PandaWiki:AI 驱动的开源知识库系
文章目录
- PandaWiki:AI 驱动的开源知识库系统
- 摘要
- 0. 背景
- 1.总体架构
- 总体思路
- 界面展示
- 2. 系统需求分析
- 2.1 功能需求
- 2.2 非功能需求
- 3. 系统架构设计
- 4. 核心模块实现详解
- 4.1 文档处理模块
- 4.1.1 文档导入与解析
- 4.1.2 文本分片与预处理
- 4.1.3 向量嵌入生成
- 4.2 检索模块
- 4.2.1 向量检索实现
- 4.2.2 重排序优化
- 4.3 问答交互模块
- 4.3.1 对话管理
- 4.3.2 提示词构建
- 4.3.3 大模型推理
- 4.4 多渠道集成
- 5. 难点分析与解决方案
- 5.1 检索精度优化
- 5.2 大模型输出控制
- 5.3 性能与可扩展性
- 5.4 权限控制与数据隔离
- 6. 总结
- 参考文献
PandaWiki:AI 驱动的开源知识库系统
摘要
对爬虫&逆向&算法模型感兴趣的同学可以查看历史文章,私信作者一对一小班教学,学习详细案例和兼职接单渠道
随着企业数据量的爆发式增长,业务人员对数据查询的即时性、准确性需求日益迫切。传统 SQL 查询方式存在技术门槛高、响应速度慢等问题,制约了数据价值的高效释放。SQLBot 作为一款基于大模型和 RAG(检索增强生成)技术的智能问数系统,通过自然语言到 SQL 的自动转换,实现了数据查询的 “零代码” 化。本文采用深度模块化剖析方法,从系统架构、核心模块、技术难点及解决方案等维度,全面解析 SQLBot 的实现机制,为同类智能数据查询系统的设计与开发提供参考。
0. 背景
随着企业数字化转型的深入,知识管理成为组织效率提升的关键环节。传统的知识库系统普遍存在检索效率低、更新维护复杂、用户体验差等问题。根据 Gartner 研究报告,知识工作者平均花费 20% 的工作时间用于查找信息,低效的知识管理直接影响组织生产力。
近年来,大语言模型(LLM)和检索增强生成(RAG)技术的发展为智能知识库系统带来了革命性突破。RAG 技术通过将检索到的相关文档片段与大模型结合,既保留了大模型的生成能力,又通过引入外部知识解决了幻觉问题和知识时效性问题。
PandaWiki 正是在这一背景下诞生的开源解决方案,它基于 RAG 架构,整合了文档解析、向量嵌入、相似性检索和大模型问答等功能,帮助用户快速构建智能化的产品文档、技术文档、FAQ 和博客系统。
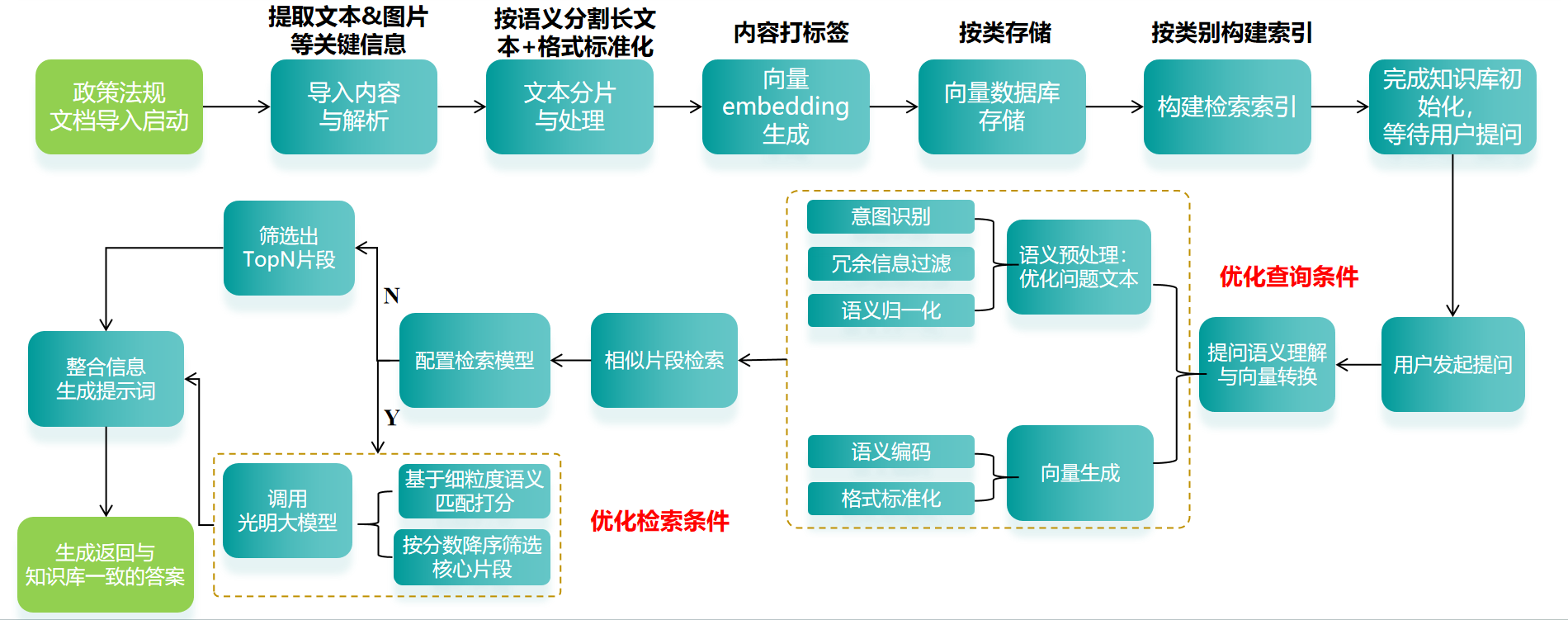
1.总体架构
总体思路
界面展示
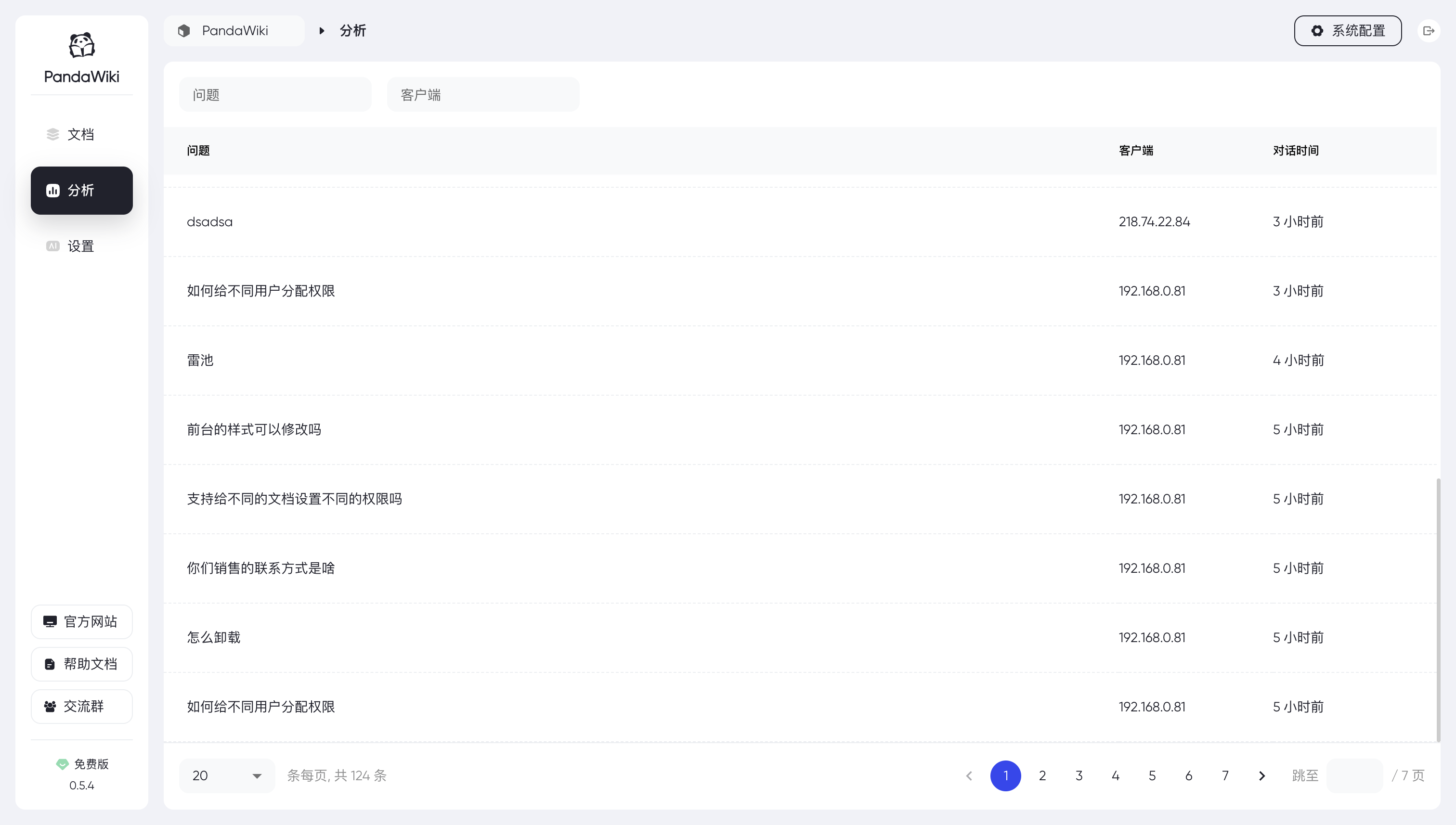
2. 系统需求分析
2.1 功能需求
PandaWiki 作为 AI 驱动的知识库系统,核心功能需求包括:
- 文档管理:支持多种格式文档的导入(URL、Sitemap、RSS、离线文件)与解析
- 知识组织:实现文档的结构化存储与索引构建
- 智能检索:基于语义的精准检索,支持自然语言查询
- AI 问答:根据知识库内容生成准确、简洁的回答,并标注来源
- 权限控制:基于用户组的访问权限管理
- 多端适配:支持网页端与微信服务号等多渠道交互
2.2 非功能需求
- 性能:检索响应时间快,问答生成延迟低
- 可扩展性:支持知识库规模线性扩展,单个知识库文档数可达 10 万级
- 准确性:问答结果准确率 > 90%(基于知识库内容)
- 易用性:直观的管理界面
- 安全性:敏感内容过滤,操作权限控制
3. 系统架构设计
PandaWiki 整体架构分为前端层、API 层、核心业务层和数据存储层四个部分。本文重点分析核心业务层的实现,其主要包含以下模块:
- 文档处理模块:负责文档导入、解析与预处理
- 向量检索模块:实现文档片段的向量嵌入与相似性检索
- 大模型交互模块:处理用户提问,生成回答
- 权限管理模块:控制文档访问权限
- 会话管理模块:维护用户对话上下文
4. 核心模块实现详解
4.1 文档处理模块
文档处理是知识库系统的基础,负责将原始文档转化为适合检索和生成的结构化数据。
4.1.1 文档导入与解析
PandaWiki 支持多种来源的文档导入,包括 URL、Sitemap、RSS 和离线文件。代码中通过 FormatNodeChunks 函数实现文档的格式化处理:
func FormatNodeChunks(nodeChunks []*RankedNodeChunks, baseURL string) string {documents := make([]string, 0)for _, result := range nodeChunks {document := strings.Builder{}document.WriteString(fmt.Sprintf("<document>\nID: %s\n标题: %s\nURL: %s\n内容:\n", result.NodeID, result.NodeName, result.GetURL(baseURL)))for _, chunk := range result.Chunks {// 处理内容中的静态文件URLprocessedContent := processContentWithBaseURL(chunk.Content, baseURL)document.WriteString(fmt.Sprintf("%s\n", processedContent))}document.WriteString("</document>")documents = append(documents, document.String())}return strings.Join(documents, "\n")
}
该函数将文档片段格式化,为后续的向量生成和检索做好准备。同时,processContentWithBaseURL 函数处理文档中的图片等静态资源链接,确保资源可正确访问。
4.1.2 文本分片与预处理
长文本需要进行分片处理以提高检索精度。PandaWiki 通过 SplitByTokenLimit 函数实现基于 Token 的文本分割:
func (u *LLMUsecase) SplitByTokenLimit(text string, maxTokens int) ([]string, error) {if maxTokens <= 0 {return nil, fmt.Errorf("maxTokens must be greater than 0")}encoding, err := tiktoken.GetEncoding("cl100k_base")if err != nil {return nil, fmt.Errorf("failed to get encoding: %w", err)}tokens := encoding.Encode(text, nil, nil)if len(tokens) <= maxTokens {return []string{text}, nil}// 计算需要的片段数量并分配空间numChunks := (len(tokens) + maxTokens - 1) / maxTokens // 向上取整result := make([]string, 0, numChunks)for i := 0; i < len(tokens); i += maxTokens {end := i + maxTokensif end > len(tokens) {end = len(tokens)}chunk := tokens[i:end]decodedChunk := encoding.Decode(chunk)result = append(result, decodedChunk)}return result, nil
}
该实现使用 tiktoken 库进行 Token 计算,确保每个分片的 Token 数量不超过设定阈值,为后续的向量生成和模型输入做好准备。
4.1.3 向量嵌入生成
文档片段需要转换为向量才能进行语义检索。PandaWiki 在 ModelUsecase 中初始化嵌入模型:
func (u *ModelUsecase) initEmbeddingAndRerankModel(ctx context.Context) error {// ... 省略部分代码 ...if err := u.createAndSyncModelToRAGLite(ctx, "bge-m3", domain.ModelTypeEmbedding); err != nil {return fmt.Errorf("create and sync model err: %v", err)}if err := u.createAndSyncModelToRAGLite(ctx, "bge-reranker-v2-m3", domain.ModelTypeRerank); err != nil {return fmt.Errorf("create and sync model err: %v", err)}if err := u.createAndSyncModelToRAGLite(ctx, "qwen2.5-3b-instruct", domain.ModelTypeAnalysis); err != nil {return fmt.Errorf("create and sync model err: %v", err)}return nil
}
系统默认使用 bge-m3 作为嵌入模型,将文本片段转换为高维向量,存储到向量数据库中。
4.2 检索模块
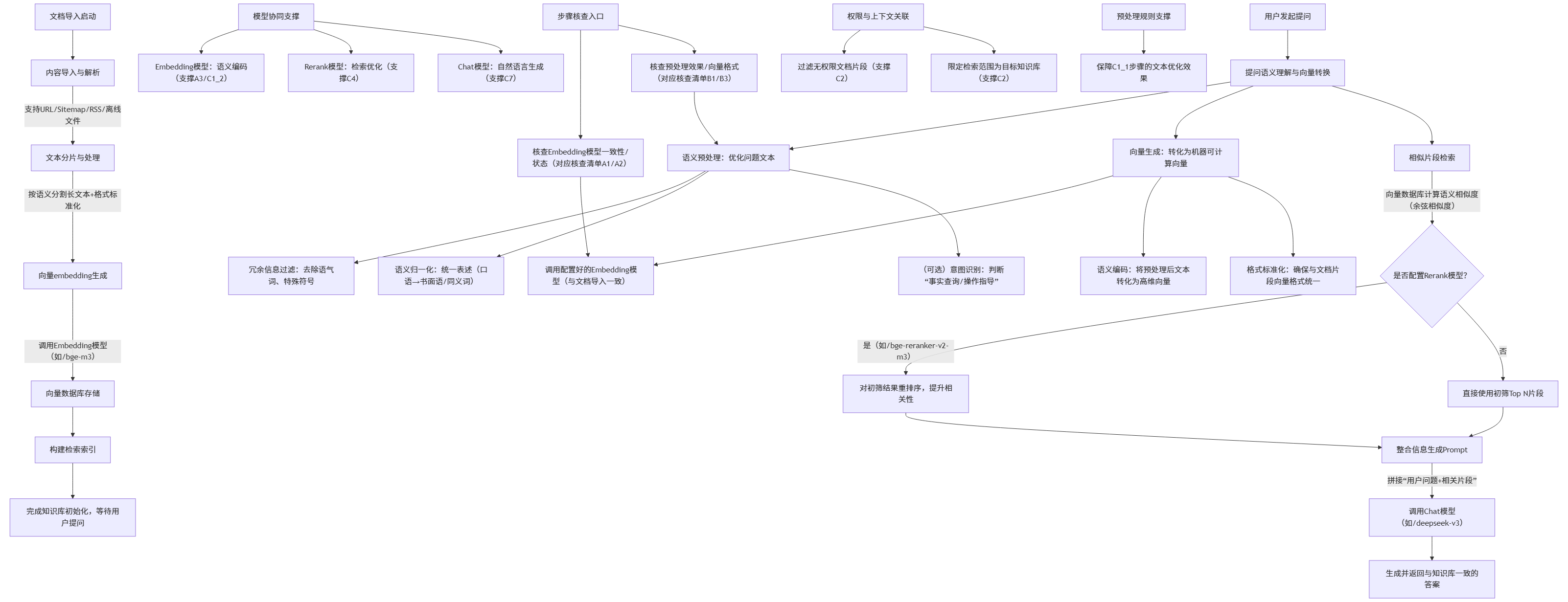
检索是 RAG 系统的核心环节,直接影响问答质量。PandaWiki 采用 向量检索 + 重排序" 的二级检索策略。
4.2.1 向量检索实现
在 LLMUsecase 的 GetRankNodes 方法中实现了向量检索:
func (u *LLMUsecase) GetRankNodes(ctx context.Context, datasetIDs []string, question string, groupIDs []int, historyMessages []*schema.Message) ([]*domain.RankedNodeChunks, error) {var rankedNodes []*domain.RankedNodeChunks// 从raglite获取相关文档records, err := u.rag.QueryRecords(ctx, datasetIDs, question, groupIDs, historyMessages)if err != nil {return nil, fmt.Errorf("get records from raglite failed: %w", err)}u.logger.Info("get related documents from raglite", log.Any("record_count", len(records)))// ... 处理检索结果 ...
}
该方法调用 RAG 服务查询与问题相关的文档片段,查询时考虑了用户组权限,确保只返回有权访问的内容。
4.2.2 重排序优化
对于检索到的初步结果,系统支持使用重排序模型(如 bge-reranker-v2-m3)进一步优化相关性:
// 在模型初始化时配置重排序模型
if err := u.createAndSyncModelToRAGLite(ctx, "bge-reranker-v2-m3", domain.ModelTypeRerank); err != nil {return fmt.Errorf("create and sync model err: %v", err)
}
重排序模型对初步检索结果进行精细排序,提升 top N 结果的相关性,为后续的答案生成提供更高质量的素材。
4.3 问答交互模块
问答交互模块负责处理用户提问,生成基于知识库的回答。
4.3.1 对话管理
Chat 方法实现了完整的对话流程管理:
func (u *ChatUsecase) Chat(ctx context.Context, req *domain.ChatRequest) (<-chan domain.SSEEvent, error) {eventCh := make(chan domain.SSEEvent, 100)go func() {defer close(eventCh)// 1. 获取应用详情并验证app, err := u.appRepo.GetOrCreateAppByKBIDAndType(ctx, req.KBID, req.AppType)// ... 省略验证逻辑 ...// 2. 获取模型并验证model, err := u.modelUsecase.GetChatModel(ctx)// ... 省略模型验证逻辑 ...// 3. 会话管理// ... 省略会话创建/验证逻辑 ...// 4. 检索文档并格式化提示词messages, rankedNodes, err := u.llmUsecase.FormatConversationMessages(ctx, req.ConversationID, req.KBID, groupIds)// ... 省略错误处理 ...// 5. LLM推理(流式回调)、消息存储、token统计// ... 省略推理逻辑 ...}()return eventCh, nil
}
该方法通过 goroutine 异步处理对话请求,使用 SSE (Server-Sent Events) 实现流式响应,提升用户体验。
4.3.2 提示词构建
FormatConversationMessages 方法构建用于大模型的提示词:
func (u *LLMUsecase) FormatConversationMessages(ctx context.Context,conversationID string,kbID string,groupIDs []int,
) ([]*schema.Message, []*domain.RankedNodeChunks, error) {// ... 省略部分代码 ...systemPrompt := domain.SystemPromptif prompt, err := u.promptRepo.GetPrompt(ctx, kbID); err != nil {u.logger.Error("get prompt from settings failed", log.Error(err))} else {if prompt != "" {systemPrompt = prompt}}template := prompt.FromMessages(schema.GoTemplate,schema.SystemMessage(systemPrompt),schema.UserMessage(domain.UserQuestionFormatter),)// ... 格式化文档内容 ...formattedMessages, err := template.Format(ctx, map[string]any{"CurrentDate": time.Now().Format("2006-01-02"),"Question": question,"Documents": documents,})// ... 返回格式化后的消息 ...
}
系统使用模板引擎构建提示词,将用户问题、相关文档片段和系统指令组合,为大模型提供清晰的生成指引。
4.3.3 大模型推理
ChatWithAgent 方法实现了与大模型的交互:
func (u *LLMUsecase) ChatWithAgent(ctx context.Context,chatModel model.BaseChatModel,messages []*schema.Message,usage *schema.TokenUsage,onChunk func(ctx context.Context, dataType, chunk string) error,
) error {resp, err := chatModel.Stream(ctx, messages)if err != nil {return fmt.Errorf("stream failed: %w", err)}// ... 处理流式响应 ...for {msg, err := resp.Recv()if err == io.EOF {break}if err != nil {return fmt.Errorf("recv failed: %w", err)}// ... 处理推理结果 ...if err := onChunk(ctx, "data", msg.Content); err != nil {return fmt.Errorf("on chunk data: %w", err)}}return nil
}
该方法支持流式推理,将大模型生成的内容实时返回给用户,减少等待感。同时记录 Token 使用量,用于统计和计费。
4.4 多渠道集成
PandaWiki 支持多渠道交互,以微信服务号为例:
func (cfg *WechatServiceConfig) Processmessage(msgRet *MsgRet, Kfmsg *WeixinUserAskMsg, GetQA bot.GetQAFun) error {// ... 省略消息处理逻辑 ...// 1. 首先响应用户if err := cfg.SendResponseToKfTxt(userId, openkfId, "正在思考您的问题,请稍等...", token); err != nil {return err}// 获取用户详细信息customer, err := GetUserInfo(userId, token)// ... 省略用户信息处理 ...// 调用AI获取回答wccontent, err := GetQA(cfg.Ctx, content, domain.ConversationInfo{UserInfo: domain.UserInfo{UserID: customer.ExternalUserID,NickName: customer.Nickname,Avatar: customer.Avatar,From: domain.MessageFromPrivate,}}, conversationID)// ... 省略后续处理 ...
}
该实现处理微信用户的提问,集成了人工客服转接功能,当用户输入 “转人工” 或 “人工客服” 时,系统会尝试转接人工服务。
5. 难点分析与解决方案
5.1 检索精度优化
难点:如何提高文档检索的相关性,直接影响问答质量。
解决方案:
- 采用二级检索策略:向量检索获取初步结果,重排序模型优化结果顺序
- 引入上下文感知:在检索时考虑历史对话信息
- 实现文档片段的精细分割,平衡语义完整性和检索精度
// 二级检索策略的实现体现在检索流程中
C2[相似片段检索] -->|向量数据库计算语义相似度| C3{是否配置Rerank模型?}
C3 -->|是| C4[对初筛结果重排序]
C3 -->|否| C5[直接使用初筛Top N片段]
5.2 大模型输出控制
难点:确保大模型生成的回答准确引用知识库内容,避免幻觉。
解决方案:
- 设计严格的提示词模板,明确要求模型基于提供的文档回答
- 实现引用标注机制,要求模型为每个事实性陈述标注来源
- 对模型输出进行后处理,验证引用的有效性
// 系统提示词中明确输出要求
var SystemPrompt = `
你是一个专业的AI知识库问答助手,要按照以下步骤回答用户问题。
// ... 省略部分内容 ...
6. 如果回答的内容引用了文档,请使用内联引用格式标注回答内容的来源:- 你需要给回答中引用的相关文档添加唯一序号,序号从1开始依次递增- 句号前放置引用标记- 引用使用格式 [[文档序号](URL)]
// ... 省略部分内容 ...
5.3 性能与可扩展性
难点:随着知识库规模增长,如何保持系统性能。
解决方案:
- 实现基于 Token 限制的文本分片,控制单个检索单元的大小
- 采用异步处理机制,将文档解析和向量生成等耗时操作放入队列
- 优化数据库查询,使用适当的索引和缓存策略
// 异步处理文档向量更新
func (u *ModelUsecase) TriggerUpsertRecords(ctx context.Context) error {// ... 省略部分代码 ...// 遍历所有节点err = u.nodeRepo.TraverseNodesByCursor(ctx, func(nodeRelease *domain.NodeRelease) error {// 通过消息队列异步更新向量内容nodeContentVectorRequests := []*domain.NodeReleaseVectorRequest{{KBID: nodeRelease.KBID,NodeReleaseID: nodeRelease.ID,Action: "upsert",},}if err := u.ragRepo.AsyncUpdateNodeReleaseVector(ctx, nodeContentVectorRequests); err != nil {return err}return nil})// ... 省略部分代码 ...
}
5.4 权限控制与数据隔离
难点:确保不同用户只能访问其有权限的文档内容。
解决方案:
- 实现基于用户组的权限管理机制
- 在检索环节过滤无权限的文档片段
- 对不同知识库进行严格的数据隔离
// 在检索时传入用户组ID,实现权限过滤
func (u *LLMUsecase) GetRankNodes(ctx context.Context, datasetIDs []string, question string, groupIDs []int, historyMessages []*schema.Message) ([]*domain.RankedNodeChunks, error) {// ... 省略部分代码 ...// 获取相关文档,传入groupIDs实现权限过滤records, err := u.rag.QueryRecords(ctx, datasetIDs, question, groupIDs, historyMessages)// ... 省略部分代码 ...
}
6. 总结
PandaWiki 作为一款开源的 AI 知识库系统,通过模块化设计实现了文档管理、智能检索和问答交互等核心功能。系统基于 RAG 架构,将向量检索与大模型生成相结合,既保证了回答的准确性,又具备自然语言理解和生成能力。
本文深入剖析了 PandaWiki 的技术实现,包括文档处理流程、检索机制、问答交互和多渠道集成等关键模块。针对系统实现中的难点,如检索精度、模型输出控制、性能优化和权限管理,PandaWiki 都提供了切实可行的解决方案。
PandaWiki 的开源实现为企业和开发者提供了一个可定制的智能知识库解决方案,降低了 AI 技术在知识管理领域的应用门槛,具有较高的实用价值和参考意义。
参考文献
- PandaWiki 官方文档. https://github.com/chaitin/PandaWiki