ForkJoinPool 核心的任务分配与执行
ForkJoinPool通过其独特的工作窃取(work-stealing)算法和双端队列(WorkQueue) 设计来高效地分配和执行任务。为了帮你快速理清头绪,我先用一个流程图来展示其核心的任务分配与执行逻辑:
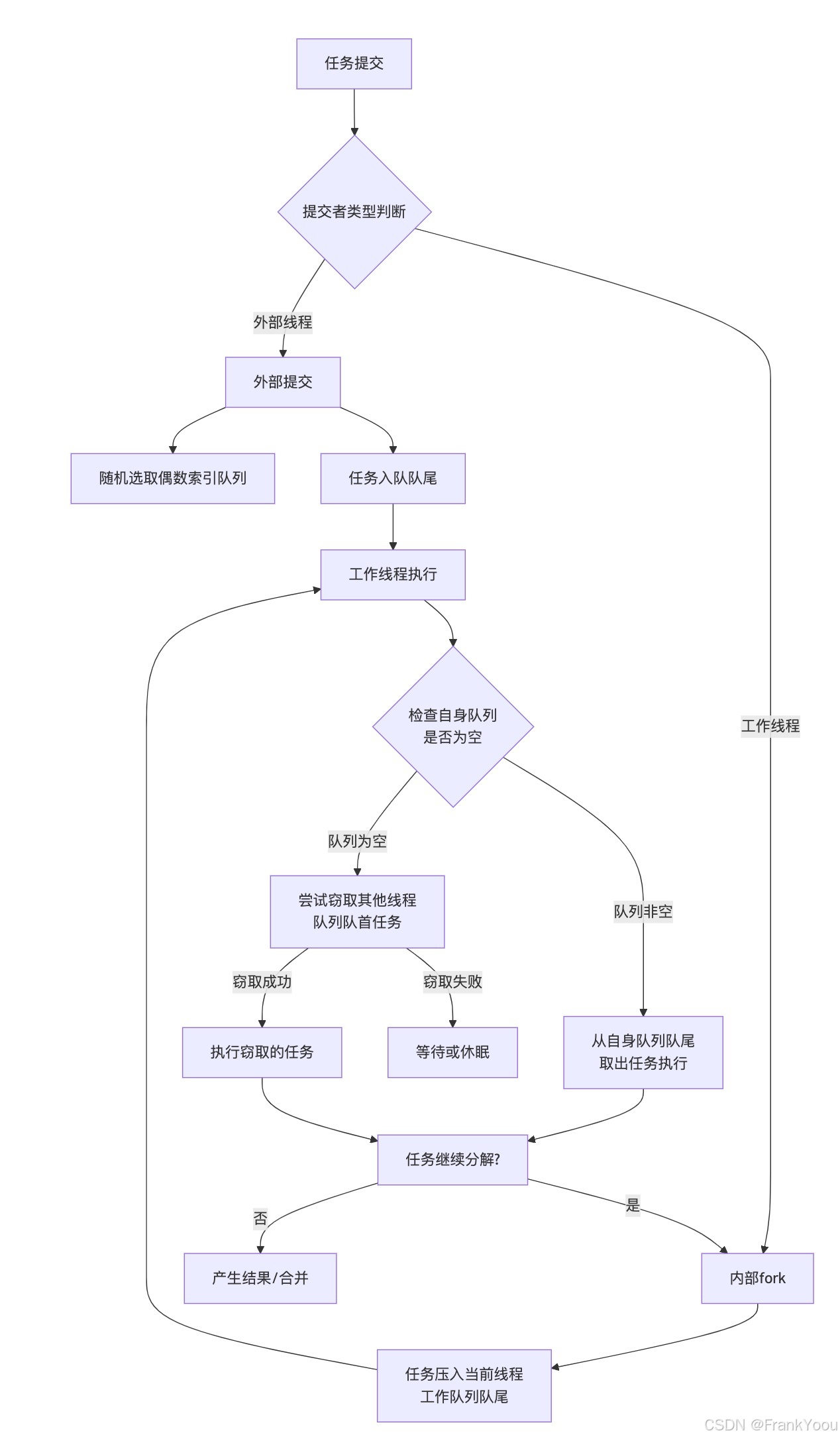
🔍 任务分配的核心机制
流程图展示了任务的生命周期,ForkJoinPool中任务分配的具体方式主要有两种:
-
外部任务提交
当你从非ForkJoinWorkerThread线程(例如主线程)提交任务时,ForkJoinPool会使用一个随机算法(通常涉及ThreadLocalRandom)来选择一个偶数索引的工作队列(WorkQueue),并将任务放入该队列的队尾。 -
内部任务分解(fork)
当工作线程(ForkJoinWorkerThread) 在执行任务过程中调用fork()方法时,产生的子任务会被直接压入当前线程自身的工作队列的队尾。这是一种后进先出(LIFO)的策略。
🔄 工作窃取与负载均衡
ForkJoinPool的精髓在于其工作窃取(work-stealing)机制,它能自动实现负载均衡:
-
窃取的发生:当一个工作线程自己的任务队列为空时,它不会空闲等待,而是会随机选择另一个工作线程的队列,从该队列的队首窃取一个任务来执行。
-
队列访问模式:工作线程处理自己的队列时是LIFO(后进先出),而从其他队列窃取任务时是FIFO(先进先出)。这样设计主要是因为最新加入的任务可能粒度更小,更快完成,有利于资源利用;而窃取队首的老任务,有助于均衡负载。
📝 任务的提交与执行方法
向ForkJoinPool提交任务主要有以下几种方式,它们都遵循上述的分配机制:
| 方法名 | 特点 | 适用场景 |
|---|---|---|
invoke() | 同步执行,调用后等待任务完成并返回结果。 | 需要立即获取结果的情况。 |
submit() | 异步执行,立即返回Future对象,可通过Future获取结果。 | 提交后需要继续处理其他逻辑,稍后获取结果。 |
execute() | 异步执行,没有返回值。 | 执行不需要返回结果的任务。 |
💡 实践建议与注意点
-
明智使用
fork()和join():在分解任务时,使用invokeAll()方法通常比分别为每个子任务调用fork()更高效。因为invokeAll()能避免当前线程闲置,让它也参与到子任务的计算中。 -
选择合适的任务类型:
-
RecursiveTask:用于有返回值的任务。 -
RecursiveAction:用于没有返回值的任务。
-
-
设定合理的任务阈值:确保任务能被有效地分解,但分解出的子任务也不能过小,以免任务管理和调度的开销超过并行计算带来的好处。
-
避免阻塞操作:ForkJoinPool的工作线程数量通常与CPU核心数相关。如果在任务中执行阻塞I/O操作,可能会阻塞工作线程,影响整个池的性能。请考虑使用专门的线程池来处理阻塞任务。
-
留意队列模式:ForkJoinPool可以根据设定的模式(
asyncMode),让队列采用先进先出(FIFO)而非后进先出(LIFO)的方式工作,这适用于某些不要求任务顺序完成的场景。
ForkJoinPool 不适合 I/O 密集型任务,原因如下:
| 方面 | 问题描述 | 影响 |
|---|---|---|
| 线程数量 | 固定数量(通常等于CPU核心数) | I/O等待时CPU空闲,无法充分利用资源 |
| 阻塞问题 | 工作线程在I/O时被阻塞 | 工作窃取机制失效,整体吞吐量下降 |
| 设计目标 | 为计算密集型任务优化 | 不适合大量等待的操作 |
| 资源利用 | 无法动态扩展线程数 | I/O密集型任务需要更多线程应对阻塞 |
💎 总结
ForkJoinPool的任务分配核心在于其工作窃取算法和双端队列。任务通过外部提交或内部fork() 进入队列。工作线程优先处理自身队列的任务,空闲时则窃取其他队列的任务,从而实现高效的负载均衡。这种设计特别适合可分解的、计算密集型的任务。