(论文速读)ECLIPSE:突破性的轻量级文本到图像生成技术
论文题目:ECLIPSE: A Resource-Efficient Text-to-Image Prior for Image Generations(用于图像生成的资源高效的文本到图像优先)
会议:CVPR2024
摘要:文本到图像(T2I)扩散模型,特别是unCLIP模型(例如,DALL-E-2),以大量计算资源为代价,在各种构成T2I基准上实现了最先进(SOTA)的性能。unCLIP堆栈包括T2I先验图像解码器和扩散图像解码器。与潜在扩散模型相比,仅T2I先验模型就增加了10亿个参数,这增加了计算量和高质量数据的要求。本文介绍了一种新的对比学习方法ECLIPSE1,它既具有参数效率,又具有数据效率。ECLIPSE利用预先训练的视觉语言模型(例如CLIP)将知识提取到先前的模型中。我们证明,ECLIPSE训练先验,只有3.3%的参数和仅仅2.8%的数据训练,超过基线tti先验在资源有限的设置下平均71.6%的偏好得分。它也达到了与SOTA大模型相当的性能,在遵循文本组合的能力方面达到了平均63.36%的偏好得分。在两个unCLIP扩散图像解码器(Karlo和Kandinsky)上进行的大量实验证实,ECLIPSE优先级始终提供高性能,同时显着减少了对资源的依赖。
项目页面:https://eclipset2i.vercel.app/
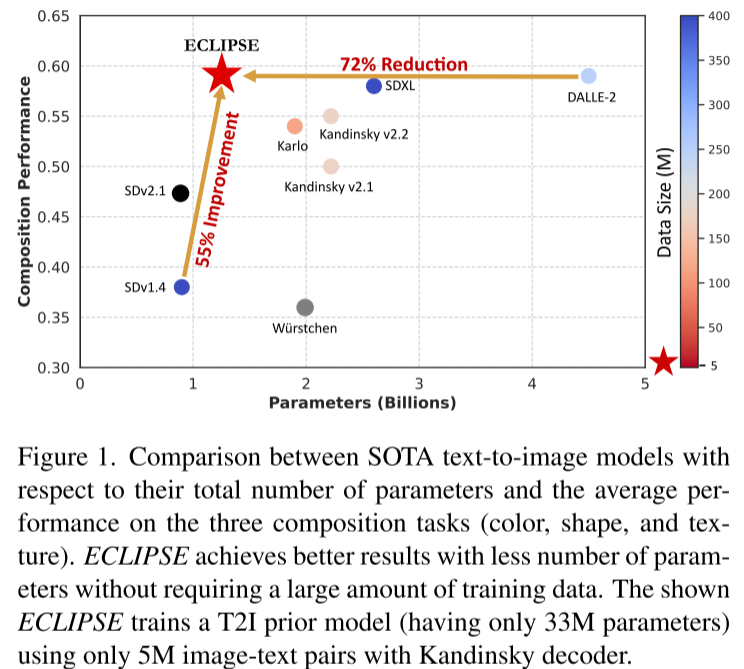
引言:AI图像生成的新突破
在人工智能快速发展的今天,文本到图像生成技术已经从科幻概念变为现实应用。从DALL-E-2到Stable Diffusion,这些模型能够根据文字描述生成令人惊叹的图像。然而,这些先进模型背后隐藏着一个巨大的问题:它们需要庞大的计算资源和海量数据才能达到理想效果。
近期,来自亚利桑那州立大学的研究团队提出了一个革命性的解决方案——ECLIPSE(Efficient Contrastive Learning-based Image Prior for Scalable Efficiency),这项技术在保持图像生成质量的同时,将所需的计算资源和数据量减少了90%以上。
现有技术面临的挑战
计算资源的沉重负担
目前主流的文本到图像生成模型主要分为两大类:
- 潜在扩散模型(LDM):如广受欢迎的Stable Diffusion
- unCLIP模型:如DALL-E-2、Kandinsky等
其中,unCLIP模型在处理复杂的文本组合描述(如"一个蓝色背包和一头棕色奶牛")时表现更加出色,但代价是巨大的计算成本。这些模型通常包含两个核心组件:
- 文本到图像先验模块(T2I Prior):负责将文本嵌入转换为图像嵌入
- 扩散图像解码器:基于图像嵌入生成最终图像
问题在于,T2I Prior模块单独就包含约10亿参数,使得整个系统参数量超过20亿,训练需要数千个GPU小时。
数据饥渴症
这些大型模型对数据的需求同样惊人:
- DALL-E-2:2.5亿图像-文本对
- Kandinsky:1.77亿图像-文本对
- Karlo:1.15亿图像-文本对
如此庞大的数据需求不仅增加了训练成本,也限制了技术的普及和应用。
ECLIPSE:轻量化的突破性方案
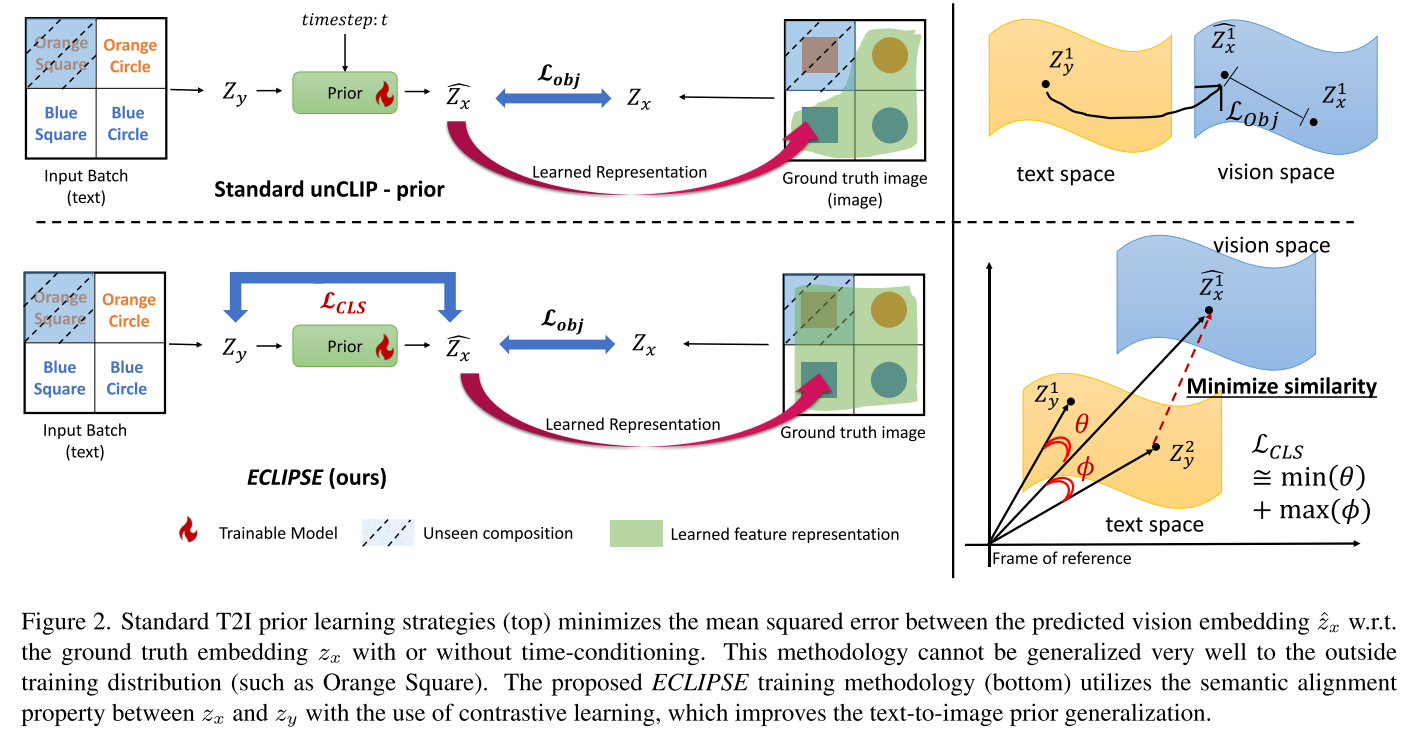
核心思想:从扩散到对比学习
ECLIPSE的核心创新在于重新思考了T2I Prior的训练方式。研究团队发现,传统的扩散prior过程不仅计算成本高,对最终图像质量的贡献也微乎其微。基于这一发现,他们提出了两个关键改进:
- 摒弃扩散过程:采用非扩散的神经网络架构
- 引入对比学习:利用CLIP等预训练模型的知识进行指导
技术细节:双重损失函数设计
ECLIPSE采用了巧妙的双重损失函数设计:
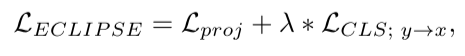
其中:
- L_proj(投影损失):确保文本嵌入能够准确映射到图像嵌入空间
- L_CLS(对比损失):利用CLIP的语义对齐特性,提高模型的泛化能力
这种设计使得模型不仅能学会基本的文本-图像映射,还能理解跨模态的语义关系,从而在面对训练时未见过的组合时仍能生成合理的图像。
架构优化:小而精的设计
ECLIPSE对模型架构进行了大胆的精简:
- 参数量:从10亿减少到3300万(Karlo)和3400万(Kandinsky)
- 参数减少比例:97%
- 训练时间:缩短至50个GPU小时
实验结果:小模型,大性能
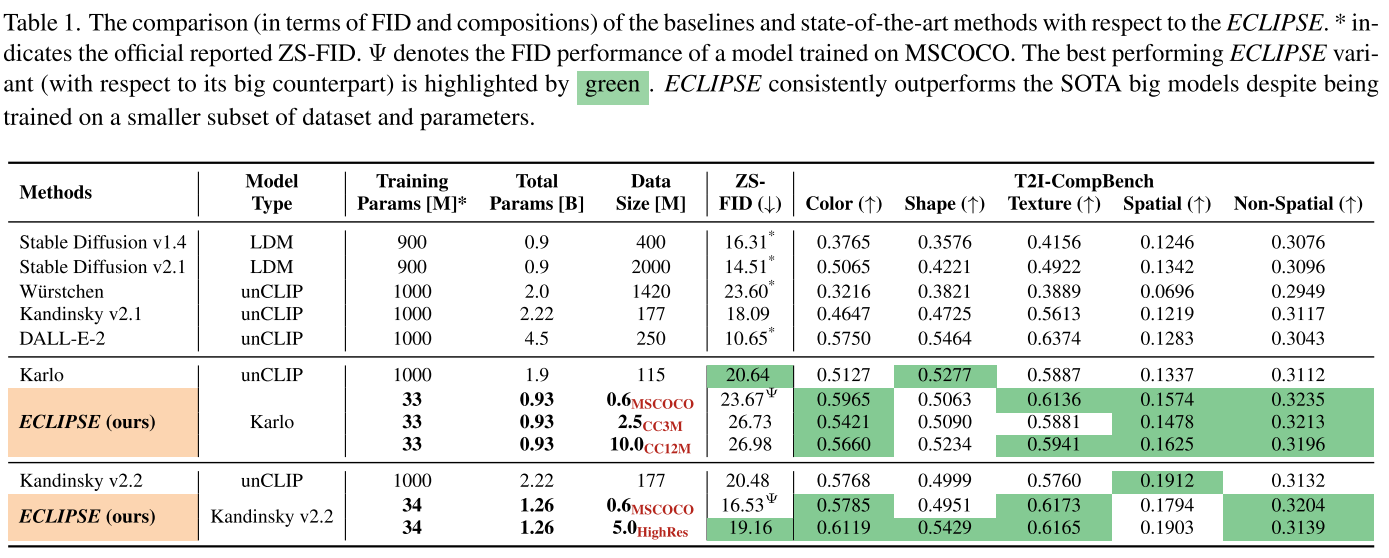

量化表现
研究团队在多个标准数据集上进行了全面测试,结果令人印象深刻:
资源效率对比:
- 仅使用3.3%的参数量
- 仅需要2.8%的训练数据
- 训练时间减少95%+
性能表现:
- 在资源受限环境下,平均偏好分数达到71.6%
- 在文本组合跟随能力上,与SOTA大模型性能相当(63.36%)
- 在T2I-CompBench的颜色、形状、纹理等任务上全面超越基线模型
质量验证
通过大量的定性和定量评估,ECLIPSE展现出了令人信服的图像生成质量:
复杂文本理解能力:
- "一个蓝色背包和一头棕色奶牛"
- "一个苹果和一头大象,苹果和大象一样大"
- "戴着红色太阳镜的金毛犬在夜间"
在这些复杂的组合描述上,ECLIPSE生成的图像在语义准确性和视觉质量方面都表现出色,甚至在某些情况下超越了使用更多资源训练的大型模型。
技术深度分析
为什么对比学习如此有效?
传统的扩散prior训练主要依赖于最小化重构误差,这种方式容易产生过拟合,特别是在数据量有限的情况下。而ECLIPSE引入的对比学习机制具有以下优势:
- 更好的泛化能力:通过学习文本-图像的相对关系而非绝对映射
- 知识迁移:充分利用CLIP等大型预训练模型的丰富知识
- 鲁棒性提升:对训练数据的分布变化更加敏感
非扩散架构的优势
研究团队通过详细的消融实验发现:
- 增加扩散步数并不能显著提升图像质量
- 扩散过程中的噪声注入甚至会略微降低性能
- 非扩散架构在保持性能的同时大幅减少了推理时间
实际应用前景
民主化AI图像生成
ECLIPSE的突破意义不仅在于技术本身,更在于它为AI图像生成技术的普及铺平了道路:
降低门槛:
- 个人开发者和小团队也能训练高质量的图像生成模型
- 减少对昂贵GPU集群的依赖
- 缩短从想法到产品的开发周期
环保友好:
- 显著减少训练过程的能源消耗
- 降低AI技术发展的碳足迹
- 支持可持续的AI发展理念
商业化潜力
内容创作产业:
- 广告设计自动化
- 游戏素材快速生成
- 个性化内容制作
教育和研究:
- 降低学术研究的技术门槛
- 支持更多创新实验
- 加速相关技术的发展
技术局限与未来展望
当前局限
尽管ECLIPSE取得了显著进展,但仍存在一些局限:
- 数据质量敏感性:模型性能仍然受到训练数据质量的影响
- 复杂场景处理:在处理极其复杂的空间关系时可能存在不足
- 风格一致性:在某些艺术风格的生成上可能不如专门优化的大模型
未来发展方向
技术改进:
- 进一步优化对比学习策略
- 探索更高效的架构设计
- 结合其他先进的训练技巧
应用扩展:
- 支持更多模态的生成任务
- 集成到实时应用中
- 开发专门的行业解决方案
结论:小模型的大智慧
ECLIPSE项目展示了一个重要的发展趋势:在AI领域,更大并不总是更好。通过巧妙的算法设计和深入的问题分析,研究团队证明了我们可以用更少的资源实现更高的效率。
这项工作的意义远超技术本身。它为整个AI社区提供了一个重要启示:真正的创新往往来自于对问题本质的深入理解,而非简单的规模扩张。
随着ECLIPSE等轻量化技术的不断发展,我们有理由相信,强大的AI图像生成能力将不再是少数科技巨头的专利,而是每个创作者都能触及的工具。这将开启一个更加民主化、更具创新性的AI应用新时代。