从零起步学习MySQL || 第五章:select语句的执行过程是怎么样的?(结合源码深度解析)

🧩 一、整体流程概览
MySQL 的执行过程可以分为两大部分:
-
Server 层(SQL 层):负责连接管理、解析、优化、执行等逻辑。
-
存储引擎层(Engine 层):负责数据的存取,比如 InnoDB、MyISAM 等。
可以理解为:
Server 层决定 “查什么、怎么查”,
存储引擎层负责 “去磁盘拿数据回来”。
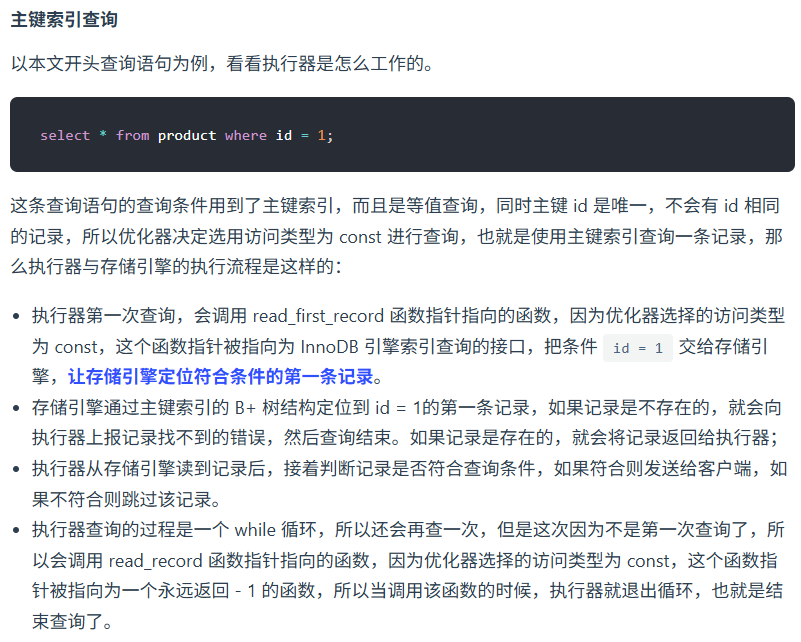
⚙️ 二、执行流程的 7 个核心阶段
假设你执行了:
SELECT name FROM user WHERE id = 1;
我们来看看 MySQL 内部经历的全过程。
① 连接器(Connection Manager)
-
当客户端(比如 Navicat、Java 应用中的 JDBC)发起连接时,MySQL 首先由 连接器 处理。
-
验证用户名、密码,建立 TCP 连接。
-
如果连接成功,会分配一个线程来处理这个客户端的后续请求。
🧠 知识点
-
长连接(
connection pool)可以复用连接,避免频繁建立/销毁 TCP。 -
但长连接可能导致 内存膨胀(因为线程上下文缓存),可通过
mysql_reset_connection()重置。这一过程无需重连和重新做权限验证,但是会将连接恢复至刚刚创建完的状态。
② 查询缓存(Query Cache)【MySQL 8.0 已移除】
-
旧版本 MySQL(<8.0)会先看这条 SQL 是否在缓存中。
-
如果命中缓存,直接返回结果。
-
因为更新任意表会导致缓存失效,所以性能反而不稳定,现代 MySQL 不再使用。

③ 解析器(Parser)
-
词法分析:把 SQL 拆成 token(如
SELECT、name、FROM、user等)(分析关键字)。 -
语法分析:生成 语法树(Parse Tree)。
-
检查语法是否正确(例如是否缺少关键字等)。
-
如果语法有问题,这里就会报错
-
🧠 类比理解
就像编译器在编译源代码时,先把源码拆解成语法结构。
④ 预处理器(Preprocessor)
-
进一步验证 SQL 的合法性:
-
表、字段是否存在;
-
用户是否有权限;
-
名称是否有歧义。
-
将 * 修改为所有列
-
根据源码发现,如果有表或字段不存在,会在语法分析后,预处理前出现报错
⑤ 优化器(Optimizer)
这是 MySQL 智能的地方 —— 选择最优执行计划。

优化器的主要任务:
-
确定使用哪个索引;
-
确定表连接顺序;
-
是否可以利用索引覆盖;
-
是否可以进行查询重写、常量折叠等。
📘 示例
SELECT * FROM user WHERE age > 20 AND name = 'Tom';
优化器可能决定:
-
使用
name索引(因为选择性更高), -
先过滤出
name='Tom'再判断age > 20。
🧠 查看优化器决策
EXPLAIN SELECT * FROM user WHERE age > 20 AND name = 'Tom';
可查看执行计划、索引使用情况、行扫描数等。
⑥ 执行器(Executor)
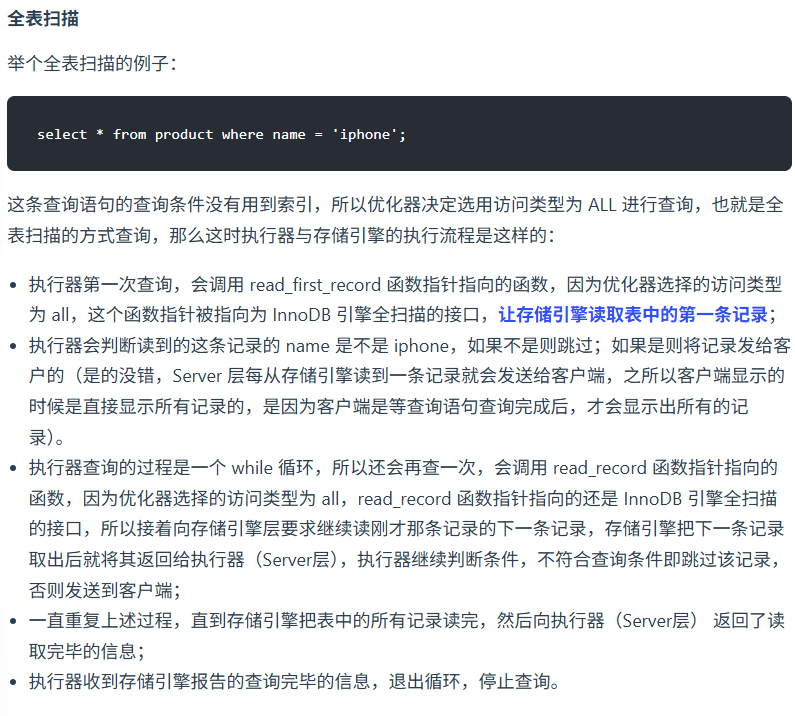
索引下推
前提假设
假设 t_user 表有以下结构:
- 主键:
id(聚簇索引,存储完整行数据)。 - 二级索引:
idx_age(包含age列,且包含reward列,即索引中存储了age和reward的值)。 - 数据示例(简化):
| id | age | reward |
|---|---|---|
| 1 | 21 | 50000 |
| 2 | 22 | 100000 |
| 3 | 23 | 80000 |
| 4 | 24 | 100000 |
| 5 | 25 | 120000 |
有索引下推时,reward = 100000 的判断会提前到存储引擎层,减少不必要的回表。过程如下:
步骤 1:Server 层发起查询,定位初始记录
Server 层调用存储引擎接口,要求找到满足 age > 20 的第一条二级索引记录(即 age=21 对应的索引项,对应 id=1)。
步骤 2:存储引擎层提前过滤 reward 条件
存储引擎定位到 age=21 的二级索引记录后,不立即回表,而是先检查索引中包含的 reward 列:
- 该记录的
reward=50000,不满足reward=100000→ 直接跳过这条索引记录,不回表。
步骤 3:遍历下一条索引记录,重复过滤
存储引擎继续取下一条 age > 20 的索引记录(age=22,对应 id=2):
- 检查索引中的
reward=100000→ 满足条件 → 执行回表:根据id=2到聚簇索引中取出完整行数据(id=2, age=22, reward=100000),返回给 Server 层。
步骤 4:Server 层最终校验并返回
Server 层拿到回表后的完整行,检查所有查询条件(这里只剩最终校验,通常已符合),将记录发送给客户端。
步骤 5:继续遍历剩余索引记录
存储引擎继续遍历后续 age > 20 的索引记录:
age=23(reward=80000)→ 不满足,跳过,不回表;age=24(reward=100000)→ 满足,回表,返回给 Server 层;age=25(reward=120000)→ 不满足,跳过,不回表。
🧩 执行器与引擎的关系
-
执行器只管“要什么数据”;
-
存储引擎负责“怎么取数据”。
⑦ 存储引擎层(Engine Layer)
以 InnoDB 为例(MySQL 默认引擎):
-
根据索引(B+ 树)定位数据页(Page);
-
如果数据页在 Buffer Pool(内存缓存),直接返回;
-
如果不在内存中,从磁盘加载到 Buffer Pool;
-
把对应行数据返回给执行器;
-
执行器拿到结果后,返回给客户端。
🧠 知识点:Buffer Pool
-
InnoDB 的数据按页(通常 16KB)为单位管理;
-
缓存热数据,减少磁盘 I/O;
-
类似于操作系统的页缓存机制。
🔍 三、整个执行流程图(简化版)
客户端│▼
连接器 → [查询缓存(已废弃)] → 解析器 → 预处理器 → 优化器 → 执行器│▼存储引擎(InnoDB)│▼磁盘数据 / Buffer Pool
🚀 四、性能优化角度总结
-
连接层优化:使用连接池,避免频繁创建连接。
-
SQL 优化:查看执行计划(
EXPLAIN),确认索引是否被使用。 -
索引优化:建立合适的联合索引、覆盖索引。
-
缓存优化:利用应用层缓存(Redis),减少频繁查询。
-
内存优化:调大
innodb_buffer_pool_size,让更多数据命中内存。
🧭 五、完整示例总结
以语句:
SELECT name FROM user WHERE id = 1;
整个过程如下:
-
客户端通过 TCP 连接到 MySQL;
-
连接器验证身份;
-
SQL 进入解析器生成语法树;
-
预处理器验证表和列;
-
优化器确定使用主键索引;
-
执行器调用 InnoDB;
-
InnoDB 在 Buffer Pool 查找对应页;
-
若页存在,直接返回;否则读磁盘;
-
执行器将结果返回客户端;
-
客户端接收并显示结果。