的。
一、架构概览:控制平面与工作节点的分层协同
Kubernetes 集群采用 “控制平面(Master)+ 工作节点(Node)” 的分层架构(如图 1 所示),其中:
-
控制平面(Master):作为 “决策大脑”,负责全局调度、状态管理与 API 服务,确保集群按预期目标运行;
-
工作节点(Node):作为 “执行单元”,承载实际的应用负载(容器),并与控制平面协同完成资源管
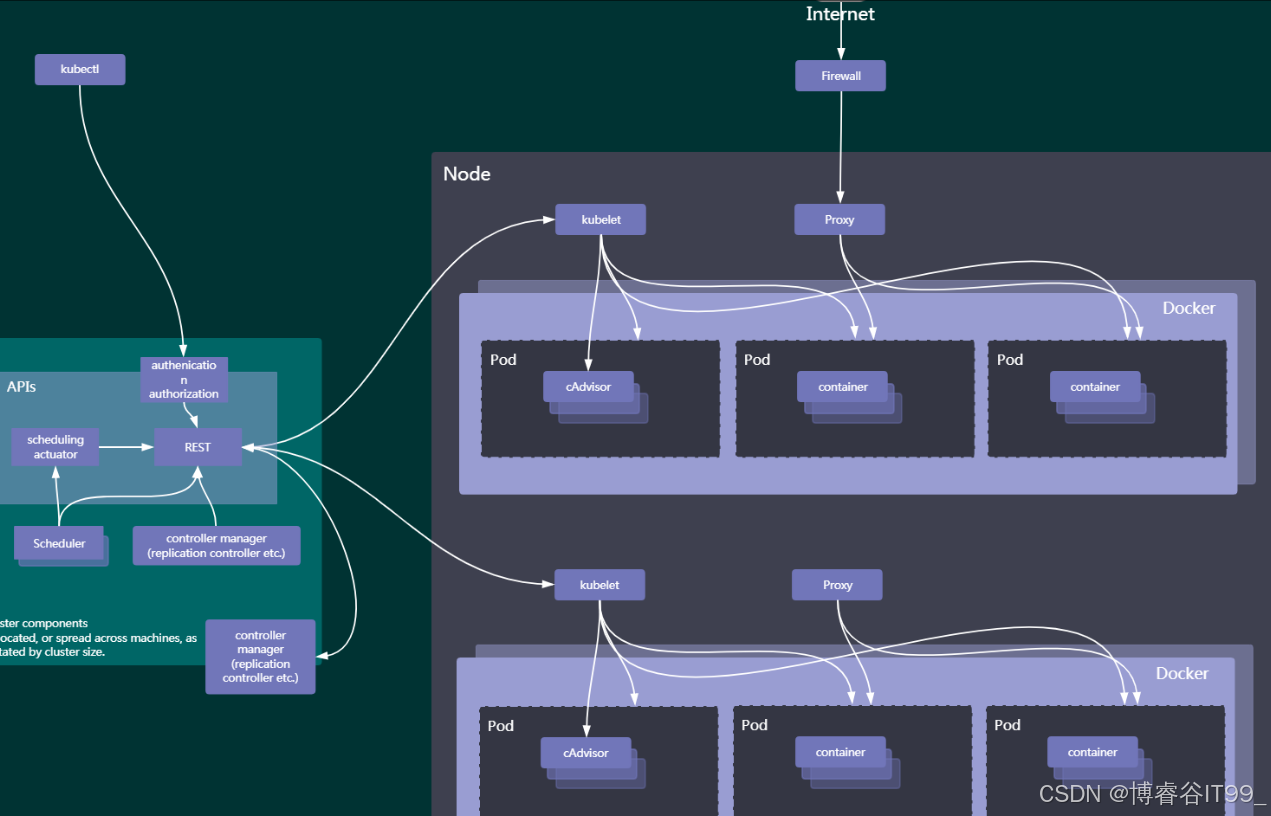
二、控制平面:集群的 “决策中枢”
控制平面由多个核心组件构成,每个组件各司其职,共同完成 “调度、管理、监控” 等决策任务。
1. API Server:集群的 “统一门户”
API Server 是 Kubernetes 所有操作的唯一入口,通过RESTful API对外暴露集群的全部能力(如创建 Pod、查询节点状态)。它同时承担:
-
认证与授权:验证所有请求的合法性(如通过 Token、证书确认用户身份),并判断请求是否有权限操作目标资源;
-
数据存储中介:所有集群状态(如 Pod、Node 的信息)最终存储在
etcd(分布式键值存储)中,API Server 是etcd的 “唯一写入入口”,确保集群状态的一致性。
无论是kubectl命令行工具、Web Dashboard,还是其他组件(如 Scheduler、Controller Manager),都必须通过 API Server 与集群交互,保证了 “单一数据源” 的设计原则。
2. Scheduler:资源的 “智能调度员”
当用户提交 “运行 Pod” 的请求时,Scheduler 会启动 “调度流程”:
-
资源感知:收集所有 Node 节点的实时资源状态(剩余 CPU、内存、存储等);
-
策略匹配:结合 Pod 的资源需求(如声明 “1 核 CPU、2GB 内存”)与调度策略(如 “亲和性规则”“反亲和性规则”“资源均衡策略”);
-
节点选择:为每个 Pod 挑选 “最适合” 的 Node 节点(如资源充足、符合亲和性要求),并通过 API Server 将调度结果通知目标 Node 的
kubelet。
这种 “智能调度” 确保了资源的高效利用,避免节点负载不均。
3. Controller Manager:集群的 “状态守护者”
Controller Manager 是一组 “控制器(Controller)” 的集合,每个控制器专注于维护一类资源的 “期望状态” 与 “实际状态” 一致:
-
副本控制器(Replication Controller):确保指定的 Pod 副本数始终符合预期(如配置 3 个副本,若某个 Pod 因节点故障终止,会自动在其他节点重建新 Pod);
-
节点控制器(Node Controller):监控 Node 节点的健康状态,若节点不可用,会自动将该节点上的 Pod 迁移至健康节点;
-
服务控制器(Service Controller):维护 “Service(服务)” 与 “Pod” 的关联,确保服务能稳定转发流量到后端 Pod。
通过这种 “闭环控制”,Controller Manager 让集群始终保持 “用户期望的状态”。
三、工作节点:负载的 “执行单元”
工作节点(Node)是承载应用的 “实体服务器”,运行着支撑 Pod 运行的核心组件。
1. Kubelet:Node 的 “代理人”
Kubelet 是 Node 与控制平面通信的 “桥梁”,核心职责包括:
-
接收调度指令:从 API Server 获取 “在本节点启动 Pod” 的指令;
-
管理容器生命周期:调用容器运行时(如 Docker)创建、启动、停止容器;
-
监控与上报状态:实时监控 Pod 和容器的运行状态(如存活、资源使用),并将状态上报给 API Server,让控制平面 “掌握” 集群的实时情况。
2. Kube-Proxy:网络的 “交通枢纽”
Kube-Proxy 负责 Node 的网络代理与服务暴露,解决两大核心问题:
-
Pod 间通信:通过维护
iptables或ipvs规则,实现集群内不同 Node 上的 Pod 互通(即使 Pod IP 动态变化,也能通过规则转发流量); -
服务(Service)访问:为 Service 分配 “虚拟 IP(VIP)”,并将外部或内部请求转发到后端 Pod,实现 “服务发现” 与 “负载均衡”。例如,访问 “nginx-service” 的 VIP 时,流量会被分发到多个 Nginx Pod 上。
3. 容器运行时与监控:Pod 的 “载体与管家”
-
容器运行时(如 Docker):是 Pod 的 “运行环境”,负责将容器镜像(如
nginx:latest)启动为实际的容器进程,为应用提供隔离的运行空间; -
cAdvisor:内置的容器监控工具,自动采集每个 Pod 和容器的资源使用数据(如 CPU 使用率、内存占用、磁盘 IO),这些数据既是 Scheduler 调度的依据,也是用户进行 “资源分析与优化” 的基础。
四、Pod:最小调度单元的 “设计智慧”
Pod 是 Kubernetes 中最小的调度与管理单元(而非单个容器),这种设计源于 “应用组件协同” 的需求:
-
多容器协作:一个 Pod 可包含多个紧密协作的容器(如 “前端 Nginx 容器 + 后端 Java 容器”),它们共享网络命名空间(同一 IP、端口范围)与存储卷(Volume),便于通过 “localhost通信” 或 “文件共享” 协同工作;
-
生命周期绑定:Pod 内的所有容器 “同生共死”—— 若一个容器崩溃,Kubelet 会重启整个 Pod,确保组件间的协同稳定性。
这种设计让 “应用组件的协作” 与 “集群的调度管理” 解耦,既保障了应用逻辑的完整性,又让集群能以 “Pod” 为单位高效调度。
五、外部访问与安全:从公网到集群内部的流量链路
当外部流量(如用户从 Internet 访问服务)进入集群时,需经过 “安全与网络” 的层层保障:
-
Firewall(防火墙):作为 “第一道防线”,过滤非法流量,仅允许合法端口(如 80、443)的请求进入;
-
Ingress/Service:Firewall 之后,流量通过 Ingress(七层 HTTP 路由)或Service(四层 TCP/UDP 负载均衡) 分发到后端 Pod,实现 “公网 → 集群服务 → 应用 Pod” 的完整访问链路。
这种分层的网络设计,既保障了安全性,又实现了服务的灵活暴露。
六、自愈与弹性:组件协同的 “智能体现”
Kubernetes 的 “故障自愈” 与 “弹性伸缩” 能力,是各组件协同的直接结果:
-
故障自愈:若某个 Pod 崩溃,Controller Manager 的 “副本控制器” 会检测到 “实际副本数 < 期望副本数”,随即通知 Scheduler 重新调度一个 Pod 到健康 Node,Kubelet 再启动新 Pod,整个过程无需人工干预;
-
弹性伸缩:当
cAdvisor采集的资源数据(如 CPU 使用率持续超过 80%)触发阈值时,** 水平自动扩缩容(HPA)** 会自动增加 Pod 副本数,Kubelet 随之在 Node 上启动新容器;流量低谷时,又会自动减少副本,节省资源。
这种 “自动化闭环” 让集群能自适应业务负载的变化。
结语:协同架构造就 “云原生操作系统”
Kubernetes 的核心优势,并非单个组件的强大,而是 “控制中枢(Master)→ 执行单元(Node)→ 最小载体(Pod)” 的分层协同 。控制平面像 “操作系统内核”,负责全局决策;工作节点像 “硬件资源池”,提供计算能力;Pod 像 “进程”,承载具体应用。
正是这套精密的组件协作机制,让 Kubernetes 能支撑起复杂的云原生应用,成为 “云时代的基础设施操作系统”—— 不仅能管理容器,更能让分布式系统的运维从 “人工折腾” 走向 “自动化智能调度”。
编辑分享
在文章中添加一些Kubernetes的实际应用案例
创作一篇面向初学者的Kubernetes核心架构科普文章
推荐一些讲解Kubernetes核心架构的视频