VLLM-大模型部署Qwen3-8b
1、Huggingfacce Transformer 本地部署
-
优点:私有化部署安全靠谱
-
缺点:需要 GPU、只能自己用
2、vLLM
vLLM 是一个开源的大模型推理加速框架,通过 PagedAttention 高效地管理 attention 中缓存的张量,实现了比 HuggingFace Transformers 高 14-24 倍的吞吐量。
-
优化的核心要点:提升内存 (显存) 的利用效率 => GPU 内存碎片化 = 慢
-
Github: https://github.com/vllm-project/vllm
-
Document: https://docs.vllm.ai/en/latest/
2.1. Continuous Batching
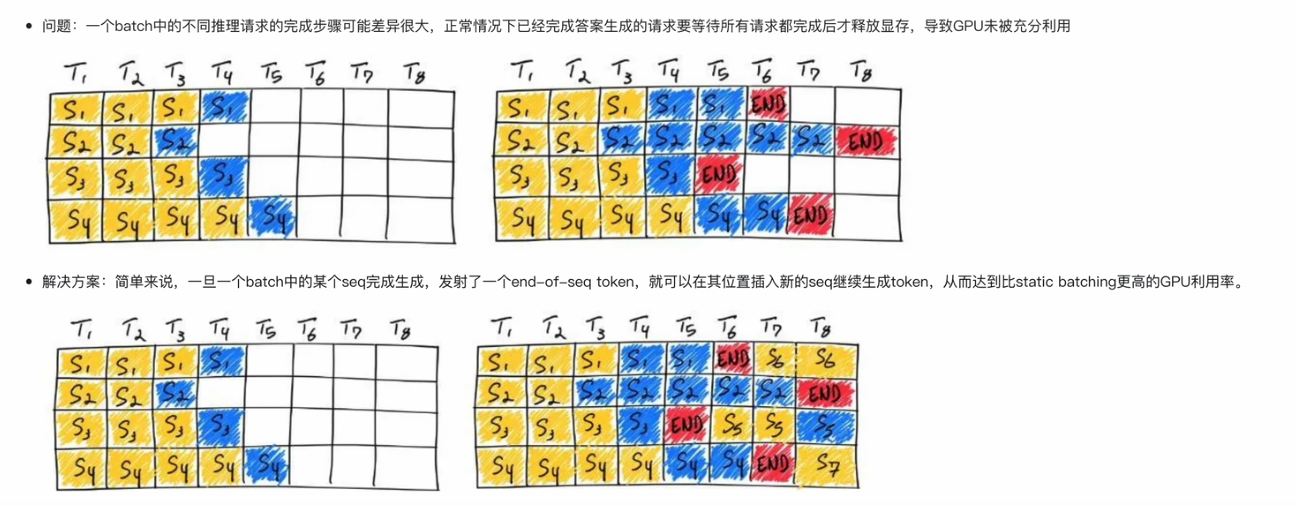
2.2. PagedAttention
2.2.1 kv缓存
PagedAttention 是 vLLM 的核心技术,它解决了 LLM 服务中内存的瓶颈问题。传统的注意力算法在自回归解码过程中,需要将所有输入 Token 的注意力键和值张量存储在 GPU 内存中,以生成下一个 Token。这些缓存的键和值张量通常被称为 KV 缓存。
import torch
from transformers import GPT2LMHeadModel, GPT2Tokenizermodel = GPT2LMHeadModel.from_pretrained("/WORK/Test/gpt", torchscript=True).eval()# tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("/WORK/Test/gpt")
in_text = "Lionel Messi is a"
in_tokens = torch.tensor(tokenizer.encode(in_text))# inference
token_eos = torch.tensor([198]) # line break symbol
out_token = None
i = 0
with torch.no_grad():while out_token != token_eos:logits, _ = model(in_tokens)out_token = torch.argmax(logits[-1, :], dim=0, keepdim=True)in_tokens = torch.cat((in_tokens, out_token), 0) # 每生成一个token,都会被拼接到原先的输入文本中text = tokenizer.decode(in_tokens)print(f'step {i} input: {text}', flush=True)i += 1out_text = tokenizer.decode(in_tokens)
print(f'Input: {in_text}')
print(f'Output: {out_text}')-
推理时的每个 step,都需要用到之前 step 的所有 token,为避免重复计算,我们考虑每个 step 缓存当前计算的 key/value 结果,这样之后的 step 便可直接读取缓存结果而避免重复性的计算
-
然而,天下没有免费的午餐,KV Cache 的使用受限于缓存大小。简单推导可得出 Cache 所需缓存为:2∗2∗b∗s∗dmodel∗nlayers,b 为 batch_size,s 为序列长度,假定参数用半精度存储,以 GPT - 3 - 175B 为例,若 batch_size=1,序列长度为 100,则 Cache 需要缓存2∗2∗100∗12288∗96=472MB
2.2.2 PagedAttention 原理和实现流程
vLLM 的作者发现大模型推理的性能瓶颈主要来自于内存:
-
自回归过程中缓存的 K 和 V 张量非常大,在 LLaMA-13B 中,单个序列输入进来需要占用 1.7GB 内存
-
内存占用是动态的,取决于输入序列的长度。由于碎片化和过度预留,现有的系统浪费了 60%-80% 的内存。PagedAttention 灵感来自于操作系统中虚拟内存和分页的经典思想,它可以允许在非连续空间存储连续的 KV 张量。具体来说:
-
PagedAttention 把每个序列的 KV 缓存进行了分块,每个块包含固定长度的 token,而在计算 attention 时可以高效地找到并获取那些块。
-
每个固定长度的块可以看成虚拟内存中的页,token 可以看成字节,序列可以看成进程。那么通过一个块表就可以将连续的逻辑块映射到非连续的物理块,而物理块可以根据新生成的 token 按需分配。
3、vllm部署方案
3.1 安装llm
pip install --upgrade pip
pip install vllm# 验证安装
pip show vllm3.2 准备模型文件
3.2.1 支持的模型列表
-
Text-only 大模型列表: https://docs.vllm.ai/en/latest/models/supported_models.html#list-of-text-only-language-models
-
多模态大模型列表: https://docs.vllm.ai/en/latest/models/supported_models.html#list-of-multimodal-language-models
3.2.2 下载模型
- Huggingface
# 安装依赖 pip install -U huggingface_hub# 设置环境变量 export HF_ENDPOINT=https://hf-mirror.com# 下载模型到指定路径 huggingface-cli download --resume-download Qwen/Qwen3-8B --local-dir {local_path} --local-dir-use-symlinks False # Qwen/Qwen3-8B为huggingface上的模型名称 # --local-dir 后设置本地保存路径 # --local-dir-use-symlinks False 参数禁用文件软链接,这样下载路径下所见即所得 - Modelscope
# 安装依赖 pip install modelscope# 下载到本地路径 modelscope download --model Qwen/Qwen3-8B --local_dir {local_path}
3.2.3 部署 OpenAI API 服务
服务启动命令
# 使用两卡来部署QwQ-32B
CUDA_VISIBLE_DEVICES=0,1 vllm serve {local_path} \--api-key abc123 # 设置api-key--served-model-name Qwen/Qwen3-8B # API服务的模型名称--max_model_len 4096 # 最大处理长度(输入prompt + 生成内容的 token 总数)--tensor-parallel-size 2 # 张量并行数量,和你使用GPU卡数保持一致--port 7890# 示例
vllm serve /root/models/Qwen3-8B --api-key abc123 --served-model-name Qwen/Qwen3-8B --max_model_len 4096 --port 78903.2.4 服务验证
Curl 验证
# 注意要设置正确的api-key
curl http://{ip}:7890/v1/completions -H "Authorization: Bearer abc123"Python 验证
import requestsurl = f"http://{ip}:7890/v1/models"
headers = {"Authorization": "Bearer abc123"}
response = requests.get(url, headers=headers)
print(response.json())3.2.5 调用对话服务
-
https://platform.openai.com/docs/api-reference/chat/create
from openai import OpenAI
client = OpenAI(base_url=f"http://{ip}:7890/v1",api_key="abc123",
)completion = client.chat.completions.create(model="Qwen/Qwen3-8B", # 模型名称要和启动服务时设定的 served-model-name 参数一致messages=[{"role": "user", "content": "Hello!"}]
)print(completion.choices[0].message)