k8s容器java应用频繁重启问题排查 OOM方向
1.排查是否为OOM导致的服务重启
1.1检查k8s yaml
{"env":[{"name":"JAVA_OPTS","value":"-Xmx4260m-Xms4260m -XX:+UseG1GC -XX:+UnlockExperimentalVMOptions -XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=512m -XX:+HeapDumpOnOutOfMemoryError -XX:OnOutOfMemoryError=/quitJava.sh-XX:HeapDumpPath=/var/logs/dump/app.hprof -XX:+PrintGCDetails-XX:+PrintGCDateStamps -Xloggc:/var/logs/dump/gc-app.log -Drocketmq.client.logLevel=error"}
上述可以看到在发生oom时会在/var/logs/dump目录下生成app.hprof 的dump文件,但实际查看未发现产生该文件
2.排查是否为k8s探针导致的服务重启
2.1 k8s三种探针
2.1.1Liveness Probe(存活探针)
作用:检测容器是否“活着”。
目标:判断应用进程是否挂掉或进入无法恢复的状态。
触发动作:如果探针失败,Kubernetes 会 重启容器(Restart Container)。
使用场景:应用死锁(thread lock)、无限循环、内存溢出后无法自我恢复。
Liveness 保证应用不挂死,失败会强制重启容器。
示例:
livenessProbe:httpGet:path: /healthport: 8080initialDelaySeconds: 30 # 等待应用启动periodSeconds: 10 # 每 10 秒检测一次failureThreshold: 3 # 连续 3 次失败才重启
2.1.2 Readiness Probe(就绪探针)
作用:检测容器是否“准备好接收流量”。
目标:判断应用是否可以处理请求。
触发动作:
探针失败时,Kubernetes 会 把 Pod 从 Service 的 Endpoints 中移除,不再接收流量。
容器不会被重启(与 Liveness 不同)。
使用场景:应用启动慢、依赖初始化(DB、缓存)
高负载下暂时无法处理请求
Readiness 控制流量,确保 Pod 只在准备好时才接收请求。
示例:
readinessProbe:httpGet:path: /readyport: 8080initialDelaySeconds: 10periodSeconds: 5failureThreshold: 3
2.1.3 Startup Probe(启动探针)
作用:专门用于 慢启动的应用,防止 Liveness 探针过早重启。
目标:在应用完全启动之前,延迟 Liveness 的判断。
触发动作:如果启动探针失败,Kubernetes 会 重启容器
成功后,Liveness 和 Readiness 才开始工作
使用场景:
Java、Spring Boot、Tomcat 等启动时间长的应用
避免 Liveness 在启动期间误杀容器
Startup 保护容器启动,长时间慢启动不会被误判为死掉。
示例:
startupProbe:httpGet:path: /healthport: 8080initialDelaySeconds: 0periodSeconds: 10failureThreshold: 30 # 等待 5 分钟
2.2 排查问题
根据2.1的内容,推断可能是Liveness Probe导致服务被kill重启,查看实际的探针脚本
livenessProbe:exec:command:- /bin/bash- '-c'- >r2=$(curl -i --max-time 10'http://localhost:8099/health_check' | awk 'NR==1 {print}')echo $r2if [[ ! "$r2" =~ "200" ]]; thenecho "health未就绪"exit 1fifailureThreshold: 5initialDelaySeconds: 40periodSeconds: 5successThreshold: 1timeoutSeconds: 10
由上述脚本可知存活探针主要是检测/health_check 返回状态码是否为200来判断应用是否正常,如果非200则会退出容器进行重启。
为了检查实际的检测情况,我们对脚本进行了修改,再每次探针执行时都进行状态码的打印,最终修改为
livenessProbe:exec:command:- /bin/bash- '-c'- >r2=$(curl -i --max-time 10'http://localhost:8099/health_check' | awk 'NR==1 {print}')echo $r2svc=appdate_hms=$(date '+%Y-%m-%d %H:%M:%S')echo -e "\n${date_hms} ===== $r2 =====" >> /var/logs/pid.txtif [[ ! "$r2" =~ "200" ]]; thenecho "health未就绪"exit 1fifailureThreshold: 5initialDelaySeconds: 40periodSeconds: 5successThreshold: 1timeoutSeconds: 10
等待服务自动重启后,发现在重启期间存活探针调用的/health接口未出现非200的状态码,说明不是探针导致的服务重启
3.连接k8s集群查看pod实际启动情况
3.1 执行指令查看
3.1.1 连接k8s集群
进入阿里云容器服务 Kubernetes版ACK,拿到kubeConfig,
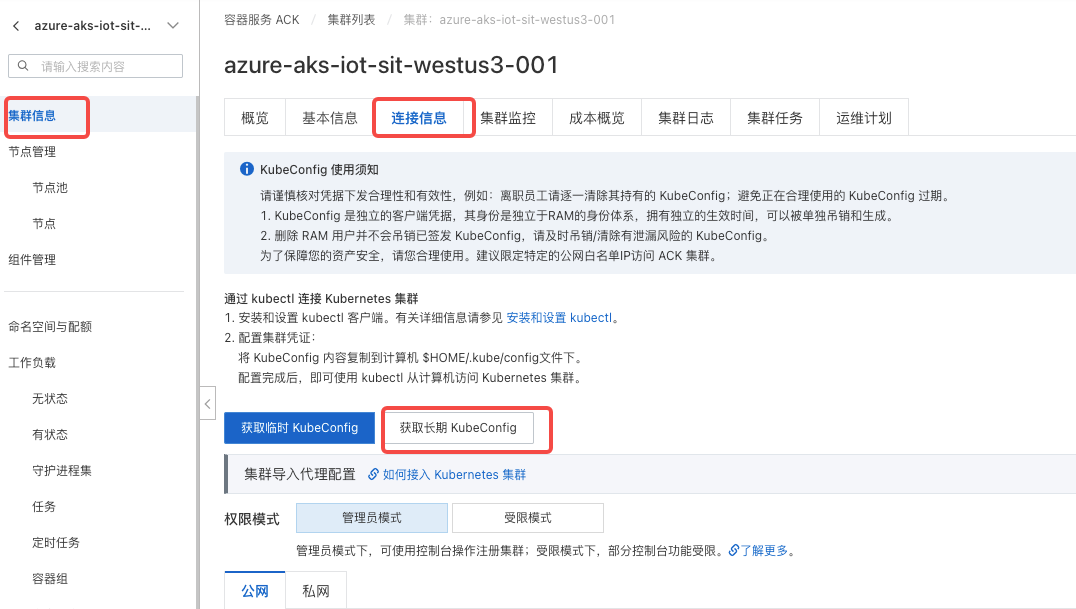
将kubeConfig复制到本地,并新建一个文件/Users/xxx/Utils/ecoflow-sit-cloud.yaml

3.1.2 查看pod信息
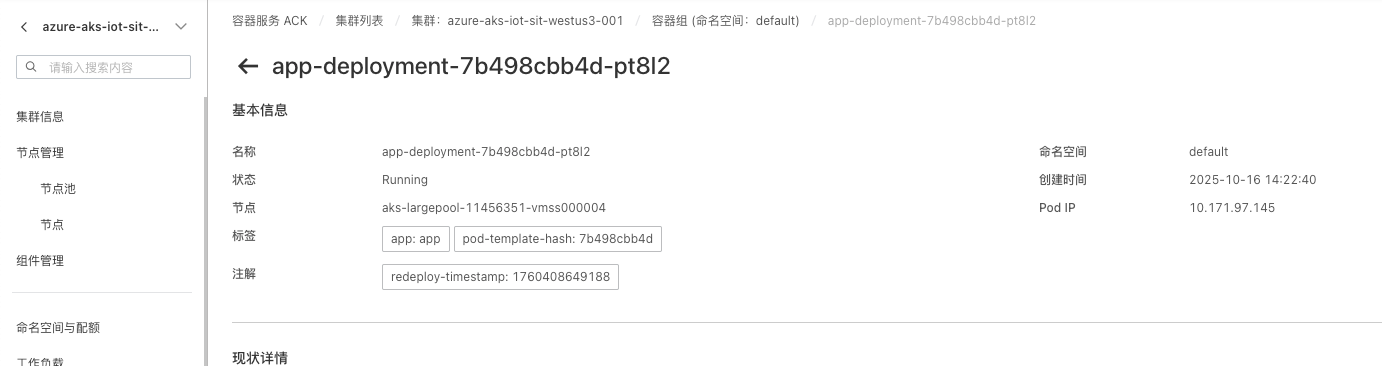
3.1.3 执行命令
第一步
export KUBECONFIG=/Users/xxx/Utils/ecoflow-sit-cloud.yaml
第二步 查看容器退出原因
kubectl describe pod app-deployment-67699fcf96-m255k -n default | grep -A5 "Last State"

发现最终还是oom导致的重启,但是为什么没有产生dump文件?
4.原因分析
4.1 未产生dump文件的原因
4.1.1 查看启动参数
{"env":[{"name":"JAVA_OPTS","value":"-Xmx4260m-Xms4260m -XX:+UseG1GC -XX:+UnlockExperimentalVMOptions -XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=512m -XX:+HeapDumpOnOutOfMemoryError -XX:OnOutOfMemoryError=/quitJava.sh-XX:HeapDumpPath=/var/logs/dump/app.hprof -XX:+PrintGCDetails-XX:+PrintGCDateStamps -Xloggc:/var/logs/dump/gc-app.log -Drocketmq.client.logLevel=error"}
发现在oom是会执行脚本quitJava.sh
pid=1 # ......1.........
kill -15 $pid
sleep 5s
kill -9 $pid
脚本首先会kill掉java进程,-15代表会等待后续的处理完成,但隔5秒后直接kill -9强制对进程进行删除
4.1.2 没有产生dump文件的原因
因为生产dump文件需要一定时间,但在oom时执行的脚本只等待5秒钟。所以实际情况是在5秒内未生成完dump文件,进程被kill掉了
5. 排查方式
5.1 修改oom执行脚本
pid=1 # ......1.........
date_hms=$(date '+%Y-%m-%d %H:%M:%S')
jpid=$(ps -ef | grep java | awk 'NR==2 {print $1}')
jstack ${jpid} > ${jstack_name}/var/logs/dump_jstack_${date_hms}.txt
kill -15 $pid
sleep 60s
kill -9 $pid
延时60秒进行kill -9 ,给dump日志足够的生成时间,并且增加jstack,在发生上述情况的时候可以记录相关线程的信息,方便后续排查oom问题
5.2 修改k8s pod yaml
在存活探针脚本中增加gc和jvm内存的相关日志,方便查看整体的内存变化趋势,用于排查当前的oom问题
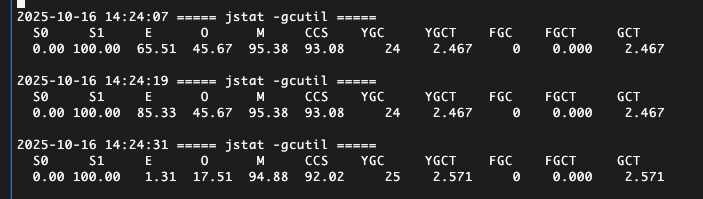
livenessProbe:exec:command:- /bin/bash- '-c'- >r2=$(curl -i --max-time 10'http://localhost:8099/health_check' | awk 'NR==1 {print}')jpid=$(ps -ef | grep java | awk 'NR==2 {print $1}')svc=appdate_hms=$(date '+%Y-%m-%d %H:%M:%S')jstat_gc_name=/var/logs/${svc}_jstat_gc.txtjstat_gcutil_name=/var/logs/${svc}_jstat_gcutil.txtecho -e "\n${date_hms} ===== jstat -gc =====" >> $jstat_gc_nameecho -e "\n${date_hms} ===== jstat -gcutil =====" >> $jstat_gcutil_namejstat -gc $(jps -l | grep /app.jar | awk '{print $1}') 1000 1 >> $jstat_gc_namejstat -gcutil $(jps -l | grep /app.jar | awk '{print $1}') 1000 1 >> $jstat_gcutil_nameecho $r2if [[ ! "$r2" =~ "200" ]]; thenecho "health未就绪"exit 1fifailureThreshold: 5initialDelaySeconds: 40periodSeconds: 12successThreshold: 1timeoutSeconds: 10
最终gc和内存执行效果